| ±ύΦ≠ΆΤΦω: |
±ΨΈΡ÷ς“ΣΫ≤ΫβΝΥΈΡΦΰœΒΆ≥≤ψ¥ΈΖ÷ΈωΓΔΈΡΦΰœΒΆ≥ΫαΙΙ”κΙΛΉς‘≠άμ’βΝΫΗωΖΫΟφΒΡΡΎ»ίΓΘ
±ΨΈΡά¥Ή‘”ΎΥ―ΚϋΘ§”…ΜπΝζΙϊ»μΦΰAnna±ύΦ≠ΓΔΆΤΦωΓΘ |
|
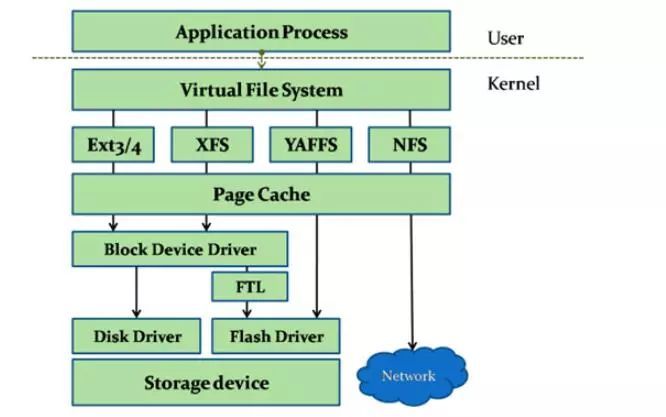
“ΜΓΔΈΡΦΰœΒΆ≥≤ψ¥ΈΖ÷Έω
”……œΕχœ¬÷ς“ΣΖ÷ΈΣ”ΟΜß≤ψΓΔVFS≤ψΓΔΈΡΦΰœΒΆ≥≤ψΓΔΜΚ¥φ≤ψΓΔΩι…η±Η≤ψΓΔ¥≈≈Χ«ΐΕ·≤ψΓΔ¥≈≈ΧΈοάμ≤ψ
”ΟΜß≤ψ
Ήν…œΟφ”ΟΜß≤ψΨΆ «Έ“Ο«»’≥Θ Ι”ΟΒΡΗς÷÷≥Χ–ρΘ§–η“ΣΒΡΫ”ΩΎ÷ς“Σ «ΈΡΦΰΒΡ¥¥Ϋ®ΓΔ…Ψ≥ΐΓΔ¥ρΩΣΓΔΙΊ±’ΓΔ–¥ΓΔΕΝΒ»ΓΘ
VFS≤ψ
Έ“Ο«÷ΣΒάLinuxΖ÷ΈΣ”ΟΜßΧ§ΚΆΡΎΚΥΧ§Θ§”ΟΜßΧ§«κ«σ”≤ΦΰΉ ‘¥–η“ΣΒς”ΟSystem CallΆ®ΙΐΡΎΚΥΧ§»Ξ Βœ÷ΓΘ”ΟΜßΒΡ’β–©ΈΡΦΰœύΙΊ≤ΌΉςΕΦ”–Ε‘”ΠΒΡSystem
CallΚ· ΐΫ”ΩΎΘ§Ϋ”ΩΎΒς”ΟVFSΕ‘”ΠΒΡΚ· ΐΓΘ
ΈΡΦΰœΒΆ≥≤ψ
≤ΜΆ§ΒΡΈΡΦΰœΒΆ≥ Βœ÷ΝΥVFSΒΡ’β–©Κ· ΐΘ§Ά®Ιΐ÷Η’κΉΔ≤αΒΫVFSάοΟφΓΘΥυ“‘Θ§”ΟΜßΒΡ≤ΌΉςΆ®ΙΐVFSΉΣΒΫΗς÷÷ΈΡΦΰœΒΆ≥ΓΘΈΡΦΰœΒΆ≥Α―ΈΡΦΰΕΝ–¥ΟϋΝνΉΣΜ·ΈΣΕ‘¥≈≈ΧLBAΒΡ≤ΌΉςΘ§ΤπΝΥ“ΜΗωΖ≠“κΚΆ¥≈≈ΧΙήάμΒΡΉς”ΟΓΘ
ΜΚ¥φ≤ψ
ΈΡΦΰœΒΆ≥ΒΉœ¬”–ΜΚ¥φΘ§Page CacheΘ§Φ”ΥΌ–‘ΡήΓΘΕ‘¥≈≈ΧLBAΒΡ–¥ ΐΨίΜΚ¥φΒΫ’βάοΓΘ
Ωι…η±Η≤ψ
Ωι…η±ΗΫ”ΩΎBlock Device «”Οά¥ΖΟΈ ¥≈≈ΧLBAΒΡ≤ψΦΕΘ§ΕΝ–¥ΟϋΝνΉιΚœ÷°Κσ≤ε»κΒΫΟϋΝνΕ”Ν–Θ§¥≈≈ΧΒΡ«ΐΕ·¥”Ε”Ν–ΕΝΟϋΝν÷¥––ΓΘLinux…ηΦΤΝΥΒγΧίΥψΖ®Β»Ε‘ΚήΕύLBAΒΡΕΝ–¥Ϋχ––”≈Μ·≈≈–ρΘ§ΨΓΝΩΑ―Ν§–χΒΊ÷ΖΖ≈‘Ύ“ΜΤπΓΘ
¥≈≈Χ«ΐΕ·≤ψ
¥≈≈ΧΒΡ«ΐΕ·≥Χ–ρΑ―Ε‘LBAΒΡΕΝ–¥ΟϋΝνΉΣΜ·ΈΣΗςΉ‘ΒΡ–≠“ιΘ§±»»γ±δ≥…ATAΟϋΝνΘ§SCSIΟϋΝνΘ§Μρ’Ώ «Ή‘ΦΚ”≤ΦΰΩ…“‘ Ε±πΒΡΉ‘Ε®“εΟϋΝνΘ§ΖΔΥΆΗχ¥≈≈ΧΩΊ÷ΤΤςΓΘHost
Based SSD…θ÷Ν‘ΎΩι…η±Η≤ψΚΆ¥≈≈Χ«ΐΕ·≤ψ Βœ÷ΝΥFTLΘ§±δ≥…Ε‘Flash–ΨΤ§ΒΡ≤ΌΉςΓΘ
¥≈≈ΧΈοάμ≤ψ
ΕΝ–¥Έοάμ ΐΨίΒΫ¥≈≈ΧΫι÷ ΓΘ
ΕΰΓΔΈΡΦΰœΒΆ≥ΫαΙΙ”κΙΛΉς‘≠άμ
Έ“Ο«ΕΦ÷ΣΒάΘ§windowsΈΡΦΰœΒΆ≥÷ς“Σ”–fatΓΔntfsΒ»Θ§ΕχlinuxΈΡΦΰœΒΆ≥‘ρ÷÷άύΖ±ΕύΘ§÷ς“Σ”–VFSΉωΝΥ“ΜΗω»μΦΰ≥ιœσ≤ψΘ§œρ…œΧαΙ©ΈΡΦΰ≤ΌΉςΫ”ΩΎΘ§œρœ¬ΧαΙ©±ξΉΦΫ”ΩΎΙ©≤ΜΆ§ΈΡΦΰœΒΆ≥Ε‘Ϋ”Θ§œ¬Οφ÷ς“ΣΨΆ“‘EXT4ΈΡΦΰœΒΆ≥ΈΣάΐΘ§Ϋ≤ΫβΈΡΦΰœΒΆ≥ΫαΙΙ”κΙΛΉς‘≠άμΘΚ
…œΟφΝΫΗωΆΦ¥σΧε≥ œ÷ΝΥext4ΈΡΦΰœΒΆ≥ΒΡΫαΙΙΘ§¥”÷–“≤œύ–≈ΡήΙΜ≥θ≤ΫΒΡΝλΈρΒΫΈΡΦΰœΒΆ≥ΕΝ–¥ΒΡ¬ΏΦ≠Ιΐ≥ΧΓΘœ¬ΟφΕ‘…œΆΦάο±ΏΒΡΙΙ≥…‘ΣΥΊΉωΗωΦρΒΞΒΡΫ≤ΫβΘΚ
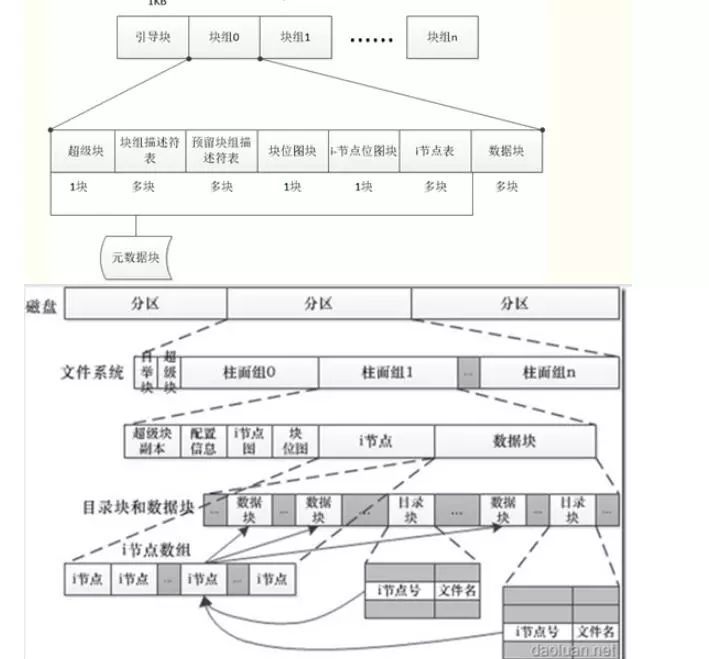
“ΐΒΦΩι
ΈΣ¥≈≈ΧΖ÷«χΒΡΒΎ“ΜΗωΩιΘ§Φ«¬ΦΈΡΦΰœΒΆ≥Ζ÷«χΒΡ“Μ–©–≈œΔΘ§“ΐΒΦΦ”‘ΊΒ±«ΑΖ÷«χΒΡ≥Χ–ρΚΆ ΐΨί±Μ±Θ¥φ‘Ύ’βΗωΩι÷–ΓΘ“ΜΑψ’Φ”Ο2KBΓΘ
≥§ΦΕΩι
≥§ΦΕΩι”Ο”Ύ¥φ¥ΔΈΡΦΰœΒΆ≥»ΪΨ÷ΒΡ≈δ÷Ο≤Έ ΐ(Τ©»γΘΚΩι¥σ–ΓΘ§ΉήΒΡΩι ΐΚΆinode ΐ)ΚΆΕ·Χ§–≈œΔ(Τ©»γΘΚΒ±«ΑΩ’œ–Ωι ΐΚΆinode ΐ)Θ§Τδ¥Π”ΎΈΡΦΰœΒΆ≥ΩΣ ΦΈΜ÷ΟΒΡ1k¥ΠΘ§Υυ’Φ¥σ–ΓΈΣ1kΓΘ
ΈΣΝΥœΒΆ≥ΒΡΫΓΉ≥–‘Θ§Ήν≥θΟΩΗωΩιΉιΕΦ”–≥§ΦΕΩιΚΆΉιΟη ωΖϊ±μ(“‘œ¬ΫΪ”ΟGDT)ΒΡ“ΜΗωΩΫ±¥Θ§ΒΪ «Β±ΈΡΦΰœΒΆ≥Κή¥σ ±Θ§’β―υάΥΖ―ΝΥΚήΕύΩι(”»Τδ «GDT’Φ”ΟΒΡΩιΕύ)Θ§Κσά¥≤…”ΟΝΥ“Μ÷÷œΓ ηΒΡΖΫ Ϋά¥¥φ¥Δ’β–©ΩΫ±¥Θ§÷Μ”–ΩιΉιΚ≈ «3,
5 ,7ΒΡΟίΒΡΩιΉι(Τ©»γΥΒ1,3,5,7,9,25,49Γ≠)≤≈±ΗΖί’βΗωΩΫ±¥ΓΘ
Ά®≥Θ«ιΩωœ¬Θ§÷Μ”–÷ςΩΫ±¥(ΒΎ0ΩιΩιΉι)ΒΡ≥§ΦΕΩι–≈œΔ±ΜΈΡΦΰœΒΆ≥ Ι”ΟΘ§ΤδΥϋΩΫ±¥÷Μ”–‘Ύ÷ςΩΫ±¥±ΜΤΤΜΒΒΡ«ιΩωœ¬≤≈ Ι”ΟΓΘ
ΩιΉιΟη ωΖϊ
GDT”Ο”Ύ¥φ¥ΔΩιΉιΟη ωΖϊΘ§Τδ’Φ”Ο“ΜΗωΜρ’ΏΕύΗω ΐΨίΩιΘ§ΨΏΧε»ΓΨω”ΎΈΡΦΰœΒΆ≥ΒΡ¥σ–ΓΓΘ
Υϋ÷ς“ΣΑϋΚ§ΩιΈΜΆΦΘ§inodeΈΜΆΦΚΆinode±μΈΜ÷ΟΘ§Β±«ΑΩ’œ–Ωι ΐΘ§inode ΐ“‘ΦΑ Ι”ΟΒΡΡΩ¬Φ ΐ(”Ο”ΎΤΫΚβΗςΗωΩιΉιΡΩ¬Φ ΐ)Θ§ΨΏΧεΕ®“εΩ…“‘≤ΈΦϊext3_fs.hΈΡΦΰ÷–struct
ext3_group_descΓΘ
ΟΩΗωΩιΉιΕΦΕ‘”Π’β―υ“ΜΗωΟη ωΖϊΘ§ΡΩ«ΑΗΟΫαΙΙ’Φ”Ο32ΗωΉ÷ΫΎΘ§“ρ¥ΥΕ‘”ΎΩι¥σ–ΓΈΣ4kΒΡΈΡΦΰœΒΆ≥ά¥ΥΒΘ§ΟΩΗωΩιΩ…“‘¥φ¥Δ128ΗωΩιΉιΟη ωΖϊΓΘ”…”ΎGDTΕ‘”ΎΕ®ΈΜΈΡΦΰœΒΆ≥ΒΡ‘Σ ΐΨίΖ«≥Θ÷Ί“ΣΘ§“ρ¥ΥΚΆ≥§ΦΕΩι“Μ―υΘ§“≤Ε‘ΤδΫχ––ΝΥ±ΗΖίΓΘGDT‘ΎΟΩΗωΩιΉι(»γΙϊ”–±ΗΖί)÷–ΡΎ»ίΕΦ «“Μ―υΒΡΘ§ΤδΥυ’ΦΩι ΐ“≤ «œύΆ§ΒΡΓΘ
¥”…œΟφΒΡΫι…ήΩ…“‘Ω¥≥ωΩιΉι÷–ΒΡ‘Σ ΐΨίΤ©»γΩιΈΜΆΦΘ§inodeΈΜΆΦ,inode±μΤδΈΜ÷Ο≤Μ «ΙΧΕ®ΒΡΘ§Β±»ΜΡ§»œ«ιΩωœ¬Θ§ΈΡΦΰœΒΆ≥‘Ύ¥¥Ϋ® ±ΤδΈΜ÷Ο‘ΎΟΩΗωΩιΉι÷–ΕΦ «“Μ―υΒΡΘ§»γΆΦ2Υυ Ψ(ΦΌ…ηΑ¥’’œΓ ηΖΫ Ϋ¥φ¥ΔΘ§«“n≤Μ «3,5,7ΒΡΟί)
ΩιΉι
ΟΩΗωΩιΉιΑϋΚ§“ΜΗωΩιΈΜΆΦΩιΘ§“ΜΗω inode ΈΜΆΦΩιΘ§“ΜΗωΜρΕύΗωΩι”Ο”ΎΟη ω inode ±μΚΆ”Ο”Ύ¥φ¥ΔΈΡΦΰ ΐΨίΒΡ ΐΨίΩιΘ§≥ΐ¥Υ÷°ΆβΘ§ΜΙ”–Ω…ΡήΑϋΚ§≥§ΦΕΩιΚΆΥυ”–ΩιΉιΟη ωΖϊ±μ(»ΓΨω”ΎΩιΉιΚ≈ΚΆΈΡΦΰœΒΆ≥¥¥Ϋ® ± Ι”ΟΒΡ≤Έ ΐ)ΓΘœ¬ΟφΫΪΕ‘’β–©‘Σ ΐΨίΉς“Μ–©Φρ“ΣΫι…ήΓΘ
ΩιΈΜΆΦ
ΩιΈΜΆΦ”Ο”ΎΟη ωΗΟΩιΉιΥυΙήάμΒΡΩιΒΡΖ÷≈δΉ¥Χ§ΓΘ»γΙϊΡ≥ΗωΩιΕ‘”ΠΒΡΈΜΈ¥÷ΟΈΜΘ§Ρ«Ο¥¥ζ±μΗΟΩιΈ¥Ζ÷≈δΘ§Ω…“‘”Ο”Ύ¥φ¥Δ ΐΨίΘΜΖώ‘ρΘ§¥ζ±μΗΟΩι“―Ψ≠”Ο”Ύ¥φ¥Δ ΐΨίΜρ’ΏΗΟΩι≤ΜΡήΙΜ Ι”Ο(Τ©»γΗΟΩιΈοάμ…œ≤Μ¥φ‘Ύ)ΓΘ”…”ΎΩιΈΜΆΦΫω’Φ“ΜΗωΩιΘ§“ρ¥Υ’β“≤ΨΆΨωΕ®ΝΥΩιΉιΒΡ¥σ–ΓΓΘ
InodeΈΜΆΦ
InodeΈΜΆΦ”Ο”ΎΟη ωΗΟΩιΉιΥυΙήάμΒΡinodeΒΡΖ÷≈δΉ¥Χ§ΓΘΈ“Ο«÷ΣΒάinode «”Ο”ΎΟη ωΈΡΦΰΒΡ‘Σ ΐΨίΘ§ΟΩΗωinodeΕ‘”ΠΈΡΦΰœΒΆ≥÷–Έ®“ΜΒΡ“ΜΗωΚ≈Θ§»γΙϊinodeΈΜΆΦ÷–œύ”ΠΈΜ÷ΟΈΜΘ§Ρ«Ο¥¥ζ±μΗΟinode“―Ψ≠Ζ÷≈δ≥ω»ΞΘΜΖώ‘ρΩ…“‘ Ι”ΟΓΘ”…”ΎΤδΫω’Φ”Ο“ΜΗωΩιΘ§“ρ¥Υ’β“≤œό÷ΤΝΥ“ΜΗωΩιΉι÷–ΥυΡήΙΜ Ι”ΟΒΡΉν¥σinode ΐΝΩΓΘ
Inode±μ
Inode±μ”Ο”Ύ¥φ¥Δinode–≈œΔΓΘΥϋ’Φ”Ο“ΜΗωΜρΕύΗωΩι(ΈΣΝΥ”––ßΒΡάϊ”ΟΩ’ΦδΘ§ΕύΗωinode¥φ¥Δ‘Ύ“ΜΗωΩι÷–)Θ§Τδ¥σ–Γ»ΓΨω”ΎΈΡΦΰœΒΆ≥¥¥Ϋ® ±ΒΡ≤Έ ΐΘ§”…”ΎinodeΈΜΆΦΒΡœό÷ΤΘ§ΨωΕ®ΝΥΤδΉν¥σΥυ’Φ”ΟΒΡΩ’ΦδΓΘ
“‘…œ’βΦΗΗωΙΙ≥…‘ΣΥΊΥυ¥ΠΒΡ¥≈≈ΧΩι≥…ΈΣΈΡΦΰœΒΆ≥ΒΡ‘Σ ΐΨίΩιΘ§ Θ”ύΒΡ≤ΩΖ÷‘ρ”Οά¥¥φ¥Δ’φ’ΐΒΡΈΡΦΰΡΎ»ίΘ§≥ΤΈΣ ΐΨίΩιΘ§Εχ ΐΨίΩιΤδ Β“≤ΑϋΚ§ ΐΨίΚΆΡΩ¬ΦΓΘ
ΝΥΫβΝΥΈΡΦΰœΒΆ≥ΒΡΫαΙΙΚσΘ§Ϋ”œ¬ά¥Έ“Ο«ά¥Ω¥Ω¥≤ΌΉςœΒΆ≥ «»γΚΈΕΝ»Γ“ΜΗωΈΡΦΰΒΡΘΚ
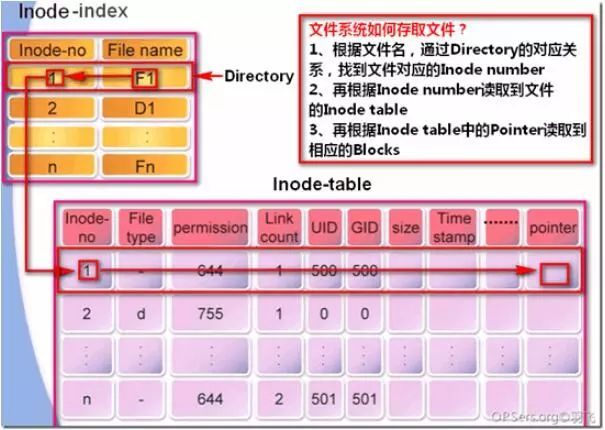
¥σΧεΙΐ≥Χ»γœ¬ΘΚ
1ΓΔΗυΨίΈΡΦΰΥυ‘ΎΡΩ¬ΦΒΡinode–≈œΔΘ§’“ΒΫΡΩ¬ΦΈΡΦΰΕ‘”Π ΐΨίΩι
2ΓΔΗυΨίΈΡΦΰΟϊ¥” ΐΨίΩι÷–’“ΒΫΕ‘”ΠΒΡinodeΫΎΒψ–≈œΔ
3ΓΔ¥”ΈΡΦΰinodeΫΎΒψ–≈œΔ÷–’“ΒΫΈΡΦΰΡΎ»ίΥυ‘Ύ ΐΨίΩιΩιΚ≈
4ΓΔΕΝ»Γ ΐΨίΩιΡΎ»ί
ΒΫ’βάοΘ§œύ–≈ΚήΕύ»ΥΜα”–“ΜΗω“…Έ Θ§Έ“Ο«÷ΣΒά“ΜΗωΈΡΦΰ÷Μ”–“ΜΗωInodeΫΎΒψά¥¥φΖ≈ΥϋΒΡ τ–‘–≈œΔΘ§Ρ«Ο¥ΡψΩ…ΡήΜαœκ»γΙϊ“ΜΗω¥σΈΡΦΰΘ§Ρ«ΥϋΒΡblock“ΜΕ® «ΕύΗωΒΡΘ§«“Ω…Ρή≤ΜΝ§–χΒΡΘ§Ρ«Ο¥inode‘θΟ¥ά¥±μ ΨΡΊ,œ¬ΟφΒΡΆΦΗφΥΏΡψ¥πΑΗ:
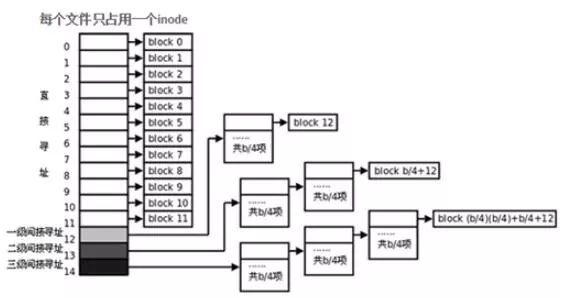
“≤ΨΆ «ΥΒΘ§»γΙϊΈΡΦΰΡΎ»ίΧΪ¥σΘ§Ε‘”Π ΐΨίΩι ΐΝΩΙΐΕύΘ§inodeΫΎΒψ±Ψ…μΧαΙ©ΒΡ¥φ¥ΔΩ’Φδ≤ΜΙΜΘ§Μα Ι”ΟΤδΥϊΒΡΦδΫ” ΐΨίΩιά¥¥φ¥Δ ΐΨίΩιΈΜ÷Ο–≈œΔΘ§ΉνΕύΩ…“‘”–»ΐΦΕ―Α÷ΖΫαΙΙΓΘ
ΒΫ’βάοΘ§”ΠΗΟΕΦ“―Ψ≠Ζ«≥Θ«ε≥ΰΈΡΦΰΕΝ»ΓΒΡΙΐ≥ΧΝΥΘ§Ρ«Ο¥œ¬Οφ‘Ό≈Ή≥ωΝΫΗω“…Έ ΘΚ
1ΓΔΈΡΦΰΒΡΩΫ±¥ΓΔΦτ«–ΒΡΒΉ≤ψΙΐ≥Χ «‘θ―υΒΡΘΩ
2ΓΔ»μΝ§Ϋ”ΚΆ”≤Ν§Ϋ”Ζ÷±π «»γΚΈ Βœ÷ΒΡΘΩ
œ¬Οφά¥ΫαΚœstatΟϋΝνΕ· ÷≤ΌΉς“Μœ¬Θ§±ψ÷Σ’φœύΘΚ
1Θ©ΩΫ±¥ΈΡΦΰΘΚ¥¥Ϋ®“ΜΗω–¬ΒΡinodeΫΎΒψΘ§≤Δ«“ΩΫ±¥ ΐΨίΩιΡΎ»ί

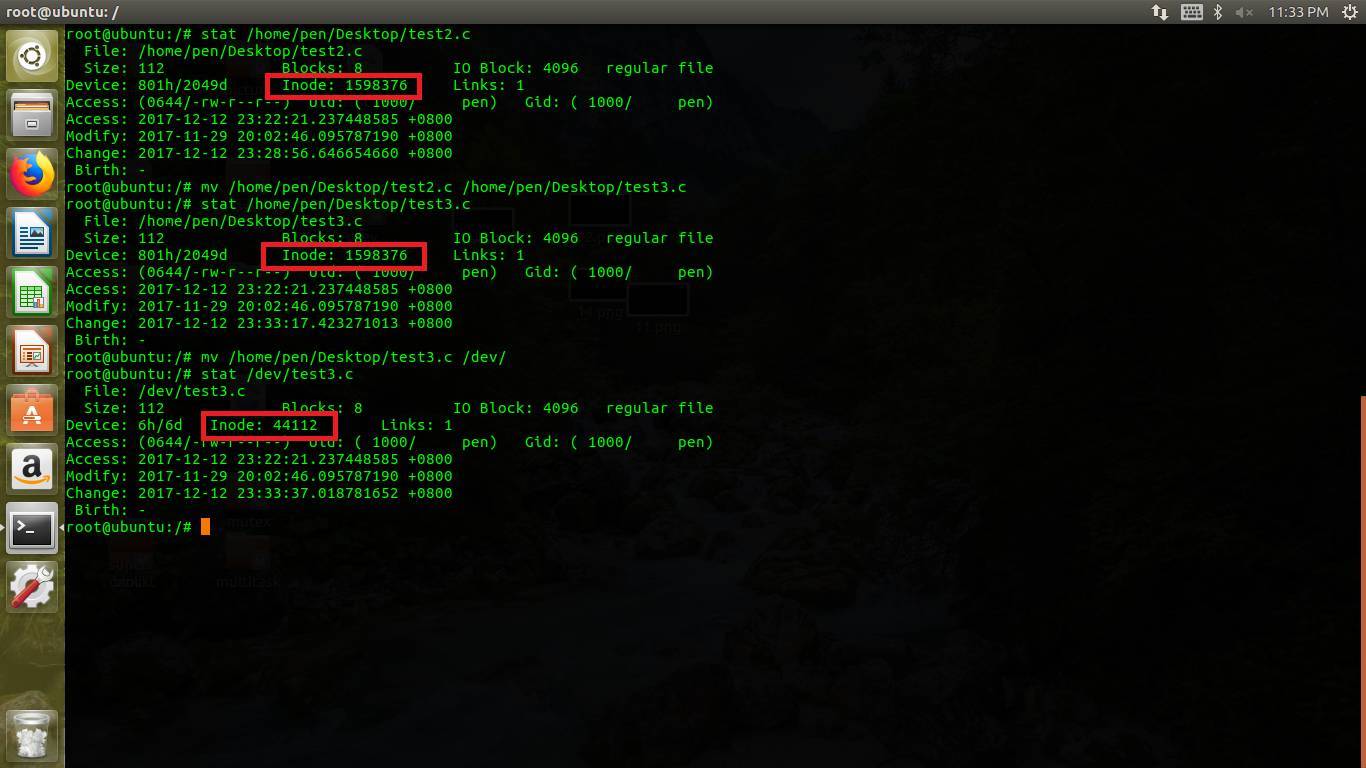
2Θ©Φτ«–ΈΡΦΰΘΚΆ§ΗωΖ÷«χάο±ΏmvΘ§inodeΫΎΒψ≤Μ±δΘ§÷Μ «Ηϋ–¬ΡΩ¬ΦΈΡΦΰΕ‘”Π ΐΨίΩιάο±ΏΒΡΈΡΦΰΟϊΚΆinodeΕ‘”ΠΙΊœΒΘΜΩγΖ÷«χmvΘ§‘ρΗζΩΫ±¥“ΜΗωΒάάμΘ§–η“Σ¥¥Ϋ®–¬ΒΡinodeΘ§“ρΈΣinodeΫΎΒψ≤ΜΆ§Ζ÷«χ «≤ΜΡήΙ≤œμΒΡΓΘ
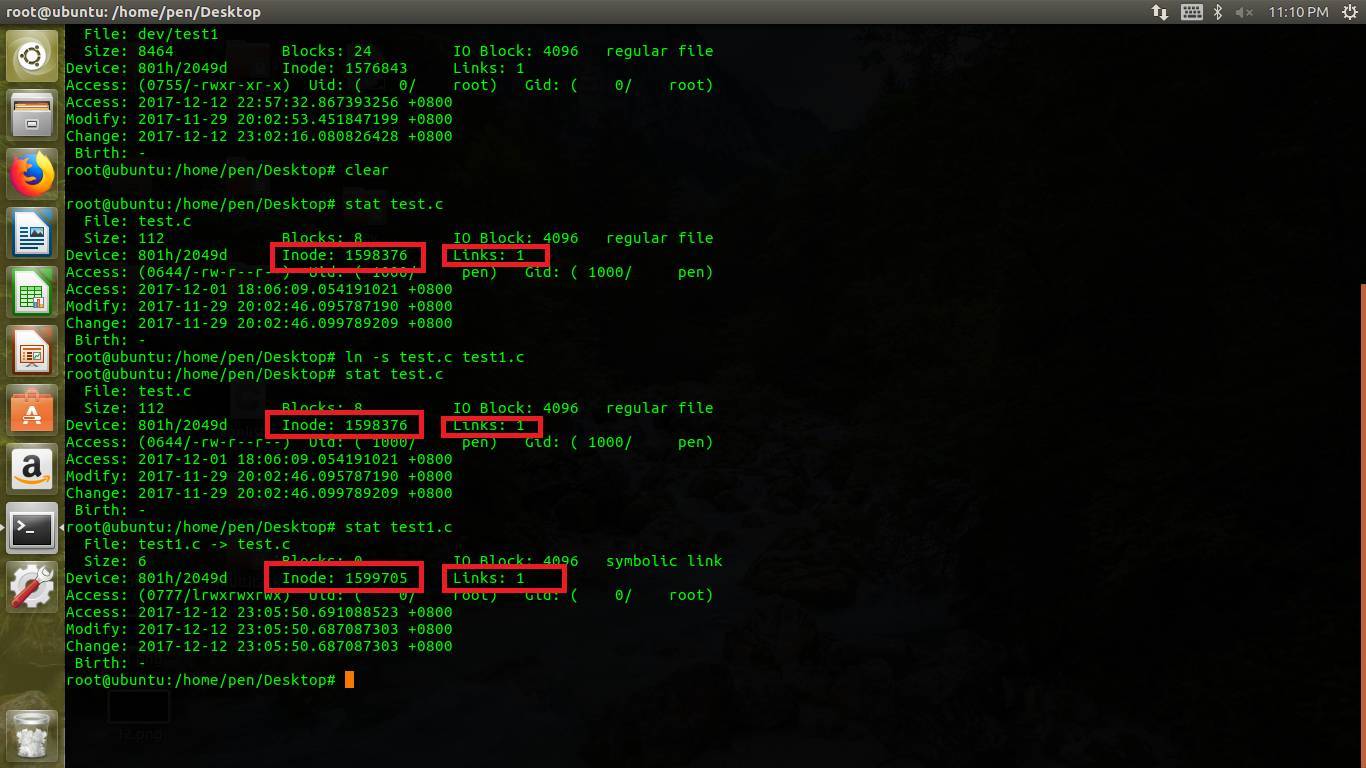
3Θ©»μΝ§Ϋ”ΘΚ¥¥Ϋ®»μΝ§Ϋ”Μα¥¥Ϋ®“ΜΗω–¬ΒΡinodeΫΎΒψΘ§ΤδΕ‘”Π ΐΨίΩιΡΎ»ί¥φ¥ΔΥυΝ¥Ϋ”ΒΡΈΡΦΰΟϊ–≈œΔΘ§’β―υ‘≠ΈΡΦΰΦ¥±ψ…Ψ≥ΐΝΥΘ§÷Ί–¬Ϋ®ΝΔ“ΜΗωΆ§ΟϊΒΡΈΡΦΰΘ§»μΝ§Ϋ”“ά»ΜΡήΙΜ…ζ–ßΓΘ
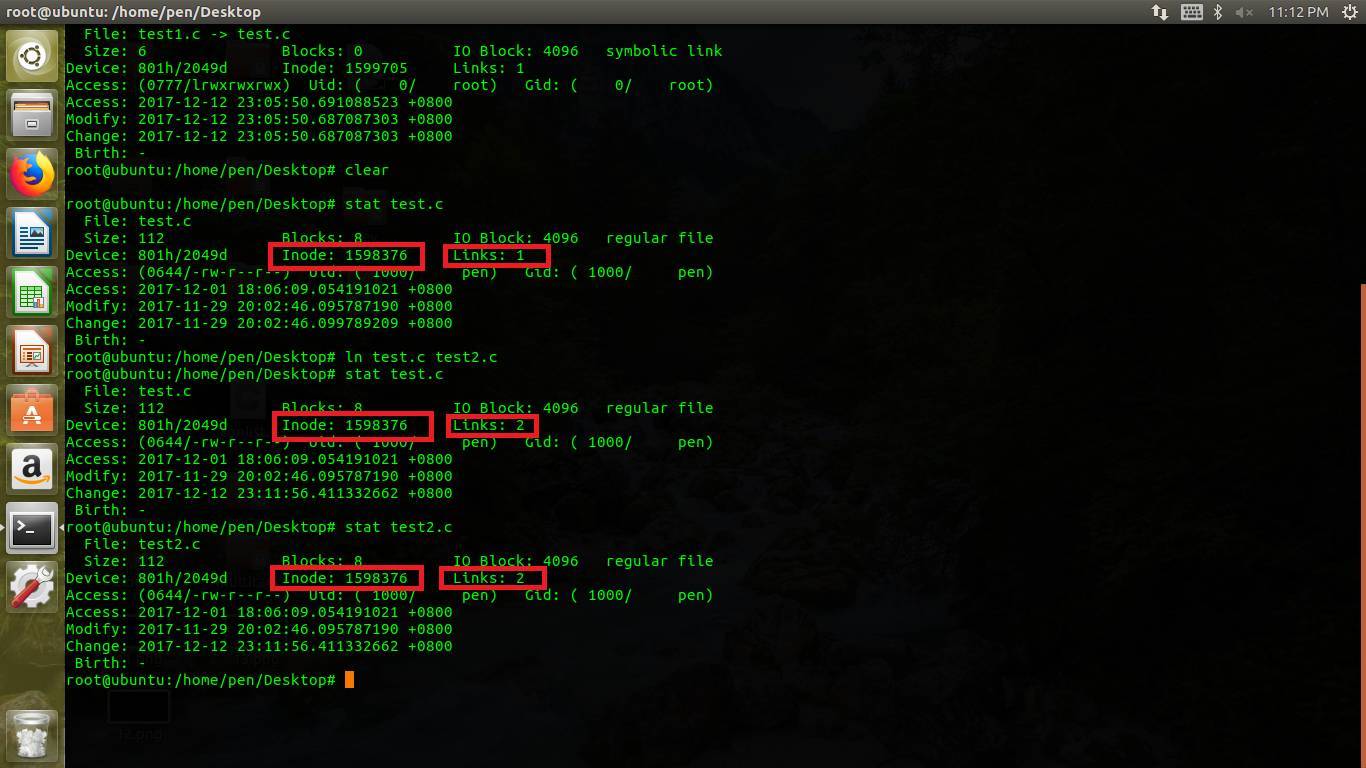
4)”≤Ν¥Ϋ”ΘΚ¥¥Ϋ®”≤Ν¥Ϋ”Θ§≤Δ≤ΜΜα–¬Ϋ®inodeΫΎΒψΘ§÷Μ «linksΦ”1Θ§ΜΙ”–‘ΌΡΩ¬ΦΈΡΦΰΕ‘”Π ΐΨίΩι…œ‘ωΦ”“ΜΧθΈΡΦΰΟϊΚΆinodeΕ‘”ΠΙΊœΒΦ«¬ΦΘΜ÷Μ”–ΫΪ”≤Ν¥Ϋ”ΚΆ‘≠ΈΡΦΰΕΦ…Ψ≥ΐ÷°ΚσΘ§ΈΡΦΰ≤≈Μα’φ’ΐ…Ψ≥ΐΘ§Φ¥linksΈΣ0≤≈’φ’ΐ…Ψ≥ΐΓΘ
|






