| ±ύΦ≠ΆΤΦω: |
±ΨΈΡ÷ς“Σ±ΨΈΡΦρ“ΣΫι…ήΝΥΕύΚΥΕύœΏ≥ΧΜΖΨ≥ΒΡΧΊ–‘Θ§Ε‘»μΦΰ…ηΦΤΨω≤ΏΒΡ”Αœλ“‘ΦΑ–©÷Ί“ΣΩΦ¬« ¬œνΚΆΦΦ«…ΓΘ
±ΨΈΡά¥Ή‘”ΎIBMΘ§”…ΜπΝζΙϊ»μΦΰAnna±ύΦ≠ΓΔΆΤΦωΓΘ |
|
ΦρΫι
ΦΤΥψ”≤Φΰ’ΐ‘ΎΩλΥΌ≈ν≤ΣΖΔ’ΙΓΘ‘Ύ ±÷”ΥΌΕ»≥ ΤΫΈ»Ή¥Χ§ΒΡΆ§ ±Θ§ΨßΧεΙήΟήΕ»‘Ύ≤ΜΕœ‘ω≥ΛΓΘ¥ΠάμΤς÷Τ‘λ…ΧœΘΆϊΆ®Ιΐ»ΟΟΩΗω–ΨΤ§”Β”–ΕύΗωΚΥΚΆ”≤ΦΰœΏ≥Χά¥ΧαΗΏΕύ¥ΠάμΡήΝΠΓΘάΐ»γΘ§IBM
POWER7? Ε‘≥ΤΕύ¥ΠάμΤςΦήΙΙΆ®ΙΐΟΩΗωΚΥ÷ß≥÷Εύ¥ο 4 ΗωœΏ≥ΧΓΔΟΩΗω–ΨΤ§÷ß≥÷ 8 ΗωΚΥΓΔΟΩΧ®ΖΰΈώΤς÷ß≥÷
32 Ηω–ΨΤ§≤ε≤έά¥ Βœ÷ΗΏΕ»≤Δ–––‘Θ§ΉήΙ≤ 1024 Ηω≤ΔΖΔ”≤ΦΰœΏ≥ΧΓΘœύ±»÷°œ¬Θ§IBM POWER6?
ΦήΙΙΫω÷ß≥÷ΟΩΗωΚΥ 2 ΗωœΏ≥ΧΓΔΟΩΗω–ΨΤ§ 2 ΗωΚΥΓΔΟΩΧ®ΖΰΈώΤς 32 Ηω–ΨΤ§≤ε≤έΘ§ΉήΙ≤ 128 Ηω≤Δ––”≤ΦΰœΏ≥ΧΓΘ
ΩΣΖΔ»μΦΰ ±Θ§ΡΩ«Α…ηΦΤ»Υ‘±–η“ΣΩΦ¬«Ω…ΡήΜα≤Ω π»μΦΰΒΡΕύ¥ΠάμΤςΓΔΕύΚΥΦήΙΙΓΘ’β «“ρΈΣΘΚ
Ά®Ιΐ Ι”ΟΗϋΕύΚΥΓΔ”≤ΦΰœΏ≥ΧΓΔΗϋΗΏΒΡΡΎ¥φΘ§”Π”Ο≥Χ–ρ”ΠΗΟΜαΗϋΚΟΒΊ÷¥––ΚΆΗϋ≥ω…ΪΒΊ…λΥθ–‘Θ§≤ΔΡή¬ζΉψ≤ΜΕœ‘ω≥ΛΒΡ–‘ΡήΚΆ–߬ –η«σΓΘ
ΥφΉ≈‘Ϋά¥‘ΫΕύΒΊ Ι”ΟΕύΚΥΓΔΕύ¥ΠάμΤςœΒΆ≥Θ§»μΦΰ…ηΦΤΉΔ“β ¬œνœ÷‘Ύ”ΠΗΟΩΦ¬«ΑϋΚ§ΡήΙΜ‘Ύ’β–©ΦΤΥψΉ ‘¥÷°Φδ”––ßΒΊΖ÷ΖΔ»μΦΰΙΠΡήΒΡΖΫΖ®ΓΘ
»γΙϊ‘Ύ…ηΦΤΒΡΙΐ≥Χ÷–ΟΜ”–ΩΦ¬«’β–©ΩΦ¬« ¬œνΘ§Ρ«Ο¥‘ΎΕύ¥ΠάμΤςΓΔΕύΚΥΜΖΨ≥÷–‘Υ––”Π”Ο≥Χ–ρΩ…ΡήΜαΒΦ÷¬―œ÷Ί«“≤Μ“ΉΖΔœ÷ΒΡ–‘ΡήΈ ΧβΓΘ
±ΨΈΡΫΪΜαΦρ“ΣΫι…ήΈΣΕύΚΥΓΔΕύ¥ΠάμΤςΜΖΨ≥…ηΦΤ»μΦΰ ±ΒΡ“Μ–©÷Ί“ΣΉΔ“β ¬œνΓΘ
‘Ύ–ΨΤ§ΕύœΏ≥ΧΓΔΕύΚΥΓΔΕύ¥ΠάμΤςΦήΙΙ…œ»μΦΰΩ……λΥθ–‘ΒΡΉηΑ≠
”Π”Ο≥Χ–ρ”ΠΗΟΡήΙΜ‘ΎΕύΚΥΓΔΕύ¥ΠάμΤςΜΖΨ≥÷–ΗϋΚΟΒΊ…λΥθΓΔΗϋ≥ω…ΪΒΊ÷¥––ΓΘΒΪ «Θ§»γΙϊ”Π”Ο≥Χ–ρ…ηΦΤΒΡ–ß¬ ΒΆœ¬Θ§‘ρΩ…ΡήΜα‘Ύ’β―υΒΡΜΖΨ≥÷–÷¥––ΒΟΫœ≤νΘ§ΒΪΆ®Ιΐ Ι”ΟΩ…”ΟΒΡΦΤΥψΉ ‘¥Ω…“‘ΗϋΚΟΒΊ…λΥθΚΆΗϋ≥ω…ΪΒΊ÷¥––ΓΘ’βΗωΩ……λΥθ–‘ΒΡ“Μ–©÷Ί“ΣΉηΑ≠Ω…Ρή «ΘΚ
–߬ ΒΆœ¬ΒΡ≤Δ––Μ·ΘΚΒΞΤ§”Π”Ο≥Χ–ρΜρ»μΦΰΈόΖ®”––ß Ι”ΟΩ…”ΟΒΡΦΤΥψΉ ‘¥ΓΘΡζ–η“ΣΫΪ”Π”Ο≥Χ–ρΉι÷·≥…≤Δ––»ΈΈώΓΘ‘Ύ¥ΪΆ≥ΒΡ≤Μ÷ß≥÷ΕύœΏ≥ΧΒΡ”Π”Ο≥Χ–ρΜρ»μΦΰ÷–Θ§Έ“Ο«ΜαΨ≠≥ΘΩ¥ΒΫ’βΗωΈ ΧβΓΘ’β–©”Π”Ο≥Χ–ρ‘ΎΕύΚΥΓΔΕύ¥ΠάμΤςΓΔ–ΨΤ§ΕύœΏ≥Χ”≤Φΰ…œΈόΖ®…λΥθΘ§≤Δ«“ΈόΖ® Βœ÷ΗϋΚΟΒΡΆΧΆ¬ΝΩΓΘœΏ≥ΧΧΪΕύΩ…ΡήΜαΚΆœΏ≥ΧΧΪ…Ό“Μ―υΘ§ΕΦ≤ΜΜα≤ζ…ζΚΟΒΡΫαΙϊΓΘ
¥°––ΤΩΨ±ΘΚ‘ΎΕύΗωœΏ≥ΧΜρΫχ≥Χ÷°ΦδΙ≤œμ ΐΨίΫαΙΙΒΡ”Π”Ο≥Χ–ρΩ…ΡήΜα”–¥°––ΤΩΨ±ΓΘΈΣΝΥ±Θ≥÷ ΐΨίΆξ’ϊ–‘Θ§Ω…Ρή±Ί–κ Ι”ΟΥχΕ®ΚΆ¥°––Μ·ΦΦ θΘ®άΐ»γΘ§ΕΝ»ΓΥχΓΔΕΝ–¥ΥχΓΔ–¥»κΥχΓΔΉ‘–ΐΥχΓΔΜΞ≥βΒ»Θ©ΫΪ’β–©Ι≤œμ ΐΨίΫαΙΙΒΡΖΟΈ ¥°––Μ·ΓΘ…ηΦΤΒΟ–ß¬ ΒΆœ¬ΒΡΥχΩ…ΡήΜα”…”ΎΕύΗωœΏ≥ΧΜρΫχ≥Χ÷°ΦδΒΡΗΏΕ»Υχ’υ”ΟΕχΒΦ÷¬¥°––ΤΩΨ±Θ§¥”Εχ≥Δ ‘Μώ»ΓΥχΓΘ’βΩ…ΡήΜα«±‘ΎΒΊΫΒΒΆ”Π”Ο≥Χ–ρΜρ»μΦΰΒΡ–‘ΡήΓΘ”Π”Ο≥Χ–ρΒΡ–‘ΡήΩ…ΡήΜαΥφΉ≈ΚΥ–ΡΜρ¥ΠάμΤς ΐΝΩΒΡ‘ωΦ”ΕχΫΒΒΆΓΘ
Ε‘≤ΌΉςœΒΆ≥ (OS) Μρ‘Υ–– ±ΜΖΨ≥ΒΡΙΐΕ»“άάΒΘΚΡζ≤ΜΡή“άάΒ≤ΌΉςœΒΆ≥ΓΔ‘Υ–– ±ΜΖΨ≥Μρ±ύ“κΤςά¥Άξ≥……λΥθ”Π”Ο≥Χ–ρΜρ»μΦΰΥυ–ηΒΡ“Μ«–≤ΌΉςΓΘΒΪ «Θ§±ύ“κΤςΚΆ‘Υ–– ±ΜΖΨ≥Ω…“‘Αο÷ζΧαΙ©“ΜΕ®ΒΡ”≈Μ·Θ§Ρζ≤ΜΡή“άάΒΥϋΟ«ΫβΨωΥυ”–Ω……λΥθ–‘Έ ΧβΓΘάΐ»γΘ§≤ΜΡή“άάΒ
Java? –ιΡβΜζ (JVM) Ά®ΙΐΉ‘Ε·≤Δ––ά¥ΖΔœ÷ Java ”Π”Ο≥Χ–ρΒΡΉνΦ―Ω……λΥθΒΡΜζΜαΓΘ
ΙΛΉςΗΚ‘ΊΒΡ≤ΜΤΫΚβΩ…Ρή «“ΜΗωΤΩΨ±ΘΚΙΛΉςΗΚ‘ΊΒΡ≤ΜΨυ‘»Ζ÷≤ΦΩ…ΡήΒΦ÷¬ΈόΖ®”––ßΒΊάϊ”ΟΦΤΥψΉ ‘¥ΓΘΡζΩ…Ρή±Ί–κΫΪΫœ¥σΒΡ»ΈΈώΜ°Ζ÷≥…Ω…“‘≤Δ––‘Υ––ΒΡΫœ–ΓΒΡ»ΈΈώΘ§ΜΙΩ…Ρή±Ί–κΫΪ¥°––ΥψΖ®ΗϋΗΡΈΣ≤Δ––ΥψΖ®Θ§“‘±ψΧαΗΏ–‘ΡήΚΆΩ……λΥθ–‘ΓΘ
I/O ΤΩΨ±ΘΚ”…”ΎΉη÷Ι¥≈≈Χ δ»κ/ δ≥ω (I/O) ΜρΗΏΆχ¬γ―”≥ΌΕχΒΦ÷¬ΒΡΤΩΨ±Ω…ΡήΜα―œ÷Ί“÷÷Τ”Π”Ο≥Χ–ρΒΡΩ……λΥθ–‘ΓΘ
Έό–ßΒΡΡΎ¥φΙήάμΘΚ‘ΎΕύΚΥΤΫΧ®…œΘ§“ρΈΣ”–ΚήΕύ¥ΠάμΒΞ‘ΣΘ§“ρ¥Υ¥ΩΦΤΥψΩ…ΡήΖ«≥ΘΝ°ΦέΘ§≤Δ«“÷ς“ΣΡΎ¥φΩ…Ρή“≤≤Μ «Έ ΧβΘ§“ρΈΣΥϋ’ΐ‘Ύ±δΒΟ‘Ϋά¥‘Ϋ¥σΓΘΒΪ «Θ§ΡΎ¥φ¥χΩμ“Μ÷± «“ΜΗωΤΩΨ±Θ§“ρΈΣΥυ”–¥ΠάμΤςΚΥ–ΡΕΦΙ±œΉΝΥ“ΜΗωΆ®”ΟΒΡΉήœΏΓΘΈό–ßΒΡΡΎ¥φΙήάμΩ…ΡήΒΦ÷¬“Μ–©Ρ―“‘Φλ≤βΒΫΒΡ–‘ΡήΈ ΧβΘ§±»»γΈ±Ι≤œμΓΘ
ΒΆ¥ΠάμΤςάϊ”Ο¬ Ω…ΡήΜαΟς»Ζ±μΟςΉ ‘¥άϊ”Ο¬ Έ¥¥οΒΫΉνΦ―÷ΒΓΘΈΣΝΥΝΥΫβ–‘ΡήΈ ΧβΘ§Ρζ–η“ΣΤάΙά“Μœ¬”Π”Ο≥Χ–ρ «ΖώΨΏ”–ΧΪ…ΌΜρΧΪΕύΒΡœΏ≥ΧΘ§ «Ζώ”–ΥχΕ®ΜρΆ§≤ΫΈ ΧβΓΔΆχ¬γΜρ
I/O ―”≥ΌΓΔΡΎ¥φΕΕΕ·ΜρΤδΥϊΡΎ¥φΙήάμΈ ΧβΓΘ÷Μ“ΣΉ ‘¥ «Μ®Ζ―‘Ύ”–“β“εΒΡΙΛΉςΒΡ”Π”Ο≥Χ–ρœΏ≥Χ…œΘ§ΗΏ¥ΠάμΤςάϊ”Ο¬ Ά®≥ΘΕΦΜα≤Μ¥μΓΘ
–ΨΤ§ΕύœΏ≥Χ (CMT)ΓΔΕύΚΥΚΆΕύ¥ΠάμΤς (MP) œΒΆ≥Η≈ ω
‘ΎΧ÷¬έ–ΨΤ§ΕύœΏ≥ΧΓΔΕύΚΥΓΔΕύ¥ΠάμΤςΜΖΨ≥ΒΡ…ηΦΤΉΔ“β ¬œν÷°«ΑΘ§Έ“Ο«ΜαΦρ“ΣΫι…ή’βάύœΒΆ≥ΓΘΆΦ 1 Υυ ωΒΡœΒΆ≥”–ΝΫΗω¥ΠάμΤςΘ§ΟΩΗω¥ΠάμΤς”–ΝΫΗωΚΥ–ΡΘ§≤Δ«“ΟΩΗωΚΥ–Ρ”–ΝΫΗω”≤ΦΰœΏ≥ΧΓΘΟΩΗωΚΥ–Ρ”–“ΜΗω
L1 ΜΚ¥φΚΆ“ΜΗω L2 ΜΚ¥φΓΘ“ρ¥ΥΘ§ΟΩΗωΚΥ–ΡΩ…ΡήΕΦ”Β”–Ή‘ΦΚΒΡ L2 ΜΚ¥φΘ§Μρ’ΏΆ§“ΜΗω¥ΠάμΤς…œΒΡΚΥ–ΡΩ…ΡήΜαΙ≤œμ
L2 ΜΚ¥φΓΘΆ§“ΜΗωΚΥ…œΒΡ”≤ΦΰœΏ≥ΧΜαΙ≤œμ L1 ΚΆ L2 ΜΚ¥φΓΘ
ΆΦ 1. “ΜΗωΒδ–ΆΒΡ–ΨΤ§ΕύœΏ≥ΧΓΔΕύΚΥΓΔΕύ¥ΠάμΤςœΒΆ≥
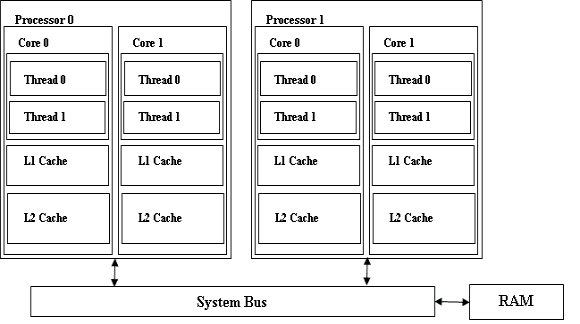
Οη ω–ΨΤ§ΕύœΏ≥ΧΓΔΕύΚΥΓΔΕύ¥ΠάμΤςœΒΆ≥ΒΡΖΫΩρΆΦΓΘ
Υυ”–ΚΥΚΆ¥ΠάμΤςΕΦΙ≤œμœΒΆ≥ΉήœΏΘ§≤ΔΆ®ΙΐœΒΆ≥ΉήœΏΖΟΈ ÷ς“ΣΡΎ¥φΜρ RAMΓΘΕ‘”Ύ”Π”Ο≥Χ–ρΚΆ≤ΌΉςœΒΆ≥Θ§ΗΟœΒΆ≥Ω¥Τπά¥ΨΆœώ «
8 Ηω¬ΏΦ≠¥ΠάμΤςΓΘ
“‘œ¬÷Ί“ΣΗ≈ΡνΫΪΑο÷ζΈ“Ο«ΝΥΫβΈΣ’β―υ“ΜΗω–ΨΤ§ΕύœΏ≥ΧΓΔΕύΚΥΓΔΕύ¥ΠάμΤςΜΖΨ≥…ηΦΤ”Π”Ο≥Χ–ρ ±ΥυΟφΝΌΒΡΧτ’ΫΓΘ
ΜΚ¥φ“Μ÷¬–‘
ΜΚ¥φ“Μ÷¬–‘ «±μ Ψ¥ΠάμΤςΜΚ¥φ÷–ΒΡ ΐΨίœνΡΩ÷Β”κœΒΆ≥ΡΎ¥φ÷–ΒΡ ΐΨίœνΡΩ÷ΒœύΆ§ΒΡ“Μ÷÷Ή¥Χ§ΓΘΗΟΉ¥Χ§Ε‘”Ύ»μΦΰά¥ΥΒ «ΆΗΟςΒΡΓΘΒΪ «Θ§œΒΆ≥ΈΣΝΥ±Θ≥÷ΜΚ¥φ“Μ÷¬–‘Εχ÷¥––ΒΡ≤ΌΉςΩ…ΡήΜα”Αœλ»μΦΰΒΡ–‘ΡήΓΘ
ΩΦ¬«’β―υ“ΜΗω ΨάΐΘΚΈ“Ο«ΦΌΕ®‘ΎΆΦ 1 Υυ ωΒΡœΒΆ≥÷–Θ§œΏ≥Χ 1 ’ΐ‘Ύ¥ΠάμΤς 0 …œ‘Υ––Θ§ΕχœΏ≥Χ 2 ’ΐ‘Ύ¥ΠάμΤς
1 …œ‘Υ––ΓΘ»γΙϊ’βΝΫΗωœΏ≥ΧΕΦ’ΐ‘ΎΕΝ»ΓΚΆ–¥»κœύΆ§ΒΡ ΐΨίœνΘ§Ρ«Ο¥ΗΟœΒΆ≥±Ί–κ÷¥––ΕνΆβΒΡ≤ΌΉςΘ§“‘»Ζ±Θ‘ΎΫχ––ΟΩΗωΕΝ»ΓΚΆ–¥»κ≤ΌΉς ±Θ§œΏ≥ΧΕΦΩ¥ΒΫœύΆ§ΒΡ ΐΨί÷ΒΓΘ
Β±œΏ≥Χ 1 ‘Ύ”κœΏ≥Χ 2 Ι≤œμΒΡ ΐΨίœν÷–÷¥–––¥»κ≤ΌΉς ±Θ§Μα‘ΎΤδ¥ΠάμΤςΜΚ¥φΚΆœΒΆ≥ΡΎ¥φ÷–Ηϋ–¬ΗΟ ΐΨίœνΘ§ΒΪ≤ΜΜα‘ΎœΏ≥Χ
2 ¥ΠάμΤςΒΡΜΚ¥φ÷–ΝΔΦ¥Ηϋ–¬ ΐΨίΘ§“ρΈΣœΏ≥Χ 2 Ω…Ρή≤Μ‘Ό–η“ΣΖΟΈ ΗΟ ΐΨίœνΓΘ»γΙϊœΏ≥Χ 2 ÷°ΚσΖΟΈ ΗΟ ΐΨίœνΘ§‘ρΤδ¥ΠάμΤς…œΒΡΜΚ¥φΉ”œΒΆ≥±Ί–κ Ήœ»¥”œΒΆ≥ΡΎ¥φ÷–Μώ»Γ–¬ΒΡ ΐΨί÷ΒΓΘ“ρ¥ΥΘ§œΏ≥Χ
1 ΒΡ–¥»κΜαΤ» ΙœΏ≥Χ 2 ‘Ύœ¬¥ΈΖΟΈ ΗΟ ΐΨί ±Β»¥ΐ¥”œΒΆ≥ΡΎ¥φ÷–ΕΝ»Γ ΐΨίΓΘΫωΒ± ΐΨί±ΜΤδ÷–“ΜΗωœΏ≥Χ–όΗΡ ±Θ§≤≈Μα≥ωœ÷’β÷÷«ιΩωΓΘ»γΙϊΟΩΗωœΏ≥ΧΕΦΫχ––ΝΥ“ΜœΒΝ–ΒΡ–¥»κ≤ΌΉςΘ§Ρ«Ο¥’βΩ…ΡήΜα―œ÷Ί”ΑœλœΒΆ≥ΒΡ–‘ΡήΘ§“ρΈΣΥυ”– ±ΦδΕΦΜ®Ζ―‘ΎΒ»¥ΐΗϋ–¬œΒΆ≥ΡΎ¥φ÷–ΒΡ ΐΨί÷Β…œΓΘ’β÷÷«ιΩω±Μ≥ΤΈΣΓΑΤΙ≈“–ß”ΠΓ±Θ§Β±‘ΎΕύ¥ΠάμΤςΚΆΕύΚΥœΒΆ≥…œ‘Υ–– ±Θ§”Π±ήΟβΖΔ…ζ’β÷÷«ιΩωΘ§’β «“Μœν÷Ί“ΣΒΡ»μΦΰ…ηΦΤΉΔ“β ¬œνΓΘ
–αΧΫ - Snooping
’β «“ΜΗωΗζΉΌΟΩΗωΜΚ¥φ––ΒΡΉ¥Χ§ΒΡΜΚ¥φΉ”œΒΆ≥ΓΘΗΟœΒΆ≥ Ι”Ο“ΜΗω≥ΤΈΣ ΓΑΉήœΏΕ·Χ§Φύ ”Γ± Μρ’Ώ≥ΤΈΣΓΑΉήœΏ–αΧΫΓ±
ΒΡΦΦ θά¥Φύ ”‘ΎœΒΆ≥ΉήœΏ…œΖΔ…ζΒΡΥυ”– ¬ΈώΘ§“‘Φλ≤βΜΚ¥φ÷–ΒΡΡ≥ΗωΒΊ÷Ζ…œΚΈ ±ΖΔ…ζΝΥΕΝ»ΓΜρ–¥»κ≤ΌΉςΓΘ
Β±’βΗωΜΚ¥φΉ”œΒΆ≥‘ΎœΒΆ≥ΉήœΏ…œΦλ≤βΒΫΕ‘ΜΚ¥φ÷–Φ”‘ΊΒΡΡΎ¥φ«χ”ρΫχ––ΒΡΕΝ»Γ≤ΌΉς ±Θ§ΥϋΜαΫΪΗΟΜΚ¥φ––ΒΡΉ¥Χ§ΗϋΗΡΈΣ
ΓΑsharedΓ±ΓΘ»γΙϊΥϋΦλ≤βΒΫΕ‘ΗΟΒΊ÷ΖΒΡ–¥»κ≤ΌΉς ±Θ§ΜαΫΪΜΚ¥φ––ΒΡΉ¥Χ§ΗϋΗΡΈΣ ΓΑinvalidΓ±ΓΘ
ΗΟΜΚ¥φΉ”œΒΆ≥œκ÷ΣΒάΘ§Β±ΗΟœΒΆ≥‘ΎΦύ ”œΒΆ≥ΉήœΏ ±Θ§œΒΆ≥ «Ζώ‘ΎΤδΜΚ¥φ÷–ΑϋΚ§ ΐΨίΒΡΈ©“ΜΗ±±ΨΓΘ»γΙϊ ΐΨί”…ΥϋΉ‘ΦΚΒΡ
CPU Ϋχ––ΝΥΗϋ–¬Θ§Ρ«Ο¥’βΗωΜΚ¥φΉ”œΒΆ≥ΜαΫΪΜΚ¥φ––ΒΡΉ¥Χ§¥” ΓΑexclusiveΓ± ΗϋΗΡΈΣ ΓΑmodifiedΓ±ΓΘ»γΙϊΗΟΜΚ¥φΉ”œΒΆ≥Φλ≤βΒΫΝμ“ΜΗω¥ΠάμΤςΕ‘ΗΟΒΊ÷ΖΒΡΕΝ»ΓΘ§ΥϋΜαΉη÷ΙΖΟΈ Θ§Ηϋ–¬œΒΆ≥ΡΎ¥φ÷–ΒΡ ΐΨίΘ§»ΜΚσ‘ –μΗΟ¥ΠάμΒΡΖΟΈ ΦΧ–χΫχ––ΓΘΥϋΜΙ‘ –μΫΪΗΟΜΚ¥φ––ΒΡΉ¥Χ§±ξΦ«ΈΣ
sharedΓΘ
”–ΙΊ’β–©Η≈ΡνΒΡœξœΗ–≈œΔΘ§«κ≤Έ‘Ρ ≤ΈΩΦΉ Νœ ≤ΩΖ÷÷–”–ΙΊ ΓΑΕύΚΥΕύ¥ΠάμΤςœΒΆ≥ΒΡ»μΦΰ…ηΦΤΈ ΧβΓ± ΒΡΈΡ’¬ΓΘ
ΕύΚΥΕύ¥ΠάμΤςΜΖΨ≥Ε‘»μΦΰ…ηΦΤΨω≤ΏΒΡ”Αœλ
Β±…ηΦΤ“Σ‘ΎΕύΚΥΜρΕύ¥ΠάμΤςœΒΆ≥…œ‘Υ––ΒΡ»μΦΰ ±Θ§÷ς“ΣΒΡΩΦ¬« ¬œν «»γΚΈΖ÷≈δΫΪ‘ΎΩ…”ΟΒΡ¥ΠάμΤς…œΆξ≥…ΒΡΙΛΉςΓΘΖ÷≈δΗΟΙΛΉςΒΡΉν≥Θ”ΟΖΫΖ® « Ι”Ο“ΜΗωœΏ≥ΧΡΘ–ΆΘ§ΗΟΡΘ–ΆΩ…ΫΪΙΛΉςΖ÷≥…Ω…“‘‘Ύ≤ΜΆ§¥ΠάμΤς…œ≤Δ––‘Υ––ΒΡΗςΗω÷¥––ΒΞ‘ΣΓΘ»γΙϊœΏ≥Χ÷°Φδ±Υ¥ΥΆξ»ΪΕάΝΔΘ§Ρ«Ο¥ΥϋΟ«ΒΡ…ηΦΤΈό–ηΩΦ¬«ΥϋΟ«÷°ΦδΒΡΫΜΜΞΖΫ ΫΓΘάΐ»γΘ§‘Ύ“ΜΗωœΒΆ≥…œ‘Υ––ΒΡΝΫΗω≥Χ–ρΘ§ΟΩΗω≥Χ–ρΕΦ Ι”ΟΒΞΕάΒΡΫχ≥Χ‘ΎΉ‘ΦΚΒΡΚΥ–Ρ…œ‘Υ––Θ§“ρ¥ΥΈό–η±Υ¥ΥΫχ––ΙΊΉΔΓΘ≥Χ–ρΒΡ–‘Ρή≤ΜΜα ήΒΫ»ΈΚΈ”ΑœλΘ§≥ΐΖ«ΥϋΟ«’υ”ΟΙ≤œμΒΡΉ ‘¥Θ§±»»γœΒΆ≥ΡΎ¥φΜρœύΆ§ΒΡ
I/O …η±ΗΓΘ
Ϋ”œ¬ά¥“ΣΧ÷¬έΒΡ÷ΊΒψ «ΚΥ–ΡΚΆ¥ΠάμΤς”κ÷ς“ΣΡΎ¥φΒΡΙΒΆ®ΖΫ ΫΘ§“‘ΦΑ’βΕ‘»μΦΰ…ηΦΤΨω≤Ώ”–ΚΈ”ΑœλΓΘ
«κ≤ΈΦϊ“‘œ¬÷Ί“ΣΒΡ…ηΦΤΉΔ“β ¬œνΓΘ
±ήΟβΡΎ¥φ’υ”Ο
‘ΎΡΎ¥φΚΆΜΚ¥φ÷–Θ§Ης÷÷≤ΜΆ§ΒΡΚΥΙ≤œμ“ΜΗωΆ®”ΟΒΡ ΐΨί«χ”ρΘ§’β–η“Σ‘ΎΥϋΟ«÷°ΦδΫχ––Ά§≤ΫΓΘΒ±≤ΜΆ§ΒΡΚΥΆ§ ±ΖΟΈ Ά§“ΜΗω ΐΨί«χ”ρ ±Θ§ΜαΖΔ…ζΡΎ¥φ’υ”ΟΓΘ‘Ύ≤ΜΆ§ΒΡΚΥ÷°ΦδΆ§≤Ϋ ΐΨίΜα“ρΉήœΏΆ®–≈ΓΔΥχΕ®≥…±Ψ“‘ΦΑΜΚ¥φ»± ßΕχ”–Κή¥σΒΡ–‘ΡήΥπ ßΓΘ
»γΙϊ”Π”Ο≥Χ–ρ”–ΕύΗωœΏ≥ΧΘ§≤Δ«“Υυ”–œΏ≥ΧΕΦΗϋ–¬Μρ–όΗΡΆ§“ΜΗωΡΎ¥φΒΊ÷ΖΘ§Ρ«Ο¥’ΐ»γ«ΑΟφ≤ΩΖ÷ΥυΧ÷¬έΒΡΡ«―υΘ§ΈΣΝΥ±Θ≥÷ΜΚ¥φ“Μ÷¬–‘Θ§Ω…ΡήΜα≤ζ…ζ“Μ¥Έ÷Ί¥σΒΡΤΙ≈“–ß”ΠΓΘ’βΜαΒΦ÷¬–‘ΡήΫΒΒΆΓΘ
”–ΙΊΒΡœξœΗ–≈œΔΘ§«κ≤Έ‘Ρ ≤ΈΩΦΉ Νœ ≤ΩΖ÷÷– ΓΑΕύΚΥΤΫΧ®ΒΡΡΎ¥φΈ ΧβΓ± ΈΡ’¬ΒΡ ΓΑΡΎ¥φ’υ”ΟΓ± ≤ΩΖ÷ΓΘΗΟΈΡ’¬ΑϋΚ§“ΜΗωΦρΒΞΒΡ≥Χ–ρΘ§¥Υ≥Χ–ρ―ί ΨΝΥΡΎ¥φ’υ”ΟΒΡ≤ΜΝΦ”ΑœλΓΘΗΟ Ψάΐ’Ι ΨΘ§Φ¥ ΙΕύΗωœΏ≥Χ÷°Φδ÷ΜΙ≤œμ“ΜΗω±δΝΩΘ§Β±Ε‘Ηϋ–¬ Ι”Ο‘≠Ή”÷ΗΝν ±Θ§–‘ΡήΥπ ß“≤ΜαΚή¥σΓΘ
±ήΟβΡΎ¥φ’υ”ΟΒΡΦΦ«…
≤Μ“Σ‘ΎΚΥ÷°ΦδΙ≤œμΩ…–¥»κΒΡΉ¥Χ§ΘΚ
ΈΣΝΥΉν¥σ≥ΧΕ»ΒΊΦθ…ΌΡΎ¥φΉήœΏΆ®–≈Θ§Ω…“‘Ά®ΙΐΉν–ΓΜ·Ι≤œμΈΜ÷Ο/ ΐΨίΨΓΩ…ΡήΒΊΦθ…ΌΚΥ–ΡΫΜΜΞΘ§Φ¥ ΙΙ≤œμ ΐΨίΟΜ”–Υχ±ΘΜΛΘ§Εχ”–“Μ–©”≤ΦΰΦΕ±π‘≠Ή”÷ΗΝνΘ®»γ
Microsoft? Windows? 32 ΈΜΤΫΧ®…œΒΡ InterlockedExchangeAdd64Θ©±ΘΜΛ“≤ «»γ¥ΥΓΘ
Φθ…ΌœΏ≥Χ÷°ΦδΒΡΡΎ¥φ’υ”ΟΒΡ“ΜΗωΖΫΖ® «¥”ΕύΗωœΏ≥Χ÷–œϊ≥ΐΕ‘Ι≤œμΡΎ¥φ«χ”ρΒΡΗϋ–¬ΓΘάΐ»γΘ§Φ¥±ψ «‘ΎΕύΗωœΏ≥Χ–η“ΣΗϋ–¬»ΪΨ÷ΦΤ ΐΤςΜράέΦΤΉή ΐΘ®»γΆ≥ΦΤ ΐΨίΘ© ±Θ§ΗςΗωœΏ≥Χ“≤Ω…“‘±Θ≥÷œΏ≥Χ±ΨΒΊΉή ΐΘ§≤Δ»Ο»ΪΨ÷Ήή ΐΫω‘Ύ–η“Σ ±Ά®Ιΐ“ΜΗωΆ®”ΟΒΡœΏ≥ΧΫχ––Ηϋ–¬ΓΘ“ρ¥ΥΘ§‘ΎΙ≤œμΡΎ¥φ«χ”ρ…œΒΡ’υ”ΟΜα¥σ¥σΦθ…ΌΓΘ
«ςœρ”ΎΦθ…ΌΥχ’υ”ΟΒΡΡΘ ΫΜαΦθ…ΌΡΎ¥φΆ®–≈Θ§“ρΈΣΥϋ «“ΜΗωΙ≤œμΒΡΩ…–¥»κΉ¥Χ§Θ§ΗΟΉ¥Χ§–η“Σ Ι”ΟΥχ≤Δ≤ζ…ζ’υ”ΟΓΘ
±ήΟβ”…ΚΥΜΚ¥φ‘λ≥…ΒΡΈ±Ι≤œμΓΘ”–ΙΊΒΡœξœΗ–≈œΔΘ§«κ≤Έ‘Ρœ¬“Μ–ΓΫΎΓΘ
±ήΟβΈ±Ι≤œμ
»γΙϊΝΫΗωΜρΕύΗω¥ΠάμΤς’ΐ‘ΎœρΆ§“ΜΜΚ¥φ––ΒΡ≤ΜΆ§≤ΩΖ÷÷––¥»κ ΐΨίΘ§Ρ«Ο¥ΚήΕύΜΚ¥φΚΆΉήœΏΆ®–≈Ω…ΡήΜαΒΦ÷¬ΤδΥϊ¥ΠάμΤς…œΒΡΨ…––ΒΡΟΩΗωΜΚ¥φΗ±±Ψ ß–ßΜρΫχ––Ηϋ–¬ΓΘ’β≥ΤΈΣ
ΓΑΈ±Ι≤œμΓ± Μρ’Ώ“≤≥ΤΈΣ ΓΑCPU ΜΚ¥φ––Η…»≈Γ±ΓΘΚΆΝΫΗωΜρΕύΗωœΏ≥ΧΙ≤œμΆ§“Μ ΐΨίΘ®“ρ¥Υ–η“Σ≥Χ–ρΜ·ΒΡΆ§≤ΫΜζ÷Τά¥»Ζ±ΘΑ¥Υ≥–ρΖΟΈ Θ©ΒΡ’φ’ΐΙ≤œμ≤ΜΆ§Θ§Β±ΝΫΗωΜρΕύΗωœΏ≥ΧΖΟΈ ΈΜ”ΎΆ§“ΜΜΚ¥φ––…œΒΡΈόΙΊ ΐΨί ±Θ§ΨΆΜα≤ζ…ζΈ±Ι≤œμΓΘ
Ά®Ιΐ“‘œ¬¥ζ¬κΤ§ΕΈΗϋΚΟΒΊΝΥΫβΈ±Ι≤œμΘ®≤ΈΩΦΘΚΈ±Ι≤œμΘ©ΓΘ
«εΒΞ 1. ”Ο”Ύ―ί ΨΈ±Ι≤œμΒΡ¥ζ¬κ Ψάΐ
double sumLocal[N_THREADS];
. . . . .
. . . . .
void ThreadFunc(void *data)
{
. . . . . . .
int id = p->threadId;
sumLocal[id] = 0.0;
. . . . . .
. . . . . .
for (i=0; i<N; i++)
sumLocal[id] += p[i];
. . . . . .
} |
‘Ύ…œΟφΒΡ¥ζ¬κ Ψάΐ÷–Θ§±δΝΩ sumLocal ΒΡ¥σ–Γ”κœΏ≥ΧΒΡ ΐΝΩœύΆ§ΓΘ ΐΉι
sumLocal Ω…ΡήΜαΒΦ÷¬Έ±Ι≤œμΘ§“ρΈΣΒ±ΥϋΟ«–όΗΡΒΡ‘ΣΥΊΈΜ”ΎΆ§“ΜΜΚ¥φ––…œ ±Θ§ΕύΗωœΏ≥ΧΜα‘Ύ ΐΉι÷–÷¥–––¥»κ≤ΌΉςΓΘΆΦ
2 ―ί ΨΝΥΒ±‘Ύ sumLocal ÷––όΗΡΝΫΗωΝ§–χΒΡ‘ΣΥΊ ±Θ§œΏ≥Χ 0 ΚΆœΏ≥Χ 1 ÷°ΦδΒΡΈ±Ι≤œμΓΘœΏ≥Χ
0 ΚΆœΏ≥Χ 1 ’ΐ‘Ύ–όΗΡ ΐΉι sumLocal ÷–Ν§–χΒΡ≤ΜΆ§‘ΣΥΊΓΘ’β–©‘ΣΥΊ‘ΎΡΎ¥φ÷–±Υ¥ΥΝΎΫϋΘ§“ρ¥ΥΫΪΈΜ”ΎΆ§“ΜΗωΜΚ¥φ––…œΓΘ»γΆΦΥυ ΨΘ§ΜΚ¥φ––±ΜΦ”‘ΊΒΫ
CPU0 ΚΆ CPU1 ΒΡΜΚ¥φ÷–Θ®Μ“…ΪΦΐΆΖΘ©ΓΘΦ¥ ΙœΏ≥Χ’ΐ‘Ύ–όΗΡΡΎ¥φ÷–ΒΡ≤ΜΆ§«χ”ρΘ®Κλ…ΪΚΆάΕ…ΪΦΐΆΖΘ©Θ§ΈΣΝΥ±Θ≥÷ΜΚ¥φ“Μ÷¬–‘Θ§‘ΎΦ”‘ΊΗΟΜΚ¥φ––ΒΡΥυ”–¥ΠάμΤς…œΘ§ΗΟΜΚ¥φ––Μα ß–ßΘ§¥”Εχ«Ω÷ΤΫχ––Ηϋ–¬ΓΘ
ΆΦ 2. Έ±Ι≤œμΘ®≤ΈΩΦΘΚ≤ΈΩΦΉ Νœ≤ΩΖ÷÷–ΒΡ±ήΟβΚΆ±ξ ΕœΏ≥Χ÷°ΦδΒΡΈ±Ι≤œμΓΘΘ©
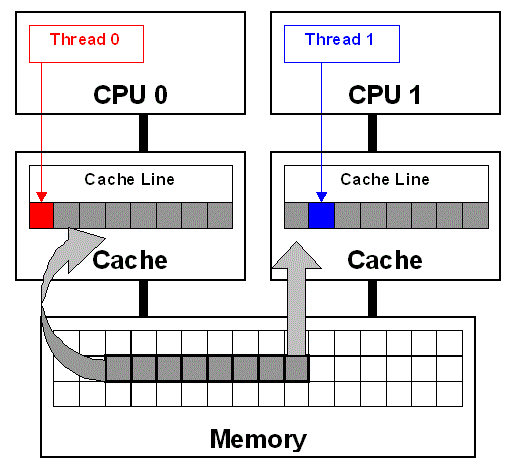
Οη ωœΏ≥Χ 0 ΚΆœΏ≥Χ 1 ÷°ΦδΈ±Ι≤œμΒΡΖΫΩρΆΦΓΘ
Έ±Ι≤œμΜα―œ÷ΊΫΒΒΆ”Π”Ο≥Χ–ρΒΡ–‘ΡήΘ§≤Δ«“Κή≤Μ»ί“ΉΦλ≤βΒΫΓΘ”–ΙΊ―ί ΨΈ±Ι≤œμ≤ΜΝΦ”ΑœλΒΡΦρΒΞ≥Χ–ρΘ§«κ≤Έ‘Ρ ≤ΈΩΦΉ Νœ
≤ΩΖ÷÷–ΒΡΈΡ’¬ ΓΑΕύΚΥΤΫΧ® - CS Liu ΒΡΡΎ¥φΈ ΧβΓ±ΓΘ
±ήΟβΈ±Ι≤œμΒΡΦΦ«…
Ω…“‘ Ι”ΟΩ…”Ο”ΎΕ‘Ρ≥ΗωΧΊΕ®¥ΠάμΤςΫχ––”–ΧθΦΰΒΊ±ύ“κΒΡ±ύ“κΤςΕ‘Τκ÷ΗΝνΘ§Ά®ΙΐΫΪ ΐΨίΫαΙΙ”κΜΚ¥φ––±ΏΫγΕ‘Τκά¥±ήΟβΈ±Ι≤œμΓΘάΐ»γΘ§‘Ύ
Linux? ΤΫΧ®…œΘ§ΆΖΈΡΦΰ adm-i386/cache.h ΈΣ Intel? x86 ΦήΙΙœΒΝ–ΒΡ
L1 ΜΚ¥φ––¥σ–ΓΕ®“εΝΥΚξ L1_CACHE_BYTESΓΘΡζ“≤Ω…“‘Ά®Ιΐ±ύ≥ΧΖΫ Ϋ»ΖΕ®¥ΠάμΜΚ¥φ––ΒΡ¥σ–ΓΓΘ”–ΙΊ‘ΎΜΚ¥φ––±ΏΫγ…œΕ‘Τκ ΐΨίΫαΙΙ“‘ΦΑΆ®Ιΐ±ύ≥ΧΖΫ Ϋ¥¥Ϋ®ΩγΤΫΧ®Κ· ΐ“‘Μώ»ΓΜΚ¥φ––¥σ–ΓΒΡœξœΗ–≈œΔΘ§«κ≤Έ‘Ρ
≤ΈΩΦΉ Νœ ≤ΩΖ÷ΓΘ
Νμ“ΜΗωΦΦ«……φΦΑΕ‘Ψ≠≥ΘΖΟΈ ΒΡ ΐΨίΫαΙΙΝλ”ρΫχ––Ζ÷ΉιΘ§“‘±ψ»ΟΥϋΟ«≥…ΈΣΒΞΗωΒΡΜΚ¥φ––Θ§“ρ¥ΥΩ…“‘Ά®ΙΐΒΞΗωΡΎ¥φΖΟΈ ά¥Φ”‘ΊΥϋΟ«ΓΘ’βΜαΦθ…ΌΡΎ¥φ―”≥ΌΓΘΒΪ «»γΙϊ ΐΨίΫαΙΙΖ«≥ΘΨό¥σΘ§‘ρΩ…ΡήΜα‘ωΦ”ΜΚ¥φ’Φ”ΟΘ§≤Δ«“Ω…Ρή–η“ΣΈΰ…ϋ“Μ–©¥ρΑϋ–߬ ά¥Φθ…ΌΜρœϊ≥ΐΈ±Ι≤œμΓΘ”–ΙΊœξœΗ–≈œΔΘ§«κ≤Έ‘Ρ
≤ΈΩΦΉ Νœ ≤ΩΖ÷÷–ΒΡ ΓΑΜΚ¥φ±ύ≥Χ―υ ΫΒΡ‘ΣΥΊΓ± ΈΡ’¬ΓΘ
ΈΣΝΥΖά÷Ι ΐΉι÷–ΖΔ…ζΈ±Ι≤œμΘ§”ΠΗΟΫΪ ΐΉι”κΜΚ¥φΒΡ¥σ–ΓΤΞ≈δΓΘΫαΙΙΒΡ¥σ–Γ±Ί–κ «¥ΠάμΤςΜΚ¥φ––¥σ–ΓΒΡ’ϊ ΐ±ΕΓΘ
»γΙϊ–η“ΣΦΌΕ®ΜΚ¥φ––¥σ–Γ“‘±ψ«Ω÷ΤΕ‘ΤκΘ§‘ρ”Π Ι”Ο 32 Ή÷ΫΎΓΘ«κΉΔ“βΘΚ
32 Ή÷ΫΎΕ‘ΤκΒΡΜΚ¥φ––Ά§ ±“≤ « 16 Ή÷ΫΎΕ‘ΤκΒΡΜΚ¥φ––ΓΘ
‘Ύ¥σΕύ ΐ¥ΠάμΤς…œΘ§ ΚœΦΌΕ® 32 Ή÷ΫΎΜΚ¥φ––¥σ–ΓΓΘάΐ»γΘ§IBM PowerPC? 601 Οϊ“ε…œ”–“ΜΗω
64 Ή÷ΫΎΜΚ¥φ––Θ§ΒΪΥϋ ΒΦ …œ”–ΝΫΗω“―Ν§Ϋ”ΒΡ 32 Ή÷ΫΎΜΚ¥φ––ΓΘSparc64 ”–“ΜΗω 32 Ή÷ΫΎ L1
ΚΆ“ΜΗω 64 Ή÷ΫΎ L2 ΜΚ¥φ––ΓΘAlpha ”–“ΜΗω 32 Ή÷ΫΎ L1 ΜΚ¥φ––ΓΘItanium ΦήΙΙ”–“ΜΗω
64 Ή÷ΫΎ L1 ΜΚ¥φ––Θ§IBM System z? ”–“ΜΗω 256K L1 ΜΚ¥φ––ΚΆ 128 Ή÷ΫΎΜΚ¥φ––Θ§Εχ
x86 ¥ΠάμΤς”– 64 Ή÷ΫΎ L1 ΜΚ¥φ––ΓΘ
‘Ύ“ΜΗωΚΥ…œ”––ß÷¥––ΒΡΆ®”ΟΙφ‘ρ «ΫΪ ΐΨίΫτΫτΑϋΙϋΘ§“‘±ψΗΟ ΐΨί’Φ”ΟΫœ…ΌΒΡΩ’ΦδΓΘΒΪ‘ΎΕύΚΥ¥ΠάμΤς…œΘ§ΑϋΙϋΙ≤œμ ΐΨίΩ…ΡήΜαΒΦ÷¬―œ÷ΊΒΡΈ±Ι≤œμΓΘΆ®≥ΘΘ§ΫβΨωΖΫΑΗ «ΫτΫτΑϋΙϋ ΐΨίΘ§ΗχΟΩΗωœΏ≥ΧΧαΙ©ΥϋΉ‘ΦΚΒΡΉ®”ΟΗ±±Ψ“‘±ψ ΙΤδΦΧ–χΙΛΉςΘ§÷°Κσ‘ΌΫΪΫαΙϊΫχ––Κœ≤ΔΓΘ
œΏ≥Χ Ι”ΟΝΥ≥ΡΒφΫαΙΙΜρ ΐΨίΘ§»Ζ±Θ≤ΜΆ§œΏ≥ΧΥυ”Β”–Μρ–όΗΡΒΡ ΐΨίΈΜ”Ύ≤ΜΆ§ΒΡΜΚ¥φ––…œΓΘ
œϊ≥ΐΈ±Ι≤œμΘΩ¥μΈσΘΓ
‘Ύάμœκ«ιΩωœ¬Θ§Έ“Ο«ΒΡΡΩ±ξ «œϊ≥ΐΙ≤œμΘ§Εχ≤Μ÷Μ «Έ±Ι≤œμΓΘΆ®≥ΘΘ§»μΦΰ…ηΦΤ”ΠΗΟΨΓΝΠœϊ≥ΐΕ‘ΥχΓΔΆ§≤ΫΜζ÷Τ“‘ΦΑΙ≤œμΒΡ–η«σΓΘ”–ΙΊΒΡ÷Ί“ΣΙέΒψΘ§«κ≤Έ‘Ρ
Dmitriy Vyukov ΒΡΈΡ’¬ΓΘ
Έ±Ι≤œμ≤Μ»ί“ΉΦλ≤βΘ§ΒΪ”–ΦΗΗωΙΛΨΏΘ®»γ Oprofile ΚΆ Valgrind ΒΡ ΐΨί’υ”ΟΦλ≤β (DRD)
ΡΘΩιΘ©Ω…“‘ΈΣΡζΧαΙ©Αο÷ζΓΘ
œϊ≥ΐΜρΦθ…ΌΥχ’υ”Ο
’βΗω…ηΦΤΉΔ“β ¬œν ««ΑΟφΧαΒΫΒΡΝΫΗωΩΦ¬« ¬œνΒΡά©’ΙΘ§ΡΩΒΡ «±ήΟβΡΎ¥φ’υ”ΟΚΆΈ±Ι≤œμΓΘ’ΐ»γ«ΑΟφ≤ΩΖ÷Υυ ωΘ§»μΦΰ…ηΦΤ’ΏΒΡ÷ς“ΣΡΩ±ξ”ΠΗΟ «œϊ≥ΐΙ≤œμΘ§“‘±ψœΏ≥ΧΜρΫχ≥Χ÷°Φδ≤ΜΜαΖΔ…ζΉ ‘¥’υ”ΟΓΘ«ΑΟφ≤ΩΖ÷÷–Υυ ωΒΡ“Μ–©ΦΦ«…Θ®»γ Ι”ΟœΏ≥Χ±ΨΒΊ±δΝΩ¥ζΧφ»ΪΨ÷Ι≤œμ«χ”ρΘ©Ω…“‘Ζά÷ΙΖΔ…ζΡΎ¥φ’υ”ΟΚΆΈ±Ι≤œμΓΘΒΪ «Θ§ΗΟΦΦ«…≤Δ≤Μ ”Ο”ΎΥυ”–«ιΩωΓΘ
άΐ»γΘ§»γΙϊ”–“ΜΗω±Θ≥÷Ή ‘¥Ή¥Χ§ΒΡ ΐΨίΫαΙΙΘ§‘ρ”–Ω…ΡήΈόΖ®‘ΎΟΩΗωœΏ≥Χ÷–ΑϋΚ§ΗΟΫαΙΙΒΡΗ±±ΨΓΘΗΟ ΐΨίΫαΙΙΩ…Ρή±Ί–κ”…”Π”Ο≥Χ–ρ÷–ΒΡΥυ”–œΏ≥ΧΕΝ»ΓΚΆ–όΗΡΓΘ“ρ¥ΥΘ§±Ί–κ Ι”ΟΆ§≤ΫΦΦ θά¥±Θ≥÷ ΐΨίΒΡ“Μ÷¬–‘“‘ΦΑ¥ΥάύΙ≤œμ ΐΨίΫαΙΙΒΡΆξ’ϊ–‘ΓΘ»γΙϊ¥φ‘Ύ”Ο”Ύ±ΘΜΛΙ≤œμΉ ‘¥ΒΡΥχΜρΆ§≤ΫΙΙ‘λΘ§‘ρΩ…ΡήΜα‘ΎΕύΗωœΏ≥ΧΜρΫχ≥Χ÷°Φδ≥ωœ÷Υχ’υ”ΟΘ§¥”ΕχΫΒΒΆ–‘ΡήΓΘ
‘ΎΕύΚΥΓΔΕύ¥ΠάμΤςœΒΆ≥…œΘ§Ω…Ρή”–Ω’Φδά¥Ά§ ±‘Υ––¥σΝΩœΏ≥ΧΜρΫχ≥ΧΘ§ΒΪ «Θ§»γΙϊ’β–©œΏ≥Χ±Ί–κ≤ΜΕœΒΊ±Υ¥ΥΨΚ’υΘ§“‘ΖΟΈ Μρ–όΗΡΙ≤œμΉ ‘¥Μρ ΐΨίΫαΙΙΘ§Ρ«Ο¥œΒΆ≥ΒΡΉήΧεΆΧΆ¬ΝΩΜα”–ΥυΫΒΒΆΓΘ’βΜαΒΦ÷¬”Π”Ο≥Χ–ρΈόΖ®Ά®Ιΐ…λΥθά¥”––ßΒΊάϊ”ΟΩ…”ΟΒΡΦΤΥψΉ ‘¥ΓΘ‘Ύ”…”ΎΥχ’υ”ΟΕχΒΦ÷¬–‘ΡήΫΒΒΆΒΡΦΪΜΒ«ιΩωœ¬Θ§ΥφΉ≈ΚΥ–ΡΜρ¥ΠάμΤς ΐΝΩΒΡ‘ωΦ”Θ§”Π”Ο≥Χ–ρΒΡ–‘ΡήΜα”–ΥυΫΒΒΆΓΘ
±ήΟβΥχ’υ”ΟΒΡΦΦ«…
±ήΟβ‘Ύ ΐΨίΫαΙΙ÷–ΖΔ…ζΥχ’υ”ΟΒΡΖΫΖ®÷°“Μ «≤…”Ο≤ΔΖΔ ΐΨίΫαΙΙ…ηΦΤΚΆΈόΥχΥψΖ®Θ§’βΜαœϊ≥ΐΥχ“‘ΦΑ¥ΪΆ≥ΒΡΆ§≤ΫΦΦ«…Θ®±»»γΜΞ≥βΘ©ΓΘ”–Εύ÷÷≤ΔΖΔ ΐΨίΫαΙΙΒΡ…ηΦΤ≤Δ≤Μ–η“Σάϊ”ΟΆ§≤ΫΜζ÷ΤΘ§±»»γΜΞ≥βΓΘ”–ΙΊ¥Υάύ≤ΔΖΔ ΐΨίΫαΙΙ…ηΦΤΒΡ“Μ–© ΨάΐΘ§«κ≤Έ‘Ρ
≤ΈΩΦΉ Νœ ≤ΩΖ÷ΓΘ
ΈόΥχΥψΖ®ΒΡ“Μ–© Ψάΐ»γœ¬ΘΚ
Ι”Ο œύΕ‘¬έ±ύ≥Χ ΒΡΩ……λΥθ≤ΔΖΔΙΰœΘ±μΘΚΗΟΦΦ«…ΒΡΉνΦρΒΞ Ψάΐ « Read Copy Update (RCU)Θ§ΥϋΉ®”Ο”Ύ
Linux ΡΎΚΥΘ§¥σ¥σΧαΗΏΝΥ Linux ΡΎΚΥΒΡ–‘ΡήΘ§≤ΔΦρΜ·ΝΥ Linux ΡΎΚΥΒΡ¥ζ¬κΓΘ
ΈόΥχΩ…ά©’Ι”––ρΖ÷ΗνΒΡΙΰœΘΝ–±μΘΚ’βΗωΈόΥχΒίΙιΩ…ά©’ΙΙΰœΘΥψΖ® Ι”ΟΝΥΈόΥχΒΡΝ¥Ϋ”Ν–±μΘ§’β–©Ν–±μ Ι”Ο‘≠Ή”÷ΗΝνά¥–όΗΡΝ¥Ϋ”ΒΡΝ–±μΓΘ
‘Ύ Linux ΡΎΚΥ÷–Θ§ΙψΖΚ Ι”ΟΝΥΟΩ¥ΠάμΤς±δΝΩΘ§œΒΆ≥…œΒΡΟΩΗω¥ΠάμΤςΕΦΜώΒΟΝΥΉ‘ΦΚΒΡ“ΜΗωΗχΕ®±δΝΩΒΡΗ±±ΨΓΘΖΟΈ ΟΩ¥ΠάμΤς±δΝΩ≤Μ–η“Σ Ι”ΟΥχΘ§¥ΥΆβΘ§“ρΈΣ‘Ύ≤ΜΆ§ΒΡ¥ΠάμΤς…œΘ§’β–©±δΝΩΈ¥‘ΎœΏ≥Χ÷°ΦδΙ≤œμΘ§“ρ¥ΥΟΜ”–Έ±Ι≤œμΜρΡΎ¥φ’υ”ΟΓΘ’β÷÷ΦΦ«…Ζ«≥Θ Κœ ’Φ·Ά≥ΦΤ–≈œΔΓΘ
Φθ…ΌΥχ’υ”ΟΒΡΦΦ«…
Β± Ι”Ο¥ΪΆ≥ΥχΜρΆ§≤ΫΦΦ«…Θ®»γΉ‘–ΐΥχΘ© ±Θ§±Ί–κΉΔ“βΒΡ «Θ§≤Μ“Σ Ι”ΟΒΞΤ§ΥχΜρ»ΪΨ÷ΥχΘ§Εχ «ΫΪ’β–©ΥχΖ÷≥…ΗϋœΗ–ΓΒΡ≤ΩΖ÷ΓΘ“ρ¥ΥΘ§ΥχΜα±ΘΜΛ ΐΨίΫαΙΙ÷–ΒΡΡ≥ΗωΧΊΕ®«χ”ρ“‘ΦΑΫœ–ΓΒΡ«χ”ρΓΘ’β―υΕύΗωœΏ≥ΧΨΆΡήΙΜΆ®ΙΐΜώ»Γ±ΘΜΛ’β–©≥…‘±ΒΡœύ”ΠΥχΘ§‘ΎΆ§“Μ ΐΨίΫαΙΙΒΡ≤ΜΆ§≥…‘±…œ≤ΔΖΔΫχ––≤ΌΉςΓΘ’β÷÷ΖΫΖ®Ω…“‘ Βœ÷ΗϋΕύ≤ΔΖΔΓΘ
…θ÷ΝΒ±»μΦΰ…ηΦΤ÷–ΒΡΆ§≤ΫΜζ÷ΤΡήΙΜ Βœ÷ΗϋΚΟΒΡ≤ΔΖΔΚΆΦθ…ΌΥχ’υ”Ο ±Θ§“≤Ω…ΡήΜα”…”ΎΈ±Ι≤œμΕχΒΦ÷¬ΖΔ…ζ–‘ΡήΈ ΧβΓΘάΐ»γΘ§ΩΦ¬«“ΜΗωΙΰœΘ ΐΨίΫαΙΙΓΘ»γΙϊ¥φ‘Ύ“ΜΗωΉ‘–ΐΥχ ΐΉιΘ§”Ο”Ύ±ΘΜΛΙΰœΘ÷–ΒΡΟΩΗωΙΰœΘΆΑΘ§Ρ«Ο¥‘ΎΉ‘–ΐΥχ ΐΉι÷–Ω…ΡήΜα≥ωœ÷Έ±Ι≤œμΓΘΝΫΗωœΏ≥Χ‘ΎΝΫΗω≤ΜΆ§ΒΡ¥ΠάμΤς…œ‘Υ––Θ§ΟΩΗωœΏ≥ΧΕΦΥχΕ®ΙΰœΘ÷–ΒΡ≤ΜΆ§ΙΰœΘΆΑȧѫϥ±ΥϋΟ«Υυ–ηΒΡΉ‘–ΐΥχΈΜ”ΎΆ§“ΜΗωΜΚ¥φ––…œ ±Θ§Ω…ΡήΜαΖΔ…ζΈ±Ι≤œμΓΘ“ρ¥ΥΘ§‘Ύ…ηΦΤ¥ΥάύΥψΖ® ±–η“ΣΩΦ¬«≤…”Ο±ήΟβΖΔ…ζΈ±Ι≤œμΒΡΆ®”ΟΦΦ«…ΓΘ
Φλ≤βΥχ’υ”Ο“‘ΦΑœϊ≥ΐΜρΦθ…ΌΥχ’υ”ΟΕ‘”Ύ‘ΎΕύΚΥΓΔΕύ¥ΠάμΤςΜΖΨ≥÷–ΧαΙ©”Π”Ο≥Χ–ρΒΡΩ……λΥθ–‘Ζ«≥Θ÷Ί“ΣΓΘ≤ΌΉςœΒΆ≥ΧαΙ©ΝΥ”Ο”ΎΦλ≤βΚΆΕ»ΝΩ”…”ΎΥχ’υ”ΟΕχΒΦ÷¬–‘ΡήΤΩΨ±ΒΡ Β”ΟΙΛΨΏΓΘάΐ»γΘ§Solaris
ΧαΙ©ΝΥ Lockstat Β”ΟΙΛΨΏΘ§”Ο”ΎΕ»ΝΩΡΎΚΥΡΘΩι÷–ΒΡΥχ’υ”ΟΓΘΆ§―υΘ§Linux ΡΎΚΥ“≤ΧαΙ©ΝΥ Lockstat
ΚΆ Lockdep ΩρΦήΘ§”Ο”ΎΦλ≤βΚΆΕ»ΝΩΥχ’υ”Ο“‘ΦΑ–‘ΡήΤΩΨ±ΓΘ"Windows –‘ΡήΙΛΨΏΑϋ
- Xperf" ‘Ύ Windows …œΧαΙ©ΝΥάύΥΤΒΡΙΠΡήΓΘ”–ΙΊΒΡœξœΗ–≈œΔΘ§«κ≤Έ‘Ρ ≤ΈΩΦΉ Νœ
≤ΩΖ÷ΓΘ
±ήΟβΕ―’υ”Ο
C/C++ ±ξΉΦΡΎ¥φΙήάμάΐ≥Χ « Ι”ΟΧΊΕ®”ΎΤΫΧ®ΒΡΡΎ¥φΙήάμ API Βœ÷ΒΡΘ§ΥϋΆ®≥ΘΜυ”ΎΕ―ΒΡΗ≈ΡνΓΘ’β–©Ωβάΐ≥ΧΘ®Έό¬έ «ΒΞœΏ≥ΧΑφ±ΨΜΙ «ΕύœΏ≥ΧΑφ±ΨΘ©‘ΎΒΞΗωΕ―…œΖ÷≈δΜρ ΆΖ≈ΡΎ¥φΓΘΥϋ «»ΪΨ÷Ή ‘¥Θ§‘ΎΡ≥ΗωΫχ≥Χ÷–ΒΡœΏ≥Χ÷°ΦδΙ≤œμ≤Δ’υ”ΟΓΘΕ―’υ”Ο «ΡΎ¥φΟήΦ·–ΆΕύœΏ≥Χ”Π”Ο≥Χ–ρΒΡΤΩΨ±÷°“ΜΓΘ
±ήΟβΕ―’υ”ΟΒΡΦΦ«…
Ι”ΟœΏ≥Χ±ΨΒΊ/Ή®”ΟΕ―Ϋχ––ΡΎ¥φΙήάμΘ§¥”Εχœϊ≥ΐΝΥΉ ‘¥’υ”ΟΓΘ‘Ύ Windows ΤΫΧ®…œΘ§Ω…“‘ Ι”Ο HeapCreate()
ΈΣΟΩΗωœΏ≥Χ¥¥Ϋ®“ΜΗωΉ®”ΟΕ―Θ§≤ΔΫΪΖΒΜΊΒΡΕ―Ψδ±ζ¥ΪΒίΗχ HeapAlloc()/HeapFree() Κ· ΐΓΘ
≤ΈΩΦΉ Νœ ≤ΩΖ÷÷–ΒΡ ΓΑΕύΚΥΤΫΧ®ΒΡΡΎ¥φΈ Χβ - CS LiuΓ± ΈΡ’¬ΧαΙ©ΝΥ“ΜΗωΕ―’υ”Ο ΨάΐΓΘ‘Ύ’βΗω≤ΈΩΦΉ Νœ÷–Θ§Ής’Ώ―ί ΨΝΥ»γΚΈ Ι”ΟΉ®”ΟΕ―ΫΪ–‘ΡήΧαΗΏ
3 ±ΕΉσ”“Θ®”κ Ι”Ο»ΪΨ÷Ε―œύ±»Θ©ΓΘ
ΉΔ“βΘΚ
‘Ύ Windows ΤΫΧ®…œΘ§Β±¥¥Ϋ®Ε― ±Θ§Ω…“‘…η÷Ο heap_no_serialization ±ξ÷ΨΘ§’β“βΈΕΉ≈¥”ΕύΗωœΏ≥ΧΖΟΈ Υϋ ±≤Μ–η“ΣΫχ––Ά§≤ΫΓΘΒΪ ¬ Β÷ΛΟςΘ§‘Ύ
vista ΦΑΗϋΗΏΑφ±ΨΒΡ≤ΌΉςœΒΆ≥…œΘ§ΫΪΗΟ±ξ÷Ψ…η÷ΟΈΣœΏ≥ΧΥΫ”–Ε―ΥΌΕ»ΜαΚή¬ΐΓΘ
Heap_no_serialization ΚΆ“Μ–©Βς ‘ΖΫΑΗΫΪΫϊ”Ο ΓΑLow Fragment HeapΓ±
ΙΠΡήΘ§œ÷‘Ύ’β «Ε―ΒΡ ¬ ΒΡ§»œ≤Ώ¬‘Θ§“ρ¥ΥΫχ––ΝΥΗΏΕ»”≈Μ·ΓΘ
ΧαΗΏ¥ΠάμΤςΙΊΝΣ
¥ΠάμΤςΙΊΝΣ «“ΜΗωœΏ≥ΧΜρΫχ≥Χ τ–‘Θ§ΗΟ τ–‘ΗφΥΏ≤ΌΉςœΒΆ≥Ω…“‘‘ΎΡΡ–©ΚΥΜρ¬ΏΦ≠¥ΠάμΤς…œ‘Υ––Ϋχ≥ΧΓΘ’βΗϋ Κœ«Ε»κ Ϋ»μΦΰ…ηΦΤΓΘ
ΆΦ 3 œ‘ ΨΝΥ“ΜΗωœΒΆ≥≈δ÷ΟΘ§ΗΟ≈δ÷ΟΑϋΚ§ΝΫΗω¥ΠάμΤςΘ§ΟΩΗω¥ΠάμΤς”–ΝΫΗωΚΥΘ§’βΝΫΗωΚΥΕΦ”–“ΜΗωΙ≤œμΒΡ L2
ΜΚ¥φΓΘ‘ΎΗΟ≈δ÷Ο÷–Θ§‘ΎΆ§“Μ¥ΠάμΤς…œΒΡΝΫΗωΚΥ÷°Φδ“‘ΦΑ≤ΜΆ§¥ΠάμΤς…œΒΡΝΫΗωΚΥ÷°ΦδΘ§ΜΚ¥φΉ”œΒΆ≥ΒΡ––ΈΣΫΪΜα”–Υυ≤ΜΆ§ΓΘ»γΙϊΝΫΗωœύΙΊΒΡΫχ≥ΧΜρΡ≥ΗωΫχ≥ΧΒΡΝΫΗωœύΙΊœΏ≥Χ±ΜΖ÷≈δΗχΆ§“Μ¥ΠάμΤς…œΒΡΝΫΗωΚΥΘ§Ρ«Ο¥ΥϋΟ«Ω…“‘ΗϋΚΟΒΊάϊ”ΟΙ≤œμΒΡ
L2 ΜΚ¥φΘ§Εχ«“Ω…“‘Φθ…Ό±Θ≥÷ΜΚ¥φ“Μ÷¬–‘ΒΡΩΣœζΓΘ
ΆΦ 3. ΕύΗωΚΥΙ≤œμ“ΜΗω L2 ΜΚ¥φΒΡœΒΆ≥
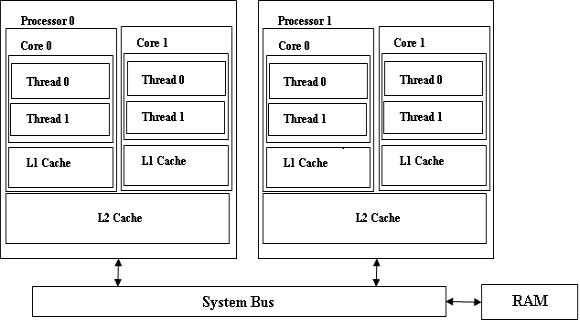
Οη ωΕύΚΥΕύ¥ΠάμΤςœΒΆ≥Θ®Ρ≥Ηω¥ΠάμΤς…œΒΡΚΥΙ≤œμ“ΜΗω L2 ΜΚ¥φΘ©ΒΡΖΫΩρΆΦΓΘ
…ηΦΤΉΔ“β ¬œν
«Ε»κ ΫœΒΆ≥ΒΡ»μΦΰ…ηΦΤ’ΏΩ…“‘άϊ”Ο’βΗω±Θ≥÷ΜΚ¥φ“Μ÷¬–‘œύΕ‘ΫœΒΆΒΡΩΣœζΘ§Ά®Ιΐ±ύ≥ΧΩΊ÷ΤœρΚΥΖ÷≈δœΏ≥ΧΓΘ
‘Ύ Linux ΚΆ Windows ≤ΌΉςœΒΆ≥…œΒΡ“‘œ¬œΒΆ≥Βς”ΟΩ…“‘ΗφΥΏ”Π”Ο≥Χ–ρΘ§Ε‘”ΎΧΊΕ®ΒΡΫχ≥Χά¥ΥΒΘ§¥ΠάμΤς «»γΚΈΙΊΝΣΒΡΘ§≤ΔΈΣΫχ≥Χ…η÷Ο¥ΠάμΤςΙΊΝΣ―Ύ¬κΘΚ
«εΒΞ 2. ”Ο”ΎΙήάμ¥ΠάμΤςΙΊΝΣΒΡœΒΆ≥Βς”Ο
Linux Example:
/* Get a process' CPU affinity mask */
extern int
sched_getaffinity(pid_t pid, size_t cpusetsize,
cpu_set_t *cpuset);
/* Set a process's affinity mask */
extern int
sched_setaffinity(pid_t pid, size_t cpusetsize,
const cpu_set_t *cpuset);
Windows Example:
/* Set processor affinity */
BOOL WINAPI
SetProcessAffinityMask (Handle hProcess, DWORD_PTR
dwProcessAffinityMask);
/* Set Thread affinity */
DWORD_PTR WINAPI
SetThreadAffinityMask (Handle hThread, DWORD_PTR
dwThreadAffinityMask);
|
±ύ≥ΧΡΘ–Ά
Β±ΈΣ”Π”Ο≥Χ–ρ÷–ΒΡœΏ≥ΧΖ÷≈δΙΛΉς ±Θ§»μΦΰ…ηΦΤ’ΏΩ…“‘ΩΦ¬«ΝΫΗω≤ΜΆ§ΒΡ±ύ≥ΧΡΘ–ΆΓΘΥϋΟ« «ΘΚ
ΙΠΡήΖ÷Ϋβ
ΗΟΡΘ–ΆΒΡΡΩ±ξ «ΝΥΫβ”Π”Ο≥Χ–ρΜρ»μΦΰ±Ί–κ÷¥––ΒΡ≤ΌΉςΘ§≤ΔΫΪΟΩΗω≤ΌΉςΖ÷≈δΗχ≤ΜΆ§ΒΡœΏ≥ΧΓΘ
Ω…“‘ΫΪΕύΗω≤ΌΉςΉιΚœ‘Ύ“ΜΗωœΏ≥Χ÷–Θ§ΒΪΙΠΡήΖ÷ΫβΒΡΫαΙϊ «ΟΩΗω≤ΌΉςΕΦ”…ΧΊΕ®ΒΡœΏ≥Χά¥÷¥––ΓΘ
”ρΖ÷ΫβΜρ≥ΤΈΣ ΐΨίΖ÷Ϋβ
ΗΟΡΘ–ΆΒΡΡΩ±ξ «Ζ÷Έω»μΦΰΜρ”Π”Ο≥Χ–ρΥυ–ηΒΡ ΐΨίΦ·Θ§“‘±ψΕ‘ΥϋΟ«Ϋχ––ΙήάμΜρ¥ΠάμΘ§≤ΔΫΪ’β–© ΐΨίΦ·Ζ÷Ϋβ≥…Ω…“‘ΒΞΕά¥ΠάμΒΡΫœ–ΓΉιΦΰΓΘ
»μΦΰ÷–ΒΡœΏ≥ΧΜα÷ΊΗ¥“Σ÷¥––ΒΡ≤ΌΉςΘ§ΒΪΟΩΗωœΏ≥ΧΫΪ‘ΎΒΞΕάΒΡ ΐΨίΉιΦΰ…œ÷¥––≤ΌΉςΓΘ
»μΦΰΥυ–ηΒΡ≤ΌΉςάύ–Ά“‘ΦΑ ΐΨίΧΊ–‘ΕΦΜα”ΑœλΡΘ–ΆΒΡ―Γ‘ώΘ§ΒΪ «±Ί–κΝΥΫβ’β–©ΡΘ–Ά»γΚΈ‘ΎΕύ¥ΠάμΤςΜρΕύΚΥΜΖΨ≥÷–÷¥––ΓΘ
»μΦΰ…ηΦΤ’Ώ–η“ΣΩΦ¬«ΒΡΦΗΗωΉΔ“β ¬œν
ΨΓΙή ΐΨίΖ÷Ϋβ÷–ΒΡΜΚ¥φΫΜΜΞΩ¥ΥΤΖ«≥ΘΦρΒΞΘ®“βΈΕΉ≈ ΐΨίΖ÷Ϋβ”≈”ΎΙΠΡήΖ÷ΫβΘ©Θ§ΒΪ÷ß≥÷”ρΖ÷ΫβΥυ–ηΒΡ»μΦΰ…ηΦΤΩ…ΡήΟφΝΌΖ«≥Θ¥σΒΡΧτ’ΫΓΘ
Ζ÷ΫβΡΘ–Ά÷–ΒΡ ΐΨί»‘»Μ–η“ΣΈΜ”Ύ≤ΜΆ§ΒΡΜΚ¥φ––…œΘ§“‘±ήΟβ≥ωœ÷Έ±Ι≤œμΒΡΩ…ΡήΓΘ
‘Ύ ≤ΈΩΦΉ Νœ≤ΩΖ÷÷–ΒΡΕύΚΥΕύ¥ΠάμΤςœΒΆ≥ΒΡ»μΦΰ…ηΦΤΈ Χβ≤ΈΩΦΈΡœΉ÷–Θ§œξœΗΫι…ήΝΥ±ύ≥ΧΡΘ–ΆΓΔΈΣΕύΚΥΕύ¥ΠάμΤςΦήΙΙΫχ––»μΦΰ…ηΦΤ ±”Π”Ο’β–©ΡΘ–ΆΒΡΧτ’ΫΚΆ”≈ ΤΓΘ
Ϋα χ”ο
±ΨΈΡΦρ“ΣΫι…ήΝΥΕύΚΥΕύœΏ≥ΧΜΖΨ≥ΒΡΧΊ–‘Θ§ΜΙΫι…ήΝΥ‘ΎΕύΚΥΕύ¥ΠάμΤςœΒΆ≥…œΩ…ΡήΒΦ÷¬ΫΒΒΆ”Π”Ο≥Χ–ρ–‘ΡήΜρΖΝΑ≠”Π”Ο≥Χ–ρΩ……λΥθ–‘ΒΡ“Μ–©÷Ί“ΣΈ ΧβΘ§Χ÷¬έΝΥ‘Ύ’β―υΒΡΜΖΨ≥÷–…ηΦΤ»μΦΰ ±ΒΡ“Μ–©÷Ί“ΣΩΦ¬« ¬œνΚΆΦΦ«…ΓΘΩΦ¬«ΝΥ’β–©ΩΦ¬« ¬œνΕχ…ηΦΤΒΡ»μΦΰΜρ”Π”Ο≥Χ–ρΩ…“‘”––ßΒΊάϊ”ΟΩ…”ΟΒΡΦΤΥψΉ ‘¥Θ§ΜΙΩ…“‘±ήΟβ–‘ΡήΚΆΩ……λΥθ–‘Έ Χβ |









