| БрМЭЦМі: |
| БОЮФРДздгкibm,ОпЬхНщЩмСЫШчКЮЖдШЯжЊЯЕЭГЕФбЕСЗСїГЬгІгУ
DevOpsЃЌАќРЈбЕСЗЪ§ОнЁЂНЈФЃКЭадФмЦРЙРЁЃ |
|
ШЯжЊЯЕЭГЮЊЙЙНЈгаЧПДѓЕФжЧФмзїЮЊжЇГХЕФаТаЭгІгУГЬађЬсЙЉСЫОјМбЛњЛсЁЃетаЉаТгІгУГЬађашвЊгУвЛжжаТЗНЪНРДЫМПМПЊЗЂСїГЬЁЃDevOps
ИХФюдіЧПСЫДЋЭГЕФгІгУГЬађПЊЗЂЃЌЫќНЋдЫгЊПМТЧвђЫиШкШыЕНСЫПЊЗЂЪБМфЁЂжДааКЭСїГЬжаЁЃдкБОНЬГЬжаЃЌЮвУЧНЋИХЪівЛжжЁАШЯжЊ
DevOpsЁБСїГЬЃЌИУСїГЬИФНјКЭЕїећ DevOps ЕФзюМбВПЗжЃЌвдЛёЕУаТЕФШЯжЊгІгУГЬађЁЃОпЬхРДНВЃЌЮвУЧНЋНщЩмШчКЮЖдШЯжЊЯЕЭГЕФбЕСЗСїГЬгІгУ
DevOpsЃЌАќРЈбЕСЗЪ§ОнЁЂНЈФЃКЭадФмЦРЙРЁЃ
ШЯжЊШЮЮёРраЭ
ДгИљБОЩЯНВЃЌШЯжЊЛђШЫЙЄжЧФм (AI) ЯЕЭГОпгаДгЪ§ОнжаРэНтЁЂЭЦРэКЭбЇЯАЕФФмСІЁЃДгИќЩюВуДЮНВЃЌИУЯЕЭГНЈСЂдкИїжжВЛЭЌРраЭШЯжЊШЮЮёЕФзщКЯЕФЛљДЁЩЯЃЌетаЉШЮЮёзщКЯдквЛЦ№КѓЃЌЙЙГЩСЫећИіШЯжЊгІгУГЬађЕФвЛВПЗжЁЃетаЉШЮЮёАќРЈЃК
ЪЕЬхЬсШЁ
ЖЮТфМьЫї
ЮФБОЗжРр
гяЕїКЭЧщаїМьВт
жЊЪЖЬсШЁ
гябдЗвы
гявєзЊТМ
МЦЫуЛњЪгОѕ
ЭМ 1. ШЯжЊШЮЮё
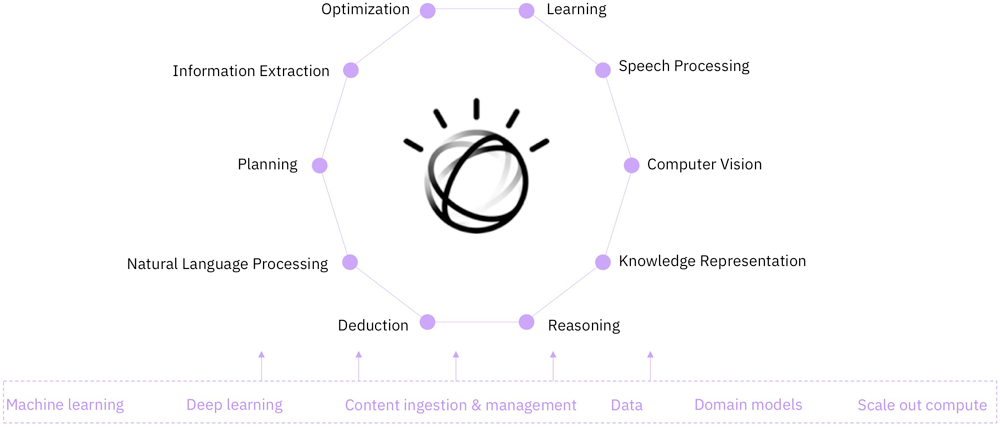
ШЯжЊЯЕЭГЫљЛљгкЕФПЦбЇАќРЈЕЋВЛЯогкЛњЦїбЇЯА (ML)ЃЌЛњЦїбЇЯААќРЈЩюЖШбЇЯАКЭздШЛгябдДІРэЁЃетаЉзщМўФмБэЯжГіШЯжЊЯЕЭГЕФвЛжжЛђЖржжФмСІЃЈБШШчРэНтЁЂЭЦРэЁЂбЇЯАКЭНЛЛЅЃЉЁЃетаЉШЯжЊЯЕЭГРћгУРДздФкВПЁЂЕкШ§ЗНЁЂЙКТђЕФКЭПЊдДЕФНсЙЙЛЏКЭЗЧНсЙЙЛЏЪ§ОнЃЌЗЂОђПЩВйзїЕФЖДВьКЭжЊЪЖЁЃ
гыШнвздкЪ§ОнПтжазщжЏКЭЩИбЁЕФНсЙЙЛЏЪ§ОнВЛЭЌЃЌДгДЋЭГЩЯНВЃЌЗЧНсЙЙЛЏЪ§ОнашвЊШЫРДРэНтЁЃЗЧНсЙЙЛЏЪ§ОнЕФЪОР§АќРЈгУздШЛгябдБраДЕФЮФЕЕЁЂТМвєЁЂЭМЯёЃЌЩѕжСЪЧЩчНЛУНЬхЮФеТЕШЁЃетаЉРраЭЕФЃЈЗЧНсЙЙЛЏЃЉЪ§ОнЪЧЮвУЧдкЦѓвЕжаУПЬьДІРэЕФЪ§ОнЃЌАќРЈбаОПБЈИцЁЂДћПюЮФМўЁЂБИЭќТМЁЂКєНажааФТМвєЛђВњЦЗЦРТлЁЃ
ЭМ 2. ЦѓвЕФкЭтЕФИїжжРраЭЕФЗЧНсЙЙЛЏЪ§Он
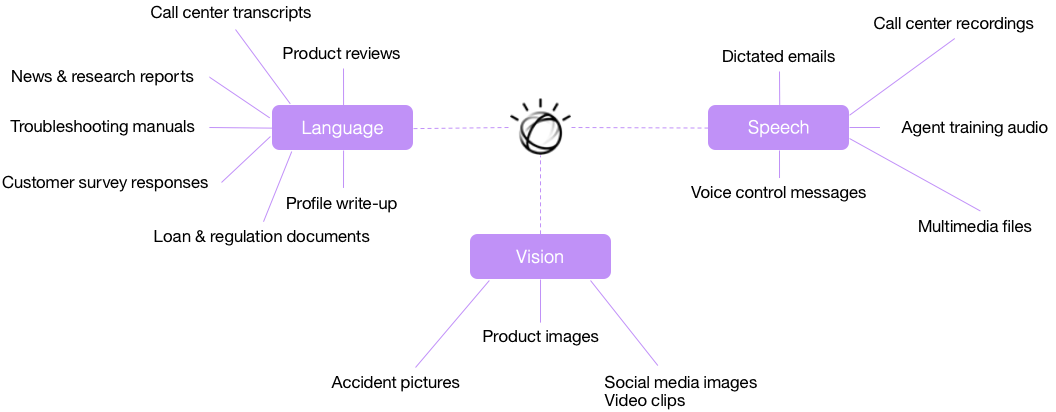
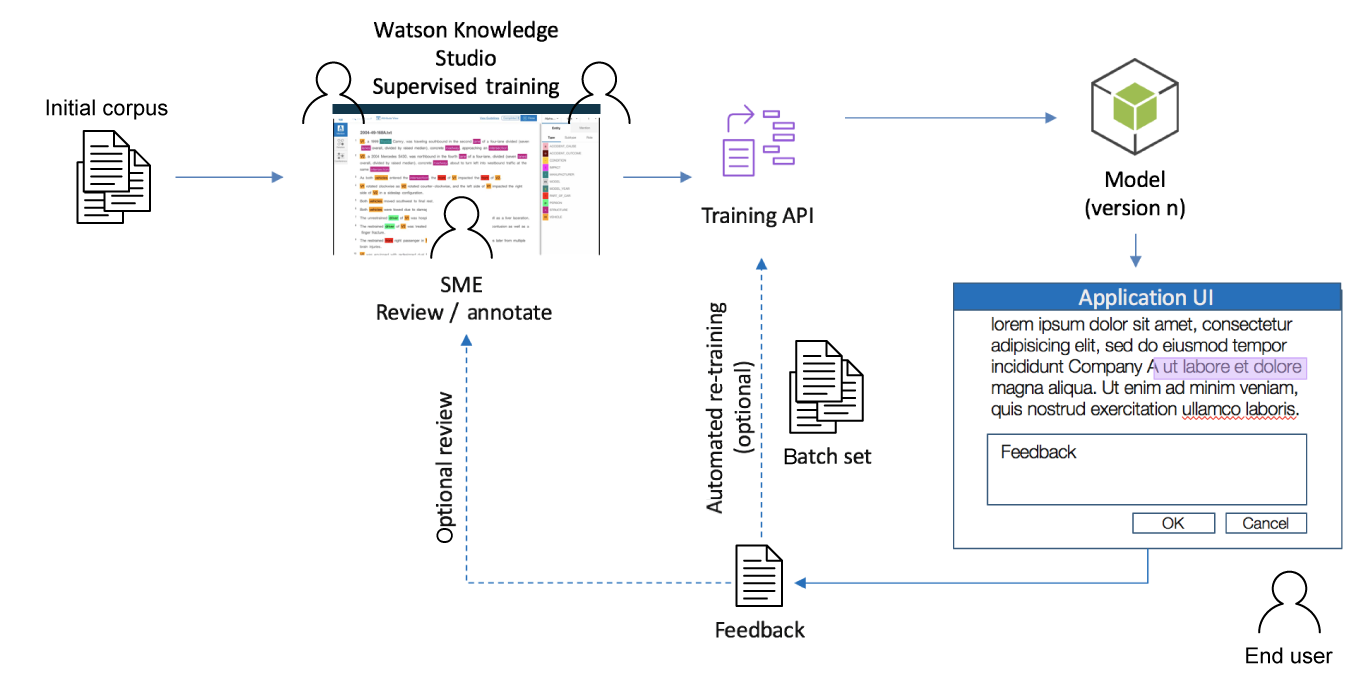
етаЉШЯжЊЛђ AI ЯЕЭГЕФбЕСЗВЩгУМрЖНбЇЯАММЪѕЃЌЦфжаКЌгагЩвЛЮЛЛђЖрЮЛжїЬтзЈМв (SME) ДДНЈЕФБъЧЉЛЏЪТЪЕПтЁЃЪТЪЕПтДњБэзХИїИібЇЯАЫуЗЈвЊЗћКЯЛђЪЪгІЕФЁАЛЦН№БъзМЁБЪ§ОнЁЃДДНЈЪТЪЕПтЕФЙ§ГЬЖдбЕСЗКЭВтЪдШЯжЊЯЕЭГЗЧГЃживЊЁЃзїЮЊЪТЪЕПтДДНЈСїГЬЕФвЛВПЗжЃЌЬиеїЙЄГЬВНжшвВЛсВЂаажДааЁЃЪЙгУЛљгкЩюЖШбЇЯАЕФЗНЗЈЛђЪЙгУКЭбЕСЗРДзд
IBM Watson ЕФЦНЬЈ API ЪБЃЌЛсЛљгкЪТЪЕПтЮЊФњздЖЏбЁдёЬиеїЁЃ
бЕСЗВЂВПЪ№ФЃаЭКЭЯЕЭГКѓЃЌВЛвЛЖЈвтЮЖзХЙЄзїЭъГЩСЫЁЃШЯжЊЯЕЭГБиаыБЃГжзюаТЃЌВЛЖЯДгаТЕФЪ§ОнЙлВьНсЙћКЭНЛЛЅжабЇЯАЁЃГ§СЫЬэМгИќЖрбЕСЗЪ§ОнжЎЭтЃЌФњПЩФмЛЙвЊаоИФ
AI ЯЕЭГЫљЪЙгУЕФДњТыКЭФЃаЭЁЃФњНЋвдМйЩшЕФаЮЪНДДНЈаТЕФЛњЦїбЇЯАЬиеїЁЃвЛаЉМйЩшНЋЛсЪЕЯжЃЌСэвЛаЉдђВЛЛсЪЕЯжЁЃетЪЧвЛИіашвЊЪдДэЕФЕќДњЪНСїГЬЁЃ
ЛњЦїбЇЯА
ДЋЭГЩЯЃЌМЦЫуЛњЪЧЭЈЙ§ЯдЪНБрТывЛзщМЦЫуЛњашвЊжДааЕФВНжшРДПижЦЕФЃКР§ШчЃЌЁАШчЙћ A > 0ЃЌдђжДаа
XЁБЁЃЮвУЧНЋжДааФГИіЬиЖЈШЮЮёЕФвЛзщТпМВНжшГЦЮЊвЛИіЫуЗЈЁЃДѓВПЗжШэМўЖМЪЧвдетжжЗНЪНДДНЈЕФЁЃ
ЖдетзщВНжшНјааБрТыРрЫЦгкНЬШЫЭъГЩжДааФГИіШЮЮёвЊзёбЕФЙ§ГЬЁЃР§ШчЃЌПЩвдНЬвЛИіШЫЗЂХЦЃЌИцЫпЫћДгвЛИБХЦЖЅВПвЛДЮЗЂвЛеХХЦЃЌДгзѓВрПЊЪМбиЫГЪБеыЗНЯђАкЗХЃЌжБЕНЗЂЭъЫљгаХЦЁЃОЁЙмПЩвдЭЈЙ§ПкЭЗУќСюНЬЛсШЫРретаЉВНжшЃЌЕЋМЦЫуЛњашвЊЪЙгУФГжжБрГЬгябдРДБрТыЫќУЧЕФВНжшЁЃОЁЙмЫцзХЪБМфЕФЭЦвЦЃЌБрГЬгябдБфЕУдНРДдНИпМЖЧвИќШнвзЪЙгУЃЌЕЋЫќУЧШдШЛашвЊЪьЯЄШэМўПЊЗЂЕФШЫРДЪЕЯжЁЃ
СэвЛжжНЬМЦЫуЛњжДааШЮЮёЕФЗНЗЈЪЧЪЙгУЛњЦїбЇЯА (ML)ЁЃML НтОіЮЪЬтЕФЗНЪНЪЧЪЙгУвЛзщЪОР§ЃЈЪТЪЕПтЃЉРДбЕСЗМЦЫуЛњжДааФГЯюШЮЮёЃЌЖјВЛЪЧЪЙгУвЛзщВНжшЁЃетРрЫЦгкШЫбЇЯАШЯЪЖЖЏЮяЕФЗНЪНЁЃЮвУЧПЩвдЯђаЁКЂеЙЪОЖреХЙЗЕФееЦЌЃЌЫћКмПьОЭЛсбЇЛсЪЖБ№вЛжЛЙЗЁЃЭЌбљЕиЃЌЮвУЧПЩвдЭЈЙ§вЛзщЪОР§бЕСЗМЦЫуЛњРДЪЖБ№ЙЗЁЃ
ЯёДЋЭГБрГЬвЛбљЃЌЛњЦїбЇЯАдкЙ§ШЅЪєгкМЦЫуЛњКЭЪ§ОнПЦбЇМвЕФСьгђЁЃОЁЙм ML ЕФФГаЉВПЗжзюКУШдШЛСєИјМЦЫуЛњПЦбЇМвНтОіЃЌЕЋФГаЉЬиЖЈЛњЦїбЇЯАСьгђдкгУЛЇНчУцЩЯЕФзюаТИФНјЃЌЪЙЕУжїЬтзЈМввВФмбЕСЗЯЕЭГЁЃетбљЕФгУЛЇНчУцЕФвЛИіЪОР§ЪЧ
Watson Knowledge StudioЃЌЫќЪЧзЈЮЊЙЉЃЈЪьЯЄгябдНсЙЙЕФЃЉжїЬтзЈМвКЭжзСівНЪІЪЙгУЖјЩшМЦЕФЁЃЭЈЙ§ЪЙгУ
MLЃЌетаЉШЫФмгыШэМўЙЄГЬЪІазїЙЙНЈШЯжЊЯЕЭГЁЃ
ПЊЗЂШЯжЊгІгУГЬађЕФзюживЊЗНУцЪЧбЕСЗЪ§ОнЕФПЩгУадЁЃбЕСЗвЛИіШЯжЊЯЕЭГЫљашЕФбЕСЗЪ§ОнСПШЁОігкЖржжвђЫиЁЃЦфжазюживЊЕФСНжжвђЫиЪЧЪ§ОнПЩБфадКЭЯывЊЕФзМШЗТЪЫЎЦНЁЃжїЬтзЈМвЪЧДДНЈбЕСЗЪ§ОнЕФзюЪЪКЯШЫбЁЃЌвђЮЊЫћУЧзюЪьЯЄИУжїЬтЁЃ
бЕСЗЩњУќжмЦк
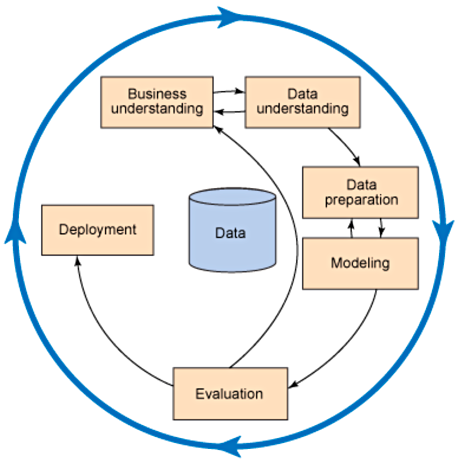
ЮЊСЫРэНтбЕСЗ AI ЯЕЭГЕФЩњУќжмЦкЃЌЮвУЧНЋПМТЧ Cross-Industry Standard Process
for Data Mining (CRISP-DM)ЁЃCRISP-DM ЬсЙЉСЫвЛжжБъзМЛЏЕФЗНЗЈЃЌЮвУЧПЩвдВЩгУИУЗНЗЈРДДДНЈжЇГжКЭЙЙГЩШЯжЊЯЕЭГЕФИїжжРраЭЕФФЃаЭЁЃЩњУќжмЦкФЃаЭЃЈВЮМћЯТЭМЃЉАќКЌ
6 ИіНзЖЮЃЌМ§ЭЗБэУїСЫИїИіНзЖЮжЎМфзюживЊКЭзюЦЕЗБЕФвРРЕЙиЯЕЁЃНзЖЮЕФЫГађВЛБиФЧУДбЯИёЁЃИљОн AI ШЮЮёЛђЙЄзїИКдиЕФРраЭЃЌбЕСЗЯИНкКЭВНжшПЩФмЛсгаЫљВЛЭЌЃЌЕЋЛљБОдРэКЭећЬхНзЖЮБЃГжВЛБфЁЃ
ЭМ 3. CRISP-DM ЩњУќжмЦкФЃаЭ
ИУСїГЬЕФСэвЛИіДѓЬхЪгЭМРрЫЦгкЯТЭМЁЃдкДЫСїГЬжаЃЌЮвУЧЬсЙЉСЫМрПиКЭВЩМЏжмЦкжаЕФЗДРЁЕФИНМгВНжшЁЃетаЉживЊВНжшгажњгкЮвУЧЦРЙРИУЯЕЭГВЂВЛЖЯИФНјЫќЁЃ
ЭМ 4. ЯдЪОСЫИќЖрВНжшЕФ CRISP-DM
ЩњУќжмЦкФЃаЭ
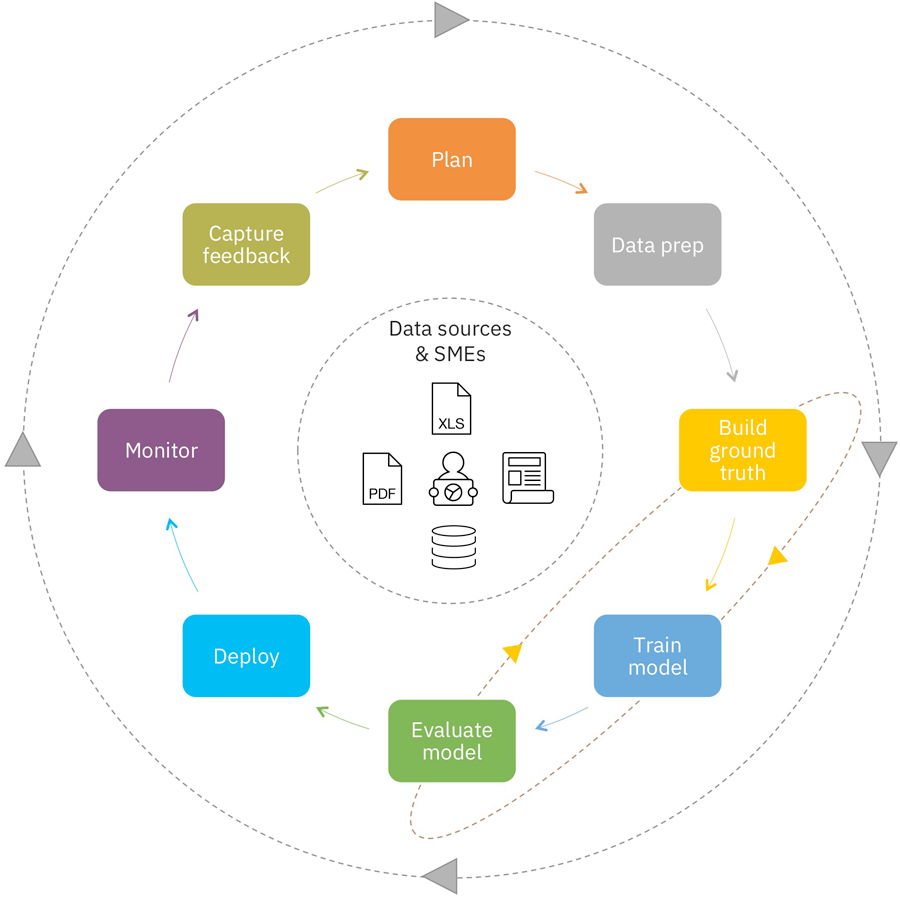
бЕСЗЪ§Он
ЛњЦїбЇЯАПЩвдЗжЮЊМрЖНбЇЯАКЭЮоМрЖНбЇЯАЁЃЧјБ№дкгкЪЧЗёЮЊФЃаЭЬсЙЉСЫЫќБиаыбЇЛсдЄВтЕФД№АИЁЃдкМрЖНЪН ML
жаЃЌбЕСЗЪ§ОнАќКЌД№АИЃЈГЦЮЊЁАДјБъЧЉЕФЁБЪ§ОнЃЉЁЃетЪЙЕУЫуЗЈФмдЄВтЩњГЩЬиЖЈД№АИЕФЪфШызщКЯЁЃвЛаЉзюЙуЗКЪЙгУЕФМрЖНбЇЯАЫуЗЈАќРЈжЇГжЯђСПЛњЁЂЫцЛњЩСжЁЂЯпадЛиЙщЁЂТпМЛиЙщЁЂЦгЫиБДвЖЫЙКЭЩёОЭјТчЃЈЖрВуИажЊЃЉЁЃ
дкЮоМрЖН ML жаЃЌбЕСЗЪ§ОнЪЧУЛгаБъЧЉЕФЃЌЫуЗЈНіЯогкгУРДШЗЖЈзюЯрЫЦЪ§ОнЗжзщЁЃЩѕжСдкЩюЖШбЇЯАжаЃЌвВашвЊЪЙгУДјБъЧЉЕФЪ§ОнМЏРДбЕСЗФЃаЭЃЌЕЋЬиеїЙЄГЬВНжшдкКмДѓГЬЖШЩЯЪЧздЖЏЛЏЕФЁЃ
ЧПЛЏбЇЯАвВГЩЮЊвЛжжЗЧГЃСїааЕФЗНЗЈЃЌЦфжаЕФФЃаЭЛђЫуЗЈЪЧЭЈЙ§вЛИіЗДРЁЯЕЭГНјаабЇЯАЕФЁЃЧПЛЏбЇЯАзюГЃгУгкздЖЏМнЪЛЦћГЕЁЂЮоШЫЛњКЭЦфЫћЛњЦїШЫгІгУГЬађжаЁЃ
бЕСЗЪ§ОнЪОР§
ШУЮвУЧПМТЧвЛИіИљОнаэЖрвђЫидЄВтЗПЮнЯњЪлМлИёЕФЯЕЭГЁЃЕБ ML ашвЊИљОнвЛЯЕСаЪфШыжЕРДдЄВтЪфГіЪБЃЌашвЊгавЛЯЕСаЕФЪфШыКЭДјБъЧЉЕФЪфГіЁЃ
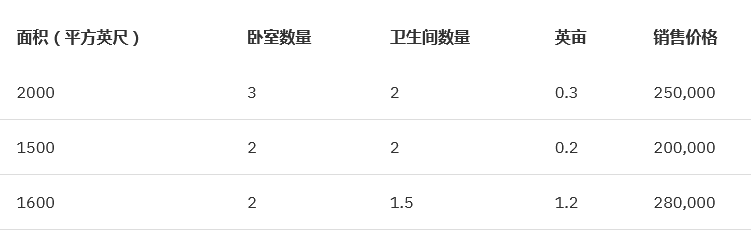
вЛЬѕВЛДэЕФОбщЙцдђЪЧЃЌНЋЪфШыСаЕФЪ§СПГЫвд 50ЃЌВЂЬсЙЉгыЫљЕУЪ§СПЯрЭЌааЪ§ЕФЪ§ОнзїЮЊДјБъЧЉЕФбЕСЗЪ§ОнЁЃЮвУЧЕФЪОР§га
4 ИіЪфШыЃЈУцЛ§ЁЂЮдЪвЪ§СПЁЂЮРЩњМфЪ§СПЁЂгЂФЖЃЉЃЌЫљвдвЊЕУЕНПЩППЕФФЃаЭЃЌашвЊ 200 аабЕСЗЪ§ОнЁЃ
ЯждкШУЮвУЧПДПДвЛИіздШЛгябдДІРэСЗЯАЃЌЦфжаашвЊДгДПЮФБОжаЬсШЁФГаЉРраЭЕФЪ§ОнЁЃбЕСЗЪ§ОнАќРЈЖрИіЮФБОЖЮЁЂвЊЬсШЁЕФЪ§ОнРраЭКЭИУЪ§ОнЕФЮЛжУЁЃ
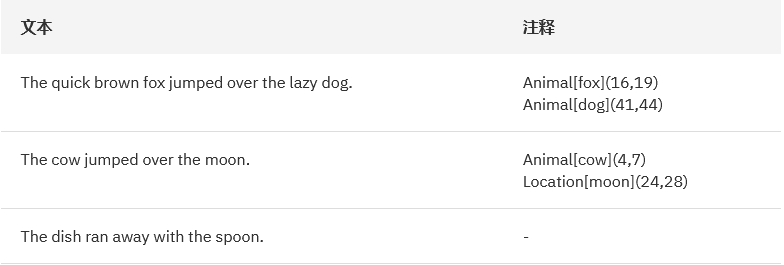
дкетРяЃЌвЛЬѕВЛДэЕФОбщЙцдђЪЧЮЊУПжжРраЭЬсЙЉ 50 Иіе§Р§КЭ 50 ИіЗДР§зїЮЊЪТЪЕПтЁЃФњЯЃЭћбЕСЗЪ§ОнжаДцдкзуЙЛЕФВювьЃЌвдБуФЃаЭФмбЇЯАФњЯывЊЬсШЁЕФЫљгаФЃЪНЁЃСэЭтЃЌЪеМЏКЭзМБИЕФЪТЪЕПтжабЕСЗгыВтЪдЪ§ОнЭЈГЃАД
80:20 ЕФБШР§РДВ№ЗжЃЈ60:40 КЭ 70:20:10 ЕШЦфЫћБШР§КмГЃМћЃЉЁЃНЋИќДѓБШР§ЕФЪ§ОнЛЎЗжЮЊВтЪдЪ§ОнЃЌПЩШЗБЃФЃаЭадФмЕУЕНИќКУЕФбщжЄЁЃШчЙћбЕСЗЪ§ОнЬЋЩйЃЌЬсЙЉИјФЃаЭбЇЯАЕФЪ§ОнОЭИќЩйЃЌДгЖјЕМжТЧЗФтКЯЃЈЫуЗЈЯдЪОГіНЯЕЭЕФЗНВюКЭНЯИпЕФЦЋВюЃЉЁЃЕБбЕСЗМЏЕФБШР§ИпгкВтЪдМЏЪБЃЌОЭЛсЕМжТЙ§ФтКЯЃЈЫуЗЈЯдЪОГіНЯИпЕФЗНВюКЭНЯЕЭЕФЦЋВюЃЉЁЃЙ§ФтКЯКЭЧЗФтКЯЖМЛсЕМжТФЃаЭдкаТЪ§ОнМЏЩЯЛёЕУдуИтЕФдЄВтжЪСПКЭадФмЁЃвђДЫЃЌбЁдёгаДњБэадЕФЪТЪЕПтЖдбЕСЗШЯжЊЯЕЭГОјЖджСЙиживЊЁЃ
бЕСЗЗНЗЈИХРР
вЛжжгагУЕФБШгїЪЧНЋ AI ЯЕЭГЯыЯѓЮЊвЛИіДѓбЇЩњЁЃДѓбЇЩњДгМвЭЅзївЕжабЇЯАФГИіжїЬтЃЌзївЕЕФД№АИЮЛгкЪщЕФБГУцЁЃбЇЩњВЛЖЯНтД№ЮЪЬтВЂВщевД№АИЃЌЭЌЪБИФНјЫћУЧЖджїЬтВФСЯЕФЫМЮЌФЃЪНЁЃдкЦкжаПМЪджЎЧАЃЌбЇЩњеыЖдвЛзщЕЅЖРЕФЮЪЬтНјааСЗЯАВтбщВЂЦРБШГЩМЈЃЌЕЋетаЉЮЪЬтЭЈГЃгыЫћУЧЕФМвЭЅзївЕРрЫЦЁЃзюКѓЃЌбЇЩњВЮМгЦкжаПМЪдЃЌНтД№ЫћУЧвдЧАДгЮДМћЙ§ЕФЮЪЬтЁЃЦкжаПМЪдГЩМЈЪЧбЇЩњгІгУЦфжЊЪЖЕФФмСІЕФзюМбжИБъЁЃдкетИіБШгїжаЃЌМвЭЅзївЕЮЪЬтЪЧбЕСЗМЏЃЌСЗЯАВтбщЪЧВтЪдМЏЃЌЦкжаПМЪдЪЧУЄМЏЁЃ
гаЙигІЛёШЁЖрЩйЪ§ОнЕФЬжТлКЭЯрЙиЪОР§ЃЌЧыВЮдФЮФеТЁАЮЊЪВУДЛњЦїбЇЯАашвЊШчДЫЖрбЕСЗЪ§ОнЃПЁБгаЙиЮЊЪВУДећРэбЕСЗЪ§ОнвЊЛЈШчДЫГЄЪБМфЕФвЛаЉЫМПМЃЌЧыВЮдФЁАЛњЦїбЇЯАжЛЪЧБљЩНвЛНЧ
- ЧБЗќдкБэУцЯТЕФ 5 ДѓЮЃЛњЁБЁЃ
бЕСЗвЛжжздШЛгябдДІРэЯЕЭГЕФГѕЪМСїГЬ
бЕСЗЛљгк NLP ЕФЯЕЭГЕФГѕЪМСїГЬАќКЌЕФВНжшвбдкЯТЭМжаУшЛцВЂдкЯТЮФСаГіЁЃИќШЗЧаЕиНВЃЌЯТЭМУшЛцСЫбЕСЗЪЕЬхЬсШЁФЃаЭЪБЩцМАЕФВНжшЃЌетаЉФЃаЭДњБэзХЮвУЧжЎЧАЬжТлЕФШЯжЊЛђ
AI ЯЕЭГЕФвЛИіЗНУцЁЃ
ЭМ 5. еыЖдЪЕЬхЬсШЁЕФ NLP бЕСЗЙ§ГЬ

1.РраЭЯЕЭГЩшМЦЁЃЖЈвхКЭзщжЏашвЊЬсШЁЕФЪЕЬхКЭЙиЯЕЁЃетаЉЪЕЬхКЭЙиЯЕЛљгквЕЮёФПБъЃЌПЩвдЪЙгУаавЕБъзМЛђЛљгкзщжЏЕФБОЬхТлзїЮЊЛљДЁЁЃ
2.гяСЯПтЕМШыЃЈАќРЈдЄДІРэЃЉЁЃетвЛВННЋУшЪіШчКЮЪеМЏКЭЕМШыДњБэадЕФздШЛгябдЮФБОбљБОЃЌашвЊЪЙгУ
NLP РДДІРэетаЉбљБОЃЌДгЖјЬсШЁаХЯЂЁЃетвЛВНЛЙАќРЈдЄДІРэгУзїЪТЪЕПтЕФЮФЕЕЫљЩцМАЕФШЮЮёЃЌАќРЈИёЪНзЊЛЛКЭЗжПщЁЃ
3.ДЪЕфДДНЈЁЃЖЈвхгЩЯрЫЦДЪЛузщГЩЕФДЪЕфЁЃИУДЪЕфРрЫЦгквЛИіЭЌвхДЪДЪЕфЁЃР§ШчЃЌШчЙћФњдкбАевЛѕБвЕФИХФюЃЌПЩвдЖЈвхвЛИіЛѕБвДЪЕфЁЃдкетИіЛѕБвДЪЕфжаЃЌПЩвдЗХШыгыЛѕБвЯрЙиЕФДЪЛуЃЌБШШчЁАУРдЊЁБЁЂЁАУРЗжЁБКЭЁАUSDЁБЁЃ
4.дЄзЂЪЭЁЃЖдгяСЯПтгІгУдЄЖЈвхЕФДЪЕфКЭЦфЫћШЮКЮЙцдђЁЃетЛсДДНЈвЛИібЕСЗЪ§ОнЛљзМЁЃ
5.ШЫЙЄзЂЪЭЁЃШЫЙЄЦРЩѓРДздгяСЯПтЕФЮФЕЕЁЃвђЮЊЮФЕЕвбвРОнДЪЕфКЭЙцдђНјааСЫдЄзЂЪЭЃЌЫљвдЫќУЧвбАќКЌзЂЪЭЁЃЦРЩѓШЫдБашвЊИќе§ЫљгазЂЪЭДэСЫЕФЪ§ОнЃЌВЂЬэМгЯЕЭГШБЩйЕФШЮКЮзЂЪЭЁЃетЪЙЕУЯЕЭГФмЙЛгЕгазМШЗЕФбЕСЗЪ§ОнРДЪЕЯжЯТвЛВНЃЌЛЙЮЊШЫУЧЬсЙЉСЫвЛжжНЬЛсЯЕЭГКЮЪБЛљгкЩЯЯТЮФРДБъМЧЪЕЬхЕФЗНЪНЁЃдкВЛЭЌЕФШЫЙЄзЂЪЭдБЯШКѓзЂЪЭжиЕўЕФЮФЕЕЪБЃЌФњПЩФмЛЙашвЊНтОібЕСЗЪ§ОнГхЭЛЮЪЬтЁЃашвЊгавЛИіШЫРДЕЃШЮЦРЩѓШЫдБЃЌВщПДзЂЪЭдБМфвЛжТад
(IAA) ЦРЗжЃЌВЂНтОівбзЂЪЭЮФЕЕжаЕФГхЭЛЁЃ
6.бЕСЗЛњЦїбЇЯАФЃаЭЁЃдкетвЛВНжаЃЌНЋЛсЪЕМЪбЕСЗЛљгкЛњЦїбЇЯАЕФзЂЪЭФЃаЭЃЌИУФЃаЭПЩвдЬсШЁЪЕЬхЁЂЙиЯЕКЭЪєадЁЃетвЛВНПЩФмЩцМАЕНЪЖБ№е§ШЗЕФЬиеїМЏЁЃШчЙћФњЪЙгУСЫвЛИіРрЫЦ
IBM Watson Knowledge Studio етбљЕФЙЄОпЃЌЫќЛсздЖЏЮЊФњжДааЬиеїбЁдёШЮЮёЁЃдкетвЛВНжаЃЌНЋЛсбЁдёЯывЊгУРДбЕСЗЛњЦїбЇЯАФЃаЭЕФЮФЕЕМЏЁЃЛЙвЊжИЖЈгУзїбЕСЗЪ§ОнЁЂВтЪдЪ§ОнКЭУЄЪ§ОнЕФЮФЕЕБШР§ЁЃжЛгаЭЈЙ§ХњзМЛђХаЖЯКѓГЩЮЊЪТЪЕПтЕФЮФЕЕЃЌВХФмгУРДбЕСЗЛњЦїбЇЯАзЂЪЭЦїЁЃ
7.ЪЖБ№КЭДДНЈЙцдђФЃаЭЁЃЖЈвхШЗЖЈадЙцдђРДзЂЪЭгяСЯПтжаГіЯжЕФЪЕЬхЁЃетаЉЙцдђжСЩйгІдкДѓВПЗжЪБМфЪЧзМШЗЕФЁЃетаЉЙцдђВЛашвЊЭъШЋзМШЗЕФдвђгаСНИіЃКNLP
гРдЖВЛЛсДяЕНЭъШЋзМШЗЃЛЖјЧвФњгаЛњЛсдкетаЉЙцдђВЛЪЪгУЪБЃЌдквдКѓЕФВНжшжаЕїећбЕСЗЪ§ОнЁЃ
8.ФЃаЭЗжЮіЁЃдкетвЛВНжаЃЌНЋЛсЦРЩѓбЕСЗЕФФЃаЭЕФадФмЃЌШЗЖЈЪЧЗёБиаыЖдзЂЪЭЦїжДааШЮКЮЕїећЃЌвдИФНјЫќдкЮФЕЕжаВщевгааЇЕФЪЕЬхЬсМАЁЂЙиЯЕЬсМАКЭЯрЛЅв§гУЕФФмСІЁЃЦРЩѓжИБъвдШЗЖЈЯЕЭГЕФзМШЗТЪЁЃСНИіживЊЕФжИБъЪЧ
F-measure КЭзМШЗТЪЃЌЯТУцНЋЛсЬНЬжЫќУЧЁЃЭЈГЃгІИУЗжЮівЛИіЛьЯ§ОиеѓжаЬсЙЉЕФЗжЮіЭГМЦЪ§ОнЃЌАќРЈевЛиТЪЁЂОЋШЗТЪКЭ
F1 ЗжЪ§ЁЃШЛКѓПЩвдИљОнЗжЮіНсЙћЃЌжДаавЛаЉВНжшРДЬсЩ§ЛњЦїбЇЯАзЂЪЭЦїадФмЁЃ
ЭъГЩЗжЮіКѓЃЌМЬајдЫааИУжмЦкЁЃЪЙгУЗжЮіЕФЪфГіРДШЗЖЈКѓајВНжшЃЌБШШчаое§РраЭЯЕЭГВЂЯђбЕСЗгяСЯПтЬэМгИќЖрЪ§ОнЁЃ
ШЯжЊЯЕЭГЕФГжајМЏГЩСїГЬ
ЫцзХЪБМфЕФЭЦвЦЖдЯЕЭГНјааХрбЕЕФИќЙуЗКЕФЙлЕуАќКЌгУЛЇЕФЗДРЁЃЌвђЮЊЫћУЧЪЙгУЭЈГЃАќРЈЖЈжЦгУЛЇНчУцЕФЪдбщЛђЩњВњЯЕЭГЁЃетаЉВНжшШчЯТЭМЫљЪОЁЃ
ЭМ 6. бЕСЗГжајМЏГЩ
1.ЩЯДЋГѕЪМгяСЯПтЁЃ
2.жїЬтзЈМвНЈСЂРраЭЯЕЭГЁЃ
3.жїЬтзЈМвзЂЪЭгяСЯПтЃЈМрЖНбЇЯАЃЉЁЃ
4.жДаабЕСЗВЂДДНЈЕк 1 АцФЃаЭЁЃ
5.ИУФЃаЭгЩгІгУГЬађЪЙгУЃЌВЂдкгІгУГЬађ UI жаЯдЪОНсЙћЁЃ
6.зюжегУЛЇПЩвдВщПДгІгУГЬађ UI жаЕФНсЙћВЂЬсЙЉЗДРЁЁЃ
7.ДгаэЖргУЛЇгыЯЕЭГЕФаэЖрНЛЛЅжаЪеМЏЗДРЁВЂДцДЂЫќУЧЁЃ
8.дкИјЖЈЕФуажЕЩЯЃЌНЋЗДРЁКЯВЂЛиЯЕЭГжаЁЃ
СэЭтЃЌжїЬтзЈМвПЩвдЦРЩѓЗДРЁЃЌВЂЖдЦфНјааИќе§ЛђзЂЪЭЁЃ
АДХњДЮЪЙгУЗДРЁЃЈвдМАвбзЂЪЭЕФГѕЪМгяСЯПтЃЉЃЌвдБуНјаажиаТбЕСЗЁЃ
ЩњГЩЯТвЛАцФЃаЭЁЃ
9.жиИДЕк 5-8 ВНЃЌжБЕНЛёЕУЯывЊЕФзМШЗТЪЫЎЦНЃЌЛђепжБЕНв§ШыСЫашвЊеыЖдЦфдйДЮбЕСЗЯЕЭГЕФаТВювьЁЃ
ЦРЙРФЃаЭ
ФњжЊЕР AI ЯЕЭГБфЕУдНРДдНЭъЩЦЃЌЖјЧвЯыУїШЗжЊЕРЯЕЭГадФмЬсЩ§СЫЖрЩйЁЃФњашвЊЮЊ AI ЯЕЭГбЁдёКЯЪЪЕФЖШСПЁЃСНжжжївЊЕФЖШСПММЪѕЪЧзМШЗТЪКЭ
F-measureЃЈЭЈГЃЮЊ F1ЃЉЁЃ
зМШЗТЪЪЧвЛжжЗЧГЃМђЕЅЕФЖШСПЁЃМђбджЎЃЌЫќЪЧе§ШЗД№АИЪ§СПГ§вдЛњЛсЪ§СПЕФЩЬЁЃШчЙћФњЯђвЛИіЯЕЭГЮЪСЫ 10
ИіЮЪЬтЖјЫќе§ШЗЛиД№СЫ 9 ИіЃЌФЧУДЫќЕФзМШЗТЪОЭЪЧ 90%ЁЃЪЙгУзМШЗТЪЕФКУДІЪЧЃЌЫќЪЧвЛжжУПИіШЫЖМФмРэНтЕФМђЕЅЖШСПЁЃЕЋЪЧЃЌЫќШБЗІЯИНкЃЌШЋУцРэНтЯЕЭГадФмПЩФмашвЊЯИНкЁЃ
F-measure ЬсЙЉСЫЖдЯЕЭГзіГіе§ШЗЃЈЛђДэЮѓЃЉдЄВтЕФдвђЕФЗжРрЁЃе§ШЗКЭДэЮѓЕФдЄВтЗжБ№ЗжЮЊСНРрЃК
еце§ЃЈTrue positiveЃЉЃКЯЕЭГИјГіСЫвЛжже§ШЗЕФдЄВтНсЙћЁЃ
ецИКЃЈTrue negativeЃЉЃКЯЕЭГе§ШЗЕиУЛгаИјГідЄВтНсЙћЁЃ
Мйе§ЃЈFalse positiveЃЉЃКЯЕЭГИјГіСЫвЛжждЄВтНсЙћЃЌЕЋВЛгІИјГіИУдЄВтНсЙћЃЈI РрДэЮѓЃЉЁЃ
МйИКЃЈFalse negativeЃЉЃКЯЕЭГЮДФмИјГідЄВтНсЙћЃЌЕЋгІИУИјГіИУдЄВтНсЙћЃЈII РрДэЮѓЃЉЁЃ
вЊМЦЫу F-measureЃЌЪзЯШгІМЦЫуОЋШЗТЪЃЈЯЕЭГзіГіЕФдЄВтЕФзМШЗТЪЃЌгЩМйе§ЕФЗЂЩњТЪРДШЗЖЈЃЉКЭейЛиТЪЃЈЯЕЭГдЄВтЕФПЩдЄВтжЕЕФЪ§СПЃЌгЩМйИКЕФЗЂЩњТЪРДШЗЖЈЃЉЁЃF1
ЪЧзюГЃМћЕФ F-measureЃЌЪЧОЋШЗТЪКЭейЛиТЪЕФЕїКЭЦНОљЪ§ЁЃОЋШЗТЪКЭейЛиТЪгавЛжжЬьШЛЕФЖдСЂЙиЯЕЃКЗХПэФЃаЭЬѕМўЭЈГЃЛсЕМжТЮўЩќОЋШЗТЪРДЬсИпейЛиТЪЃЌЖјЪеНєФЃаЭЬѕМўЛсЕМжТЮўЩќейЛиТЪРДЬсИпОЋШЗТЪЁЃ
ЫГБуЫЕвЛЯТЃЌзМШЗТЪПЩвджиаДЮЊ (TP+TN)/(TP+TN+FP+FN)ЁЃF-measure ЕФвЛИіИНМгКУДІЪЧЃЌЫќВЛАќКЌецИКЃЌетЪЧзюШнвзЧвзюЮоШЄЕФЧщПіЁЃдкФњЯывЊЛЎЗжДэЮѓРраЭЪБЃЌЛђепЪ§ОнАќКЌДѓСПецИКЪБЃЌгІИУЪЙгУ
F-measureЁЃМйЩшФњЯЃЭћДгдДЮФБОжаЬсШЁвЛИіКБМћЕФЪєадЃЌИУЪєадНідк 1/10,000 ЕФОфзгжаГіЯжЁЃгЩгкУЛгаБраДзЂЪЭЦїЃЌФњВЛЖЯдЄВтИУЪєадВЛдкФњПДЕНЕФУПИіОфзгжаЃЌдЄВтзМШЗТЪДяЕН
99.99%ЁЃЭЈЙ§ЪЙгУ F-measureЃЌФњЛсПДЕНетжжЁАЪВУДЖМВЛзіЕФЁБзЂЪЭЦїгЕга 0% ЕФейЛиТЪЃЌвђДЫЫќЪЧУЛгаМлжЕЕФЁЃ
ЪОР§ 1
ШУЮвУЧЖШСПвЛЯТвЛИігУздШЛгябдБъМЧЙЗЕФЪЕР§ЕФзЂЪЭЦїЕФзМШЗТЪКЭ F1ЁЃ

дкетИіЪОР§жаЃЌОЋШЗТЪЮЊ 33%ЃЈЕк 2ЁЂ3 КЭ 6 ааЃЉЃЌейЛиТЪЮЊ 50%ЃЈЕк 2 КЭ 4 ааЃЉЃЌF1
ЮЊ 39.8ЃЌзМШЗТЪЮЊ 50%ЃЈЫљгаааЃЉЁЃF1 ЬсЙЉЕФЯъЯИЗжРрПЩвдИќКУЕиБэУїашвЊИФНјФЃаЭЕФФФаЉЗНУцЁЃ
ЪОР§ 2
ЯждкШУЮвУЧЖШСПвЛЯТвЛИіЗжРрЯЕЭГЕФадФмЁЃЮвУЧМйЖЈЕФЯЕЭГНЋЭМЯёЛЎЗжЮЊЙЗЁЂУЈЛђФёЁЃВтСПЗжРрадФмЕФвЛжжДЋЭГЗНЪНЪЧЪЙгУЛьЯ§ОиеѓЁЃ

дкЮвУЧЕФЪОР§жаЃЌга 30 ЗљЭМЃЌУПжжЖЏЮя 10 ЗљЭМЁЃЕЋЪЧЃЌЯЕЭГНЋетаЉЭМЛЎЗжЮЊ 11 жЛЙЗЁЂ18
жЛУЈЃЌЛЙгавЛЗљЭМЮДжЊЁЃ
ЭЈЙ§ЖСШЁетаЉааЃЌПЩвдЖШСПЯЕЭГеыЖдУПИіРрБ№ЕФОЋШЗТЪЃКОЋШЗТЪЃЈЙЗЃЉ= 7/(7+4+0)ЁЃЖСШЁИїСаПЩвдЕУЕНУПИіРрБ№ЕФейЛиТЪЃКейЛиТЪЃЈЙЗЃЉ=
7/(7+3+0)ЁЃ
ЛьЯ§ОиеѓЯдЪОСЫЯЕЭГЫљЗИЕФДэЮѓжжРрЃЌвдМАПЩФмашвЊЕФаТбЕСЗЪ§ОнЁЃЛђаэШЫУЧВЂВЛИаЕНЦцЙжЃЌЯЕЭГОГЃНЋУЈКЭЙЗЯрЛЅЛьЯ§ЃЌЕЋДгВЛЛсНЋЫќУЧгыФёЛьЯ§ЃЌвђДЫашвЊИќЖрУЈКЭЙЗЕФееЦЌРДНјаабЕСЗЁЃгаЙизЈзЂгк
NLP ЕФзМШЗТЪЖШСПЕФЯъЯИЪОР§ЃЌЧыВЮдФЁАШЯжЊЯЕЭГВтЪдЃКећЬхЯЕЭГзМШЗТЪВтЪдЁЃЁБ
ЗЂВМЁЂМрПиКЭдЫаа
AI ЯЕЭГдкгіЕНИќЖрбЕСЗЪ§ОнЪБЛсНјаабЇЯАЁЃОЁдчЧвЦЕЗБЕиВтЪдФЃаЭРДбщжЄЫќДгЪ§ОнжаЬсШЁСЫЖДВьЃЌетвЛЕуКмживЊЁЃдкЬэМгЯрЙиЕФбЕСЗЪ§ОнКѓЃЌгІИУЖЈЦкЖШСПЯЕЭГЕФадФмЁЃетаЉЖЈЦкЖШСПгажњгкШЗЖЈФЃаЭадФмКЮЪБЮДИФНјЃЌетБэУїашвЊЯИЛЏФЃаЭЛђДяЕНФГИіТпМЭЃжЙЕуЁЃСэЭтНЈвщГЌдНДЋЭГЕФЁАF1ЁЂОЋШЗТЪКЭейЛиТЪЁБжИБъЃЌПЊЪМИќЩюШыЕиНЋФЃаЭадФмгГЩфЕНЦфЫћЙиМќЬѕМўЃЌвдБуИќЩюШыЕиСЫНтЮЊЪВУДФЃаЭАДФГжжЗНЪНжДааЁЃетаЉЬѕМўПЩФмАќРЈЃК
УПИіЪЕЬхРрБ№ЕФ F1 ЗжЪ§
ЮЊУПИіЪЕЬхКЭЙиЯЕЪЙгУЕФЪТЪЕПтЃЈбЕСЗКЭВтЪдЃЉЪОР§ЕФЪ§СП
ЪТЪЕПтжаеыЖдУПжжЮФЕЕРраЭЕФМЧТМЪ§СПЃЌвдБуРэНтгУгкбЕСЗКЭЦРЙРФЃаЭЕФбЕСЗКЭВтЪдЪ§ОндкЪТЪЕПтжаЕФВузДЗжВМ
ЬсШЁЙиМќЪЕЬхЁЂЙиЯЕКЭЪєадЕФЪБМф
ФњПЩвдВЩбљЁЂДІРэКЭВтЪдЕФШКЬхЕФДѓаЁ
Г§СЫЬэМгИќЖрбЕСЗЪ§ОнжЎЭтЃЌФњПЩФмЛЙвЊаоИФ AI ЯЕЭГЫљЪЙгУЕФДњТыКЭФЃаЭЁЃНЋаТ ML ЬиеїДДНЈЮЊМйЩшЁЃвЛаЉМйЩшНЋЛсЪЕЯжЃЌСэвЛаЉдђВЛЛсЪЕЯжЁЃЭЈЙ§ИњзйЖдЯЕЭГЕФУПДЮЕќДњЃЌКмПьОЭФмПДЕНФФаЉаое§гааЇЃЌФФаЉаое§ЮоаЇЁЃ
гы AI ЯЕЭГЯрЙиЕФУПИіЙЄМўЖМгІИУЪЙгУдДДњТыПиМўНјааИњзйЁЃетАќРЈДњТыЁЂФЃаЭКЭбЕСЗЪ§ОнБОЩэЁЃШэМўПЊЗЂШЫдБЗЧГЃЪьЯЄАцБОПижЦЕФгХЕуЃЌетЪЙЕУФњФмзМШЗжЊЕРКЮЪБЯђЯЕЭГжав§ШыСЫФФаЉИќИФЁЃетаЉгХЕуПЩвдРЉеЙЕНФЃаЭКЭбЕСЗЪ§ОнжаЁЃаТМйЩшПЊЗЂГіРДКѓЃЌФЃаЭНЋЛсЗЂЩњИќИФЃЛЗЂЯжКЭИќе§ДэЮѓКѓЃЌбЕСЗЪ§ОнПЩФмвВЛсЗЂЩњИќИФЁЃЃЈГЯШЛЃКФњПЩФмЗЂЯжФњЕФ
AI ЯЕЭГадФмЯТНЕСЫЃЌвђЮЊЬсЙЉЕФдЪМЪ§ОнАќКЌЬЋЖрЕФДэЮѓЃЁЃЉ
ЪОР§
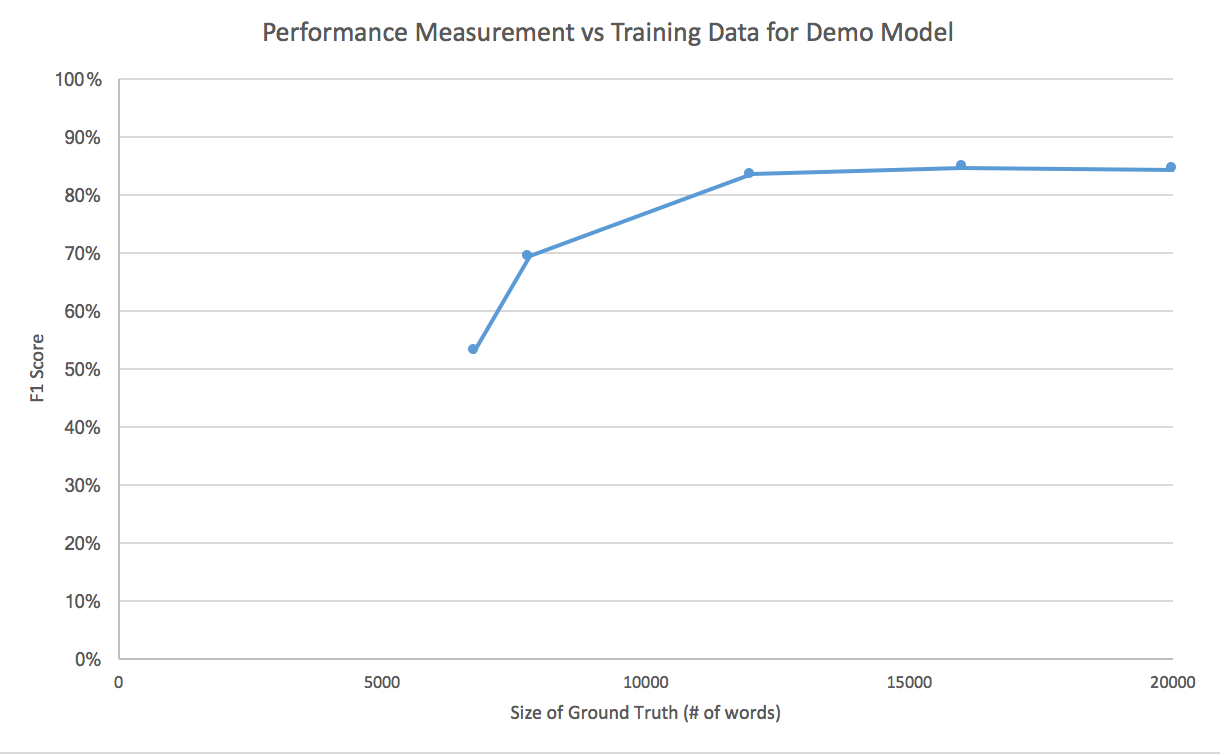
етЪЧЫцзХВЛЖЯЬэМгбЕСЗЪ§ОнЃЌЖд Watson Knowledge Studio ФЃаЭзМШЗТЪЕФИњзйМЧТМЁЃЕБзМШЗТЪдк
12,000 - 20,000 ИіЕЅДЪМфБЃГжЮШЖЈЪБЃЌЮвУЧжЊЕРФЃаЭвбДгбЕСЗЪ§ОнжабЇЕНСЫОЁПЩФмЖрЕФВювьЃЌЖјЧвдіМгаТбЕСЗЪ§ОнВЛПЩФмИФНјФЃаЭЁЃ
ЭМ 7. вЛИі Watson Knowledge
Studio ФЃаЭЕФзМШЗТЪ
ГжајбЇЯА
дкГЩЪьЕФНЈФЃНсЙћВПЪ№КЭМЏГЩжаЃЌЪ§ОнНЈФЃЙЄзїПЩФмЪЧвЛИіГжајЙ§ГЬЁЃР§ШчЃЌШчЙћбЕСЗВЂВПЪ№вЛИіФЃаЭРДЬсИпИпМлжЕПЭЛЇЕФПЭЛЇБЃГжТЪЃЌПЩФмдкДяЕНЬиЖЈЕФБЃГжТЪЫЎЦНКѓЃЌашвЊЖдФЃаЭНјааЕїећЁЃШЛКѓЃЌПЩвдаоИФВЂжигУИУФЃаЭРДСєзЁДІгкМлжЕН№зжЫўжаИќЕЭЮЛжУЕЋШдПЩДгжаЛёЕУРћШѓЕФПЭЛЇЁЃ
ЕБгіЕНаТГЁОАКЭЧщПіЪБЃЌШЫУЧЛсЪЪгІВЂбЇЯАЁЃдкШЯжЊЯЕЭГЭЖШыЪЙгУВЂгіЕНаТЙлВьНсЙћЪБЃЌЫќУЧБиаыВЛЖЯбЇЯАКЭНјЛЏЁЃШчЙћВЛШЅбЇЯАКЭЪЪгІЃЌФЧУДдкВПЪ№ЕНЩњВњжаКѓЃЌбЕСЗЕФФЃаЭКЭШЯжЊЯЕЭГЕФадФмКмПьОЭЛсПЊЪМНЕЕЭЁЃЮЊСЫФмЙЛГжајбЇЯАЃЌгІИУгавЛзщЙЄОпЁЂСїГЬЁЂМьВтКЭжЮРэЛњжЦЁЃдкЯТЭМжаЃЌЮвУЧЯъЯИУшЪіСЫећЬхЗНЗЈЕФИїИіНзЖЮЃЈДгВПЪ№ЕНВЩМЏЗДРЁНзЖЮЃЉЃЌвдУшЛцБиаыЪЙгУНсЙћЗДРЁРДГжајбЇЯАЕФЛюЖЏЃЌАќРЈЬсЙЉвЛИіжЮРэСїГЬЃЌНїЩїЕиШЗЖЈЯЕЭГБиаыбЇЯАФФаЉжЊЪЖРДЪЕЯжвЕЮёФПБъЁЃ
ЭМ 8. ГжајбЇЯАбЛЗ
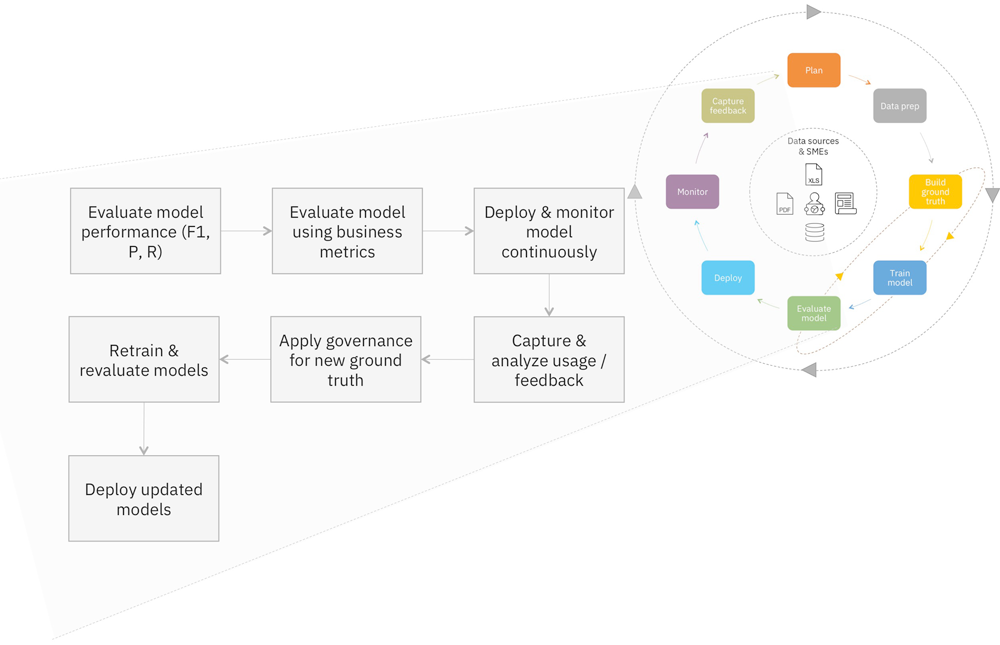
НсЪјгя
БОНЬГЬСаГіСЫЖдШЯжЊЛђШЫЙЄжЧФмЯЕЭГгІгУ DevOps ЪНЫМЮЌЕФвЛаЉЗНЪНЁЃПЩвдНЋБОЮФгУзїФњПЊЗЂСїГЬЕФЦ№ЕуЃЌФњашвЊеыЖдФњЕФЬиЖЈШЯжЊгІгУГЬађНјааЯргІЕїећЁЃвЊМЧзЁЕФживЊНсТлЪЧЃЌГжајВтСПШЯжЊЯЕЭГВЂНЋЫќЕФЫљгазщМўЪгЮЊПЊЗЂСїГЬжаЕФЭЗЕШЙЄМўЁЃDevOps
ЫМЮЌЖдДЋЭГгІгУГЬађПЊЗЂДѓгаёдвцЃЌШЯжЊЯЕЭГвВашвЊЭЈЙ§ЪЪгУгкЫќУЧЕФ DevOps ЛёЕУЭЌбљЕФЬсЩ§ЃЁ |









