| БрМЭЦМі: |
| БОЮФРДздгкзїепЛЦваЯі,DevOpsЃЈгЂЮФDevelopmentКЭOperationsЕФзщКЯЃЉЪЧвЛзщЙ§ГЬЁЂЗНЗЈгыЯЕЭГЕФЭГГЦЃЌгУгкДйНјПЊЗЂЃЈгІгУГЬађ/ШэМўЙЄГЬЃЉЁЂММЪѕдЫгЊКЭжЪСПБЃеЯЃЈQAЃЉВПУХжЎМфЕФЙЕЭЈЁЂазїгыећКЯЁЃ |
|
1. УцСйЕФЬєеН
НёФъЕФ2018GOPSЁЄЩюлкеОЩшСЫН№ШкКЭЭЈаХзЈГЁЁЃвђЮЊН№ШкКЭЭЈаХаавЕУцСйзХЛЅСЊЭјзюДѓЕФГхЛїЁЃгаСЫЮЂаХКЭQQЃЌЫЛЙЗЂЖЬаХЃПгаСЫжЇИЖБІКЭЮЂаХжЇИЖЃЌЫЛЙЫцЩэаЏДјвјааПЈЃПетаЉЪЧЛЅСЊЭјаавЕЖдН№ШкКЭЭЈаХаавЕДјРДЕФГхЛїЁЃДЋЭГаавЕКЭЛЅСЊЭјаавЕВюБ№ОоДѓЃЌЮвднЧвВЛЬИЬхжЦЩЯЁЂСїГЬЩЯЁЂЙмРэЩЯЁЂШЫдБЩЯЕФВюБ№ЃЌНёЬьЮвУЧЬИЬИITЩЯЕФВюОрЁЃ

ДЋЭГаавЕвдЁАНЛдПГзЁБФЃЪНЮЊжїЃЌГЇМвПЊЗЂЭъГЩКѓЃЌФУАќЙ§РДЯжГЁВПЪ№ЁЃдЫЮЌГЩБОИпЩаЧвВЛЫЕЃЌБЯОЙЛЈЕФЪЧЙњМвЕФЧЎЃЌзюТщЗГЕФЪЧаЇТЪКЭжЪСПЬиБ№ВюЁЃЖдУцЕФЛЅСЊЭјаавЕжївЊЪЧздбаздЮЌЃЌЫћУЧгУЕФЪЧDevOpsЬхЯЕЃЌИпаЇИпжЪЕФНЛИЖЃЌСщЛюЕигІЖдБфЛЏЁЃ
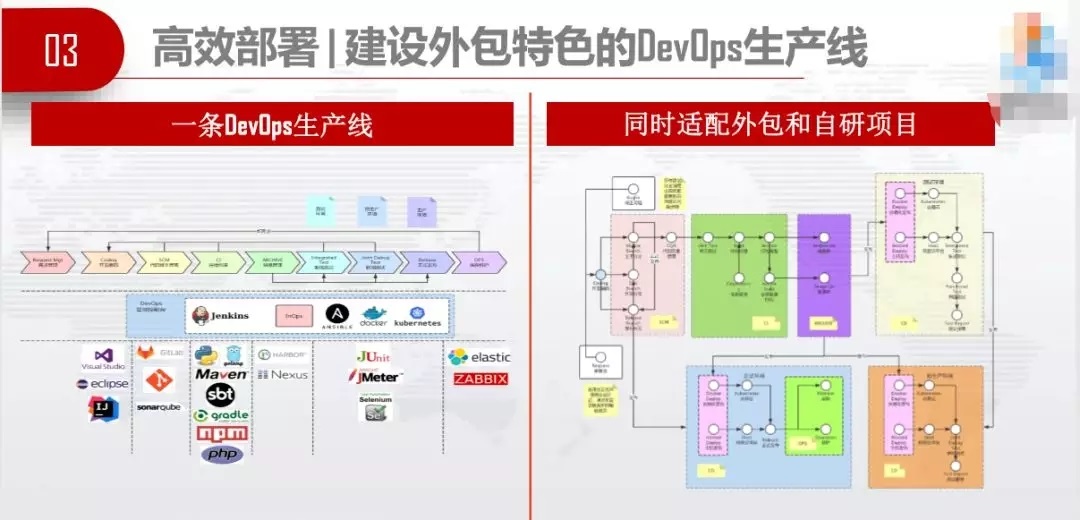
2. ЪЕМљDevOpsЕФЕРТЗбЁдё
ШчКЮбЇЯАDevOpsЬхЯЕЃЌгаВЛЭЌЕФбЁдёЁЃгааЉЙњЦѓЁЂДЋЭГаавЕбЁдёвРРЕЭтАќЃЌЯЃЭћЭЈЙ§ЭтАќДјЖЏЮвУЧзЊаЭЁЃетОЭЯёЁАЪфбЊЁБЃЌАбЭтВПаТЯЪбЊвКЪфШыЕНДЋЭГЦѓвЕРяЁЃЁАЪфбЊЁБКмКУЃЌПЩвдНтШМУМжЎМБЃЌЕЋЮвУЧВЛФмвЛжБвРРЕЫќЁЃ
здбаздЮЌЕФШЋУцзЊаЭЃЌЮвУЧГЦжЎЮЊЁАЛЛбЊЁБЃЌдЫгЊЩЬдкЭЦШЋУцITЛЏЁЂЪ§зжЛЏзЊаЭЃЌеавЛДѓХњМЦЫуЛњзЈвЕЕФаТдБЙЄЃЌзщжЏДѓСПЕФITХрбЕЃЌЯЃЭћПЩвдбЇЯАзджїбаЗЂЃЌздМКдЫЮЌећИіЭјТчЬхЯЕКЭITЬхЯЕЁЃетЪЧвЛИіКмКУЕФдИОАЃЌЕЋЭЌЪБЫќЪЧКмФбЪЕЯжЕФЁЃдкЪЕЯжЙ§ГЬжаЃЌПЩФмЛсУцСйКмЖрПВПРЁЃЫљвдЮвУЧбЁдёСЫХрг§ЛљвђЃЌГжајИФСМетЬѕЁАдьбЊЁБжЎТЗЁЃ
3. ММЪѕЕФЪЕМљ
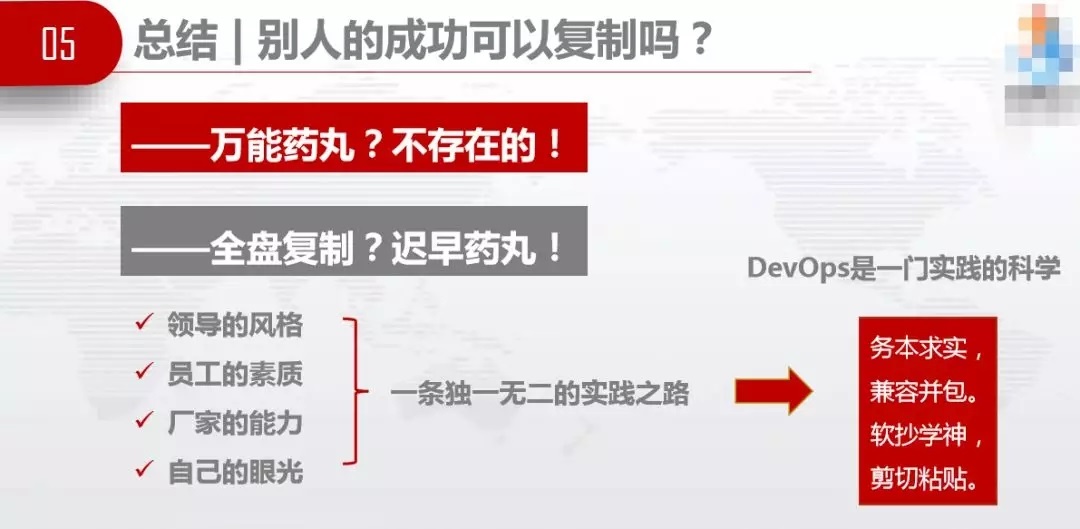
3.1 бЁдёЦеЪЪЁЂЭъБИЕФЬхЯЕРДЖдБъбЇЯА
Хрг§ЛљвђЃЌзмЕУгаЛљвђЃЌЛљвђДгКЮЖјРДЁЃУПИіЛЅСЊЭјаавЕЖМгаздМКЕФЬиадЃЌвВгаЦфГЩЙІжЎДІЃЌФбвдШЋХЬИДжЦЁЃЫљвдЮвУЧгІИУевЦеЪЪЭъБИЬхЯЕЃЌЮвЯђДѓМвЭЦМіСНИіБШНЯКУЕФЬхЯЕЃЌвЛЪЧИпаЇдЫЮЌЩчЧјЕФDevOpsЕРЗЈЪѕЦїЃЌЖўЪЧжаЙњаХЯЂЭЈаХбаОПдКЕФЁЖбаЗЂдЫЮЌвЛЬхЛЏФмСІГЩЪьЖШФЃаЭЁЗЁЃ
ЕРЗЈЪѕЦїЃЌжаЙњЗчЬиБ№ХЈЃЌЮвЮФЛЏЫЎЦНВЛИпЃЌВЛЬЋИвбЇЃЌЛЙЪЧРДбЇЙњБъАЩЁЃ
жаЙњаХЯЂЭЈаХбаОПдКDevOpsФЃаЭЃЌЕБжаАќРЈ42ИіЙ§ГЬЃЌФбвдШЋбЇЁЃБШШчУєНнПЊЗЂЙмРэЃЌДЋЭГаавЕжЎЧАвдЭтАќЮЊжїЃЌЭтАќФФгаУєНнПЊЗЂЃЌФуСЌДњТыЖМУЛгаЁЃ
ЁАдкЦПОБжЎЭтЕФШЮКЮЕиЗНзїГіЕФИФНјЖМЪЧМйЯѓЁБЁЊАЌРћ?ИпЕТРЬиЁЖФПБъЁЗ
3.2 бЁШЁСљДѓЙ§ГЬЃЌгХЯШНтОіЭДЕу
ЮвУЧашвЊДг42ИіЙ§ГЬжабЁШЁЧаШыЕуЃЌгУРДНтОіФПЧАЕФЦПОБКЭЭДЕуЁЃЙуЖЋвЦЖЏбЁдёСЫвдЯТСљИіЙ§ГЬзїЮЊЧаШыЕуЃЌ
вЛЪЧЙЪЪТгыШЮЮёХХЦкЃЌЙмРэашЧѓЕФЩцжкЦкЭћЃЛ
ЖўЪЧВПЪ№гыЗжВМФЃЪНЃЌЭДЕуЪЧИФНјАцБОЩЯЯпаЇТЪЃЛ
Ш§ЪЧгІгУМрПиЃЌЮЊСЫНтОіЙЪеЯЖЈЮЛТ§ЕФЭДЕуЃЛ
ЫФЪЧЪТМўЯьгІМАДІРэЃЌНтОіЕФЪЧЙЪеЯДІРэЕФЭДЕуЃЛ
ЮхЪЧИпПЩгУЙцЛЎЃЌЬсЩ§ЯЕЭГПЩППадЃЛ
СљЪЧЖШСПжИБъЃЌЖЈадЖЈСПЦРЙРDevOpsзЊаЭаЇЙћЃЌГжајгХЛЏЁЃ
3.3 бЁШЁСљДѓЙ§ГЬЃЌгХЯШНтОіЭДЕу
3.3.1 ЕквЛИіЙ§ГЬЁЊЁЊЙЪЪТгыШЮЮёХХЦк
ДЋЭГаавЕITЙмРэВПУХОГЃБЛгУЛЇВПУХЭЖЫпЃКАыФъЙ§ШЅСЫЃЌЮвЬсЕФашЧѓдѕУДЛЙУЛПЊЗЂЁЃГЇМвКмЭДПрЃЌИіИіЖМЪЧДѓвЏЃЌЫцЪБЫцЕиМгШћашЧѓЃЌИіИіЖМЫЕздМКЕФашЧѓзюНєМБЃЌЮвИвЕУзяЫЃПЮвУЧзїЮЊITЙмРэЕФНЧЩЋЃЌвВКмЮоФЮЃЌФъГѕЮЪДѓМвгаЩЖашЧѓЃЌИіИіВЛЬсЃЌФъжаИіИіЫЕМБЁЃБШЗНЫЕЃЌМЏЭХ2ЁЂ3дТЗнПЊЙЄзїЛсЃЌ1дТЗнСЂЯюЃЌСЂЯюЪБУЛашЧѓЃЌПЊЭъФъЖШЙЄзїЛсЬсГівЛЖбЕФашЧѓЁЃРЯАхКмРЇЛѓЃЌЕНЕзЪЧГЇМвВЛИјСІЛЙЪЧЮвУЧЙмРэЫЎЦНВюЃЌЮЊЪВУДДѓМвЖМВЛТњвтЁЃЮвУЧЕФвЉЪЧЙмРэКУИїЗНЦкЭћЁЃЮвЯШЩљУївЛЯТЃЌетИівЉВЂВЛФмЬсИпашЧѓНЛИЖЕФЫйЖШЃЌФЧИівЊЕШШЋХЬв§ШыDevOpsУєНнПЊЗЂЬхЯЕВХФмНтОіЁЃдкDevOpsЬхЯЕЛЙУЛТфЕижЎЧАЃЌЮвУЧЯШЙмКУИїЗНЦкЭћЃЌЯШШУгУЛЇКЭРЯАхВЛФЧУДЭДПрЃЌЮвУЧздМКвВВЛФЧУДЭДПрЃЌЯШЛКНтЭДПрСЫЃЌдйПМТЧКѓУцЕФИФНјЁЃ

ашЧѓЙмПиЗжГЩСНВПЗжЃЌвЛИіЪЧФъЖШзЪдДЕФЙмПиЃЌвВОЭЪЧжЦЖЈФъЖШАцБОЗЂВММЦЛЎЁЃЙиМќЕуЪЧЁАХХГЕДЮЃЌЗжГЕЦБЁБЁЃФъГѕЙЄзїЛсЛЙУЛПЊЃЌЮвУЧПЩвдИљОнЯюФПН№ЖюКЭШЫЬьЕЅМлЙРЫуЃЌЙРЫуШЋФъПЩгУЕФШЫСІзЪдДЃЌМйЩшга1.2ЭђШЫЃЌжЦЖЈШЋФъАцБОЕФЗжХфМЦЛЎЁЃгаЕуЯёСаГЕЪБПЬБэвЛбљЃЌашЧѓдкФФЬьНижЙЁЂФФЬьЪмРэЁЂФФЬьХХАцЁЂФФЬьЩЯЯпЁЃЗжХфИїАцБОЕФзЪдДЪ§СПЃЌИљОнШЋФъЯаУІЙцТЩАВХХИїИіАцБОЕФзЪдДЪ§СПЁЃ12ИідТРяЃЌВЂВЛЪЧУПИідТЖМЦНОљЗжХфЃЌФъЕзЬиБ№УІЃЌашЧѓЬиБ№ЖрЃЌЮвУЧвЊЮЊЕкШ§ЕкЫФМОЖШЖрАВХХЁЃЗжХфгУЛЇЕФзЪдДБШР§ЃЌВЛЪЧЦНОљЗжХфЃЌвЊПДЫЖдЯЕЭГвЊЧѓЬсЕУЖрЁЃШЅФъетИіВПУХЬсГі60%ЕФашЧѓЃЌРДФъЮвИјЫћУЧЗж60%ЕФзЪдДЃЌФъГѕЗжГЕЦБЃЌгУЭъГЕЦБжЛФмЕШзХЃЌвЊВЛОЭжЛФмЯђЦфЫћгаГЕЦБЕФШЫаЕїЁЃдЄСє10%ЕФЛњЖЏзЪдДЃЌНєёюКЯЯЕЭГЙІФмвЊЭГвЛЗЂГЕЪБМфЁЃ
ШеГЃашЧѓЕФЙмПиЃЌВЩгУСаГЕФЃЪНЃЌетИіИХФюдкИпаЇдЫЮЌЩчЧјЕФЙЋжкКХРяУцгаЬсЕНЃЌДѓМвПЩвдШЅПДПДЁЃСаГЕФЃЪНжиЕудкгкПЊСНЛсЁЂГіГЕаэПЩЁЂАДЪБГіГЕЁЃетИіашЧѓФмВЛФмзіЃЌЭЈЙ§ПЊЩшМЦЦРЩѓЛсРДШЗЖЈЃЌетИіашЧѓМБВЛМБЃЌЪВУДЪБКђзіЃЌЭЈЙ§гУЛЇашЧѓХХАцЛсРДШЗЖЈЁЃЮвУЧЙмРэгУЛЇЕФашЧѓЃЌЮоЗЧЪЧШУЫРДЖЈГЇМвЕФПЊЗЂзЪдДЃЌИјЫгУЁЃЫљвдЃЌНтОіЮЪЬтЕФИљБОЃЌЦфЪЕжЛашвЊАбШЈСІЛЙИјвЕжїОЭКУСЫЁЃзїЮЊITПЊЗЂЕФЙмРэВПУХЃЌЦОЪВУДФуЫЕСЫЫуЃЌвЛЖЈЪЧвЕжїЫЕСЫЫуЁЃвдКѓвЕжїОЭВЛЛсдйЫЕЃКИјФуЬсЕФашЧѓЖМЙ§СЫАыФъСЫЮЊЩЖЖМУЛзіЃЌвђЮЊвЕжїПЩвдздМКОіЖЈЃЌАбНєМБЕФашЧѓХХНјСНЛсЁЃ
ЙмКУЦкЭћЃЌНдДѓЛЖЯВЁЃДѓМвжЊЕРЗЂГЕЪБМфБэЃЌгУЛЇжЊЕРЫћгаЖрЩйзЪдДПЩвдЃЌАВХХЪБВЛЛсТвЬсЃЌВЛЛсКСЮоГЩБОЕФЬсашЧѓЃЌПЊЗЂепвВжЊЕРздМКвЊзіЪВУДЪТЧщЃЌВЛЛсЫљгаашЧѓЖМЪЧНєМБашЧѓЁЃ

3.3.2 ЕкЖўИіЙ§ГЬЁЊЁЊВПЪ№гыЗЂВМФЃЪН
ЃЈЯТЭМЃЉетЪЧЙуЖЋвЦЖЏЪЕМЪЕФЯЕЭГЙиЯЕЭМЃЌёюКЯЕУЗЧГЃНєЃЌAЯЕЭГЗЂВМЃЌBЁЂCЁЂDЕУСЊЕїЁЃвЛИіГЇМвАОвЙЃЌЦфЫћГЇМввЊИњзХАОвЙЁЃЮвУЧЩ§МЖЕБЬьЭэЩЯВХПЊЪМПчЯЕЭГЕФСЊЕїЃЌЫљвдАцБОЗЂВМЪЧИіджФбЁЃ
ШчКЮНтОіДЫЮЪЬтЃЌЮвУЧЕФДыЪЉЪЧаТдідЄЩњВњЛЗОГЃЌИФдьЗЂВМСїГЬЮЊСНМЖВПЪ№ЁЃдЄЩњВњЛЗОГзіЕФЪЧПчЯЕЭГСЊЕїЁЂФЃФтВтЪдЁЂЭГвЛАцБОЬцЛЛЃЌзюКѓЭГвЛЕНЩњВњЛЗОГЩЯЁЃдЄЩњВњЛЗОГПЩвдАзЬьзіЃЌКЯзїЛяАщКЭЭЌЪТЖМВЛгУдйФЧУДаСПрАОвЙжЕАрИюНгСЫЁЃ
дкЮвУЧзіИпаЇВПЪ№ЕФЙ§ГЬжаЃЌЮвУЧЯђЬкбЖРЖОЈбЇЯАЃЌБОЭМгЩЬкбЖРЖОЈЕФдЫЮЌздЖЏЛЏЗЂеЙРњГЬРДЁЃЮвУЧИјздМКЖЈСЫФПБъЃЌЛљзМФПБъЪЧИњГЇМвЕФШэМўЗЂВМАќБъзМЛЏЃЌВЮЪ§ЕФХфжУЮФМўБъзМЛЏЃЌЩ§МЖСїГЬБъзМЛЏЁЃЬєеНФПБъвВгаЃЌГЇЩЬПЩвдИљОнздМКЕФММЪѕЪЕСІЃЌПЊеЙЪ§ОнПтНХБОздЖЏЛЏЁЂећЬхЗЂВМНХБОЛЏЁЂгУDevOpsЩњВњЯпЧ§ЖЏЕФздЖЏЗЂВМЁЃ

ГЇМвзіЕФздЖЏЗЂВМВЂВЛЪЧШУЫћУЧзівЛИіздЖЏЗЂВМЕФЭјеОКЭЯЕЭГЃЌЮвУЧЭъШЋПЩвдДгDevOpsЬхЯЕжаЛёЕУбјЗжЁЃЃЈзѓЭМЃЉВЮМгЙ§DevOpsДѓЛсЕФЖМКмЪьЯЄЃЌетЬѕЩњВњЯпБОЩэОЭФмзіЗЂВМЃЌжЛвЊв§ШыОЭКУСЫЃЌВЛгУаТНЈЁЃЕБШЛЃЌЮЊСЫЪЪХфЭтАќФЃЪНЃЌЮвУЧЖдЩњВњЯпвВзіСЫвЛаЉИФдьЃЌШУЫќЭЌЪБЪЪХфЭтАќКЭздбаЯюФПЁЃетБпЪЧЭтАќЯюФПЃЌетБпЪЧздбаЯюФПЁЃгадДДњТыЕФзпетЬѕТЗЃЌУЛгадДДњТыЕФзпФЧЬѕТЗЁЃ
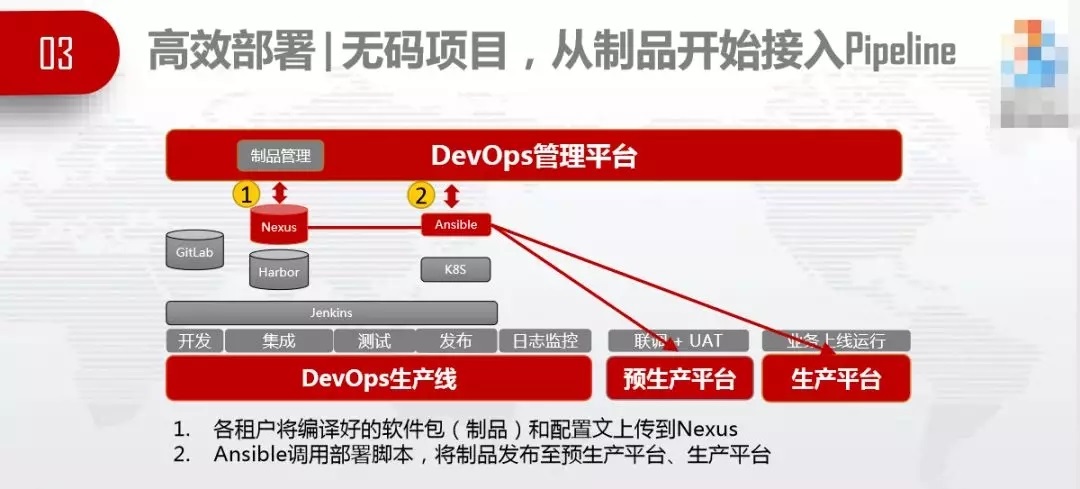
ЮоТыЯюФПЃЈЮодДДњТыЫѕаДЃЉЃЌДгжЦЦЗПЊЪМНгШыPipelineЃЌБрвыКУЕФАќЩЯДЋЕНNexusЃЌгЩDevOpsЩњВњЯпЧ§ЖЏВПЪ№ЁЃ
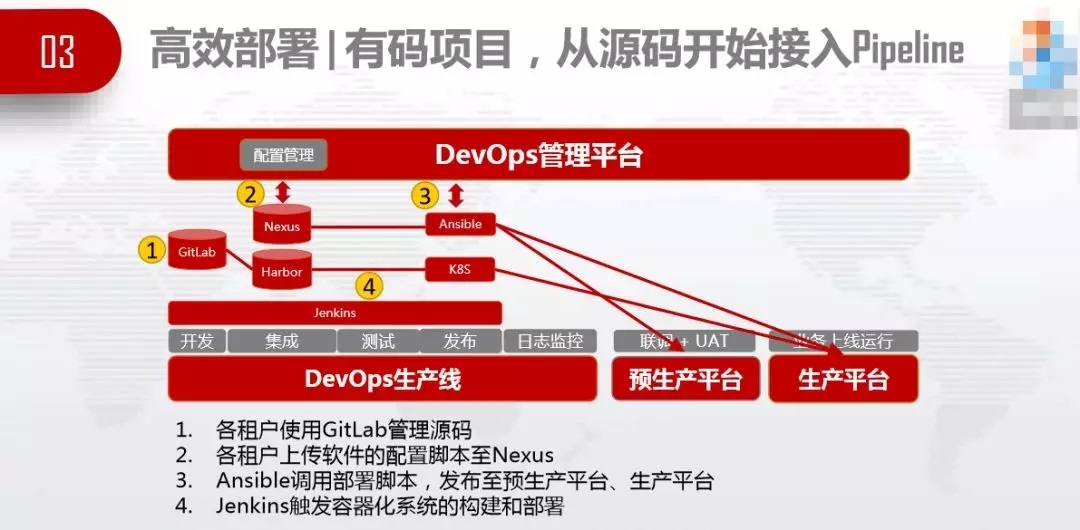
гаТыЯюФПЃЌИїзтЛЇЪЙгУGitLabЙмРэдДДњТыЃЌКЯзїЛяАщПЩвддкздМКЕФШэМўжааФЙЄзїЃЌВЛгУЕНМзЗНЯжГЁЃЌОЭПЩвдНЋВњЦЗдкpipelineЩЯНјааБрвыЁЂВтЪдЁЂВПЪ№ЁЂЗЂВМЕНЩњВњЦНЬЈКЭдЄЩњВњЦНЬЈЁЃ
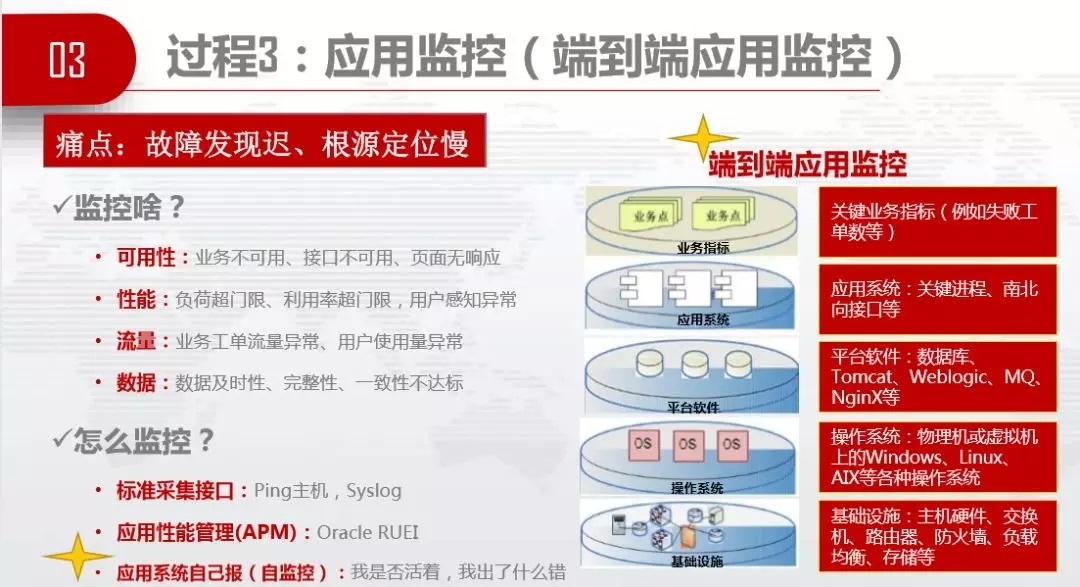
3.3.3 ЕкШ§ИіЙ§ГЬЁЊЁЊгІгУМрПи
ЭДЕуЪЧЙЪеЯЗЂЯжГйЃЌИљдДЖЈЮЛТ§ЁЃЮЊСЫИќПьЗЂЯжКЭЖЈЮЛЙЪеЯЃЌБиаывЊПЊеЙгІгУМрПиЃЌМрПиЩЖЃППЩгУадЁЂадФмЁЂСїСПЁЂЪ§ОнжЪСПЁЃдѕУДМрПиЃПвЛЪЧЭЈЙ§БъзМЛЏВЩМЏНгПкЃЌВЩМЏжїЛњЕФИККЩЁЂжИБъЁЂзДЬЌЕШЃЌЖўЪЧгІгУадФмЙмРэЃЌЮвУЧгУЕФЪЧOracle
RUEIЃЌШ§ЪЧгІгУЯЕЭГздМКБЈЃЌвЊНтПЊгІгУЕФКкКазгЃЌжЛФмШУгІгУздМКБЈЁЃЮвУЧетРязіЕФБШНЯДѓЕФДДаТЪЧЖЫЕНЖЫЕФгІгУМрПиЃЌЮвУЧЯждквЊАбИїВуЕФгІгУМрПиДЎЦ№РДЃЌГЩЮЊЖЫЕНЖЫЕФвЕЮёМрПиЃЌЪЙЕУЖЈЮЛИќМгЗНБуЁЃ
БОДЮDevOpsжїЬтЪЧAIOpsЃЌНгЯТРДЮвУЧвЊДггІгУМрПиРЉеЙЕНЭГвЛШежОЁЃгІгУМрПижЛЪЧМрПивьГЃЃЌФПЕФЪЧПьЫйЖЈЮЛЙЪеЯЕуЁЃЭГвЛШежОЪЧНшжњДѓЪ§ОнЭкОђЁЂЛњЦїбЇЯАММЪѕЭкОђвўЛМЁЂЙЪеЯдЄОЏЃЌЪЙЕУДЋЭГдЫЮЌПЩвдЯђдЫгЊзЊаЭЃЌвВЯђAIOpsНјЛЏЁЃЮвУЧЕФФПБъЪЧзіЖЫЕНЖЫМрПиЁЂШежОЃЌФПБъЪЧЁАСНИіЯШгкЁБЧААыВПЗжЃЌвЛЪЧЯШгкгУЛЇЗЂЩњЮЪЬтЃЌЖўЪЧЯШгкЭЖЫпНтОіЮЪЬтЁЃ

3.3.4 ЕкЫФИіЙ§ГЬЁЊЁЊЪТМўЯьгІМАДІРэ
ЭДЕуЪЧЙЪеЯаоИДУІТвЃЌжЛФмЮЇЙлЃЌЪјЪжЮоВпЁЃЮЪЬтИљдДдкгкетИчУЧСНДЮЙЪеЯЖМДЉТЬЩЋвТЗўЃЌЮвУЧШУЫћАбетМўвТЗўШгСЫЃЌвдКѓОЭдйвВУЛгаЙЪеЯСЫЃЈПЊЭцаІЃЉЁЃ
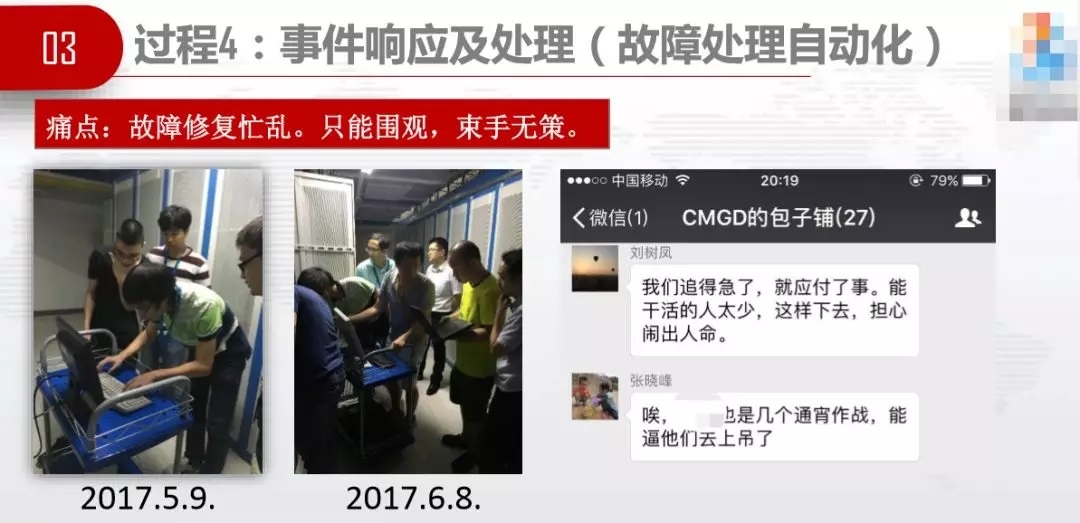
дЫЮЌЙЄОпНХБОЛЏЩЕЙЯЛЏжЧФмЛЏЃЌОпЬхДыЪЉЪЧЗУЬИГЇМвдЫЮЌШЫдБЃЌЮЪЫћУЧЃЌГЃМћЙЪеЯгаФФаЉЃПЫћУЧЪЧдѕУДДІРэЕФЃПГЇМвдЫЮЌШЫдБЫЕЃЌНгПкгЕШћЁЂПЈЕЅЁЂШБЪ§ЁЂгІгУНјГЬЕѕЫРЃЌНтОіЗНЗЈЪЧЪжЙЄЙ§ЕЅЁЂПЊЦєЯоСїЁЂдіПЊЗўЮёЦїЁЂЪжЙЄВЙЪ§ЁЂЪжЙЄжиЦєЕШЁЃЮвУЧМЬајЮЪЃЌФмЗёзіЕННХБОЛЏЁЂЩЕЙЯЛЏЃЌФмзіЕНИјЫћУЧМгЗжЁЃЩЕЙЯЛЏжЎКѓЃЌМЬајЬНЫїжЧФмЛЏЁЃ
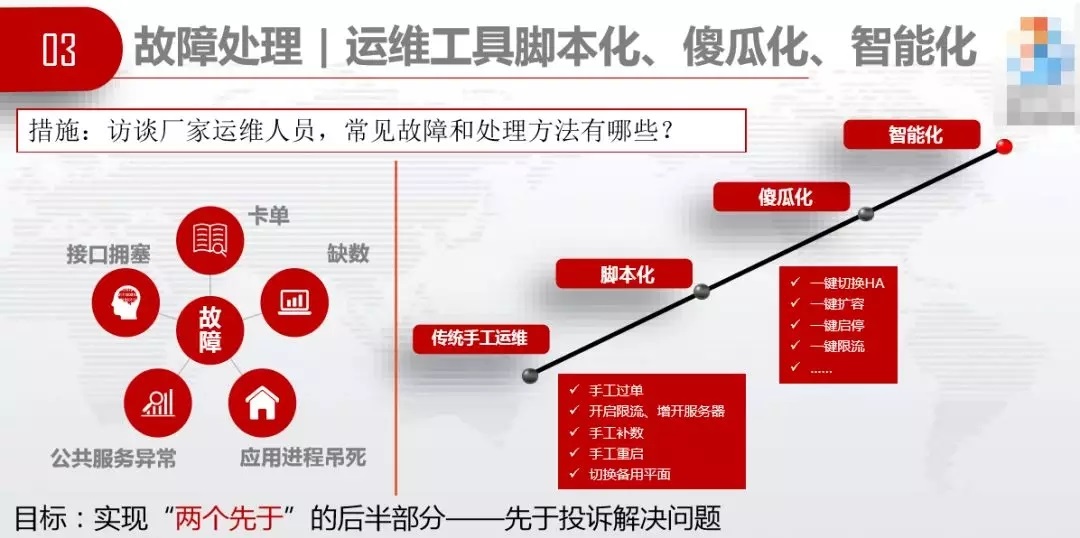
3.3.5 ЕкЮхИіЙ§ГЬЁЊЁЊИпПЩгУЙцЛЎ
етеХЭМЪЧДгЬкбЖРЖОЈПЇЗШЕГФЧРяГЕФЁЃЬкбЖРЖОЈдЫЮЌШЫдБжївЊгаШ§ЯюЙЄзїЃЌЩшжУдЄОЏЁЂДІРэБЈОЏЁЂаоИДИпПЩгУЁЃЬкбЖРЖОЈВЛгУЧРаоЙЪеЯЃЌвђЮЊЫћУЧIaaSЕФдЫгУМмЙЙЪЧИпПЩгУЃЌВЛашвЊЧРЁЃжЛашвЊдкГіЯжИцОЏЪБЃЌЧаЛЛИпПЩгУЃЌгаЪБМфдйТ§Т§аоИДИпПЩгУЃЌВЛгУЧРаоЁЃ
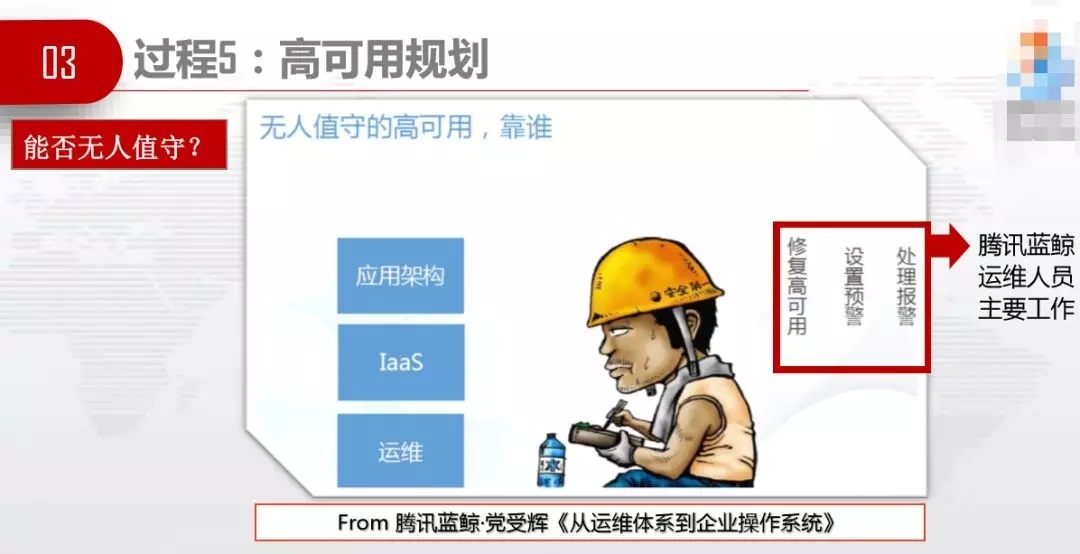
дЫгЊЩЬФмЗёзіИпПЩгУИФдьЃЌЩЯУцЪЧЛЅСЊЭјаавЕЕФШэМўМмЙЙЃЌЫћУЧгУЕФЪЧCloud-NativeЁЂDockerЁЂMSЁЂCephЁЂSDNЃЌЮвУЧгУЕФЪЧМЏжаЪНIBM
SVCЁЂДЋЭГШ§ВуЭјТчНсЙЙЁЂVLANЁЂVMwareЁЃШЋУцжиЙЙгІгУЯЕЭГздШЛЪЧжЮБОЕФЗНЗЈЃЌЕЋЪЧгаРЇФбКЭЗчЯеЃЌЮвУЧПЩвдЯШДгВПЪ№ВуУцПЊеЙHAИФдьЃЌЯћГ§ЕЅЕуЃЌВЛгУИФДњТыЃЌВЛгУжаЖЯвЕЮёЃЌжЛашвЊдкВПЪ№ВуУцПЊеЙЁЃЛЈЕуЧЎЖрВПЪ№МИЬзЃЌетЪЧЁАИјЗЩаажаЕФЗЩЛњМгзАв§ЧцЁБЁЃ

ШчКЮзіИпПЩгУЙцЛЎЃЌНшМјЙЋжкдЦЕФПЩгУЧјЃЌвЛИіПЩгУЧјГіЯжЛљДЁЩшЪЉЙЪеЯВЛгАЯьСэвЛИіПЩгУЧјЁЃУПвЛВуЖМгаЖрПЩгУЧјЃЌАДЗДЧзКЭддђЃЌвЕЮёЯЕЭГПчВЛЭЌЕФПЩгУЧјНјааВПЪ№ЁЃЭЈЙ§ЖрПЩгУЧјЕФВПЪ№ЪЕЯжИпПЩгУЃЌМђЕЅДжБЉЁЃ
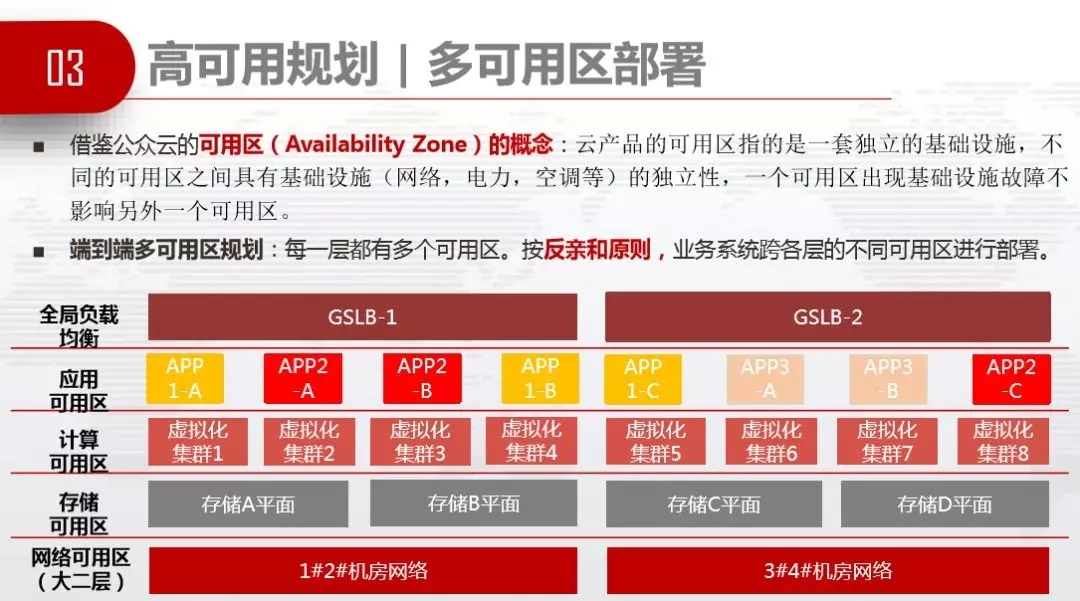
ЖЫЕНЖЫЕФИпПЩгУВПЪ№ЬхЯЕгаЭјТчИпПЩгУЁЂжїЛњИпПЩгУЁЂЙЋЙВSaaSИпПЩгУЁЂДцДЂИпПЩгУКЭгІгУВПЪ№ИпПЩгУЁЃ
ИпПЩгУЙцЛЎЕФЭЌЪБЃЌвЊЭЌВННјааCMDBЧхЯДЁЃвђЮЊИпПЩгУЙцЛЎБиаыгаCMDBЃЌВЛШЛФуВЛжЊЕРЫИњЫЗДЧзКЭЁЃзіЕНЪВУДГЬЖШЃПЮЊИпПЩгУЧаЛЛЁЂЮЊЙЪеЯЖЈЮЛЁЂЮЊздЖЏЛЏВПЪ№зіCMDBЃЌВЛвЊзіДѓCMDBЃЌЙЛгУОЭКУЃЌОЁСІЖјЮЊЃЌЮвУЧШЁЕФЪЧCMDBзюаЁМЖЁЃ
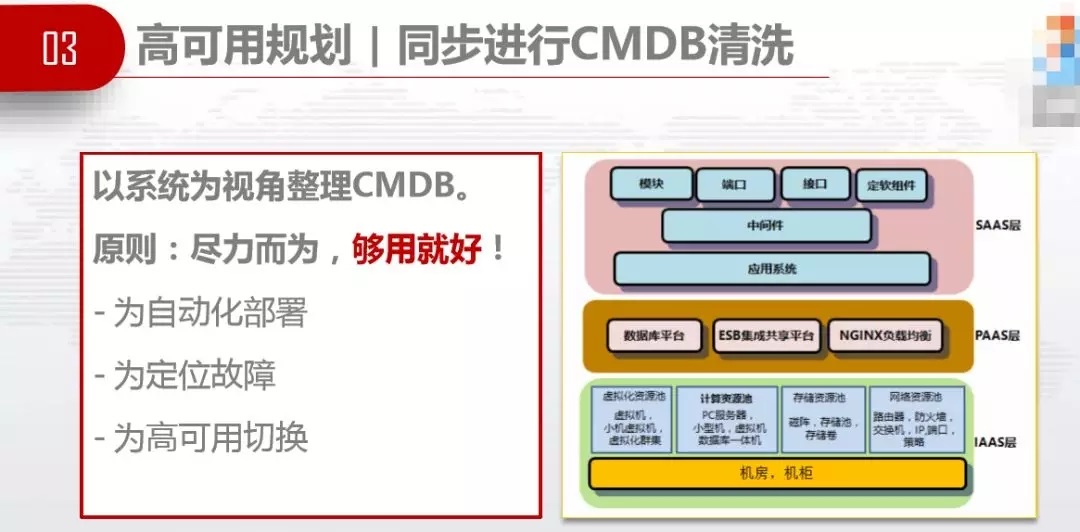
3.3.6ЕкСљИіЙ§ГЬЁЊЁЊЖШСПжИБъ
ЙњЦѓгавЛИіЬиЕуЃЌЁАЬњДђЕФгЊХЬСїЫЎЕФСьЕМЁБЃЌдкЙњЦѓИќвЊзЂвтЬхЯЕЕФПЩГжајЗЂеЙЃЌНЋзюМбЪЕМљЙЬЛЏаЮГЩЦѓБъЁЃгІгУЯЕЭГНЛЮЌБъзМЃЌБиаыТњзувЛМќВПЪ№ЁЂвЛМќЦєЭЃЃЌвЛМќЧаЛЛHAЁЃЪ§ОнПтБрГЬЙцЗЖКмживЊЃЌЮвУЧжЦЖЈСЫЁЖЪ§ОнПтгІгУБрГЬЕФNЬѕОќЙцЁЗЃЌЪ§ОнПтгІгУвЊЗЧГЃжиЪгЙцЗЖадЃЌЗёдђзіИќЖрЕФИпПЩгУЖМЪЧЮоаЇЕФЁЃIaaSЁЂPaaSЁЂSaaSМмЙЙЕФЙцЗЖЃЌвЊЧѓЕЅЦНУцЙЪеЯЪБПЩжЇГХвЕЮёИпЗхЃЌЖрПЩгУЧјВПЪ№ЁЂЗДЧзКЭаДддђЁЃDevOpsЙЄОпбЁаЭНЈвщЃЌПЊдДддђЁЂжїСїддђЁЂФмСІддђЁЃ

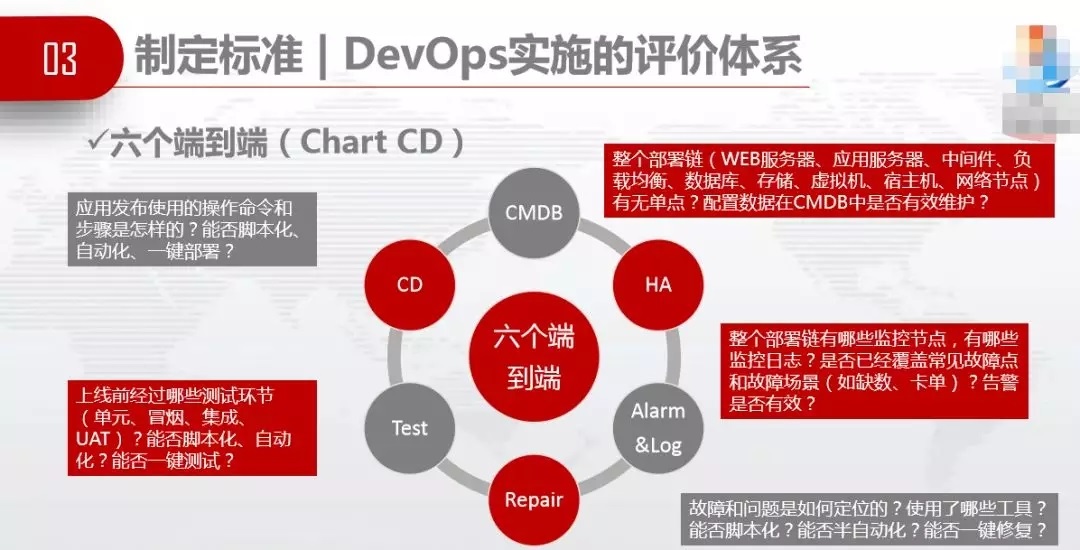
жЦЖЈБъзМЃЌDevOpsЪЕЪЉЕФЦРМлЬхЯЕЁЃСљИіЖЫЕНЖЫЃЈChart CDЃЉЃЌЖЫЕНЖЫCMDBЁЂЖЫЕНЖЫЕФHAЁЂЖЫЕНЖЫЕФAlarm
and logЁЂЖЫЕНЖЫЕФRepairЁЂЖЫЕНЖЫЕФCDЁЃ
4. ЙмРэИаЮђ
ЭђЪТПЊЭЗФбЃЌКѓУцНсЮВвВКмФбЁЃМмЙЙЛЙУЛИФБфЃЌДѓМвЖМдкЙлЭћЕФЪБКђЃЌПЩвдФЭаФХрг§жжзгЃЌВЛЗСЯШДДдьКЭаГгаРћЕФЭтВПЛЗОГЁЃЮвУЧзмНсСЫШ§ИіЪЦЃЌЫГЪЦЁЂНшЪЦЁЂдьЪЦЁЃ
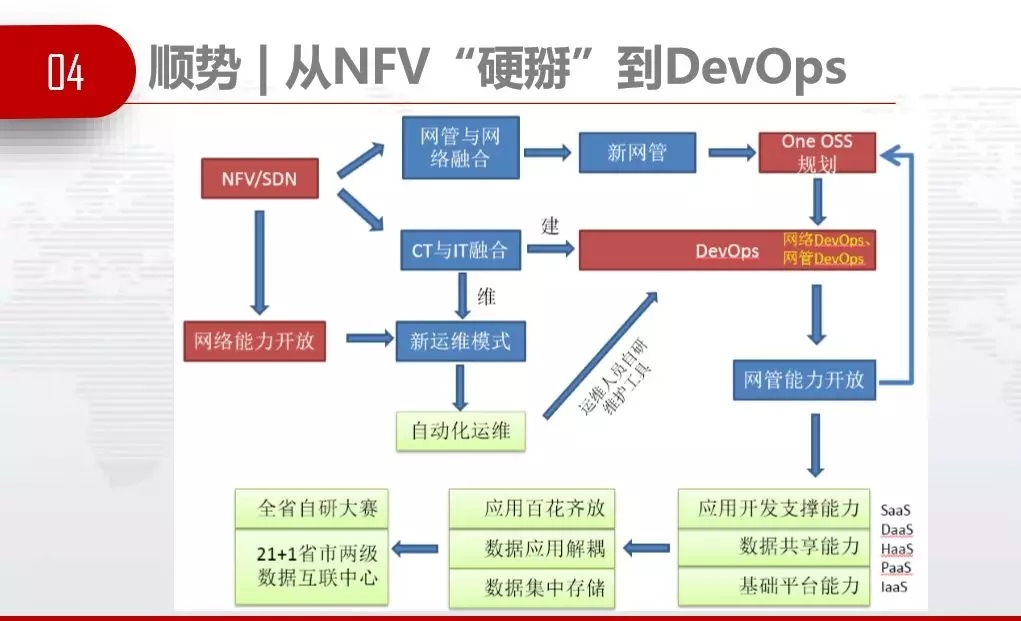
ЫГЪЦЃЌдЫгЊЩЬзюНќМИФъвЊзіNFVЃЌШЅФъЁЂЧАФъЪБЮвУЧЯыАьЗЈДгNFVЁАгВъўЁБDevOpsЃЌШчЙћУЛгаDevOpsЃЌИљБОЮоЗЈзіNFVЁЃ
НшЪЦЃЌ2016ФъЃЌЮвЛЙЪЧGOPSЕФЦеЭЈЙлжкЃЌжЛЪЧдкЛсГЁЭтБпЫцБуевСЫвЛИіУРХЎКЯгАЃЌНсЙћОЭИњИпаЇдЫЮЌЩчЧјСЊЯЕЩЯСЫЁЃ
ОЙ§вЛРДЖўЛиЕФСЊЯЕЃЌШЅФъФъЕзЮвУЧдкЙуЖЋвЦЖЏПЊСЫМвУХПкGOPSЃЌЧыСЫЯєзмЁЂРжЩёЁЂПЇЗШЕГИјЮвУЧСьЕМНВПЮЁЃЪЕМЪЩЯЪЧЯыНшЪЦЃЌЮвЫЕЕФСьЕМВЛвЛЖЈЛсШЯЭЌЃЌЮвПЩвдЧызЈМвЙ§РДНВЁЃНшЪЦЃЌЮвУЧвЊзпГіШЅЃЌЧыНјРДЃЌЧыЕНзщжЏРяЃЌГЩЮЊФуЕФжњЪЦЁЃ

дьЪЦЃЌПЊЪМЪБКмЖрСьЕМШЯЮЊDevOpsЪЧздбаЃЌЮвУЧАьСЫСННьздбаДѓШќЃЌздбаДѓШќЕФНсЙћЪЧв§Ц№РЯАхжиЪгЃЌаЫЦ№бЇITЕФШШГБЃЌПЊЗЂСЫвЛХњаЁЙЄОпЃЌХрбјСЫвЛХњITИпЪжЁЃЮвУЧАбЪЦдьЦ№РДЃЌШУДѓМвОѕЕУITВЛФЧУДФбЃЌзіЭјТчдЫЮЌЕФШЫвВПЩвдаДДњТыЁЃДгИїДѓИпаЃеаЕФЕчаХзЈвЕЁЂЙтЕчзЈвЕЁЂЮяРэзЈвЕвВПЩвдаДДњТыЃЌЭЌЪБЮЊЁАЛЛбЊЁБДђЯТЛљДЁЃЌгаШЫВХВХПЩвдзЊаЭЃЌдьЪЦКмживЊЁЃ

ВЛНіШчДЫЃЌНёФъ2дТЗнЙуЖЋвЦЖЏЛЙзщжЏСЫЯТвЛДњЭјТчжЧФмдЫЮЌITММЪѕЩГСњЃЌетИіЩГСњРїКІСЫЃЌжїЬтЪЧШУЭЌЪТЩЯЬЈНВЁЃШЅФъЧыЭтУцЕФзЈМвРДНВЃЌХрг§СЫвЛФъЃЌНшзуСЫЪЦЃЌНёФъОЭПЩвдздМКНВСЫЁЃЮвЧыСЫМЦЛЎВПЁЂЭјгХЁЂПЭЯьЕШВЛЭЌВПУХЕФзЈМвЙ§РДНВЁЃЯєАяжїЫЕЁАДјзХЩэБпаЁЛяАщЃЌвЛЦ№гфПьЕиЭцЫЃЁБЁЃвЛЦ№ЭцЫЃЃЌвЛЦ№дьЪЦЃЌАбDevOpsЪЦЭЗдьЦ№РДЁЃ

ИуЖЈЭтВПЛЗОГКѓЃЌЭХНсвЛЧаПЩвдЭХНсЕФСІСПЁЃЖдЭХЖгЃЌЮвУЧвЊМгЧПХрбЕЃЌЭиеЙаТЪгвАЃЌХЩШЅBATЁЂGOPSбЇЯАЁЃМЈаЇЧуаБЃЌЮвУЧЙФРјдИвтЭЖЩэЕНзЊаЭЙЄзїжаЕФдБЙЄЃЌЬсЙЉЦНЬЈКЭЮшЬЈЃЌИјГЩГЄЛњЛсЁЃЮвУЧШУЭЌЪТЩЯЬЈНВЃЌЖдДѓМвЕФЙФЮшКмгаАяжњЁЃ
ЖдГЇМвЃЌзЊаЭЧзздЙмЃЌФЊгУЭтАќЙмЭтАќЁЃгУКУжИЛгАєЃЌФмзіЕНСНИіЯШгкПЩвдМгЗжЃЌЯШгкгУЛЇЗЂЯжЮЪЬтЃЌЯШгкЭЖЫпНтОіЮЪЬтЁЃФмЙЛвЛМќаоИДЕФМгЗжЃЌHAЧаЛЛЕФМгЗжЃЌДгдДТыПЊЪМCIЁЂCDЕФПЩвдМгЗжЁЃ
ЛЅСЊЭјБъИЫЃЌТГбИЯШЩњЫЕЙ§ЁАЮвУЧвЊдЫгУФдЫшЃЌЗХГіблЙтЃЌздМКРДФУЁБЁЃ
ЮвУЧвЊбАЧѓРЯАхЕФжЇГжЃЌУЛгаРЯАхЕФжЇГжЃЌЫљгаЪТЧщдкЙњЦѓЖМЪЧВЛПЩааЕФЁЃ

5. змНс
ГЩЙІПЩвдИДжЦТ№ЃПРюПЊИДгавЛБОЪщЫЕЁЖЮвЕФГЩЙІПЩвдИДжЦЁЗЃЌЛЙгаШЫаДЁЖЮвЕФГЩЙІВЛПЩИДжЦЁЗЃЌDevOpsзЊаЭЕФЭђФмвЉЭшВЛДцдкЁЃСьЕМЕФЗчИёЁЂдБЙЄЕФЫижЪЁЂГЇМвЕФФмСІКЭздМКЕФблЙтВЛвЛбљЃЌзЂЖЈУПИіЦѓвЕКЭЭХЖгЕФDevOpsзЊаЭжЎТЗЪЧЖРвЛЮоЖўЕФЃЌБиаыБпзпБпЪдБпбЇЁЃЮвУЧвЊЮёБОЧѓЪЕЃЌЛиЙщБОаФЃЌФузіDevOpsЪЧЮЊСЫЪВУДЁЃЮвзіDevOpsзЊаЭЪЧвЊНтОШАОвЙжЕАрЕФЭЌЪТЃЌШУЫћУЧВЛгУОГЃАОвЙСЌжсзЊЃЌетЖдЮвУЧЭЌЪТРДЫЕЪЧКмКУЕФОШЪъЁЃШэГбЇЩёЃЌДѓМвПЩвдЕНИїЕиЗНбЇЯАЃЌВЛвЛЖЈвЊШЋГЃЌвЊбЇЛсМєЧаеГЬљЁЃ
жТОДКЭзЃдИЃЌНёФъЪЧИФИяПЊЗХ40жмФъЃЌИФИяПЊЗХЪЧДгЩюлкетЦЌЭСЕиПЊЪМЕФЃЌИљОнжаЙњЕФЪЕМЪЧщПіжЦЖЈСЫЗЂеЙжЎТЗЃЌЮвУЧвЦЖЏDevOpsзЊаЭвВЪЧШчДЫЃЌИљОнШеГЃЩњЛюЫљзіЕФГЂЪдКЭЪЕМљЃЌЮвУЧВЛЪЧДгЭЗзіЦ№ЃЌЮвУЧЪЧеОдкОоШЫЕФМчАђЩЯЗЂеЙЃЌвЛЪЧИпаЇдЫЮЌЩчЧјЃЌЖўЪЧРЖОЈЁЃЮвУЧДгетСНИіОоШЫЩэЩЯбЇЯАЕНКмЖрЖЋЮїЃЌвЛВЂЯђЫћУЧБэЪОИааЛЁЃШчЙћгаашвЊгУЕНЮвУЧЕФХѓгбЃЌЮвУЧЫцЪБдИвтЯзГіЮвУЧЕФЬнзгЁЃ

6. QAЛЗНк
ЬЈЯТЃКзђЬьЮвдкЮЪДЋЭГЦѓвЕЕФDevOpsдѕУДзіЁЃЕквЛЃЌDevOpsБШНЯЙизЂЕФЪЧвЕЮёМлжЕЃЌФњВЛЯыШУажЕмНуУУФЧУДРлЃЌГ§ДЫжЎЭтФњзіDevOpsзЊаЭЃЌЪЕЯжСЫЪВУДЃЌЪЕЯжСЫЖрЩйФњЖдРЯАхЕФГаХЕЁЃ
ЛЦваЯіЃКЮвЕФФПБъВЛНіНіЪЧВЛЯЃЭћЭЌЪТУЧФЧУДУІФЧУДРлЃЌЮвЯЃЭћDevOpsзЊаЭПЩвдДјРДМлжЕЁЃЮвУЧЭјЙмЯЕЭГЪЧжЇГХЭјТчдЫЮЌЃЌЪЕМЪЩЯвВжЇГХвЕЮёЗЂеЙЃЌБШШчДњЮЌЙмРэЯЕЭГЃЌЫќгаКмЖрашЧѓЃЌЙІФмПьЕуЩЯЯпЃЌЖдзАЮЌЪІИЕЕФаЇТЪКмгаАяжњЁЃетИіЦЌзгУЛгаЬИЕНФњЕФЬсЮЪЃЌЮвУЧзМБИдк4дТЗнПЊЪМАбФГМИИігІгУЯЕЭГДгдДДњТыПЊЪМНгШыDevOpsЃЌЗХдкЮвУЧЕФDevOpsЩњВњЯпЩЯЁЃЮвУЧвбОГЩЙІГЂЪдСЫвЛИіаЁЙЄОпЃЌдРДДѓИХАыИідТЛђепвЛИідТИќаТвЛДЮАцБОЃЌЯждкУПЬьПЩвдИќаТАцБОЁЃЮвИњРЯАхГаХЕЃЌЯТАыФъЪЕЯжФГаЉЯЕЭГНЛИЖжмЦкЃЌДгвЛИідТБфГЩвЛЬьЛђепвЛжмЃЌетЪЧDevOpsИјЮвУЧДјРДЕФвЕЮёЩЯЕФМлжЕЁЃ
ЬЈЯТЃКЕкЖўЃЌФуУЧгаздбаЭХЖгКЭГЇМвЮоТыЭХЖгЃЌФуздбаЕФеМБШЛсдНРДдНДѓЃЌГЇМвКЭКЯзїЛяАщЛсжЇГХФњетУДзіТ№ЃПАбдДДњТыНЛИјжаЙњвЦЖЏЁЃ
ЛЦваЯіЃКзїЮЊвЦЖЏЃЌФбвдАбЙмРэШэМўБфГЩздбаЃЌБЯОЙИїИіГЇМвГСЕэЪЎМИЖўЪЎФъЕФЖЋЮїЃЌФбвдППМИИіШЫгУАыФъЛђепвЛФъЪБМфЬцДњЫќЁЃЮвУЧзіЕФЪЧЙиМќзщМўзЪдДЃЌБШШчSSOЁЂааСаЪ§ОнПтЙиМќзщМўЁЃЮоТлЪЧздбаЛЙЪЧЭтАќЃЌзюжеЫпЧѓЪЧАбдДДњТыЗХдкЙуЖЋвЦЖЏЕФDevOpsЩњВњЯпЃЌЗХдкЙуЖЋвЦЖЏЕФGitLabНјааЙмРэЁЃЮвУЧБЃжЄЪЧздМКдБЙЄЙмРэDevOpsЩњВњЯпЃЌВЛШУЭтАќГЇМвЙмРэЃЌОЁСПЯћГ§ДѓМвЕФЙЫТЧЁЃЫљвдЛЙЪЧгаГЇМвдИвтАбдДДњТыЗХдкЮвУЧЩЯУцЕФЃЌЮвУЧвЊЗіГжетжжГЇМвЁЃ
ЬЈЯТЃКЮвУЧРэНтЭтАќЛЗОГЯТЕФDevOpsдЫааЃЌКЫаФдкЭтАќЁЃКЯзїЗНЪЧЗЧГЃживЊЕФСІСПЃЌЭЦааDevOpsЗЧГЃживЊЃЌЬиБ№дкЮвУЧаавЕЬхЯЕЯТЁЃКЯзїЗНИїгаИїЕФВЛЭЌЃЌгаЪБКђгЩгкЦфЖЈЮЛЁЂвЕЮёЕМЯђЮЪЬтЃЌашЧѓВЛвЛбљЁЃдЫгЊЩЬЬхЯЕжаЃЌЪЦБивЊЭЦЖЏДѓМвЭљЧАзпЁЃЭЈЙ§жИЛгАєЕїећЃЌеташвЊЭЖШыЃЌгаУЛгаИќКУЕФНтОіЗНАИЃЌБЯОЙВЛЪЧУПИідЫгЊЩЬЖМЯёвЦЖЏетбљПЩвдгаДѓЭЖШыЕФЁЃ
ЛЦваЯіЃКНшМјУЋжїЯЏДђеЬЕФзіЗЈЃЌРТЃвЛХњЃЌКіЪгвЛХњЃЌДђЛївЛХњЁЃЮвУЧЕФЕАИтетУДДѓЃЌзмЛсгаШЫдИвтХфКЯФуЁЃМЦЗбЯЕЭГЕФГЇМвгаЛЊЮЊЁЂбЧаХКЭСЊДДШ§МвПЩвдбЁдёЃЌЭјТчжЇГХЕФГЇМвОЭИќЖрСЫЃЌМИЪЎМвЃЌзмЛсгаШЫХфКЯФуЕФЁЃЮвУЧзїЮЊМзЗНЙмРэШЫдБЙЛВЛЙЛМсЖЈЃЌСьЕМЪЧЗёзуЙЛжЇГжФуЁЃЕБГЇМвШЅСьЕМФЧРяИцзДЃЌФуФмЗёЖЅзЁЁЃЮвУЧДгЭДЕузХЪжЃЌНтОіЕФЪЧЯжЪЕжаЕФРЇФбЃЌВЂУЛгазіЕпИВадЕФЖЋЮїЃЌФуУЛРэгЩВЛХфКЯЮвЁЃЮвДгЭЗЕНЮВЖМЪЧЮЊСЫНтОіФЧМИИіЭДЕуЃЌЮвПЊЪМЪБВЂУЛгаШУФуНЛГідДДњТыЃЌФуПЩвдВЛНЛЃЌЕБГЇМвЗЂЯжНЛжЦЦЗЗЧГЃРлЃЌНЛдДДњТыЧЎгжЖргжЧсЫЩЃЌОЭвЛЖЈЛсбЁдёНЛдДДњТыЁЃ
ЬЈЯТЃКЗЧГЃдоЭЌФњЬИЕНЕФЭтАќзЊаЭЃЌЕЋЭЌЙњЦѓЪЕМљРДПДЃЌГ§СЫФњЬИЕНЕФЭДЕуЃЌЮвУЧЛЙгаЦфЫћЕФЭДЕуЁЃвЛЪЧШЫСІзЪдДЗНУцЃЌЮвУЧЮоЗЈЖРСЂзджїЃЌЮвУЧгЩЙЋЫОжїГжЃЌдкШЫСІЩЯФбвдЪЕЯждіМгШЫдБЃЛЖўЪЧЙњЦѓЭХЖгДДаТФмСІПЯЖЈВЛШчГЇМвЃЌвЛЕЉНјШыЙњЦѓЭХЖгЃЌЦфДДаТФмСІТэЩЯВЛзуЃЌетЪЧЮвУЧЕФЯжЪЕЧщПіЃЌФњФмИјЮвУЧЬсГіЪВУДНЈвщЃП
ЛЦваЯіЃКЕквЛЃЌШЫСІзЪдДШЗЪЕЪЧГЄЦкЕФЮЪЬтЃЌЭђЪТПЊЭЗФбЃЌФуБиаыбЇЛсЫГЪЦЁЂНшЪЦКЭдьЪЦЃЌвЊЫГзХЕБЧАЦѓвЕЫљдкЕФЭДЕуРДИФНјЃЌБШШчИќПьЕФНЛИЖЁЂИќИпЕФдЫЮЌжЪСПЁЃНшЪЦЃЌЖрДјФуЕФСьЕМКЭЭЌЪТВЮМгИїжжТлЬГЃЌЖрЯђЛЅСЊЭјаавЕКЭЛЅСЊЭјЙЋЫОбЇЯАЃЌСЫНтЁЂЖдБъЃЌШУЫћзпГіШЅПДЃЌЫћздШЛЛсгаСЫНтЁЃШЫаФЪЧШтГЄЕФЃЌгаДЅЖЏжЎКѓЃЌвЊЖрЯђСьЕМЧыЪОКЭЛуБЈЃЌЖрЫЕАИР§ЁЃЙигкШЫСІКЭЭХЖгЕФЮЪЬтЃЌЪзЯШвЊФкВПЭкЧБЃЌДгвЛИіЭХЖгзмФмГщГівЛСНИігаЯыЗЈгаФмСІЕФШЫЃЌШУЫћзЈжАзіDevOpsЁЃКмЖрШЫПДЕНЫћзіГіРДЕФЖЋЮїКмгавтЫМЃЌвВЛсгааЫШЄгаЖЏСІШЅбЇЁЃФуПЩвдевГівЛИіжжзгЁЊЁЊдьбЊЃЌевЕНетИіЛљвђЃЌВЂНЋЦфЕуШМЁЃ
ЬЈЯТЃКздгаЭХЖгЕФДДаТФмСІдѕУДЬсЩ§ЁЃ
ЛЦваЯіЃКЮвУЧЙњЦѓЕФЭХЖгПЯЖЈУЛЗЈЯёЛЅСЊЭјЙЋЫОФЧУДгаМЄЧщКЭФЧУДИпЕФФмСІЃЌОЁСІЖјЮЊЃЌВЛвЊЧПЧѓЃЌБШвдЧАКУОЭааСЫЃЌВЛвЊИњЛЅСЊЭјЙЋЫОБШЃЌетгАЯьавИЃИаЃЈПЊЭцаІЃЉЁЃ
DevOps ТфЕиЮЊКЮетУДФбЃП
РД DevOps ЙњМЪЗхЛсбАевевД№АИ
DOIS ДѓЛсЮЊФњГЪЯжЛЅСЊЭјЙЋЫОгыКЃЭтЦѓвЕЕФЪЕМљОбщгыЙЄОпММЪѕЃЌОлНЙ DevOps дкН№ШкЁЂЭЈаХЁЂСуЪлЕШаавЕЕФЯЕЭГадЪЕМљЃЌВЛПеЬИЃЁВЛЮёащЃЁзЈзЂ
DevOps ТфЕиЃЁ |









