ЧАМИЬьЬ§РЯЭѕЗжЯэЃЌЬсЕНЙигк
DevOps дкЙњФкЭтЕФЗЂеЙЮЪЬтЃЌЦфжаОЭЫЕЕНдчЦкЬкбЖзідЫЮЌЪБЃЌФЧИіЪБКђвВУЛЪВУДвтЪЖЪЧ DevOps
ЃЌЦфЪЕОЭЪЧдкБфЬЌЕФвЕЮёЬхСПЯТУцвЛВНВНзіГіРДЕФЃЌКѓРДЙњФк DevOps ЕФИХФюЛ№Ц№РДСЫЃЌВХЗЂЯждРДетИіНазі
DevOps ЁЃ

ЭІгавтЫМЕФвЛИіЛАЬтЃЌЬ§РЯЭѕНВЭъЃЌвВКмгаИаДЅЃЌЫљвдЗжЯэЯТЮвУЧздМКЕФдЫЮЌЃЈ DevOps ЃЉбнНјЙ§ГЬЃЌгаЕуГЄЃЌЕЋБШНЯЭъећЃЌПДЭъЛђаэЛсгаЪеЛёЁЃ
ЕквЛНзЖЮЃКжЛга Dev ЃЌУЛга Ops ЃЌDev ЪЧШЋеЛЙЄГЬЪІ

ШчКЮРэНтЃПзюГѕЕФЪБКђЃЌВњЦЗКЭвЕЮёаЮЬЌЖМДІгкУўЫїЦкЃЌвЕЮёИДдгЖШВЛИпЃЌЗУЮЪСПВЛДѓЃЌШэМўФмЙЛОЁПьХмЦ№РДЭЦЯђЪаГЁЪЧзюживЊЕФЃЌЫљвдМмЙЙЩЯВЛЩшМЦЕФКмИДдгЃЌЕЅЬхЛђЗжВуМмЙЙзувгЁЃШчЯТУцЕфаЭЕФ
LNMP МмЙЙЃК

ЗўЮёЦїКЭЭјТчЩшБИЪ§СПвВОЭЪЧСНЮЛЪ§ЙцФЃЃЌзюзювЛПЊЪМИіЮЛЪ§вВгаПЩФмЁЃЫљвдМИИіПЊЗЂЭЌбЇдкМђЕЅМмЙЙЯТЃЌЮЌЛЄМИЪЎЬЈЗўЮёЦїЛЙЪЧУЛЮЪЬтЕФЫљвдЃЌетИіЪБЦкШЗЪЕВЛашвЊдЫЮЌЙЄГЬЪІЃЈ
ЕЋЪЧВЂВЛвтЮЖзХУЛгадЫЮЌЕФЪТЧщ ЃЉЃЌетИіТпМЭЌбљЪЪгУгкВтЪдЁЃ
ЯждкКмЖр startup ЙЋЫОЃЌжБНгдкдЦЩЯЪЙгУ docker ВПЪ№ФЃЪНЃЌЖдгкЛљДЁЩшЪЉОЭИќВЛгУЭЖШыЬЋЖрОЋСІШЅЮЌЛЄЃЌЫљвдетаЉЙЋЫОЖМЛсНВЮвУЧЕФбаЗЂЭХЖгБШНЯЕЅвЛЃЌжЛгаПЊЗЂЃЌУЛгадЫЮЌКЭВтЪдЃЌЫљгаЕФЪТЧщПЊЗЂЖМПЩвдИуЖЈЁЃ
ЕкЖўНзЖЮЃКDev + Ops ЃЌЕЋВЛЪЧ DevOps
вЛИівЕЮёЗЂеЙСМКУЕФЙЋЫОЃЌЕквЛИіНзЖЮПЯЖЈВЛЛсЭЃСєЬЋОУЃЌБЯОЙвЕЮёдкЗЂеЙЃЌЩѕжСЪЧИпЫйЗЂеЙЃЌВЛШЛЙЋЫОПЯЖЈОЭУЛЪВУДЧАЭОСЫЁЃ
АщЫцзХвЕЮёЗЂеЙЃЌвЕЮёИДдгЖШЩ§ИпЃЌПЊЗЂашвЊНЋИќЖрЕФОЋСІЗХЕНИќЖрИќПьЕиашЧѓЪЕЯжЩЯЃЌвВОЭЪЧМЏжаОЋСІаДДњТыЃЛЭЌЪБвЕЮёЗУЮЪСПдіМгЃЌКѓЖЫЩшБИЪ§СПвВдіМгЦ№РДЃЈ
вЛЖЈЪБЦкФкЖбЛњЦїЛЙЪЧПЩвдНтОіВЛЩйЮЪЬтЕФ ЃЉЃЌДяЕНМИАйЩЯЧЇетбљЕФЙцФЃЃЌЮЌЛЄЕФЙЄзїСПвВОЭЩЯРДСЫЁЃ
ЫљвдКмздШЛЕФЃЌетИіЪБКђОЭашвЊ Ops етбљЕФНЧЩЋРДЙмРэКЭЮЌЛЄЩшБИЃЌЭЌЪБЖдгк DB ЁЂЛКДцЁЂWeb ЗўЮёЦїЁЂДцДЂвдМА
CDN етбљЕФЭЈгУЛљДЁЗўЮёвВЪЪгУетИіТпМЁЃИХРЈвЛЕуЫЕЃЌГ§СЫаДДњТыЃЌдЫЮЌзюКУФмАбЫљгажЎЧАПЊЗЂИЩЕФЪТЧщЖМИЩСЫЁЃ

етЪБ Ops ЕФжївЊжАд№ЃКгВМўЮЌЛЄЁЂЭјТчЩшБИЮЌЛЄЁЂDBA ЁЂЛљДЁЗўЮёЮЌЛЄЕШЁЃ
ЮввВЪЧдкетбљвЛИіНзЖЮНјШыЕНЯждкЕФЙЋЫОЃЌЮвОѕЕУдкетИіНзЖЮЩЯЃЌЮвУЧЕФвтЪЖЛЙЪЧБШНЯКУЕФЃЌБШЮвЕБЪБЕФвтЪЖвЊГЌЧАКмЖрЃЌдЫЮЌЭХЖгвбООпБИЙЄОпПЊЗЂФмСІЃЌВЂгаСЫРрЫЦЛњЦїзЪдДЙмРэЁЂPHP
ЗЂВМЯЕЭГЁЂМрПиЕШвЛаЉЙЄОпЦНЬЈЃЌвдМАвЛаЉЗЧГЃИпаЇЕФздЖЏЛЏНХБОЙЄОпЁЃЫљвдЃЌетИіЭХЖгДгвЛПЊЪМОЭГчЩаФмгУММЪѕНтОіЮЪЬтОЭОјЖдВЛППШЫЕФРэФюЁЃ
ЕЋЪЧдЫЮЌЕФзЂвтСІШдШЛОлНЙдкЩЯУцЬсЕНЕФЛљДЁЩшЪЉКЭЗўЮёВуУцЃЌЖјЧвдЫЮЌПЊЗЂдкзіЕФЪТЧщИќЖрЕФЪЧздИјздзуЃЌвВОЭЪЧТњзудЫЮЌЭХЖгФкВПЕФЙЄОпашЧѓЃЌЕБШЛвВгавЛВПЗждвђЪЧЪмЯогкЕБЪБЕФММЪѕМмЙЙЃЌЙцФЃКЭИДдгЖШгаЯоЃЌдЫЮЌФмзіЕФЪТЧщвВгаЯоЁЃ
ЫљвдетИіЪБКђЪЧ Dev ЪЧ Dev ЃЌOps ЪЧ Ops ЃЌЛЙУЛгазіЕН Dev КЭ Ops ЕФШкКЯЁЃ
ЕкШ§НзЖЮЃКШдЪЧ Dev + Ops ЃЌЕЋ Ops ПЊЪМзщНЈдЫЮЌПЊЗЂЭХЖг
етРягаИіММЪѕМмЙЙбнНјЕФБГОАЃЌОЭЪЧДгЕЅЬх + ЗжВуЕФМмЙЙЃЌЯђЗўЮёЛЏМмЙЙбнНјЁЃЫцзХвЕЮёИДдгЖШЕФЬсЩ§ЃЌЫљгаДњТыКЭТпМЖМЗХЕНвЛИіЙЄГЬРяЕФНсЙћОЭЪЧЯТЭМЃК
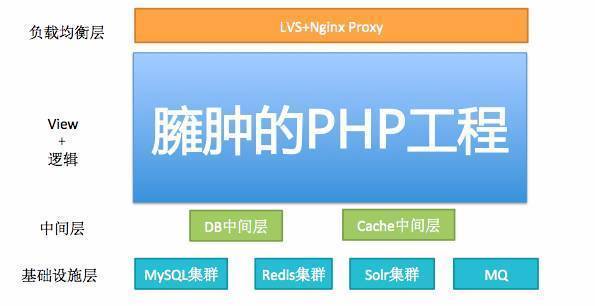
етЪБёюКЯбЯжиЃЌЧЃвЛЗЂЖјЖЏШЋЩэЃЌПЊЗЂаЇТЪШеНЅЕЭЯТЃЌЫљвдвЊзіЕФЪТЧщОЭЪЧвЛИізжЃЌВ№ЃЈ зЈвЕЫЕЗЈЃКЗўЮёЛЏВ№Зж
ЃЉЃЌШчЯТЭМЫљЪОЃК
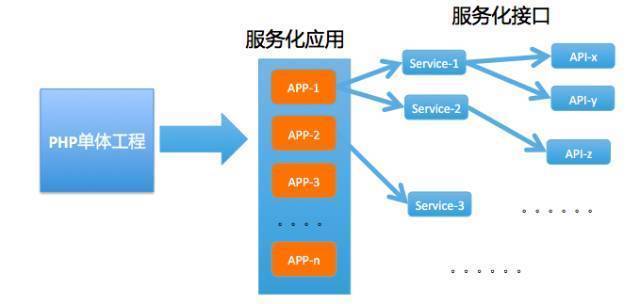
етЪБЃЌДѓСПЕФгІгУБЛВ№ЗжГіРДЃЌЖддЫЮЌздЖЏЛЏЁЂГжајЗЂВМЁЂЮШЖЈадЕФвЊЧѓОЭЫцжЎЖјРДЃЌЫљвд Ops ПЊЪМе§ЪНзщНЈдЫЮЌПЊЗЂЭХЖгРДзігаЙцЛЎЕФЁЂЯЕЭГадЕФЬсЩ§аЇТЪКЭЮШЖЈадЗНУцЕФЪТЧщЃЌетИіЪБКђЕФдЫЮЌПЊЗЂЭХЖгжЇГХЕФашЧѓЗНгаСНИіЃКвЛИіЪЧдЫЮЌФкВПЃЌвЛИіЪЧПЊЗЂЃЌвђЮЊдЫЮЌЛсХфКЯжЇГжПЊЗЂзіКмЖрЪТЧщЃЌЫљвдКмЖрЧщПіЯТдЫЮЌЕФашЧѓвЛЖЈГЬЖШЩЯОЭДњБэСЫПЊЗЂЕФашЧѓЃЌЕЋВЛЪЧЭъШЋДњБэЁЃ
дЫЮЌФкВПЕФашЧѓжївЊЪЧзЪдДЗжХфЁЂРЉЫѕШнЁЂгІгУЙмРэЁЂгђУћЁЂVIP ЕШЕФЙмРэашЧѓЃЌПЊЗЂжївЊЪЧГжајНЛИЖЕФашЧѓЃЌСНепЙВЭЌЕФашЧѓОЭЪЧМрПиЁЂШнСПЙмРэЁЂадФмЙмРэЁЂСДТЗИњзйЕШЕШЁЃетаЉОпЬхФкШнЃЌжЎЧАгаВПЗжЮФеТЗжЯэЙ§ЃЌетРяОЭВЛЯИЫЕСЫЁЃ
ЛЙЪЧЫЕЫЕетИіНзЖЮ DevOps ДцдкЕФвЛаЉЮЪЬтЃК
дЫЮЌПЊЗЂЪЧЭбРыЪЕМЪдЫЮЌЙЄзїЕФ
етИіЭХЖгЕФЖЈЮЛЛЙЪЧвЊДгдЫЮЌетРяГаНгашЧѓЃЌШЛКѓПЊЗЂЪЕЯжЃЌВЂВЛЪЕМЪВЮгыдЫЮЌЙЄзїЃЌдйМгЩЯдЫЮЌПЊЗЂздЩэвВЛсгавЛаЉЖРСЂЕФЯыЗЈЛђепДјзХжЎЧАЕФОбщдкЩшМЦПЊЗЂЃЌЫљвдЖдгкЯжзДЯТЕФдЫЮЌЙЄзїРэНтЪЧВЛЙЛЩюШыЕФЁЃЭЌЪБЃЌдЫЮЌЭЌбЇздЩэвВВЛЪЧВњЦЗГіЩэЃЌвЛПЊЪМвВКмФбАДееВњЦЗЛЏЕФЫМЮЌФЃЪНБэДяЧхГўздМКЕФашЧѓЃЌЭљЭљОЭЪЧЯжЪЕЙЄзїГЁОАЕФПкЪіЃЌЫљвдБэДяЕФИќЯёЪЧвЛИіИіЙІФмЕуЕФЖбЦіЃЌЖјВЛЪЧЯЕЭГЛЏЕФНЈЩшЫМТЗЁЃ
ЫљвдетРяЪМжеОЭЛсгаИі Gap ЁЃНсЙћЩЯЃЌзюжБНгЕФЬхЯжОЭЪЧдЫЮЌПЊЗЂзіГіРДЕФЙЄОпКЭЦНЬЈУЛЗЈКмКУЕФТњзудЫЮЌЕФашЧѓЃЌЩѕжСЙ§ГЬжавВЛсГіЯжвЛаЉУЌЖмЃЌБШШчдЫЮЌБЇдЙдЫЮЌПЊЗЂУЛФмКмКУЕиЪЕЯжашЧѓЃЌзіГіРДЕФЖЋЮїВЛКУгУЃЌЩѕжСЪЧУЛЗЈгУЃЌдЫЮЌПЊЗЂвВЛсБЇдЙдЫЮЌашЧѓУЛЬсЧхГўЃЌЛђепЫЕаСаСПрПрзіГіРДЕФЖЋЮїдЫЮЌВЛгУЃЌаСПрЖМЪЧАзЗбЁЃ

ЫљвдФуПДЃЌвЛИіЭХЖгВЂВЛЪЧгаСЫдЫЮЌПЊЗЂКЭдЫЮЌздЖЏЛЏОЭЭђЪТДѓМЊСЫЃЌЛЙЛсЩцМАЕНвЛаЉЭХЖгЙмРэКЭдЫзїФЃЪНЩЯЕФЮЪЬтЁЃ
ЖјЧвЯжЪЕжаЃЌгаКмЖрЙЋЫОЕФдЫЮЌПЊЗЂЭХЖгЪЧЖРСЂЕФЃЌдЫЮЌКЭдЫЮЌПЊЗЂВЛЪЧЭЌвЛИіжїЙмЃЌЩѕжСВЛдкЭЌвЛИізщжЏМмЙЙЯТЃЌетбљОЭКмШнвзГіЯжЩЯУцЫЕЕФетИіЮЪЬтЁЃетРяИљБОдвђЛЙЪЧФПБъВЛвЛжТЃЌдЫЮЌЪЧашвЊвЛИіЦНЬЈФмАбздМКЕФЪТЖМИЩСЫЃЌЕЋЪЧдЫЮЌПЊЗЂИќЖрЕФЪЧПМТЧФуИјЮвЬсЪВУДашЧѓЮвзіЪВУДашЧѓЃЌФПБъЪЧзіЭъашЧѓЃЌЖјжСгкКУВЛКУгУЃЌВЛЪЧзюживЊЕФЪТЧщЁЃ
ЩдКУвЛЕуЕФдЫзїФЃЪНЃЌдЫЮЌКЭдЫЮЌПЊЗЂдкФГИіОпЬхЕФЯюФПЩЯаЮГЩащФтЭХЖгЃЌетИіЭХЖгЕФФПБъКЭПМКЫЗНЪНвЛжТЃЌШчЙћдЫЮЌКЭПЊЗЂЕФаЇТЪЕУВЛЕНЬсЩ§ЃЌЭХЖгЕФећЬхМЈаЇОЭЛсЪмЕНгАЯьЃЌжСгкПМКЫЗНЪНКЭвЛаЉЯИНкОЭВЛЯъЯИЫЕСЫЁЃМЧзЁвЛЕуЃЌОЭЪЧФПБъвЛжТЕФЧщПіЯТЃЌДѓМвВХЛсГЏвЛИіЗНЯђЪЙОЂЃЌЪТЧщзіЕиВХЛсИќКУЁЃ

зюКУЕФЗНЪНЃЌГдздМКЕФЙЗЪГЁЃEat your own dog food .
Ops ШЅзідЫЮЌПЊЗЂЃЌдЫЮЌПЊЗЂШЅзі Ops ЃЌетбљвВОЭВЛДцдкашЧѓДЋЕнЕФЙ§ГЬКЭ Gap СЫЃЌздМКзіГіРДЕФЖЋЮїздМКгУЃЌдЫЮЌПЊЗЂПЩвдИќЩюПЬЕиРэНтдЫЮЌЙЄзїЃЌЖјВЛЪЧЬьТэааПеЕиЦОПе
YY ЁЃ
етбљПЩвдШУБЫДЫФмЙЛеОдкЖдЗНЕФНЧЖШШЅПМТЧЮЪЬтЃЌвВОЭВЛЛсгаЪВУДБЇдЙКЭжИд№СЫЁЃ
ЮвУЧЕБЧАФЃЪНЪЧащФтЯюФПзщФЃЪНЃЌКУдкдЫЮЌКЭдЫЮЌПЊЗЂЭХЖгЖМдкЭГвЛЭХЖгжаЃЌетбљПЩвдЪЁШЅДѓСПЙЕЭЈГЩБОЃЌФПБъвВПЩвдЯрЖдШнвзДяГЩвЛжТЁЃЭЌЪБЃЌЮвдкзіЕФвЛИіГЂЪдОЭЪЧЩЯУцЫЕЕФЃЌOps
гавЛВПЗждБЙЄвЊШЅзідЫЮЌПЊЗЂЕФЪТЧщЃЌдЫЮЌПЊЗЂвЊШЅзідЫЮЌЕФЪТЧщЃЌКѓајгІИУЛсАбСНИіЭХЖгж№ВНШкКЯЁЃ
змНсЯТЕквЛИіЮЪЬтЃЌЮвУЧПЩвдПДЕНВЛЙт Dev КЭ Ops жЎМфЛсгаазїЮЪЬтЃЌФФХТЪЧдЫЮЌЭХЖгФкВПЕФПЊЗЂЃЌдкХфКЯЩЯвВЛсДцдкЮЪЬтЃЌетЪЧИіЯИНкЮЪЬтЃЌашвЊЭХЖгЙмРэКЭЯюФПдЫзїЩЯзівЛаЉгХЛЏЁЃ
дЫЮЌПЊЗЂКЭвЕЮёПЊЗЂЭХЖгЕФазїЮЪЬт
ЕквЛИіЮЪЬтПЩвдЭЈЙ§ФкВПЙЕЭЈКЭазїЕФЗНЪНШЅИФНјЃЌЕЋЪЧЖдЭтЃЌжЛФмЧПЕїЗўЮёвтЪЖЃЌетРяОЭвЛИіХаЖЯддђЃЌШчЙћФузіГіРДЕФЖЋЮїЃЌПЊЗЂЖМВЛгУЛђепвтМћКмДѓЃЌФЧжЛФмЫЕФуЕФЙЄзїЭъГЩВЛЕНЮЛЃЌЛђепдкКЯзїазїЩЯЪЧгаКмДѓЮЪЬтЕФЁЃ
ЕкЫФНзЖЮЃКеце§ЕФ DevOps ЃЌDev КЭ Ops ШкКЯ
ЕБ Ops ЕФФмСІГСЕэЕНвЛИіИіВњЦЗЦНЬЈжЎКѓЃЌдРДПЊЗЂвРРЕдЫЮЌЕФШЫШЅИЩЕФЪТЧщЃЌОЭПЩвдзджњЕивРРЕдЫЮЌЦНЬЈШЅзіСЫЃЌвВОЭЪЧШеГЃдЫЮЌгЩПЊЗЂздМКзіЃЌЖјВЛдйвРРЕдЫЮЌетИіЛЗНкЃЌеце§ЪЕЯж
DevOps ЁЃ
ЕфаЭАИР§ОЭЪЧГжајНЛИЖзіКУжЎКѓЃЌПЊЗЂЭъШЋПЩвдзджњЗЂВМЃЌШЋГЬЮоашдЫЮЌНщШыЁЃ

ЫљвдЃЌХаЖЯвЛИіЭХЖгЪЧВЛЪЧ DevOps ФЃЪНЃЌгавЛИіКмМђЕЅЕФддђЃЌЩЯУцвВЬсЕНСЫЃЌШчЙћдЫЮЌзіГіРДЕФЖЋЮїПЊЗЂгУВЛЩЯЃЌФЧОЭВЛвЊНа
DevOps ЃЌЛђаэФузіЕФжЛЪЧдЫЮЌздЖЏЛЏЖјвбЁЃ
ЮвУЧЖМПЩвдгУетИіБъзМШЅЖдееЯТЃЌД№АИВЛбдЖјгїЃЌВЛаХПЩвдЪдЪдЁЃ
ЕБШЛЃЌЮвУЧздМКвВЛЙгаКмЖрЕиЗНзіЕФВЛЙЛЭъЩЦЃЌжЛФмЫуЪЧетИіНзЖЮЕФЙ§ГЬжаЃЌЛЙУЛгаЭъШЋДяЕНЁЃКѓУцЮвУЧЛсељШЁАбЫљгаФПЧАдЫЮЌдкзіЕФЪТЧщШЋВПГСЕэЕНЦНЬЈЩЯЃЌШУПЊЗЂзджњЭъГЩЃЌЩѕжСзіЕНШУПЊЗЂзіЕНПЊЗЂ-ЗЂВМ-дйПЊЗЂЕФФЃЪНЃЌЭъШЋВЛгУПМТЧКѓЖЫЕФЪТЧщЃЌЕБШЛТЗЛЙКмГЄЃЌБиШЛвВЛсКмЧњелЁЃ
ЯёАЂРяЃЌзіЕФОЭИќМЋжТЃЌФПЧАОЭвбОВЛДцдк PEЃЈ гІгУдЫЮЌ ЃЉЭХЖгСЫЃЌдРДЕФ PE вЊУДзЊаЭШЅзі DevOps
ВњЦЗЩшМЦЛђПЊЗЂЃЌвЊУДОЭУцСйвЛИіКмВаПсЕФЯжЪЕЃЌБЛЬдЬЁЃПЩвддЄМћЃЌАЂРяЮДРДгІИУвВВЛдйЛсеаДПдЫЮЌИкЮЛЃЌЮДРДжЛгаПЊЗЂЃЌПЩвдЬсЩ§баЗЂаЇФмЕФПЊЗЂШЫВХЁЃ
ЙњЭтЯё Netflix КЭ Amazon ЪЧбЙИљОЭУЛгадЫЮЌетбљЕФНЧЩЋЃЌдЫЮЌЕФЪТЧщЖМЪЧгЩПЊЗЂЙЄГЬЪІРДЭъГЩЃЌЫљвдЫћУЧвВЯЗГЦ
SDE ЪЧ Someone Do Everything ЁЃ
ЫљвдЃЌдЫЮЌзЊаЭВЛЪЧвЛОфЯХЛЃШЫЕФЛАЃЌецЕФвбОдкЮвУЧЩэБпЗЂЩњСЫЁЃ

зюКѓЃЌЫЕвЛЯТЮвУЧецЪЕЕФОРњ
дкЩЯУцетаЉЙ§ГЬжаЃЌЯждкзмНсЯТРДЪЧвЛИі DevOps бнНјЙ§ГЬЃЌЫЕЪЕЛАЃЌЮвУЧЕБЪБВЂУЛга DevOps
ЁЂГжајНЛИЖЛђеп SRE ЕШЕШетаЉИХФюЕФвтЪЖЃЌАкдкЮвУЧУцЧАЕФОЭЪЧвЛИіИіКмЯжЪЕКмЪЕМЪЕФЮЪЬтЃЌЕБЪБЕФзДЬЌвВЪЧвЛСГуТБЦЁЃ
БШШчЮвУЧВЩгУСЫ Java ЕФММЪѕеЛЃЌзіСЫЗўЮёЛЏВ№ЗжжЎКѓЃЌЗЧГЃЯжЪЕЕФЮЪЬтОЭЪЧФудѕУДзіЗЂВМЃЌПЊЗЂећЬьЖЂдкдЫЮЌЦЈЙЩКѓУцЃЌФуУЧдѕУДФмАбЗЂВМаЇТЪЬсЩ§ЩЯШЅЃЌФуУЧФмВЛФмПьЕуЃЌвЕЮёдкКѓУцДпзХЩЯЯпФиЃЌФуУЧдѕУДНтОіЮвЕФЗжХњЗЂВМВЛЭЃЗўЮЪЬтЃЌФуУЧдѕУДЙмРэКУЮвУЧЕФЗжжЇКЯВЂКЭАцБОЙмРэЮЪЬтЃЌФуУЧдѕУДЙмРэКУЮвУЧЕФЖўЗНАќКЭШ§ЗНАќЕШЕШЁЃ
дйБШШчЃЌГіСЫЙЪеЯЃЌвЛШКШЫЖбЕНвЛЦ№вЛЕуЕуХХВщЃЌЖјЧвгаЪБКђевВЛЕНЮЪЬтдкФФЖљЃЌвЕЮёЖМЛжИДВЛСЫЃЌбЙСІЩНДѓЕНвЊБРРЃЃЌЫљвдЕНЕздѕУДФмЬсЩ§ЮШЖЈадЁЂЬсЩ§ХХеЯЕФаЇТЪвВЪЧЖМЪЧвЛИіИіЗЧГЃЗЧГЃЯжЪЕЕФЮЪЬтЁЃ

ЮвУЧФмзіЕФОЭЪЧДгЪЕМЪЮЪЬтКЭвЕЮёГЁОАГіЗЂЃЌгХЯШНтОіНєМБЕФЁЂМЌЪжЕФЮЪЬтЃЌШЛКѓВЛЖЯЕиЭЈЙ§вЕНчЕФЭМЪщЁЂЩчЧјЮФеТЁЂЛсвщКЭДѓХЃбЇЯАЁЂНЛСїКЭЬНЬжЃЌВЛЖЯЕФЭъЩЦЃЌдйОЭЪЧеаЦИЕНгаОбщЕФШЫЃЌетбљПЩвдЩйзпКмЖрЭфТЗЃЌзюКѓвВОЭетбљвЛВНВНзіГЩЯждкетИібљзгСЫЃЌКѓРДВХЗЂЯжЃЌдРДЮвУЧетИіВюВЛЖрвВПЩвдНазі
DevOps СЫЃЌЫфШЛЛЙгаКмЖрПЩвдИФНјКЭЬсЩ§ЕФЕиЗНЁЃ
ЫљвдЮЊЪВУДвЛПЊЪМЬсЕНЫЕЬ§РЯЭѕЕФЗжЯэКмгаИаДЅЃЌЫЕЭъЩЯУцетаЉЪЕМЪЧщПіЃЌЮвУЧЛсЗЂЯжЦфЪЕЙ§ГЬКЭОРњЖМЪЧЯрЫЦЕФЁЃ
ЫфШЛетЦЊЮФеТВфСЫ DevOps ЕФШШЕуЃЌЕЋЪЧЮвЭЈЦЊЖМУЛгаНВЛђЫЕ DevOps РэФюЛђЗНЗЈТлЕФЖЋЮїЃЌЫљвдзюКѓЃЌЛЙЪЧБэДявЛЯТЙлЕуЃЌММЪѕЗЂеЙКЭЛ§РлЖМЪЧБЛвЕЮёИјБЦГіРДЕФЃЌЪЕЪЕдкдкНтОіЮЪЬтВХЪЧе§ЕРЃЌДгБОжЪЩЯЫЕЃЌЮвУЧУЛгаЪВУДЬиБ№жЎДІЃЌжЛЪЧБШНЯавдЫЃЌе§дкОРњетбљвЛИіЙ§ГЬЖјвбЁЃ |









