ДИзгСНФъЧАЕЧТНФЋЖћБОЪБЃЌЭъШЋЪЧDevOpsаЁАзЁЃУцЪдREAЕФЪБКђЃЌБЛЮЪЕНЪВУДЪЧContinuous
DeliveryЃЈГжајНЛИЖЃЉЃЌДИзгГЯПвЕиБэЪОЁАВЛжЊЕРЁБЁЃУцЪдЙйВЛвРВЛШФЃЌЁАВЛжЊЕРВЛвЊНєЃЌФуЯыЯыдѕУДбљВХФмзіЕНContinuous
DeliveryЃПЁБ ДИзгЛиЙЫСЫвЛЯТздМКЮЌЛЄЯюФПЪБЕФиЌУЮЃЌехзУзХгУДЪЫЕЃКЁАеташвЊКУЖрздЖЏЛЏЕФЙЄОпжЇГжЃЌдѕУДВтЪдЃЌдѕУДНгШыВЛЭЌЕФЭјТчЃЌдѕУДВПЪ№ВЛЭЌЕФЛЗОГЃЌЛЙгаЪ§ОнПтЕФdata
migrationКЭЛиЙіЃЌИіЖЅИіЕФЖМЪЧЭДЕуЁЃЁБ
жЎЧАДИзгЫљзіЙ§ЕФЯЕЭГЖМЪЧMonolithЃЈЕЅЬхЃЉМмЙЙЃЌЫљвдЃЌУПДЮашвЊжиЦєЩњВњЛЗОГЪБЃЌецЕУвЛЖјдйЃЌдйЖјШ§ЕиШЗШЯЁЃЫљвдЕБREAЕФЭЌЪТИјЮвНВНтЮвУЧЕФЮЂЗўЮёМмЙЙЃЌКЭдѕУДзіContinuous
DeliveryЪБЃЌЮвЮЪЃКЁАФЧзюЛЕЕФЧщПіОЭЪЧжиЦєЯЕЭГСЫЃПЁБетИіЭЌЪТЫЕЃКЁАВЛЃЌжиЦєЯЕЭГЪЧе§ГЃЧщПіЁЃЁБгЩДЫЃЌДИзгПЊЪМТ§Т§СЫНтREAЧПДѓЕФDevOpsЁЃ
ЮЂЗўЮёКЭDevOps
дкНщЩмREAЕФDevOpsжЎЧАЃЌЛЙЪЧМђЕЅЫЕЫЕЮвУЧЪЙгУЕФЮЂЗўЮёМмЙЙЁЃ
ЮЂЗўЮёгаЪББЛШЫкИВЁЮЅБГСЫDRYддђЃЌЕЋЪЧMonolithМмЙЙЯТИїжжЗўЮёМфЕФЧПёюКЯЖдгкРЉеЙВПЪ№ЖМКмЭДПрЃЌЫљвдDonЁЏt
repeat yourself ГЯШЛВЛДэЃЌЮЂЗўЮёМмЙЙЯТЃЌЖЈвхКУБпНчжЎКѓЃЈAPIsЃЉЃЌУПИіЮЂЗўЮёЖРСЂДцдкЃЌЖРСЂВПЪ№ЧвПЩРЉеЙЃЌМДЪЙгавЛаЉМђЕЅЕФИДжЦеГЬљЃЌЦфДјРДЕФСщЛюадвВЪЧMonolithМмЙЙВЛОпБИЕФЁЃ
дкREAФкВПЃЌЮЊСЫБЃжЄФГжжГЬЖШЕФвЛжТадЃЌЮвУЧЕФЮЂЗўЮёЖМашвЊзёб12 FactorЃК
ЛљзМДњТыЃК вЛЗнЛљзМДњТыЃЌЖрЗнВПЪ№ЁЃ
вРРЕЃК ЯдЪНЩљУївРРЕЙиЯЕЁЃ
ХфжУЃК дкЛЗОГжаДцДЂХфжУЁЃ
КѓЖЫЗўЮёЃК АбКѓЖЫЗўЮёЕБзїИНМгзЪдДЁЃ
ЙЙНЈЃЌЗЂВМЃЌдЫааЃК бЯИёЗжРыЙЙНЈКЭдЫааЁЃ
НјГЬЃК вдвЛИіЛђЖрИіЮозДЬЌНјГЬдЫаагІгУЁЃ
ЖЫПкАѓЖЈЃК ЭЈЙ§ЖЫПкАѓЖЈЬсЙЉЗўЮёЁЃ
ВЂЗЂЃК ЭЈЙ§НјГЬФЃаЭНјааРЉеЙЁЃ
взДІРэЃК ПьЫйЦєЖЏКЭгХбХжежЙПЩзюДѓЛЏНЁзГадЁЃ
ПЊЗЂЛЗОГгыЯпЩЯЛЗОГЕШМлЃК ОЁПЩФмЕФБЃГжПЊЗЂЃЌдЄЗЂВМЃЌЯпЩЯЛЗОГЯрЭЌЁЃ
ШежОЃК АбШежОЕБзїЪТМўСїЁЃ
ЙмРэНјГЬЃК КѓЬЈЙмРэШЮЮёЕБзївЛДЮадНјГЬдЫааЁЃ
ВЛЙ§ВЛЙмЮЂЗўЮёЩшМЦЕУШчКЮОЋСМЃЌЕБвЛИіЁАаЁЖјУРЁБЕФЭХЖгЃЈ5-6УћПЊЗЂШЫдБЃЉашвЊЭЌЪБПЊЗЂЮЌЛЄЩњВњЛЗОГжа10ИівдЩЯЕФЮЂЗўЮёЪБЃЌЗўЮёдЫааКЭЙмРэЩЯЕФЖюЭтИДдгадЪЙЕУШЋздЖЏЙЙНЈКЭВПЪ№БфЕУВЛПЩЛђШБЃЌИќНјвЛВНЃЌзюКУЪЙгУContinuous
DeliveryРДНтОіетаЉЮЪЬтЃЌЖјDevOpsЮЊеце§ЕФContinuous DeliveryЬсЙЉСЫБивЊЕФжЇГжЁЃ
ФЧDevOpsОПОЙЪЧЪВУДЃПDevOpsОЭЪЧИќКУЕФгХЛЏПЊЗЂ(DEV)ЁЂВтЪд(QA)ЁЂдЫЮЌ(OPS)ЕФСїГЬЃЌПЊЗЂдЫЮЌвЛЬхЛЏЃЌЭЈЙ§ИпЖШздЖЏЛЏЙЄОпгыСїГЬРДЪЙЕУШэМўЙЙНЈЁЂВтЪдЁЂЗЂВМИќМгПьНнЁЂЦЕЗБКЭПЩППЁЃ
ЯТУцетеХЭМЃЈЭМЦЌРДдДЪВУДЪЧ DevOpsЃПЃЉОЭЪЧDevOpsЕФШеГЃЁЃ

МШШЛDevOpsВЛЪЧаТЙЄОпЃЌВЛЪЧаТЭХЖгЃЌВЛЪЧаТНЧЩЋЃЌвВВЛЪЧДѓСПжЊЪЖЃЌЖјЧвDevOpsЕФЮАДѓЪЕМљРДздгкаэЖрВЛЭЌЕФСьгђЃЌВЂЧвдкITзщжЏФкжДааЃЌЮЊСЫЬсЩ§ITЕФадФмЃЌФЧЯТУцОЭШУДИзгНВНВREAЕФDevOpsЪЕМљЃЌЪзЯШздШЛДгзюЬљНќЮвУЧГЬађдГЕФШЋЙЄОпСДПЊЪМЁЃ
REA DevOpsШЋЙЄОпСД
REAЪЕМЪЪЙгУЕНЕФШЋЙЄОпСДАќРЈЃК
ДњТыВжПтЃКgithubЦѓвЕАцЁЃ
ЙЙНЈКЭВПЪ№ЙЄОпЃКBuildkiteКЭJenkinsЃЌЛЙгавЛаЉРЯЕФЯюФПвРШЛдкЪЙгУBambooЁЃ
ШнЦїЦНЬЈЃКЮЂЗўЮёгУDockerНјааДђАќЃЌDockerЕФв§ШыШУЙЋЫОФкВПЮЂЗўЮёЕФВПЪ№СїГЬвЛжТЛЏЁЃ
ЛЗОГЃКФПЧАОјДѓВПЗжЕФserviceВПЪ№дкAWSЃЈAmazon Web ServicesЃЉжаЃЌПЊЗЂЛЗОГКЭВтЪдЛЗОГЪЙгУЭЌвЛЬзIAMЃЌЩњВњЛЗОГЪЙгУСэвЛЬзIAMЃЌШ§ЬзЛЗОГЭЈЙ§Virtual
Private Cloud (VPC)ЕФЩшжУНјааИєРыЁЃВЛЭЌВПУХЕФВЛЭЌЕФзщдкIAMЯТгЕгаВЛЭЌНЧЩЋКЭЗУЮЪШЈЯоЁЃВПЪ№ВЩгУAWS
CloudformationЗўЮёЃЌБмУтЪжЖЏДДНЈКЭИќаТЪЙгУЕНЕФAWSЕФвЕЮёЁЃ
ШежОЙмРэЃКsplunkЁЃDockerвбОЬсЙЉЖдSplunkЕФжЇГжЃЌЫљгаЮЂЗўЮёЕФШежОЖМФмЙЛЭЈЙ§Splunk
AgentЗЂЫЭЕНМЏжаЕФSplunkЗўЮёЦїЁЃМЏжаЪНЕФШежОЙмРэЗНЪНЃЌЗНБуГЬађдГУЧНјааtrouble shootingЃЌЖјЧвЭъШЋБмУтСЫЕЧТНЕНВЛЭЌЕФЛњЦїЪеМЏlogЕФОНОГЁЃ
МрПиЃКНЈСЂЗжВуЕФМрПиЬхЯЕЁЃЪЙгУNewRelicгУРДМрПиЭјТчЁЂЩшБИКЭгІгУЕФадФмЃЛЪЙгУAWS CloudwatchМрПиAWSЕФЗўЮёЃЌБШШчФГИіSQSЖдгІЕФdead-letter
queueРяЪЧВЛЪЧЪеЕНСЫЯћЯЂЃЌЛђепAWS LamdaжДааЪЧВЛЪЧгаДэЮѓЕШЃЛNagiosЬсЙЉЗўЮёПЩгУадМрПиЁЃПЩвджБНгЪЙгУREAФкВПЕФrea-health-checkПтЃЌЬсЙЉаФЬјAPIЙЉNagiosЕФжїЖЏФЃЪНЪЙгУЃЛвВПЩвдЭЈЙ§ЩшжУНгЪеЯргІЕФЯћЯЂИёЪНЃЌЪЙгУNagiosБЛЖЏФЃЪНМрПиЮЂЗўЮёЁЃВЛЙмФФжжФЃЪНЯТЗЂЯжЮЪЬтЃЌNagiosТэЩЯЛсВњЩњИцОЏЗЂЫЭЕНPagerDutyЁЃ
ИцОЏЃКPagerDutyЁЃЧАУцЬсЕНЕФМрПиЙЄОпЖМПЩвдЗЂГіИцОЏЃЌетаЉИцОЏЛсЭЈЙ§PagerDutyгУгЪМўЃЌSlackЃЌЕчЛАКЭЖЬаХЕФЗНЪНЭЈжЊИјЕБЪБЕФжЕШеШЫдБЁЃPageDutyЫфШЛЪЧШЋЬь24аЁЪБдЫааЃЌвВжЛгаМЋЩйВПЗжИпгХЯШМЖЕФИцОЏВХЛсдкЗЧЙЄзїЪБМфЗЂГіЁЃЛЙгавЛИіИцОЏЕФРДдДЪЧZendesk
TicketЃЌетжжаХЯЂЭЈГЃжБНгРДздгкПЭЛЇЁЃОЭЮвУЧзщЖјбдЃЌЛљБОЩЯЖМЪЧвЛаЉЪ§ОнДэЮѓЃЌашвЊИіБ№аое§ЁЃ
аЭЌЙЄзїЃКLeankitЁЃ
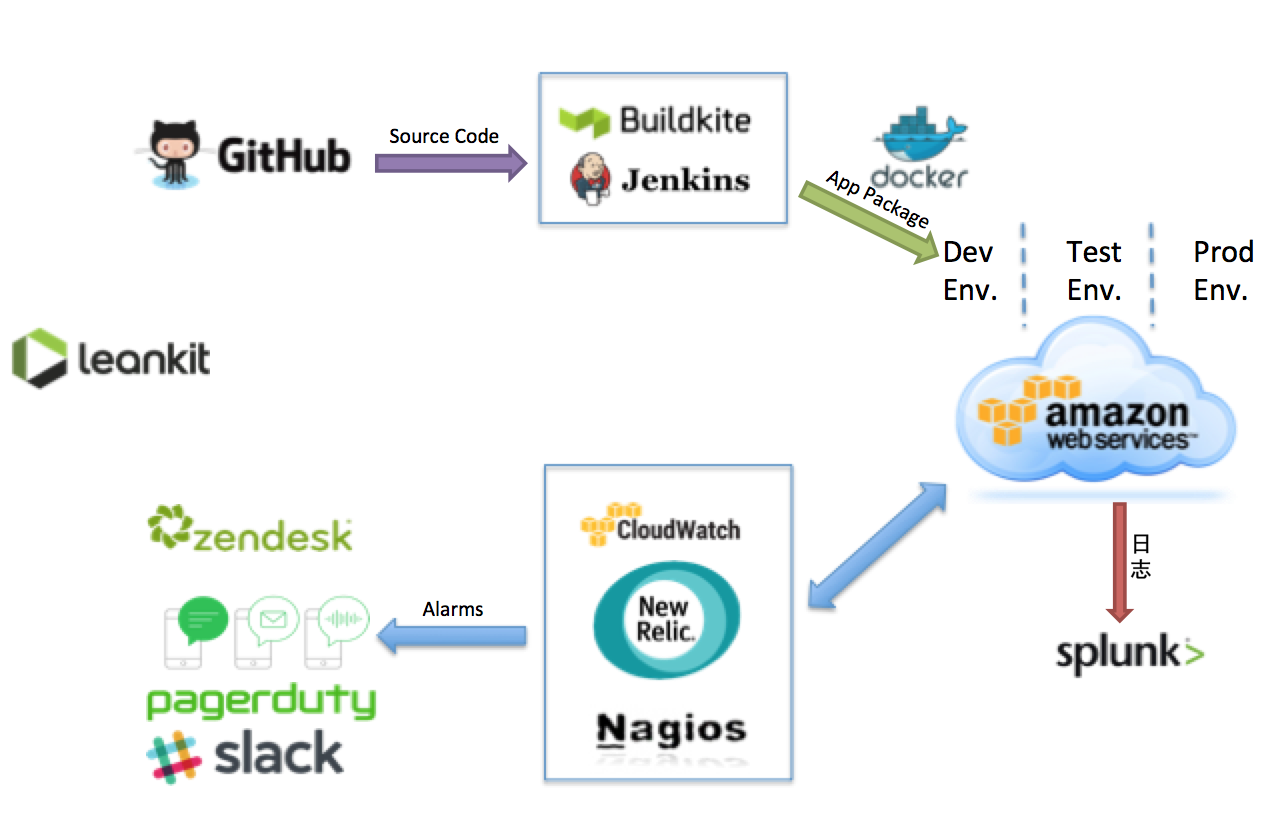
ЙЄОпСДПДЦ№РДВЂВЛИДдгЃЌФЧУДгаСЫЙЄОпСДЃЌЫљгаЕФЮЪЬтОЭгШаЖјНтСЫТ№ЃПД№АИздШЛЪЧЗёЖЈЕФЁЃ
дѕУДбљздЖЏЛЏЫљгаСїГЬЃПдѕбљЮЊREAГЌЙ§40ИізщЙмРэAWSЕФеЫКХЃПдѕУДЮЊAWSРяЕФВтЪдЛЗОГКЭЩњВњЛЗОГХфжУVPCЃПдѕбљАбЮЂЗўЮёВПЪ№ЕНВЛЭЌЕФЛЗОГЃПМрПиЕФВпТддѕУДбљЪЕЪЉЃЌдѕУДбљдкВЛЭЌЕФзщжЎМфаЕїЃПЫљгаЕФМИАйИіЮЂЗўЮёЃЌвЛЕЉФГаЉЮЂЗўЮёГ§СЫЮЪЬтдѕУДАьЕШЕШЁЃетаЉЖМашвЊЙЄОпСДЧаЧаЪЕЪЕЕФТфЕиЁЃ
REA DevOpsЙЄОпСДЕФЪЕЪЉЙ§ГЬжаЃЌЗжВуазїВЛЕЋРхЧхВЛЭЌВПУХЕФд№ШЮЃЌвВШУЫљгаПЊЗЂШЫдБВЮгыЕНOperationЙЄзїжаЃЌШУDevOpsШкШыУПИіITШЫдБЕФШеГЃЁЃ
REA DevOpsЕФЗжВуазї
REA DevOpsВЛЭЌВуУцЕФЮЪЬтгЩВЛЭЌЕФзщИКд№ЃЌШчЯТЭМЁЃ

ВЛЭЌЕФSquadsЃЈREAв§ШыСЫSpotifyФЃЪНЃЉЪЙгУDevOpsЙЄОпСДРДПЊЗЂКЭЮЌЛЄздМКЕФЮЂЗўЮёЁЃЯъЧщЛсдкЯТУцвЛНкНјааНщЩмЁЃ
Delivery EngineeringЭХЖгЃЌЙЫУћЫМвхЃЌОЭЪЧЮЊСЫШУГЬађдГУЧИќПьИќКУЕиЗЂВМгІгУЃЌжївЊжАд№ЪЧЙЄОпЕФПЊЗЂКЭЙмРэЁЃАќРЈДДНЈDocker
RegistryЃЌзМБИКУвбОАВзАСЫБивЊПтЕФbaked Docker imageЃЌгаСЫетаЉЛљзМЕФDocker
ImagesЃЌПЊЗЂЭХЖгдкЮЊздМКЕФЮЂЗўЮёЙЙНЈDocker ImageЕФЪБПЩвдгааЇНкЪЁЪБМфЃЌЛЙФмЙцБмИїжжПтАцБОВЛвЛжТЕФЮЪЬтЁЃDelivery
EngineeringЛЙашвЊЮЊВЛЭЌВПУХХфжУBuildkiteЃЌBuildkiteЕФAgentsВПЪ№дкAWSЕФEC2жаЃЌИљОнашвЊСЌНгЕФЛЗОГЃЌЖрИіAgentsЗжВМдкВЛЭЌЕФVPCЁЃ
зюжЕЕУвЛЬсЕФЪЧDelivery EngineeringПЊЗЂЕФrea-shipperЁЃ
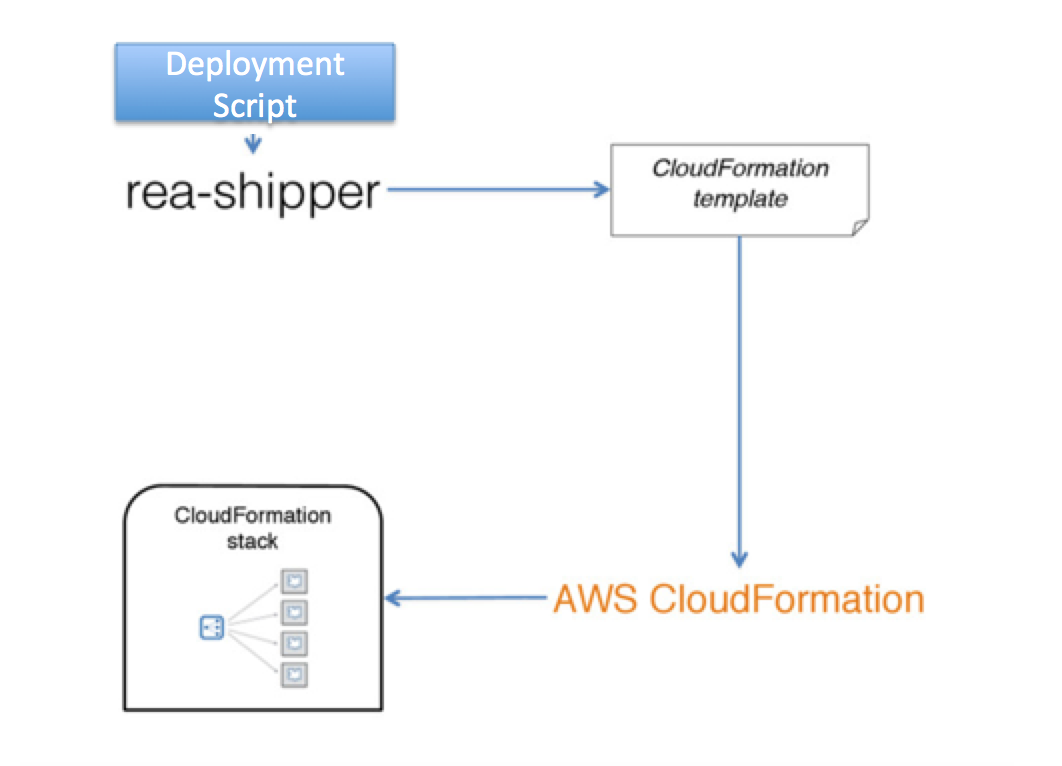
rea-shipperЪЕЯжСЫДгЙЙНЈЕНВПЪ№ЕФШЋздЖЏЃЌеце§НтОіСЫзюЭДЕФФЧИіЕуЁЃ
ЮЊСЫБЃжЄZero downtimeЃЌrea-shipperЖСШЁЮЂЗўЮёЕФcloudformationХфжУЃЌВЩгУimmutable
ASGЃЈauto scaling groupЃЉdeploymentФЃЪН НјааВПЪ№ЁЃ
rea-shipperздЖЏНЋМрПиКЭШежОЙмРэЫљашвЊЕФФЃПщвВгУDockerДђАќЃЌдкВПЪ№Й§ГЬжагыУПИіЮЂЗўЮёЕФDocker
ImageећКЯЃЌШчЯТЭМЫљЪОЁЃетбљЮЂЗўЮёПЊЗЂШЫдБжЛашвЊЙизЂвЕЮёЕФПЊЗЂЃЌЮоашЕЃаФШежОКЭМрПиЕФЮЪЬтЁЃ
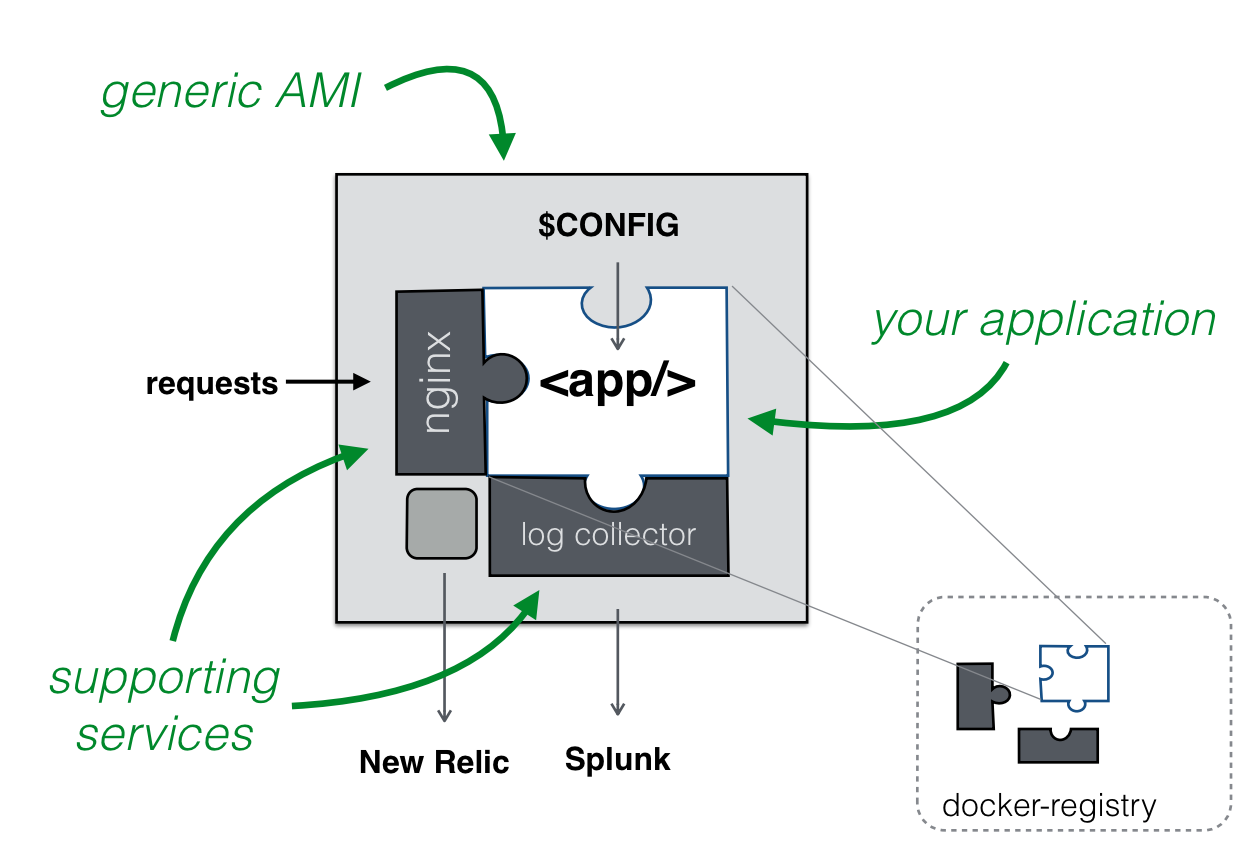
вдЮвУЧвЛИіЪЕМЪЕФservice charge-centralЮЊР§ЃЌЕЧТНЕНEC2 instanceжЎКѓЃЌПЩвдПДЕНе§дкдЫааЕФМИИіcontainerЁЃ

Global Infrastructure & Architecture ЭХЖгИКд№ЛљДЁЩшЪЉНЈЩшЃЌЙмРэЮЌЛЄВЂПЊЗЂЯргІЕФЙЄОпЃЌАќРЈЭјТчЁЂЪ§ОнжааФЁЂAWSеЫКХЕФЙмРэЁЂSplunkЕФМЏГЩЕШЁЃБШШчЃЌШЅФъЯЄФсДѓгъЃЌAmazonЕФЛњЗПБЛЫЎбЭСЫЃЌАФжоДѓХњЭјеОЪмЕНгАЯьЃЌвВАќРЈЮвУЧЙЋЫОЕФвЛаЁВПЗжЃЌЕБЪБПрСЫGIA
teamЕФШЫСЫЁЃ
ЫљвдШЋЙЄОпСДЕФХфжУКЭПЊЗЂЪЧGlobal Infrastructure & Architecture
КЭDelivery EngineeringЕФжАд№ЃЌЖјзїЮЊГЬађдГЕФДИзгЃЌдђЪЧЙЄОпСДЕФЪЙгУепЁЃЯТУцОЭЫЕЫЕГЬађдГЫљВЮгыЕФDevOpsШеГЃЁЃ
ГЬађдГDevOpsШеГЃ
1. Coding
ЧАУцЬсЕНЙ§ДњТыПтЪЙгУgithubЦѓвЕАцЃЌВЩгУgithub flowЁЃ
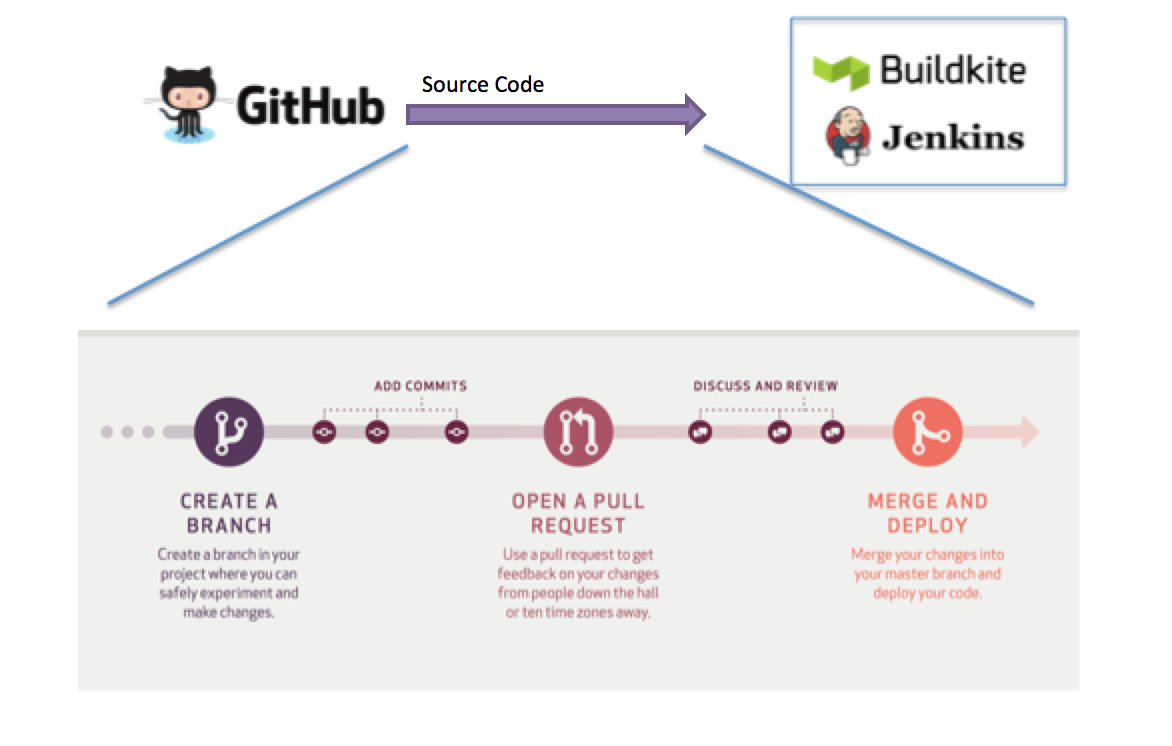
ЮЂЗўЮёашвЊЕФВПЪ№НХБОКЭAWS CloudformationЕФаХЯЂЃЌЬсЙЉИјВЛЭЌМрПиЙЄОпЕФНгПкЃЌfried
Docker image ЖЈвхЕШЃЌвВЖМЪЧДњТыЕФвЛВПЗжЃЌашвЊПЊЗЂШЫдБЭъГЩЁЃ
2. ЙЙНЈКЭВПЪ№
ЙЙНЈКЭВПЪ№ОЭвдBuildkiteЮЊР§згЃЌетЪЧвЛИіЮЂЗўЮёЕФbuildkiteНХБОЁЃ
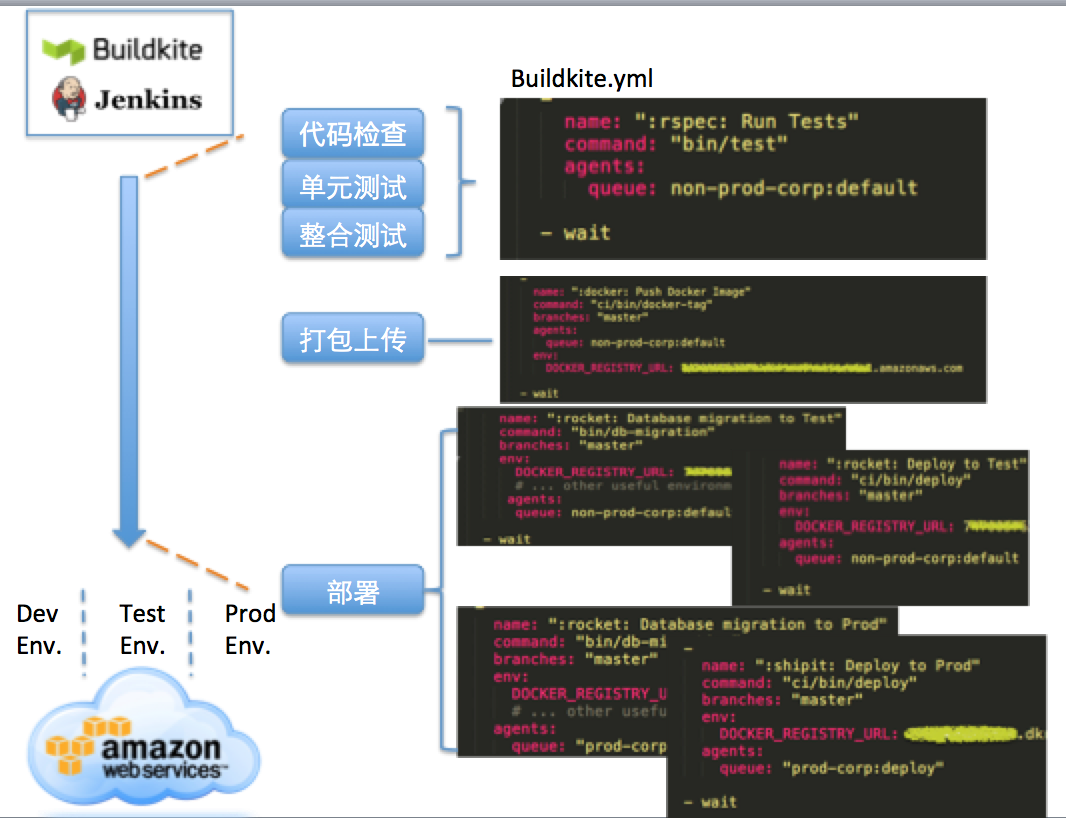
етИіСїГЬРяДњТыМьВщКЭЕЅдЊВтЪдздЖЏЛЏЦ№РДКмШнвзЃЌФЧУДдѕУДзіећКЯВтЪдЃПREAЛљгкIan RobinsonЬсГіЕФгУЯћЗбепЧ§ЖЏЕФЦѕдМНјааУцЯђЗўЮёПЊЗЂЕФФЃЪНПЊЗЂСЫ
ПЊдДЕФPact ВтЪдПђМмЃЌгУЧсСПМЖЕФЦѕдМВтЪдРДДњЬцКёжиЕФМЏГЩВтЪдЁЃPactдкЯћЗбЖЫгУЕЅдЊВтЪдЕФаЮЪНЃЈИќЧсЃЉРДЩњГЩ
pact ЦѕдМЃЌЗўЮёЖЫЭЈЙ§бщжЄЦѕдМРДБЃжЄСНепЮШЖЈМЏГЩЁЃвЛЕЉгавЛЖЫЦѕдМЮДОаЩЬЗЂЩњИФБфЃЌФЧУДPactВтЪдОЭЛсЪЇАмЁЃ
ЙЙНЈГЩЙІжЎКѓЃЌЛсАбЮЂЗўЮёДђАќГЩDocker ImageШЛКѓЩЯДЋЕНDocker RegistryЁЃЮвУЧЛсбЁдёдкDelivery
EngineeringЬсЙЉЕФЛљзМDocker ImageжЎЩЯРДДђАќЃЌетЪЧвЛИіЮЂЗўЮёЕФDockerfileЕФР§згЃК
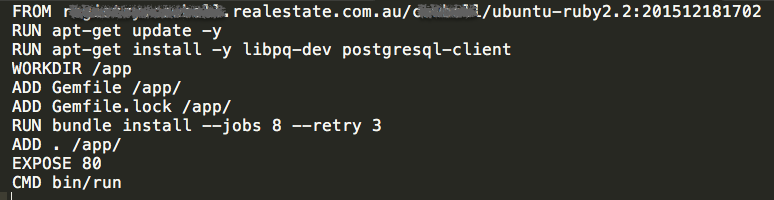
гУетжжЗНЪНЃЌдкbuildkiteЩЯДђАќВЂЩЯДЋЕНDocker RegistryЕФЪБМфаЁгкШ§ЗжжгЁЃ

ВПЪ№ЪБЃЌНХБОЛсЕїгУrea-shipperЁЃВЛЭЌЕФЛЗОГЯТЃЌBuildkiteЛсбЁдёВЛЭЌЕФAgentНјааВПЪ№ЃКTest
ЛЗОГЕФnon-prod-corp:defaultКЭProdЛЗОГЕФprod-corp:defaultЁЃВПЪ№ЕФЪБМфЭЈГЃ10ЗжжгвдФкЃЌЯТУцЪЧвЛИіЮЂЗўЮёВПЪ№ЕНtestЃЈ6Зж1УыЃЉКЭprodЃЈ5Зж43УыЃЉЕФЪБМфЃЌЭМжаФмЙЛПДЕНCloudformationИќаТЕФВНжшЁЃ
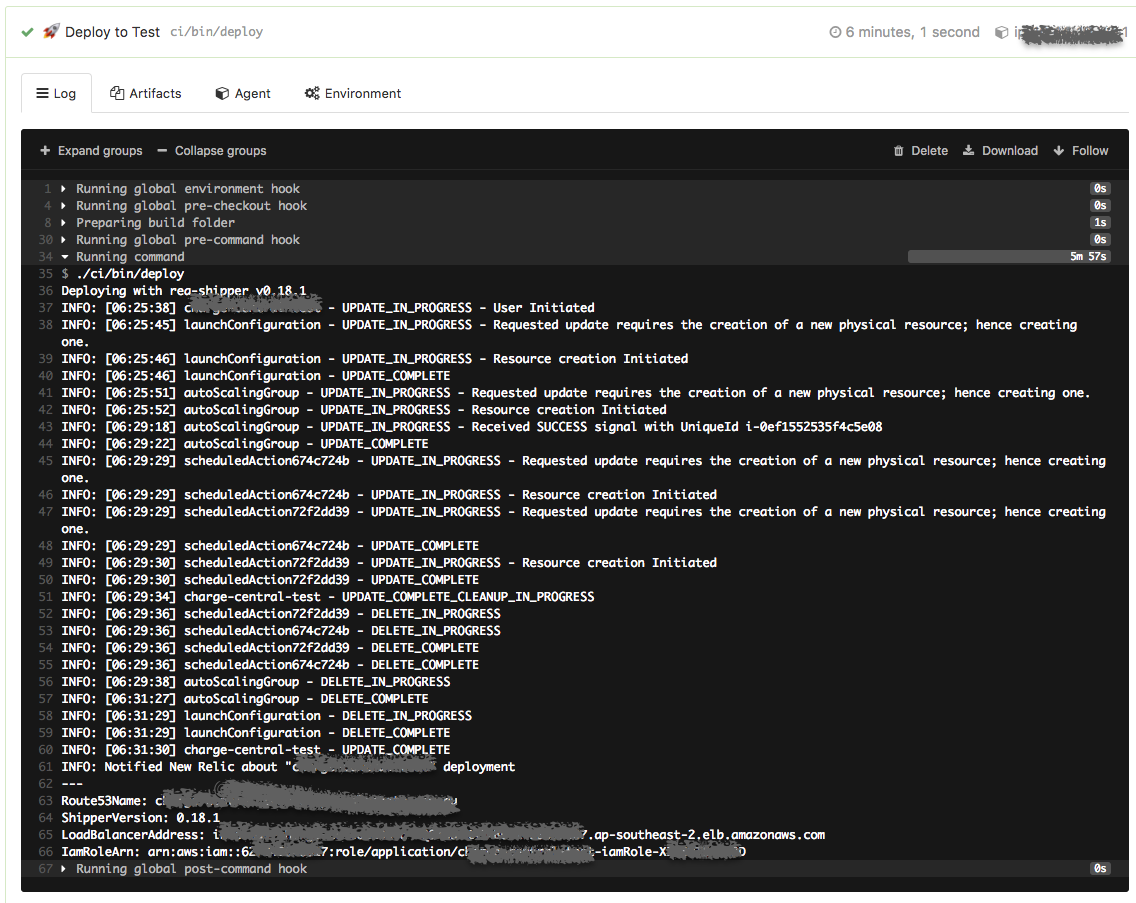
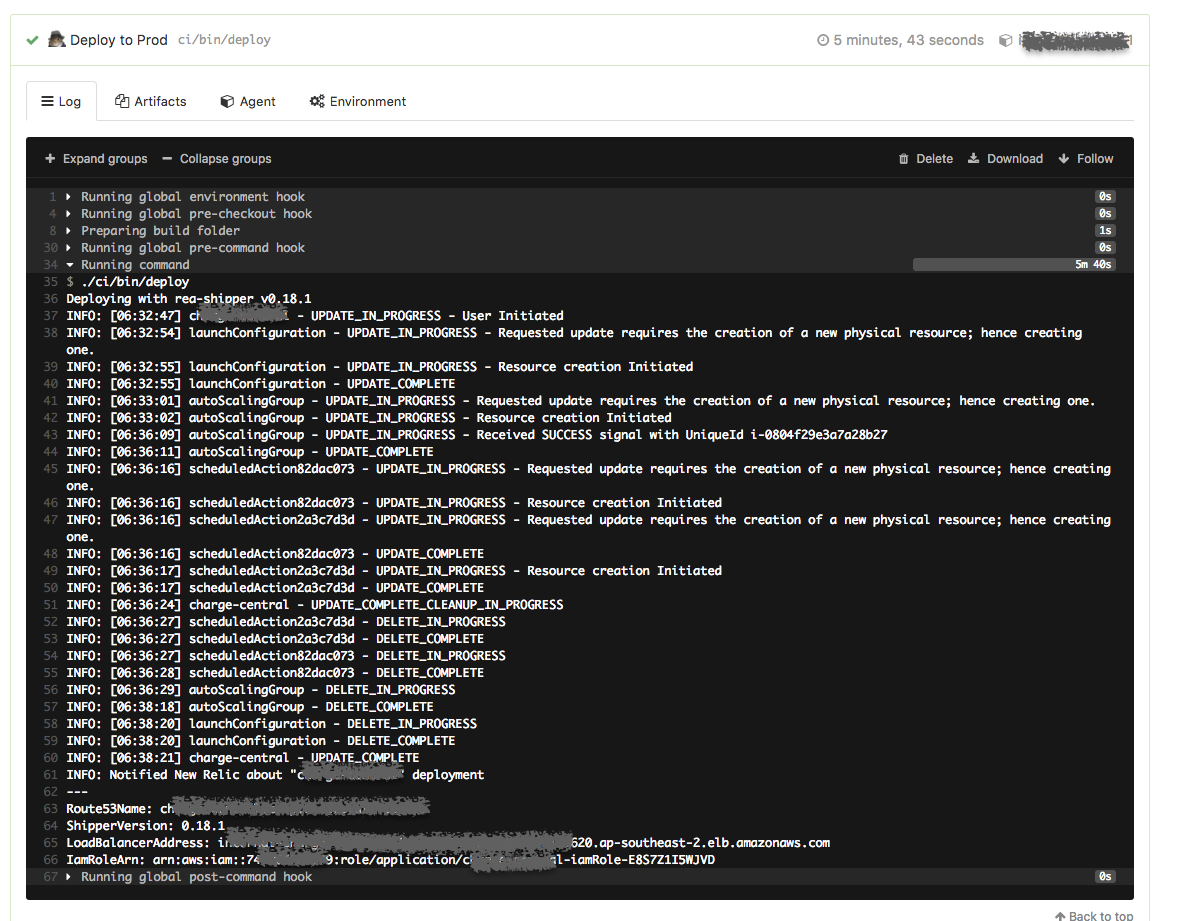
ОЁЙмЪЧШЋздЖЏЕФВПЪ№ЃЌПМТЧЕНЩњВњЛЗОГЕФживЊадЃЌЮвУЧЛЙЪЧбЁдёНїЩїЕиBlockЃЌашвЊФГИіПЊЗЂШЫдБЪжЖЏДЅЗЂЁЃДЅЗЂЕФЪБМфУЛгаЬиБ№ЕФЙцЖЈЃЌжЛЪЧдкЮвУЧЕФkanbanжаЃЌdeployЪЧзюКѓвЛВНЃЌетвтЮЖзХжЛгаеце§ВПЪ№ЕНЩњВњЛЗОГЃЌетИіПЈЦЌВХЫуЭъГЩЁЃШчЙћВПЪ№Й§ГЬжаГіЯжЪЇАмЃЌrea-shipperВЛЛсЧаЛЛдЫаажаЕФASGЃЈAuto
Scalling GroupЃЉЃЌвЕЮёВЂВЛЛсЪмЕНгАЯьЁЃШчЙћВПЪ№ЕФаТАцБОЗЂЯжbugашвЊНєМБЛиЙіЃЌПЩвдКмШнвзЕиИљОнDocker
ImageЕФАцБОевЕНЯргІЕФImageНјааВПЪ№ЁЃ
3. дЫЮЌ
ШеГЃЕФдЫЮЌШчЯТЭМЫљЪОЃК
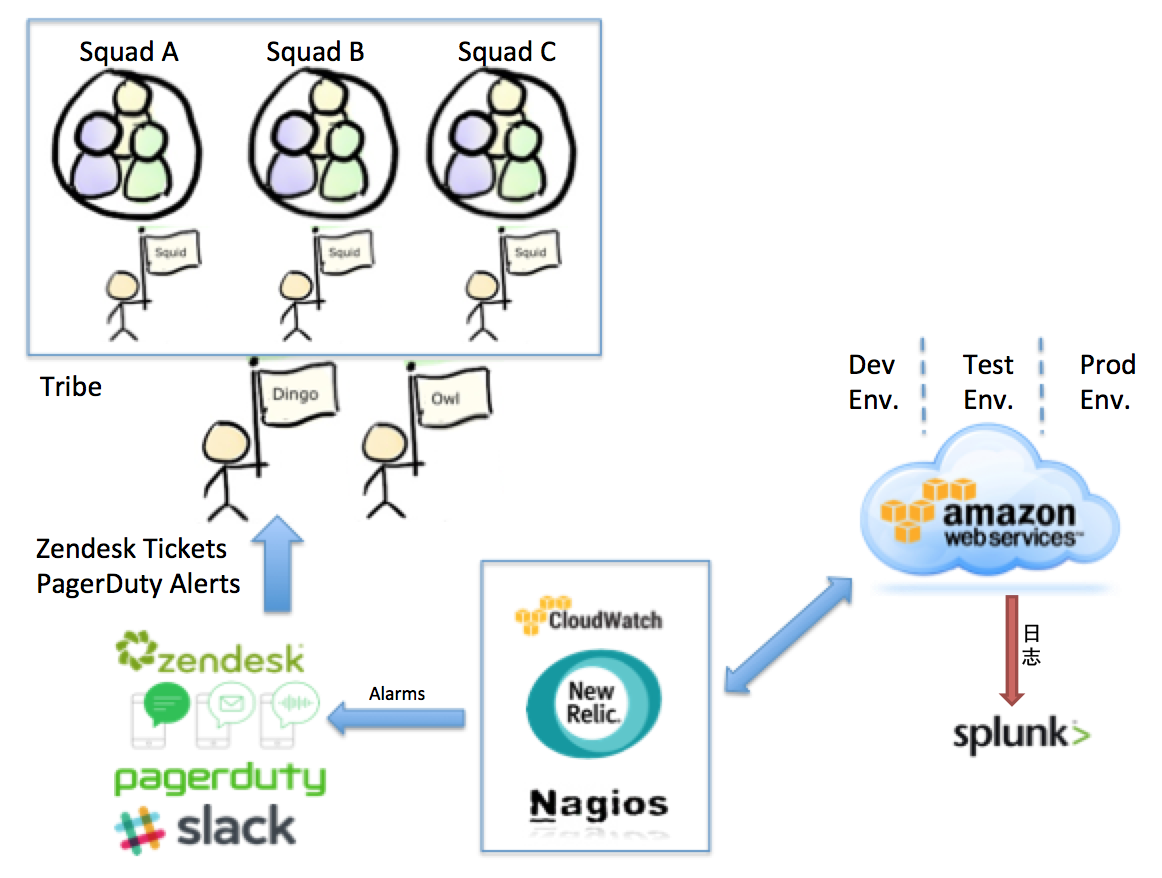
ашвЊДІРэЕФЮЪЬтвЛАугаСНжжЃК
жБНгдДгкПЭЛЇЕФЮЪЬтЃЌЪЙгУZendesk TicketЁЃ
дДгкЩњВњЛЗОГЕФЮЪЬтЃЌБШШчPagerDutyИцОЏЁЃ
ЮвУЧTribeга5ИіSquadЃЌГ§СЫгаГЌЙ§30ИіmicroserviceжЎЭтЃЌЛЙгаИњВЛЭЌЯЕЭГЕФНгПкЃЌШчЙћВЛФмзщжЏКУЃЌПЊЗЂШЫдБУПЬьБиЖЈЛсБЛИїжжЮЪЬтДђШХЁЃЫљвдШчЭМЫљЪОЃЌTribeМЖБ№гаDingoЃЈЙЄзїЪБМфЃЉЛђепOwlЃЈЗЧЙЄзїЪБМфЃЉзїЮЊНгПкШЫЃЌИКд№ДІРэКЭЗжЗЂЮЪЬтЕНSquadМЖБ№ЕФSquidЁЃDingoЃЌOwlКЭSquidЪЧЭХЖгЕФПЊЗЂШЫдБТжИкЁЃ
змНс
БОЮФНщЩмСЫREA DevOpsЕФЪЕМљЃЌАќРЈЙЄОпСДЃЌЙЄОпСДЕФЗжВуазївдМАЪЙгУжаЕФСїГЬЁЃдйРДЖдБШвЛЯТGene
KimЕФ3ИіЗНЗЈЃКСїГЬЃЌЗДРЁКЭГжајбЇЯАЃЌет3ИіЗНЗЈЪЧDevOpsЕФжївЊВПЗжЃЌЬсЙЉвЛжжТЗБъРДРэНтКЭжДааDevOpsЁЃДИзгФмЙЛПДЕНЕФЪЧдкREA
DevOpsЪЕМљжаЃЌУПИіПЊЗЂШЫдБЖМВЮгыЕНСїГЬЕФВЛЖЯгХЛЏжаЃЌШУСїГЬБфЕУИќЫГГЉКЭПьЫйЃЛЭЈЙ§ВЛЭЌЗНЪНПЩЪгЛЏМрПиКЭЗДРЁЃЌвдДяЕНИќПьЕФЗДРЁТЗОЖЃЛПЊЗХШЋДњТыПтИјЫљгаПЊЗЂШЫдБЃЌЙФРјГЬађдГГжајбЇЯАКЭИФНјЕШЕШЁЃ
вдЩЯжжжжЃЌЭЦМідФЖСЮвУЧЙЋЫОЭЌЪТЕФЮФеТРДИќЩюШыЕФСЫНтREAЕФЮФЛЏЁЃScaling On-Call:
from 10 Ops to 100 DevsЃЌНВЪіСЫдѕУДДгетбљЕФзДЬЌЃК

ЕНДяЯТУцЕФзДЬЌЃК
етжжБфЛЏВЂВЛЪЧММЪѕИФНјДјРДЕФЃЌЖјЪЧдДгкГжајбЇЯАЕФЦѓвЕЮФЛЏЁЃЖјетЃЌе§ЪЧDevOpsзюашвЊЕФЁЃ |









