ΉνΫϋΈ“‘ΡΕΝΝΥΚήΕύ”–ΙΊDevOpsΒΡΈΡ’¬Θ§Τδ÷–“Μ–©Ζ«≥Θ”–»ΛΘ§»ΜΕχ“Μ–©ΡΎ»ί“≤Κή«ΖΩΦ¬«ΓΘΟ≤ΥΤΚήΕύ»Υ‘Ϋά¥‘ΫΦαΕ®ΒΊ‘ΎDevOps”κchefΓΔpuppetΜρDocker»ίΤςΒΡ λΝΖ‘Υ”ΟΖΫΟφΜ°ΝΥΒ»Κ≈ΓΘΕ‘¥ΥΈ“”–≤ΜΆ§Ω¥Ζ®ΓΘDevOpsΒΡΖΕ≥κ‘Ε‘Ε≥§ΙΐpuppetΜρDockerΒ»ΙΛΨΏΓΘ
’β―υΒΡΩ¥Ζ®…θ÷Ν»ΟΈ“Η–Ψθ”––©ΤχΖΏΓΘDevOps‘ΎΈ“Ω¥ά¥ΦΪΈΣ÷Ί“ΣΘ§Ιΐ»Ξ15Ρξά¥Θ§Έ““Μ÷±‘Ύ¥σ–ΆΜζΙΙΘ§÷ς“Σ «¥σ–ΆΫπ»ΎΜζΙΙ÷–¥” ¬ΙΛ≥Χ“ΒΈώΓΘDevOps «“Μ÷÷Ζ«≥Θ÷Ί“ΣΒΡΖΫΖ®¬έΘ§ΗΟΖΫΖ®ΫΪΫβΨω“Μ–©Ήν¥σ–ΆΈ ΧβΒΡΜυ±Ψ‘≠‘ρΚΆ ΒΦυ«Γ»γΤδΖ÷ΒΊ»ΎΈΣ“ΜΧεΘ§ΚήΚΟΒΊΫβΨωΝΥ¥ΥάύΜζΙΙΒΡ»μΦΰΩΣΖΔœνΡΩ÷–“Μ÷÷ΉνΝν»ΥΗ–Ψθ±·ΝΙΒΡ ßΑή“ΣΥΊΘΚΩΣΖΔ’ΏΚΆ‘ΥΈ§»Υ‘±÷°ΦδΒΡΜ묓÷°«ΫΓΘ
«κ≤Μ“ΣΈσΜαΈ“ΒΡ’β÷÷ΙέΒψΘ§≥ΐΝΥΡ≥–©XP ΒΦυΘ§¥σ≤ΩΖ÷¥Υάύ¥σ–ΆΜζΙΙΕ‘ΟτΫίΩΣΖΔΖΫΖ®¬έΒΡ‘Υ”ΟΜΙ”–Κή≥ΛΒΡ¬Ζ“ΣΉΏΘ§Ά§ ±ΜΙ”–ΚήΕύΤδΥϊ‘≠“ρΜαΒΦ÷¬»μΦΰΩΣΖΔœνΡΩΒΡ ßΑήΜρ―”ΈσΓΘ
ΒΪ‘ΎΈ“Ω¥ά¥Θ§Μ묓÷°«ΫΡΩ«Α“ά»Μ «ΥϊΟ«ΥυΟφΝΌΒΡΉνΝν»ΥΨΎ…ΞΓΔΉνάΥΖ― ±ΦδΓΔΆ§ ±“≤œύΒ±”ό¥άΒΡΈ ΧβΓΘ
”κΤδΕάΉ‘…ζΟΤΤχΘ§Έ“ΨθΒΟ≤Μ»γΥΒΒψΗϋ Β‘ΎΒΡΕΪΈςΘ§–¥“ΜΤΣΨΓΩ…ΡήΨΪΉΦΒΡΈΡ’¬Θ§œρ¥σΦ“Ϋι…ήDevOpsΒΫΒΉ « ≤Ο¥Θ§ΡήΈΣΈ“Ο«¥χά¥ ≤Ο¥ΓΘ≥ΛΜΑΕΧΥΒΘ§DevOps≤Δ≤Μ «Ρ≥“ΜΧΉΙΛΨΏΓΘDevOps «“Μ÷÷ΖΫΖ®¬έΘ§Τδ÷–ΑϋΚ§“ΜœΒΝ–Μυ±Ψ‘≠‘ρΚΆ ΒΦυΘ§Ϋω¥ΥΕχ“―ΓΘΕχΥυ”ΟΒΡΙΛΨΏΘ®Μρ’ΏΥΒΓΑΙΛΨΏΝ¥Γ±Α…Θ§±œΨΙ”Ο”ΎΈΣ’β–© ΒΦυΧαΙ©÷ß≥÷ΒΡΙΛΨΏΦ·”–Ή≈ΦΪΗΏΒΡά©’Ι–‘Θ©÷Μ «ΈΣΝΥΕ‘’β―υΒΡ ΒΦυΧαΙ©÷ß≥÷ΓΘ
Ήν÷’ά¥ΥΒΘ§’β–©ΙΛΨΏ±Ψ…μ≤Δ≤Μ÷Ί“ΣΓΘœύ±»ΝΫΡξ«ΑΘ§ΡΩ«ΑΒΡDevOpsΙΛΨΏΝ¥“―Ψ≠≤ζ…ζΝΥΖ≠ΧλΗ≤ΒΊΒΡ±δΜ·Θ§Ω…œκΕχ÷ΣΘ§ΝΫΡξΚσΜΙΜα≤ζ…ζΗϋ¥σΒΡ≤ν“λΓΘ≤ΜΙΐ’β≤Δ≤Μ÷Ί“ΣΓΘ÷Ί“ΣΒΡ «ΡήΙΜΚœάμΒΊάμΫβ’β–©Μυ±Ψ‘≠‘ρΚΆ ΒΦυΓΘ
±ΨΈΡ≤Δ≤ΜΉΦ±ΗΫι…ήΡ≥–©ΙΛΨΏΝ¥Θ§…θ÷ΝΆξ»Ϊ≤ΜΜαΧαΒΫ’β–©ΙΛΨΏΓΘΆχ…œΧ÷¬έDevOpsΙΛΨΏΝ¥ΒΡΈΡ’¬“―Ψ≠ΧΪΕύΝΥΓΘΈ“œκ‘Ύ±ΨΈΡ÷–ΧΗΧΗΉνΜυ±ΨΒΡ‘≠‘ρΚΆ ΒΦυΘ§ΥϋΟ«ΒΡ÷ς“ΣΡΩΒΡΘ§±œΨΙ’β–©≤≈ «Ε‘Έ“Εχ―‘Ήν÷Ί“ΣΒΡΓΘ
DevOps «“Μ÷÷ΖΫΖ®¬έΘ§ΙιΡ…ΉήΫαΝΥΟφΝΌΕά“ΜΈόΕΰΒΡΜζ”ωΚΆ«Ω”–ΝΠ–η«σΒΡΆχ¬γΨόΆΖΟ«Θ§ΫαΚœΉ‘…μ“ΒΈώ±Ψ÷ ΙΙΥΦ≥ω»Ϊ–¬ΙΛΉςΖΫ ΫΒΡΙΐ≥Χ÷–Υυ≤…”ΟΒΡ ΒΦυΘ§ΕχΥϊΟ«ΒΡ“ΒΈώ–η«σ“≤Κή÷±Ϋ”ΘΚ“‘ ΖΈό«ΑάΐΒΡΫΎΉύΕ‘Ή‘ΦΚΒΡœΒΆ≥Ϋχ––―ίΫχΘ§”– ±ΚρΩ…ΡήΜΙ–η“Σ“‘ΧλΈΣΒΞΈΜΕ‘œΒΆ≥Μρ“ΒΈώΫχ––ά©’ΙΓΘ
Υδ»ΜDevOpsΕ‘≥θ¥¥ΙΪΥΨά¥ΥΒΚήΟςœ‘ «≤ΜΩ…Μρ»±ΒΡΘ§ΒΪΈ“»œΈΣΡ«–©”–Ή≈≈”¥σΒΡάœ ΫIT≤ΩΟ≈ΒΡ¥σΤσ“Β≤≈ «Ρή¥”’β–©Μυ±Ψ‘≠‘ρΚΆ ΒΦυ÷–ΜώΒΟΉν¥σ ’“φΒΡΓΘ±ΨΈΡΫΪ ‘ΆΦΫβ ΆΒΟ≥ω’βΗωΫα¬έΒΡ‘≠“ρΚΆ Βœ÷ΖΫΖ®ΓΘ
1. ΦρΫι
DevOpsΥυΙΊΉΔΒΡ≤Μ «ΙΛΨΏ±Ψ…μΘ§“≤≤Μ «Ε‘chefΜρDockerΒΡ’ΤΈ’≥ΧΕ»ΓΘDevOps «“Μ÷÷ΖΫΖ®¬έΘ§ «“ΜœΒΝ–Ω…“‘Αο÷ζΩΣΖΔ’ΏΚΆ‘ΥΈ§»Υ‘±‘Ύ Βœ÷ΗςΉ‘ΡΩ±ξΘ®GoalΘ©ΒΡ«ΑΧαœ¬Θ§œρΉ‘ΦΚΒΡΩΆΜßΜρ”ΟΜßΫΜΗΕΉν¥σΜ·Φέ÷ΒΦΑΉνΗΏ÷ ΝΩ≥…ΙϊΒΡΜυ±Ψ‘≠‘ρΚΆ ΒΦυΓΘ
ΩΣΖΔ’ΏΚΆ‘ΥΈ§»Υ‘±÷°ΦδΉν¥σΒΡΈ Χβ‘Ύ”ΎΘΚΥδ»ΜΕΦ «Τσ“Β÷–¥σ–ΆIT≤ΩΟ≈≤ΜΩ…Μρ»±ΒΡΘ§ΒΪΥϊΟ«”–Ή≈ΫΊ»Μ≤ΜΆ§ΒΡΡΩΒΡΘ®ObjectiveΘ©ΓΘ
ΩΣΖΔ’ΏΚΆ‘ΥΈ§»Υ‘±÷°ΦδΡΩΒΡ…œΒΡ≤ν“λΨΆΫ–ΉωΜ묓÷°«ΫΓΘœ¬ΈΡΜαΫι…ή’βΗωΗ≈ΡνΒΡΉΦ»ΖΕ®“εΘ§“‘ΦΑΈΣ ≤Ο¥Έ“»œΈΣ’β÷÷Ή¥ΩωΚή―œΨΰ≤Δ«“Κή‘ψΗβΓΘ
DevOps «“Μ÷÷»ΎΚœΝΥ“ΜœΒΝ–Μυ±Ψ‘≠‘ρΚΆ ΒΦυΒΡΖΫΖ®¬έΘ®≤Δ¥”’β–© ΒΦυ÷–≈……ζ≥ωΝΥΗς÷÷ΙΛΨΏΘ©Θ§“β‘ΎΑο÷ζ’β–©»Υ‘±œρΉ≈“ΜΗωΆ≥“ΜΒΡΙ≤Ά§ΡΩΒΡ≈§ΝΠΘΚΨΓΩ…ΡήΈΣΙΪΥΨΧαΙ©ΗϋΕύΦέ÷ΒΓΘ
Νν»ΥΨΣΤφΒΡ «Θ§’βΗωΈ ΧβΨΙ»Μ”–“ΜΗωΖ«≥ΘΦρΒΞΒΡΓΑ“χΉ”Β·Γ±ΘΚ»Ο…ζ≤ζΕΥ±δΒΟΟτΫίΤπά¥ΘΓ
Εχ’β«Γ«Γ’ΐ «DevOpsΥυ“Σ¥ο≥…ΒΡΈ®“ΜΡΩ±ξΘΓ
ΒΪ‘ΎΫχ“Μ≤ΫΧ÷¬έ’β“ΜΒψ÷°«ΑΘ§ Ήœ»–η“ΣΧΗΧΗΤδΥϊΦΗΦΰ ¬ΓΘ
1.1 Ιήάμ–≈Χθ
ITΙήάμ’β≥Γ’Ϋ’υΒΡ‘≠Ε·ΝΠΒΫΒΉ « ≤Ο¥ΘΩΜΜΨδΜΑΥΒΘ§‘Ύ»μΦΰΩΣΖΔœνΡΩ÷–Θ§ΙήάμΙΛΉς Ή“ΣΒΡΘ§“‘ΦΑΉν÷Ί“ΣΒΡΡΩΒΡ « ≤Ο¥ΘΩ
”– ≤Ο¥œκΖ®¬πΘΩ
Έ“ά¥ΧαΙ©“ΜΗωœΏΥςΑ…ΘΚ‘ΎΫ®ΝΔ“ΜΦ“≥θ¥¥ΙΪΥΨ ±Θ§Ήν÷Ί“ΣΒΡ ¬«ι « ≤Ο¥ΘΩ
Β±»Μ «“ΣΦ”Ωλ…œ – ±ΦδΘ®TTMΘ©ΘΓ
…œ – ±ΦδΘ®Φ¥TTMΘ© «÷Η“ΜΦΰ≤ζΤΖ¥”Ήν≥θΒΡΙΙΥΦΒΫΉν÷’Ω…Ι©”ΟΜß Ι”ΟΜρΙΚ¬ρ’β“ΜΙΐ≥ΧΥυ–η“ΣΒΡ ±ΦδΓΘΕ‘”Ύ≤ζΤΖΚήΩλΜαΙΐ ±ΒΡ––“ΒΘ§TTM «“ΜΗωΖ«≥Θ÷Ί“ΣΒΡΗ≈ΡνΓΘ
‘Ύ»μΦΰΙΛ≥ΧΖΫΟφΘ§Υυ≤…”ΟΒΡΖΫΖ®ΓΔ“ΒΈώΘ§“‘ΦΑΨΏΧεΦΦ θΦΗΚθΟΩΡξΕΦΜα±δΜ·Θ§“ρΕχTTMΨΆ≥…ΝΥ“ΜΗωΖ«≥Θ÷Ί“ΣΒΡKPIΘ®ΙΊΦϋΦ®–ß÷Η±ξΘ©ΓΘ
TTMΆ®≥Θ“≤Μα±ΜΫ–Ήω«Α÷Ο ±ΦδΘ®Lead TimeΘ©ΓΘ
ΒΎ“ΜΗωΈ Χβ‘Ύ”ΎΘ§Θ®ΚήΕύ»Υ»œΈΣΘ©‘ΎΩΣΖΔΙΐ≥Χ÷–TTMΚΆ≤ζΤΖ÷ ΝΩ «ΝΫΗωΕ‘ΝΔΒΡ τ–‘ΓΘ‘Ύœ¬ΈΡΩ…“‘Ω¥ΒΫΘ§ΗΡ…Τ÷ ΝΩΘ®ΫχΕχΧαΗΏΈ»Ε®–‘Θ© «‘ΥΈ§»Υ‘±ΒΡΡΩΒΡΘ§ΕχΩΣΖΔ’ΏΒΡΡΩΒΡ‘Ύ”ΎΫΒΒΆ«Α÷Ο ±ΦδΘ®ΫχΕχΧαΗΏTTMΘ©ΓΘ
«κ»ίΈ“ά¥Ϋβ Ά“Μœ¬ΓΘ
ITΉι÷·Μρ≤ΩΟ≈Ά®≥ΘΜαΆ®ΙΐΝΫΗωΙΊΦϋΒΡKPIΫχ––ΤάΙάΘΚ»μΦΰ±Ψ…μΒΡ÷ ΝΩΘ§“ρΕχ–η“ΣΨΓΩ…ΡήΦθ…Ό»±œίΒΡ ΐΝΩΘΜ¥ΥΆβΜΙ”–TTMΘ§“ρΕχ–η“ΣΫΪ“ΒΈώΙΙœκΘ®Ά®≥Θ”…“ΒΈώ”ΟΜßΧαΙ©Θ©±δΈΣΉν÷’≥…ΙϊΘ§≤Δ“‘ΨΓΩ…ΡήΩλΒΡΥΌΕ»ΧαΙ©Ηχ”ΟΜßΜρΩΆΜßΓΘ
’βάοΒΡΈ Χβ‘Ύ”ΎΘ§¥σ≤ΩΖ÷«ιΩωœ¬’βΝΫΗωΫΊ»Μ≤ΜΆ§ΒΡΡΩΒΡ «”…ΝΫΗω≤ΜΆ§Ά≈Ε”ΧαΙ©÷ß≥÷ΒΡΘΚΗΚ‘πΙΙΫ®»μΦΰΒΡΩΣΖΔ’ΏΘ§“‘ΦΑΗΚ‘π‘Υ––»μΦΰΒΡ‘ΥΈ§»Υ‘±ΓΘ
1.2 “ΜΗωΒδ–ΆΒΡITΉι÷·
‘ΎΉι÷·ΡΎ≤ΩΗΚ‘πΙήάμ÷Ί“ΣIT≤ΩΟ≈ΒΡΒδ–ΆITΉι÷·Ά®≥ΘΩ¥Τπά¥ «’β―υΒΡΘΚ
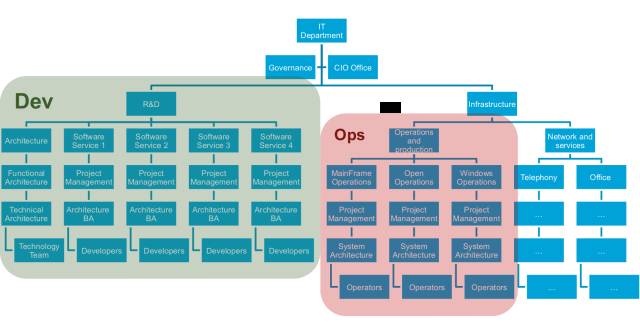
÷ς“Σ”…”Ύάζ ΖΒΡ‘≠“ρΘ®¥σ≤ΩΖ÷‘ΥΈ§»Υ‘±ά¥Ή‘”≤ΦΰΚΆΒγ–≈“ΒΈώΝλ”ρΘ©Θ§‘ΥΈ§»Υ‘±ΚΆΩΣΖΔ’ΏΖ÷ τ≤ΜΆ§ΒΡΉι÷·ΫαΙΙΖ÷÷ßΓΘΩΣΖΔ’Ώ τ”Ύ―–ΖΔ≤ΩΟ≈Θ§Εχ‘ΥΈ§»Υ‘±¥σ≤ΩΖ÷ ±Κρ τ”ΎΜυ¥ΓΦήΙΙ≤ΩΟ≈Θ®ΜρΉ®Ο≈ΒΡ‘ΥΈ§≤ΩΟ≈Θ©ΓΘ
±πΆϋΝΥΘ§ΥϊΟ«”–Ή≈≤ΜΆ§ΒΡΡΩΒΡΘΚ
¥ΥΆβΉςΈΣ≈‘ΉΔΘ§’βΝΫΗωΆ≈Ε””– ±ΚρΜα Ι”Ο≤ΜΆ§ΒΡ‘ΛΥψά¥‘Υ”ΣΓΘΩΣΖΔΆ≈Ε” Ι”ΟΙΙΫ®Θ®BuildΘ©‘ΛΥψΘ§‘ΥΈ§Ά≈Ε” Ι”Ο‘Υ”ΣΘ®RunΘ©‘ΛΥψΓΘ≤ΜΆ§ΒΡ‘ΛΥψΘ§Ε‘ΩΊ÷Τ»®‘Ϋά¥‘ΫΗΏΒΡ–η«σΘ§“‘ΦΑΤσ“ΒIT≥…±ΨΒΡΥθΥ°Θ§’β–©“ρΥΊΫαΚœ‘Ύ“ΜΤπΜαΫχ“Μ≤ΫΖ≈¥σΝΫΗωΆ≈Ε”ΗςΉ‘ΡΩΒΡΒΡΕ‘ΝΔ–‘ΓΘ
Θ®“ά±Ψ»Υ”όΦϊΘ§ ±÷ΝΫώ»’Θ§ΥφΉ≈»Υ”κ»Υ÷°ΦδΈό ±ΈόΩΧΥφ ±ΥφΒΊΫχ––ΒΡΫΜΜΞΘ§“‘ΦΑ”…≤ΜΆ§ΡΩΒΡΆΤΕ·Ή≈Τσ“ΒΚΆ…γΜαΫχ–– ΐΉ÷Μ·ΉΣ–ΆΘ§IT‘ΛΥψΖΫΟφΙ≈άœΒΡΓΑΙφΜ°/ΙΙΫ®/‘Υ––Γ±ΩρΦή“―Ψ≠≤ΜΡ«Ο¥ΚœάμΝΥΘ§≤ΜΙΐ’β”÷ «Νμ“ΜΜΊ ¬ΝΥΓΘΘ©
1.3 ‘ΥΈ§»Υ‘±≤β¥λΑήΗ–
Ϋ”œ¬ά¥Ω¥Ω¥‘ΥΈ§»Υ‘±Θ§“ΜΤπΩ¥Ω¥Βδ–ΆΒΡ‘ΥΈ§Ά≈Ε”Α―¥σ≤ΩΖ÷ ±ΦδΕΦΜ®‘ΎΡΡάοΝΥΘΚ
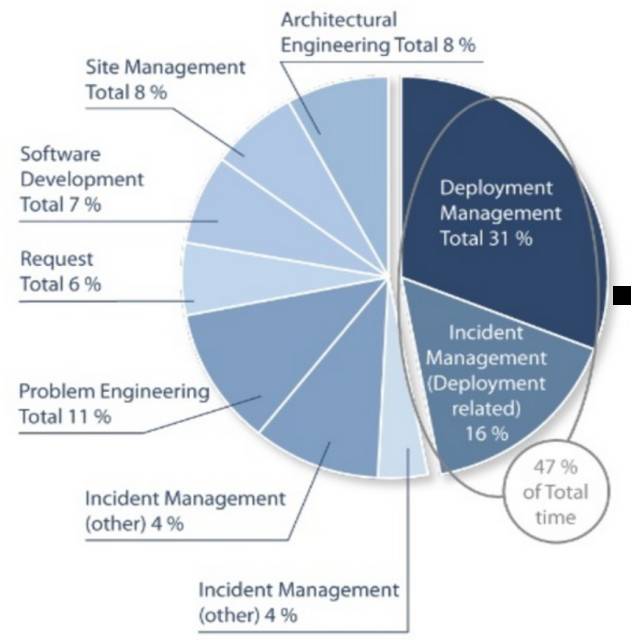
‘ΥΈ§Ά≈Ε”ΒΡ ±ΦδΖ÷≈δ
Θ®ά¥‘¥ΘΚStudy from Deepak Patil [Microsoft Global Foundation Services] in 2006, via James Hamilton [Amazon Web Services] [http://mvdirona.com/jrh/TalksAndPapers/JamesHamilton_POA20090226.pdf]5Θ©
…ζ≤ζΆ≈Ε””–ΫΪΫϋ“ΜΑκΘ®47%Θ©ΒΡ ±ΦδΜ®‘ΎΝΥ”κ≤Ω π”–ΙΊΒΡΙΛΉς÷–ΘΚ
- ÷¥–– ΒΦ ΒΡ≤Ω πΙΛΉς
- Μρ–όΗ¥”κ≤Ω πΙΛΉς”–ΙΊΒΡΈ Χβ
’β―υΒΡKPIΤδ ΒœύΒ±ΖηΩώΘ§ΒΪ ΒΦ …œΈ“Ο«‘γΨΆ”ΠΗΟ≤…Ρ…ΓΘ ΒΦ …œ‘γ‘Ύ40Ρξ«ΑΘ§ΦΤΥψΜζΩΤ―ßΒΡΓΑ‘≠ Φ ±¥ζΓ±ΨΆ“―”Ωœ÷≥ω‘ΥΈ§Ά≈Ε”Θ§Β± ±ΦΤΥψΜζ÷ς“Σ‘Υ”Ο‘ΎΙΛ“ΒΫγΘ§‘ΥΈ§»Υ‘±–η“Σ ÷ΙΛ‘Υ––¥σΝΩΟϋΝνά¥÷¥––Ή‘ΦΚΒΡ»ΈΈώΓΘΈΣΝΥ¬Ρ––÷Α‘πΘ§ΥϊΟ«“―Ψ≠œΑΙΏ”ΎΑ¥’’«εΒΞ‘Υ––Ης÷÷Ης―υΒΡΟϋΝνΜρ ÷ΙΛΝς≥ΧΓΘ
ΆΜ»Μ”–“ΜΧλΥϊΟ«÷’”Ύ“β ΕΒΫΉ‘ΦΚΓΑΉή‘ΎΉωΉ≈œύΆ§ΒΡ ¬«ιΓ±Θ§»ΜΕχ≥Λ¥οΥΡ °ΕύΡξΒΡΙΛΉςΙΐ≥Χ÷–»¥ΦΗΚθΟΜ»ΥΩΦ¬«Ιΐ±δΗοΓΘ
ΩΦ¬«ΒΫ’β“ΜΒψΡψΜαΖΔœ÷Θ§ Β‘Ύ «ΧΪΖηΩώΝΥΓΘΤΫΨυά¥ΥΒΘ§‘ΥΈ§»Υ‘±ΫΪΫϋ“ΜΑκΒΡ ±ΦδΕΦ‘Ύ¥Πάμ”κ≤Ω π”–ΙΊΒΡ»ΈΈώΘΓ
ΈΣΝΥΗΡ±δ’β÷÷Ή¥ΩωΘ§±Ί–κΩΦ¬«ΒΫΝΫΗωΉνΙΊΦϋΒΡ–η«σΘΚ
- Ά®ΙΐΉ‘Ε·Μ·≤Ω πΫΪΡΩ«Α’β÷÷ ÷ΙΛ»ΈΈώΥυ–ηΒΡ ±ΦδΦθ…Ό31%ΓΘ
- Ά®Ιΐ≤ζ“ΒΜ·¥κ ©Θ®άύΥΤ”ΎΆ®ΙΐXPΚΆΟτΫί Βœ÷ΒΡ»μΦΰΩΣΖΔ≤ζ“ΒΜ·Θ©ΫΪ–η“Σ¥ΠάμΒΡ”κ’β–©≤Ω π”–ΙΊΒΡΈ ΧβΦθ…Ό16%ΓΘ
1.4 Μυ¥ΓΦήΙΙΉ‘Ε·Μ·
‘Ύ’βΖΫΟφ“≤”–“ΜΗωœύΒ±ΗΜ”–ΤτΖΔ–‘ΒΡΆ≥ΦΤΫαΙϊΘΚ
“‘ ÷ΙΛ≤ΌΉςΒΡ ΐΝΩΥυ±μ ΨΒΡ≥…ΙΠ≤Ω πΗ≈¬ ΓΘ
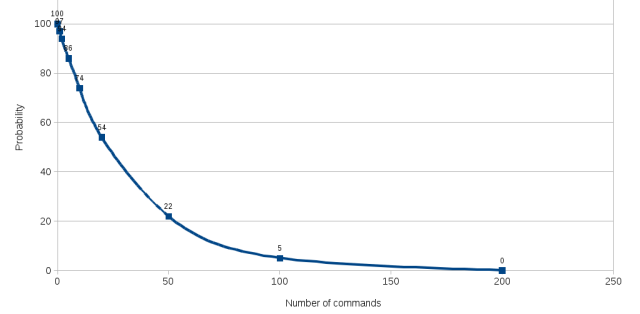
’β–©Ά≥ΦΤΗφΥΏΈ“Ο«ΘΚ
- ÷Μ–η ÷ΙΛ‘Υ––5ΧθΟϋΝνΒΡ«ιΩωœ¬Θ§≥…ΙΠ≤Ω πΒΡΗ≈¬ ΨΆ“―Βχ÷Ν86%ΓΘ
- »γ–η ÷ΙΛ‘Υ––55ΧθΟϋΝνΘ§≥…ΙΠ≤Ω πΒΡΗ≈¬ ΫΪΒχ÷Ν22%ΓΘ
- »γ–η ÷ΙΛ‘Υ––100ΧθΟϋΝνΘ§≥…ΙΠ≤Ω πΒΡΗ≈¬ ΫΪ«ςΫϋ”Ύ0Θ®Ϋω2%Θ©ΘΓ
≥…ΙΠ≤Ω π“βΈΕΉ≈»μΦΰΡήΙΜΑ¥’’‘ΛΤΎ‘Ύ…ζ≤ζΜΖΨ≥÷–‘Υ––ΓΘΈ¥Ρή≥…ΙΠ≤Ω π“βΈΕΉ≈”–ΕΪΈς≥ω¥μΘ§Ω…Ρή–η“ΣΫχ––±Ί“ΣΒΡΖ÷Έω≤≈ΡήΝΥΫβ≤Ω πΙΐ≥Χ÷–ΡΡάο≥ω¥μΘ§ «Ζώ–η“Σ”Π”ΟΡ≥÷÷≤ΙΕΓΘ§Μρ–η“Σ–όΗΡΡ≥–©≈δ÷ΟΓΘ
“ρ¥Υ»Ο’β“Μ«– Βœ÷Ή‘Ε·Μ·≤Δ≤Μœß“Μ«–¥ζΦέ±ήΟβ ÷ΙΛ≤ΌΉςΥΤΚθ «ΗωΚΟ÷ς“βΘ§Ε‘Α…ΘΩ
Ρ«Ο¥––“Βάο’βΖΫΟφΒΡœ÷Ή¥ «‘θ―υΒΡΘΚ
‘ΥΈ§Ά≈Ε”ΒΡ ±ΦδΖ÷≈δΘ®ά¥‘¥ΘΚIT Ops & DevOps Productivity Report 2013 - Rebellabs - http://pages.zeroturnaround.com/rs/zeroturnaround/images/it-ops-devops-productivity-report-2013%20copy.pdfΘ©
Θ®ΥΒ ΒΜΑΘ§’βΗωΆ≥ΦΤ–≈œΔ±»ΫœάœΝΥΘ§ «2013ΡξΒΡΫαΙϊΘ§œύ–≈œ÷‘ΎΒΡΫαΙϊΜα”–Υυ≤ΜΆ§Θ©
»ΜΕχ’β“≤Ω…“‘»ΟΈ“Ο«Ος»ΖΒΡ÷ΣΒάΘ§‘ΎΜυ¥ΓΦήΙΙΉ‘Ε·Μ·ΖΫΟφΈ“Ο«ΜΙ”–Εύ‘ΕΒΡ¬Ζ“ΣΉΏΘ§≤Δ«“DevOpsΒΡΜυ±Ψ‘≠‘ρΚΆ ΒΦυ“ά»Μ «Ρ«Ο¥ΒΡ÷Ί“ΣΓΘ
Άχ¬γΨόΆΖϫ±»ΜΜαΆ®Ιΐ–¬ΒΡΖΫΖ®ΚΆ ΒΦυΦΑ ±¬ζΉψΉ‘ΦΚΒΡ–η«σΘ§ΥϊΟ«‘γ“―ΩΣ ΦΙΙΫ®Ή‘ΦΚΒΡΙΛ≥Χ“ΒΈώΘ§Εχ’ΐ «ΥϊΟ«Υυ»ΖΝΔΒΡ ΒΦυ÷πΫΞ―ή…ζ≥ωΒ±ΫώΈ“Ο«Υυ λœΛΒΡDevOpsΓΘ
Ω¥Ω¥’β–©Άχ¬γΨόΆΖΟ«‘Ύ’βΖΫΟφΡΩ«ΑΥυ¥ΠΒΡΈΜ÷ΟΑ…Θ§ΨΌΦΗΗωάΐΉ”ΘΚ
- Facebook”– ΐ«ßΟϊΩΣΖΔΚΆ‘ΥΈ§»Υ‘±Θ§≥…«ß…œΆρΧ®ΖΰΈώΤςΓΘΤΫΨυά¥ΥΒ“ΜΈΜ‘ΥΈ§»Υ‘±ΗΚ‘π500Χ®ΖΰΈώΤςΘ®ΜΙ»œΈΣΉ‘Ε·Μ· «Ω…―ΓΒΡ¬πΘΩΘ©ΥϊΟ«ΟΩΧλ≤Ω πΝΫ¥ΈΘ®ΜΖ Ϋ≤Ω πΘ§Deployment ringΒΡΗ≈ΡνΘ©ΓΘ
- FlickrΟΩΧλ≤Ω π10¥ΈΓΘ
- NetflixΟς»Ζ’κΕ‘ ßΑήΫχ––Ης÷÷…ηΦΤΘΓΥϊΟ«ΒΡ»μΦΰΑ¥’’…ηΦΤ¥”ΉνΒΉ≤ψΦ¥Ω…»ί»ΧœΒΆ≥ ßΑήΘ§ΥϊΟ«Μα‘Ύ…ζ≤ζΜΖΨ≥÷–Ϋχ––»ΪΟφΒΡ≤β ‘ΘΚΟΩΧλΆ®ΙΐΥφΜζΙΊ±’–ιΡβΜζΒΡΖΫ Ϋ‘Ύ…ζ≤ζΜΖΨ≥÷–÷¥––65000¥Έ ßΑή≤β ‘Γ≠Γ≠ ≤Δ»Ζ±Θ’β÷÷«ιΩωœ¬“Μ«–“ά»ΜΩ…“‘’ΐ≥ΘΙΛΉςΓΘ
ΥϊΟ«’β÷÷ΉωΖ®ΟΊΟήΚΈ‘ΎΘΩ
1.5 DevOpsΘΚΫω¥Υ“Μ¥ΈΘ§“ΜΩ≈…ώΤφΒΡ“χΉ”Β·
ΥϊΟ«ΒΡΟΊΟήΚήΦρΒΞΘΚΫΪΟτΫίά©’Ι÷Ν…ζ≤ζΕΥΘΚ
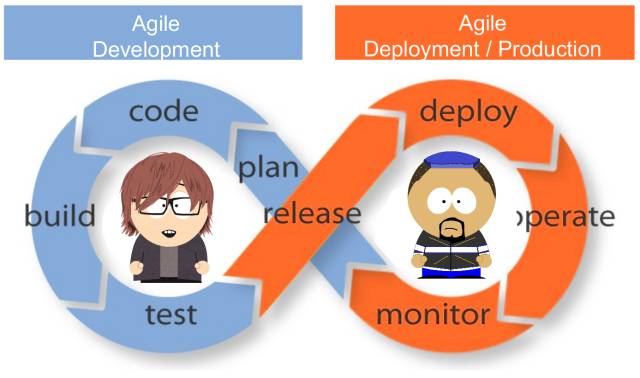
DevOpsΒΡΙ≤¥φ÷ς“Σ «ΈΣΝΥά©’ΙΟτΫίΩΣΖΔ ΒΦυΘ§Ϋχ“Μ≤ΫΆξ…Τ»μΦΰ±δΗϋ‘ΎΙΙΫ®ΓΔ―ι÷ΛΓΔ≤Ω πΓΔΫΜΗΕΒ»ΫΉΕΈ÷–ΒΡΝςΕ·Θ§Ά§ ±Ά®Ιΐ»μΦΰ”Π”Ο≥Χ–ρΒΡ»ΪΟφΥυ”–»®”ηΝΠΩγ÷ΑΡήΆ≈Ε”Άξ≥…¥”…ηΦΤΒΫ…ζ≤ζ÷ß≥÷Β»ΗςΜΖΫΎΒΡΙΛΉςΓΘ
DevOpsΙΡάχ»μΦΰΩΣΖΔ’ΏΚΆIT‘ΥΈ§»Υ‘±÷°ΦδΥυΫχ––ΒΡΙΒΆ®ΓΔ–≠ΉςΓΔΦ·≥…ΚΆΉ‘Ε·Μ·Θ§Ϋη¥Υ”–÷ζ”ΎΗΡ…ΤΥΪΖΫ‘ΎΫΜΗΕ»μΦΰΙΐ≥Χ÷–ΒΡΥΌΕ»ΚΆ÷ ΝΩΓΘ
DevOpsΆ≈Ε”Ηϋ≤ύ÷Ί”ΎΆ®Ιΐ±ξΉΦΜ·ΩΣΖΔΜΖΨ≥ΚΆΉ‘Ε·Μ·ΫΜΗΕΝς≥ΧΗΡ…ΤΫΜΗΕΙΛΉςΒΡΩ…‘Λ≤β–‘ΓΔ–ß¬ ΓΔΑ≤»Ϊ–‘Θ§“‘ΦΑΩ…Έ§ΜΛ–‘ΓΘάμœκ«ιΩωœ¬Θ§DevOpsΩ…“‘ΈΣΩΣΖΔ’ΏΧαΙ©ΗϋΩ…ΩΊΒΡ…ζ≤ζΜΖΨ≥Θ§Αο÷ζΥϊΟ«ΗϋΚΟΒΊάμΫβ…ζ≤ζΜυ¥ΓΦήΙΙΓΘ
DevOpsΙΡάχΆ≈Ε”Ή‘÷ςΫχ––Ή‘ΦΚ”Π”Ο≥Χ–ρΒΡΙΙΫ®ΓΔ―ι÷ΛΓΔΫΜΗΕΚΆ÷ß≥÷ΓΘ
Ρ«Ο¥ΚΥ–Ρ‘≠‘ρΒΫΒΉ « ≤Ο¥ΘΩ
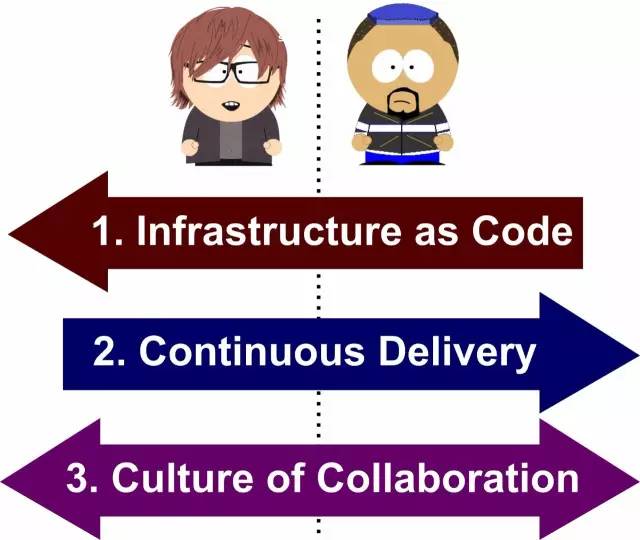
DevOpsΒΡΜυ±Ψ‘≠‘ρ
œ¬ΈΡΫΪΫι…ήΉν÷Ί“ΣΒΡ»ΐ¥σΜυ±Ψ‘≠‘ρΓΘ
2. Μυ¥ΓΦήΙΙΦ¥¥ζ¬κ
»ΥΉήΜαΖΗ¥μΘ§“ρΈΣ»ΥΡ‘ Β‘Ύ «≤Μ…Ο≥Λ¥Πάμ÷ΊΗ¥–‘ΒΡ»ΈΈώΘ§œύ±»ShellΫ≈±ΨΘ§»ΥάύΒΡΥΌΕ» Β‘Ύ «ΧΪ¬ΐΝΥΓΘ±œΨΙΈ“Ο«ΕΦ «»ΥάύΘ§“ρ¥Υ”–±Ί“Σœώ¥Πάμ¥ζ¬κΡ«―υΩΦ¬«ΚΆ¥Πάμ”–ΙΊΜυ¥ΓΦήΙΙΒΡΗ≈ΡνΘΓ
Μυ¥ΓΦήΙΙΦ¥¥ζ¬κΘ®IaCΘ© «¥σ≤ΩΖ÷Ά®”ΟDevOps ΒΦυΒΡ«ΑΧα“Σ«σΘ§άΐ»γΑφ±ΨΩΊ÷ΤΓΔ¥ζ¬κ…σ‘ΡΓΔ≥÷–χΦ·≥…ΓΔΉ‘Ε·Μ·≤β ‘ΓΘ’β“ΜΗ≈Ρν…φΦΑΦΤΥψΜυ¥ΓΦήΙΙΘ®»ίΤςΓΔ–ιΡβΜζΓΔΈοάμΜζΓΔ»μΦΰΑ≤ΉΑΒ»Θ©ΒΡΙήάμΚΆΙ©”ΠΘ§“‘ΦΑΆ®ΙΐΜζΤςΩ…¥ΠάμΒΡΕ®“εΈΡΦΰΜρΫ≈±ΨΕ‘ΤδΫχ––ΒΡ≈δ÷ΟΘ§ΫΜΜΞ Ϋ≈δ÷ΟΙΛΨΏΚΆ ÷ΙΛΟϋΝνΒΡ Ι”Ο“―Ψ≠≤ΜΚœ ±“ΥΝΥΓΘ
’β“Μ‘≠‘ρΕ‘DevOpsΒΡ÷Ί“Σ–‘‘θΟ¥«ΩΒςΕΦ≤ΜΈΣΙΐΘ§ΥϋΩ…“‘’φ’ΐΫΪ»μΦΰΩΣΖΔœύΙΊΒΡ ΒΦυ”Π”ΟΗχΖΰΈώΤςΚΆΜυ¥ΓΦήΙΙΓΘ
‘ΤΦΤΥψ ΙΒΟΗ¥‘”ΒΡIT≤Ω πΩ…“‘ΦΧ–χ–ßΖ¬¥ΪΆ≥ΈοάμΆΊΤΥΓΘΈ“Ο«Ω…“‘œύΕ‘«αΥ…ΒΊΕ‘Η¥‘”–ιΡβΆχ¬γΓΔ¥φ¥ΔΚΆΖΰΈώΤςΒΡΙΙΫ® Βœ÷Ή‘Ε·Μ·ΓΘΖΰΈώΤςΜΖΨ≥ΒΡΖΫΖΫΟφΟφΘ§…œ÷ΝΜυ¥ΓΦήΙΙœ¬÷Ν≤ΌΉςœΒΆ≥…η÷ΟΘ§ΨυΩ…±ύ¬κ≤Δ¥φ¥Δ÷ΝΑφ±ΨΩΊ÷Τ≤÷ΩβΓΘ
2.1 Η≈ ω
“‘Ζ«≥ΘΗ≈ά®ΒΡΖΫ Ϋά¥Ω¥Θ§Μυ¥ΓΦήΙΙΚΆ‘ΥΈ§Υυ–η Βœ÷ΒΡΉ‘Ε·Μ·≥ΧΕ»Ω…Ά®Ιΐœ¬ΆΦ’β÷÷ΦήΙΙά¥±μ ΨΘΚ
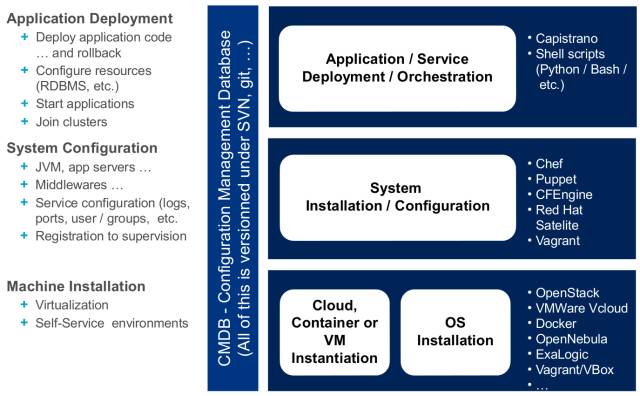
…œ ωΦήΙΙΆΦ÷–ΉςΈΣ ΨάΐΒΡΙΛΨΏ÷ς“ΣΟφœρ≤ΜΆ§≤ψΒΡΙΙΫ®ΙΛΉςΘ§ ΒΦ …œDevOpsΙΛΨΏΝ¥ΒΡΉς”Ο‘Ε≤Μ÷Ι»γ¥ΥΓΘ
Έ“ΨθΒΟ‘Ύ’βάοΩ…“‘¬‘ΈΔ…ν»κΒΊΧΗΧΗDevOpsΒΡΙΛΨΏΝ¥ΝΥΓΘ
2.2 DevOpsΙΛΨΏΝ¥
DevOps ΒΦ «“Μ÷÷ΈΡΜ·…œΒΡ±δ«®Θ§¥ζ±μΝΥΩΣΖΔΓΔ‘ΥΈ§ΓΔ≤β ‘Β»ΜΖΫΎ÷°ΦδΒΡ–≠ΉςΘ§“ρ¥ΥDevOpsΙΛΨΏ «Ζ«≥ΘΕύ÷÷Εύ―υΒΡΘ§…θ÷ΝΩ…“‘”…Εύ÷÷ΙΛΨΏΉι≥…“ΜΗωΆξ’ϊΒΡDevOpsΙΛΨΏΝ¥ΓΘ¥ΥάύΙΛΨΏΩ…“‘”Π”Ο”Ύ“Μ÷÷ΜρΕύ÷÷άύ±πΘ§≤ΔΩ…Χεœ÷≥ω»μΦΰΩΣΖΔΚΆΫΜΗΕΙΐ≥ΧΒΡ≤ΜΆ§ΫΉΕΈΘΚ
- ±ύ¬κΘΚ¥ζ¬κΩΣΖΔΚΆ…σ‘ΡΘ§Αφ±ΨΩΊ÷ΤΙΛΨΏΓΔ¥ζ¬κΚœ≤ΔΙΛΨΏ
- ΙΙΫ®ΘΚ≥÷–χΦ·≥…ΙΛΨΏΓΔΙΙΫ®Ή¥Χ§Ά≥ΦΤΙΛΨΏ
- ≤β ‘ΘΚΆ®Ιΐ≤β ‘ΚΆΫαΙϊ»ΖΕ®Φ®–ßΒΡΙΛΨΏ
- ¥ρΑϋΘΚ≥…ΤΖ≤÷ΩβΓΔ”Π”Ο≥Χ–ρ≤Ω π«Α‘ί¥φ
- ΖΔ≤ΦΘΚ±δΗϋΙήάμΓΔΖΔ≤Φ…σ≈ζΓΔΖΔ≤ΦΉ‘Ε·Μ·
- ≈δ÷ΟΘΚΜυ¥ΓΦήΙΙ≈δ÷ΟΚΆ≤Ω πΘ§Μυ¥ΓΦήΙΙΦ¥¥ζ¬κΙΛΨΏ
- Φύ ”ΘΚ”Π”Ο≥Χ–ρ–‘ΡήΦύ ”ΓΔΉν÷’”ΟΜßΧε―ι
Υδ»ΜΩ…”ΟΙΛΨΏ”–ΚήΕύΘ§ΒΪΤδ÷–“Μ–©ΜΖΫΎ «Ήι÷·ΡΎ≤Ω”Π”ΟDevOpsΙΛΨΏΝ¥≤ΜΩ…Μρ»±ΒΡΓΘ
÷ν»γDockerΘ®»ίΤςΜ·Θ©ΓΔJenkinsΘ®≥÷–χΦ·≥…Θ©ΓΔPuppetΘ®Μυ¥ΓΦήΙΙΙΙΫ®Θ©ΓΔVagrantΘ®–ιΡβΜ·ΤΫΧ®Θ©Β»≥Θ”ΟΓΔΙψΖΚ Ι”ΟΒΡΙΛΨΏΕΦ «2016ΡξΒΡDevOps»»Ο≈ΙΛΨΏΓΘ
Μυ¥ΓΦήΙΙΉιΦΰΒΡΑφ±ΨΩΊ÷ΤΓΔ≥÷–χΦ·≥…ΚΆΉ‘Ε·Μ·≤β ‘
Μυ¥ΓΦήΙΙΒΡΑφ±ΨΩΊ÷ΤΡήΝΠΘ®ΕχΖ«Μυ¥ΓΦήΙΙΒΡΙΙΫ®Ϋ≈±ΨΜρ≈δ÷ΟΈΡΦΰΘ©ΦΑΕ‘ΤδΫχ––Ή‘Ε·Μ·≤β ‘ΒΡΡήΝΠΦΪΤδ÷Ί“ΣΓΘDevOpsΉν÷’ΜαΫΪ30Ρξ«Α»μΦΰΙΛ≥ΧΝλ”ρΥυ≤…”ΟΒΡΆ§“ΜΧΉXP ΒΦυ¥χ÷Ν…ζ≤ζΕΥΓΘ
¥ΥΆβΜυ¥ΓΦήΙΙ‘ΣΥΊ”ΠΗΟΡήœρ»μΦΰΫΜΗΕΈο“Μ―υΫχ––≥÷–χΦ·≥…ΓΘ
2.3 ’“φ
DevOpsΒΡ ’“φ”–ΚήΕύΘ§Αϋά®ΒΪ≤Μœό”ΎΘΚ
- Ω…÷ΊΗ¥–‘”κΩ…ΩΩ–‘ΘΚ ±÷ΝΫώ»’Θ§ΙΙΫ®…ζ≤ζ”ΟΦΤΥψΜζ÷Μ–η“Σ‘Υ––Ϋ≈±ΨΜρ±Ί“ΣΒΡpuppetΟϋΝνΦ¥Ω…ΓΘΆ®Ιΐ«ΓΒ±ΒΊ Ι”ΟDocker»ίΤςΜρVagrant–ιΡβΜζΘ§÷Μ–η‘Υ––“ΜΧθΟϋΝνΦ¥Ω…≈δ÷ΟΚΟΑϋΚ§≤ΌΉςœΒΆ≥≤ψ“‘ΦΑΥυ–η»μΦΰΚΆ≈δ÷ΟΒΡ…ζ≤ζ”ΟΦΤΥψΜζΓΘΒ±»ΜΘ§ΥφΉ≈Ης÷÷±δΗϋΜρ»μΦΰΩΣΖΔΓΔ≥÷–χΦ·≥…Θ§≤ΔΉ‘Ε·≤β ‘Θ§’βΧΉΙΙΫ®Ϋ≈±ΨΜρΜζ÷Τ“≤ΜαΫχ––≥÷–χΦ·≥…ΓΘΉν÷’–“Ως”–ΝΥXPΜρΟτΫίΘ§Έ“Ο«‘Ύ»μΦΰΩΣΖΔΕΥΥυ Ι”ΟΒΡΆ§“ΜΧΉ ΒΦυ“≤Ρή»Ο‘ΥΈ§ΕΥΜώ“φΓΘ
- …ζ≤ζΝΠΘΚ“ΜΦϋ≤Ω πΘ§“ΜΦϋΙ©”ΠΘ§“ΜΦϋ¥¥Ϋ®–¬ΜΖΨ≥Γ≠Γ≠’ϊΗω…ζ≤ζΜΖΨ≥Ω…“‘Ά®Ιΐ“ΜΧθΟϋΝνΜρ“ΜΦϋΒψΜςΒΡΖΫ Ϋ¥¥Ϋ®ΓΘ’β―υΒΡ“ΜΧθΟϋΝν“≤–μΜα‘Υ––≥Λ¥ο ΐ–Γ ±Θ§ΒΪ‘Ύ’βΙΐ≥Χ÷–‘ΥΈ§»Υ‘±Ω…“‘¥” ¬ΤδΥϊΗϋ”–»ΛΒΡΙΛΉςΘ§ΕχΈό–ηΒ»¥ΐ“ΜΧθΟϋΝν÷¥––Άξ±œΚσΦΧ–χ δ»κœ¬“ΜΧθΟϋΝνΘ§±œΨΙ’β―υΒΡΙΐ≥Χ”– ±ΚρΩ…Ρή–η“ΣΜ®Ζ―ΦΗΧλ ±Φδ≤≈ΡήΆξ≥…Γ≠Γ≠
- Μ÷Η¥ ±ΦδΘΓΘΚ“ΜΦϋΒψΜςΦ¥Ω…Μ÷Η¥…ζ≤ζΜΖΨ≥Θ§ΨΆ «’βΟ¥ΦρΒΞΓΘ
- »Ζ±ΘΜυ¥ΓΦήΙΙΒΡΆ§÷ ΘΚ≥ΙΒΉ±ήΟβ‘ΥΈ§»Υ‘±ΟΩ¥ΈΙΙΫ®ΜΖΨ≥ΜρΑ≤ΉΑ»μΦΰ ±Ήν÷’ΜώΒΟΒΡΫαΙϊ”κ‘ΛΤΎ”–Υυ≤ν“λΘ§’β «»Ζ±ΘΜυ¥ΓΦήΙΙΨχΕ‘Ά§÷ Θ®HomogeneousΘ©≤Δ«“Ω…‘Όœ÷ΒΡΈ®“ΜΩ…––ΖΫΖ®ΓΘ“‘¥ΥΈΣΜυ¥ΓΘ§Ά®ΙΐΕ‘Ϋ≈±ΨΜρPuppet≈δ÷ΟΈΡΦΰ Ι”ΟΑφ±ΨΩΊ÷ΤΜζ÷ΤΘ§Έ“Ο«…θ÷ΝΩ…“‘÷ΊΫ®≥ω”κ…œ÷ήΓΔ…œΗω‘¬Θ§Μρ»μΦΰΧΊΕ®Αφ±ΨΖΔ≤Φ ±Άξ»Ϊ“Μ÷¬ΒΡ…ζ≤ζΜΖΨ≥ΓΘ
- Έ§≥÷’ϊΤκΜ°“ΜΒΡ±ξΉΦΘΚΜυ¥ΓΦήΙΙ±ξΉΦ…θ÷ΝΩ…“‘≤ΜΗ¥¥φ‘ΎΘ§¥ζ¬κ±Ψ…μΨΆ «±ξΉΦΓΘ
- »ΟΩΣΖΔ’ΏΉ‘––Άξ≥…¥σ≤ΩΖ÷ΙΛΉςΘΚ»γΙϊΩΣΖΔ’ΏΉ‘ΦΚΆΜ»ΜΩ…“‘‘ΎΉ‘ΦΚΒΡΜυ¥ΓΦήΙΙ…œ“ΜΦϋΒψΜς÷ΊΫ®…ζ≤ζΜΖΨ≥Θ§ΥϊΟ«“≤ΨΆΩ…“‘Ή‘––Άξ≥…ΚήΕύ”κ…ζ≤ζΜΖΨ≥”–ΙΊΒΡ»ΈΈώΘ§άΐ»γΗϋΚΟΒΊάμΫβ…ζ≤ζ ßΑήΘ§ΧαΙ©Ηϋ«ΓΒ±ΒΡ≈δ÷ΟΘ§ Βœ÷≤Ω πΫ≈±ΨΒ»ΓΘ
’β÷Μ «Έ“Ηω»ΥΗ–ΨθIaCΩ…ΧαΙ©ΒΡ≤ΩΖ÷ ’“φΘ§œύ–≈ΜΙ”–ΚήΕύΤδΥϊ ’“φΓΘ
3. ≥÷–χΫΜΗΕ
≥÷–χΫΜΗΕ «“Μ÷÷Ω…“‘Αο÷ζΆ≈Ε”“‘ΗϋΕΧΒΡ÷ήΤΎΫΜΗΕ»μΦΰΒΡΖΫΖ®Θ§ΗΟΖΫΖ®»Ζ±ΘΝΥΆ≈Ε”Ω…“‘‘Ύ»ΈΚΈ ±ΦδΖΔ≤Φ≥ωΩ…ΩΩΒΡ»μΦΰΓΘΗΟΖΫΖ®“β‘Ύ“‘ΗϋΩλΥΌΕ»ΗϋΗΏΤΒ¬ Ϋχ––»μΦΰΒΡΙΙΫ®ΓΔ≤β ‘ΚΆΖΔ≤ΦΓΘ
Ά®ΙΐΕ‘…ζ≤ζΜΖΨ≥÷–ΒΡ”Π”Ο≥Χ–ρΫχ––ΗϋΗΏΤΒ¥ΈΒΡ‘ωΝΩΗϋ–¬Θ§’β÷÷ΖΫΖ®”–÷ζ”ΎΫΒΒΆΫΜΗΕ±δΗϋΙΐ≥Χ÷–…φΦΑΒΡ≥…±ΨΓΔ ±ΦδΚΆΖγœ’ΓΘΉψΙΜΦρΒΞ÷±Ϋ”≤Δ«“Ω…÷ΊΗ¥ΒΡ≤Ω πΝς≥ΧΕ‘≥÷–χΫΜΗΕΕχ―‘÷ΝΙΊ÷Ί“ΣΓΘ
ΉΔ“βΘΚ≥÷–χΫΜΗΕ ΓΌ ≥÷–χ≤Ω π - ”– ±ΚρΚήΕύ»ΥΜαΑ―≥÷–χΫΜΗΕΈσ»œΈΣ≥…≥÷–χ≤Ω πΓΘ≥÷–χ≤Ω π «÷ΗΟΩΗω±δΗϋΩ…“‘Ή‘Ε·≤Ω πΒΫ…ζ≤ζΜΖΨ≥ΓΘ≥÷–χΫΜΗΕ «÷ΗΆ≈Ε”»Ζ±ΘΟΩΗω±δΗϋΩ…“‘≤Ω π÷Ν…ζ≤ζΜΖΨ≥Θ§ΒΪ“≤–μ≤Δ≤Μ–η“Σ ΒΦ ≤Ω πΘ§’βΆ®≥ΘΩ…Ρή «≥ω”Ύ“ΒΈώΖΫΟφΒΡ‘≠“ρΓΘ÷Μ”–≥…ΙΠ Βœ÷≥÷–χΫΜΗΕΒΡ«ΑΧαœ¬Θ§≤≈ΡήΫχ––≥÷–χ≤Ω πΓΘ
≥÷–χΫΜΗΕΒΡ÷ς“ΣœκΖ®‘Ύ”ΎΘΚ
- ≤Ω π‘ΫΤΒΖ±Θ§Ε‘≤Ω πΝς≥ΧΨΆΜα‘Ϋ λœΛΘ§Ή‘Ε·Μ·Μζ÷ΤΨΆΡήΜώΒΟΗϋΚΟΒΡΫαΙϊΓΘ»γΙϊΆ§“ΜΦΰ ¬ΟΩΧλ–η“Σ÷¥––3¥ΈΘ§ΚήΩλΡψΫΪ±δΒΡΈό±»φΒ λΘ§ΒΪΚήΩλ“≤Μα“ρΈΣ»’Η¥“Μ»’ΫβΨωΆ§―υΒΡΈ ΧβΕχΗ–ΒΫ―αΖ≥ΓΘ
- ≤Ω π‘ΫΤΒΖ±Θ§Υυ≤Ω τΒΡ±δΗϋΦ·ΨΆ‘ΫΈΔ≤ΜΉψΒάΘ§Εχ’β–©ΈΔ≤ΜΉψΒάΒΡΡΎ»ίΉν”–Ω…Ρή≥ω¥μΘ§…θ÷ΝΩ…ΡήΒΦ÷¬ΕΣ ßΕ‘’ϊΗω±δΗϋΦ·ΒΡΩΊ÷ΤΝΠΓΘ
- ≤Ω π‘ΫΤΒΖ±Θ§TTRΘ®–όΗ¥Θ·ΫβΨωΥυ–η ±ΦδΘ©÷Η±ξΨΆΜα‘Ϋ≥ω…ΪΘ§¥”“ΒΈώ”ΟΜߥΠΜώΒΟ”–ΙΊΙΠΡήΒΡΗςάύΖ¥άΓΒΡΥΌΕ»‘ΫΩλΘ§Ής≥ωΗΡΫχ“‘±ψΆξΟά¬ζΉψΕ‘ΖΫ–η«σΒΡΙΐ≥Χ“≤Μα‘ΫΦρΒΞΘ®’βΖΫΟφTTR”κTTMΤδ ΒΖ«≥ΘœύΥΤΘ©ΓΘ
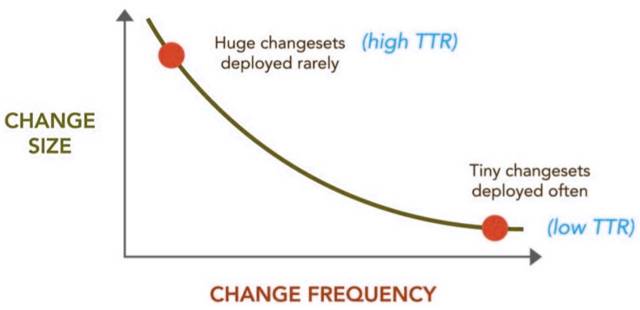
–ΓΙφΡΘ±δΗϋ/ΗϋΗΏΤΒ¥ΈΘ®ά¥‘¥ΘΚOps Meta-Metrics: The Currency You Pay For Change - http://fr.slideshare.net/jallspaw/ops-metametrics-the-currency-you-pay-for-change-4608108Θ©
ΒΪ≥÷–χΫΜΗΕ≤Δ≤ΜΫωΫω «ΨΓΩ…ΡήΤΒΖ±ΒΊΙΙΫ®Ω…ΖΔ≤ΦΓΔ…ζ≤ζΨΆ–ςΑφ±ΨΒΡ»μΦΰ≤ζΤΖΡ«Ο¥ΦρΒΞΓΘ≥÷–χΫΜΗΕΑϋΚ§3ΗωΙΊΦϋ ΒΦυΘΚ
- ¥” ΒΦυ÷–―ßœΑ
- Ή‘Ε·Μ·
- ΗϋΤΒΖ±ΒΡ≤Ω π
3.1 ¥” ΒΦυ÷–―ßœΑ
≥÷–χΫΜΗΕΒΡΙΊΦϋ‘Ύ”Ύ“ΣΡή¥” ΒΦυ÷–―ßœΑΓΘ’φάμ≤Δ≤Μ¥φ‘Ύ”ΎΩΣΖΔΆ≈Ε”÷–Θ§Εχ‘Ύ”Ύ“ΒΈώ”ΟΜß÷–ΓΘ»ΜΕχΈό¬έΜ®Εύ≥Λ ±ΦδΘ§ΟΜ»ΥΡή’φ’ΐ«ε≥ΰΒΊ±μ¥οΉ‘ΦΚΒΡœκΖ®Θ§Μρ’ΏΫΪΉ‘ΦΚΒΡœκΖ®”Ο«εΈζΒΡΈΡΒΒΗ≈ά®≥ωά¥ΓΘ“≤’ΐ «“ρ¥ΥΘ§ΟτΫίΖΫΖ®¬έ«ΩΒςΫΪΙΠΡήΧαΙ©Ηχ”ΟΜßΘ§≤Δ≤Μœß“Μ«–¥ζΦέ¥””ΟΜߥΠΜώΒΟΨΓΩ…ΡήΕύΒΡΖ¥άΓΓΘ
≥÷–χΫΜΗΕ”κ≥÷–χ≤Ω πάύΥΤΘ§–η“ΣΨΓΩ…ΡήΦθ…Ό«Α÷Ο ±ΦδΘ§’β“≤ «ΨΓΩλ¥””ΟΜߥΠΜώΒΟΓΑ’φάμΓ±ΒΡΙΊΦϋΓΘ
ΒΪ’φάμΨχΕ‘≤ΜΜαά¥Ή‘’ΐΙφ–Έ ΫΒΡ”ΟΜßΖ¥άΓΓΘΈ“Ο«Ψχ≤ΜΡήΨΓ–≈Ή‘ΦΚΒΡ”ΟΜßΜρΦΡœΘΆϊ”ΎΆ®Ιΐ’ΐΙφ–Έ ΫΒΡΖ¥άΓΝΥΫβ”ΟΜßΓΘΈ“Ο«÷ΜΡήœύ–≈Ή‘ΦΚΒΡΕ»ΝΩΓΘ
≥’Ο‘”ΎΕ»ΝΩ «ΨΪ“φ¥¥“ΒΘ®Lean StartupΘ©ΜνΕ·÷–“ΜΗω÷Ί“ΣΒΡΗ≈ΡνΘ§ΒΪ’β“ΜΗ≈ΡνΕ‘DevOpsΆ§―υ÷Ί“ΣΓΘΈ“Ο«”ΠΗΟΕ»ΝΩ“Μ«–ΘΓ»ΖΕ®Ήν«ΓΒ±ΒΡΕ»ΝΩ÷Η±ξΩ…“‘»ΟΆ≈Ε”ΝΥΫβΡ≥÷÷ΖΫΖ®Ήν÷’ΡήΖώ≥…ΙΠΜρ ßΑήΘ§ΝΥΫβ‘θ―υΉωΩ…“‘ΜώΒΟΗϋΚΟΒΡΫαΙϊΘ§“‘ΦΑΡΡ–©Ήν≥…ΙΠΒΡΉωΖ®Ά§ ±“≤‘ΧΚ§Ή≈“ΜΕ®ΒΡΖγœ’ΓΘΈΣΝΥΑο÷ζΆ≈Ε”Ήω≥ωΗϋΟς÷«ΒΡΨω≤ΏΘ§‘Ύ»ΖΕ®“ΣΚβΝΩΒΡ÷Η±ξ ±Θ§“ΜΕ®“Σ±ßΉ≈ΓΑΡΰΕύΈπ…ΌΓ±ΒΡ‘≠‘ρΓΘ
≤Μ–η“ΣΓΑΩΦ¬«Γ±Θ§÷Μ–η“ΣΓΑ÷ΣΒάΓ±ΘΓΓΑ÷ΣΒάΓ±ΒΡΈ®“ΜΖΫΖ®ΨΆ «Ε»ΝΩΘ§Ε»ΝΩ“Μ«–ΘΚœλ”Π ±ΦδΓΔ”ΟΜßΥΦΩΦ ±ΦδΓΔ’Ι Ψ¥Έ ΐΓΔAPIΒς”Ο¥Έ ΐΓΔΒψΜς¬ Β»Θ§ΒΪ’β–©≤ΔΖ«–η“ΣΕ»ΝΩΒΡ»Ϊ≤ΩΓΘ’“≥ωΥυ”–Ρή»ΟΡψΗϋΫχ“Μ≤ΫΝΥΫβ”ΟΜßΕ‘ΙΠΡήΩ¥Ζ®ΒΡΕ»ΝΩ÷Η±ξΘ§Ε‘Υυ”–’β–©÷Η±ξΫχ––Ε»ΝΩΘΓ
’β÷÷ΖΫΖ®Ω…“‘±μ ΨΈΣ»γœ¬–Έ ΫΘΚ
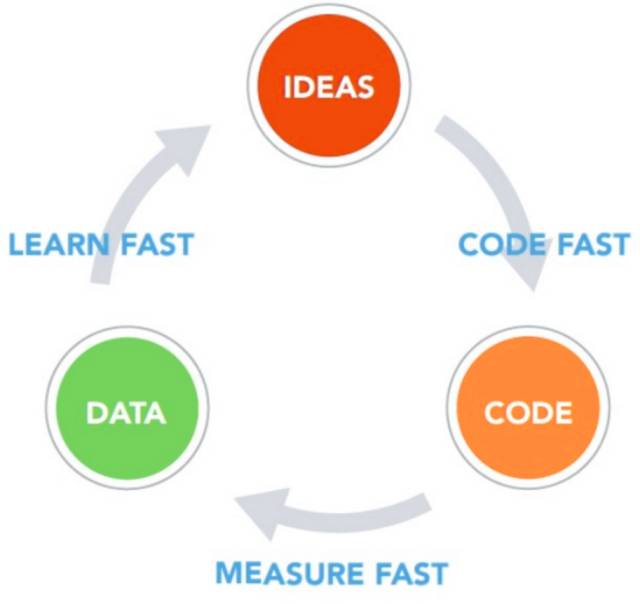
3.2 Ή‘Ε·Μ·
Ή‘Ε·Μ·“―Ψ≠‘Ύ…œΈΡ2. Μυ¥ΓΦήΙΙΦ¥¥ζ¬κ“ΜΫΎΫχ––ΝΥΧ÷¬έΓΘ
‘Ύ’βάοΈ“œκ«ΩΒςΒΡ «Θ§‘ΎΟΜ”–ΫΪ”κΜυ¥ΓΦήΙΙ”–ΙΊΒΡΥυ”–Ι©”ΠΚΆ»ΈΈώ Βœ÷ΆΉ…ΤΓΔ»ΪΟφΒΡΉ‘Ε·Μ·÷°«ΑΘ§≥÷–χΫΜΗΕΗυ±ΨΈό¥”ΧΗΤπΓΘ
’β“ΜΒψΚή÷Ί“ΣΘ§“ρ¥Υ”–±Ί“Σ‘Ό÷ΊΗ¥“Μ±ιΘΚΜΖΨ≥ΒΡ¥νΫ®ΚΆ…ζ≤ζΨΆ–ςΑφ±Ψ»μΦΰΒΡ≤Ω π÷Μ–η“Σ“ΜΦϋΒψΜςΘ§÷Μ–η“Σ‘Υ––“ΜΧθΟϋΝνΘ§’ϊΗωΙΐ≥Χ”ΠΗΟΉ‘Ε·Άξ≥…ΓΘΖώ‘ρΗυ±ΨΈόΖ®…ηœκΡή“ΜΧλΕύ¥Έ≤٠𢧓ΜΗω»μΦΰΓΘ
‘Ύœ¬ΈΡΒΡ3.5 ΝψΆΘΜζ≤Ω π“ΜΫΎ÷–Θ§ΜΙΫΪΫι…ή”–÷ζ”ΎΉ‘Ε·Μ·ΫΜΗΕΒΡΤδΥϊ÷Ί“ΣΦΦ θΓΘ
3.3 ΗϋΤΒΖ±ΒΡ≤Ω π
DevOpsΒΡ–≈Χθ‘Ύ”ΎΘΚ
ΓΑ‘Ϋ «άßΡ―ΒΡ ¬Θ§–η“ΣΗϋΤΒΖ±ΒΊΫχ––ΘΓΓ±
ΟτΫίΥΦΈ§÷–Θ§άßΡ―»ΈΈώΗϋ“Σ”≠Ρ―Εχ…œΘ§ΗϋΤΒΖ±ΒΊ»ΞΉωΘ§’β÷–œκΖ®Ζ«≥Θ÷Ί“ΣΓΘ
Ή‘Ε·Μ·≤β ‘ΓΔ÷ΊΙΙΓΔ ΐΨίΩβ«®“ΤΓΔΟφœρΩΆΜßΒΡ≤ζΤΖΙφΗώΓΔΙφΜ°ΓΔΖΔ≤Φ - Υυ”–’β–©ΜνΕ·ΕΦ“ΣΨΓΩ…ΡήΤΒΖ±ΒΊΫχ––ΓΘ
‘≠“ρ÷ς“Σ”–»ΐΒψΘΚ
- Ήœ»Θ§ΥφΉ≈“ΣΉωΒΡΙΛΉςΝΩ÷πΫΞ‘ωΦ”Θ§’β–©»ΈΈώ“≤Μα±δΒΡ”ζΦ”άßΡ―Θ§ΒΪ»γΙϊΡή≤πΫβΈΣ–ΓΩιΘ§‘ρΜα±δΒΡœύΕ‘»ί“Ή–©ΓΘ“‘ ΐΨίΩβ«®“ΤΈΣάΐΘΚ“Μ–©…φΦΑ¥σΝΩ±μΒΡ¥σΙφΡΘ ΐΨίΩβ«®“ΤΙΛΉςΚή¬ιΖ≥Θ§»ί“Ή≥ω¥μΓΘΒΪ»γΙϊ“Μ¥Έ÷Μ«®“Τ“Μ≤ΩΖ÷Θ§‘ρΩ…“‘œύΕ‘Ϋœ»ί“ΉΒΊ≥…ΙΠΆξ≥…’ϊΗω«®“Τ»ΈΈώΓΘ¥ΥΆβΜΙΩ…“‘«αΥ…ΒΊΫΪΕύΗω–ΓΙφΡΘΒΡ«®“Τ»ΈΈώΑ≤≈≈≥…“ΜΕ®ΒΡ–ρΝ–Θ§‘ΎΫΪ“ΜΗωΦηΡ―ΒΡ¥σ»ΈΈώ≤πΫβΈΣ“ΜœΒΝ–»ί“Ή Βœ÷ΒΡ–ΓΡΩ±ξΚσΘ§¥ΠάμΤπά¥ΨΆΦρΒΞΕύΝΥΓΘΘ®’β“≤ « ΐΨίΩβ÷ΊΙΙΒΡ±Ψ÷ Θ©
- ΒΎΕΰΗω‘≠“ρ‘Ύ”ΎΖ¥άΓΓΘ¥σ≤ΩΖ÷ΟτΫίΥΦΈ§ΙΊΉΔΒΡ «…η÷ΟΖ¥άΓΜΖ¬ΖΘ§Ϋη¥Υ»ΟΈ“Ο«ΗϋΩλΥΌΒΊ―ßœΑΝΥΫβΓΘΖ¥άΓ“―Ψ≠ «ΦΪœό±ύ≥ΧΘ®Extreme ProgrammingΘ©÷–“ΜΗωΖ«≥Θ÷Ί“ΣΘ§‘ΧΚ§Ψό¥σΦέ÷ΒΒΡΗ≈ΡνΓΘ‘Ύ÷ν»γ»μΦΰΩΣΖΔΒ»Η¥‘”Νς≥Χ÷–Θ§Έ“Ο«–η“ΣΗϋΤΒΖ±ΒΊΦλ≤ιΉ‘ΦΚΒΡΉν–¬Ϋχ’ΙΘ§≤ΔΫχ––±Ί“ΣΒΡΨά’ΐΓΘΈΣ¥ΥΈ“Ο«±Ί–κΨΓ“Μ«–Ω…Ρή¥¥Ϋ®Ζ¥άΓΜΖ¬ΖΘ§≤ΔΧαΗΏΖ¥άΓΒΡΤΒ¬ Θ§’β―υ≤≈ΡήΗϋΩλΥΌΒΊΉΟ«ιΉω≥ωΒς’ϊΓΘ
- ΒΎ»ΐΗω‘≠“ρ « ΒΦυΓΘΕ‘”Ύ»ΈΚΈΜνΕ·Θ§‘ΫΤΒΖ±ΒΊ¥” ¬ΨΆ‘ΫΡήΜώΒΟΆξ…ΤΓΘ ΒΦυΩ…“‘Αο÷ζΈ“Ο«άμ«ε’ϊΗωΝς≥ΧΘ§»ΟΈ“Ο«Ηϋ λœΛ¥ζ±μ”– ¬«ι≥ω¥μΒΡ’ς’ΉΓΘ÷Μ“Σ»œ’φΉΝΡΞΉ‘ΦΚ¥” ¬ΒΡΙΛΉςΘ§ΨΆΡήΧαΝΕ≥ωΫϋ“Μ≤ΫΆξ…ΤΥυ–ηΒΡ ΒΦυΓΘΕ‘”Ύ»μΦΰΩΣΖΔΘ§“≤”–Ω…Ρή Βœ÷“ΜΕ®≥ΧΕ»ΒΡΉ‘Ε·Μ·ΓΘ“ΜΒ©”–»ΥΫΪΡ≥Φΰ ¬ΉωΝΥΕύ¥ΈΘ§ΨΆΩ…“‘Ηϋ»ί“ΉΒΊ»ΖΕ®ΗΟ»γΚΈΫχ––Ή‘Ε·Μ·Θ§Ηϋ÷Ί“ΣΒΡ «Θ§’β―υΒΡ»Υ‘ΎΕ‘’β–© ¬«ι Βœ÷Ή‘Ε·Μ·ΖΫΟφΫΪ”–Ηϋ¥σΒΡΕ·ΜζΓΘ¥Υ ±Ή‘Ε·Μ·”»ΈΣ÷Ί“ΣΘ§“ρΈΣΩ…“‘Φ”ΩλΥΌΕ»≤ΔΫΒΒΆ≥ω¥μΒΡΗ≈¬ ΓΘ
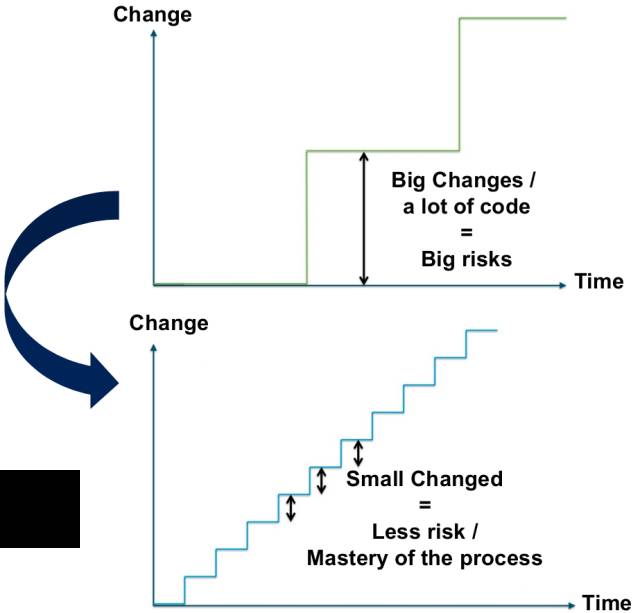
’ΤΈ’’ϊΗωΝς≥Χ
Ρ«Ο¥’βΨΆ≤ζ…ζΝΥ“ΜΗωΈ ΧβΘΚ Ι”ΟDevOpsΖΫΖ® ±Θ§ΗΟ―Γ‘ώ‘θ―υΒΡΫΜΗΕΤΒ¬ ΘΩ
’βΗωΈ ΧβΟΜ”–±ξΉΦ¥πΑΗΘ§Εχ «»ΓΨω”Ύ≤ζΤΖΓΔΆ≈Ε”ΓΔ –≥ΓΓΔΙΪΥΨΓΔ”ΟΜßΓΔ‘ΥΈ§–η«σΒ»Ης÷÷“ρΥΊΓΘ
Έ“»œΈΣΉνΦ―¥πΑΗ”ΠΗΟ «ΘΚ»γΙϊ≤ΜΡή Βœ÷÷Ν…ΌΟΩΝΫ÷ή“Μ¥ΈΫΜΗΕΘ§Μρ‘Ύ≥ε¥ΧΫΉΕΈΫα χ ±ΫΜΗΕΘ§Ρ«Ο¥Ν§ΟτΫίΕΦΧΗ≤Μ…œΘ§DevOps”÷¥”ΚΈΧΗΤπΡΊΘΩ
DevOpsΙΡάχΈ“Ο«ΨΓΩ…ΡήΤΒΖ±ΒΡΫΜΗΕΓΘ‘ΎΈ“Ω¥ά¥Θ§Ρψ–η“ΣΕ‘Ά≈Ε”Ϋχ––≈ύ―ΒΘ§»ΟΥϊΟ«ΡήΙΜΉωΒΫΨΓΩ…ΡήΤΒΖ±ΒΡΫΜΗΕΓΘΈ“‘ΎΈ“ΒΡΆ≈Ε”÷– Ι”ΟΒΡ“Μ÷÷ΫœΈΣΩ…––ΒΡΖΫΖ® «‘ΎQAΜΖΨ≥÷–ΟΩΧλΫΜΗΕΝΫ¥ΈΓΘΫΜΗΕΙΐ≥Χ «Άξ»ΪΉ‘Ε·Μ·ΒΡΘΚΟΩΧλΝΫ¥ΈΘ§÷–ΈγΚΆΈγ“ΙΗς“Μ¥ΈΘ§ΦΤΥψΜζΤτΕ·Τπά¥Θ§ΙΙΫ®»μΦΰΉιΦΰΘ§‘Υ––Φ·≥…≤β ‘Θ§ΙΙΫ®≤ΔΤτΕ·–ιΡβΜζΘ§≤Ω π»μΦΰΉιΦΰΘ§Ε‘ΤδΫχ––≈δ÷ΟΘ§‘Υ––ΙΠΡή≤β ‘Β»ΓΘ
3.4 ≥÷–χΫΜΗΕΒΡ«ΑΧα–η«σ
‘ΎΗΡΈΣ Ι”Ο≥÷–χΫΜΗΕΖΫ Ϋ÷°«ΑΘ§–η“Σ¬ζΉψΡΡ–©“Σ«σΘΩ
Έ“≤ίΡβΒΡ–η«σ«εΒΞ»γœ¬ΘΚ
- Ε‘»μΦΰΉιΦΰΒΡΩΣΖΔΚΆΤΫΧ®ΒΡΙ©”ΠΚΆ…η÷ΟΫχ––≥÷–χΦ·≥…ΓΘ
- TDD - ≤β ‘«ΐΕ·ΒΡΩΣΖΔΓΘ’β“ΜΒψΜΙ”–¥ΐ…Χ»ΕΓ≠Γ≠ΒΪ Φ÷’ΜΙ «–η“ΣΟφΕ‘ΘΚTDD «ΡΩ«ΑΈ®“ΜΡήΆ®ΙΐΒΞ‘Σ≤β ‘Ε‘¥ζ¬κΚΆΖ÷÷ßΫχ––Ω…Ϋ” ή≥ΧΕ»Η≤Η«ΒΡΖΫΖ®Θ®ΒΞ‘Σ≤β ‘ ΙΒΟΈ ΧβΒΡ–όΗ¥Ιΐ≥Χ±»Φ·≥…≤β ‘ΜρΙΠΡή≤β ‘»ί“ΉΚήΕύΘ©ΓΘ
- ¥ζ¬κ…σ‘ΡΘΓ÷Ν…Ό“ΣΫχ––¥ζ¬κ…σ‘ΡΓ≠Γ≠»γΙϊΡήΫχ––ΫαΕ‘±ύ≥ΧΘ®Pair programmingΘ©Β±»ΜΨΆΗϋΚΟΝΥΓΘ
- »μΦΰΒΡ≥÷–χ…σΦΤ - άΐ»γ Ι”ΟSonarΓΘ
- ‘Ύ…ζ≤ζΦΕΜΖΨ≥ Βœ÷ΙΠΡή≤β ‘ΒΡΉ‘Ε·Μ·ΓΘ
- Ηϋ«Ω¥σΒΡΖ«ΙΠΡή≤β ‘Ή‘Ε·Μ·Θ®–‘ΡήΓΔΩ…”Ο–‘Β»Θ©ΓΘ
- ΕάΝΔ”ΎΡΩ±ξΜΖΨ≥ΒΡΉ‘Ε·Μ·¥ρΑϋΚΆ≤Ω πΓΘ
ΝμΆβ‘ΎΙήάμ÷Ί¥σΙΠΡήΚΆ―ίΫχ ±Θ§ΜΙ–η“ΣΨΏ±ΗΫΓ»ΪΒΡ»μΦΰΩΣΖΔ ΒΦυΘ§άΐ»γΝψΆΘΜζ≤Ω πΦΦ θΓΘ
3.5 ΝψΆΘΜζ≤Ω π
ΓΑΝψΆΘΜζ≤Ω πΘ®ZDDΘ©Ω…‘Ύ≤Μ÷–Εœœ÷”–ΖΰΈώΒΡ«ιΩωœ¬≤Ω π–¬ΑφœΒΆ≥ΓΘΓ±
Ά®ΙΐZDDΖΫ Ϋ≤Ω π”Π”Ο≥Χ–ρ ±Θ§Ω…‘Ύ»Ζ±Θ”ΟΜß≤ΜΜα‘β”ω”Π”Ο≥Χ–ρΆΘΜζΒΡ«ΑΧαœ¬ΫΪ–¬Αφ”Π”Ο“ΐ»κ…ζ≤ζΜΖΨ≥ΓΘ¥””ΟΜßΚΆΙΪΥΨΒΡΫ«Ε»ά¥Ω¥Θ§’β”ΠΗΟ «ΉνΦ―≤Ω πΖΫ ΫΘ§“ρΈΣΩ…“‘‘Ύ≤Μ‘λ≥…»ΈΚΈ÷–ΕœΒΡ«ιΩωœ¬“ΐ»κ–¬ΙΠΡή≤Δ–όΗ¥BugΓΘ
œ¬ΈΡΫΪΫι…ή4÷÷ΦΦ θΘΚ
- ΙΠΡήΩΣΙΊΘ®Feature FlippingΘ©
- ΟΰΚΎΤτΕ·Θ®Dark launchΘ©
- άΕΘ·¬Χ≤Ω πΘ®Blue/Green DeploymentΘ©
- ΫπΥΩ»ΗΖΔ≤ΦΘ®Canari releaseΘ©
ΙΠΡήΩΣΙΊ
ΙΠΡήΩΣΙΊΩ…Ι©Έ“Ο«‘Ύ»μΦΰ‘Υ––Ιΐ≥Χ÷–Ττ”ΟΘ·Ϋϊ”Οœύ”ΠΒΡΙΠΡήΓΘ’β÷÷ΦΦ θΤδ ΒΖ«≥Θ»ί“ΉάμΫβΚΆ Ι”ΟΘΚΈΣ…ζ≤ζΑφ±ΨΧαΙ©“ΜΗωΡή≥ΙΒΉΫϊ”ΟΡ≥œνΙΠΡήΒΡ≈δ÷ΟΘ§≤Δ÷Μ‘ΎΕ‘”ΠΙΠΡή≥ΙΒΉΆξΙΛΩ…“‘’ΐ≥ΘΙΛΉςΚσ≤≈ΫΪΗΟ τ–‘ΦΛΜνΓΘ
ΨΌάΐά¥ΥΒΘ§»τ“ΣΫΪΡ≥Ηω”Π”Ο≥Χ–ρΡΎΒΡ“ΜΗωΙΠΡή»ΪΨ÷Ϋϊ”ΟΜρΦΛΜνΘΚ
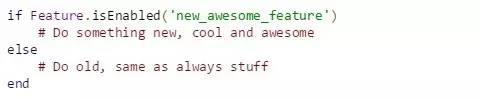
Μρ’Ώ»γΙϊ“Σ’φΕ‘ΨΏΧε”ΟΜß Βœ÷άύΥΤΡΩΒΡΘΚ
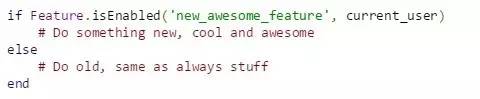
ΟΰΚΎΤτΕ·
ΟΰΚΎΤτΕ·ΒΡΡΩΒΡ‘Ύ”ΎΆ®Ιΐ…ζ≤ζΜΖΨ≥Ϋχ––ΗΚ‘ΊΡΘΡβΘΓ
‘Ύ≤β ‘ΜΖΨ≥÷–Θ§Ά®≥ΘΚήΡ―ΈΣ»μΦΰΡΘΡβ≥ω≥…ΑΌ…œ«ßΆρ”ΟΜßΙφΡΘΒΡΗΚ‘ΊΓΘ
»γΙϊ≤ΜΫχ––«– ΒΒΡΗΚ‘Ί≤β ‘Θ§ΨΆΈόΖ®÷ΣΒάΜυ¥ΓΦήΙΙΡήΖώ≥– ήΉΓΉν÷’ΟφΝΌΒΡ―ΙΝΠΓΘ
¥Υ ±≤Δ≤Μ–η“ΣΡΘΡβΗΚ‘ΊΘ§Εχ «Ω…“‘ ΒΦ ≤Ω π’β―υΒΡΙΠΡήΘ§»ΜΚσΩ¥Ω¥‘Ύ≤Μ”ΑœλΩ…”Ο–‘ΒΡ«ΑΧαœ¬ΒΫΒΉΜαΖΔ…ζ ≤Ο¥ΓΘ
FacebookΫΪ’β÷÷ΉωΖ®≥Τ÷°ΈΣΙΠΡήΒΡΓΑΟΰΚΎΤτΕ·Γ±ΓΘ
ΦΌ…ηΈ“Ο«“ΣΫΪ“ΜΗω”–5“Ύ”ΟΜß Ι”ΟΒΡΨ≤Χ§Υ―ΥςΉ÷ΕΈ±δ≥…“ΜΗωΑϋΚ§Ή‘Ε·≤Ι»ΪΙΠΡήΒΡΉ÷ΕΈΘ§Ϋη¥Υ»Ο”ΟΜßΩ…“‘ΗϋΩλΥΌΜώΒΟΥ―ΥςΫαΙϊΓΘΈΣΗΟΙΠΡήΙΙΫ®“ΜΗωWebΖΰΈώΘ§≤Δ«“œΘΆϊΡΘΡβΥυ”–”ΟΜßΆ§ ± δ»κΈΡΉ÷Θ§œρΗΟWebΖΰΈώ…ζ≥…¥σΝΩ«κ«σΒΡ≥ΓΨΑΓΘ
¥Υ ±Φ¥Ω…Ά®ΙΐΟΰΚΎΤτΕ·≤Ώ¬‘ΈΣœ÷”–±μΒΞΧμΦ”“ΜΗω“ΰ≤ΊΒΡΚσΧ®Ϋχ≥ΧΘ§Ά®ΙΐΗΟΫχ≥ΧΫΪ δ»κΒΡΥ―ΥςΙΊΦϋΉ÷ΖΔΥΆΗχ–¬‘ωΒΡΉ‘Ε·≤Ι»ΪΖΰΈώΘ§≤ΔΉ‘Ε·ΖΔΥΆΕύ¥ΈΓΘ
ΨΆΥψ–¬‘ωΒΡWebΖΰΈώ≥ΙΒΉ±άάΘΝΥΘ§“≤≤ΜΜα‘λ≥…»ΈΚΈ Β÷ ΥπΚΠΓΘΆχ“≥…œΩ…“‘Άξ»ΪΚω¬‘ΖΰΈώΤς¥μΈσΓΘΕχΨΆΥψΗΟΖΰΈώ±άάΘΝΥΘ§Έ“Ο«÷Ν…ΌΜΙΩ…“‘Ε‘ΗΟΖΰΈώΫχ––”≈Μ·ΚΆΆξ…ΤΘ§÷±ΒΫΡή≥– ή»γ¥Υ¥σΝΩΒΡΗΚ‘ΊΓΘ
’βΨΆΒ»”Ύ‘Ύœ÷ Β άΫγ÷–Ϋχ––ΝΥ“Μ¥ΈΗΚ‘Ί≤β ‘ΓΘ
άΕΘ·¬Χ≤Ω π
άΕΘ·¬Χ≤Ω π «÷ΗΈΣœ¬“ΜΑφ≤ζΤΖΙΙΫ®Νμ“ΜΗωΆξ’ϊΒΡ…ζ≤ζΜΖΨ≥ΓΘΩΣΖΔΚΆ‘ΥΈ§Ά≈Ε”Ω…“‘‘Ύ’βΗωΒΞΕάΒΡ…ζ≤ζΜΖΨ≥÷–Ζ≈–ΡΒΊΙΙΫ®œ¬“ΜΑφ≤ζΤΖΓΘ
Β±œ¬“ΜΑφ≤ζΤΖ»Ϊ≤ΩΆξ≥…ΚσΘ§Ω…“‘–όΗΡΗΚ‘ΊΨυΚβΤςΒΡ≈δ÷ΟΘ§“‘ΆΗΟςΒΡΖΫ ΫΫΪ”ΟΜßΉ‘Ε·÷ΊΕ®œρ÷Ν–¬ΖΔ≤ΦΒΡœ¬“ΜΑφΓΘ
ΥφΚσΩ…ΫΪ…œ“ΜΑφΒΡ…ζ≤ζΜΖΨ≥ΜΊ ’Θ§”Ο”ΎΙΙΫ®œ¬œ¬“ΜΑφΒΡ≤ζΤΖΓΘ
“‘¥ΥάύΆΤΓΘ
Θ®ά¥‘¥ΘΚLes Patterns des G®Πants du Web ®C Zero Downtime Deployment - http://blog.octo.com/zero-downtime-deployment/Θ©
’β «“Μ÷÷œύΒ±”––ßΦρΒΞΒΡΖΫΖ®Θ§ΒΪΈ Χβ‘Ύ”Ύ’β÷÷ΖΫ Ϋ–η“ΣΥΪ±ΕΒΡΜυ¥ΓΦήΙΙ“‘ΦΑΗϋΕύΒΡΖΰΈώΤςΒ»ΓΘ
ΦΌ…η“Μœ¬FacebookœΘΆϊΫΪΑϋΚ§≥…«ß…œΆρΧ®ΖΰΈώΤςΒΡΜΖΨ≥ΓΑ’’‘≠―υ‘Όά¥“ΜΧΉΓ±Γ≠Γ≠
Τδ ΒΜΙ”–ΗϋΚΟΒΡΖΫΖ®ΓΘ
ΫπΥΩ»ΗΖΔ≤Φ
¥”±Ψ÷ ά¥Ω¥Θ§ΫπΥΩ»ΗΖΔ≤Φ”κάΕΘ·¬Χ≤Ω πΖ«≥ΘάύΥΤΘ§ΒΪΈό–ηΉΦ±ΗΕνΆβΒΡ“ΜΧΉ…ζ≤ζΜΖΨ≥ΓΘ
’β÷÷ΖΫ ΫΒΡΡΩ±ξ‘Ύ”Ύ“‘‘ωΝΩΒΡΖΫ ΫΫΪ”ΟΜß«–ΜΜ÷Ν–¬Αφ±ΨΘΚΥφΉ≈‘Ϋά¥‘ΫΕύΒΡΖΰΈώΤς¥”Β±«ΑΑφ±Ψ«®“Τ÷Νœ¬“ΜΑφΘ§œύΆ§±»άΐΒΡ”ΟΜß“≤Μα±ΜΆ§ ±«®“ΤΓΘ
Ά®Ιΐ’β÷÷ΖΫ ΫΘ§ΟΩΗω…ζ≤ζΜΖΨ≥ΕΦΡήΜώΒΟ”κΗΚ‘Ί–η«σœύΤΞ≈δΒΡΖΰΈώΤς ΐΝΩΓΘ
Ήœ»Θ§÷ΜΫΪ…ΌΝΩΖΰΈώΤςΚΆ…Ό≤ΩΖ÷”ΟΜß«®“Τ÷Νœ¬“ΜΑφΘ§Ϋη¥ΥΜΙΩ…“‘‘ΎΈό–κΟΑœ’”ΑœλΥυ”–”ΟΜßΒΡ«ΑΧαœ¬Ε‘–¬ΑφΫχ––≤β ‘ΓΘ
Β±Υυ”–ΖΰΈώΤςΉν÷’¥”Β±«ΑΑφ«®“Τ÷Νœ¬“ΜΑφΚσΘ§ΖΔ≤ΦΙΛΉς“―Ψ≠Άξ≥…Θ§”÷Ω…“‘¥”ΆΖΩΣ ΦΉΦ±Ηœ¬œ¬“ΜΑφΝΥΓΘ
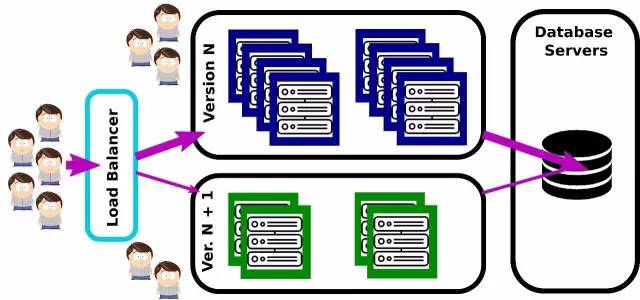
ΫπΥΩ»Η≤Ω πΘ®ά¥‘¥ΘΚLes Patterns des G®Πants du Web ®C Zero Downtime Deployment - http://blog.octo.com/zero-downtime-deployment/Θ©
4. –≠Ής
ΟτΫί»μΦΰΩΣΖΔΤΤ≥ΐΝΥ–η«σΖ÷ΈωΓΔ≤β ‘ΚΆΩΣΖΔ÷°ΦδΒΡ“Μ–©ΗτΚ“ΓΘ≤Ω πΓΔ‘ΥΈ§ΚΆΈ§ΜΛΒ»ΤδΥϊΜνΕ·”κ»μΦΰΩΣΖΔΙΐ≥Χ÷–ΒΡΤδΥϊΜΖΫΎ“≤¥φ‘ΎάύΥΤΒΡΖ÷ΗτΓΘDevOpsΖΫΖ®“β‘ΎΤΤ≥ΐΥυ”–’β–©ΗτΚ“Θ§ΙΡάχΩΣΖΔΚΆ‘ΥΈ§»Υ‘±÷°ΦδΒΡ–≠ΉςΓΘ
»γΙϊΟΜ”–≈ύ―χ≥ω’ΐ»ΖΒΡΈΡΜ·Θ§ΨΆΥψ”–ΉνΑτΒΡΙΛΨΏΘ§DevOpsΕ‘ΡψΕχ―‘“≤≤ΜΙΐ «Νμ“ΜΗω»»Ο≈¥ ΜψΑ’ΝΥΓΘ
DevOpsΈΡΜ·ΒΡ÷ς“ΣΧΊ’ς‘Ύ”ΎΩΣΖΔΚΆ‘ΥΈ§Ϋ«…Ϊ÷°Φδ»’“φ‘ωΦ”ΒΡ–≠ΉςΓΘ’β «“Μ÷÷‘ΎΆ≈Ε”ΡΎ≤Ω“‘ΦΑΉι÷·≤ψΟφ…œΚή÷Ί“ΣΒΡΈΡΜ·±δ«®Θ§Ά®Ιΐ’β―υΒΡ±δ«®≤≈Ρή¥ΌΫχΗϋΚΟΒΡ–≠ΉςΓΘ
’β÷÷ΖΫ ΫΫβΨωΝΥ“ΜΗωΖ«≥Θ÷Ί“ΣΒΡΈ ΧβΘ§Εχ’βΗωΈ ΧβΆξ»ΪΩ…“‘”Οœ¬Οφ’βΗωΆχ¬γΝς––ΜΑά¥Χεœ÷ΘΚ
ΩΣΖΔΙΛΉς“―Άξ≥…/œ÷‘Ύ’β «‘ΥΈ§ΒΡΈ ΧβΝΥ

Θ®ά¥‘¥ΘΚDevOps Memes @ EMCworld 2015 - http://fr.slideshare.net/bgracely/devops-memes-emcworld-2015Θ©
Ά≈Ε”ΚœΉςΕ‘DevOps «»γ¥ΥΒΡ÷Ί“ΣΘ§¥σ≤ΩΖ÷ΖΫΖ®¬έΥυ“Σ Βœ÷ΒΡΉν÷’ΡΩ±ξΉήΒΡά¥ΥΒΩ…“‘Ά®ΙΐΝΫΗωCά¥ Βœ÷ΘΚ–≠ΉςΘ®CollaborationΘ©ΚΆΙΒΆ®Θ®CommunicationΘ©ΓΘΥδ»ΜΒΞ¥ΩΉωΒΫ’β–©Ψύάκ’φ’ΐΒΡDevOpsΙΛΉςΜΖΨ≥ΜΙ”–Κή¥σΒΡ≤νΨύΘ§ΒΪ»ΈΚΈΙΪΥΨ÷Μ“ΣΡήΦα≥÷’βΝΫΗωCΘ§ΨΆΒ»”Ύ¬θ≥ωΝΥΉν’ΐ»ΖΒΡΒΎ“Μ≤ΫΓΘ
ΒΪΈΣ ≤Ο¥ΜαΡ«Ο¥Ρ―ΉωΒΫΘΩ
4.1 Μ묓÷°«Ϋ
“ρΈΣ”–“ΜΕ¬Μ묓÷°«ΫΘΚ
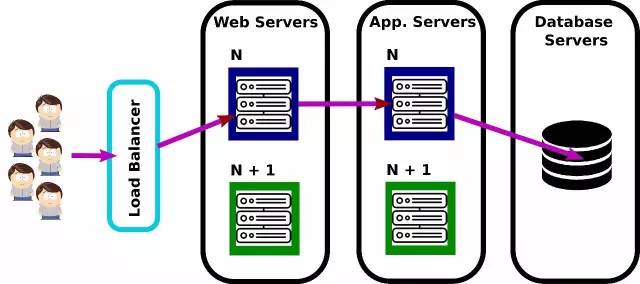
‘Ύ¥ΪΆ≥ΩΣΖΔ÷ήΤΎ÷–Θ§ΩΣΖΔΆ≈Ε”ΫΪ–¬ΖΔ≤ΦΒΡ»μΦΰΓΑΗτ«Ϋ»”ΗχΓ±‘ΥΈ§»Υ‘±Θ§“βΈΕΉ≈Ή‘ΦΚΒΡΙΛΉς“―Ψ≠Υ≥άϊΆξ≥…ΓΘ
‘ΥΈ§»Υ‘±Ϋ” ÷ΩΣΖΔ’ΏΒΡ≥…ΙϊΘ§ΉΦ±ΗΩΣ ΦΫχ––≤Ω πΓΘ‘ΥΈ§»Υ‘± ÷ΙΛ–όΗΡ”…ΩΣΖΔ’ΏΧαΙ©ΒΡ≤Ω πΫ≈±ΨΘ§Β±»ΜΗϋΕύ ±Κρ’β–©Ϋ≈±ΨΕΦ «‘ΥΈ§»Υ‘±Ή‘ΦΚΈ§ΜΛΒΡΓΘ
‘ΥΈ§»Υ‘±ΜΙ–η“Σ ÷ΙΛ–όΗΡ≈δ÷ΟΈΡΦΰΘ§“‘Ζ¥”≥…ζ≤ζΜΖΨ≥ΒΡ–η«σΘ§Εχ…ζ≤ζΜΖΨ≥ΆυΆυ”κΩΣΖΔΜρQAΜΖΨ≥”–Κή¥σ≤ν“λΓΘ
ΨΆΥψΉνάμœκΒΡ«ιΩωΘ§‘ΥΈ§»Υ‘±Ω…Ρή÷Μ «ΉωΝΥ“Μ–©‘Ύ…œ“ΜΗωΜΖΨ≥÷–“―Ψ≠ΉωΙΐΒΡ÷ΊΗ¥ΙΛΉςΘ§ΕχΉν‘ψΗβΒΡ«ιΩωΘ§Ω…ΡήΜα“ΐ»κΜρΖΔœ÷–¬ΒΡBugΓΘ
ΥφΚσIT‘ΥΈ§Ά≈Ε”ΩΣ ΦΧ÷¬έΥϊΟ«Υυ»œΈΣΒΡΘ§ΡΩ«ΑΉν’ΐ»ΖΒΡ≤Ω πΝς≥ΧΘ§»ΜΕχ”…”ΎΩΣΖΔΚΆ‘ΥΈ§‘ΎΫ≈±ΨΓΔ≈δ÷ΟΓΔΝς≥ΧΘ§…θ÷ΝΜΖΨ≥Β»ΖΫΟφΒΡ≤ν“λΘ§Μυ±Ψ…œΒ»Ά§”Ύ“Σ¥”ΝψΩΣ ΦΫΪΥυ”–ΙΛΉς÷Ί–¬÷¥––“Μ±ιΓΘ
Β±»Μ’β“ΜΙΐ≥Χ÷–≤ΜΩ…±ήΟβΜα”ωΒΫΈ ΧβΘ§ΥϊΟ«ΝΣœΒΩΣΖΔ’ΏœΘΆϊΫχ––≈≈¥μΓΘ‘ΥΈ§≥ΤΩΣΖΔ’ΏΧαΙ©ΒΡ¥ζ¬κ±Ψ…μ”–Έ ΧβΘ§ΩΣΖΔ’Ώ‘ρΜΊ”Π≥Τ¥ζ¬κ‘ΎΉ‘ΦΚΒΡΜΖΨ≥÷–“Μ«–’ΐ≥ΘΘ§“ρ¥Υ¥μΈσΩœΕ®‘¥Ή‘‘ΥΈ§ΕΥΓΘ
”…”Ύ≈δ÷ΟΓΔΈΡΦΰΈΜ÷ΟΘ§“‘ΦΑΟφΝΌ’β÷÷Ή¥Χ§Υυ÷¥––ΒΡ≤ΌΉς”κΉ‘ΦΚΒΡ‘ΛΤΎΒ»“ρΥΊ¥φ‘ΎΫœ¥σ≤ν“λΘ§ΩΣΖΔ’Ώ…θ÷ΝΚήΡ―Ε‘’β―υΒΡΈ ΧβΫχ––’οΕœΓΘ±δΗϋ¥ΑΩΎΝτœ¬ΒΡ ±ΦδΥυ ΘΈόΦΗΘ§Β±»Μ“≤ΟΜ ≤Ο¥ΉψΙΜΩΩΤΉΒΡΖΫΖ®ΫΪΜΖΨ≥ΜΊΙω÷Ν…œ“ΜΗω’ΐ≥ΘΉ¥Χ§ΓΘ
Ρ«Ο¥‘≠±Ψ”ΠΗΟ“ΜΖΪΖγΥ≥ΒΡ≤Ω πΙΐ≥ΧΘ§ΈΣ ≤Ο¥ΉνΚ󻥱δ≥…ΝΥΓΑ÷Ύ÷Ψ≥…≥«Γ±ΒΡ”ΠΦ±―ίœΑΘΩ±Ί–κΨ≠άζ¥σΝΩ÷Η‘πΚΆ¥μΈσ≤≈ΡήΉν÷’»Ο…ζ≤ζΜΖΨ≥Μ÷Η¥Ω…”ΟΉ¥Χ§ΘΩ
’β÷÷«ιΩωΨ≠≥ΘΖΔ…ζΘ§Ψ≠≥ΘΘΓ
DevOpsά¥Ψ»≥ΓΝΥ
Ά®Ιΐ‘ΎΙ≤Ά§ΒΡ“ΒΈώΡΩΒΡ«ιΨ≥÷–»ΟΩΣΖΔΚΆ‘ΥΈ§Ϋ«…Ϊ”κΝς≥Χ±δΒΡ“Μ÷¬Θ§DevOps”–÷ζ”Ύ¥ΌΫχITΒΡΆ≥“ΜΓΘΩΣΖΔΚΆ‘ΥΈ§ΕΦ–η“ΣΟς»ΖΘ§Ή‘ΦΚ «Ά≥“Μ“ΒΈώΝς≥ΧΒΡ“ΜΖίΉ”ΓΘDevOpsΥΦΈ§»Ζ±ΘΝΥΈό¬έΉι÷·ΫαΙΙ «‘θ―υΒΡΘ§ΗωΧεΨω≤Ώ”κ––ΈΣ–η“ΣΨΓΝΠΈΣΆ≥“ΜΒΡ“ΒΈώΝς≥ΧΧαΙ©÷ß≥÷ΚΆ¥ΌΫχΉς”ΟΓΘ
―«¬μ―ΖCTOWerner Vogel…θ÷Ν‘Ύ2014ΡξΥΒΙΐΘΚ
ΓΑΥ≠ΩΣΖΔΘ§Υ≠‘Υ––ΓΘΓ±
4.2 »μΦΰΩΣΖΔΝς≥Χ
œ¬ΆΦΦρ“ΣΟη ωΝΥΟτΫί»μΦΰΩΣΖΔΝς≥ΧΆ®≥ΘΒΡ―υΉ”ΓΘ
ΉνΩΣ ΦΘ§“ΒΈώ¥ζ±μ”κ≤ζΤΖΗΚ‘π»Υ“‘ΦΑΦήΙΙΆ≈Ε”ΚœΉςΕ®“ε»μΦΰΘ§’β“ΜΙΐ≥ΧΩ…ΡήΜα Ι”ΟStory MappingΚΆ”ΟΜßΙ ¬Θ§Μρ’Ώ Ι”ΟΗϋΆξ’ϊΒΡΙφΖΕΓΘ
ΥφΚσΩΣΖΔΆ≈Ε”Ά®ΙΐΕΧ‘ίΒΡΩΣΖΔ≥ε¥ΧΩΣΖΔ≥ω»μΦΰΘ§≤Δ‘ΎΟΩΗω≥ε¥ΧΫα χΚσΫΪ…ζ≤ζΨΆ–ςΑφ±ΨΒΡ»μΦΰΖΔ≤ΦΗχ“ΒΈώ”ΟΜßΘ§ΫχΕχ ’Φ·Ζ¥άΓ≤ΔΨΓΩ…ΡήΤΒΖ±ΒΊΒς’ϊΖΫœρΓΘ
ΉνΚσΘ§Ψ≠άζΙΐΟΩΗω–¬ΒΡάο≥Χ±°ΚσΘ§ΫΪ»μΦΰ≤Ω πΗχ’ϊΗω“ΒΈώœΏΗϋΙψΖΚΒΡ”ΟΜß»ΚΧεΓΘ
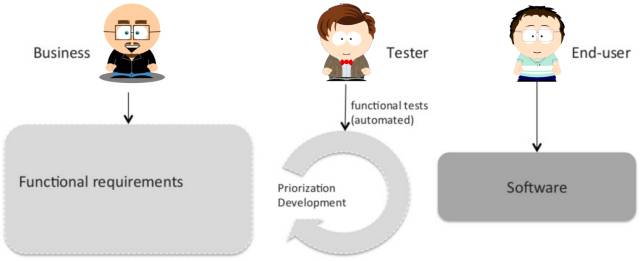
»μΦΰΩΣΖΔΝς≥Χ
DevOps‘λ≥…ΒΡΉν¥σΧτ’Ϋ‘Ύ”Ύ–η“ΣάμΫβ‘ΥΈ§»Υ‘± «»μΦΰΒΡΝμ“ΜΗω”ΟΜß»ΚΧεΘΓ“ρ¥ΥΥϊΟ«“≤”ΠΗΟ±Μ»ΪΟφΡ…»κ»μΦΰΩΣΖΔΝς≥Χ÷–ΓΘ
‘Ύ‘ΛΕ®ΒΡ ±ΦδάοΘ§‘ΥΈ§”ΠΗΟΗχ≥ωΉ‘ΦΚΒΡΖ«ΙΠΡή–η«σΘ§ΨΆ»γΆ§“ΒΈώ”ΟΜßΗχ≥ωΉ‘ΦΚΒΡΙΠΡή–η«σ“Μ―υΓΘΩΣΖΔΆ≈Ε””ΠΗΟΑ¥’’Ά§Β»≥ΧΕ»ΒΡ÷Ί“Σ–‘ΚΆ”≈œ»ΦΕ¥Πάμ’β÷÷Ζ«ΙΠΡή–η«σΓΘ
‘Ύ Βœ÷ΒΡΙΐ≥Χ÷–Θ§‘ΥΈ§”ΠΗΟ≥÷–χΧαΙ©Ζ¥άΓΚΆΖ«ΙΠΡή≤β ‘ΙφΖΕΘ§ΨΆœώ“ΒΈώ”ΟΜß’κΕ‘ΙΠΡήΧΊ–‘ΧαΙ©Ζ¥άΓ“Μ―υΓΘ
ΉνΚσΘ§‘ΥΈ§ΚΆ“ΒΈώ”ΟΜß“Μ―υΘ§≥…ΈΣΝΥ»μΦΰΒΡ”ΟΜßΓΘ
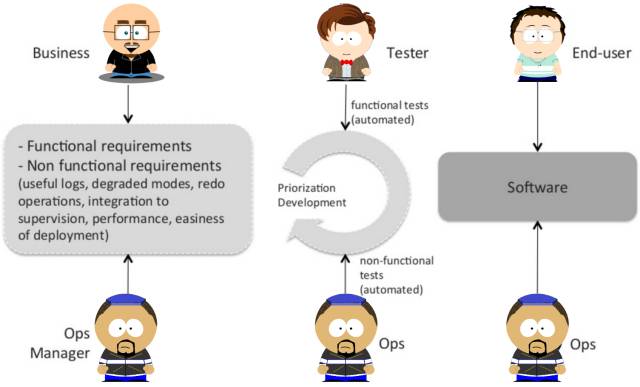
”–‘ΥΈ§»Υ‘±≤Έ”κΒΡ»μΦΰΩΣΖΔΝς≥Χ
Ά®Ιΐ≤…”ΟDevOpsΖΫΖ®Θ§‘ΥΈ§Ω…“‘»ΪΟφ»Ύ»κ»μΦΰΩΣΖΔΝς≥Χ÷–ΓΘ
4.3 Ι≤œμΙΛΨΏ
‘Ύ¥ΪΆ≥ΒΡ¥σ–ΆΤσ“Β÷–Θ§‘ΥΈ§Ά≈Ε”ΚΆΩΣΖΔΆ≈Ε”Ζ÷±π Ι”ΟΉ®”ΟΒΡΘ§ΟΜ”– ≤Ο¥ΫΜΦ·ΒΡΙΛΨΏΦ·ΓΘ
‘ΥΈ§»Υ‘±Ά®≥Θ≤Δ≤ΜœκΝΥΫβΩΣΖΔΆ≈Ε”Υυ Ι”ΟΒΡSCMœΒΆ≥“‘ΦΑ≥÷–χΦ·≥…ΜΖΨ≥ΓΘΥϊΟ«»œΈΣ’β–©≤ΔΖ«Ή‘ΦΚΒΡ±Ψ÷ΑΙΛΉςΘ§ΚΠ≈¬Ή‘ΦΚ‘Ύ¥ΞΦΑ’β–©œΒΆ≥ΚσΜα±ΜΩΣΖΔ’ΏΒΡΗς÷÷«κ«σΥυ―ΆΟΜΓΘ±œΨΙΥϊΟ«ΈΣΝΥ’’Νœ…ζ≤ζœΒΆ≥ΨΆ”–ΟΠ≤ΜΆξΒΡΙΛΉςΝΥΓΘ
Νμ“ΜΖΫΟφΘ§ΩΣΖΔ’ΏΆ®≥ΘΈόΖ®ΖΟΈ …ζ≤ζœΒΆ≥ΒΡ»’÷ΨΚΆΦύ ”»’÷ΨΘ§”– ±’β «“ρΈΣΟΜ”–’β―υΒΡ“β‘ΗΘ§”– ±‘ρ «“ρΈΣ÷ΤΕ»ΜρΑ≤»ΪΖΫΟφΒΡΙΥ¬«ΓΘ
’β÷÷Ή¥Ωω–η“ΣΗΡ±δΘΓDevOps”Π‘ΥΕχ…ζΓΘ
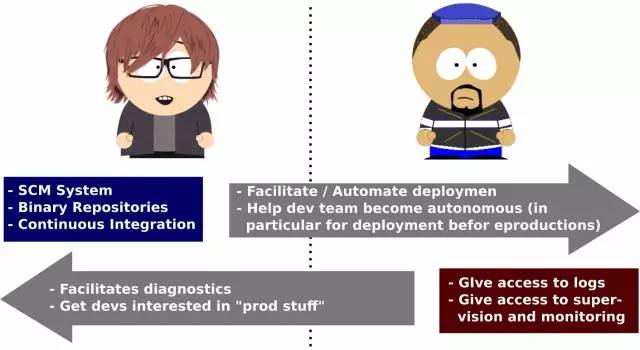
Ι≤œμΙΛΨΏ
’βΗωΡΩ±ξΤδ ΒΚήΡ― Βœ÷ΓΘΨΌάΐά¥ΥΒΘ§≥ω”Ύ÷ΤΕ»ΜρΑ≤»ΪΖΫΟφΒΡ‘≠“ρΘ§»’÷ΨΩ…ΡήΜα±Μ Β ±ΡδΟϊΜ·Θ§Ά§ ±–η“ΣΕ‘ΦύΙήΙΛΨΏΫχ––±Ί“ΣΒΡ±ΘΜΛΘ§“‘±ήΟβΈ¥Ψ≠≈ύ―ΒΜρ±Ψ”Π±ΜΫϊ÷ΙΒΡΩΣΖΔ’ΏΗϋΗΡ…ζ≤ζΜΖΨ≥ΒΡ≈δ÷ΟΓΘ“ρ¥Υ Βœ÷’β“ΜΡΩ±ξ–η“ΣΗΕ≥ω¥σΝΩ ±ΦδΚΆ≥…±ΨΉ ‘¥ΓΘΒΪ’β―υΉωΥυΡήΜώΒΟΒΡ ’“φ‘Ε¥σ”ΎΥυ–ηΫχ––ΒΡΆΕ»κΘ§’β÷÷ΖΫΖ®Ε‘’ϊΗωΙΪΥΨΒΡΆΕΉ ΜΊ±®Ζ«≥ΘΟςœ‘ΓΘ
4.4 –≠Ά§ΙΛΉς
DevOpsΒΡ“Μ÷÷Μυ±Ψ’ή―ß «»œΈΣΘ§ΩΣΖΔ’ΏΚΆ‘ΥΈ§»Υ‘±±Ί–κΕ®ΤΎΫχ––Οή«–ΒΡΚœΉςΓΘ
’βΨΆ“βΈΕΉ≈ΥϊΟ«±Ί–κΫΪΕ‘ΖΫ ”Ής÷Ί“ΣΒΡάϊ“φœύΙΊ’ΏΘ§≤ΔΜΐΦΪ÷ςΕ·ΒΊ―Α«σΚœΉςΓΘ
ήΒΫXP ΒΦυ÷–ΓΑœ÷≥ΓΩΆΜßΓ±ΒΡΤτΖΔΘ§ΟτΫίΩΣΖΔ’Ώ ή¥ΥΦΛάχΩ…“‘”κ“ΒΈώΫχ––ΗϋΫτΟήΒΡΚœΉςΘ§Ή‘¬…ΒΡΟτΫί’ΏΜΙΩ…“‘ΗϋΫχ“Μ≤ΫΫΪ’β―υΒΡ ΒΦυ‘Υ”ΟΗχΗϋΙψΖΚΒΡάϊ“φœύΙΊ’ΏΘ§άΐ»γΩ…“‘»ΟΩΣΖΔ’Ώ”κΥυ”–ΤδΥϊœύΙΊ’ΏΫχ––ΚœΉςΘ§Αϋά®‘ΥΈ§ΚΆ÷ß≥÷»Υ‘±ΓΘ
’β «“ΜΧθΥΪ––ΒάΘΚ‘ΥΈ§ΚΆ÷ß≥÷»Υ‘±“≤±Ί–κ‘Η“β”κΩΣΖΔ’ΏΫχ––Οή«–ΒΡΚœΉςΓΘ
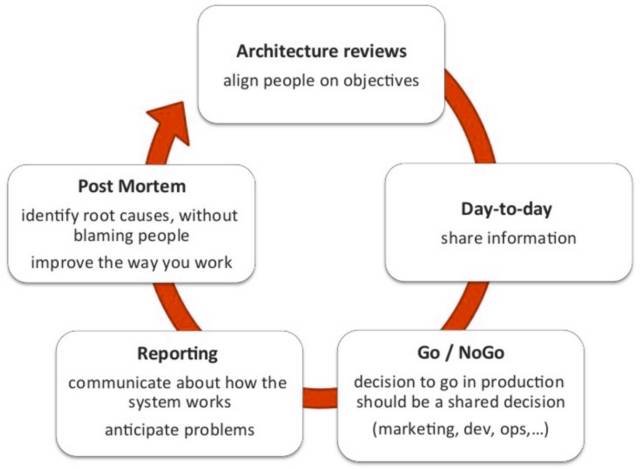
–≠Ά§ΙΛΉς
¥ΥΆβΜΙΩ…“‘Ά®Ιΐ–≠ΉςΘΚ
- »Ο‘ΥΈ§»Υ‘±≤Έ”κΟτΫί“« ΫΘ®ΟΩ»’ScrumΓΔ≥ε¥ΧΙφΜ°ΓΔ‘Ό¥Έ≥ε¥ΧΒ»Θ©
- »ΟΩΣΖΔ’Ώ≤Έ”κ…ζ≤ζΜΖΨ≥ΒΡΆΤ≥ω»ΈΈώ
- ‘ΎΩΣΖΔΚΆ‘ΥΈ§÷°Φδ¥ρ‘λΆ≥“ΜΒΡ≥÷–χΗΡΫχΡΩ±ξ
5. Ϋα¬έ
DevOps «“Μ¥ΈΗοΟϋΘ§÷ς“Σ «ΈΣΝΥœϊ≥ΐ”Β”–¥σΙφΡΘIT≤ΩΟ≈ΒΡ¥σ–ΆΤσ“Β÷–Θ§ΩΣΖΔΆ≈Ε”ΚΆ‘ΥΈ§Ά≈Ε”÷°Φδ”…”Ύάζ Ζ‘≠“ρ≤ζ…ζΒΡΗτΚ“”κΙ¬ΝΔΥυ‘λ≥…ΒΡΜ묓œ÷Ή¥ΓΘ
‘ΎΈ“15ΡξΒΡ÷Α“Β…ζ―Ρ÷–Θ§2/3ΒΡ ±ΦδΨΆ÷Α”Ύ¥Υάύ¥σ––ΜζΙΙΘ§Τδ÷–¥σ≤ΩΖ÷ «Ϋπ»ΎΜζΙΙΘ§ΟΩΧλΈ“ΕΦ‘ΎΦϊ÷Λ’Ώ’βΕ¬Μ묓÷°«ΫΒΡ¥φ‘ΎΓΘάΐ»γΈ“Ψ≠≥ΘΜαΧΐΒΫ’β―υΒΡΥΒΖ®ΘΚ
- ΓΑ‘ΎΈ“ΒΡTomcat…œΙΛΉςΚή’ΐ≥ΘΘ§Κή±ß«ΗΘ§ΒΪΈ“Άξ»Ϊ≤ΜΕ°ΡψΥυ”ΟΒΡWebsphereΘ§Αο≤Μ…œΡψΝΥΓΘΓ±Θ®ΩΣΖΔ’ΏΥΒΘ©
- ΓΑΈ“Ο«’φΒΡ≤ΜΡή¥”…ζ≤ζ ΐΨίΩβ÷–ΗχΡψΧα»Γ’β’≈±μΘ§άοΟφΑϋΚ§ΝΥ”κΩΆΜß”–ΙΊΒΡΜζΟή ΐΨίΓΘΓ±Θ®‘ΥΈ§»Υ‘±ΥΒΘ©ΟΩΧλΕΦΜα”ωΒΫΤδΥϊΚήΕύάύΥΤΒΡΕ‘ΜΑΓ≠Γ≠ΧλΧλ»γ¥ΥΘΓ
ΚΟ‘ΎDevOps»’ΫΞ≥… λΘ§‘Ϋά¥‘ΫΕύ¥ΪΆ≥Τσ“Β“≤‘ΎΩΣ Φ÷πΫΞΉΏ…œ’ΐΆΨΘ§ΩΣ ΦΫ” ήDevOpsΒΡ‘≠‘ρΚΆ ΒΦυΓΘΒΪΜΙ”–ΚήΕύΤσ“ΒΈόΕ·”Ύ÷‘ΓΘ
Ρ«Ο¥Ε‘”ΎΡ«–©–ΓΙφΡΘΒΡΘ§ΩΣΖΔΚΆ‘ΥΈ§÷ΑΡή÷°ΦδΆ®≥Θ≤ΜΜα≤ζ…ζΡ«Ο¥¥σΖ÷ΤγΒΡΤσ“ΒΡΊΘΩ
’β―υΒΡΤσ“Β”Π”ΟDevOps‘≠‘ρΚΆ ΒΦυΘ§άΐ»γΉ‘Ε·Μ·≤Ω πΓΔ≥÷–χΫΜΗΕΚΆΙΠΡήΩΣΙΊΘ§“Μ―υΡήΜώ“φΖΥ«≥ΓΘ
Έ“»œΈΣDevOps‘≠‘ρΩ…“‘ΉήΫαΈΣΘΚ
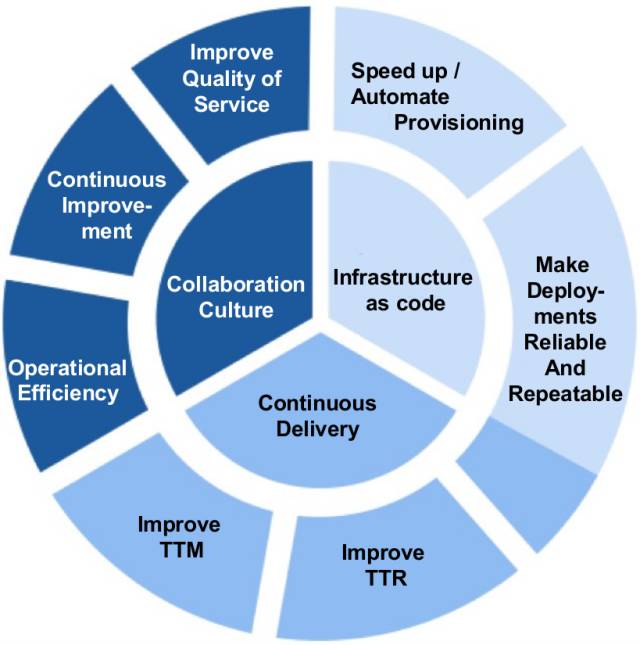
DevOps ΒΦ …œ «œρΉ≈¥σΙφΡΘΟτΫίΘ®Scaling AgilityΘ©¬θ≥ωΒΡΝμ“Μ≤ΫΘΓ |









