| 编辑推荐: |
本文主要讲解了计算单元三种构型、 硬件隔离(适用于多核MCU)、.软件虚拟化Hypervisor、Hypervisor的技术原理
、车载场景下方案实现等相关内容。
本文来自于微信 汽车电子与软件,由火龙果软件Anna编辑、推荐。 |
|
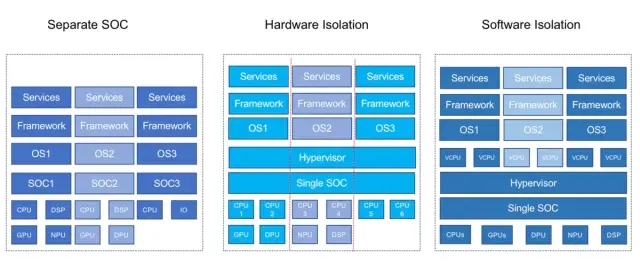
1 计算单元三种构型
之前的文章中,为大家介绍过计算单元的三种构建方式,虽然集中式的计算机是一个趋势,但并不是所有任务都适合放在中央计算机上运行,在进行多个ECU合并的过程中,原来ECU的硬件会合并为少数几个XCU,硬件隔离与软件虚拟化,是保证相互之间功能不相互干扰的重要技术手段。
中央计算单元构型.jpg
分离式是指,将多个不同的芯片集成到一个计算单元上去,每个运行不同的操作系统,只是在形态上集中到了一起,各单元依然独立的完成各自任务,代表如特斯拉AP,奥迪zFAS等。
硬件隔离式是指,在统一的计算平台上采用虚拟化方案,同时运行多个操作系统,但是各个系统依然在硬件上进行隔离,每个系统都有自己的专属硬件资源。
软件虚拟式是指,在统一的计算平台上采用虚拟化方案,同时运行多个操作系统,每个操作系统所使用的硬件资源,由Hypervisor层动态调配,每个系统并没有专属的硬件资源。
分离式最大的好处就是功能边界清晰,相比于传统的独立的BOX,只需要在电路设计上,把每个芯片放在不同的PCB板,然后将多块PCB叠加在一起。坏处就是,硬件资源浪费,每个芯片都需要一个最小系统,并且硬件上还没法拓展。
硬件隔离式和软件虚拟式,都采用了虚拟化方案,唯一不同点在于硬件资源是否专属,如果是专属的,就意味着资源无法动态调配,容易产生资源浪费。虚拟化方案最大的好处是,硬件上的可拓展性,如果中央计算单元采用刀片式的设计结构,可以很方便的拓展计算单元的算力,而不用替换整个计算单元。
2 硬件隔离
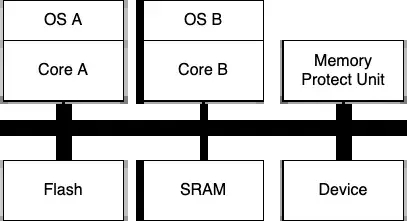
Hypervisor大家听到的比较多了,一般用在多核MPU上进行OS的虚拟化,很多软件厂商也在做多核MCU上的Hypervisor方案,但严格意义上讲,这类方案称为“Hypervisor”并不准确。所谓的多核MCU上的“虚拟化方案”,其实就是采用了AMP的架构,核心工作就是划分内存、配置CPU运行模式等工作。
Hypervisor-AMP.png
目前支持多核处理器的体系结构有对称多处理SMP(Symmetric Multi-Processing)构架和非对称多处理AMP(Asymmetric
Multi-Processing)构架两种。
AMP模式,各个CPU上运行不同的操作系统实例,各个操作系统拥有自己专用的内存,相互之间通过访问受限的共享内存进行通信。
SMP模式,系统中所有CPU的地位相同,共同运行一个操作系统实例,所有CPU共享系统内存和外设资源。
在传统的汽车电子ECU当中,绝大部分使用的计算单元都称为“MCU”,和另外一个大家经常听到“MPU”有很大区别,估计很多人也有一些疑问吧,究竟MCU和MPU有什么区别?其实这个两个词的边界正越来越模糊,高性能的MCU与MPU之间的差异也越来越小,其中一个比较重要的差异就是,MCU片上只有内存保护单元,而MPU通常都有MMU(
最新的Cortex-R82也支持MMU)。
多核MCU上只有内存保护单元而没有MMU,是无法做到真正意义上的虚拟化的,而基于AMP架构,运行多个操作系统,本质上和采用多个单核的MCU没有太大差异,所以称为“硬件隔离”更加准确。在追求可靠性、确定性、低延时的MCU应用场景中,硬件隔离是一种更好的选择,对纯软件的虚拟化方案需求并不是很高。
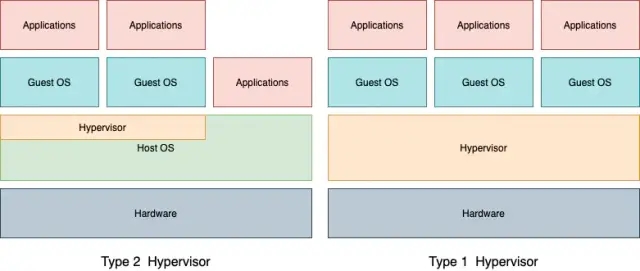
3 软件虚拟化Hypervisor
Hypervisor通常被分成Type1与Type2,Type1类型的Hypervisor直接运行在硬件之上,Hypervisor需要自己管理所有硬件资源;Type2类型的Hypervisor运行在某个Host系统之上,利用Host系统对硬件资源进行访问。大家在PC上使用的Virtual
Box和VMware虚拟机,就属于Type2的类型。
Hypervisor-Type1-Type2.png
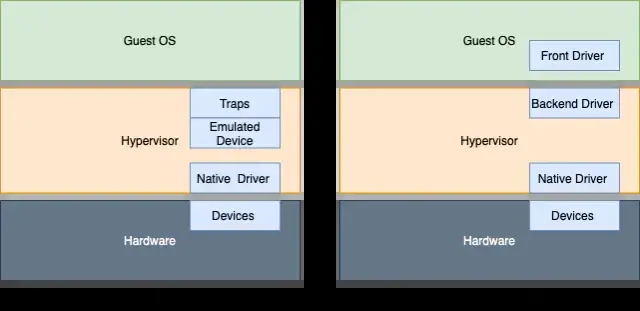
全虚拟化时,Hypervisor完整模拟了所有硬件资源,Guest OS不知道正在被虚拟化,它也不需要任何修改就能运行,Hypervisor负责捕获并处理所有特权指令,如果Guest
OS使用的指令集架构与物理设备的相同(例如都是ARM64),那么用户级别的指令可以直接在物理设备上运行。
在某些场景下,要完全模拟一个真实的物理设备是非常慢的,因为所有对模拟寄存器的访问都会产生一个软中断,之后系统需要切换处理器特权模式,陷入到Hypervisor当中进行模拟,这样会带来很多额外的性能开销。
为了解决这个问题,部分外围设备会采用半虚拟化,半虚拟化方式需要修改Guest OS,使之意识到自身运行在虚拟机当中,通过Guest
OS当中的前端驱动,与Hypervisor中的后端驱动进行直接通信,以此来换取更好得I/O性能,virtio就是一种半虚拟化的方案。
Hypervisor-virtio.png
4 Hypervisor的技术原理
下面将以ARMv8-A架构为例介绍一下Hypervisor的实现原理。
4.1处理器特权模式
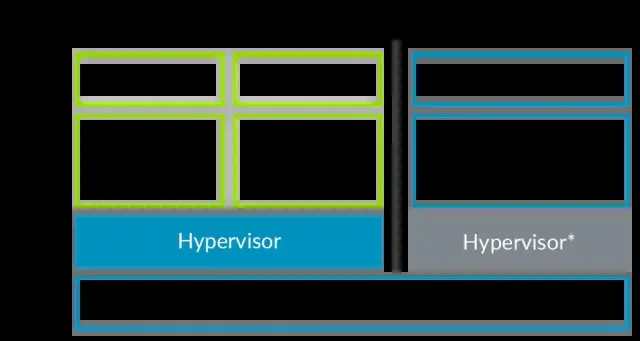
几乎所有的操作系统、虚拟化方案都是建立在处理器特权模式的基础之上的,ARMv8定义了4种特权级别:
EL0:Application
EL1:OS Kernel
EL2:Hypervisor
EL3:Secure Monitor
从EL0-EL3,特权级别依次升高,应用软件发起的系统调用(ARM上是svc,x86上是int),或者产生了外部中断,会导致特权级别的变更。
EL.png
从上面这张图当中可以看出,Application、OS、Hypervisor 等,分别运行在不同的特权级别上,应用程序可以通过系统调用陷入到OS或者Hypervisor当中,以执行不同的特权指令。
4.2 处理器编程模型
如果不理解处理器的编程模型,接下里很多概念将无法理解,所以先简短介绍一下,以下以ARMv8
AArch64为例,解释了处理器的运行过程。
.section ".text.boot"
.globl _start
.org 0x80000 //制定内核入口地址
_start:
ldr x5, =_start // 建立堆栈
mov sp, x5
ldr x5, =__bss_start // 清BSS
ldr w6, =__bss_size
3: cbz w6, 4f
str xzr, [x5], #8
sub w6, w6, #1
cbnz w6, 3b
4: bl kernel_main //跳转到C代码
b 1b
void kernel_main()
{
init_uart(); //初始化设备
init_vmm(); //初始化内存、mmu、Pagetable
init_irqs(); //初始化中断向量表
init_timer(); //初始化时钟
struct guestVM_s *guest = createVM (0x48000000,
0x20000000); //创建guest实例
enable_IRQS(); //开中断
schedule(guest);//调度guest os执行
}
|
没有做过系统软件或者嵌入式软件的人,会觉得处理器的启动是个特别复杂的过程,其实从软件角度来看,一点也不复杂,一个裸机硬件,只要经过以下步骤就能运行起来:
通过汇编初始化CPU,建立堆栈。
跳转执行C函数。
看不懂汇编没关系,只要知道,要对裸机进行编程,只需要一段汇编建立C语言运行必要的堆栈,剩下的就可以全用C解决了,在用C写的kernel_main当中,需要做以下几件事情:
初始化设备
初始化内存、设置MMU、建立页表
初始化中断向量表
初始化时钟
创建任务(实例代码中是创建虚拟机实例)
开启中断
进行任务调度
原理上很简单,但还有一些基本的事情要做,虽然已经可以用C写代码了,但是大家所熟悉的libc还不能使用,为此,你必须建立自己的syscall和libc,之后才能方便的构建后续代码。
这部分内容其实都是操作系统的基本原理,虽然电子相关专业的学生都学过这门课程,但估计有90%的人从来没有自己动手写过Kernel。想要了解更多详细内容,请参考ARM官网的ARMv8指令集架构
介绍这么多,其实最核心的是要理解中断向量表的概念,所有的系统调用和大家所熟知的驱动程序,最后都是以某种方式链接到这里,因此运行在EL1和EL2的OS内核与Hypervisor就有机会去捕获这些异常与中断,该原理是虚拟化实现的最基本的技术基础。
4.3 系统调用
上面EL0-EL3层次的划分,会让很多人觉得各层的软件是并行运行的,其实在单个CPU的层面,代码的运行都是顺序执行的,举个ARM64汇编的例子:
.text //code
section
.globl _start
_start:
mov x0, 0 // stdout has file descriptor 0
ldr x1, =msg // buffer to write
mov x2, len // size of buffer
mov x8, 64 // sys_write() is atHello world in
assembly language ARM64 (AArch64, ARMv8)
.text //code section
.globl _start
_start:
mov x0, 0 // stdout has file descriptor 0
ldr x1, =msg // buffer to write
mov x2, len // size of buffer
mov x8, 64 // sys_write() is at index 64 in
kernel functions table
svc #0 // generate kernel call sys_write (stdout,
msg, len);
mov x0, 123 // exit code
mov x8, 93 // sys_exit() is at index 93 in kernel
functions table
svc #0 // generate kernel call sys_exit(123);
.data //data section
msg:
.ascii "Hello, World!\n"
len = . - msg
|
以上代码其实等价为调用sys_write与sys_exit两个系统调用,如果调用libc的函数,大概效果就是printf("hello
world!")。在设置完参数寄存器之后,调用svc指令,cpu就会去之前设置的中断向量表中,查找相关的中断子服务。
4.4 内存虚拟化
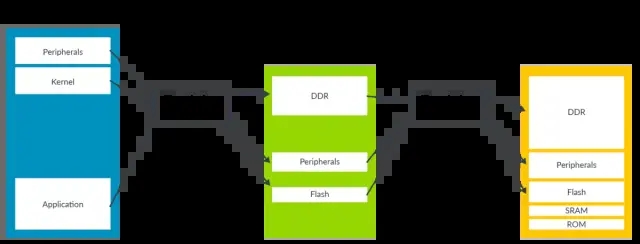
在整个Hypervisor的技术架构当中,内存的虚拟化是基石,而MMU是实现内存虚拟化的硬件基础,内存的虚拟化依赖于MMU的两级页表转换机制(Stage1与Stage2),它允许Hypervisor控制虚拟机的内存视图。
Guest OS控制的页表转换称之为stage 1转换,负责将Guest OS视角的虚拟地址(VA)转换为中间物理地址(IPA),而stage
2转换由Hypervisor控制,负责将中间地址(IPA)转换为真实的物理地址(PA)。
VA-IPA-PA.png
4.5 设备虚拟化
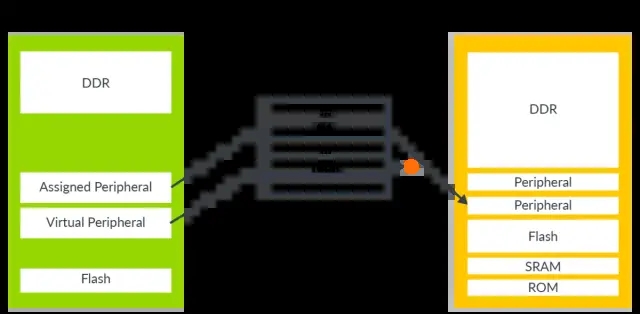
应用程序要访问外部设备,经过Guest OS的driver处理,其实就是访问中间物理地址IPA的一块内存区域,如果将这个IPA和设备真实的物理地址PA映射起来,那么该物理设备就被Guest
OS 独占了,这种设备就叫做直通设备(Pass-through)。
如果该IPA没有和真实的物理地址映射,那么在stage2转换的过程中就会产生一个EL2异常,该异常会被运行在EL2的Hypervisor捕捉到,通过中断向量表的地址,就能够找到处理该异常的子程序,从而就能够在当中模拟设备的行为。
Stage2-fault.png
5 硬件隔离与软件虚拟化方案开发
5.1 多核MCU硬件隔离
前面也介绍过了硬件隔离的方案,本质上其不属于Hypervisor的范畴,要使用硬件隔离方案,有几点需要注意:
需要支持内存保护单元的多核MCU芯片,这个条件很好满足,英飞凌和NXP的多核MCU基本都支持。
需要一家提供硬件隔离方案的软件供应商,虽然硬件隔离的技术方案主要是依赖硬件特性,自己做的技术门槛不高,但一般的玩家也不太能自己搞定,。
需要运行在不同核心上的基础软件,比如Autosar或者FreeRTOS等,需要一定的porting和配置工作才能在隔离后的硬件上运行起来。
如果选择的MCU的芯片支持的IO接口足够,完全可以把IO资源以独占的方式给到某个核心使用,如果某些接口只有一个,比如以太网,要在两个核心之间共享,实现起来就比较麻烦。
需要一套稳定可靠的核间通信机制,该机制一般需要基于共享的内存区域去实现。
5.2 多核MPU虚拟化
为了在多核MPU上使用软件的虚拟化方案,以下条件是必备的:
支持虚拟化的多核处理器
内存管理单元MMU与IOMMU
Hypervisor Monitor Software(Blackberry的Hypervisor
2.0 或者开源的Xen等)
运行虚拟化的内核(Linux或者QNX)
稳定可靠的虚拟化驱动支持
MPU上的虚拟化方案使用起来比较复杂,和所要使用的芯片厂商非常相关, 市场上有很多家提供Hypervisor
Monitor Software软件的公司,也可以选择开源的方案,主要的瓶颈不是在Hypervisor运行框架本身,其本质上是一个操作系统中间件,工作量最大的还是在驱动之上,因为大型MPU上的设备和驱动非常复杂。
像高通这样的公司,会基于第三方公司的Hypervisor框架,把所有Host与Guest系统上的驱动开发整合完毕再提供给客户,出了问题找高通就行了,一般很少和第三方Hypervisor框架供应商有很多交集。
其他的很多芯片厂商,本身并不提供完整的虚拟化解决方案,客户必须自己,或者找第三方的公司合作,把所有Host与Guest系统上front/backend驱动开发完毕。
在中央计算单元所有的外设当中,最复杂的有这么几大块:Graphics、Video、 Audio、AI
Core,而这其中Graphics又是排名第一的。这几个都是消耗内存和计算资源的大户,几乎70%的导致系统不稳定的问题,都出自这几个大户。
6 结语
从这些技术细节也可以看到,硬件隔离的可靠性其实是非常高的,软件的虚拟的Guest OS的确存在一些不稳定因素,但其实在中央计算单元中,只需要两个操作系统即可,用于自动驾驶、车控、网关的RTOS,以及用于娱乐的普通OS(如Android、Linux)。用于娱乐的OS完全可以通过虚拟机的方式运行,用于自动驾驶、车控、网关的RTOS,可以直接运行在Hypervisor层,这样在兼顾实时计算的要求的前提下也能获得丰富的娱乐系统功能。
|







 订阅
订阅