| БрМЭЦМі: |
БОЮФжаНЋРћгУApache
Spark(CoreЃЌSQLЃЌStreaming)ЃЌApache ParquetЃЌTwitter
StreamЕШЪЕЪБСїЪ§ОнПьЫйЗУЮЪРњЪЗЪ§ОнЁЃЯЃЭћЖдФњгаЫљАяжњ
БОЮФРДздгкit168ЃЌгЩЛ№СњЙћШэМўDeloresБрМЁЂЭЦМіЁЃ |
|
Apache HadoopМђЪЗ
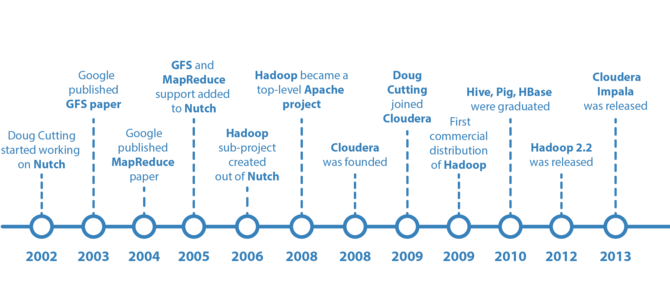
ЁЁApache HadoopгЩ Apache Software Foundation ЙЋЫОгк 2005 ФъЧяЬьзїЮЊLuceneЕФзгЯюФПNutchЕФвЛВПЗже§ЪНв§ШыЁЃЫќЪмЕНзюЯШгЩ Google Lab ПЊЗЂЕФ Map/Reduce КЭ Google File System(GFS) ЕФЦєЗЂЁЃЫќГЩЮЊвЛИіЖРСЂЯюФПЕФЪБМфвбга10ФъЁЃ ФПЧАвбОгаКмЖрПЭЛЇЪЕЪЉСЫЛљгкHadoopЕФM / RЙмЕРЃЌВЂГЩЙІдЫааЕНЯждкЃК OozieЕФЙЄзїСїУПШедЫааДІРэ150TBвдЩЯЕФЪ§ОнВЂЩњГЩЗжЮіБЈИц ЁЁBashЕФЙЄзїСїУПШедЫааДІРэ8TBвдЩЯЕФЪ§ОнВЂЩњГЩЗжЮіБЈИц
2016ФъЩЬвЕЯжЪЕЗЂЩњСЫБфЛЏЃЌдНПьзіГіОіВпЭљЭљМлжЕОЭЛсдНДѓЁЃСэЭтЃЌММЪѕБОЩэвВдкЗЂеЙЃЌKafkaЃЌStormЃЌTridentЃЌSamzaЃЌSparkЃЌFlinkЃЌParquetЃЌAvroЃЌдЦЬсЙЉЩЬЕШЖМГЩЮЊСЫЙЄГЬЪІУЧЕФСїаагя вђДЫЃЌЯжДњЛљгкHadoopЕФM / RЙмЕРПЩФмЛсЪЧЯТЭМЫљЪОЕФетбљЃК
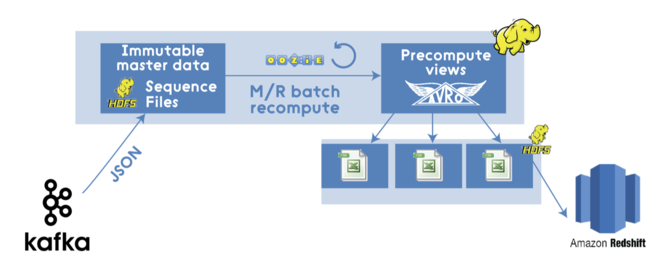
ЭМЩЯЕФM/RЭЈЕРПДЦ№РДВЛДэЃЌЕЋЦфЪЕЫќБОжЪЩЯЛЙЪЧвЛИіДЋЭГЕФХњДІРэЃЌгазХДЋЭГХњДІРэЕФШБЕуЃЌЕБаТЕФЪ§ОндДдДВЛЖЯЕФНјШыЯЕЭГжаЪБЃЌЛЙЪЧашвЊДѓСПЕФЪБМфРДДІРэЁЃ
ЁЁЁЁLambda МмЙЙ еыЖдЩЯУцЕФЮЪЬтЃЌNathan MarzЬсГіСЫвЛИіЭЈгУЁЂПЩРЉеЙКЭШнДэадЧПЕФЪ§ОнДІРэМмЙЙМДLambdaМмЙЙЃЌЫќЪЧЭЈЙ§РћгУХњДІРэКЭСїДІРэЗНЗЈРДДІРэДѓСПЪ§ОнЕФЁЃNathan MarzЕФЪщЖдДгдДТыЕФНЧЖШЖдLambdaМмЙЙНјааСЫЯъОЁЕФНщЩмЁЃ ВуНсЙЙ етЪЧLambdaМмЙЙздЩЯЖјЯТЕФВуНсЙЙЃК
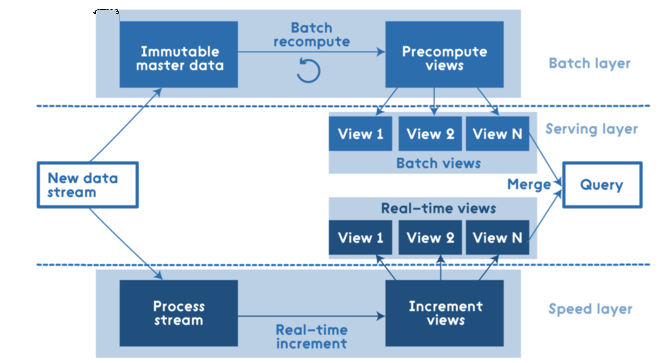
ЫљгаЪ§ОнНјШыЯЕЭГКѓЖМЗжХЩЕНХњДІРэВуКЭЫйЖШВуНјааДІРэЁЃХњДІРэВуЙмРэжїЪ§ОнМЏ(вЛИіВЛПЩБфЕФЃЌжЛПЩдіМгЕФдЪМЪ§ОнМЏ)ЃЌВЂдЄЯШМЦЫуХњДІРэЪгЭМЁЃ ЗўЮёВуЖдХњЪгЭМНјааЫїв§ЃЌвдБуПЩвдНјааЕЭбгГйЕФСйЪБВщбЏЁЃ ЫйЖШВуНіДІРэзюНќЕФЪ§ОнЁЃЫљгаЕФВщбЏНсЙћЖМБиаыКЯВЂХњДІРэЪгЭМКЭЪЕЪБЪгЭМЕФВщбЏНсЙћЁЃ ЁЁвЊЕу аэЖрЙЄГЬЪІШЯЮЊLambdaМмЙЙОЭжЛАќКЌВуНсЙЙКЭЖЈвхЪ§ОнСїГЬЃЌЕЋЪЧNathan MarzЕФЪщжаЮЊЮвУЧНщЩмСЫЦфЫќМИИіБШНЯживЊЕФЕуЃК ЗжВМЪНЫМЯы БмУтдіСПНсЙЙ Ъ§ОнЕФВЛБфад ДДНЈжиаТМЦЫуЫуЗЈ Ъ§ОнЕФЯрЙиад
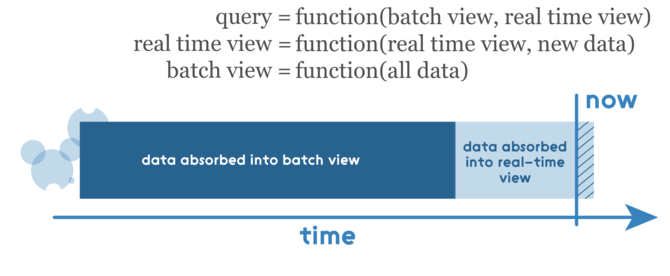
ШчЧАЫљЪіЃЌШЮКЮВщбЏНсЙћЖМБиаыЭЈЙ§КЯВЂРДздХњДІРэЪгЭМКЭЪЕЪБЪгЭМЕФНсЙћЃЌвђДЫетаЉЪгЭМБиаыЪЧПЩКЯВЂЕФЁЃдкетРявЊзЂвтЕФвЛЕуЪЧЃЌЪЕЪБЪгЭМЪЧЧАвЛИіЪЕЪБЪгЭМКЭаТЪ§ОндіСПЕФКЏЪ§ЃЌвђДЫетРяЪЙгУдіСПЫуЗЈЃЌХњДІРэЪгЭМЪЧЫљгаЪ§ОнЕФКЏЪ§ЃЌвђДЫгІИУЪЙгУжиаТМЦЫуЫуЗЈЁЃ ЁЁШЈКт ЁЁЪРМфЭђЮяЖМЪЧдкВЛЖЯЭзаКЭШЈКтжаЗЂеЙЕФЃЌLambdaНсЙЙвВВЛР§ЭтЁЃЭЈГЃЃЌЮвУЧашвЊНтОіМИИіжївЊЕФШЈКтЃК ЁЁЭъШЋжиаТМЦЫу vs.ВПЗжжиаТМЦЫу дкгааЉЧщПіЯТЃЌПЩвдЪЙгУBloomЙ§ТЫЦїРДБмУтЭъШЋжиаТМЦЫу жиМЦЫуЫуЗЈ vs. діСПЫуЗЈ діСПЫуЗЈЦфЪЕКмОпЮќв§СІЃЌЕЋЪЧгаЪБИљОнжИФЯЃЌЮвУЧБиаыЪЙгУжиМЦЫуЫуЗЈЃЌМДБуЫќКмФбЕУЕНЯрЭЌЕФНсЙћ ЁЁМгЗЈЫуЗЈ vs. НќЫЦЫуЗЈ ЁЁЫфШЛLambdaМмЙЙФмЙЛгыМгЗЈЫуЗЈКмКУЕиаЭЌЙЄзїЃЌЕЋЪЧдкгааЉЧщПіЯТИќЪЪКЯЪЙгУНќЫЦЫуЗЈЃЌР§ШчЪЙгУHyperLogLogДІРэcount-distinctЮЪЬтЁЃ ЪЕЯж ЁЁЪЕЯжLambdaМмЙЙЕФЗНЗЈгаКмЖрЃЌвђЮЊУПИіВуЕФЕзВуНтОіЗНАИЪЧЖРСЂЕФЁЃУПИіВуашвЊЕзВуЪЕЯжЕФЬиЖЈЙІФмЃЌгажњгкзіГіИќКУЕФбЁдёВЂБмУтЙ§ЖШОіВпЃК ЁЁХњСПВуЃКвЛДЮаДШыЃЌХњСПЖСШЁЖрДЮ ЗўЮёВуЃКжЇГжЫцЛњЖСШЁЕЋВЛжЇГжЫцЛњаДШы; ХњСПМЦЫуКЭХњСПаДШы ЫйЖШВуЃКЫцЛњЖСаД; діСПМЦЫу Р§ШчЃЌЦфжавЛИіЪЕЯж(ЪЙгУKafkaЃЌApache HadoopЃЌVoldemortЃЌTwitter StormЃЌCassandra)ПЩФмШчЯТЫљЪОЃК
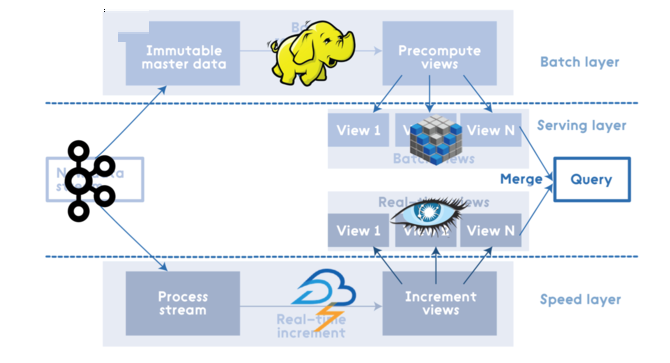
Apache Spark ЁЁApache SparkБЛЪгЮЊдкЫљгаLambdaМмЙЙВуЩЯНјааДІРэЕФМЏГЩНтОіЗНАИЁЃ ЦфжаSpark CoreАќКЌСЫИпМЖAPIКЭжЇГжГЃЙцжДааЭМЕФгХЛЏв§ЧцЃЌSparkSQLгУгкSQLКЭНсЙЙЛЏЪ§ОнДІРэЃЌSpark StreamingжЇГжЪЕЪБЪ§ОнСїЕФПЩРЉеЙЃЌИпЭЬЭТСПЃЌШнДэСїДІРэЁЃ ЕБШЛЃЌЪЙгУSparkНјааХњДІРэЕФМлИёПЩФмБШНЯИпЃЌЖјЧввВВЛЪЧЫљгаЕФГЁОАКЭЪ§ОнЖМЪЪКЯЁЃЕЋЪЧЃЌзмЬхРДЫЕApache SparkЪЧЖдLambdaМмЙЙЕФКЯРэЪЕЯжЁЃ ЁЁЪОР§гІгУ ЁЁЮвУЧДДНЈвЛИіЪОР§гІгУГЬађРДбнЪОLambdaМмЙЙЁЃетИіЪОР§ЕФжївЊФПЕФЭГМЦДгФГИіЪБПЬЕНЯждкДЫПЬЕФ#morningatlohika tweetsЙўЯЃБъЧЉЁЃ ЁЁХњДІРэЪгЭМ ЁЁЮЊСЫМђЕЅЦ№МћЃЌМйЩшЮвУЧЕФжїЪ§ОнМЏАќКЌздЪБМфПЊЪМвдРДЕФЫљгаtweetsЁЃ ДЫЭтЃЌЮвУЧЪЕЯжСЫвЛИіХњДІРэЃЌДДНЈСЫЮвУЧЕФвЕЮёФПБъЫљашЕФХњДІРэЪгЭМЃЌвђДЫЮвУЧгавЛИідЄМЦЫуЕФХњДІРэЪгЭМЃЌЦфжаАќКЌгы#morningatlohikaвЛЦ№ЪЙгУЕФЫљгажїЬтБъМЧЕФЭГМЦаХЯЂЃК

вђЮЊЪ§зжЗНБуМЧвфЃЌЫљвдЮвЪЙгУЖдгІБъЧЉЕФгЂЮФЕЅДЪЕФзжФИЪ§ФПзїЮЊБрКХЁЃ ЁЁЪЕЪБЪгЭМ ЕБгІгУГЬађЦєЖЏВЂдЫааЪБЃЌгаШЫЗЂГіСЫШчЯТЕФtweet:

дкетжжЧщПіЯТЃЌе§ШЗЕФЪЕЪБЪгЭМгІАќКЌвдЯТБъЧЉМАЦфЭГМЦаХЯЂ(дкЮвУЧЕФЪОР§жаЮЊ1ЃЌвђЮЊЯргІЕФhashБъЧЉжЛЪЙгУСЫвЛДЮ)

ВщбЏ ЁЁЕБжеЖЫгУЛЇВщбЏhashБъЧЉЕФЭГМЦНсЙћЪБЃЌЮвУЧжЛашвЊНЋХњСПЪгЭМгыЪЕЪБЪгЭМКЯВЂЦ№РДЁЃ ЫљвдЪфГігІИУШчЯТЫљЪОЃК
ЁЁГЁОА ЁЁЁЁЪОЧèОАЕФМђЛЏВНжшШчЯТЃК ЁЁЁЁЭЈЙ§Apache SparkДДНЈХњДІРэЪгЭМ(.parquet) ЁЁдкApache SparkжаЛКДцХњДІРэЪгЭМ ЁЁСїгІгУГЬађСЌНгЕНTwitter ЁЁЪЕЪБМрПи#morningatlohika tweets ЁЁЙЙНЈдіСПЪЕЪБЪгЭМ ЁЁВщбЏЃЌМДКЯВЂХњДІРэЪгЭМКЭЪЕЪБЪгЭМ
ЁЁЁЁММЪѕЯИНк ЁЁЁЁдДДњТыЛљгкApache Spark 1.6.xЃЌ(дкв§ШыНсЙЙЛЏСїжЎЧА)ЁЃ Spark StreamingМмЙЙЪЧДПЮЂаЭХњДІРэМмЙЙЃК
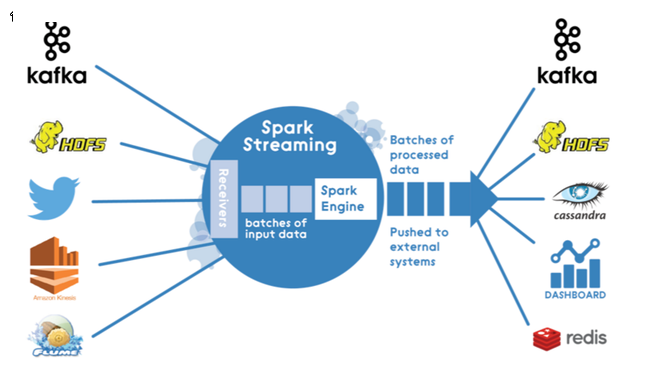
ЁЁЫљвдДІРэСїгІгУГЬађЪБЃЌЮвЪЙгУDStreamСЌНгЪЙгУTwitterUtilsЕФTwitterЃК

дкУПИіЮЂХњДЮ(ЪЙгУПЩХфжУЕФХњДІРэМфИє)ЃЌЖдаТЕФtweetsжаhashtagsЕФЭГМЦаХЯЂЕФМЦЫуЃЌВЂЪЙгУupdateStateByKey()зДЬЌзЊЛЛКЏЪ§ИќаТЪЕЪБЪгЭМЕФзДЬЌЁЃ ЮЊСЫМђЕЅЦ№МћЃЌЪЙгУСйЪББэНЋЪЕЪБЪгЭМДцДЂдкДцДЂЦїжаЁЃ ВщбЏЗўЮёЗДгГХњДІРэКЭЪЕЪБЪгЭМЕФКЯВЂЃК

ЪфГі ЁЁЮФеТПЊЭЗЬсЕНЕФЛљгкHadoopЕФM/RЙмЕРЪЙгУApache SparkРДгХЛЏЃК
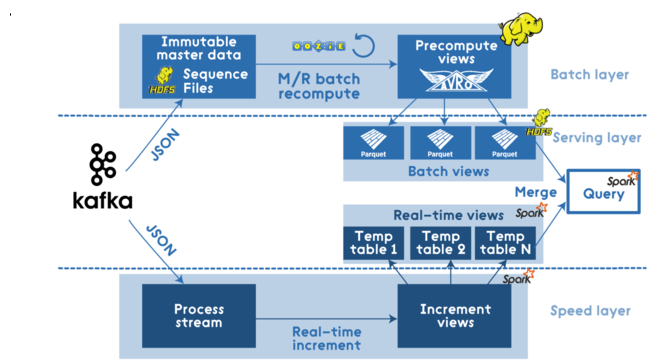
ЁЁКѓМЧЃК ЁЁе§ШчжЎЧАЬсЕНЕФLambda ArchitectureгаЦфгХЕуКЭШБЕуЃЌЫљвджЇГжепКЭЗДЖдепЖМгаЁЃ гааЉШЫЫЕХњДІРэЪгЭМКЭЪЕЪБЪгЭМгаКмЖржиИДЕФТпМЃЌвђЮЊзюжеЫћУЧашвЊДгВщбЏНЧЖШДДНЈПЩКЯВЂЕФЪгЭМЁЃ ЫљвдЫћУЧДДНЈСЫвЛИіKappaМмЙЙЃЌВЂГЦЦфЮЊLambdaМмЙЙЕФМђЛЏАцЁЃ KappaМмЙЙЯЕЭГЪЧЩОГ§СЫХњДІРэЯЕЭГЃЌШЁЖјДњжЎЕФЪЧЭЈЙ§СїЯЕЭГПьЫйЬсЙЉЪ§ОнЃК
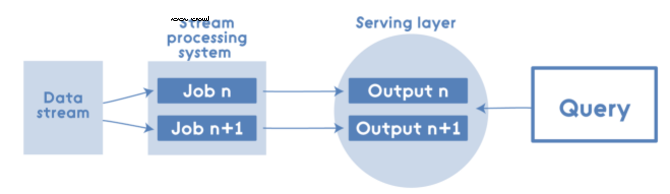
ЁЁЕЋМДЪЙдкетжжЧщПіЯТЃЌKappa ArchitectureжавВПЩвдгІгУApache SparkЃЌР§ШчСїДІРэЯЕЭГЃК
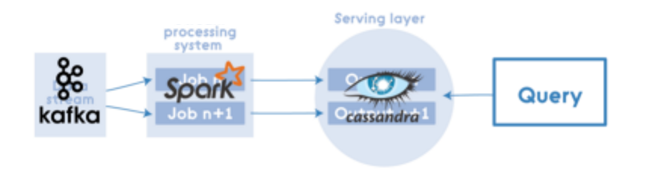
|









