| 1-HBase�İ�װ
HBase��ʲô��
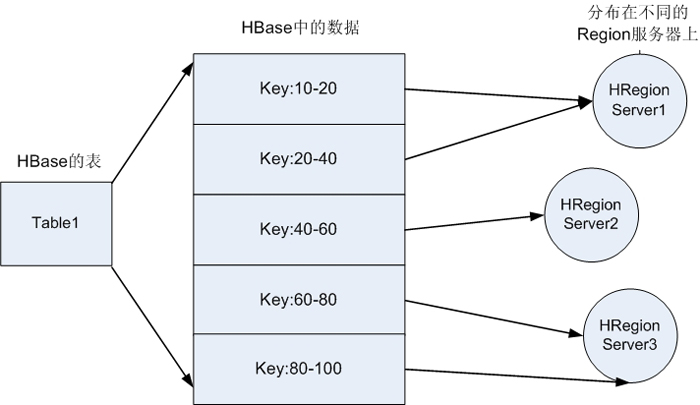
HBase��Apache Hadoop�е�һ������Ŀ��Hbase������Hadoop��HDFS��Ϊ������洢������Ԫ��ͨ��ʹ��hadoop��DFS���߾Ϳ��Կ�����Щ��Щ����
�洢�ļ��еĽṹ,������ͨ��Map/Reduce�Ŀ��(�㷨)��HBase���в��������Ҳ��ͼ��ʾ��
HBase�ڲ�Ʒ�л�������Jetty����HBase����ʱ����Ƕ��ʽ�ķ�ʽ������Jetty����˿���ͨ��web�����HBase���й����Ͳ鿴��ǰ���е�һЩ״̬���dz����ɡ�
Ϊʲô����HBase��
HBase ��ͬ��һ��Ĺ�ϵ���ݿ�,����һ���ʺ��ڷǽṹ�����ݴ洢�����ݿ�.��ν�ǽṹ�����ݴ洢����˵HBase�ǻ����еĶ����ǻ����е�ģʽ�����������д��Ĵ��������ݡ�
HBase�ǽ���Map Entry(key & value)��DB Row֮���һ�����ݴ洢��ʽ���͵��е��������������е�Memcache�����������Ǽ�һ��key��Ӧһ��
value����ܿ�����Ҫ�洢������Ե����ݽṹ����û�д�ͳ���ݿ������ô��Ĺ�����ϵ���������ν����ɢ���ݡ�
����˵������HBase�еı������Ŀ��Կ�����һ�źܴ�ı���������������Կ��Ը�������ȥ��̬���ӣ���HBase��û�б����֮�������ѯ����ֻ��Ҫ
����������ݴ洢��Hbase���Ǹ�column families �Ϳ����ˣ�����Ҫָ�����ľ������ͣ�char,varchar,int,tinyint,text�ȵȡ���������Ҫע��HBase�в������������Ĺ�
�ܡ�
Apache HBase ��Google Bigtable �зdz����Ƶĵط���һ��������ӵ��һ����ѡ��ļ��������������С��������ɵĴ洢�ģ�����û����Ը��ж�����ֲ�ͬ���У����������Ĺ����ڴ���Ŀ�зdz�ʵ�ã����Լ���ƺ������ijɱ���
�������HBase��
�� Apache��HBase�ľ�����վ������һ���ȶ��汾��HBase http://mirrors.devlib.org/apache/hbase/stable/hbase-0.20.6.tar.gz��
������ɺ�����н�ѹ����ȷ����Ļ������Ѿ���ȷ�İ�װ��Java SDK��SSH���������������С�
�����Ŀ¼
export JAVA_HOME=/JDK_PATH
�༭ conf/hbase-env.sh �ļ�,��JAVA_HOME��Ϊ���JDK��װĿ¼
�����������HBase��������,localhost,������ip��ַ
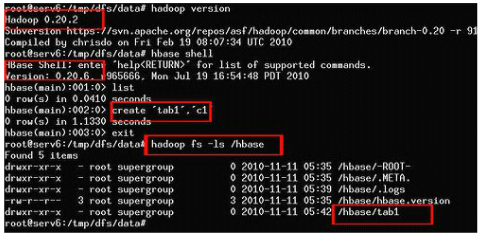
����hbase, �м���Ҫ�������������룬Ҳ���Խ������ò���Ҫ�������룬�����ɹ�����ͼ��ʾ��

����hbase REST�����Ϳ���ͨ����uri: http://localhost:60050/api/
��ͨ��REST����(GET/POST/PUT/DELETE)ʵ�ֶ�hbase��REST��ʽ���ݲ���.
Ҳ������������ָ�����HQLָ��ģʽ
$ bin/hbase shell
$ bin/stop-hbase.sh |
�ر�HBase����
����ʱ���ڵ�����
����linuxϵͳ�����������ò���ȷ��������HBase�������п��ܴ��ڵ����⣬��ͼ��ʾ��
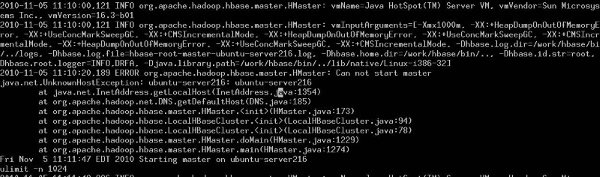
2010-11-05 11:10:20,189 ERROR org.apache.hadoop.hbase.master.HMaster: Can not start master
java.net.UnknownHostException: ubuntu-server216: ubuntu-server216 |
��ʾ�������������ȷ��������Ȳ鿴һ�� /etc/hosts/��������ʲô������ hostname ��������ģ�
hostname you_server_name
�鿴����״̬
�������Ҫ��HBase����־���м������Բ鿴 hbase.x.x./logs/�µ���־�ļ�������ʹ��tail
-f ���鿴��
ͨ�� web��ʽ�鿴������ HBase �µ�zookeeper http://localhost:60010/zk.jsp
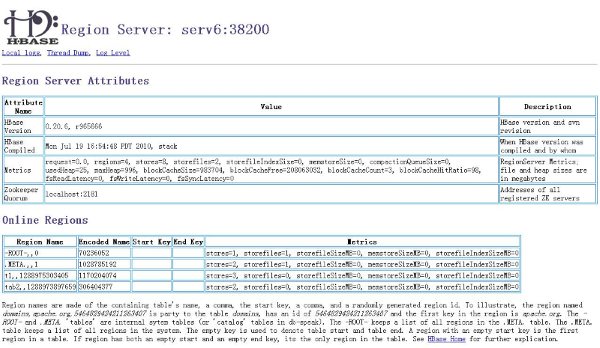
�������Ҫ�鿴��ǰ������״̬����ͨ��web�ķ�ʽ��HBase���������в鿴����ͼ��ʾ��
��չ�Ķ�1��
Apach �� Hadoop����Ŀ�а�������Щ��Ʒ����ͼ��ʾ��

Pig ����MapReduce�Ϲ����IJ�ѯ����(SQL-like),�����ڴ������м��㡣
Chukwa �ǻ���Hadoop��Ⱥ�м��ϵͳ������˵����һ�������Ź��� (WatchDog)
Hive ��DataWareHouse �� Map Reduce������������ETL���������
HBase ��һ�������еķֲ�ʽ���ݿ⡣
Map Reduce ��Google�����һ���㷨�����ڳ��������ݼ��IJ������㡣
HDFS ����֧��ǧ�Ĵ��ͷֲ�ʽ�ļ�ϵͳ��
Zookeeper �ṩ�Ĺ��ܰ���������ά�������ַ��ֲ�ʽͬ���������ȣ����ڷֲ�ʽϵͳ�Ŀɿ�Э��ϵͳ��
Avro ��һ���������л�ϵͳ���������֧�ִ��������ݽ�����Ӧ�á�
��չ�Ķ�2��
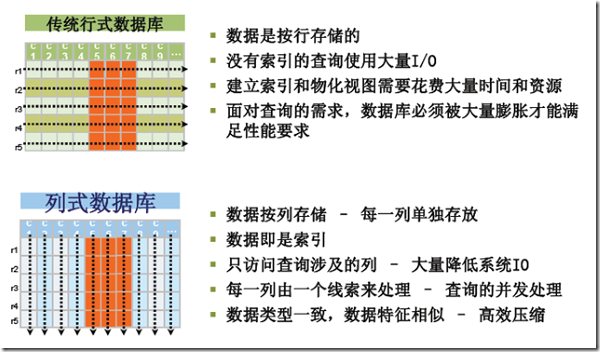
ʲô���д洢���д洢��ͬ�ڴ�ͳ�Ĺ�ϵ�����ݿ⣬�������ڱ����ǰ��д洢�ģ��з�ʽ����������Ҫ�ô�֮һ���ǣ����ڲ�ѯ�е�ѡ�������ͨ����������ģ���
���������ݿ����Զ��������ġ����д洢ÿ���ֶε����ݾۼ��洢���ڲ�ѯֻ��Ҫ���������ֶε�ʱ���ܴ����ٶ�ȡ����������һ���ֶε����ݾۼ��洢���Ǿ�
������Ϊ���־ۼ��洢��Ƹ��õ�ѹ��/��ѹ�㷨������ͼ�����˴�ͳ���д洢���д洢������
��չ�Ķ�3��
��ϵͳ������Log4J��־���Դ����һ������ʽ�Ļ����ϣ��ڴ˻����ϰ�װ splunk ���Է����������־�鿴����װ�������Բο���
http://www.splunk.com/base/Documentation/latest/Installation/InstallonLinux
2-Java����HBase����
��ƪ���½�����HBase Shell���� �� HBase Java API ��HBase ������ ���в������ڴ�֮ǰ��Ҫ��HBase���������и���ŵ��˽⡣����˵HBase�������ڲ�����Щ��Ҫ�������ɣ�HBase���ڲ�����ԭ����ʲô������ѧϰ�κ�һ��֪ʶ��������̬�Ȳ���ֻ��֪�����ʹ�ã��Բ�Ʒ���ڲ�����һ�㶼��ȥ���ģ������������⣬��������ܿ���ҵ��𰸣���������ϣ������ܶԸ������������Լ����ĵã�Ϊ�����ã������������е����˼�봴����Լ��Ľ��������������ȥӦ�Զ��ļ��㳡����ܹ���ơ�����Ŀǰ�Ķ�HBase���˽�������룬�������ϵ�ѧϰ���һ������֪���ĵ�η��������Blog�ϡ�
������һ�¶�ȡһ�м�¼HBase����ν��й����ģ�����HBase Client�˻�����Zookeeper
Qurom(������Ĵ���Ҳ�ܿ����������磺HBASE_CONFIG.set("hbase.zookeeper.quorum",
"192.168.50.216") )��ͨ��Zookeeper���Client�ܻ�֪�ĸ�Server����-ROOT-
Region����ôClient��ȥ���ʹ���-ROOT-��Server����META�м�¼��HBase�����б���Ϣ��(�����ʹ��
scan '.META.' �����г��㴴�������б�����ϸ��Ϣ),�Ӷ���ȡRegion�ֲ�����Ϣ��һ��Client��ȡ����һ�е�λ����Ϣ��������һ�������ĸ�Region��Client���Ỻ�������Ϣ��ֱ�ӷ���HRegionServer���ö���֮Client�������Ϣ�������࣬��ʹ������.META.��Ҳ��֪��ȥ�����ĸ�HRegionServer��HBase�а������ֻ������͵��ļ���һ�����ڴ洢WAL��log����һ�����ڴ洢��������ݣ���Щ���ݶ�ͨ��DFS
Client�ͷֲ�ʽ���ļ�ϵͳHDFS���н���ʵ�ִ洢��
��ͼ��ʾ��
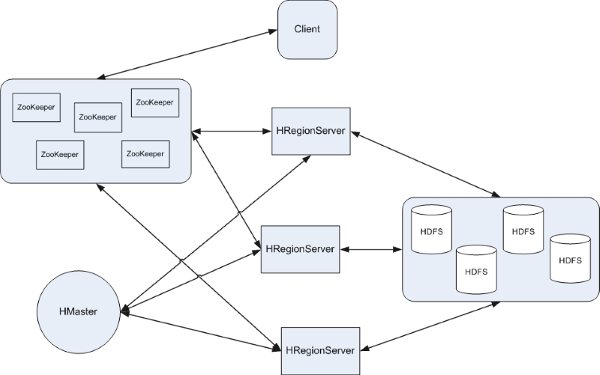
��������HBase��һЩ�ڴ�ʵ��ԭ����
HMaster�� HBase�н���һ��Master server��
HRegionServer��������HRegionʹ֮����client���ṩ������HBase
cluster�л���ڶ��HRegionServer��
ServerManager���������Region server��Ϣ����ÿ��Region
server��HServerInfo(����������HServerAddress��startCode),��load
Region������������Region server�б�
RegionManager������region���䵽region server�ľ��幤����������root��meta
��2��ϵͳ����region״̬��
RootScanner������ɨ��root region���Է���û�з����meta
region��
MetaScanner������ɨ��meta region,�Է���û�з����user
region��
HBase��������
���������ٿ�����HBase��һЩ��������������г��˼������õ�HBase
Shell������£�
�������һ�����ֶ�HBase��һЩ�������dz���Ϥ�Ļ�������Խ��� hbase ��shell ģʽ�����������
help ����鿴�������ִ�е�����ͶԸ������˵���������scan������help�в������ᵽ������������ϸ��˵����scan�����п���ʹ�õIJ��������ã����磬���������Ʋ�ѯ�ķ����ʹ�LIMIT
��STARTROW��ʹ�÷�����
scan Scan a table; pass table name and optionally a dictionary of scanner specifications.
Scanner specifications may include one or more of the following: LIMIT, STARTROW,
STOPROW, TIMESTAMP, or COLUMNS.
If no columns are specified, all columns will be scanned. To scan all members of a column family, leave the
qualifier empty as in 'col_family:'. Examples:
hbase> scan '.META.'
hbase> scan '.META.', {COLUMNS => 'info:regioninfo'}
hbase> scan 't1', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => 'xyz'} |
ʹ��Java API��HBase���������в���
��Ҫ����jar��
hbase-0.20.6.jar
hadoop-core-0.20.1.jar
commons-logging-1.1.1.jar
zookeeper-3.3.0.jar
log4j-1.2.91.jar
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.BatchUpdate;
@SuppressWarnings("deprecation")
public class HBaseTestCase {
static HBaseConfiguration cfg = null;
static {
Configuration HBASE_CONFIG = new Configuration();
HBASE_CONFIG.set("hbase.zookeeper.quorum", "192.168.50.216");
HBASE_CONFIG.set("hbase.zookeeper.property.clientPort", "2181");
cfg = new HBaseConfiguration(HBASE_CONFIG);
}
/**
* ����һ�ű�
*/
public static void creatTable(String tablename) throws Exception {
HBaseAdmin admin = new HBaseAdmin(cfg);
if (admin.tableExists(tablename)) {
System.out.println("table Exists!!!");
}
else{
HTableDescriptor tableDesc = new HTableDescriptor(tablename);
tableDesc.addFamily(new HColumnDescriptor("name:"));
admin.createTable(tableDesc);
System.out.println("create table ok .");
}
}
/**
* ����һ������
*/
public static void addData (String tablename) throws Exception{
HTable table = new HTable(cfg, tablename);
BatchUpdate update = new BatchUpdate("Huangyi");
update.put("name:java", "http://www.javabloger.com".getBytes());
table.commit(update);
System.out.println("add data ok .");
}
/**
* ��ʾ��������
*/
public static void getAllData (String tablename) throws Exception{
HTable table = new HTable(cfg, tablename);
Scan s = new Scan();
ResultScanner ss = table.getScanner(s);
for(Result r:ss){
for(KeyValue kv:r.raw()){
System.out.print(new String(kv.getColumn()));
System.out.println(new String(kv.getValue() ));
}
}
}
public static void main (String [] agrs) {
try {
String tablename="tablename";
HBaseTestCase.creatTable(tablename);
HBaseTestCase.addData(tablename);
HBaseTestCase.getAllData(tablename);
}
catch (Exception e) {
e.printStackTrace();
}
}
} |
3-HBase�Ż�����
��ƪ����dz�ԵĴӼ�������̸̸HBase��һЩ�Ż����ɣ�ֻ����Ϊ��ѧϰ�ʼǵ�һ���֣���Ϊѧ���������������Լ��Ժ���
1 �� linux ϵͳ����
Linuxϵͳ���ɴ��ļ���һ��Ĭ�ϵIJ���ֵ��1024,����㲻�����IJ�����������ʱ�����֡�Too
Many Open Files���Ĵ���������HBase�������У��������ulimit -n ��������ģ�������/etc/security/limits.conf
��/proc/sys/fs/file-max �IJ�������������Ŀ���ȥGoogle �ؼ��� ��linux
limits.conf ��
2 JVM ����
�� hbase-env.sh �ļ��е����ò�����������Ļ���Ӳ���͵�ǰ����ϵͳ��JVM(32/64λ)�����ʵ��IJ���
HBASE_HEAPSIZE 4000 HBaseʹ�õ� JVM �ѵĴ�С
HBASE_OPTS "�\server �\XX:+UseConcMarkSweepGC"JVM
GC ѡ��
HBASE_MANAGES_ZKfalse �Ƿ�ʹ��Zookeeper���зֲ�ʽ����
3 HBase�־û�
��������ϵͳ��HBase������ȫ�ޣ�����Բ����κ��ĵ�����£�����һ�ű���дһ�����ݽ��У�Ȼ�������������������ٽ���HBase��shell��ʹ��
list ����鿴��ǰ�����ڵı���һ����û���ˡ��Dz��Ǻܱ��ߣ�û�й�ϵ�������hbase/conf/hbase-default.xml������hbase.rootdir��ֵ���������ļ��ı���λ��ָ��һ���ļ���
�����磺<value>file:///you/hbase-data/path</value>���㽨����HBase�еı������ݾ�ֱ��д������Ĵ����ϣ���ͼ��ʾ��
ͬ����Ҳ����ָ����ķֲ�ʽ�ļ�ϵͳHDFS��·������: hdfs://NAMENODE_SERVER:PORT/HBASE_ROOTDIR��������д������ķֲ�ʽ�ļ�ϵͳ���ˡ�
4 ����HBase�����
��ξ���Ҫ��hbase/conf/hbase-default.xml �ļ��������ã�����������Ϊ�Ƚ���Ҫ�����ò���
hbase.client.write.buffer
���������������������д�����ݻ������Ĵ�С�����ͻ��˺ͷ������˴������ݣ�������Ϊ�����ϵͳ�������ܿ���һ��д�Ļ���������������
�����������������õĴ��ˣ������ϵͳ���ڴ���һ����Ҫ��ֱ��Ӱ��ϵͳ�����ܡ�
hbase.master.meta.thread.rescanfrequency
�������ʱ�� HMaster��ϵͳ�� root �� meta ɨ��һ�Σ���������������õij�һЩ������ϵͳ���ܺġ�
hbase.regionserver.handler.count
����������HBase/Hadoop��Server�Dz���Multiplexed, non-blocking
I/O��ʽ����Ƶģ�������������һ��Thread����ɴ������������ڴ���Client�������еķ�����Blocking
I/O������������ƻὫClient�����ݹ���������ȷ�����Queue����������Serverʱ���Ȳ���һ��Handler(Thread)����Handler����Polling�ķ�ʽ��ȡ�ø������ִ�ж�Ӧ�ķ�����Ĭ��Ϊ25������ʵ�ʳ����������ô�һЩ��
hbase.regionserver.thread.splitcompactcheckfrequency
��������������DZ�ʾ���ȥRegionServer����������һ��split/compaction��ʱ��������Ȼsplit֮ǰ���Ƚ���һ��compact����.���compact����������minor
compactҲ������major compact.compact��,������е�Store�µ�����StoreFile�ļ������Ǹ�ȡmidkey.���midkey���ܲ�������ȫ�����ݵ�mid��.һ��row-key����������ݿ��ܻ�粻ͬ��HRegion��
hbase.hregion.max.filesize
������HRegion�е�HStoreFile���ֵ���κα��е�����һ�����������С���ᱻ�з֣���HStroeFile��Ĭ�ϴ�С��256M��
hfile.block.cache.size
������ָ�� HFile/StoreFile ������JVM���з���İٷֱȣ�Ĭ��ֵ��0.2����˼����20%������������ó�0���ͱ�ʾ�Ը�ѡ�����Ρ�
hbase.zookeeper.property.maxClientCnxns
������ �������õ�ѡ����Ǵ�zookeeper�����ģ���ʾZooKeeper�ͻ���ͬʱ���ʵIJ�����������ZooKeeper����HBase��˵����һ��������������ֵ�����ʵ��Ŵ�Щ��
hbase.regionserver.global.memstore.upperLimit
��������Region Server������memstoresռ�öѵĴ�С�������ã�Ĭ��ֵ��0.4����ʾ40%���������Ϊ0�����Ƕ�ѡ��������Ρ�
hbase.hregion.memstore.flush.size
������Memstore�л�������ݳ������õķ�Χ��д�������ϣ����磺ɾ����������д��MemStore��������ǣ�ָʾ�Ǹ�value,
column �� family������Ҫɾ���ģ�HBase�ᶨ�ڶԴ洢�ļ���һ��major compaction������ʱHBase���MemStoreˢ��һ���µ�HFile�洢�ļ��С������һ��ʱ�䷶Χ��û����major
compaction����Memstore�г����ķ�Χ��д��������ˡ�
5 HBase��log4j����־
HBase����־����ȼ�Ĭ��״̬���ǰ�debug�� info �������־�ģ����Ը����Լ�����Ҫ����log����HBase��log4j��־�����ļ���
hbase\conf\log4j.properties Ŀ¼�¡�
4�C�洢
��HBase�д�����һ�ű����Էֲ��ڶ��Hregion��Ҳ��˵һ�ű����Ա���ֳɶ�飬ÿһ������Ǻ�Ϊһ��Hregion��ÿ��Hregion�ᱣ
��һ��������ij�����������ݣ��û��������Ǹ�����е�ÿ��Hregion������Hregion�������ṩά��������Hregion����Ҫͨ��
Hregion����������һ��Hregion���Ӧһ��Hregion��������һ�������ı����Ա����ڶ��Hregion
�ϡ�HRegion Server ��Region�Ķ�Ӧ��ϵ��һ�Զ�Ĺ�ϵ��ÿһ��HRegion�������ϻᱻ��Ϊ�������֣�Hmemcache(����)��Hlog(��־)��HStore(�־ò�)��
������Щ��ϵ�����Ժ��е����ӣ���ͼ��ʾ��
1.HRegionServer��HRegion��Hmemcache��Hlog��HStore֮��Ĺ�ϵ����ͼ��ʾ��
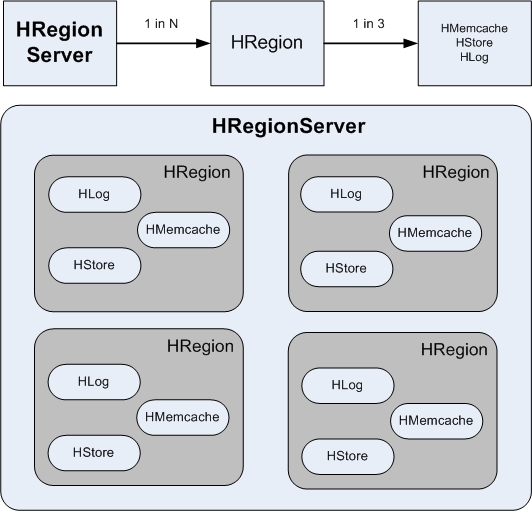
2.HBase���е�������HRegionServer�ķֲ���ϵ����ͼ��ʾ��
HBase������
HBase��ȡ�������ȶ�ȡHMemcache�е����ݣ����δȡ����ȥ��ȡHstore�е����ݣ�������ݶ�ȡ�����ܡ�
HBase���
HBaseд�����ݻ�д��HMemcache��Hlog�У�HMemcache�������棬Hlogͬ��Hmemcache��Hstore��������־������Flush
Cacheʱ�����ݳ־û���Hstore�У������HMemecache��
�ͻ��˷�����Щ���ݵ�ʱ��ͨ��Hmaster ��ÿ�� Hregion �����������Hmaster ����������һ�������ӣ�Hmaster
��HBase�ֲ�ʽϵͳ�еĹ����ߣ�������Ҫ�������Ҫ����ÿ��Hregion ��������Ҫά����ЩHregion���û�����Щ�����ݿ��Ա�����Hadoop
�ֲ�ʽ�ļ�ϵͳ�ϡ� �����������Hmaster��������ô����ϵͳ������Ч�������һῼ����ν��Hmaster��SPFO�����⣬��������е�����Hadoop��SPFO
����һ��ֻ��һ��NameNodeά��ȫ�ֵ�DataNode��HDFSһ������ȫ�����ˣ�Ҳ����˵����Heartbeat�����������⣬���������ҳ�
�����Ľ�����������ʱ�䣬���а취�ġ�
������hadoop-0.21.0��hbase-0.20.6�Ļ����������˺ܾã�һֱ������������Ϣ���£�
Exception in thread "main" java.io.IOException: Call to localhost/serv6:9000 failed on local exception:
java.io.EOFException
10/11/10 15:34:34 ERROR master.HMaster: Can not start master
java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:39)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:27)
at java.lang.reflect.Constructor.newInstance(Constructor.java:513)
at org.apache.hadoop.hbase.master.HMaster.doMain(HMaster.java:1233)
at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:1274) |
�������Ӳ���HDFS��Ҳ������HMaster�����ư���
�����밡�������룬����ǰһ�� java.io.EOFException ����쳣���Dz����п�����RPC
Э����ʽ��һ�µ��µģ�Ҳ����˵�������˺Ϳͻ��˵İ汾��һ�µ����⣿����һ��HDFS�ķ��������Ժ�һ�ж����ˣ���Ȼ�ǰ汾�����⣬������
hadoop-0.20.2 ����hbase-0.20.6 �Ƚ��ȵ���
����Ч����ͼ��ʾ��
��ͼ��һЩ����˵����
1.hadoop�汾��0.20.2 ,
2.hbase�汾��0.20.6,
3.��hbase�д�����һ�ű� tab1���˳�hbase shell����,
4.��hadoop����鿴���ļ�ϵͳ�е��ļ���Ȼ����һ���ոմ�����tab1Ŀ¼,��������ͼƬ˵��HBase�ڷֲ�ʽ�ļ�ϵͳApache
HDFS�������ˡ�
5(��Ⱥ) -ѹ��������ʧЧת��
����һƪ����HBase������������������HBase�ڷֲ�ʽ�еļܹ�����ƪ���½��ὲ��HBase�ڷֲ�ʽ������������ų�������ϵ�(SPFO)����һ��Сʵ�齲��HBase�ڷֲ�ʽ�����еĸ߿����ԣ����ۿ���һЩ��������һЩ˼���Ļ��⡣
�����ع�һ��HBase��Ҫ������
HBaseMaster
HRegionServer
HBase Client
HBase Thrift Server
HBase REST Server
HBaseMaster
HMaster �����HRegionServer��������,���Ҹ���Լ�Ⱥ�����е�HReginServer���и��ؾ��⣬HMaster�������ؼ�Ⱥ�����е�HReginServer������״�������ijһ̨HReginServer
down����HBaseMaster����Ѳ����õ�HReginServer���ṩ�����HLog�ͱ��������·���ת��������HReginServer���ṩ��HBaseMaster����������ݺͱ����й������������ṹ�ͱ������ݵı������Ϊ��
META ϵͳ���д洢�����е���ر���Ϣ������HMasterʵ����ZooKeeper��Watcher�ӿڿ��Ժ�zookeeper��Ⱥ������
HRegionServer
HReginServer�������û��Ķ���д�IJ�����HReginServerͨ����HBaseMasterͨ�Ż�ȡ�Լ���Ҫ��������ݱ�������HMaster�����Լ�������״������һ��д����������ʱ�������Ȼ�д��һ������HLog��write-ahead
log�С�HLog���������ڴ��У���ΪMemcache��ÿһ��HStoreֻ����һ��Memcache����Memcache�������õĴ�С�Ժ��ᴴ��һ��MapFile������д��������ȥ���⽫����HReginServer���ڴ�ѹ������һ���ȡ����������ʱ��HReginServer������Memcache��Ѱ�Ҹ����ݣ����Ҳ�����ʱ�Ż�ȥ��MapFiles
��Ѱ�ҡ�
HBase Client
HBase Client����Ѱ���ṩ�������ݵ�HReginServer������������У�HBase Client��������HMasterͨ�ţ��ҵ�ROOT�������������Client��Master֮����е�ͨ�Ų�����һ��ROOT�����ҵ��Ժ�Client�Ϳ���ͨ��ɨ��ROOT�����ҵ���Ӧ��META����ȥ��λʵ���ṩ���ݵ�HReginServer������λ���ṩ���ݵ�HReginServer�Ժ�Client�Ϳ���ͨ�����HReginServer�ҵ���Ҫ�������ˡ���Щ��Ϣ���ᱻClient�������������´������ʱ�Ͳ���Ҫ���������������ˡ�
HBase����ӿ�
HBase Thrift Server��HBase REST Server��ͨ����Java�����HBase���з��ʵ�һ��;����
��������
������һ��HBase��Ⱥ��ģ������˻�����һ����4̨�������ֱ���� zookeeper��HBaseMaster��HReginServer��HDSF
4������Ϊ��չʾʧЧת����Ч��HBaseMaster��HReginServer����2̨��ֻ����һ̨�����ϼ�������HBaseMaster��Ҳ������HReginServer��
ע�⣬HBase�ļ�Ⱥ������HBaseMasterֻ��ʧЧת��û��ѹ�����صĹ��ܣ���HReginServer���ṩʧЧת��Ҳ�ṩѹ�����ء�
�������嵥���£�
zookeeper 192.168.20.214
HBaseMaster 192.168.20.213/192.168.20.215
HReginServer 192.168.20.213/192.168.20.215
HDSF 192.168.20.212
����ģ����ļܹ���ͼ��ʾ��
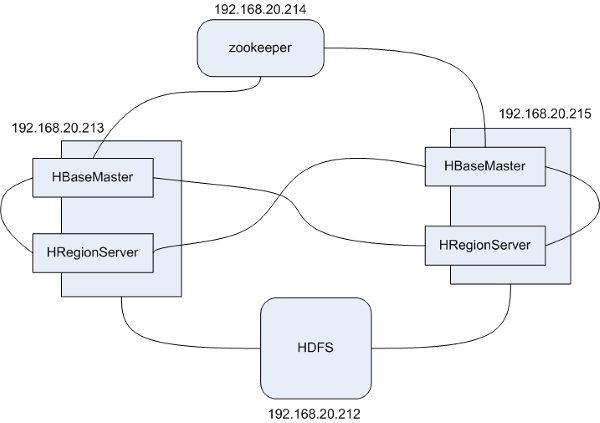
ע�⣬����ֻ������һ��ģ�������Ϊ����������ص���HBase������zookeeper��HDFS�����ǵ�̨��
��Ȼ˵������HBase�ļ�Ⱥ������ֻ����һ��HMaster�������ڼ�Ⱥ������HMaster�������������������ʹ�õ���HMaster
Serverֻ��һ��������down����ʱ������������HMaster Server�����Ṥ����ֱ����ZooKeeper�������ж��뵱ǰ���е�HMasterͨѶ��ʱ����Ϊ����������е�HMaster������down���ˣ�Zookeeper�Ż�ȥ������һ̨HMaster
Server��
����˵,���������HMaster������down���ˣ���ôzookeeper����б���ѡ����һ��HMaster
���������з��ʣ������ӹ�down����HMaster��������֮����Java�ͻ��˶�HBase���в�����ͨ��ZooKeeper�ģ�Ҳ����˵���zookeeper��Ⱥ�еĽڵ�ȫ����
��ôHBase�ļ�ȺҲ���ˡ�����HBase�����洢�е��κ����� �����������DZ�����HDFS�ϣ�����HBase��������һ�µģ�����HDFS�ļ�ϵͳ���ˣ�HBase�ļ�ȺҲ�ҡ�
��һ̨HMasterʧ�ܺͻ��˶�HBase��Ⱥ��������ʱ���ͻ����Ȼ�ͨ��zookeeperʶ��HMaster�����쳣��ֱ��ȷ�϶�κ����ӵ���һ��HMaster����ʱ�����ݵ�HMaster�������Ч����IDE�����е�Ч������ͼ��ʾ��
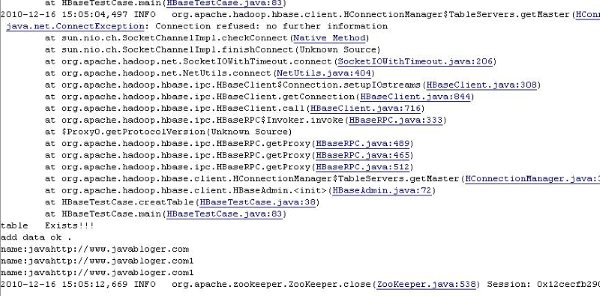
��ͼ���ܿ����׳���һЩ�쳣��name:javahttp://www.javabloger.com��name:javahttp://www.javabloger.com1�Ľ��������Ϊ����serv215��������killall
java����� HMaster��HReginServer���ص�������������Java�ͻ��˶�HBase�ļ�Ⱥ�������з������쳣�׳�������retry��һ���������ѯ�������ǰ���Ѿ�˵�˷���HBase��ͨ��zookeeper�ٺ����������ݴ���Ҳ����˵zookeeper�ӹ���һ��standby
�� HMaster����ԭ��Standby��HMaster������ʧЧ��HMaster�������ӹܵ�HBaseMaster�ٶ�HReginServer��������з��䣬��
HReginServerʧ�ܺ�zookeeper��֪ͨ HMaster��HReginServer��������з��䡣������ֵ�˵����HBase������ʵЧת���Ĺ��ܡ�
��ͼ��ʾ��

��ˮ��
1��HBase��ʧЧת����Ч�ʱȽ����ˣ���ָ������1-2���л��ͻָ���ϣ�Ҳ��������ʱû�з�����ʲô�����������ʧЧת���ͻָ����̵��ٶȣ������������ע������⡣
2���ڹٷ���վ�Ͽ���HBase0.89.20100924�İ汾��ƪ������������ͬ�������£��ҳ�����һ����һ̨�����Ͽ���������ν��HBase���⼯Ⱥ�����������л�����̨�����ķֲ�ʽ�����У�����ʧЧת�����ٶȺ�����HBase0.20.6��Ҫ�������ּ�����Ƿ������������⣬Ŀǰ��δ�ҵ���ȷ�Ĵ𰸣�����HBase0.89.20100924
�°��е�����ͬ����ԭ������ͼ��ʾ��(������Ϣ)

6 -��MySQL(RDBMS)��HBase֮��
�ҵķϻ�1:
�κ�һ���¼������Ǿ������ݣ�һĨһ������ҩ�������İٱ��䣬����ʹ��Spring����NOSQL�IJ�Ʒ���������+���ʮɫ��������������dz�����ͬ��
�Ͳ�Ʒ�в������ּ�������Ҫ�ﵽ��Ŀ����һ���ģ�ͨ���µļ����ֶ����������ܱܻ��˵�ǰ������Ҫ��Ե����⣬�������µ����������ˡ�Ҳ���ع�ͷ����������
����ԭ���Ļ����϶ද���Խ� ����취 ��Щ�������Եõ����ߵĻر���
��ͳ���ݿ��������ݿ����洢���ݣ�����˵����ı��ֶ�Խ�࣬ռ�õ����ݿռ��Խ�࣬��ô��ѯ�п��ܾ�Ҫ�����ݿ飬���ᵼ�²�ѯ���ٶȱ������ڴ���ϵͳ��һ�ű��ϰٸ��ֶΣ����ұ��е�����������������ȫ���п��ܵġ���˻�������ݿ��ѯ��ƿ�������Ƕ�֪��һ����ʶ���ݿ��б���¼�Ķ��ٶԲ�ѯ�������зdz����Ӱ�죬��ʱ����п����뵽�ֱ����ֿ���������������ݿ������ѹ������ô�ֻ�����µ����⣬���磺�ֲ�ʽ����ȫ��ΨһID�����ɡ������ݿ��ѯ
�ȣ����ɻ�������Լ��ֵ����⡣����������ְ����д洢��ģʽ������һ�ֻ����д洢��ģʽ�����ڴ��ģ���ݳ�����������п��ܷ���һЩ��ת�����ڲ�ѯ�е�ѡ�������ͨ����������ģ�����������ݿ����Զ��������ġ����д洢ÿ���ֶε����ݾۼ��洢��
���Զ�̬���ӣ�������Ϊ�վͲ��洢���ݣ���ʡ�洢�ռ䡣 ÿ���ֶε����ݰ��վۼ��洢���ܴ����ٶ�ȡ������������ѯʱָ�Ĵ��ģ����ĸ�ֱ�ӡ����迼�Ƿֿ⡢�ֱ�
Hbase���Դ洢�������Զ��з����ݣ���֧�ָ߲�����д������ʹ�ú������ݴ洢�Զ����и�ǿ����չ�ԡ�
Java�е�HashMap��Key/Value�Ľṹ����Ҳ����HBase�����ݽṹ������һ��Key/Value����ϵ,��˵HBase�������ɱ������н綨�ġ���HBase����ÿһ��"����"����һ����ΪHStore�Ķ��������ÿ��HStore��һ������MapFiles(Hadoop�е�һ���ļ�����)��ɡ�MapFiles�ĸ���������Google��SSTable��
��Hbase����������������Ҫ�ĸ��Row key �� Column Family�������Cell qualifier��Timestamp
tuple��Column family����ͨ����֮Ϊ�����塱�����ʿ��ơ����̺��ڴ��ʹ��ͳ�ƶ��������������еġ�����Column
family��֮ǰԤ�ȶ���õ�����ģ�ͣ�ÿһ��Column Family�����Ը��ݡ��������ж��column����HBaseÿ��cell�洢��Ԫ��ͬһ�������ж���汾������Ψһ��ʱ���������ÿ���汾֮��IJ��죬���µ����ݰ汾������ǰ��
��
��ˮ��Hbase��tableˮƽ���ֳ�N��Region��region��column family���ֳ�Store��ÿ��store�����ڴ��е�memstore�ͳ־û���disk�ϵ�HFile��
���������ұ���Ļ�������λ����������һ��ʵ���еij�������ԭ���Ǵ����MySQL��Blog�е�����Ǩ�Ƶ�HBase�еĹ��̣�
MySQL�����еı��ṹ��
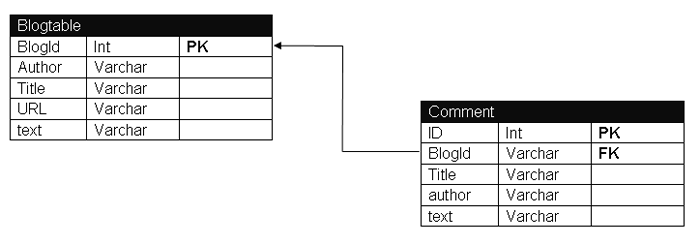
Ǩ��HBase�еı��ṹ��
ԭ��ϵͳ����2�ű�blogtable��comment��������HBase��ֻ��һ��blogtable����������մ�ͳ��RDBMS�Ļ���blogtable���е����ǹ̶��ģ�����schema
������Author,Title,URL,text�����ԣ����ߺ���ֶ��Dz��ܶ�̬���ӵġ�������������д洢ϵͳ������Hbase����ô���ǿ��Զ���blogtable����Ȼ����info
���壬User�����ݿ��Է�Ϊ��info:title ,info:author ,info:url �ȣ��������������������������ԣ������ܷ���ֻ��Ҫ
info:xxx �Ϳ����ˡ�
����Row key���������row keyΪ��ͳRDBMS�е�ijһ���е�������Hbase�Dz�֧��������ѯ�Լ�Order
by�Ȳ�ѯ�����Row key����ƾ�Ҫ������ϵͳ�IJ�ѯ����������˶ Hbase�еļ�¼�ǰ���rowkey������ģ�������ʹ�ò�ѯ��÷dz��졣
��������������£�
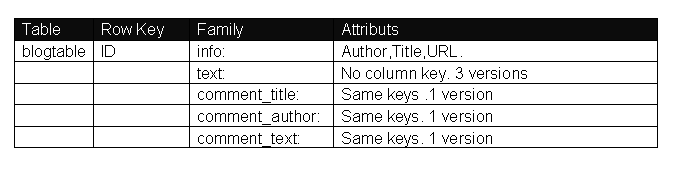
============================����blogtable��=========================
create 'blogtable', 'info','text','comment_title','comment_author','comment_text'
============================�����Ҫ��Ϣ=========================
put 'blogtable', '1', 'info:title', 'this is doc title'
put 'blogtable', '1', 'info:author', 'javabloger'
put 'blogtable', '1', 'info:url', 'http://www.javabloger.com/index.php'
put 'blogtable', '2', 'info:title', 'this is doc title2'
put 'blogtable', '2', 'info:author', 'H.E.'
put 'blogtable', '2', 'info:url', 'http://www.javabloger.com/index.html'
============================����������Ϣ=========================
put 'blogtable', '1', 'text:', 'what is this doc context ?'
put 'blogtable', '2', 'text:', 'what is this doc context2?'
==========================����������Ϣ===============================
put 'blogtable', '1', 'comment_title:', 'this is doc comment_title '
put 'blogtable', '1', 'comment_author:', 'javabloger'
put 'blogtable', '1', 'comment_text:', 'this is nice doc'
put 'blogtable', '2', 'comment_title:', 'this is blog comment_title '
put 'blogtable', '2', 'comment_author:', 'H.E.'
put 'blogtable', '2', 'comment_text:', 'this is nice blog' |
HBase�����ݲ�ѯ\��ȡ������ͨ������row key���ʣ�row key��range��ȫ��ɨ��,�������£�
ע�⣺HBase����֧��where������Order by ��ѯ��ֻ֧�ְ���Row key����ѯ�����ǿ���ͨ��HBase�ṩ��API�����������ˡ�
���磺http://hbase.apache.org/apidocs/org/apache/hadoop/hbase/filter/ColumnPrefixFilter.html
scan 'blogtable' ,{COLUMNS => ['text:','info:title']
} ��> �г� ���µ����ݺͱ���
scan 'blogtable' , {COLUMNS => 'info:url' , STARTROW
=> '2'} ��> ���ݷ�Χ�г� ���µ����ݺͱ���
get 'blogtable','1' ��> �г� ����id ����1������
get 'blogtable','1', {COLUMN => 'info'} ��> �г�
����id ����1 �� info ��ͷ(Head)����
get 'blogtable','1', {COLUMN => 'text'} ��> �г�
����id ����1 �� text �ľ���(Body)����
get 'blogtable','1', {COLUMN => ['text','info:author']}
��> �г� ����id ����1 �����ݺ�����(Body/Author)����
�ҵķϻ�2:
���˻���Java Web����������Tomcat�컹��GlassFish�죿С�����ݿ�����MySQLЧ�ʸ���MS-SQLЧ�ʸߣ��ҿ��ǹؼ�����ʲô��������ôʹ����
����Ʒ(����)�������ҽ�������Ϊ����Ҫ�Բ�Ʒ����������������˽⣬������һ���µļ������Ǿ��ѵ�ѡ�����ʣ�Tomcat��Ĭ�ϵ����в����ܺ�������
������ʹ�õ�GlassFish�������Ტ�����Ҳ�����GlassFishv2��GlassFishv3��Ĭ�ϵ����ò������������IJ��������Ҫ�Բ�
Ʒ��������������˽���ܷ�������ߵ����ܣ������Ǹй����ӳ��ҵĹ����Լ��ĸ�����ʶ �����ĸ���Ʒ����Խ�ԡ�
�ҵķϻ�3:
����NOSQL�������¼������ĵ�ȷȷ�ǿ��Խ����ȥ��������Ҫ��Ե����⣬��Ҳ�����ʺ�ÿ��Ӧ�ó�����������ʹ���²�Ʒ��ͬʱ��Ҫ�кϵ�ǰ�IJ�Ʒ��Ҫ��
�������������¼�����Ͷ�룬������Ϊ�˸�ʱ��ȥʹ��������IJ�Ʒ�Ƿ��Ӳ������ʹ����ʲô�¼������û����ĵ����ٶȺ��ȶ��ԣ�����������Ƿ�ʹ����
NOSQL���෴Google���ų�������������ܸ�ȫ�����û������˾��˵��ٶȺ�ȷ�ԣ���ҲŻ�ع�ͷ������Google��������ô�����ġ����Ը���
�Լ�����Ҫǧ���̫��ǿ�Լ�ʹ����ij���¼�����
�ҵķϻ�4:
��֮һ�仰����ʲô������ؼ�����ؼ�����ôȥʹ�ã�
7 -��ȫ&Ȩ��
�ҵķϻ���
������ʮҹ��������ʵ����̫�����ˣ������������������ĵ��Ӿ�汾�����������������������ϣ��Ⱥ��Ͼƣ�д�㶫�����Ŀ�
��2�����Ƽ���Ļ��ĿǰΪֹ��������û��ƽ������һֱ�Ǵ��������۵����Ż��⣬�������������Ƽ����ṩ�ɿ����ȶ������ٵļ��㣬���Ƽ�����Google��Ŀǰ�����Ƽ��㹩Ӧ�̣����磺Google
GAE(Google App Engine)��Google��Docs�������·�����ЩSaaS���߲�Ʒ�����ݴ洢(datastore)����BigTable�ṩ�洢����ģ��ڴ�֮ǰ���ᵽ��Yahoo����Apache����Щɽկ�汾(Google��Yahoo����Щ����)������Apache��HBase����ɽկ��Google��BigTable��
����֪�����Ƽ���ļ���������Apache��Hadoop��Ŀ��һ���ʯ������Hadoop��Ŀ�еIJ�Ʒ���Խ����Ƽ���ƽ̨�ͳ����͵ļ��㡣��֪�����Ƿ�����������HBase��ΪGoogle
GAE�ϵ����ݴ洢(datastore)����ôÿ���û�֮������ݷ���Ȩ����ô�죿���ʹ��HBase�ṩ�Դ�ͻ��ṩ��˽���ơ�(private
cloud)������һ�ֿ���һ����˾�ڲ��ļ�Ⱥ������HBase����˾���ڲ������м������ţ�ij��������֮������ݶ��Ƕ������뵫��������һ��ƽ̨�ϣ���ô��ͻᷢ��HBase���߱������Ĺ��ܣ�ò��ĿǰHBase����߰汾0.90.0��û�������Ĺ��ܶ��û��ı���Row��Cell�ķ���Ȩ�ޡ���������֪��Google��GAE��ÿ���û����ʵ����ݿ϶�����Ȩ���ֵģ���Ȼ��ֻҪ��Ȩ��¼GEA���ܿ��������û���ŵ������ˡ��������������п���û������������ƹ�˾�Ĺ���ʦ��ȴΪ���뵽����㣬���Ұ����ǵ����������ύ��HBase��Ŀ�飬���������������Ҫ�����˼�룺
Client access to HBase is authenticated
User data is private unless access has
been granted
Access to data can be granted at a table
or per column family basis.
��HBase�еı������ݻ���Ȩ�ȼ���������֤����Ȩ�ޱ���Ϊ3���࣬ÿ���а����IJ���Ȩ��������ʾ��
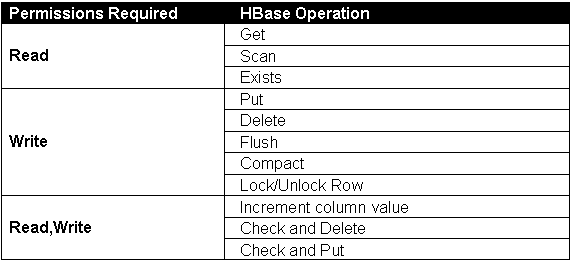
���ڷ������漰���洢��Ȩ����ָ����������е����壬Ҳ����˵ֻ�����ڱ���������Ȩ�ޣ������֮���������ϵ�Ǵ����
.META. ϵͳ���У���regioninfo:owner �ĸ�ʽ���д�ţ�����:ϵͳ��table1���������Ȩ�ģ������Ȩ�Ĵ��������3���ط�
��
The row in .META. for the first region
of table1
The node /hbase/acl/table1 of Zookeeper
The in-memory Permissions Mirror of
every regionserver that serves table1
��ͼ��ʾ��ͼ�еļ�ͷ��ʾ�����������˳��
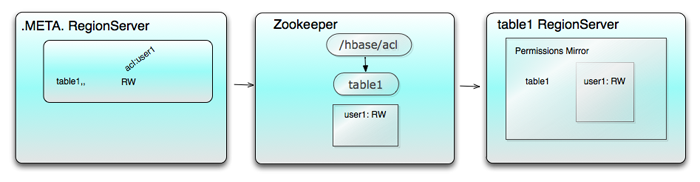
������HBase�ڷֲ�ʽ����Ⱥ�����£���Ȩ��һ���Ե����⽻����Zookeeper���������ڶ��regionservers�У�ÿ����������HRegion�д���Ŷ����������ʵ����(implement)ZKPermissionWatcher�ӿڵ�nodeCreated()
�� nodeChanged() ��������2��������Zookeeper �Ľڵ���м�أ� �ڵ��״̬������Ӧ�ı仯ʱ��ZooKeeperˢ�¾����е�Ȩ�ޡ�
��ͼ��ʾ��
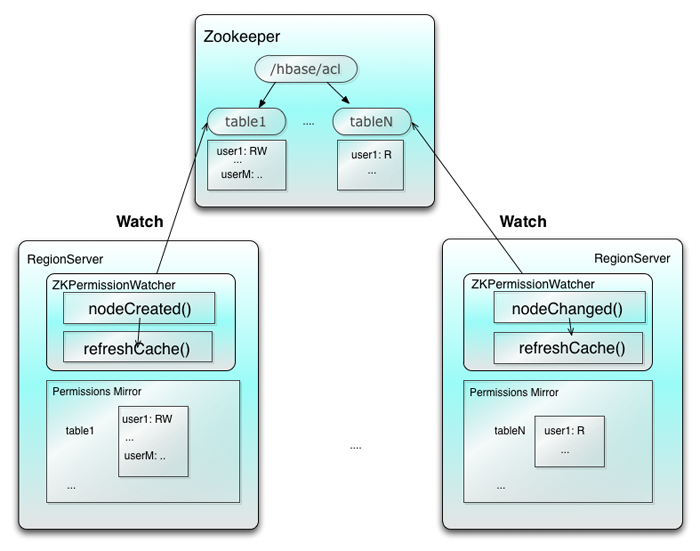
HBase����һ����Ȩ�Ĺ���������ƺ����ֵ��У������Ǽ����������ֹ�ע��������ᷢ���ı仯�ܸ����Ǵ���ʲô����Ч�����dz��ڴ��������������ʽ������
|






