|
HBase���
HBase �C Hadoop Database����һ���߿ɿ��ԡ������ܡ������С��������ķֲ�ʽ�洢ϵͳ������HBase������������PC
Server�ϴ����ģ�ṹ���洢��Ⱥ��
HBase��Google Bigtable�Ŀ�Դʵ�֣�����Google
Bigtable����GFS��Ϊ���ļ��洢ϵͳ��HBase����Hadoop HDFS��Ϊ���ļ��洢ϵͳ��Google����MapReduce������Bigtable�еĺ������ݣ�HBaseͬ������Hadoop
MapReduce������HBase�еĺ������ݣ�Google Bigtable���� Chubby��ΪЭͬ����HBase����Zookeeper��Ϊ��Ӧ��
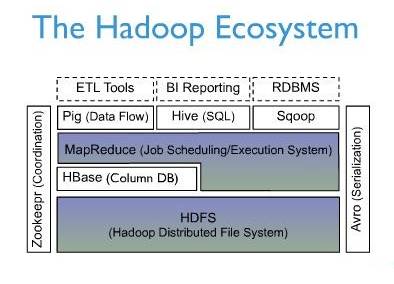
��ͼ������Hadoop EcoSystem�еĸ���ϵͳ������HBaseλ�ڽṹ���洢�㣬Hadoop
HDFSΪHBase�ṩ�˸߿ɿ��Եĵײ�洢֧�֣�Hadoop MapReduceΪHBase�ṩ�˸����ܵļ���������ZookeeperΪHBase�ṩ���ȶ������failover���ơ�
���⣬Pig��Hive��ΪHBase�ṩ�˸߲�����֧�֣�ʹ����HBase�Ͻ�������ͳ�ƴ�����ķdz���
Sqoop��ΪHBase�ṩ�˷����RDBMS���ݵ��빦�ܣ�ʹ�ô�ͳ���ݿ�������HBase��Ǩ�Ʊ�ķdz����㡣
HBase���ʽӿ�
1. Native Java API������Ч�ķ��ʷ�ʽ���ʺ�Hadoop MapReduce Job����������HBase������
2. HBase Shell��HBase�������й��ߣ���Ľӿڣ��ʺ�HBase����ʹ��
3. Thrift Gateway������Thrift���л�������֧��C++��PHP��Python�ȶ������ԣ��ʺ������칹ϵͳ���߷���HBase������
4. REST Gateway��֧��REST ����Http API����HBase, �������������
5. Pig������ʹ��Pig Latin��ʽ�������������HBase�е����ݣ���Hive���ƣ���������Ҳ�DZ����MapReduce
Job������HBase�����ݣ��ʺ�������ͳ��
6. Hive����ǰHive��Release�汾��û�м����HBase��֧�֣�������һ���汾Hive
0.7.0�н���֧��HBase������ʹ������SQL����������HBase
HBase����ģ��
Table & Column Family
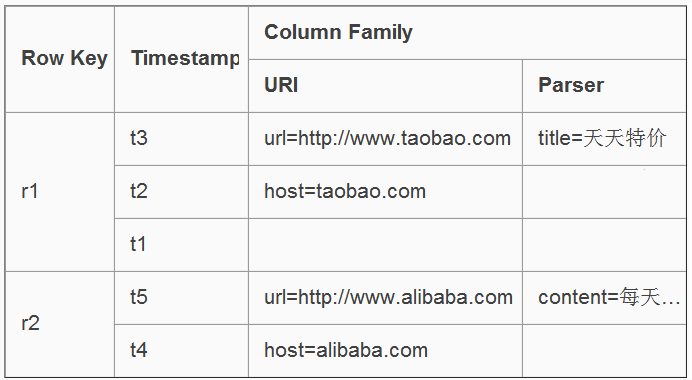
Row Key: �м���Table��������Table�еļ�¼����Row Key����
1.Timestamp: ʱ�����ÿ�����ݲ�����Ӧ��ʱ��������Կ��������ݵ�version
number
2.Column Family���дأ�Table��ˮƽ������һ�����߶��Column
Family��ɣ�һ��Column Family�п�����������Column��ɣ���Column Family֧�ֶ�̬��չ������Ԥ�ȶ���Column�������Լ����ͣ�����Column���Զ����Ƹ�ʽ�洢���û���Ҫ���н�������ת����
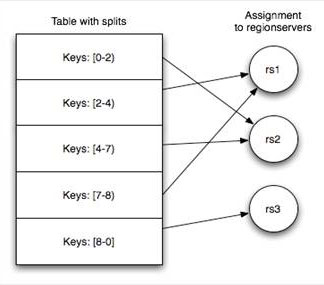
Table & Region
��Table���ż�¼���������Ӷ��������ѳɶ��splits����Ϊregions��һ��region��[startkey,endkey)��ʾ����ͬ��region�ᱻMaster�������Ӧ��RegionServer���й�����
-ROOT- && .META. Table
HBase�������������Table��-ROOT-��.META.
1..META.����¼���û�����Region��Ϣ��.META.�����ж��regoin
2.-ROOT-����¼��.META.����Region��Ϣ��-ROOT-ֻ��һ��region
3.Zookeeper�м�¼��-ROOT-����location
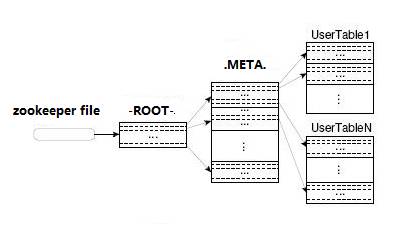
Client�����û�����֮ǰ��Ҫ���ȷ���zookeeper��Ȼ�����-ROOT-�������ŷ���.META.�����������ҵ��û����ݵ�λ��ȥ���ʣ��м���Ҫ����������������client�˻���cache���档
MapReduce on HBase
��HBaseϵͳ���������������㣬����ʵ�õ�ģ����Ȼ��MapReduce������ͼ��
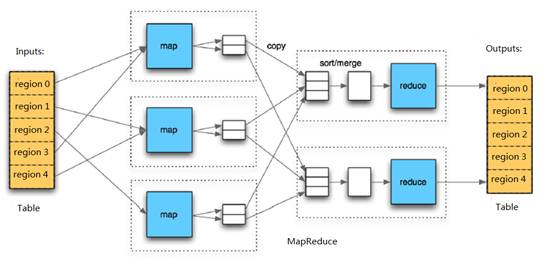
HBase Table��Region�Ĺ�ϵ���Ƚ�����HDFS File��Block�Ĺ�ϵ��HBase�ṩ������TableInputFormat��TableOutputFormat
API�����Է���Ľ�HBase Table��ΪHadoop MapReduce��Source��Sink������MapReduce
JobӦ�ÿ�����Ա��˵����������Ҫ��עHBaseϵͳ������ϸ�ڡ�
HBaseϵͳ�ܹ�
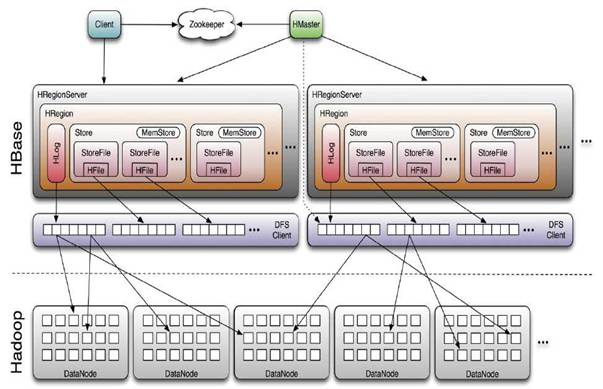
Client
HBase Clientʹ��HBase��RPC������HMaster��HRegionServer����ͨ�ţ����ڹ����������Client��HMaster����RPC���������ݶ�д�������Client��HRegionServer����RPC
Zookeeper
Zookeeper Quorum�г��˴洢��-ROOT-���ĵ�ַ��HMaster�ĵ�ַ��HRegionServerҲ����Լ���Ephemeral��ʽע�ᵽ
Zookeeper�У�ʹ��HMaster������ʱ��֪������HRegionServer�Ľ���״̬�����⣬ZookeeperҲ������HMaster��
�������⣬����������
HMaster
HMasterû�е������⣬HBase�п����������HMaster��ͨ��Zookeeper��Master
Election���Ʊ�֤����һ��Master���У�HMaster�ڹ�������Ҫ����Table��Region�Ĺ���������
1. �����û���Table������ɾ���ġ������
2. ����HRegionServer�ĸ��ؾ��⣬����Region�ֲ�
3. ��Region Split������Region�ķ���
4. ��HRegionServerͣ������ʧЧHRegionServer �ϵ�RegionsǨ��
HRegionServer
HRegionServer��Ҫ������Ӧ�û�I/O������HDFS�ļ�ϵͳ�ж�д���ݣ���HBase������ĵ�ģ�顣
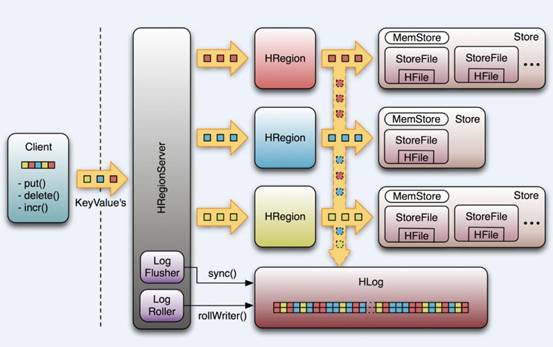
HRegionServer�ڲ�������һϵ��HRegion����ÿ��HRegion��Ӧ��Table�е�һ��
Region��HRegion���ɶ��HStore��ɡ�ÿ��HStore��Ӧ��Table�е�һ��Column
Family�Ĵ洢�����Կ���ÿ��Column Family��ʵ����һ�����еĴ洢��Ԫ�������ý��߱���ͬIO���Ե�column����һ��Column
Family�����������
HStore�洢��HBase�洢�ĺ����ˣ���������������ɣ�һ������MemStore��һ������StoreFiles��
MemStore��Sorted Memory Buffer���û�д����������Ȼ����MemStore����MemStore�����Ժ��Flush��һ��StoreFile���ײ�ʵ����HFile����
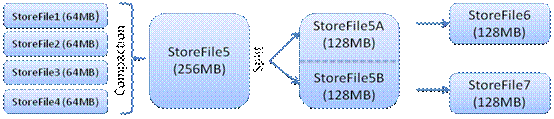
��StoreFile�ļ�����������һ����ֵ���ᴥ��Compact�ϲ������������StoreFiles�ϲ���һ��StoreFile���ϲ������л��
�а汾�ϲ�������ɾ������˿��Կ���HBase��ʵֻ���������ݣ����еĸ��º�ɾ�����������ں�����compact�����н��еģ���ʹ���û���д����ֻҪ
�����ڴ��оͿ����������أ���֤��HBase I/O�ĸ����ܡ���StoreFiles Compact�����γ�Խ��Խ���StoreFile��������StoreFile��С����һ����ֵ�ᴥ��Split������ͬʱ�ѵ�ǰ
Region Split��2��Region����Region�����ߣ���Split����2������Region�ᱻHMaster���䵽��Ӧ��HRegionServer
�ϣ�ʹ��ԭ��1��Region��ѹ�����Է�����2��Region�ϡ���ͼ������Compaction��Split�Ĺ��̣�
������������HStore�Ļ���ԭ���������˽�һ��HLog�Ĺ��ܣ���Ϊ������HStore��ϵͳ����������ǰ������û����
��ģ������ڷֲ�ʽϵͳ�����У�������ϵͳ��������崻������һ��HRegionServer�����˳���MemStore�е��ڴ����ݽ��ᶪʧ�������
Ҫ����HLog�ˡ�ÿ��HRegionServer�ж���һ��HLog����HLog��һ��ʵ��Write Ahead
Log���࣬��ÿ���û�����д��MemStore��ͬʱ��Ҳ��дһ�����ݵ�HLog�ļ��У�HLog�ļ���ʽ����������HLog�ļ����ڻ�������µģ���
ɾ���ɵ��ļ����ѳ־û���StoreFile�е����ݣ�����HRegionServer������ֹ��HMaster��ͨ��Zookeeper��֪
����HMaster���Ȼᴦ�������� HLog�ļ��������в�ͬRegion��Log���ݽ��в�֣��ֱ�ŵ���Ӧregion��Ŀ¼�£�Ȼ���ٽ�ʧЧ��region���·��䣬��ȡ
����Щregion��HRegionServer��Load Region�Ĺ����У��ᷢ������ʷHLog��Ҫ��������˻�Replay
HLog�е����ݵ�MemStore�У�Ȼ��flush��StoreFiles��������ݻָ���
HBase�洢��ʽ
HBase�е����������ļ����洢��Hadoop HDFS�ļ�ϵͳ�ϣ���Ҫ������������������ļ����ͣ�
1. HFile�� HBase��KeyValue���ݵĴ洢��ʽ��HFile��Hadoop�Ķ����Ƹ�ʽ�ļ���ʵ����StoreFile���Ƕ�HFile������������װ����StoreFile�ײ����HFile
2. HLog File��HBase��WAL��Write Ahead Log�� �Ĵ洢��ʽ����������Hadoop��Sequence
File
HFile
��ͼ��HFile�Ĵ洢��ʽ��
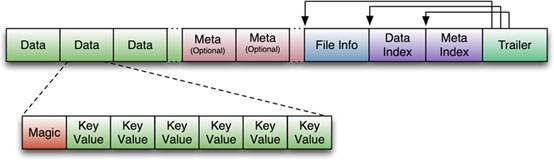
����HFile�ļ��Dz������ģ����ȹ̶���ֻ�����е����飺Trailer��FileInfo������ͼ����ʾ�ģ�Trailer
����ָ��ָ���������ݿ����ʼ�㡣File Info�м�¼���ļ���һЩMeta��Ϣ�����磺AVG_KEY_LEN,
AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY�ȡ�Data
Index��Meta Index���¼��ÿ��Data���Meta�����ʼ�㡣
Data Block��HBase I/O�Ļ�����Ԫ��Ϊ�����Ч�ʣ�HRegionServer���л���LRU��Block
Cache���ơ�ÿ��Data��Ĵ�С�����ڴ���һ��Table��ʱ��ͨ������ָ������ŵ�Block������˳��Scan��С��Block���������ѯ��
ÿ��Data����˿�ͷ��Magic�������һ����KeyValue��ƴ�Ӷ���, Magic���ݾ���һЩ������֣�Ŀ���Ƿ�ֹ�������������ϸ����ÿ��KeyValue�Ե��ڲ����졣
HFile�����ÿ��KeyValue�Ծ���һ����byte���顣�������byte������������˺ܶ�������й̶��Ľṹ����������������ľ���ṹ��

��ʼ�������̶����ȵ���ֵ���ֱ��ʾKey�ij��Ⱥ�Value�ij��ȡ���������Key����ʼ�ǹ̶����ȵ���ֵ����ʾRowKey
�ij��ȣ���������RowKey��Ȼ���ǹ̶����ȵ���ֵ����ʾFamily�ij��ȣ�Ȼ����Family��������Qualifier��Ȼ���������̶����ȵ���
ֵ����ʾTime Stamp��Key Type��Put/Delete����Value����û����ô���ӵĽṹ�����Ǵ���Ķ����������ˡ�
HLogFile
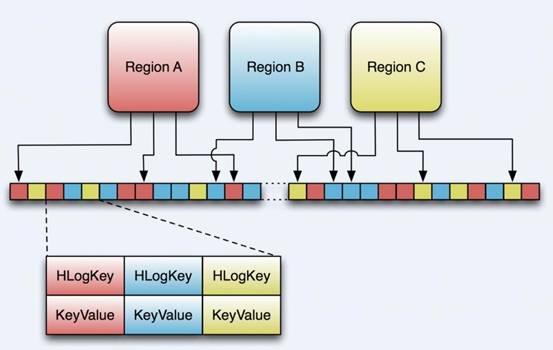
��ͼ��ʾ����HLog�ļ��Ľṹ����ʵHLog�ļ�����һ����ͨ��Hadoop
Sequence File��Sequence File ��Key��HLogKey����HLogKey�м�¼��д�����ݵĹ�����Ϣ������table��region�����⣬ͬʱ������
sequence number��timestamp��timestamp�ǡ�д��ʱ�䡱��sequence
number����ʼֵΪ0�����������һ�δ����ļ�ϵͳ��sequence number��
HLog Sequece File��Value��HBase��KeyValue������ӦHFile�е�KeyValue���ɲμ�����������
����
���Ķ�HBase�����ڹ��ܺ�����Ͻ����˴��µĽ��ܣ�����ƪ�����ޣ�����û�й������������HBase��һЩϸ�ڼ�����Ŀǰһ�ԵĴ洢ϵͳ���ǻ���HBase������ģ����������ܡ�һ�Էֲ�ʽ�洢ϵͳ����ͨ��ʵ�ʰ���������Ľ���HBaseӦ�á� |






