| 编辑推荐: |
本文介绍了CEP引擎引擎的架构并分享了一些股票业务较为有趣的应用场景。希望对您的学习有所帮助。
本文来自CSDN,由火龙果软件Alice编辑、推荐。 |
|
CEP(Complex Event Processing)是证券行业很多业务应用的重要支撑技术。CEP的概念本身并不新鲜,相关技术已经被运用超过15年以上,但是证券界肯定是运用CEP技术最为充分、最为前沿的行业之一,从算法交易(algorithmic
trading)、风险管理(risk management)、关键时刻管理(Moment of Truth
- MOT)、委托与流动性分析(order and liquidity analysis)到量化交易(quantitative
trading)乃至向投资者推送投资信号(signal generation)等等,不一而足。
CEP技术通常与Time-series Database(时序数据库)结合,最理想的解决方案是CEP技术平台向应用提供一个历史序列(historical
time-series)与实时序列(real-time series)无差异融合的数据流连续体(continuum)-
对于证券类应用而言,昨天、上周、上个月的数据不过是当下此刻数据的延续,而处理算法却是无边际的 – 只要开发者能构想出场景与模型。
广发证券的IT研发团队,一直关注Storm、Spark、Flink等流式计算的开源技术,也经历了传统Lambda架构的技术演进,在Kappa架构的技术尚未成熟之际,团队针对证券行业的技术现状与特点,采用改良的Lambda架构实现了一个CEP引擎,本文介绍了此引擎的架构并分享了一些股票业务较为有趣的应用场景,以飨同好。
随着移动互联和物联网的到来,大数据迎来了高速和蓬勃发展时期。一方面,移动互联和物联网产生的大量数据为孕育大数据技术提供了肥沃的土壤;一方面,各个公司为了应对大数据量的挑战,也急切的需要大数据技术解决生产实践中的问题。短时间内各种技术层出不穷,在这个过程中Hadoop脱颖而出,并营造了一个丰富的生态圈。虽然大数据一提起Hadoop,好像有点老生常谈,甚至觉得这个技术已经过时了,但是不能否认的是Hadoop的出现确实有非凡的意义。不管是它分布式处理数据的理念,还是高可用、容错的处理都值得好好借鉴和学习。
刚开始,大家可能都被各种分布式技术、思想所吸引,一头栽进去,掉进了技术的漩涡,不能自拔。一方面大数据处理技术和系统确实复杂、繁琐;另一方面大数据生态不断的推陈出新,新技术和新理念层出不穷,确实让人目不暇接。如果想要把生态圈中各个组件玩精通确实不是件容易的事情。本人一开始也是深陷其中,皓首穷经不能自拔。但腾出时间,整理心绪,回头反顾,突然有种释然之感。大数据并没有大家想象的那么神秘莫测与复杂,从技术角度看无非是解决大数据量的采集、计算、展示的问题。
因此本文参考Lambda/Kappa架构理念,提出了一种有行业针对性的实现方法。尽量让系统层面更简单,技术更同构,初衷在让大家聚焦在大数据业务应用上来,从而真正让大数据发挥它应有的价值。
1、 背景
Lambda架构是由Storm的作者Nathan Marz 在BackType和Twitter多年进行分布式大数据系统的经验总结提炼而成,用数学表达式可以表示如下:
batch view = function(all data)
realtime view = function(realtime view,new data)
query = function(batch view .realtime view)
逻辑架构图如下:
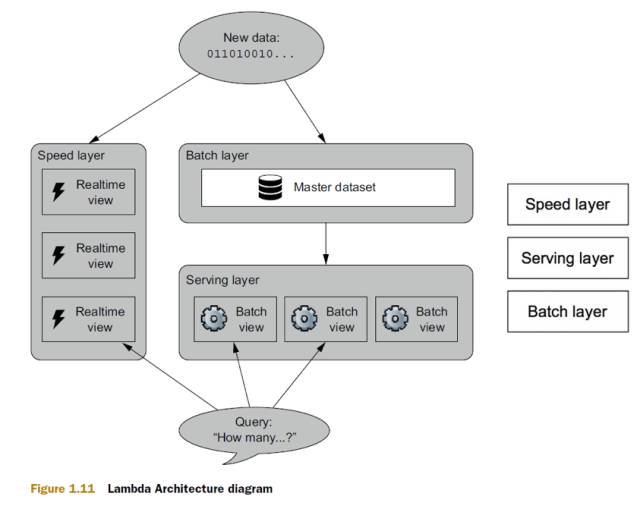
从图上可以看出,Lambda架构主要分为三层:批处理层,加速层和服务层。它整合了离线计算和实时计算,融合了不可变性(immutable),读写分离和复杂性隔离等一系列架构原则设计而成,是一个满足大数据系统关键特性的架构。Nathan
Marz认为大数据系统应该具有以下八个特性,Lambda都具备它们分别是:
Robustness and fault tolerance(鲁棒性和容错性)
Low latency reads and updates(读和更新低延时)
Scalability(可伸缩)
Generalization(通用性)
Extensibility(可扩展)
Ad hoc queries(可即席查询)
Minimal maintenance(易运维)
Debuggability(可调试)
由于Lambda架构的数据是不可变的(immutable),因此带来的好处也是显而易见的:
Human-fault tolerance(对人为的容错性):数据流水被按时序记录下来,而且数据只写一次,不做更改,而不像RDBMS只是保留最后的状态。因此不会丢失数据信息。即使平台升级或者计算程序中不小心出现Bug,修复Bug后重新计算就好。强调了数据的重新计算问题,这个特性对一个生产的数据平台来说是十分重要的。
Simplicity(简易性):可变的数据模型一般要求数据能必须被索引,以便于数据可被再次被检索到和可以被更新。但是不变的数据模型相对来说就很简单了,只是一味的追加新数据即可。大大简化了系统的复杂度。
但是Lambda也有自身的局限性,举个例子:在大数据量的情况下,要即席查询过去24小时某个网站的pv数。根据前面的数学表达式,Lambda架构需要实现三部分程序,一部分程序是批处理程序,比如可能用Hive或者MapReduce批量计算最近23.5个小时pv数,一部分程序是Storm或Spark
Streaming流式计算程序,计算0.5个小时内的pv数,然后还需要一个服务程序将这两部分结果进行合并,返回最终结果。因此Lambda架构包含固有的开发和运维的复杂性。
因为以上的缺陷,Linkedin的Jay Kreps在2014年7月2日在O’reilly《Questioning
the Lambda Architecture》提出了Kappa架构,如下图:
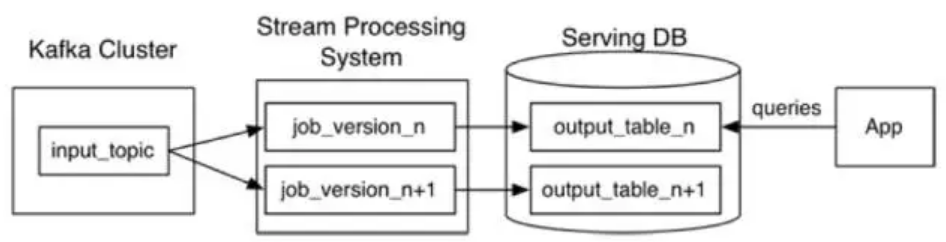
Kappa在Lambda做的最大的改进是用同一套实时计算框架代替了Lambda的批处理层,这样做的好处是一套代码或者一套技术栈可以解决一个问题。它的做法是这样的:
用Kafka做持久层,根据需求需要,用Kafka保留需要重新计算的历史数据长度,比如计算的时候可能用30天的数据,那就配置Kafka的值,让它保留最近30天的数据。
当你程序因为升级或者修复了缺陷,需要重新计算的时候,就再启一个流式计算程序,从你所需的Offset开始计算,并将结果输入到一个新的表里。
当这个流式计算程序追平第一个程序的时候,将应用切换到第二个程序的输出上。
停止第一个程序,删除第一个程序的输出结果表。
这样相当于用同一套计算框架和代码解决了Lambda架构中开发和运维比较复杂的问题。当然如果数据量很大的情况下,可以增加流式计算程序的并发度来解决速度的问题。
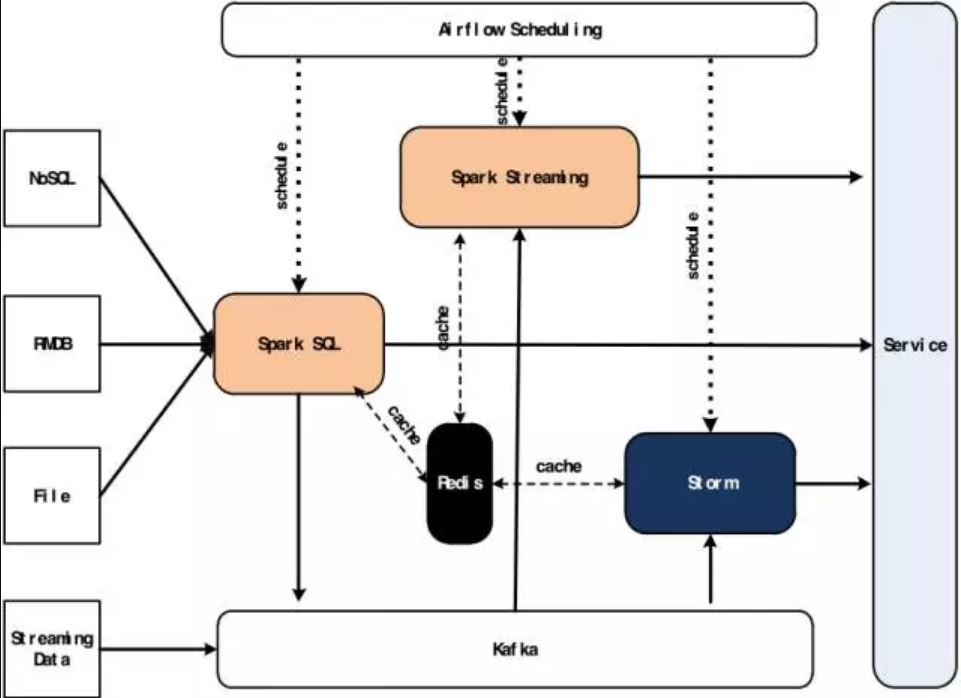
2、 广发证券Lambda架构的实现
由于金融行业在业务上受限于T+1交易,在技术上严重依赖关系型数据库(特别是Oracle)。在很多场景下,数据并不是以流的形式存在的,而且数据的更新频率也并不是很实时。比如为了做技术面分析的行情数据,大多数只是使用收盘价和历史收盘价(快照数据)作为输入,来计算各类指标,产生买卖点信号。
因此这是一个典型的批处理的场景。另一方面,比如量化交易场景,很多实时的信号又是稍纵即逝,只有够实时才存在套利的空间,而且回测和实盘模拟又是典型的流处理。鉴于以上金融行业特有的场景,我们实现了我们自己的架构(GF-Lambda),它介于Lambda和Kappa之间。一方面能够满足我们处理数据的需求;一方面又可以达到技术上的同构,减少开发运维成本。根据对数据实时性要求,将整个计算部分分为三类:
Spark SQL:代替MapReduce或者Hive的功能,实现数据的批量预处理;
Spark Streaming:近实时高吞吐的mini batching数据处理功能;
Storm:完成实时的流式数据处理;
GF-Lambda的优势如下:
在PipeLine的驱动方面,采用Airbnb开源的Airflow,Airflow使用脚本语言来实现整个PipeLine的定义,而且任务实例也是动态生成的;相比Oozie和Azkaban采用标记语言来完成PipeLine的定义,Airflow的优势是显而易见的,例如:
整个data flow采用脚本编写,便于配置管理和升级。而Oozie只能使用XML定义,升级迁移成本较大。
触发方式灵活,整个PipeLine可以动态生成,切实的做到了“analytics as a service”或者
“analysis automation”。
另外一个与Lambda或者Kappa最大的不同之处是我们采用了Redis作为缓存来存储各个计算服务的状态;虽然Spark和Storm都有Checkpoint机制,但是CheckPoint会影响到程序复杂度和性能,并且以上两种技术的CheckPoint机制并不是很完善。通过Redis和Kafka的Offset机制,不仅可以做到无状态的计算服务,而且即使升级或者系统故障,数据的可用性也不会受到影响。
整个batch layer采用Spark SQL,使用Spark SQL的好处是能做到密集计算的后移。由于历史原因,券商Oracle等关系型数据库使用比较多,而且在开市期间数据库压力也比较大,此处的Spark
SQL只是不断的从Oracle批量加载数据(除了Filter基本在Oracle上做任何计算)或者主动的通过Oracle日志旁录数据,对数据库压力较小,同时又能达到数据准实时性的要求;另外所有的计算都后置到Yarn集群上进行,不仅利于程序的运维,也利于资源的有效管控和伸缩。架构实现如下图所示:
3、 应用场景
CEP在证券市场的应用的有非常多,为了读者更好的理解上述技术架构的设计,在此介绍几个典型应用场景。
1)自选股到价和涨跌幅提醒
自选股到价和涨跌幅提醒是股票交易软件的一个基础服务器,目的在于方便用户简单、及时的盯盘。其中我们使用MongoDB来存储用户的个性化设置信息,以便各类应用可以灵活的定制自身的Schema。在功能上主要包括以下几种:
股价高于设定值提醒。
股价低于设定值提醒。
涨幅高于设定值提醒。
一分钟、五分钟涨幅高于设定值提醒。
跌幅高于设定值提醒。
一分钟、五分钟跌幅高于设定值提醒。
主要的挑战在于大数据量的实时计算,而采用GF-Lambda可以轻松解决这个问题。数据处理流程如下:
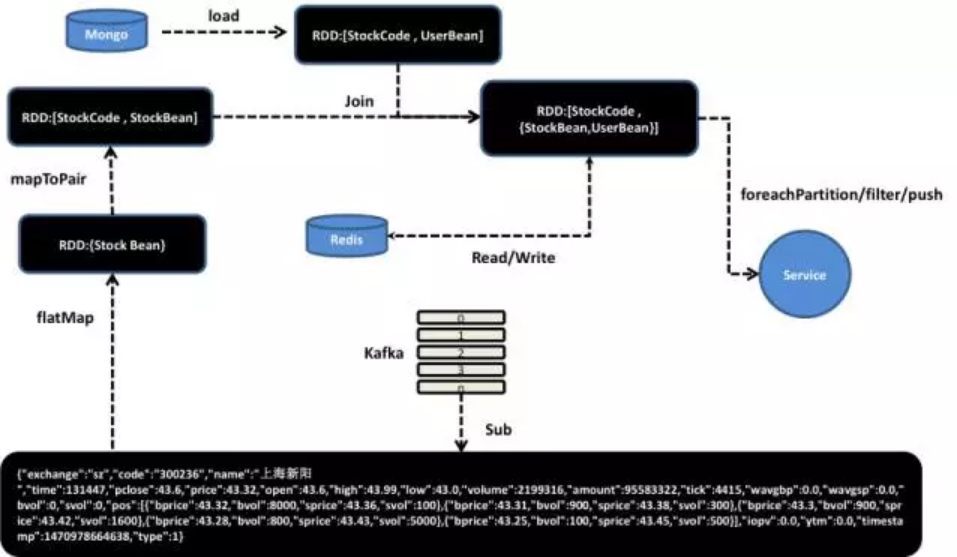
首先从Kafka订阅实时行情数据并进行解析,转化成RDD对象,然后再衍生出Key(market+stockCode),同时从Mongo增量加载用户自选股预警设置数据,然后将这两份数据进行一个Join,再分片对同一个Key的两个对象做一个Filter,产生出预警信息,并进行各个终端渠道推送。
2)自选股实时资讯
实时资讯对各类交易用户来说是非常重要的,特别是和自身严重相关的自选股实时资讯。一个公告、重大事项或者关键新闻的出现可能会影响到用户的投资回报,因此这类事件越实时,对用户来说价值就越大。
在GF-Lambda平台上,自选股实时资讯主要分为两部分:实时资讯的采集及预处理(适配)、资讯信息与用户信息的撮合。整个处理流程如下图所示:
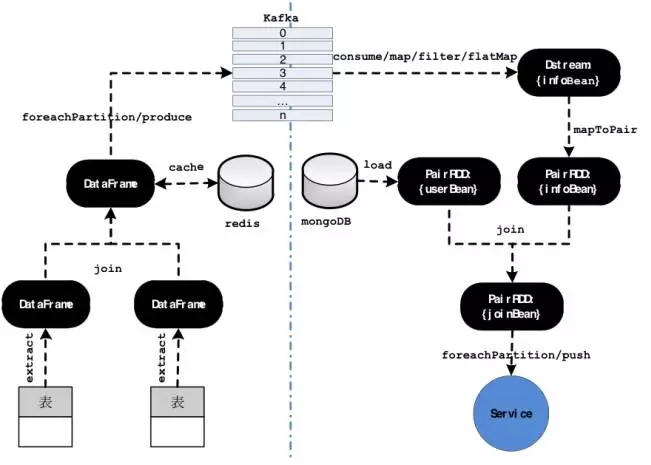
在上图分割线左侧是实时资讯的预处理部分,首先使用Spark JDBC接口从Oracle数据库加载数据到Spark,形成DataFrame,再使用Spark
SQL的高级API做数据的预处理(此处主要做表之间的关联和过滤),最后将每个Partition上的数据转化成协议要求的格式,写入Kafka中等待下游消费。
左侧数据ETL的过程是完全由Airflow来进行驱动调度的,而且每次处理完就将状态cache到Redis中,以便下次增量处理。在上图的右侧则是与用户强相关的业务逻辑,将用户配置的信息与实时资讯信息进行撮合匹配,根据用户设置的偏好来产生推送事件。
此处用Kafka来做数据间的解耦,好处是不言而喻的。首先是保证了消息之间的灵活性,因为左侧部分产生的事件是一个基础公共事件,而右侧才是一个与业务紧密耦合的逻辑事件。基础公共事件只有事件的基础属性,是可以被很多业务同时订阅使用的。
其次从技术角度讲左侧是一个类似批处理的过程,而右侧是一个流处理的过程,中间通过Kafka做一个转换与对接。这个应用其实是很具有代表性的,因为在大部分情况下,数据源并不是以流的形式存在,更新的频率也并不是那么实时,所以大多数情况下都会涉及到batch
layer与speed layer之间的转换对接。
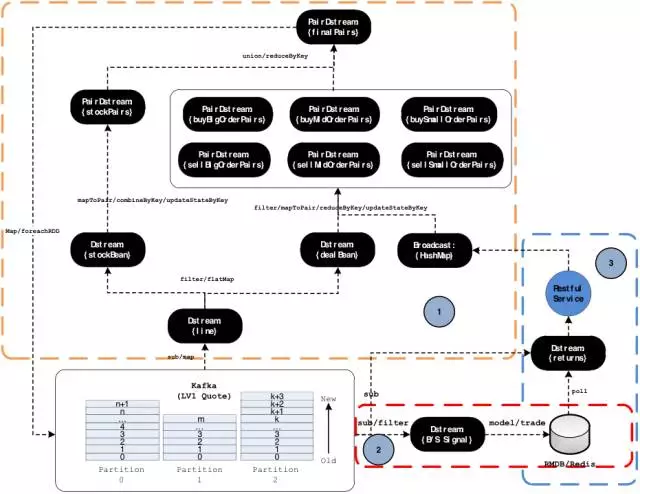
3)资金流选股策略
上面两个应用相对来说处理流程比较简单,以下这个case是一个业务
稍微繁琐的CEP应用-资金流策略交易模型,该模型使用资金流流向来判断股票在未来一段时间的涨跌情况。它基于这样一个假设,如果是资金流入的股票,则股价在未来一段时间上涨是大概率事件;如果是资金流出的股票,则股价在未来一段时间下跌是大概率事件。那么我们可以基于这个假设来构建我们的策略交易模型。如下图所示,这个模型主要分为三部分:

1)个股资金流指标的实时计算
由于涉及到一些业务术语,这里先做一个简单的介绍。
资金流是一种反映股票供求关系的指标,它的定义如下:证券价格在约定的时间段中处于上升状态时产生的成交额是推动指数上涨的力量,这部分成交额被定义为资金流入;证券价格在约定的时间段中下跌时的成交额是推动指数下跌的力量,这部分成交额被定义为资金流出;若证券价格在约定的时间段前后没有发生变化,则这段时间中的成交额不计入资金流量。当天资金流入和流出的差额可以认为是该证券当天买卖两种力量相抵之后,推动价格变化的净作用量,被定义为当天资金净流量。数量化定义如下:
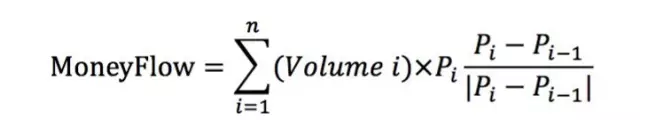
其中,Volume为成交量,为i时刻收盘价,为上一时刻收盘价。
严格意义上讲,每一个买单必须有一个相应的卖单,因此真实的资金流入无法准确的计算,只能通过其他替代方法来区分资金的流入和流出,通过高频数据,将每笔交易按照驱动股价上涨和下跌的差异,确定为资金的流入或流出,最终汇聚成一天的资金流净额数据。根据业界开发的CMSMF指标,采用高频实时数据进行资金流测算,主要出于以下两方面考虑:一是采用高频数据进行测算,可以尽可能反映真实的市场信息;二是采取报价(最近买价、卖价)作为比较基准,成交价大于等于上期最优卖价视为流入,成交价小于等于上期最优买价视为流出。
除了资金的流入、流出、净额,还有一系列衍生指标,比如根据流通股本数多少衍生出的大、中、小单流入、流出、净额,及资金流信息含量(IC)、资金流强度(MFP),资金流杠杆倍数(MFP),在这里就不一一介绍。
从技术角度讲,第一部分我们通过订阅实时行情信息,开始计算当天从开市到各个时刻点的资金流入、流出的累计值,及衍生指标,并将这些指标计算完成后重新写回到Kafka进行存储,方便下游消费。因此第一部分完全是一个大数据量的实时流处理应用,属于Lambda的speed
layer。
2)买卖信号量的产生及交易
第二部分在业务上属于模型层,即根据当前实时资金流指标信息,构建自己的策略模型,输出买卖信号。比如以一个简单的策略模型为例,如果同时满足以下三个条件产生买的信号。反之,产生卖的信号:
(大单资金流入-大单资金流出>0) && (中单资金流入-中单资金流出>0)
大单的资金流信息含量>50%
大单的资金流强度>20%
在技术上,这个应用也属于Lambda的 speed layer,通过订阅Kafka中的资金流指标,根据上面简单的模型,不断的判断是否要买或者卖,并调用接口发起买卖委托指令,最后根据回报结果操作持仓表或者成交表。(注意此处在业务上只是以简单的模型举例,没有涉及到更多的细节)
3)持仓盈亏实时追踪及交易
第三部分在业务上主要是准实时的盈亏计算。在技术层面,属于Lambda 的batch layer。通过订阅实时行情和加载持仓表/成交表,实时计算用户的盈亏情况。当然此处还有一些简单的止损策略,也可以根据盈利情况,发起卖委托指令,并操作持仓表和成交表。最后将盈利情况报给服务层,进行展示或者提供回调接口。详细的处理流程如下图所示:
总结
正如文章前面强调的一样,写这篇文章的初衷是希望大家从大数据丰富的生态中解放出来,与业务深度的跨界融合,从而开发出更多具有价值的大数据应用,真正发挥大数据应有的价值。这和Lambda架构的作者Nathan
Marz的理念也是十分吻合的,记得他还在BackType工作的时候,他们的团队才五个人,却开发了一个社会化媒体分析产品——在100TB的数据上提供各种丰富的实时分析,同时这个小的团队还负责上百台机器的集群的部署、运维和监控。
当他向别人展示产品的时候,很多人都很震惊他们只有五个人。经常有人问他:“How can so few
people do so much?”。他的回答是:“It’s not what we’re doing,
but what we’re not doing.”通过使用Lambda架构,他们避免了传统大数据架构的复杂性,从而产出变得非常显著。
在五花八门的大数据技术层出不穷的当下,Marz的理念更加重要。我们一方面需要与时俱进关注最新的技术进步
– 因为新技术的出现可能反过来让以前没有考虑过或者不敢想的应用场景变成可能,但另一方面更重要的是,大数据技术的合理运用需要建立在对行业领域知识深刻理解的基础上。大数据是金融科技的核心支撑技术之一,我们将持续关注最前沿的大数据技术与架构理念,持续优化最符合金融行业特点的解决方案,构建能放飞业务专家专业创新能力的技术平台。
|









