| 编辑推荐: |
本文介绍了elasticsearch集群中遇见的错误,并提出解决办法,运行插件Maven
Helper,希望对您的学习有所帮助。
本文来自CSDN,由火龙果软件Alice编辑、推荐。 |
|
以下三条记录源于5台机器导入近3亿条文档
1.集群压力大,某台机器失去“心跳”后,其他机器好像总找不回它,导致数据无法继续传输

查看日志,是说9300拒绝连接,想不明白,怎么会拒绝连接?很显然与防火墙无关,果然,关了防火墙依然有出现这种情况的可能。
【我感觉还是9300的写入压力太大?】
目前既没有找到好的解释,也没有好的解决办法
目前的解决办法是:
将bulk提交的request——timeout设置得很大,比如600秒,retries数也设置大一些,比如说100次。这样一来,集群不可用时,自己的代码程序不会退出。因为代码退出代价很大,你不知道什么时候集群失效了,数据传输到了哪些文件的哪些位置,重来又太耗时。
故让代码持续的去尝试请求,然后手动修复集群。
2.[WARN ][o.e.m.j.JvmGcMonitorService] [es-ip13] [gc][160]
overhead, spent [97
这是个小坑,设置初始堆和最大堆的值后(我是12g),需要将下方的默认的1g注销掉,否则还是会设置为1G【你可以在启动es时,在其日志中查看到,会有12g,12g,1g,
1g的打印;或者从kibana中通过监控界面看到,你会看到,应用不断的GC】
即使你是Python客户端,也不应该忘记,ES是Java程序,不要忘了JVM和GC
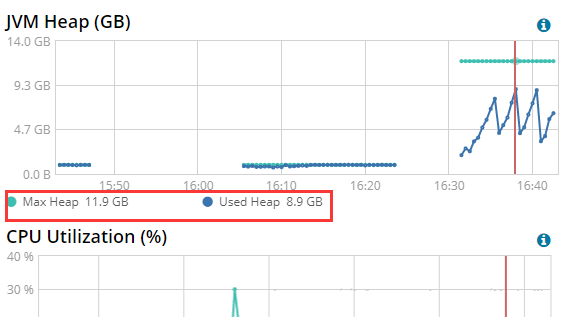
可以看到,至少在批量导入数据时,内存占用还是很高的。
2018/08/14
netty版本冲突
java.lang.NoSuchMethodError:
io.netty.util.AttributeKey.newInstance
(Ljava/lang/String;)Lio/netty/util/AttributeKey; |
最开始只看见log4j依赖包冲突:
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>${elasticsearch.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
</exclusion>
</exclusions>
</dependency> |
运行依然同样的报错:
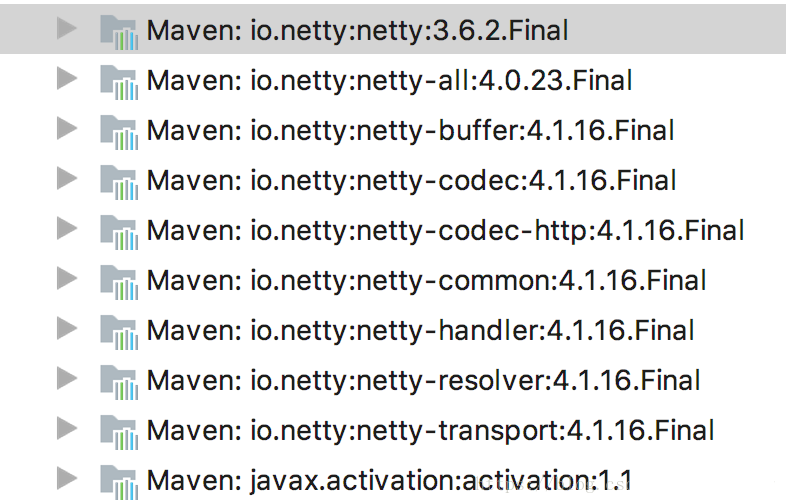
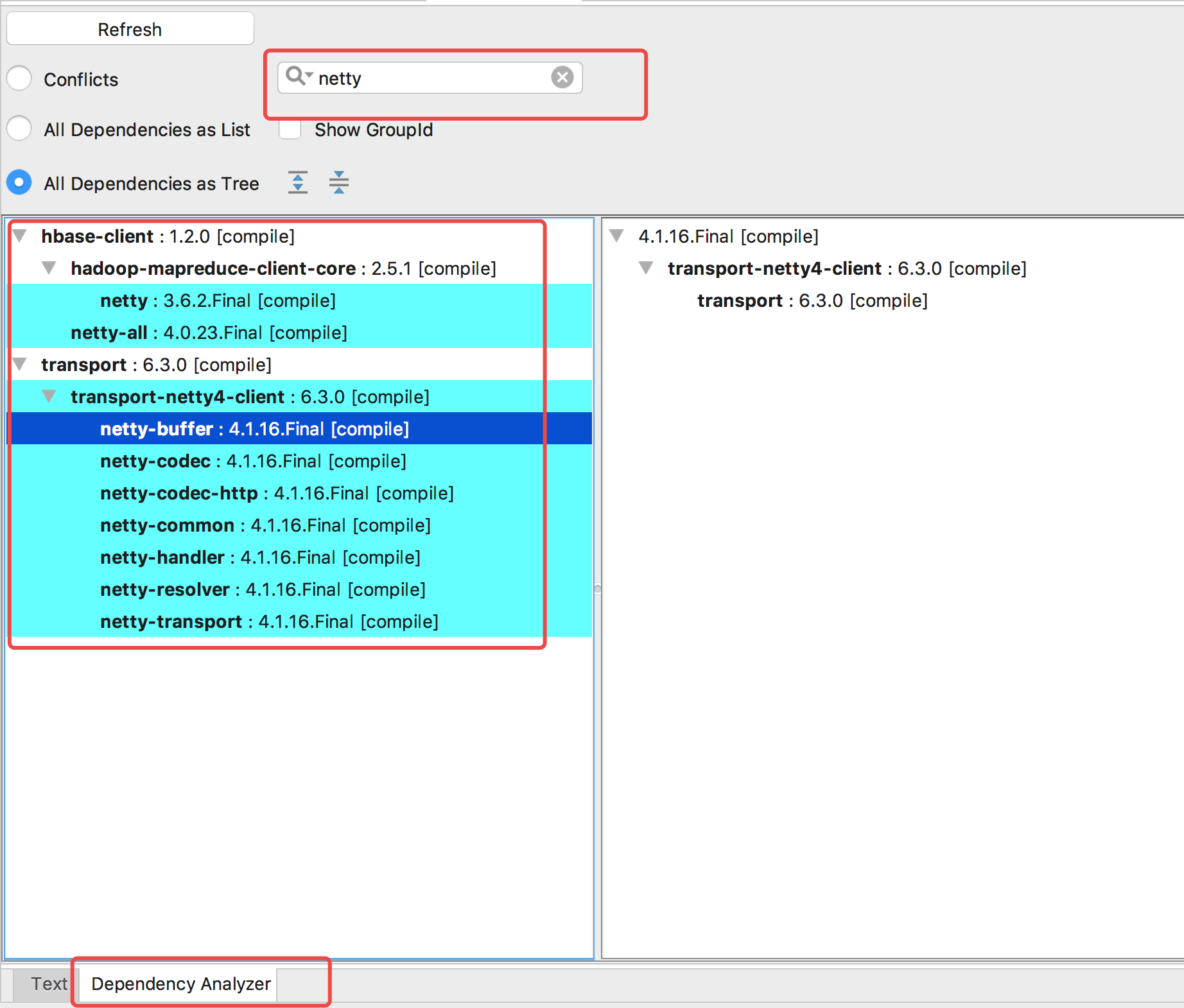
可以发现,netty确实有低版本冲突
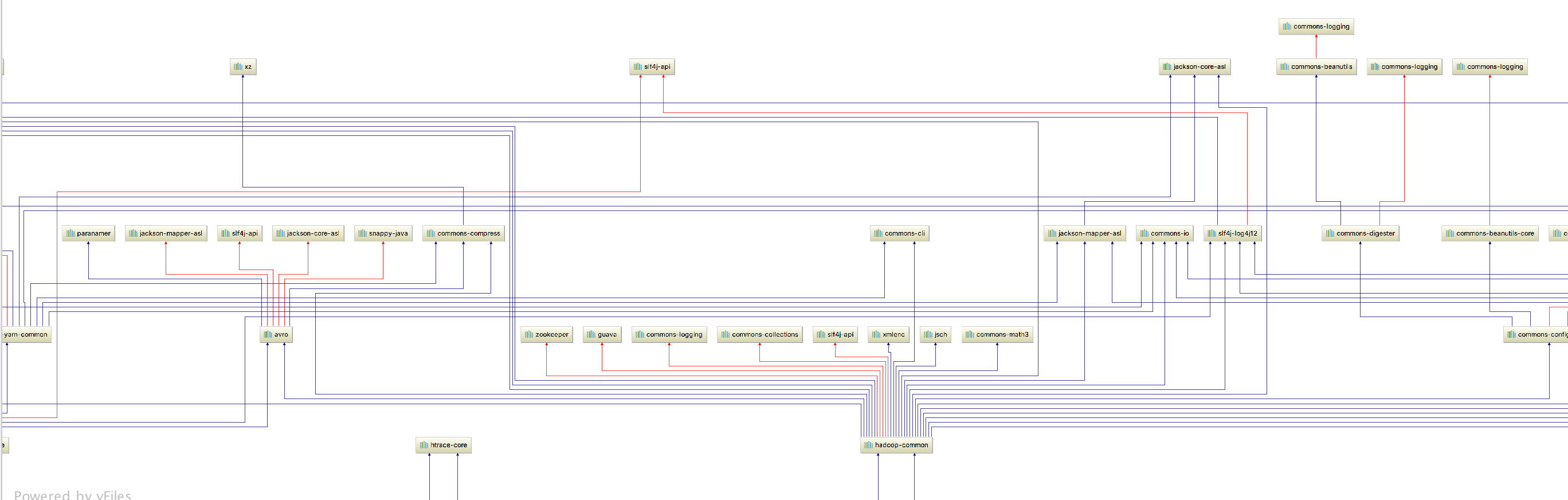
通过这种方式排除冲突依赖是不大合适了,这么多,看不过来。
一大堆博客都这样写,尼玛你认为这真的是个好办法?上百个依赖关系,要不你使用3个屏幕接起来放大慢慢看?

解决办法:
插件Maven Helper
使用示例:
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0</version>
<exclusions>
<exclusion>
<artifactId>netty</artifactId>
<groupId>io.netty</groupId>
</exclusion>
<exclusion>
<artifactId>netty-all</artifactId>
<groupId>io.netty</groupId>
</exclusion>
</exclusions>
</dependency> |
|









