| БрМЭЦМі: |
БОЮФНВЪіЪВУДЪЧЯћЯЂЯЕЭГЃЌЪВУДЪЧKafkaЃПKafkaМмЙЙЃЌДДНЈtopicЃЌЦєЖЏвЛИіЯћЗбепЃЌЯЃЭћЖдФњгаЫљАяжњ
БОЮФРДздгкЬкбЖдЦЃЌгЩЛ№СњЙћШэМўDeloresБрМЁЂЭЦМіЁЃ |
|
1ЁЂЪВУДЪЧЯћЯЂЯЕЭГЃП
ЯћЯЂЯЕЭГИКд№НЋЪ§ОнДгвЛИігІгУГЬађДЋЪфЕНСэвЛИігІгУГЬађЃЌвђДЫгІгУГЬађПЩвдзЈзЂгкЪ§ОнЃЌЕЋВЛЕЃаФШчКЮЙВЯэЫќЁЃ ЗжВМЪНЯћЯЂДЋЕнЛљгкПЩППЯћЯЂЖгСаЕФИХФюЁЃ ЯћЯЂдкПЭЛЇЖЫгІгУГЬађКЭЯћЯЂДЋЕнЯЕЭГжЎМфвьВНХХЖгЁЃ гаСНжжРраЭЕФЯћЯЂФЃЪНПЩгУ - вЛжжЪЧЕуЖдЕуЃЌСэвЛжжЪЧЗЂВМ - ЖЉдФ(pub-sub)ЯћЯЂЯЕЭГЁЃ ДѓЖрЪ§ЯћЯЂФЃЪНзёб pub-sub ЁЃ
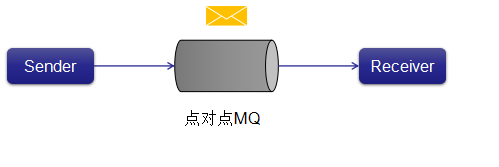
ЃЈ1ЃЉЕуЖдЕуЯћЯЂЯЕЭГ
дкЕуЖдЕуЯЕЭГжаЃЌЯћЯЂБЛБЃСєдкЖгСажаЁЃ вЛИіЛђЖрИіЯћЗбепПЩвдЯћКФЖгСажаЕФЯћЯЂЃЌЕЋЪЧЬиЖЈЯћЯЂжЛФмгЩзюЖрвЛИіЯћЗбепЯћЗбЁЃ вЛЕЉЯћЗбепЖСШЁЖгСажаЕФЯћЯЂЃЌЫќОЭДгИУЖгСажаЯћЪЇЁЃ ИУЯЕЭГЕФЕфаЭЪОР§ЪЧЖЉЕЅДІРэЯЕЭГЃЌЦфжаУПИіЖЉЕЅНЋгЩвЛИіЖЉЕЅДІРэЦїДІРэЃЌЕЋЖрИіЖЉЕЅДІРэЦївВПЩвдЭЌЪБЙЄзїЁЃ ЯТЭМУшЪіСЫНсЙЙЁЃ
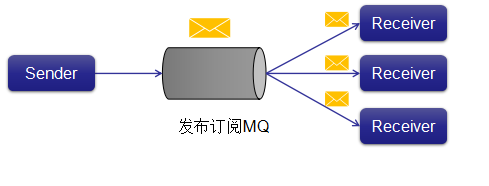
ЃЈ2ЃЉЗЂВМ - ЖЉдФЯћЯЂЯЕЭГ
дкЗЂВМ - ЖЉдФЯЕЭГжаЃЌЯћЯЂБЛБЃСєдкжїЬтжаЁЃ гыЕуЖдЕуЯЕЭГВЛЭЌЃЌЯћЗбепПЩвдЖЉдФвЛИіЛђЖрИіжїЬтВЂЪЙгУИУжїЬтжаЕФЫљгаЯћЯЂЁЃ дкЗЂВМ - ЖЉдФЯЕЭГжаЃЌЯћЯЂЩњВњепГЦЮЊЗЂВМепЃЌЯћЯЂЪЙгУепГЦЮЊЖЉдФепЁЃ вЛИіЯжЪЕЩњЛюЕФР§згЪЧDishЕчЪгЃЌЫќЗЂВМВЛЭЌЕФЧўЕРЃЌШчдЫЖЏЃЌЕчгАЃЌвєРжЕШЃЌШЮКЮШЫЖМПЩвдЖЉдФздМКЕФЦЕЕРМЏЃЌВЂЛёЕУЫћУЧЖЉдФЕФЦЕЕРЪБПЩгУЁЃ
2ЁЂЪВУДЪЧKafkaЃП
Apache KafkaЪЧвЛИіЗжВМЪНЗЂВМ - ЖЉдФЯћЯЂЯЕЭГКЭвЛИіЧПДѓЕФЖгСаЃЌПЩвдДІРэДѓСПЕФЪ§ОнЃЌВЂЪЙФњФмЙЛНЋЯћЯЂДгвЛИіЖЫЕуДЋЕнЕНСэвЛИіЖЫЕуЁЃ KafkaЪЪКЯРыЯпКЭдкЯпЯћЯЂЯћЗбЁЃ KafkaЯћЯЂБЃСєдкДХХЬЩЯЃЌВЂдкШКМЏФкИДжЦвдЗРжЙЪ§ОнЖЊЪЇЁЃ KafkaЙЙНЈдкZooKeeperЭЌВНЗўЮёжЎЩЯЁЃ ЫќгыApache StormКЭSparkЗЧГЃКУЕиМЏГЩЃЌгУгкЪЕЪБСїЪНЪ§ОнЗжЮіЁЃ
KafkaзЈЮЊЗжВМЪНИпЭЬЭТСПЯЕЭГЖјЩшМЦЁЃ гыЦфЫћЯћЯЂДЋЕнЯЕЭГЯрБШЃЌKafkaОпгаИќКУЕФЭЬЭТСПЃЌФкжУЗжЧјЃЌИДжЦКЭЙЬгаЕФШнДэФмСІЃЌетЪЙЕУЫќЗЧГЃЪЪКЯДѓЙцФЃЯћЯЂДІРэгІгУГЬађЁЃ
KafkaПЩвддкаэЖргУР§жаЪЙгУЃЌ ЦфжавЛаЉСаГіШчЯТЃК
жИБъ - KafkaЭЈГЃгУгкВйзїМрПиЪ§ОнЁЃ етЩцМАОлКЯРДздЗжВМЪНгІгУГЬађЕФЭГМЦаХЯЂЃЌвдВњЩњВйзїЪ§ОнЕФМЏжаРЁЫЭЁЃ
ШежООлКЯНтОіЗНАИ - KafkaПЩгУгкПчзщжЏДгЖрИіЗўЮёЪеМЏШежОЃЌВЂЪЙЫќУЧвдБъзМИёЪНЬсЙЉИјЖрИіЗўЮёЦїЁЃ
СїДІРэ - СїааЕФПђМм(ШчStormКЭSpark Streaming)ДгжїЬтжаЖСШЁЪ§ОнЃЌЖдЦфНјааДІРэЃЌВЂНЋДІРэКѓЕФЪ§ОнаДШыаТжїЬтЃЌЙЉгУЛЇКЭгІгУГЬађЪЙгУЁЃ KafkaЕФЧПФЭОУаддкСїДІРэЕФЩЯЯТЮФжавВЗЧГЃгагУЁЃ
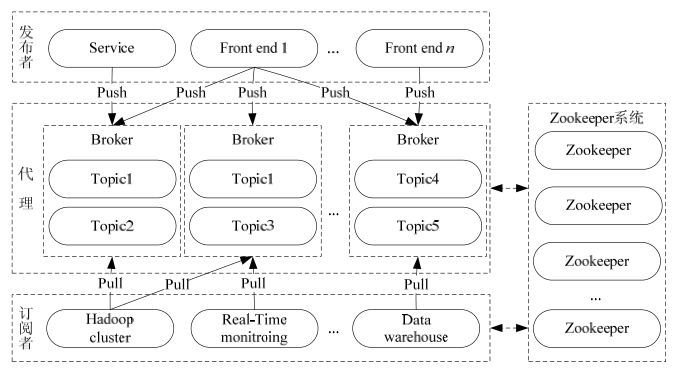
3ЁЂKafkaМмЙЙ
ЩюШыбЇЯАKafkaжЎЧАЃЌБиаыСЫНтжїЬтЃЈTopicЃЉЁЂОМЭШЫЃЈBrokerЃЉЁЂЩњВњепЃЈProducerЃЉЛђепЗЂВМепЃЌвдМАЯћЗбепЃЈConsumerЃЉЛђепЖЉдФепЕШжївЊЪѕгяЁЃ ЯТЭМЫЕУїСЫжївЊЪѕгяЃЌБэИёЯъЯИУшЪіСЫЭМБэзщМўЁЃ
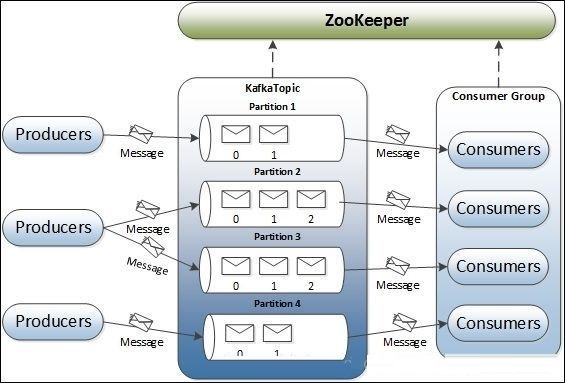
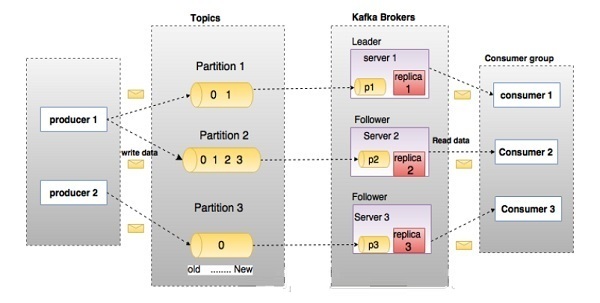
ЃЈ1ЃЉTopicsЃЈжїЬтЃЉ
ЪєгкЬиЖЈРрБ№ЕФЯћЯЂСїГЦЮЊжїЬтЁЃ Ъ§ОнДцДЂдкжїЬтжаЁЃTopicЯрЕБгкQueueЁЃ
жїЬтБЛВ№ЗжГЩЗжЧјЁЃ УПИіетбљЕФЗжЧјАќКЌВЛПЩБфгаађађСаЕФЯћЯЂЁЃ ЗжЧјБЛЪЕЯжЮЊОпгаЯрЕШДѓаЁЕФвЛзщЗжЖЮЮФМўЁЃ
ЃЈ2ЃЉPartitionЃЈЗжЧјЃЉ
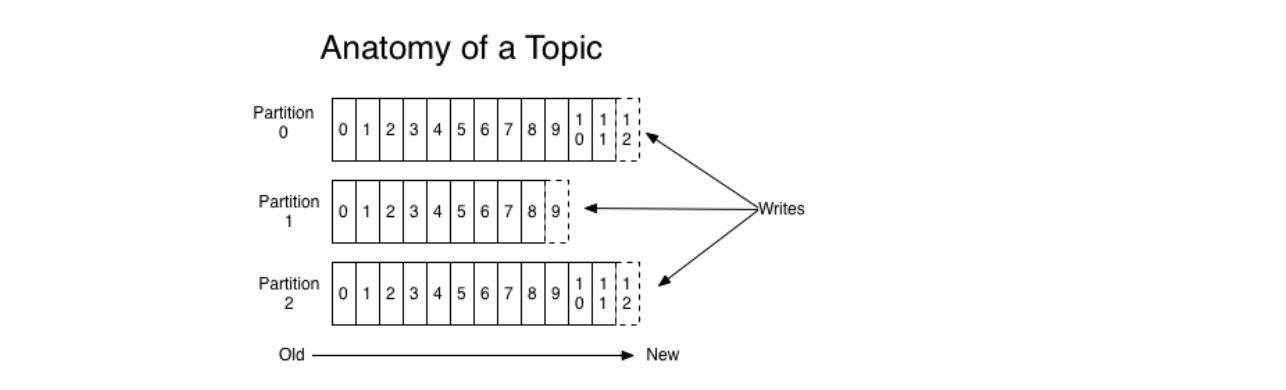
вЛИіTopicПЩвдЗжГЩЖрИіPartitionЃЌетЪЧЮЊСЫЦНааЛЏДІРэЁЃ
УПИіPartitionФкВПЯћЯЂгаађЃЌЦфжаУПИіЯћЯЂЖМгавЛИіoffsetађКХЁЃ
вЛИіPartitionжЛЖдгІвЛИіBrokerЃЌвЛИіBrokerПЩвдЙмРэЖрИіPartitionЁЃ
ЃЈ3ЃЉPartition offsetЃЈЗжЧјЦЋвЦЃЉ
УПИіЗжЧјЯћЯЂОпгаГЦЮЊ offset ЕФЮЈвЛађСаБъЪЖЁЃ
ЃЈ4ЃЉReplicas of partitionЃЈЗжЧјБИЗнЃЉ
ИББОжЛЪЧвЛИіЗжЧјЕФБИЗнЁЃ ИББОДгВЛЖСШЁЛђаДШыЪ§ОнЁЃ ЫќУЧгУгкЗРжЙЪ§ОнЖЊЪЇЁЃ
ЃЈ5ЃЉBrokersЃЈОМЭШЫЃЉ
ДњРэЪЧИКд№ЮЌЛЄЗЂВМЪ§ОнЕФМђЕЅЯЕЭГЁЃ УПИіДњРэПЩвдУПИіжїЬтОпгаСуИіЛђЖрИіЗжЧјЁЃ МйЩшЃЌШчЙћдквЛИіжїЬтКЭNИіДњРэжагаNИіЗжЧјЃЌУПИіДњРэНЋгавЛИіЗжЧјЁЃ
МйЩшдквЛИіжїЬтжагаNИіЗжЧјВЂЧвЖргкNИіДњРэ(n + m)ЃЌдђЕквЛИіNДњРэНЋОпгавЛИіЗжЧјЃЌВЂЧвЯТвЛИіMДњРэНЋВЛОпгагУгкИУЬиЖЈжїЬтЕФШЮКЮЗжЧјЁЃ
МйЩшдквЛИіжїЬтжагаNИіЗжЧјВЂЧваЁгкNИіДњРэ(n-m)ЃЌУПИіДњРэНЋдкЫќУЧжЎМфОпгавЛИіЛђЖрИіЗжЧјЙВЯэЁЃ гЩгкДњРэжЎМфЕФИКдиЗжВМВЛЯрЕШЃЌВЛЭЦМіЪЙгУДЫЗНАИЁЃ
ЃЈ6ЃЉKafka ClusterЃЈKafkaМЏШКЃЉ
KafkaгаЖрИіДњРэБЛГЦЮЊKafkaМЏШКЁЃ ПЩвдРЉеЙKafkaМЏШКЃЌЮоашЭЃЛњЁЃ етаЉМЏШКгУгкЙмРэЯћЯЂЪ§ОнЕФГжОУадКЭИДжЦЁЃ
ЃЈ7ЃЉProducersЃЈЩњВњепЃЉ
ЩњВњепЪЧЗЂЫЭИјвЛИіЛђЖрИіKafkaжїЬтЕФЯћЯЂЕФЗЂВМепЁЃ ЩњВњепЯђKafkaОМЭШЫЗЂЫЭЪ§ОнЁЃ УПЕБЩњВњепНЋЯћЯЂЗЂВМИјДњРэЪБЃЌДњРэжЛашНЋЯћЯЂИНМгЕНзюКѓвЛИіЖЮЮФМўЁЃЪЕМЪЩЯЃЌИУЯћЯЂНЋБЛИНМгЕНЗжЧјЁЃ ЩњВњепЛЙПЩвдЯђЫћУЧбЁдёЕФЗжЧјЗЂЫЭЯћЯЂЁЃ
ЃЈ8ЃЉConsumersЃЈЯћЗбепЃЉ
ConsumersДгОМЭШЫДІЖСШЁЪ§ОнЁЃ ЯћЗбепЖЉдФвЛИіЛђЖрИіжїЬтЃЌВЂЭЈЙ§ДгДњРэжаЬсШЁЪ§ОнРДЪЙгУвбЗЂВМЕФЯћЯЂЁЃ
ConsumerздМКЮЌЛЄЯћЗбЕНФФИіoffet
УПИіConsumerЖМгаЖдгІЕФgroup
groupФкЪЧqueueЯћЗбФЃаЭЃКИїИіConsumerЯћЗбВЛЭЌЕФpartitionЃЌвђДЫвЛИіЯћЯЂдкgroupФкжЛЯћЗбвЛДЮ
groupМфЪЧpublish-subscribeЯћЗбФЃаЭЃКИїИіgroupИїздЖРСЂЯћЗбЃЌЛЅВЛгАЯьЃЌвђДЫвЛИіЯћЯЂБЛУПИіgroupЯћЗбвЛДЮЁЃ
4ЁЂДДНЈtopic
ДДНЈвЛИіНазіЁАtestЁБЕФtopicЃЌЫќжЛгавЛИіЗжЧјЃЌвЛИіИББОЁЃ
[root@node1
kafka_2.11-0.11.0.1]#
bin/kafka-topics.sh --create
--zookeeper
localhost:2181 --replication-factor
1
--partitions 1 --topic test
Created topic "test".
[2017-10-29 07:44:33,497] INFO
[ReplicaFetcherManager
on broker 1]
Removed fetcher for partitions test-0
(kafka.server.ReplicaFetcherManager)
[2017-10-29 07:44:33,602] INFO Loading
producer
state from offset 0 for
partition test-0 with
message format
version 2 (kafka.log.Log)
[2017-10-29 07:44:33,618] INFO Completed
load
of log test-0 with 1 log segments,
log start offset
0 and log end
offset 0 in 66 ms (kafka.log.Log)
[2017-10-29 07:44:33,658] INFO Created
log for
partition [test,0] in
/var/log/kafka-logs with
properties
{compression.type -> producer,
message.format.version
-> 0.11.0-IV2,
file.delete.delay.ms -> 60000,
max.message.bytes -> 1000012,
min.compaction.lag.ms
-> 0,
message.timestamp.type -> CreateTime,
min.insync.replicas -> 1,
segment.jitter.ms
-> 0,
preallocate -> false, min.cleanable.
dirty.ratio
-> 0.5, index.interval.
bytes -> 4096, unclean.leader.
election.enable
-> false, retention.
bytes -> -1, delete.retention.ms
-> 86400000, cleanup.policy -> [delete],
flush.ms -> 9223372036854775807,
segment.ms
-> 604800000, segment.bytes
-> 1073741824,
retention.ms -> 604800000, message.timestamp.difference.max.ms
-> 9223372036854775807, segment.index.
bytes
-> 10485760, flush.messages
-> 9223372036854775807}.
(kafka.log.LogManager)
[2017-10-29 07:44:33,660] INFO Partition
[test,0]
on broker 1: No checkpointed
highwatermark is
found for partition test-0 (kafka.cluster.Partition)
[2017-10-29 07:44:33,665] INFO Replica
loaded
for partition test-0 with initial
high watermark
0 (kafka.cluster.Replica)
[2017-10-29 07:44:33,667] INFO Partition
[test,0]
on broker 1: test-0 starts at
Leader Epoch 0 from
offset 0. Previous
Leader Epoch was: -1
(kafka.cluster.Partition)
[root@node1 kafka_2.11-0.11.0.1]# |
ПЩвдЭЈЙ§listУќСюВщПДДДНЈЕФtopic
[root@node1
kafka_2.11-0.11.0.1]
# bin/kafka-topics.sh --list
--zookeeper localhost:2181
test
[root@node1 kafka_2.11-0.11.0.1]# |
5ЁЂЗЂЫЭЯћЯЂ
[root@node1
kafka_2.11-0.11.0.1]
# bin/kafka-console-producer.sh
--broker-list localhost:9092
--topic test
>This is a message
>[2017-10-29 07:47:28,399]
INFO Updated PartitionLeaderEpoch.
New: {epoch:0, offset:0}, Current:
{epoch:-1,
offset-1} for Partition:
test-0. Cache now contains
0 entries. (kafka.server.epoch.LeaderEpochFileCache)
This is another message
>^C[root@node1 kafka_2.11-0.11.0.1]# |
6ЁЂЦєЖЏвЛИіЯћЗбеп
KafkaЛЙгаИіЯћЗбепПижЦЬЈЃЌЛсАбЯћЯЂЪфГіЕНБъзМЪфГі
[root@node2 kafka_2.11-0.11.0.1]
# bin/kafka-console-consumer.sh
--bootstrap-server localhost:9092
--topic test
--from-beginning
[2017-10-29 07:49:32,094] INFO Topic
creation
{"version":1,"partitions":
{"45":[1],"34":[2],"12":[1],"8":[3],
"19":[2],"23":[3],"4":[2],"40":[2],"15":
[1],"11":[3],"9":[1],"44":[3],"33":[1],
"22":[2],"26":[3],"37":[2],"13":[2],"46":
[2],"24":[1],"35":[3],"16":[2],"5":[3],
"10":[2],"48":[1],"21":[1],"43":[2],"32":
[3],"49":[2],"6":[1],"36":[1],"1":[2],"39":
[1],"17":[3],"25":[2],"14":[3],
"47":[3],"31":
[2],"42":[1],"0":[1],"20":[3],"27":
[1],"2":[3],
"38":[3],"18":[1],"30":[1],"7":[2],
"29":[3],"41":
[3],"3":[1],"28":[2]}}
(kafka.admin.AdminUtils$)
[2017-10-29 07:49:32,121] INFO
[KafkaApi-2]
Auto
creation of topic
__consumer_offsets with
50 partitions
and replication factor
1 is successful
(kafka.server.KafkaApis)
[2017-10-29 07:49:36,792] INFO
[ReplicaFetcherManager
on broker 2]
Removed fetcher for partitions
__consumer_offsets-22,
__consumer_offsets-4,__consumer_offsets-7,
__consumer_offsets-46,__consumer_offsets-25
,__consumer_offsets-49,__consumer_offsets-16,
__consumer_offsets-28,__consumer_offsets-31,
__consumer_offsets-37,__consumer_offsets-19,
__consumer_offsets-13,__consumer_offsets-43,
__consumer_offsets-1,__consumer_offsets-34,
__consumer_offsets-10,__consumer_offsets-40
(kafka.server.ReplicaFetcherManager)
[2017-10-29 07:49:36,919] INFO
Loading producer
state from offset 0 for partition
__consumer_offsets-10
with message
format version 2 (kafka.log.Log)
....
....
[2017-10-29 07:49:38,414] INFO
[GroupCoordinator
2]:
Stabilized group console-consumer
-45516 generation
1
(__consumer_offsets-22)
(kafka.coordinator.group.GroupCoordinator)
[2017-10-29 07:49:38,476] INFO
[GroupCoordinator
2]:
Assignment received from leader for group
console-consumer-45516 for generation 1
(kafka.coordinator.group.GroupCoordinator)
[2017-10-29 07:49:38,566] INFO
Updated PartitionLeaderEpoch.
New:
{epoch:0, offset:0}, Current:
{epoch:-1,
offset-1} for Partition:
__consumer_offsets-22.
Cache now contains 0 entries.
(kafka.server.epoch.LeaderEpochFileCache)
This is a message
This is another message |
|









