| БрМЭЦМі: |
БОЮФНВЪіKafkaЩшМЦвЊЕуЃЌKafkaЯћЯЂДцДЂЗНЪНЃЌШчКЮЭЈЙ§offsetВщевMessageЃЌЯЃЭћЖдФњгаЫљАяжњ
БОЮФРДздгкВЉПЭдАЃЌгЩЛ№СњЙћШэМўDeloresБрМЁЂЭЦМіЁЃ |
|
KafkaМмЙЙШчЭМЃК
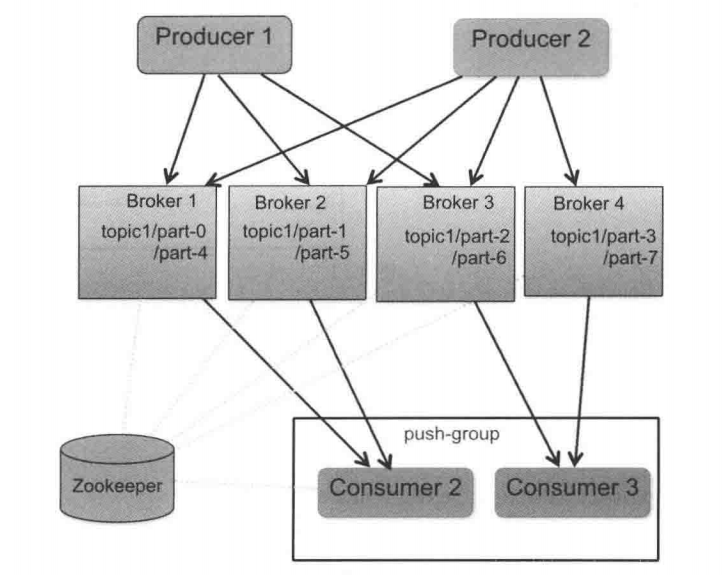
ећИіМмЙЙжаАќРЈШ§ИіНЧЩЋЁЃ
ЩњВњепЃЈProducerЃЉ:ЯћЯЂКЭЪ§ОнЩњВњеп
ДњРэЃЈBrokerЃЉ:ЛКДцДњРэЃЌKafkaЕФКЫаФЙІФм
ЯћЗбепЃЈConsumerЃЉ:ЯћЯЂКЭЪ§ОнЯћЗбеп
ећЬхМмЙЙКмМђЕЅЃЌKafkaИјProducerКЭConsumerЬсЙЉзЂВсЕФНгПкЃЌЪ§ОнДгProducerЗЂЫЭЕНBrokerЃЌBrokerГаЕЃвЛИіжаМфЛКДцКЭЗжЗЂЕФзїгУЃЌИКд№ЗжЗЂзЂВсЕНЯЕЭГжаЕФConsumerЁЃ
ЁЁЩшМЦвЊЕу
ЁЁЁЁKafkaЗЧГЃИпаЇЃЌЯТУцНщЩмKafkaИпаЇЕФдвђЃЌЖдРэНтKafkaЗЧГЃгУАяжњЁЃ
жБНгЪЙгУLinuxЮФМўЯЕЭГЕФCacheРДИпаЇЛКДцЪ§Он
ВЩгУLinux Zero-CopyЬсИпЗЂЫЭадФмЁЃДЋЭГЕФЪ§ОнЗЂЫЭашвЊЗЂЫЭ4ДЮЩЯЯТЧаЛЛЃЌВЩгУSendfileЯЕЭГЕїгУжЎКѓЃЌЪ§ОнжБНгдкФкКЫЬЌНЛЛЛЃЌЯЕЭГЩЯЯТЮФЧаЛЛМѕЩйЮЊ2ДЮЁЃПЩвдЬсИп60%ЕФЪ§ОнЗЂЫЭадФмЁЃ
KafkaвдTopicРДНјааЯћЗбЙмРэЃЌУПИіTopicАќКЌЖрИіPart(ition)ЃЌУПИіPartЖдгІвЛИіТпМLogЃЌгЩЖрИіSegmentзщГЩЁЃУПИіSegmentжаДцДЂЖрЬѕЯћЯЂЃЌЯћЯЂIDгЩТпМЮЛжУОіЖЈЃЌМДДгЯћЯЂIDПЩжБНгЖЈЮЛЕНЯћЯЂЕФДцДЂЮЛжУЃЌБмУтIDЕНЮЛжУЕФЖюЭтгГЩфЁЃУПИіPartдкФкДцжаЖдгІвЛИіIndexЃЌМЧТМУПИіSegmentжаЕФЕквЛИіЯћЯЂЦЋвЦЁЃ
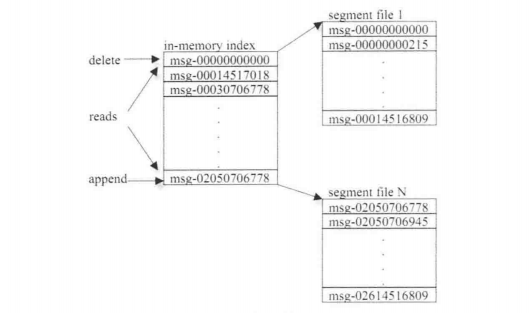
ЗЂВМепЗЂЕНФГИіTopicЕФЯћЯЂЛсБЛОљдШЕиЗжВМЕНЖрИіPartЩЯЃЈЫцЛњЛђИљОнгУЛЇжИЖЈЕФЛиЕїКЏЪ§НјааЗжВМЃЉЃЌBrokerЪеЕНЗЂВМЯћЯЂКѓЭљЖдгІPartЕФзюКѓвЛИіSegmentЩЯЬэМгИУЯћЯЂЃЌЕБФГИіSegmentЩЯЕФЯћЯЂЬѕЪ§ЕНДяХфжУжЕЛђЯћЯЂЗЂВМЪБМфГЌЙ§уажЕЪБЃЌSegmentЩЯЕФЯћЯЂБуЛсБЛflushЕНДХХЬЩЯЃЌжЛгаflushЕНДХХЬЩЯЕФЯћЯЂЖЉдФепВХФмЖЉдФЕНЃЌSegmentДяЕНвЛЖЈЕФДѓаЁКѓНЋВЛЛсдйЭљИУSegmentаДЪ§ОнЃЌBrokerЛсДДНЈаТЕФSegmentЁЃ
ЁЁЁЁШЋЯЕЭГЗжВМЪНЃЌМДЫљгаЕФProducerЁЂBrokerКЭConsumerЖМФЌШЯгаЖрИіЃЌОљЮЊЗжВМЪНЕФЁЃProducerКЭBrokerжЎМфУЛгаИКдиОљКтЛњжЦЁЃBrokerКЭConsumer жЎМфРћгУZooKeeperНјааИКдиОљКтЁЃЫљгаЕФBrokerКЭConsumerЖМЛсдкZookeeperжаНјаазЂВсЃЌЧвZookeeperЛсБЃДцЫћУЧЕФвЛаЉдЊЪ§ОнаХЯЂЁЃШчЙћФГИіBrokerКЭConsumerЗЂЩњСЫБфЛЏЃЌФЧУДЫљгаЦфЫћЕФBrokerКЭConsumerЖМЛсЕУЕНЭЈжЊЁЃ
ЁЁKafkaЯћЯЂДцДЂЗНЪН
Topic
ЁЁЁЁTopicЪЧЗЂВМЕФЯћЯЂЕФРрБ№ЛђепжжзгFeedУћЁЃЖдгкУПИіTopicЃЌKafkaМЏШКЖМЛсЮЌЛЄетИіЗжЧјЕФLogЁЃШчЭМ
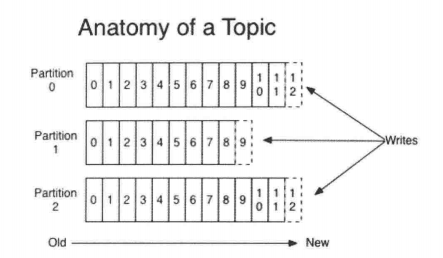
ЁЁУПИіЗжЧјЖМЪЧвЛИіЫГађЕФЁЂВЛПЩБфЕФЯћЯЂЖгСаЃЌВЂЧвПЩвдГжајЬэМгЁЃЗжЧјжаЕФЯћЯЂЖМБЛЗжХфСЫвЛИіађСаКХЃЌГЦжЎЮЊЦЋвЦСПЃЈoffsetЃЉЃЌдкУПИіЗжЧјжаДЫЦЋвЦСПЖМЪЧЮЈвЛЕФЁЃ
ЁЁЁЁKafkaМЏШКБЃДцЫљгаЕФЯћЯЂЃЌжБЕНЫћУЧЙ§ЦкЃЌЮоТлЯћЯЂЪЧЗёБЛЯћЗбЁЃЪЕМЪЩЯЃЌЯћЗбепЫљГжгаЕФНігаЕФдЊЪ§ОнОЭЪЧетИіЦЋвЦСПЃЌвВОЭЪЧЯћЗбепдкетИіLogжаЕФЮЛжУЁЃдке§ГЃЧщПіЯТЃЌЕБЯћЗбепЯћЗбЯћЯЂЕФЪБКђЦЋвЦСПвВЯпаддіМгЁЃЕЋЪЧЪЕМЪЦЋвЦСПгЩЯћЗбепПижЦЃЌЯћЗбепПЩвджижУЦЋвЦСПЃЌвджиаТЖСШЁЯћЯЂЁЃ
ЁЁЁЁетжжЩшМЦЖдЯћЗбепРДЫЕВйзїздШчЃЌвЛИіЯћЗбепЕФВйзїВЛЛсгАЯьЦфЫћЯћЗбепЖдДЫLogЕФДІРэЁЃ
ЗжЧј
ЁЁЁЁKafkaжаВЩгУЗжЧјЕФЩшМЦгаСНИіФПЕФЃКвЛЪЧПЩвдДІРэИќЖрЕФЯћЯЂЃЌЖјВЛЪмЕЅЬхЗўЮёЦїЕФЯожЦЃЌTopicгЕгаЖрИіЗжЧјЃЌвтЮЖзХЫќПЩвдВЛЪмЯожЦЕиДІРэИќЖрЪ§ОнЃЛЖўЪЧЗжЧјПЩвдзїЮЊВЂааДІРэЕФЕЅдЊЁЃ
ЁЁЁЁKafkaЛсЮЊУПИіЗжЧјДДНЈвЛИіЮФМўМаЃЌЮФМўМаЕФУќУћЗНЪНЮЊtopicName-ЗжЧјађКХЃЌШчЭМ
ЁЁЖјЗжЧјЪЧгЩЖрИіSegmentзщГЩЕФЃЌЪЧЮЊСЫЗНБуНјааШежОЧхРэЁЂЛжИДЕШЙЄзїЁЃУПИіSegmentвдИУSegmentЕквЛЬѕЯћЯЂЕФoffsetУќУћВЂвдЁА.logЁБзїЮЊКѓзКЁЃСэЭтЛЙгавЛИіЫїв§ЮФМўЃЌЫћБъУїСЫУПИіSegmentЯТАќКЌЕФLog EntryЕФoffsetЗЖЮЇЃЌЮФМўУќУћЗНЪНвВЪЧШчДЫЃЌвдЁА.indexЁБзїЮЊКѓзКЃЌШчЯТЃК

Ыїв§КЭШежОЮФМўФкВПЕФЙиЯЕЃЌШчЭМЃК
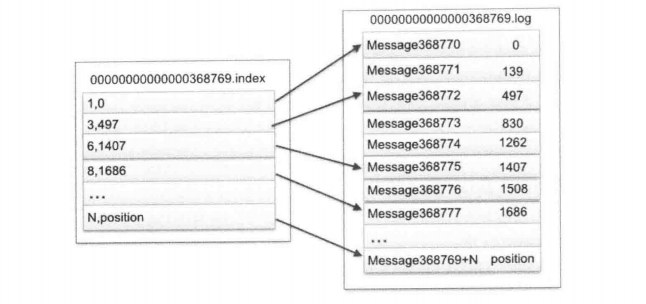
Ыїв§ЮФМўДцДЂДѓСПдЊЪ§ОнЃЌЪ§ОнЮФМўДцДЂДѓСПЯћЯЂЃЈMessageЃЉ,Ыїв§ЮФМўжаЕФдЊЪ§ОнжИЯђЖдгІЪ§ОнЮФМўжаMessageЕФЮяРэЦЋвЦЕижЗЁЃвдЫїв§ЮФМўжаЕФдЊЪ§Он3,497ЮЊР§ЃЌвРДЮдкЪ§ОнЮФМўжаБэЪОЕкШ§ИіMessageЃЈдкШЋОжPartitionжаБэЪОЕк368772ИіmessageЃЉЃЌвдМАИУЯћЯЂЕФЮяРэЦЋвЦЕижЗЮЊ497.
ЁЁ ЁЁSegmentЕФLogЮФМўгЩЖрИіMessageзщГЩЃЌЯТУцЯъЯИЫЕУїMessageЕФЮяРэНсЙЙЃЌШчЭМЃК

ВЮЪ§ЫЕУї
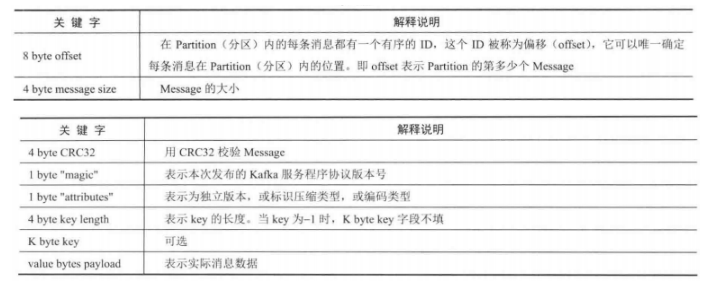
ШчКЮЭЈЙ§offsetВщевMessage
Р§ШчЃЌЖСШЁoffset=368776ЕФMessageЃЌашвЊЭЈЙ§ШчЯТСНИіВНжшЁЃ
ЕквЛВНЃКВщевSegment File.
00000000000000000000.indexБэЪОзюПЊЪМЕФЮФМўЃЌЦфЪЕЦЋвЦСПЃЈoffsetЃЉЮЊ0ЃЛЕкЖўИіЮФМў00000000000000368769.indexЕФЦфЪЕЦЋвЦСПЮЊ368770ЃЈ368769+1ЃЉЃЌвРДЮРрЭЦЁЃвдЦфЪЕЦЋвЦСПУќУћВЂХХађетаЉЮФМўЃЌжЛвЊИљОнoffset**ЖўЗжВщев**ЮФМўСаБэЃЌОЭПЩвдПьЫйЖЈЮЛЕНОпЬхЮФМўЁЃ
ЁЁ ЁЁЕБoffset=368776ЪБЃЌЖЈЮЛЕН00000000000000368769.index|logЁЃ
ЕкЖўВНЃКЭЈЙ§Segment File ВщевMessageЁЃ
ЁЁЁЁ ЭЈЙ§ЕквЛВНЖЈЮЛЕНSegment File,ЕБoffset=368776ЪБЃЌвРДЮЖЈЮЛЕН00000000000000368769.indexЕФдЊЪ§ОнЮяРэЮЛжУКЭ00000000000000368769.logЕФЮяРэЦЋвЦЕижЗЃЌШЛКѓдйЭЈЙ§00000000000000368769.logЫГађВщевЃЌжЊЕРoffset=368776ЮЊжЙЁЃ
ЁЁ ЁЁSegment Index FileВЩШЁЯЁЪшЫїв§ДцДЂЗНЪНЃЌПЩвдМѕЩйЫїв§ЮФМўДѓаЁЃЌЭЈЙ§Linux mmapНгПкПЩвджБНгНјааФкДцВйзїЁЃЯЁЪшЫїв§ЮЊЪ§ОнЮФМўЕФУПИіЖдгІMessageЩшжУвЛИідЊЪ§ОнжИеыЃЌЫќБШГэУмЫїв§НкЪЁСЫИќЖрЕФДцДЂПеМфЃЌЕЋВщевЦ№РДашвЊЯћКФИќЖрЕФЪБМфЁЃ
|









