| БрМЭЦМі: |
БОЮФжївЊЖдELKЕФзщМўКЭзщМўЙиЯЕЭМНјааНщЩмЃЌЦфДЮЖдЛљДЁЛЗОГАВзАХфжУдйЕНВтЪдвдМАЪ§ОнЛЏЕУеЙЪОЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкCSDNЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
вЛЁЂELKИХЪі
ELK ЪЧШ§ИіПЊдДШэМўЕФЫѕаДЃЌЗжБ№БэЪОЃК Elasticsearch
, Logstash , Kibana ЁЃ
ELK ЭЈГЃгУРДЙЙНЈШежОЗжЮіЦНЬЈЁЂЪ§ОнЗжЮіЫбЫїЦНЬЈЕШ
ЙйЗНЮФЕЕ
https://www.elastic.co/cn/products
зщМўНщЩм
Elasticsearch ЪЧИіПЊдДЗжВМЪНШЋЮФМьЫїКЭЪ§ОнЗжЮіЦНЬЈЁЃЫќЕФЬиЕугаЃКЗжВМЪНЃЌСуХфжУЃЌздЖЏЗЂЯжЃЌЫїв§здЖЏЗжЦЌЃЌЫїв§ИББОЛњжЦЃЌrestfulЗчИёНгПкЃЌИКдиОљКтЕШЬиЕуЁЃ
Kibana ЪЧвЛИіеыЖдElasticsearchЕФПЊдДЪ§ОнЗжЮіМАПЩЪгЛЏЦНЬЈЃЌгУРДЫбЫїЁЂВщПДНЛЛЅДцДЂдкElasticsearchЫїв§жаЕФЪ§ОнЁЃЪЙгУKibanaЃЌПЩвдЭЈЙ§ИїжжЭМБэНјааИпМЖЪ§ОнЗжЮіМАеЙЪОЁЃ
Logstash ЪЧвЛПюЛљгкВхМўЕФЪ§ОнЪеМЏКЭДІРэв§ЧцЁЃLogstash
ХфгаДѓСПЕФВхМўЃЌвдБуШЫУЧФмЙЛЧсЫЩНјааХфжУвддкЖржжВЛЭЌЕФМмЙЙжаЪеМЏЁЂДІРэВЂзЊЗЂЪ§ОнЁЃ
Beats ЧсСПМЖЕФЪ§ОнЪеМЏДІРэЙЄОп(Agent)ЃЌОпгаеМгУзЪдДЩйЕФгХЕуЃЌЪЪКЯгкдкИїИіЗўЮёЦїЩЯВЩМЏЪ§ОнКѓДЋЪфИјLogstashЃЌЙйЗНвВЭЦМіДЫЙЄОпЁЃBeatsгаЖрЖржжРраЭЃЌБШНЯГЃгУЕФЪЧ
FileBeats
зщМўЙиЯЕЭМ
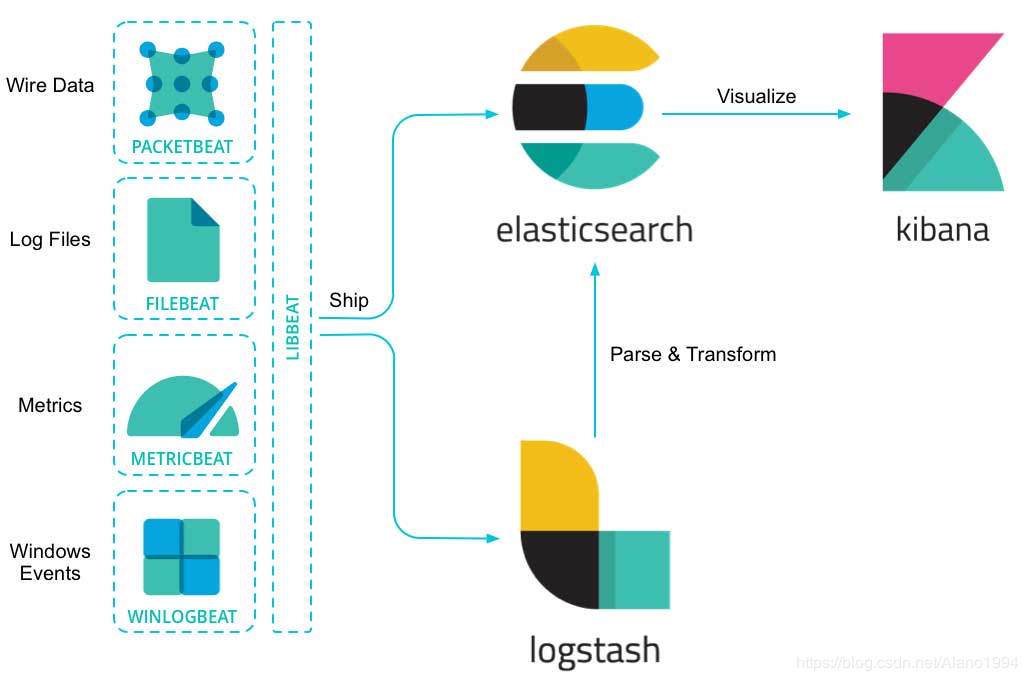
ЖўЁЂLogstashЯъНт
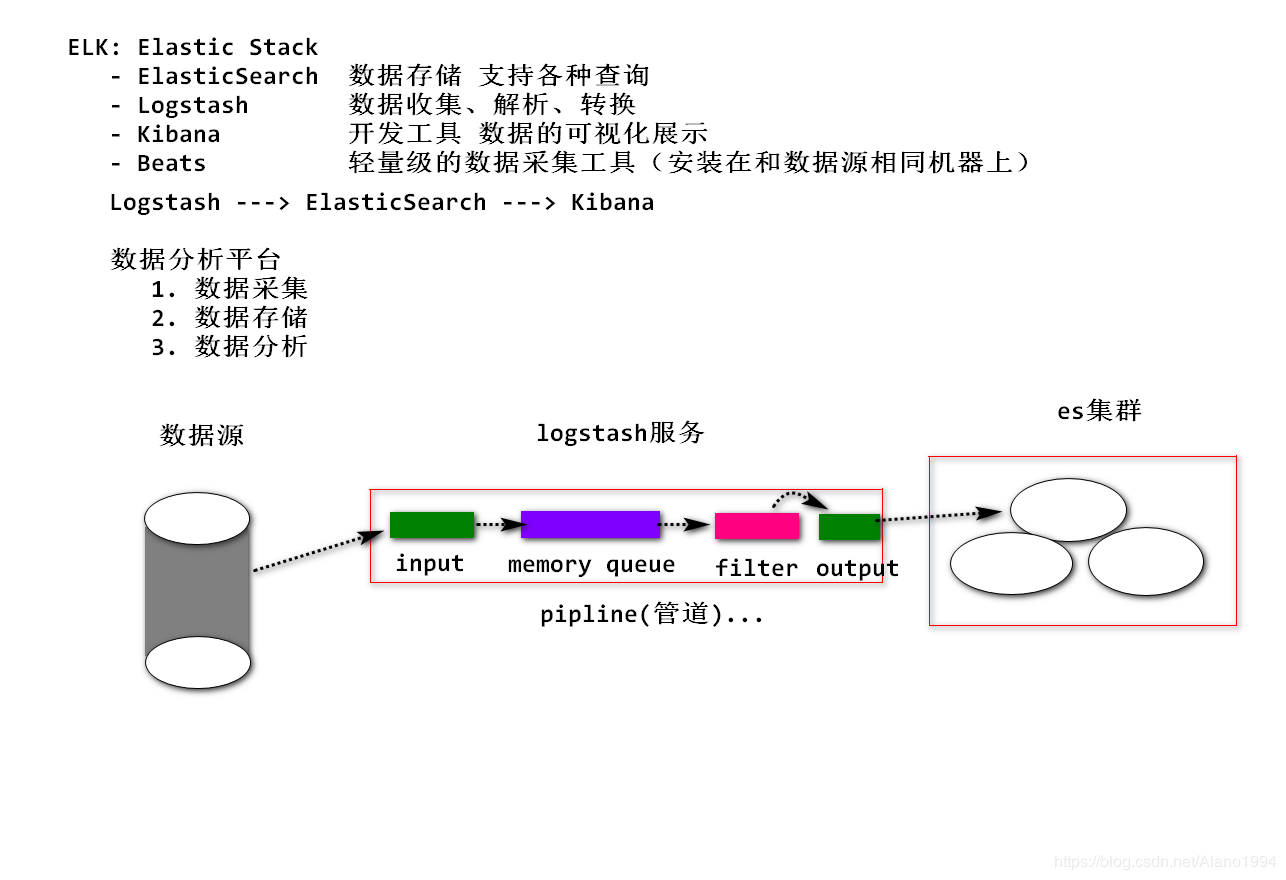
МмЙЙЭМДІРэЙ§ГЬПЩЗжЮЊвЛИіЛђЖрИіЙмЕРЁЃдкУПИіЙмЕРжаЃЌЛсгавЛИіЛђЖрИіЪфШыВхМўНгЪеЛђЪеМЏЪ§ОнЃЌШЛКѓетаЉЪ§ОнЛсМгШыФкВПЖгСаЁЃФЌШЯЧщПіЯТЃЌетаЉЪ§ОнКмЩйВЂЧвЛсДцДЂгкФкДцжаЃЌЕЋЪЧЮЊСЫЬсИпПЩППадКЭЕЏадЃЌвВПЩНјааХфжУвдРЉДѓЙцФЃВЂГЄЦкДцДЂдкДХХЬЩЯЁЃ
ДІРэЯпГЬЛсвдаЁХњСПЕФаЮЪНДгЖгСажаЖСШЁЪ§ОнЃЌВЂЭЈЙ§ШЮКЮХфжУЕФЙ§ТЫВхМўАДЫГађНјааДІРэЁЃLogstash
здДјДѓСПЕФВхМўЃЌФмЙЛТњзуЬиЖЈРраЭЕФВйзїашвЊЃЌвВОЭЪЧНтЮіЁЂДІРэВЂЗсИЛЪ§ОнЕФЙ§ГЬЁЃДІРэЭъЪ§ОнжЎКѓЃЌДІРэЯпГЬЛсНЋЪ§ОнЗЂЫЭЕНЖдгІЕФЪфГіВхМўЃЌетаЉЪфГіВхМўИКд№ЖдЪ§ОнНјааИёЪНЛЏВЂНјвЛВНЗЂЫЭЪ§ОнЃЈР§ШчЗЂЫЭЕН
ElasticsearchЃЉЁЃ
Ш§ЁЂЛљДЁЛЗОГАВзА
аоИФЭјПЈ
vi /etc/sysconfig/network-scripts/ifcfg-ens33
#аоИФЮЊПЊЛњздЖЏЗжХфЭјПЈ
ONBOOT=YES#ЛђепаоИФЮЊОВЬЌip
BOOYPROTO=static
ONBOOT=yes
#ЬэМг
IPADDR=192.168.47.152ЃЈipЕижЗЃЉ
NETMASK=255.255.255.0
GATEWAY=192.168.47.2ЃЈащФтЛњЭјЖЮЃЉ
DNS1=119.29.29.29
DNS2=182.254.116.116 |
жиЦєЭјПЈЗўЮё
| systemctl restart
network |
ЙиБеЗРЛ№ЧН
systemctl stop
firewalld (centos6 : service iptables stop)
systemctl disable firewalld (centos6 : chkconfig
iptables off) |
АВзАgccКЭwget
| yum install gcc-c++
perl-devel pcre-devel openssl-devel zlib-devel
wget |
АВзАjdk
# rpm -ivh jdk-8u181-linux-x64.rpm
ХфжУЛЗОГБфСП(ПЩВЛгУ)
# vi /etc/profile
export JAVA_HOME=/usr/java/latest
export CLASSPATH=.
export PATH=$PATH:$JAVA_HOME/bin
ИќаТзЪдД
# source /etc/profile |
вЛЬЈЗўЮёЦїАВзАnginx
НтбЙnginx
| tar -zxvf nginx-1.11.1.tar.gz |
АВзАnginxЕНжИЖЈТЗОЖ
| ./configure --prefix=/usr/local/nginx |
БрвыАВзА
FilebeatЛЗОГДюНЈ ЃЈКЭnginx АВзАдкЭЌвЛЬЈЗўЮёЦїЩЯЃЉ
АВзА
| [root@localhost
~]# tar -zxvf filebeat-6.4.0-linux-x86_64.tar.gz
-C /usr |
ХфжУ
[root@localhost
~]# mkdir logs
[root@localhost ~]# vim /usr/filebeat-6.4.0-linux-x86_64/filebeat.yml |
ШУbeatШЁЖСШЁnginxЕФШежОЮФМўВЂЧвЪфГіИјlogstashШЁДІРэ
# Change to true
to enable this input configuration.
enabled: true(ДђПЊ)
# Paths that should be crawled and fetched. Glob
based paths.
paths:
- /usr/local/nginx/logs/access*.logЃЈШежОЮФМўЃЉ
# output.elasticsearch:ЃЈЙиБеЃЉ
# Array of hosts to connect to.
# hosts: ["localhost:9200"]
output.logstash:ЃЈДђПЊЃЉ
# The Logstash hosts
hosts: ["192.168.23.143:5044"]ЃЈlogstashЕФipКХФЌШЯ5044ЖЫПкЃЉ |
ЕНnginxАВзАФПТМЦєЖЏnginx
[root@localhost
nginx-1.11.1]# cd /usr/local/nginx/
[root@localhost nginx]# sbin/nginx -c conf/nginx.con |
ЩЯДЋВтЪдЪ§ОнЃЈЗУЮЪnginxЩњГЩШежОЮФМўЃЉ
СэвЛЬЈЗўЮёЦїАВзАlogstash
зЂвтЃКШЮКЮ Logstash ХфжУЖМБиаыжСЩйАќРЈвЛИіЪфШыВхМўКЭвЛИіЪфГіВхМўЁЃЙ§ТЫВхМўЪЧПЩбЁЯюЁЃ
| [root@localhost
~]# tar -zxvf logstash-6.4.0.tar.gz -C /usr |
аоИФХфжУЮФМў
[root@localhost
logstash-6.4.0]# cd /usr/logstash-6.4.0/
[root@localhost logstash-6.4.0]# vim config/simple.conf |
ХфжУЮФМўжаРћгУGrokБэДяЪНРДзЊЛЛШежОЮФМўЮЊjsonДЎ
input {
beats {
port => "5044"
}
}
# Ъ§ОнЙ§ТЫ НтЮі
filter {
grok {
match =>{
"message" => "%{IPORHOST:client_ip}
- %{USER:auth} \[%{HTTPDATE:timestamp}\] \"(?:%
{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\"
%{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:http_referer}
%{QS:http_user_agent}"
}
}
geoip {
source => "client_ip"
}
date {
match => [ "time" , "dd/MMM/YYYY:HH:mm:ss
Z" ]
}
}
# ЪфГіЕНБОЛњЕФ ES
output {
elasticsearch {
hosts => [ "192.168.23.143:9200"
]
index => "logs-%{+YYYY.MM.dd}"
}
} |
ЦєЖЏВтЪд
БЃжЄesМЏШКЕФЗўЮёПЊЦє
ЦєЖЏlogstash
| [root@localhost
logstash-6.4.0]# bin/logstash -r -f config/elk.conf |
ЦєЖЏfilebeat
| [root@localhost
filebeat-6.4.0-linux-x86_64]# ./filebeat |
Ъ§ОнВЩМЏ
ДђПЊkibanaШЁВщПДЩњГЩЕФЫїв§
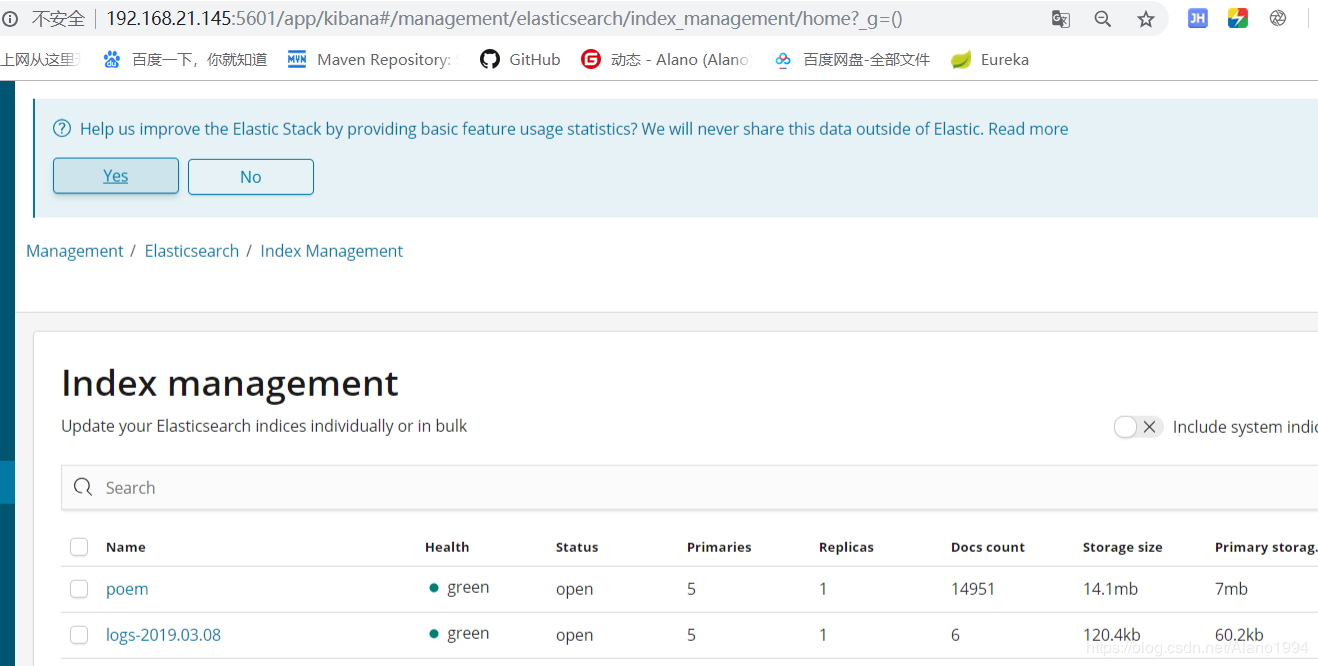
KibanaЪ§ОнПЩЪгЛЏеЙЪО
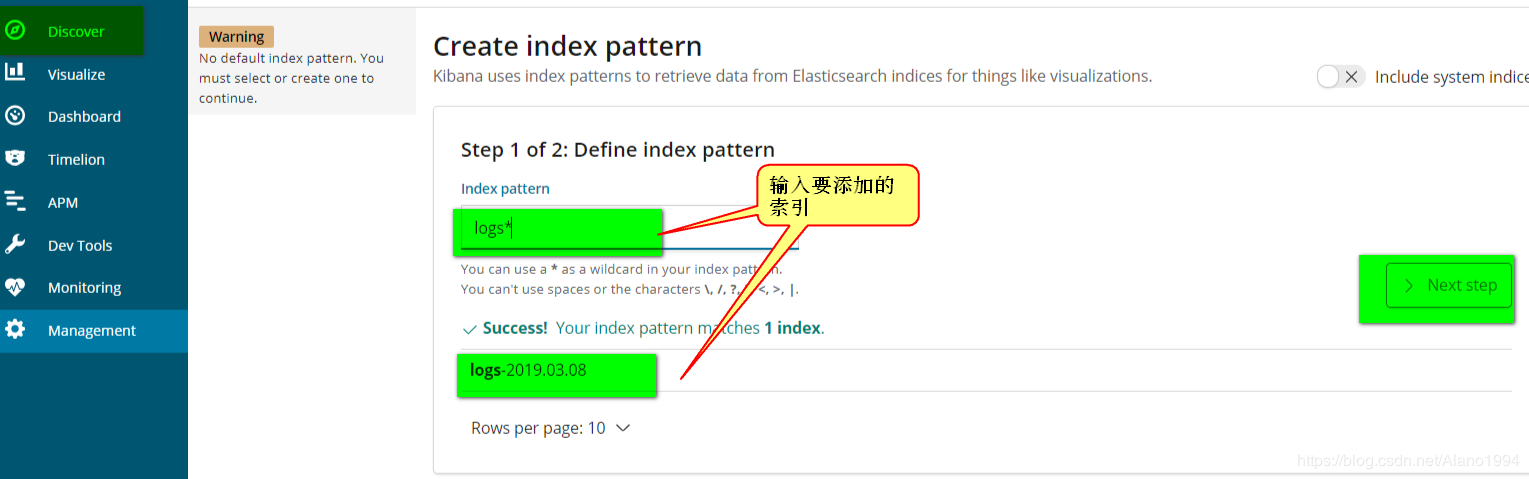
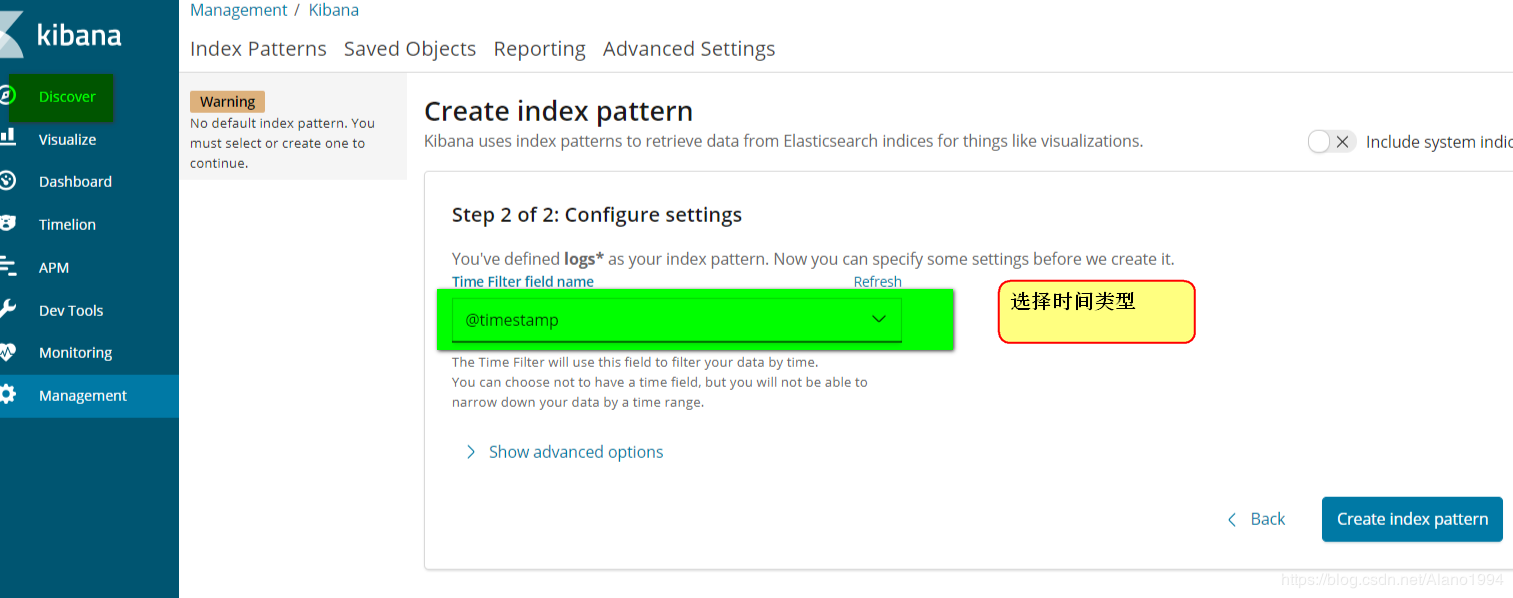
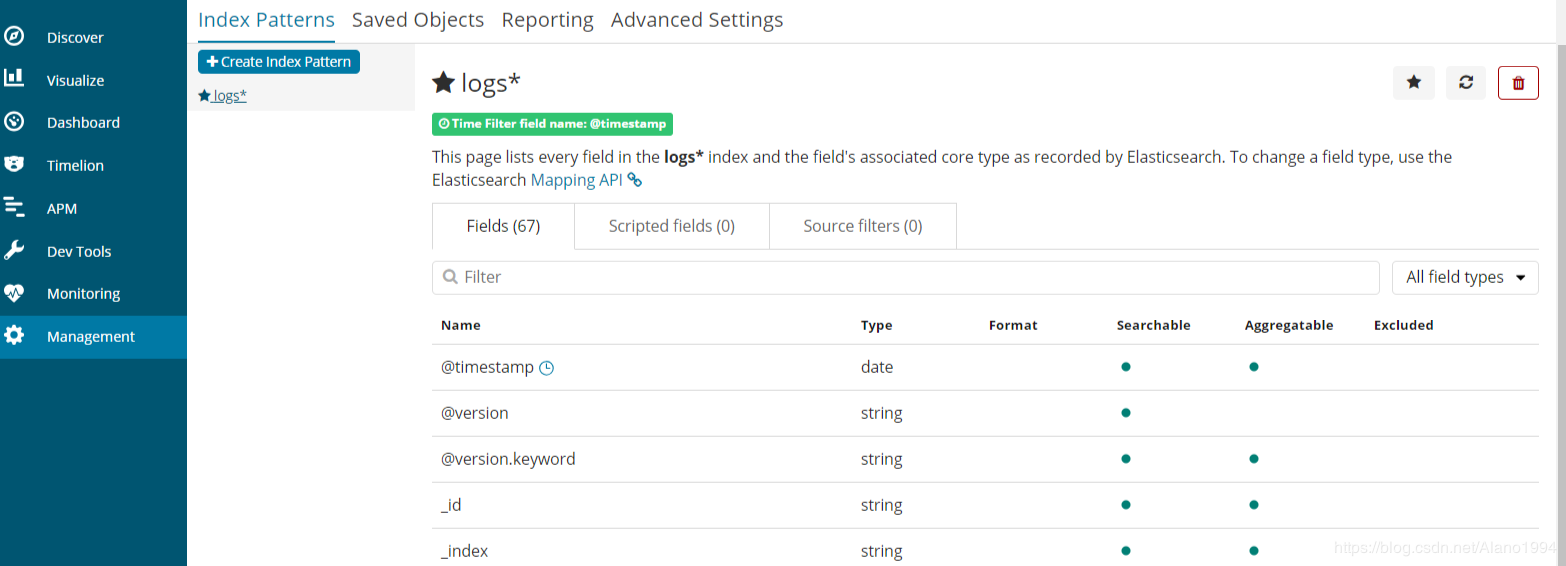
ЬэМгЪгЭМ
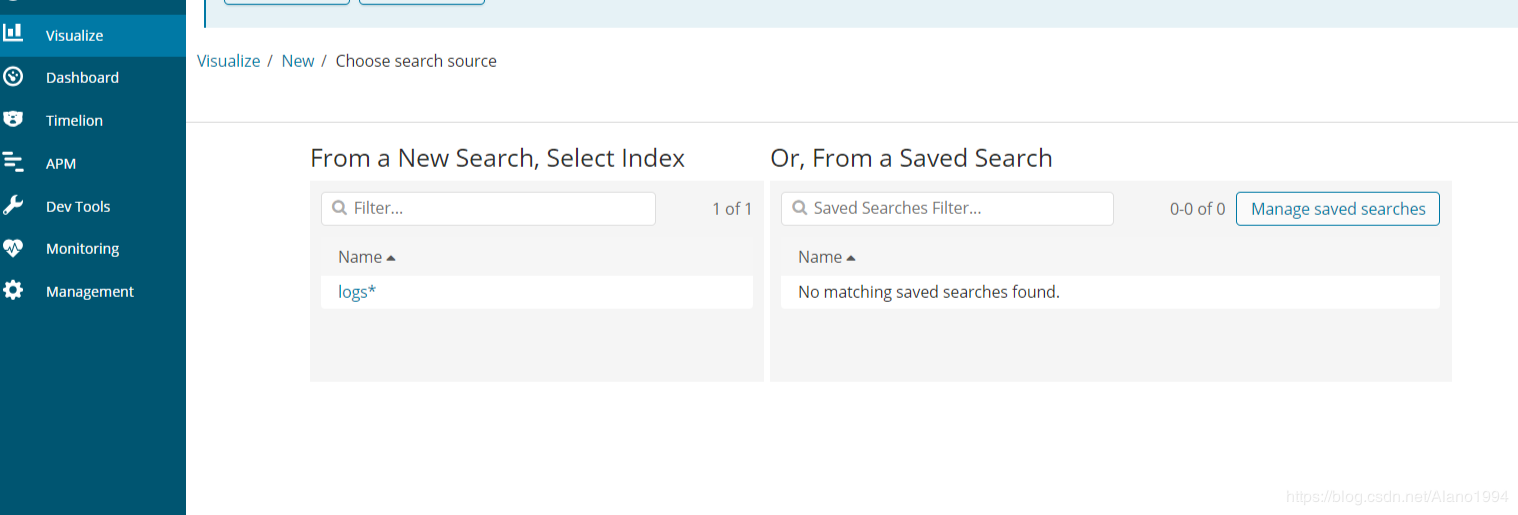
ЬэМгвЧБэХЬ
|









