| БрМЭЦМі: |
БОЮФНщЩмСЫЪ§ОнВжПтКЭHiveЕФИХФюЃЌHiveгыHadoopЩњЬЌЯЕЭГжаЦфЫћзщМўЕФЙиЯЕЃЌHiveЕФгХШБЕуЃЌHiveдкЦѓвЕжаЕФВПЪ№КЭзїгУвдМАHiveЙІФмгыМмЙЙЕШЯрЙиФкШнЁЃ
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўLucaБрМЁЂЭЦМіЁЃ |
|
HiveИХЪі
Ъ§ОнВжПтЕФИХФюЃК
Ъ§ОнВжПтЃЈData WarehouseЃЉЪЧвЛИіУцЯђжїЬтЕФЃЈSubject OrientedЃЉЁЂМЏГЩЕФЃЈIntegratedЃЉЁЂЯрЖдЮШЖЈЕФЃЈNon-VolatileЃЉЁЂЗДгГРњЪЗБфЛЏЃЈTime
VariantЃЉЕФЪ§ОнМЏКЯЃЌгУгкжЇГжЙмРэОіВпЁЃ
ДЋЭГЪ§ОнВжПтУцСйЕФЬєеНЃК
ЮоЗЈТњзуПьЫйдіГЄЕФКЃСПЪ§ОнДцДЂашЧѓЁЃ
ЮоЗЈгааЇДІРэВЛЭЌРраЭЕФЪ§ОнЁЃ
МЦЫуКЭДІРэФмСІВЛзуЁЃ
HiveМђНщЃК
HiveЪЧвЛИіЙЙНЈгкHadoopЖЅВуЕФЪ§ОнВжПтЙЄОпЃЌПЩвдВщбЏКЭЙмРэPBМЖБ№ЕФЗжВМЪНЪ§ОнЁЃ
жЇГжДѓЙцФЃЪ§ОнДцДЂЁЂЗжЮіЃЌОпгаСМКУЕФПЩРЉеЙад
ФГжжГЬЖШЩЯПЩвдПДзїЪЧгУЛЇБрГЬНгПкЃЌБОЩэВЛДцДЂКЭДІРэЪ§ОнЁЃ
вРРЕЗжВМЪНЮФМўЯЕЭГHDFSДцДЂЪ§ОнЁЃ
вРРЕЗжВМЪНВЂааМЦЫуФЃаЭMapReduceДІРэЪ§ОнЁЃ
ЖЈвхСЫМђЕЅЕФРрЫЦSQL ЕФВщбЏгябдЁЊЁЊHiveQLЁЃ
гУЛЇПЩвдЭЈЙ§БраДЕФHiveQLгяОфдЫааMapReduceШЮЮёЁЃ
ПЩвдКмШнвзАбдРДЙЙНЈдкЙиЯЕЪ§ОнПтЩЯЕФЪ§ОнВжПтгІгУГЬађвЦжВЕНHadoopЦНЬЈЩЯЁЃ
ЪЧвЛИіПЩвдЬсЙЉгааЇЁЂКЯРэЁЂжБЙлзщжЏКЭЪЙгУЪ§ОнЕФЗжЮіЙЄОпЁЃ
HiveОпгаЕФЬиЕуЗЧГЃЪЪгУгкЪ§ОнВжПтЁЃ
ЃЈ1ЃЉВЩгУХњДІРэЗНЪНДІРэКЃСПЪ§Он
HiveашвЊАбHiveQLгяОфзЊЛЛГЩMapReduceШЮЮёНјаадЫааЁЃ
Ъ§ОнВжПтДцДЂЕФЪЧОВЬЌЪ§ОнЃЌЖдОВЬЌЪ§ОнЕФЗжЮіЪЪКЯВЩгУХњДІРэЗНЪНЃЌВЛашвЊПьЫйЯьгІИјГіНсЙћЃЌЖјЧвЪ§ОнБОЩэвВВЛЛсЦЕЗББфЛЏЁЃ
ЃЈ2ЃЉЬсЙЉЪЪКЯЪ§ОнВжПтВйзїЕФЙЄОп
HiveБОЩэЬсЙЉСЫвЛЯЕСаЖдЪ§ОнНјаа**ЬсШЁЁЂзЊЛЛЁЂМгдиЃЈETLЃЉ**ЕФЙЄОпЃЌПЩвдДцДЂЁЂВщбЏКЭЗжЮіДцДЂдкHadoopжаЕФДѓЙцФЃЪ§ОнЁЃ
етаЉЙЄОпФмЙЛКмКУЕиТњзуЪ§ОнВжПтИїжжгІгУГЁОАЁЃ
ЃЈ3ЃЉжЇГжMapReduceЃЌTezЃЌSparkЕШЖржжМЦЫув§ЧцЁЃ
ЃЈ4ЃЉПЩвджБНгЗУЮЪHDFSЮФМўвдМАHBaseЁЃ
ЃЈ5ЃЉвзгУвзБрГЬЁЃ
HiveгыHadoopЩњЬЌЯЕЭГжаЦфЫћзщМўЕФЙиЯЕЃК
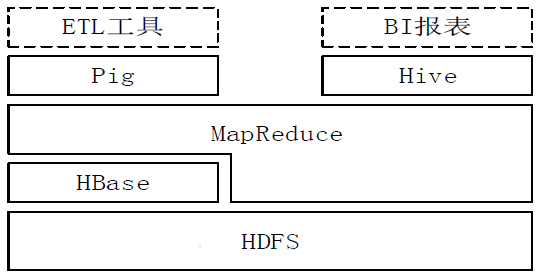
ЭМЃКHadoopЩњЬЌЯЕЭГ
HiveвРРЕгкHDFS ДцДЂЪ§Он
HiveвРРЕгкMapReduce ДІРэЪ§Он
дкФГаЉГЁОАЯТPigПЩвдзїЮЊHiveЕФЬцДњЙЄОп
HBase ЬсЙЉЪ§ОнЕФЪЕЪБЗУЮЪ
HiveЕФгХШБЕуЃК
HiveЕФгХЕуЃК
ИпПЩППЁЂИпШнДэЃКHiveServerВЩгУМЏШКФЃЪНЁЃЫЋMetaStorЁЃГЌЪБжиЪдЛњжЦЁЃ
РрSQLЃКРрЫЦSQLгяЗЈЃЌФкжУДѓСПКЏЪ§ЁЃ
ПЩРЉеЙЃКздЖЈвхДцДЂИёЪНЃЌздЖЈвхКЏЪ§ЁЃ
ЖрНгПкЃКBeelineЃЌJDBCЃЌODBCЃЌPythonЃЌThriftЁЃ
HiveЕФШБЕуЃК
бгГйНЯИпЃКФЌШЯMRЮЊжДаав§ЧцЃЌMRбгГйНЯИпЁЃ
ВЛжЇГжЮэЛЏЪгЭМЃКHiveжЇГжЦеЭЈЪгЭМЃЌВЛжЇГжЮэЛЏЪгЭМЁЃHiveВЛФмдйЪгЭМЩЯИќаТЁЂВхШыЁЂЩОГ§Ъ§ОнЁЃ
ВЛЪЪгУOLTPЃКднВЛжЇГжСаМЖБ№ЕФЪ§ОнЬэМгЁЂИќаТЁЂЩОГ§ВйзїЁЃ
днВЛжЇГжДцДЂЙ§ГЬЃКЕБЧААцБОВЛжЇГжДцДЂЙ§ГЬЃЌжЛФмЭЈЙ§UDFРДЪЕЯжвЛаЉТпМДІРэЁЃ
HiveгыДЋЭГЪ§ОнПтЕФЖдБШЗжЮіЃК
HiveдкКмЖрЗНУцКЭДЋЭГЕФЙиЯЕЪ§ОнПтРрЫЦЃЌЕЋЪЧЫќЕФЕзВувРРЕЕФЪЧHDFSКЭMapReduceЃЌЫљвддкКмЖрЗНУцгжгаБ№гкДЋЭГЪ§ОнПтЁЃ
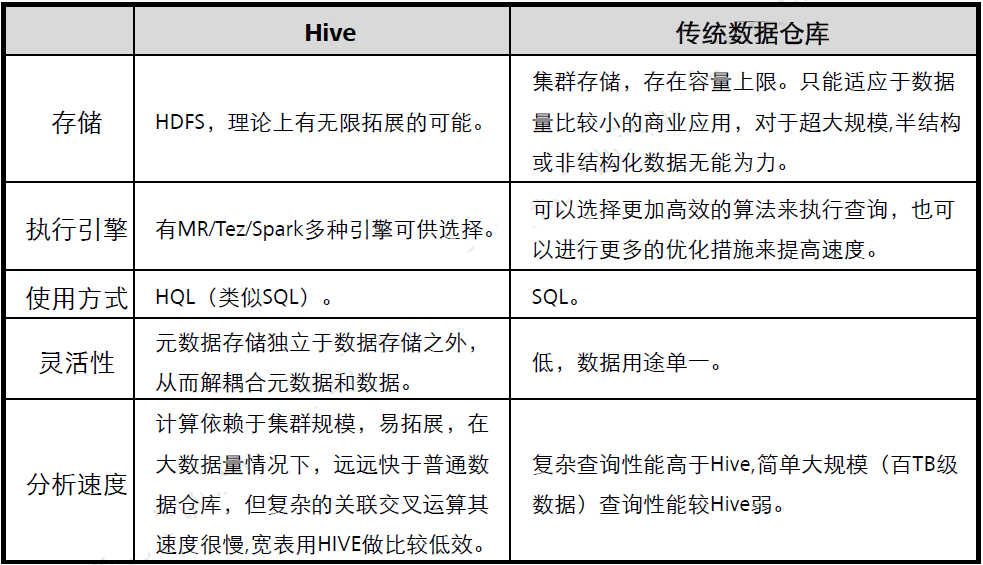
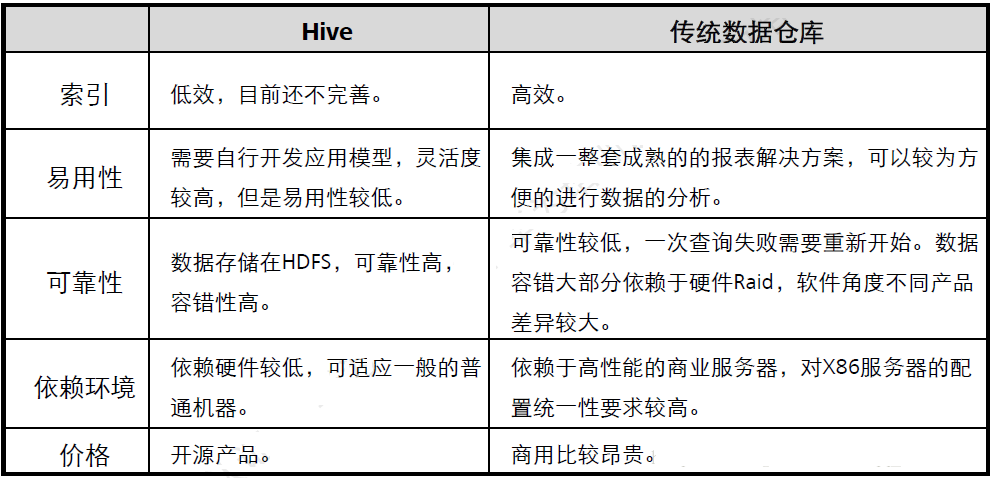
HiveдкЦѓвЕжаЕФВПЪ№КЭзїгУЃК
HiveдкЦѓвЕДѓЪ§ОнЗжЮіЦНЬЈжаЕФгІгУЃК
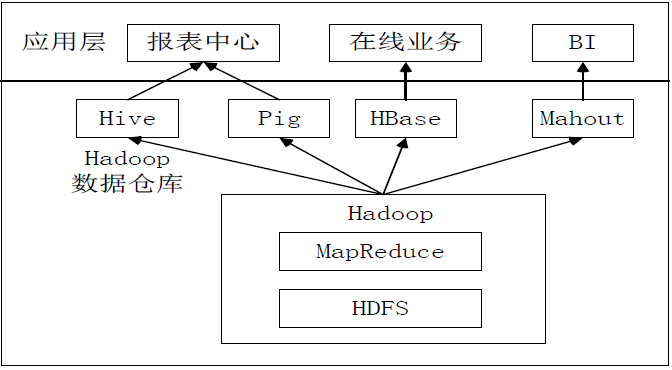
ЭМЃКЦѓвЕжавЛжжГЃМћЕФДѓЪ§ОнЗжЮіЦНЬЈВПЪ№ПђМм
HiveдкFacebookЙЋЫОжаЕФгІгУЃК
ЛљгкOracleЕФЪ§ОнВжПтЯЕЭГвбОЮоЗЈТњзуМЄдіЕФвЕЮёашЧѓ
FacebookЙЋЫОПЊЗЂСЫЪ§ОнВжПтЙЄОпHiveЃЌВЂдкЦѓвЕФкВПНјааСЫДѓСПВПЪ№
HiveдкFusionInsightжаЕФЮЛжУЃК
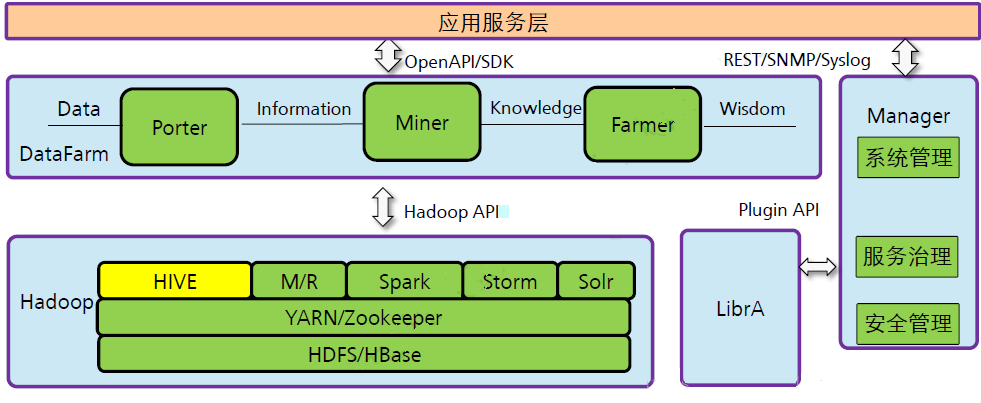
ЭМЃКHiveдкFusionInsightжаЕФЮЛжУ
HiveЪЧвЛжжЪ§ОнВжПтДІРэЙЄОпЃЌЪЙгУРрSQLЕФHiveQLгябдЪЕЯжЪ§ОнВщбЏЙІФмЃЌЫљгаЕФHiveЪ§ОнЖМДцДЂдкHDFSжаЁЃ
HiveгІгУГЁОАЃК
Ъ§ОнЭкОђЃКгУЛЇааЮЊЗжЮіЃЛаЫШЄЗжЧјЃЛЧјгђеЙЪОЃЛ
ЗЧЪЕЪБЗжЮіЃКШежОЗжЮіЃЛЮФБОЗжЮіЁЃ
Ъ§ОнЛузмЃКУПЬь/УПжмгУЛЇЕуЛїЪ§ЃЌСїСПЭГМЦЁЃ
Ъ§ОнВжПтЃКЪ§ОнГщШЁЃЌМгдиЃЌзЊЛЛЃЈETLЃЉЁЃ
HiveЙІФмгыМмЙЙ
HiveЯЕЭГМмЙЙЃК
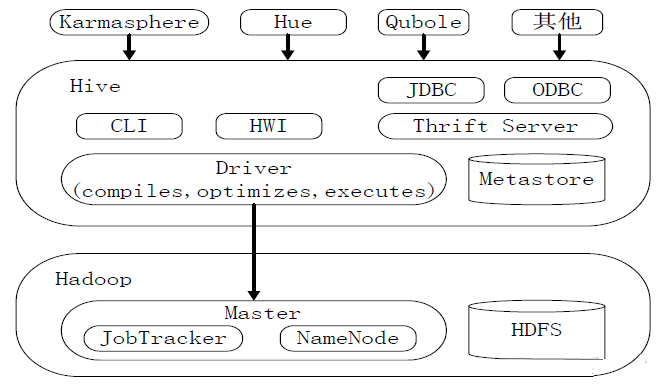
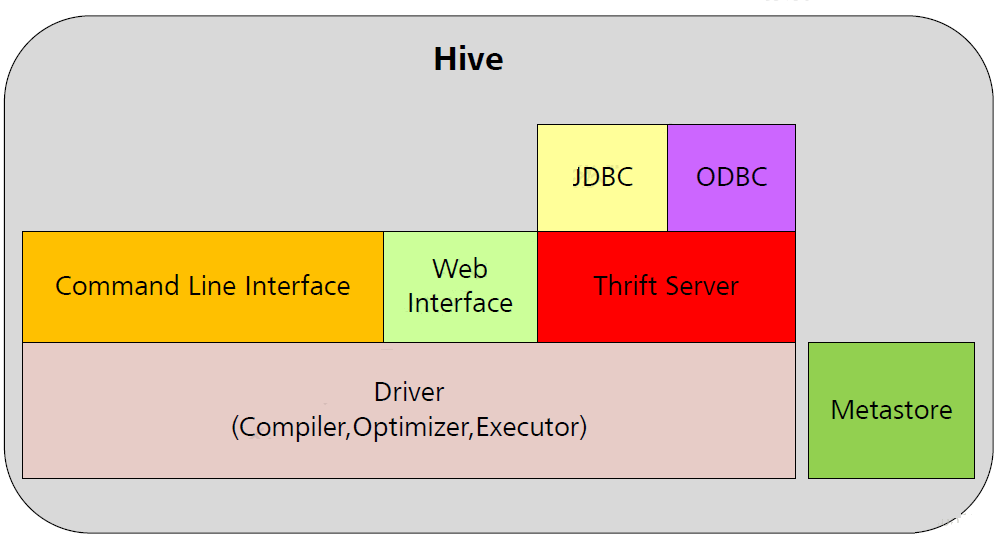
ЭМЃКHiveЯЕЭГМмЙЙ
гУЛЇНгПкФЃПщАќРЈCLIЁЂHWIЁЂJDBCЁЂODBCЁЂThrift ServerЁЃ
Ч§ЖЏФЃПщЃЈDriverЃЉАќРЈБрвыЦїЁЂгХЛЏЦїЁЂжДааЦїЕШЃЌИКд№АбHiveSQLгяОфзЊЛЛГЩвЛЯЕСаMapReduceзївЕЁЃ
дЊЪ§ОнДцДЂФЃПщЃЈMetastoreЃЉЪЧвЛИіЖРСЂЕФЙиЯЕаЭЪ§ОнПтЃЈздДјderbyЪ§ОнПтЃЌЛђMySQLЪ§ОнПтЃЉЁЃ
FusionInsight HDжаHiveЕФМмЙЙЃК
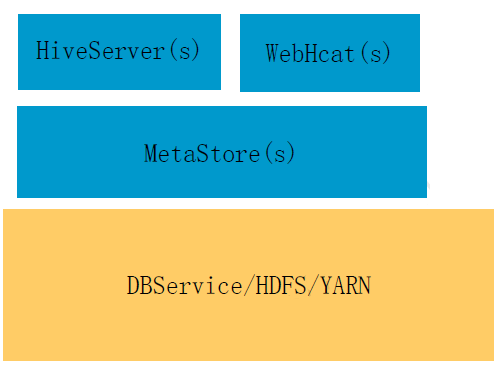
ЭМЃКFusionInsightжаHiveЕФМмЙЙ
HiveЗжЮЊШ§ИіНЧЩЋЃКHiveServerЁЂMetaStoreЁЂWebHcatЁЃ
HiveServerЃКНЋгУЛЇЬсНЛЕФHQLгяОфНјааБрвыЃЌНтЮіГЩЖдгІЕФYarnШЮЮёЃЌSparkШЮЮёЛђепHDFSВйзїЃЌДгЖјЭъГЩЪ§ОнЕФЬсШЁЃЌзЊЛЛЃЌЗжЮіЁЃ
MetaStroeЃКЬсЙЉдЊЪ§ОнЗўЮёЁЃ
WebHcatЃКЖдЭтЬсЙЉЛљгкHtppsЯДвТЕФдЊЪ§ОнЗУЮЪЁЂDDLВщбЏЕШЗўЮёЁЃ
HCatalogМмЙЙЃК
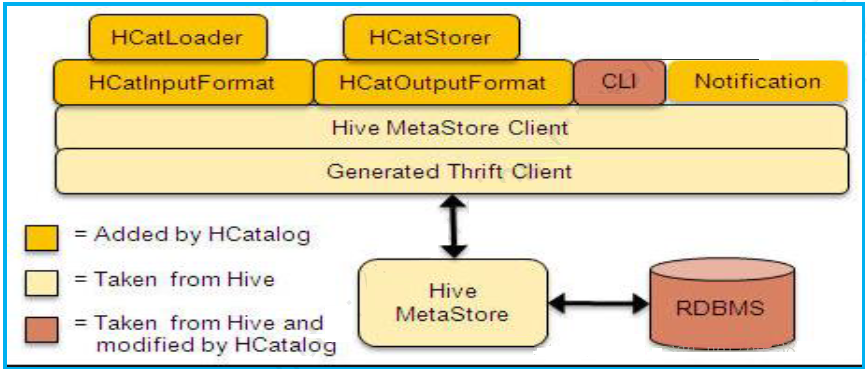
ЭМЃКHCatalogМмЙЙ
HCatalogАќРЈHcatalog ClientКЭHcatalog ServerЃК
HCatalog CLientАќРЈУќСюааЙЄОпCLIКЭClent jarАќЃЈгУгкИјPigЃЌ MRЬсЙЉдЊЪ§ОнЖСаДжЇГжЃЉЁЃ
HCatalogЭЈЙ§HiveЬсЙЉЕФHiveMetaStoreClentЖдЯѓРДМфНгЗУЮЪMetaStoreЁЃ
HCatalogЖдЭтЬсЙЉHcatloaderЃЌHCatinputFormatРДЖСШЁЪ§ОнЃЛЬсЙЉHCatStore,HCatOutputFormatРДаДШыЪ§ОнЁЃ
WebHCatМмЙЙЃК
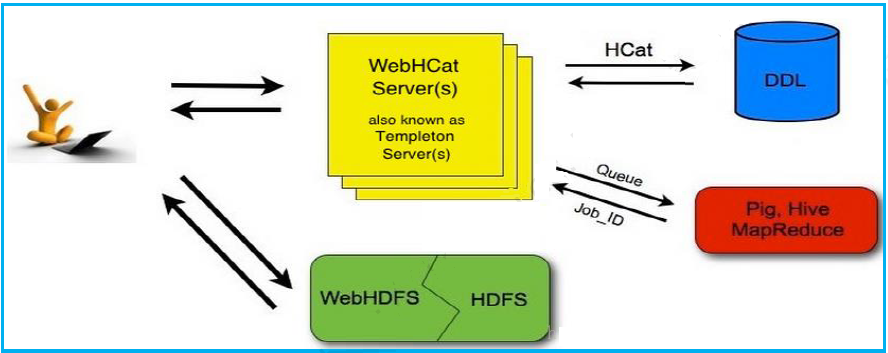
ЭМЃКWebHCatМмЙЙ
WebHCatЬсЙЉRestНгПкЃЌЪЧгУЛЇФмЙЛЭЈЙ§АВШЋЕФHTTPSавщжДаавдЯТВйзїЃК
жДааHive DDLВйзїЁЃ
дЫааHive HQLШЮЮёЁЃ
дЫааMapReduceШЮЮёЁЃ
HiveЪ§ОнДцДЂФЃаЭЃК
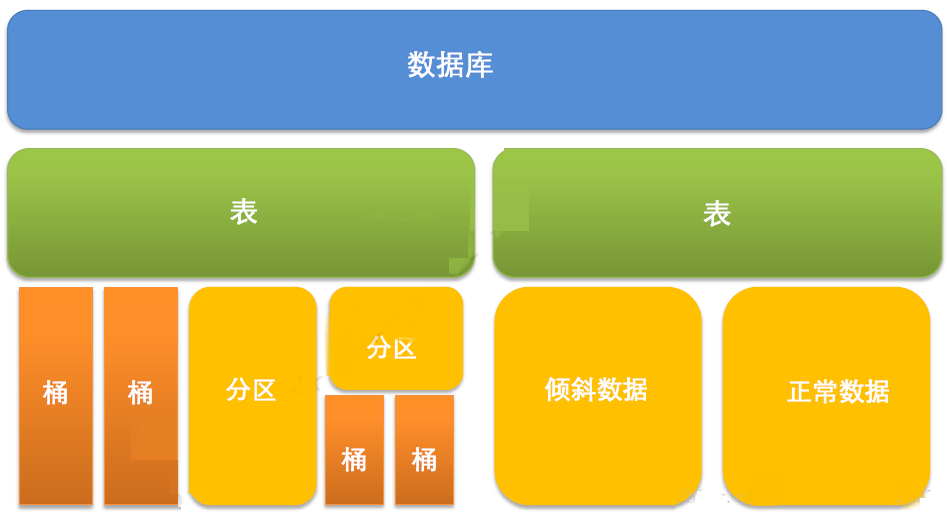
ЭМЃКHiveЪ§ОнДцДЂФЃаЭ
ЗжЧјЃКЪ§ОнБэПЩвдАДееФГИізжЖЮЕФжЕЛЎЗжЗжЧјЁЃ
УПИіЗжЧјЪЧвЛИіФПТМЁЃ
ЗжЧјЪ§СПВЛЙЬЖЈЁЃ
ЗжЧјЯТПЩдйгаЗжЧјЛђепЭАЁЃ
ЭАЃКЪ§ОнПЩвдИљОнЭАЕФЗНЪННЋВЛЭЌЪ§ОнЗХШыВЛЭЌЕФЭАжаЁЃ
УПИіЭАЪЧвЛИіЮФМўЁЃ
НЈБэЪБжИЖЈЭАИіЪ§ЃЌЭАФкПЩХХађЁЃ
Ъ§ОнАДееФГИізжЖЮЕФжЕHashКѓЗХШыФГИіЭАжаЁЃ
HiveПЩвдДДНЈЭаЙмБэКЭЭтВПБэЃК
ФЌШЯДДНЈЭаЙмБэЃЌHivaЛсНЋЪ§ОнвЦЖЏЕНЪ§ОнВжПтЕФФПТМЁЃ
ДДНЈЭтВПБэЃЌетЪБHivaЛсЕНВжПтФПТМвдЭтЕФЮЛжУЗУЮЪЪ§ОнЁЃ
ШчЙћЫљгаДІРэЖМгЩHiveЭъГЩЃЌНЈвщЪЙгУЭаЙмБэЁЃ
ШчЙћвЊгУHiveКЭЦфЫћЙЄОпРДДІРэЭЌвЛИіЪ§ОнМЏЃЌНЈвщЪЙгУЭтВПБэЁЃ

HiveжЇГжЕФКЏЪ§ЃК
HiveФкжУКЏЪ§ЃК
Ъ§ОнКЏЪ§ЃКШчround(),fllor(), abs(), rand()ЕШЁЃ
ШеЦкКЏЪ§ЃКШчto_date(), month(), day().
зжЗћДЎКЏЪ§,Шчtrim(), length(), substr()ЕШЁЃ
UDFЃЈUser-Defined FuncationЃЉгУЛЇздЖЈвхКЏЪ§ЁЃ
HiveЙЄзїдРэЃК
ЃЈ1ЃЉSQLгяОфзЊЛЛГЩMapReduceзївЕЕФЛљБОдРэЃК
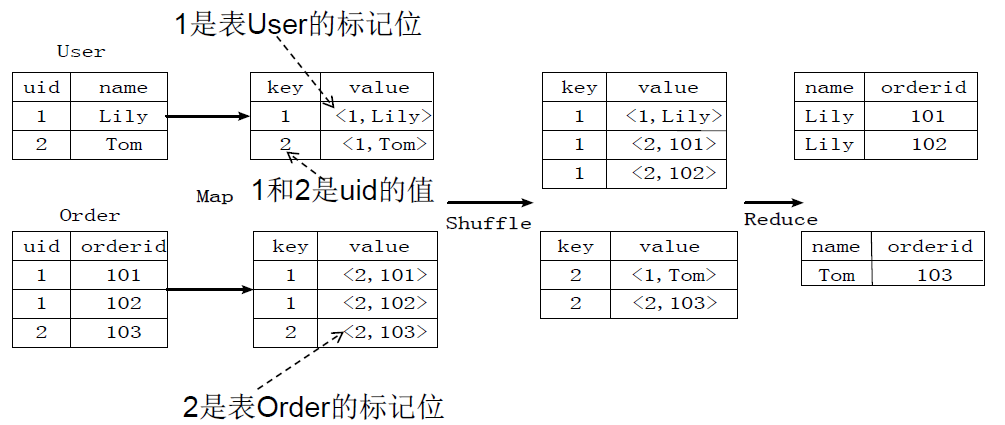
ЭМЃКjoinЕФЪЕЯждРэ
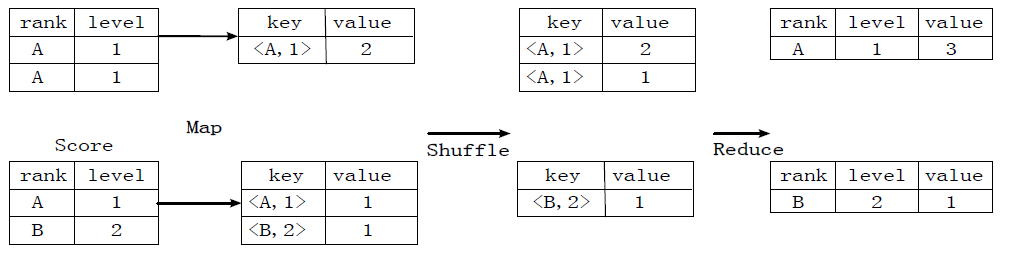
ЭМЃКgroup byЪЕЯждРэ
ДцдквЛИіЗжзщЃЈGroup ByЃЉВйзїЃЌЦфЙІФмЪЧАбБэScoreЕФВЛЭЌЦЌЖЮАДееrankКЭlevelЕФзщКЯжЕНјааКЯВЂЃЌМЦЫуВЛЭЌrankКЭlevelЕФзщКЭжЕЗжБ№гаМИЬѕМЧТМЁЃ
ЃЈ2ЃЉHiveжаSQLВщбЏзЊЛЛГЩMapReduceзїгУЕФЙ§ГЬЃК
ЕБгУЛЇЯђHiveЪфШывЛЖЮУќСюЛђВщбЏЪБЃЌHiveашвЊгыHadoopНЛЛЅЙЄзїРДЭъГЩИУВйзїЃК
Ч§ЖЏФЃПщНгЪеИУУќСюЛђВщбЏБрвыЦї
ЖдИУУќСюЛђВщбЏНјааНтЮіБрвы
гЩгХЛЏЦїЖдИУУќСюЛђВщбЏНјаагХЛЏМЦЫу
ИУУќСюЛђВщбЏЭЈЙ§жДааЦїНјаажДаа
ЯъЯИШчЙћШчЯТЃК
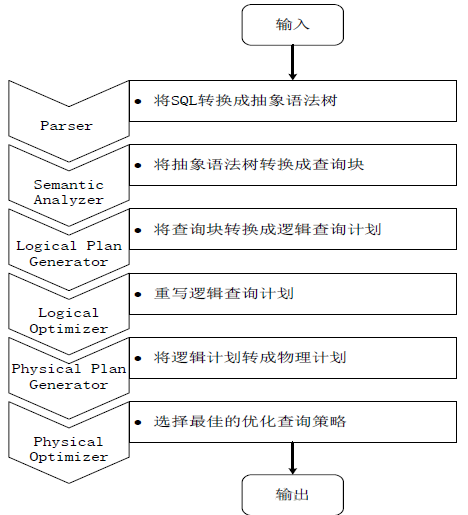
ЭМЃКSQLВщбЏзЊЛЛГЩMapReduceзївЕЕФЙ§ГЬ
Ек1ВНЃКгЩHiveЧ§ЖЏФЃПщжаЕФБрвыЦїЖдгУЛЇЪфШыЕФSQLгябдНјааДЪЗЈКЭгяЗЈНтЮіЃЌНЋSQLгяОфзЊЛЏЮЊГщЯѓгяЗЈЪїЕФаЮЪНЁЃ
Ек2ВНЃКГщЯѓгяЗЈЪїЕФНсЙЙШдКмИДдгЃЌВЛЗНБужБНгЗвыЮЊMapReduceЫуЗЈГЬађЃЌвђДЫЃЌАбГщЯѓгяЗЈЪщзЊЛЏЮЊВщбЏПщЁЃ
Ек3ВНЃКАбВщбЏПщзЊЛЛГЩТпМВщбЏМЦЛЎЃЌРяУцАќКЌСЫаэЖрТпМВйзїЗћЁЃ
Ек4ВНЃКжиаДТпМВщбЏМЦЛЎЃЌНјаагХЛЏЃЌКЯВЂЖргрВйзїЃЌМѕЩйMapReduceШЮЮёЪ§СПЁЃ
Ек5ВНЃКНЋТпМВйзїЗћзЊЛЛГЩашвЊжДааЕФОпЬхMapReduceШЮЮёЁЃ
Ек6ВНЃКЖдЩњГЩЕФMapReduceШЮЮёНјаагХЛЏЃЌЩњГЩзюжеЕФMapReduceШЮЮёжДааМЦЛЎЁЃ
Ек7ВНЃКгЩHiveЧ§ЖЏФЃПщжаЕФжДааЦїЃЌЖдзюжеЕФMapReduceШЮЮёНјаажДааЪфГіЁЃ
МИЕуЫЕУїЃК
ЕБЦєЖЏMapReduceГЬађЪБЃЌHiveБОЩэЪЧВЛЛсЩњГЩMapReduceЫуЗЈГЬађЕФЁЃ
ашвЊЭЈЙ§вЛИіБэЪОЁАJobжДааМЦЛЎЁБЕФXMLЮФМўЧ§ЖЏжДааФкжУЕФЁЂдЩњЕФMapperКЭReducerФЃПщЁЃ
HiveЭЈЙ§КЭJobTrackerЭЈаХРДГѕЪМЛЏMapReduceШЮЮёЃЌВЛБижБНгВПЪ№дкJobTrackerЫљдкЕФЙмРэНкЕуЩЯжДааЁЃ
ЭЈГЃдкДѓаЭМЏШКЩЯЃЌЛсгазЈУХЕФЭјЙиЛњРДВПЪ№HiveЙЄОпЁЃЭјЙиЛњЕФзїгУжївЊЪЧдЖГЬВйзїКЭЙмРэНкЕуЩЯЕФJobTrackerЭЈаХРДжДааШЮЮёЁЃ
Ъ§ОнЮФМўЭЈГЃДцДЂдкHDFSЩЯЃЌHDFSгЩУћГЦНкЕуЙмРэЁЃ
#HiveдіЧПЬиад
HiveдіЧПЬиад-ColocationЃК
ColocationЃЈЭЌЗжВМЃЉЃКНЋДцдкЙиСЊЙиЯЕЕФЪ§ОнЛђПЩФмНјааЙмРэВйзїЕФЪ§ОнДцДЂдкЯрЭЌЕФДцДЂНкЕуЩЯЁЃ
ЮФМўМЖЭЌЗжВМЪЕЯжЮФМўЕФПьЫйЗУЮЪЃЌБмУтСЫвђЪ§ОнАсЧЈДјРДЕФДѓСПЭјТчПЊЯњЁЃ
HiveдіЧПЬиадЈCHbaseМЧТМХњСПЩОГ§ЃК
дкHive on HBaseЙІФмЛузмЃЌFusionInsight HD HiveЬсЙЉСЫЖдHBaseБэЕФЕЅЬѕЪ§ОнЕФЩОГ§ЙІФмЃЌЭЈЙ§ЬиЖЈЕФгяЗЈЃЌHiveПЩвдНЋHBaseБэжаЗћКЯЬѕМўЕФвЛЬѕЛђЖрЬѕЪ§ОнХњСПЧхГ§ЁЃ
HiveдіЧПЬиадЈCСїПиЬиадЃК
ЭЈЙ§СїПиЬиадЃЌПЩвдЪЕЯжЃК
ЕБЧАвбОНЈСЂСЌНгЪ§ОнуажЕПижЦЁЃ
УПИігУЛЇвбОНЈСЂЕФСЌНгЪ§уажЕПижЦЁЃ
ЕЅЮЛЪБМфФкЫљгаНЈСЂЕФСЌНгЪ§уажЕПижЦЁЃ |









