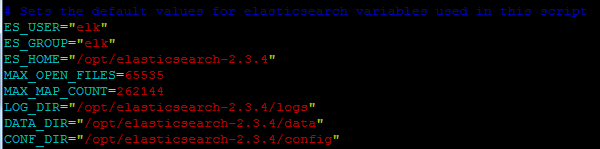
| БрМЭЦМі: |
БОЮФЪзЯШМђвЊНщЩмСЫ
ELK авщеЛЕФМИжжЕфаЭЕФМмЙЙМАЦфЪЙгУГЁОАЃЌШЛКѓеыЖд Filebeat ЕФМмЙЙЃЌЯъЯИЫЕУїСЫШчКЮАВзАКЭХфжУЕШЕШЃЌЯЃЭћЖдФњгаЫљАяжњ
БОЮФРДздгкIBMЃЌгЩЛ№СњЙћШэМўDeloresБрМЁЂЭЦМіЁЃ |
|
ELK Stack МђНщ
ELK ВЛЪЧвЛПюШэМўЃЌЖјЪЧ ElasticsearchЁЂLogstash КЭ Kibana Ш§жжШэМўВњЦЗЕФЪззжФИЫѕаДЁЃетШ§епЖМЪЧПЊдДШэМўЃЌЭЈГЃХфКЯЪЙгУЃЌЖјЧвгжЯШКѓЙщгк Elastic.co ЙЋЫОУћЯТЃЌЫљвдБЛМђГЦЮЊ ELK StackЁЃИљОн Google Trend ЕФаХЯЂЯдЪОЃЌELK Stack вбОГЩЮЊФПЧАзюСїааЕФМЏжаЪНШежОНтОіЗНАИЁЃ
ElasticsearchЃКЗжВМЪНЫбЫїКЭЗжЮів§ЧцЃЌОпгаИпПЩЩьЫѕЁЂИпПЩППКЭвзЙмРэЕШЬиЕуЁЃЛљгк Apache Lucene ЙЙНЈЃЌФмЖдДѓШнСПЕФЪ§ОнНјааНгНќЪЕЪБЕФДцДЂЁЂЫбЫїКЭЗжЮіВйзїЁЃЭЈГЃБЛгУзїФГаЉгІгУЕФЛљДЁЫбЫїв§ЧцЃЌЪЙЦфОпгаИДдгЕФЫбЫїЙІФмЃЛ
LogstashЃКЪ§ОнЪеМЏв§ЧцЁЃЫќжЇГжЖЏЬЌЕФДгИїжжЪ§ОндДЫбМЏЪ§ОнЃЌВЂЖдЪ§ОнНјааЙ§ТЫЁЂЗжЮіЁЂЗсИЛЁЂЭГвЛИёЪНЕШВйзїЃЌШЛКѓДцДЂЕНгУЛЇжИЖЈЕФЮЛжУЃЛ
KibanaЃКЪ§ОнЗжЮіКЭПЩЪгЛЏЦНЬЈЁЃЭЈГЃгы Elasticsearch ХфКЯЪЙгУЃЌЖдЦфжаЪ§ОнНјааЫбЫїЁЂЗжЮіКЭвдЭГМЦЭМБэЕФЗНЪНеЙЪОЃЛ
FilebeatЃКELK авщеЛЕФаТГЩдБЃЌвЛИіЧсСПМЖПЊдДШежОЮФМўЪ§ОнЫбМЏЦїЃЌЛљгк Logstash-Forwarder дДДњТыПЊЗЂЃЌЪЧЖдЫќЕФЬцДњЁЃдкашвЊВЩМЏШежОЪ§ОнЕФ server ЩЯАВзА FilebeatЃЌВЂжИЖЈШежОФПТМЛђШежОЮФМўКѓЃЌFilebeat ОЭФмЖСШЁЪ§ОнЃЌбИЫйЗЂЫЭЕН Logstash НјааНтЮіЃЌврЛђжБНгЗЂЫЭЕН Elasticsearch НјааМЏжаЪНДцДЂКЭЗжЮіЁЃ
ШчЙћФњЖд ELK Stack ЛЙЩаВЛСЫНтЃЌЛђЪЧЯыСЫНтИќЖрЃЌЧыЕуЛїМЏжаЪНШежОЯЕЭГ ELK авщеЛЯъНтЃЌВщПДОпЬхНщЩмЁЃ
ELK ГЃгУМмЙЙМАЪЙгУГЁОАНщЩм
дкетИіеТНкжаЃЌЮвУЧНЋНщЩмМИжжГЃгУМмЙЙМАЪЙгУГЁОАЁЃ
зюМђЕЅМмЙЙ
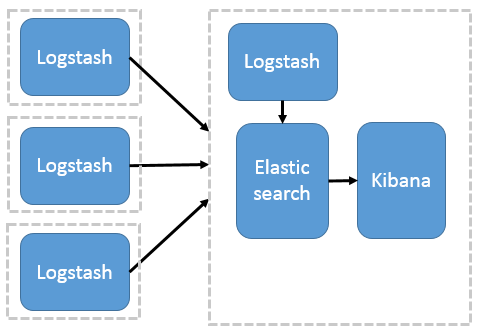
дкетжжМмЙЙжаЃЌжЛгавЛИі LogstashЁЂElasticsearch КЭ Kibana ЪЕР§ЁЃLogstash ЭЈЙ§ЪфШыВхМўДгЖржжЪ§ОндДЃЈБШШчШежОЮФМўЁЂБъзМЪфШы Stdin ЕШЃЉЛёШЁЪ§ОнЃЌдйОЙ§ТЫВхМўМгЙЄЪ§ОнЃЌШЛКѓО Elasticsearch ЪфГіВхМўЪфГіЕН ElasticsearchЃЌЭЈЙ§ Kibana еЙЪОЁЃЯъМћЭМ 1ЁЃ
ЭМ 1. зюМђЕЅМмЙЙ

етжжМмЙЙЗЧГЃМђЕЅЃЌЪЙгУГЁОАвВгаЯоЁЃГѕбЇепПЩвдДюНЈетИіМмЙЙЃЌСЫНт ELK ШчКЮЙЄзїЁЃ
Logstash зїЮЊШежОЫбМЏЦї
етжжМмЙЙЪЧЖдЩЯУцМмЙЙЕФРЉеЙЃЌАбвЛИі Logstash Ъ§ОнЫбМЏНкЕуРЉеЙЕНЖрИіЃЌЗжВМгкЖрЬЈЛњЦїЃЌНЋНтЮіКУЕФЪ§ОнЗЂЫЭЕН Elasticsearch server НјааДцДЂЃЌзюКѓдк Kibana ВщбЏЁЂЩњГЩШежОБЈБэЕШЁЃЯъМћЭМ 2ЁЃ
ЭМ 2. Logstash зїЮЊШежОЫбЫїЦї
етжжНсЙЙвђЮЊашвЊдкИїИіЗўЮёЦїЩЯВПЪ№ LogstashЃЌЖјЫќБШНЯЯћКФ CPU КЭФкДцзЪдДЃЌЫљвдБШНЯЪЪКЯМЦЫузЪдДЗсИЛЕФЗўЮёЦїЃЌЗёдђШнвздьГЩЗўЮёЦїадФмЯТНЕЃЌЩѕжСПЩФмЕМжТЮоЗЈе§ГЃЙЄзїЁЃ
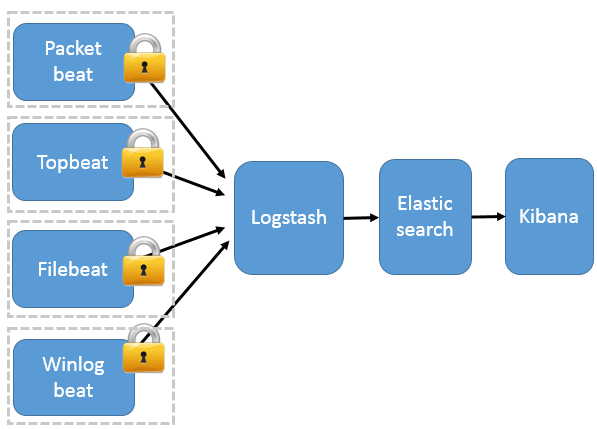
Beats зїЮЊШежОЫбМЏЦї
етжжМмЙЙв§Шы Beats зїЮЊШежОЫбМЏЦїЁЃФПЧА Beats АќРЈЫФжжЃК
PacketbeatЃЈЫбМЏЭјТчСїСПЪ§ОнЃЉЃЛ
TopbeatЃЈЫбМЏЯЕЭГЁЂНјГЬКЭЮФМўЯЕЭГМЖБ№ЕФ CPU КЭФкДцЪЙгУЧщПіЕШЪ§ОнЃЉЃЛ
FilebeatЃЈЫбМЏЮФМўЪ§ОнЃЉЃЛ
WinlogbeatЃЈЫбМЏ Windows ЪТМўШежОЪ§ОнЃЉЁЃ
Beats НЋЫбМЏЕНЕФЪ§ОнЗЂЫЭЕН LogstashЃЌО Logstash НтЮіЁЂЙ§ТЫКѓЃЌНЋЦфЗЂЫЭЕН Elasticsearch ДцДЂЃЌВЂгЩ Kibana ГЪЯжИјгУЛЇЁЃЯъМћЭМ 3ЁЃ
ЭМ 3. Beats зїЮЊШежОЫбМЏЦї
етжжМмЙЙНтОіСЫ Logstash дкИїЗўЮёЦїНкЕуЩЯеМгУЯЕЭГзЪдДИпЕФЮЪЬтЁЃЯрБШ LogstashЃЌBeats ЫљеМЯЕЭГЕФ CPU КЭФкДцМИКѕПЩвдКіТдВЛМЦЁЃСэЭтЃЌBeats КЭ Logstash жЎМфжЇГж SSL/TLS МгУмДЋЪфЃЌПЭЛЇЖЫКЭЗўЮёЦїЫЋЯђШЯжЄЃЌБЃжЄСЫЭЈаХАВШЋЁЃ
вђДЫетжжМмЙЙЪЪКЯЖдЪ§ОнАВШЋадвЊЧѓНЯИпЃЌЭЌЪБИїЗўЮёЦїадФмБШНЯУєИаЕФГЁОАЁЃ
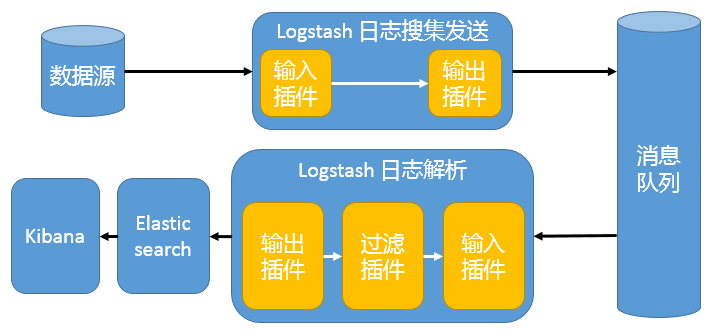
в§ШыЯћЯЂЖгСаЛњжЦЕФМмЙЙ
ЕНБЪепећРэБОЮФЪБЃЌBeats ЛЙВЛжЇГжЪфГіЕНЯћЯЂЖгСаЃЌЫљвддкЯћЯЂЖгСаЧАКѓСНЖЫжЛФмЪЧ Logstash ЪЕР§ЁЃетжжМмЙЙЪЙгУ Logstash ДгИїИіЪ§ОндДЫбМЏЪ§ОнЃЌШЛКѓОЯћЯЂЖгСаЪфГіВхМўЪфГіЕНЯћЯЂЖгСажаЁЃФПЧА Logstash жЇГж KafkaЁЂRedisЁЂRabbitMQ ЕШГЃМћЯћЯЂЖгСаЁЃШЛКѓ Logstash ЭЈЙ§ЯћЯЂЖгСаЪфШыВхМўДгЖгСажаЛёШЁЪ§ОнЃЌЗжЮіЙ§ТЫКѓОЪфГіВхМўЗЂЫЭЕН ElasticsearchЃЌзюКѓЭЈЙ§ Kibana еЙЪОЁЃЯъМћЭМ 4ЁЃ
ЭМ 4. в§ШыЯћЯЂЖгСаЛњжЦЕФМмЙЙ
етжжМмЙЙЪЪКЯгкШежОЙцФЃБШНЯХгДѓЕФЧщПіЁЃЕЋгЩгк Logstash ШежОНтЮіНкЕуКЭ Elasticsearch ЕФИККЩБШНЯжиЃЌПЩНЋЫћУЧХфжУЮЊМЏШКФЃЪНЃЌвдЗжЕЃИККЩЁЃв§ШыЯћЯЂЖгСаЃЌОљКтСЫЭјТчДЋЪфЃЌДгЖјНЕЕЭСЫЭјТчБеШћЃЌгШЦфЪЧЖЊЪЇЪ§ОнЕФПЩФмадЃЌЕЋвРШЛДцдк Logstash еМгУЯЕЭГзЪдДЙ§ЖрЕФЮЪЬтЁЃ
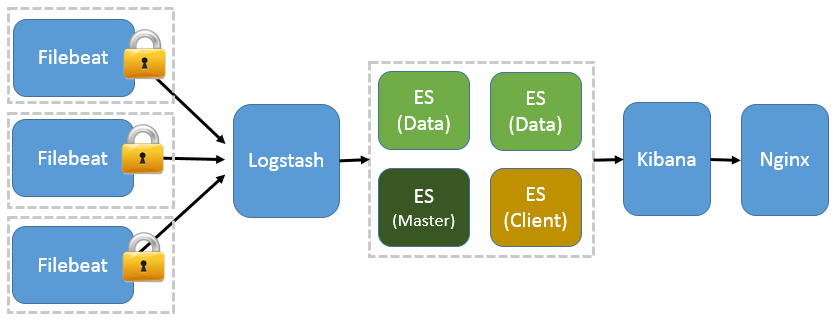
Лљгк Filebeat МмЙЙЕФХфжУВПЪ№ЯъНт
ЧАУцЬсЕН Filebeat вбОЭъШЋЬцДњСЫ Logstash-Forwarder ГЩЮЊаТвЛДњЕФШежОВЩМЏЦїЃЌЭЌЪБМјгкЫќЧсСПЁЂАВШЋЕШЬиЕуЃЌдНРДдНЖрШЫПЊЪМЪЙгУЫќЁЃетИіеТНкНЋЯъЯИНВНтШчКЮВПЪ№Лљгк Filebeat ЕФ ELK МЏжаЪНШежОНтОіЗНАИЃЌОпЬхМмЙЙМћЭМ 5ЁЃ
ЭМ 5. Лљгк Filebeat ЕФ ELK МЏШКМмЙЙ
вђЮЊУтЗбЕФ ELK УЛгаШЮКЮАВШЋЛњжЦЃЌЫљвдетРяЪЙгУСЫ Nginx зїЗДЯђДњРэЃЌБмУтгУЛЇжБНгЗУЮЪ Kibana ЗўЮёЦїЁЃМгЩЯХфжУ Nginx ЪЕЯжМђЕЅЕФгУЛЇШЯжЄЃЌвЛЖЈГЬЖШЩЯЬсИпАВШЋадЁЃСэЭтЃЌNginx БОЩэОпгаИКдиОљКтЕФзїгУЃЌФмЙЛЬсИпЯЕЭГЗУЮЪадФмЁЃ
ЯЕЭГаХЯЂ
ЦНЬЈ
БЪепЪдбщЦНЬЈЮЊ RHEL 6.xЁЃзЂвтЃЌФПЧА ELKЃЈАќРЈ BeatsЃЉВЛжЇГж AIXЁЃ
JDK
JDK ЪЧ IBM Java 8ЁЃELK ашвЊ Oracle 1.7(ЛђепЪЧ OpenJDK 1.7) МАвдЩЯЃЌШчЙћЪЧ IBM JavaЃЌдђашвЊ 8 МАвдЩЯЕФАцБО
фЏРРЦї
Kibana 4.x ВЛжЇГж IE9 МАвдЯТЃЛKibana 3.1 ЫфШЛжЇГж IE9ЃЌЕЋЪЧВЛжЇГж Safari(iOS)КЭ Chrome(Android)ЁЃОпЬхЖдфЏРРЦїЕФжЇГж
ШэМўАцБО
FilebeatЃК1.2.3ЃЛ
LogstashЃК2.3.4ЃЛ
ElasticsearchЃК2.3.4ЃЛ
KibanaЃК4.5.4ЃЛ
NginxЃК1.8.1ЁЃ
Filebeat + ELK АВзА
АВзАВНжш
ELK ЙйЭјЖдгкУПжжШэМўЬсЙЉСЫЖржжИёЪНЕФАВзААќЃЈzip/tar/rpm/DEBЃЉЃЌвд Linux ЯЕСаЯЕЭГЮЊР§ЃЌШчЙћжБНгЯТди RPMЃЌПЩвдЭЈЙ§ rpm -ivh path_of_your_rpm_file жБНгАВзАГЩЯЕЭГ serviceЁЃвдКѓОЭПЩвдЪЙгУ service УќСюЦєЭЃЁЃБШШч service elasticsearch start/stop/statusЁЃКмМђЕЅЃЌЕЋШБЕувВКмУїЯдЃЌОЭЪЧВЛФмздЖЈвхАВзАФПТМЃЌЯрЙиЮФМўЗХжУБШНЯЗжЩЂЁЃ
ЪЕМЪЪЙгУжаИќГЃгУЪЧЪЙгУ tar АќАВзАЁЃУПжжШэМўВњЦЗЕФАВзАЙ§ГЬЗЧГЃЯрЫЦЃЌЫљвдЯТУцНівд Elasticsearch ЮЊР§МђЪіАВзАЙ§ГЬЁЃ
ДДНЈ elk гУЛЇКЭгУЛЇзщЃЛ
groupadd elk # ЬэМггУЛЇзщ
useradd -g elk elk # ЬэМггУЛЇЕНжИЖЈгУЛЇзщ
passwd elk # ЮЊжИЖЈгУЛЇЩшжУУмТы
ЧаЛЛЕНаТДДНЈЕФ elk гУЛЇзіШчЯТВйзїЁЃ
ЯТдиАВзААќЃЛ
ШчЙћД§АВзАЛњЦїФмЗУЮЪЭтЭјЃЌПЩвджБНггУвдЯТУќСюЯТдиАВзААќЁЃ
wget https://download.elastic.co/
elasticsearch/release
/org/elasticsearch/distribution/
tar/elasticsearch
/2.3.4/elasticsearch-2.3.4.tar.gz |
ЗёдђЯТдиКУКѓгУ ftp ПЭЛЇЖЫЕШЙЄОпАбАќДЋЙ§ШЅЁЃ
НтбЙЕНжИЖЈФПТМЃЛ
tar xzvf elasticsearch-2.3.4.tar.gz -C /opt
етЪБОЭФмдк/opt ЯТПДЕНИеВХНтбЙГіРДЕФ elasticsearch-2.3.4 ЮФМўМаЁЃ
дЫааЃЛ
./Path_of_elasticsearch/bin/elasticsearch
бщжЄЪЧЗёЦєЖЏЃЛ
curl 'http://localhost:9200'
ШчЙћПДЕНШчЯТРрЫЦаХЯЂЃЌОЭЫЕУї Elasticsearch е§ГЃЦєЖЏСЫЁЃ
{
"name"
: "node-235",
"cluster_name"
: "elasticsearch_cms",
"version"
: {
"number" : "2.3.4",
"build_hash" : "e455fd0c13dceca8
dbbdbb1665d068ae55dabe3f",
"build_timestamp" :
"2016-06-30T11:24:31Z",
"build_snapshot" : false,
"lucene_version"
: "5.5.0"
},
"tagline" : "You Know, for
Search"
} |
ХфжУ Elasticsearch serviceЃЛ
ЩЯУцЕФдЫааУќСюЪЧдкЧАЬЈЦєЖЏ ElasticsearchЁЃЪЕМЪЪЙгУжаИќЖрЪЧдкКѓЬЈдЫааЃЌЛђепЪЧАб Elasticsearch ХфжУГЩ serviceЁЃ
Github ЩЯгавд service аЮЪНдЫаа Elasticsearch ЕФНХБОЃЌЯТдиКѓЗХЕН/etc/init.d ФПТМЯТЃЌШЛКѓгУ vim ДђПЊЃЌИљОнЪЕМЪЧщПіаоИФБШШчгУЛЇУћЁЂlog ТЗОЖЁЂЪ§ОнБЃДцТЗОЖЕШаХЯЂЁЃЭМ 6 ЪЧБЪепЪдбщгУЕФБфСПжЕЁЃ
ЭМ 6. Elasticsearch service НХБОжаЕФБфСПЖЈвх
вд service аЮЪНЦє/ЭЃ/ВщПДзДЬЌЃЛ
service elasticsearch start/stop/status
вдЩЯОЭЪЧШчКЮвд service аЮЪНАВзА ElasticsearchЃЌЖдгк FilebeatЁЂLogstash КЭ Kibana ЛЙга Nginx ЖМФмвдЯрЭЌЗНЪНАВзАЃЌетРяОЭВЛзИЪіЁЃ
Filebeat + ELK ХфжУ
Filebeat КЭ ELK ЕФАВзАКмМђЕЅЃЌБШНЯФбЕФЪЧШчКЮИљОнашЧѓНјааХфжУЁЃетИіеТНкбЁШЁСЫМИИіБШНЯЕфаЭЧвживЊЕФХфжУашЧѓКЭХфжУЗНЗЈЁЃ
Filebeat гы Logstash АВШЋЭЈаХ
гУЛЇПЩвдЪЙгУ TLS ЫЋЯђШЯжЄМгУм Filebeat КЭ Logstash ЕФСЌНгЃЌБЃжЄ Filebeat жЛЯђПЩаХЕФ Logstash ЗЂЫЭМгУмЕФЪ§ОнЁЃЭЌбљЕФЃЌLogstash вВжЛНгЪеПЩаХЕФ Filebeat ЗЂЫЭЕФЪ§ОнЁЃ
етИіЙІФмФЌШЯЪЧЙиБеЕФЁЃПЩЭЈЙ§ШчЯТВНжшдкХфжУЮФМўжаДђПЊЃК
ЩњГЩ Filebeat здЧЉУћжЄЪщКЭ key ЮФМў
вђЮЊЪдбщгУЃЌЫљвдетРяЪЙгУЕФЖМЪЧздЧЉУћжЄЪщЁЃШчКЮЪЙгУ openssl ЩњГЩздЧЉУћжЄЪщЃЌЭјЩЯгаКмЖрНЬГЬЃЌElastic github ЩЯвВжБНгЬсЙЉСЫВЮПМжИСюЁЃ
openssl req -subj
'/CN=hostname/'
-x509 -days $((100*365))
-batch
-nodes -newkeys rsa:2048 -keyout
./pki/tlk/provate/filebeat.key
-out
./pki/tls/certs/filebeat.crt |
етЬѕжИСюЩњГЩздЧЉУћжЄЪщКЭ key ЮФМўЁЃЖСепашвЊАб hostname ВПЗжИФГЩЪЕМЪЛЗОГЕФ hostnameЃЌЛђепЪЧ IP ЕижЗЁЃ
ЩњГЩ Logstash здЧЉУћжЄЪщКЭ key ЮФМў
УќСюРрЫЦЁЃ
Filebeat ХфжУ
ЪзЯШАб Logstash ЕФздЧЉУћжЄЪщДЋЫЭЕН Filebeat ЫљдкЗўЮёЦїЁЃШЛКѓЃЌЖд logstash output ВПЗжЕФ tls ХфжУзїШчЯТаоИФЃК
tls:
## logstash server ЕФздЧЉУћжЄЪщЁЃ
certificate_authorities:
["/etc/pki/tls/certs/logstash.crt"]
certificate: "/etc/pki/tls
/certs/filebeat.crt"
certificate_key: "/etc/pki/tls
/private/filebeat.key" |
ЦфжаЃК
certificate_authoritiesЃКCA жЄЪщЃЌМДгУРДЧЉЪ№жЄЪщЕФжЄЪщЁЃетРяБэЪОХфжУ Filebeat ЪЙЦфаХШЮЫљгагЩИУ CA жЄЪщЗЂааЕФжЄЪщЁЃвђЮЊздЧЉУћжЄЪщЕФЗЂааепКЭжЄЪщжїЬхЯрЭЌЃЌЫљвдетРяжБНгЪЙгУ Logstash жЄЪщЪЙ Filebeat аХШЮЪЙгУИУжЄЪщЕФ Logstash serverЃЛ
certificate & certificate_keyЃКFilebeat жЄЪщКЭ key ЮФМўЁЃFilebeat НЋЪЙгУЫќУЧЯђ Logstash server жЄУїздМКЕФПЩаХЩэЗнЁЃ
Logstash ХфжУ
ЭЌ Filebeat ХфжУРрЫЦЃЌЪзЯШАб Filebeat client ЩЯЕФжЄЪщИДжЦЕН Logstash server ЩЯЃЌШЛКѓзїШчЯТаоИФЁЃ
input {
beats {
port => 5044
ssl => true
ssl_certificate_authorities =>
["/etc/pki/tls/certs/filebeat.crt"]
ssl_certificate => "/etc/pki/tls
/certs/logstash.crt"
ssl_key => "/etc/pki/tls/private
/logstash.key"
ssl_verify_mode => "force_peer"
}
} |
ЦфжаЃК
sslЃКtrue БэЪОПЊЦє Logstash ЕФ SSL/TLS АВШЋЭЈаХЙІФмЃЛ
ssl_certificate_authoritiesЃКХфжУ Logstash ЪЙЦфаХШЮЫљгагЩИУ CA жЄЪщЗЂааЕФжЄЪщЃЛ
ssl_certificate & ssl_keyЃКLogstash server жЄЪщКЭ key ЮФМўЁЃLogstash ЪЙгУЫќУЧЯђ Filebeat client жЄУїздМКЕФПЩаХЩэЗнЃЛ
ssl_verify_modeЃКБэУї Logstash server ЪЧЗёбщжЄ Filebeat client жЄЪщЁЃгааЇжЕга peer Лђ force_peerЁЃШчЙћЪЧ force_peerЃЌБэЪОШчЙћ Filebeat УЛгаЬсЙЉжЄЪщЃЌLogstash server ОЭЛсЙиБеСЌНгЁЃ
Filebeat ЪЕЯж log rotation
ЭЈЫзЕФЫЕЃЌlog rotation ЪЧжИЕБШежОЮФМўДяЕНжИЖЈДѓаЁКѓЃЌАбЫцКѓЕФШежОаДЕНаТЕФШежОЮФМўжаЃЌдРДЕФШежОЮФМўжиУќУћЃЌМгЩЯШежОЕФЦ№жЙЪБМфЃЌвдЪЕЯжШежОЙщЕЕЕФФПЕФЁЃ
Filebeat ФЌШЯжЇГж log rotationЃЌЕЋашвЊзЂвтЕФЪЧЃЌFilebeat ВЛжЇГжЪЙгУ NAS ЛђЙвдиДХХЬБЃДцШежОЕФЧщПіЁЃвђЮЊдк Linux ЯЕСаЕФВйзїЯЕЭГжаЃЌFilebeat ЪЙгУЮФМўЕФ inode аХЯЂХаЖЯЕБЧАЮФМўЪЧаТЮФМўЛЙЪЧОЩЮФМўЁЃШчЙћЪЧ NAS ЛђЙвдиХЬЃЌЭЌвЛИіЮФМўЕФ inode аХЯЂЛсБфЛЏЃЌЕМжТ Filebeat ЮоЗЈЭъећЖСШЁ logЁЃ
ЫфШЛ Filebeat ФЌШЯжЇГж log rotationЃЌЕЋЪЧгаШ§ИіВЮЪ§ЕФЩшжУашвЊСєвтЁЃ
registry_fileЃКетИіЮФМўМЧТМСЫЕБЧАДђПЊЕФЫљга log ЮФМўЃЌвдМАУПИіЮФМўЕФ inodeЁЂЕБЧАЖСШЁЮЛжУЕШаХЯЂЁЃЕБ Filebeat ФУЕНвЛИі log ЮФМўЃЌЪзЯШВщев registry_fileЃЌШчЙћЪЧОЩЮФМўЃЌОЭДгМЧТМЕФЕБЧАЖСШЁЮЛжУДІПЊЪМЖСШЁЃЛШчЙћЪЧаТЮФМўЃЌдђДгПЊЪМЮЛжУЖСШЁЃЛ
close_olderЃКШчЙћФГИіШежОЮФМўОЙ§ close_older ЪБМфКѓУЛгааоИФВйзїЃЌFilebeat ОЭЙиБеИУЮФМўЕФ handlerЁЃШчЙћИУжЕЙ§ГЄЃЌдђЫцзХЪБМфЭЦвЦЃЌFilebeat ДђПЊЕФЮФМўЪ§СПКмЖрЃЌКФЗбЯЕЭГФкДцЃЛ
scan_frequencyЃКFilebeat УПИє scan_frequency ЪБМфЖСШЁвЛДЮЮФМўФкШнЁЃЖдгкЙиБеЕФЮФМўЃЌШчЙћКѓајгаИќаТЃЌдђОЙ§ scan_frequency ЪБМфКѓЃЌFilebeat НЋжиаТДђПЊИУЮФМўЃЌЖСШЁаТдіМгЕФФкШнЁЃ
Elasticsearch МЏШК
Elasticsearch ЦєЖЏЪБЛсИљОнХфжУЮФМўжаЩшжУЕФМЏШКУћзжЃЈcluster.nameЃЉздЖЏВщевВЂМгШыМЏШКЁЃElasctisearch НкЕуФЌШЯЪЙгУ 9300 ЖЫПкбАевМЏШКЃЌЫљвдБиаыПЊЦєетИіЖЫПкЁЃ
вЛИі Elasticsearch МЏШКжавЛАугЕгаШ§жжНЧЩЋЕФНкЕуЃЌmasterЁЂdata КЭ clientЁЃ
masterЃКmaster НкЕуИКд№вЛаЉЧсСПМЖЕФМЏШКВйзїЃЌБШШчДДНЈЁЂЩОГ§Ъ§ОнЫїв§ЁЂИњзйМЧТММЏШКжаНкЕуЕФзДЬЌЁЂОіЖЈЪ§ОнЗжЦЌЃЈshardsЃЉдк data НкЕужЎМфЕФЗжВМЃЛ
dataЃКdata НкЕуЩЯБЃДцСЫЪ§ОнЗжЦЌЁЃЫќИКд№Ъ§ОнЯрЙиВйзїЃЌБШШчЗжЦЌЕФ CRUDЃЌвдМАЫбЫїКЭећКЯВйзїЁЃетаЉВйзїЖМБШНЯЯћКФ CPUЁЂФкДцКЭ I/O зЪдДЃЛ
clientЃКclient НкЕуЦ№ЕНТЗгЩЧыЧѓЕФзїгУЃЌЪЕМЪЩЯПЩвдПДзіИКдиОљКтЦїЁЃ
ХфжУЮФМўжагаСНИігыМЏШКЯрЙиЕФХфжУЃК
node.masterЃКФЌШЯ trueЁЃTrue БэЪОИУНкЕуЪЧ master НкЕуЃЛ
node.dataЃКФЌШЯ trueЁЃTrue БэЪОИУНкЕуЪБ data НкЕуЁЃШчЙћСНИіжЕЖМЮЊ falseЃЌБэЪОЪЧ client НкЕуЁЃ
вЛИіМЏШКжаВЛвЛЖЈга client НкЕуЃЌЕЋЪЧПЯЖЈга master КЭ data НкЕуЁЃФЌШЯЕквЛИіЦєЖЏЕФНкЕуЪЧ masterЁЃMaster НкЕувВФмЦ№ЕНТЗгЩЧыЧѓКЭЫбЫїНсЙћећКЯЕФзїгУЃЌЫљвддкаЁЙцФЃЕФМЏШКжаЃЌЮоаш client НкЕуЁЃЕЋЪЧШчЙћМЏШКЙцФЃКмДѓЃЌдђгаБивЊЩшжУзЈУХЕФ clientЁЃ
Logstash ЪЙгУ grok Й§ТЫ
ШежОЪ§ОнвЛАуЖМЪЧЗЧНсЙЙЛЏЪ§ОнЃЌЖјЧвАќКЌКмЖрВЛБивЊЕФаХЯЂЃЌЫљвдашвЊдк Logstash жаЬэМгЙ§ТЫВхМўЖд Filebeat ЗЂЫЭЕФЪ§ОнНјааНсЙЙЛЏДІРэЁЃ
ЪЙгУ grok е§дђЦЅХфАбФЧаЉПДЫЦКСЮовтвхЁЂЗЧНсЙЙЛЏЕФШежОЪ§ОнНтЮіГЩПЩВщбЏЕФНсЙЙЛЏЪ§ОнЃЌЪЧФПЧА Logstash НтЮіЙ§ТЫЕФзюКУЗНЪНЁЃ
Grok ЕФгУЛЇВЛашвЊДгЭЗПЊЪМаДе§дђЁЃELK github ЩЯвбОаДКУСЫКмЖргагУЕФФЃЪНЃЌБШШчШеЦкЁЂгЪЯфЕижЗЁЂIP4/6ЁЂURL ЕШЁЃОпЬхВщПДетРяЁЃГ§ДЫжЎЭтЃЌЛЙга grok е§дђБэДяЪНЕФdebug ЙЄОпЃЌФмЗНБуПьЫйМьбщЫљаДБэДяЪНЪЧЗёе§ШЗЁЃ
ЯТУцЪЧвЛИі grok ЕФХфжУЪЕР§ЃЌЖСепПЩвдЪЪЕБаоИФТњзуФуЕФашЧѓЁЃ
filter {
grok {
match => {
"message" => [
"\[(?<Logtime>(%{MONTHNUM}/%{MONTHDAY}/%{YEAR})
\s+%{TIME}\s+%{WORD})\]\s+%{BASE16NUM}\s+(?<LogSource>
([\w|\S]+))\s+%{WORD:LogLevel}\s+(?<LogStr>[\w|\W]*)",
"\[(?<Logtime>(%{MONTHNUM}/%{MONTHDAY}/%{YEAR})
\s+%{TIME}\s+%{WORD})\]\s+%{BASE16NUM}
\s+%{WORD:LogLevel}\s+(?<LogStr>[\w|\W]*(\\n)+)"
]
}
remove_field => ["message"]
}
if "_grokparsefailure" in [tags] {
grok {
match => ["message", "(?<LogStr>[\w|\W]+)"]
remove_field => ["message"]
remove_tag => ["_grokparsefailure"]
add_field => {
LogSource => "-"
LogLevel => "-"
LogTime => "-"
}
}
}
} |
ЕквЛИі grok СаСЫСНжже§дђБэДяЪНЃЌШчЙћЕквЛжжВЛЦЅХфЃЌдђздЖЏЪЙгУЕкЖўжжЁЃШчЙћЕкЖўжжвВУЛгаЦЅХфЃЌдђЦЅХфЪЇАмЃЌlog Ъ§ОнжаЬэМгвЛИі"_grokparsefailure"гђЃЌБэУї grok ЦЅХфЪЇАмСЫЁЃЖСепПЩИљОнЪЕМЪашЧѓОіЖЈШчКЮДІРэЦЅХфЪЇАмЕФЪ§ОнЁЃетРяЃЌЖдгкЦЅХфЪЇАмЕФЃЌНЋдйЦЅХфвЛДЮЃЌВЂИјУЛгаЦЅХфЩЯЕФгђИГгшФЌШЯжЕ"-"ЃЌетбљЪЙЕУШежОЪ§ОнИёЪНЭГвЛЃЌЖМКЌга 4 ИігђЃКLogtimeЁЂLogSourceЁЂLogLevelЁЂLogTimeЃЌБугкКѓајЪ§ОнЫбЫїКЭеЙЪОЁЃ
ХфжУ Nginx ЪЕЯжгУЛЇШЯжЄ
ЙигкетВПЗжХфжУЕФНЬГЬКмЖрЃЌетРяОЭВЛзИЪіСЫЁЃ
гіЕНЕФЕфаЭЮЪЬт
ЮЪЬтЃКFilebeat ШчКЮЖСШЁЖрИіШежОФПТМЃП
ШчЙћ Filebeat Ыљдк server ЩЯдЫаагаЖрИі application serversЃЌИїздгаВЛЭЌЕФШежОФПТМЃЌФЧ Filebeat ШчКЮЭЌЪБЖСШЁЖрИіФПТМЃЌетЪЧвЛИіЗЧГЃЕфаЭЕФЮЪЬтЁЃ
НтОіЗНАИЃКЭЈЙ§ХфжУЖрИі prospector ОЭФмДяЕНвЊЧѓЁЃдкХфжУЮФМўЕФ prospectors ЯТЃЌУПИі"-"БэЪОвЛИі prospectorЃЌУПИі prospector АќКЌвЛаЉХфжУЯюЃЌжИУїетИі prospector ЫљвЊЖСШЁЕФШежОаХЯЂЁЃШчЯТЫљЪОЃК
prospectors:
-
paths:
- /home/WLPLog/*.log
# ЦфЫћХфжУЯюЃЌОпЬхВЮПМ Elastic ЙйЭј
-
paths:
- /home/ApacheLog/*.log
# ЦфЫћХфжУЯюЃЌОпЬхВЮПМ Elastic ЙйЭј |
ЮЪЬтЃКFilebeat ШчКЮЧјЗжВЛЭЌШежОРДдДЃП
ЛЙЪЧЩЯЬтжаЬсЕНЕФГЁОАЃЌFilebeat ЫфШЛФмЖСШЁВЛЭЌЕФШежОФПТМЃЌЕЋЪЧдк Logstash етБпЃЌЛђепЪЧ Elasticsearch етБпЃЌдѕУДЧјЗжВЛЭЌ application server ЕФШежОЪ§ОнФиЃП
НтОіЗНАИЃКFilebeat ЕФХфжУЯю fields ПЩвдЪЕЯжВЛЭЌШежОРДдДЕФЧјЗжЁЃгУЗЈШчЯТЃК
prospectors:
-
paths:
- /home/WLPLog/*.log
fields:
log_source: WLP
-
paths:
- /home/ApacheLog/*.log
fields:
log_source: Apache |
дк fields ХфжУЯюжаЃЌгУЛЇПЩвдздЖЈвхгђРДБъЪЖВЛЭЌЕФ logЁЃБШШчЩЯР§жаЕФ"log_source"ОЭЪЧБЪепздЖЈвхЕФЁЃШчДЫЃЌДг Filebeat ЪфГіЕФ log ОЭгавЛИіНазі log_source ЕФгђБэУїИУ log ЕФЪЕМЪРДдДЁЃ
ЮЪЬтЃКШчКЮХфжУ Logstash гы Elasticsearch МЏШКЭЈаХЃП
ЮвУЧжЊЕР Logstash ЪЙгУ Elasticsearch ЪфГіВхМўОЭФмАбЪ§ОнЗЂЫЭЕН Elasticsearch НјааДцДЂКЭЫбЫїЁЃElasticsearch ВхМўжагаИі hosts ХфжУЯюЫЕУї Elasticsearch аХЯЂЁЃЕЋЪЧМйШчЪЧвЛИі Elasticsearch МЏШКЃЌгІИУдѕУДХфжУ hostsЃП
НтОіЗНАИЃКзюМђЕЅЕФзіЗЈЪЧАбМЏШКжаЫљгаЕФ Elasticsearch НкЕуЕФ IP ЛђепЪЧ hostname аХЯЂЖМдк hosts жаХфЩЯЃЈЫќжЇГжЪ§зщЃЉЁЃЕЋЪЧШчЙћМЏШКБШНЯДѓЃЌЛђепЪЧМЏШКНкЕуБфЖЏЦЕЗБЕФЛАЃЌЛЙашвЊЮЌЛЄетИі hosts жЕЃЌВЛЬЋЗНБуЁЃБШНЯЭЦМіЕФзіЗЈЪЧжЛХфМЏШКжаФГИіНкЕуЕФаХЯЂЃЌПЩвдЪЧ client НкЕуЃЌвВПЩвдЪЧ master НкЕуЛђепЪЧ data НкЕуЁЃвђЮЊВЛЙмЪЧФФИіНкЕуЃЌЖМжЊЕРИУЫќЫљдкМЏШКЕФаХЯЂЃЈМЏШКЙцФЃЃЌИїНкЕуНЧЩЋЃЉЁЃетбљЃЌLogstash гыШЮвтНкЕуЭЈаХЪБЖМЛсЯШФУЕНМЏШКаХЯЂЃЌШЛКѓдйОіЖЈгІИУИјФФИіНкЕуЗЂЫЭЪ§ОнЪфГіЧыЧѓЁЃ
ЮЪЬтЃКШчКЮдк Kibana ЯдЪОШежОЪ§ОнЃП
НтОіЗНАИЃКЕБЪ§ОнДцДЂдк Elasticsearch ЖЫжЎКѓОЭПЩвддк Kibana ЩЯЧхГўЕФеЙЪОСЫЁЃЪзЯШдкфЏРРЦїЩЯДђПЊ Kibana вГУцЁЃШчЙћЪЙгУСЫ NginxЃЌОЭЪЙгУ Nginx ХфжУЕФ URLЃЛЗёдђОЭЪЧhttp://yourhostname:5601ЁЃ
ДДНЈШежОЫїв§ЁЃLogstash ЗЂЫЭЕФЪ§ОнЃЌФЌШЯЪЙгУ logstash ЧАзКзїЮЊЪ§ОнЫїв§ЁЃМћЭМ 7ЁЃ
ЭМ 7. Kibana ДДНЈЫїв§вГУц
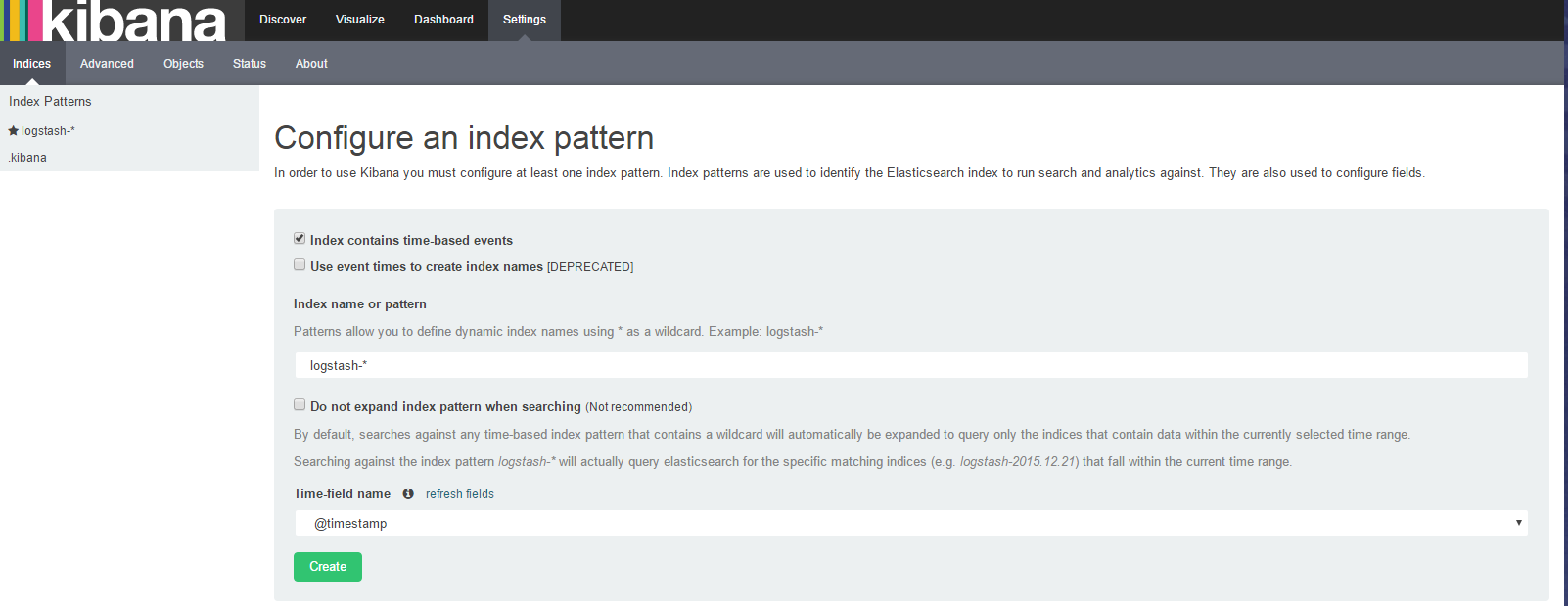
ЕуЛї CreateЃЌдйбЁдё Discover вГУцОЭФмПДМћ Logstash ЗЂЫЭЕФЪ§ОнСЫ,ШчЭМ 8 ЫљЪОЁЃ
ЭМ 8. Ъ§ОнеЙЪОвГУц
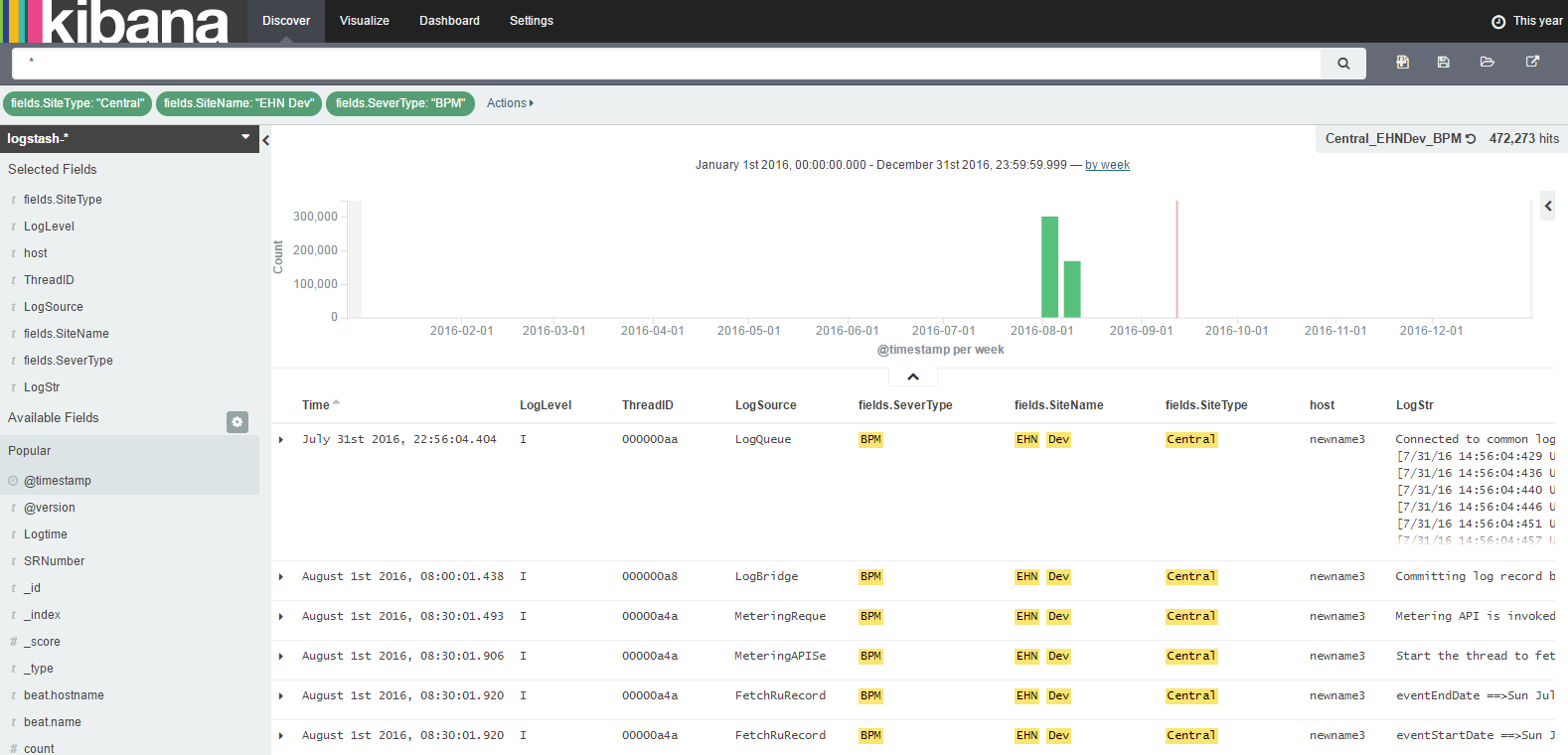
Kibana ОпЬхЕФЪЙгУЃЌБШШчШчКЮДДНЈШежО visualizationЃЌШчКЮНЋ visualization ЬэМгЕН dashboardЃЌШчКЮдк Kibana ЩЯЫбЫїШежО
|






