| БрМЭЦМі: |
БОЮФНщЩмЮЊЪВУДЪЙгУKafka,ШчКЮЯћЯЂДЋЕнБЃжЄЕФЯрЙиФкШнЃЌДЋЕнБЃжЄгявхЕФШ§ИіМЖБ№,ЭЈЙ§вЛИіЪОР§НјааЗжЮіISRМЏКЯЃЌHWКЭLEOЪЧШчКЮаЕїЙЄзїЕФЁЃ
БОЮФРДздгкМђЪщЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
1 KafkaНщЩм
KafkaЪЧзюГѕгЩLinkedinЙЋЫОПЊЗЂЃЌЪЧвЛИіЗжВМЪНЁЂжЇГжЗжЧјЕФЃЈpartitionЃЉЁЂЖрИББОЕФЃЈreplicaЃЉЃЌЛљгкzookeeperаЕїЕФЗжВМЪНЯћЯЂЯЕЭГЃЌЫќЕФзюДѓЕФЬиадОЭЪЧПЩвдЪЕЪБЕФДІРэДѓСПЪ§ОнвдТњзуИїжжашЧѓГЁОАЃКБШШчЛљгкhadoopЕФХњДІРэЯЕЭГЁЂЕЭбгГйЕФЪЕЪБЯЕЭГЁЂstorm/SparkСїЪНДІРэв§ЧцЃЌweb/nginxШежОЁЂЗУЮЪШежОЃЌЯћЯЂЗўЮёЕШЕШЃЌгУscalaгябдБраДЃЌLinkedinгк2010ФъЙБЯзИјСЫApacheЛљН№ЛсВЂГЩЮЊЖЅМЖПЊдД
ЯюФПЁЃ
2 ЮЊЪВУДЪЙгУKafka
2.1 Нтёю
дЪаэФуЖРСЂЕФРЉеЙЛђаоИФСНБпЕФДІРэЙ§ГЬЃЌжЛвЊШЗБЃЫќУЧзёЪиЭЌбљЕФНгПкдМЪјЁЃ
2.2 Шпгр
ЯћЯЂЖгСаАбЪ§ОнНјааГжОУЛЏжБЕНЫќУЧвбОБЛЭъШЋДІРэЃЌЭЈЙ§етвЛЗНЪНЙцБмСЫЪ§ОнЖЊЪЇЗчЯеЁЃаэЖрЯћЯЂЖгСаЫљВЩгУЕФ"ВхШы-ЛёШЁ-ЩОГ§"ЗЖЪНжаЃЌдкАбвЛИіЯћЯЂДгЖгСажаЩОГ§жЎЧАЃЌашвЊФуЕФДІРэЯЕЭГУїШЗЕФжИГіИУЯћЯЂвбОБЛДІРэЭъБЯЃЌДгЖјШЗБЃФуЕФЪ§ОнБЛАВШЋЕФБЃДцжБЕНФуЪЙгУЭъБЯЁЃ
2.3 РЉеЙад
вђЮЊЯћЯЂЖгСаНтёюСЫФуЕФДІРэЙ§ГЬЃЌЫљвддіДѓЯћЯЂШыЖгКЭДІРэЕФЦЕТЪЪЧКмШнвзЕФЃЌжЛвЊСэЭтдіМгДІРэЙ§ГЬМДПЩЁЃ
2.4 СщЛюад & ЗхжЕДІРэФмСІ
дкЗУЮЪСПОчдіЕФЧщПіЯТЃЌгІгУШдШЛашвЊМЬајЗЂЛгзїгУЃЌЕЋЪЧетбљЕФЭЛЗЂСїСПВЂВЛГЃМћЁЃШчЙћЮЊвдФмДІРэетРрЗхжЕЗУЮЪЮЊБъзМРДЭЖШызЪдДЫцЪБД§УќЮовЩЪЧОоДѓЕФРЫЗбЁЃЪЙгУЯћЯЂЖгСаФмЙЛЪЙЙиМќзщМўЖЅзЁЭЛЗЂЕФЗУЮЪбЙСІЃЌЖјВЛЛсвђЮЊЭЛЗЂЕФГЌИККЩЕФЧыЧѓЖјЭъШЋБРРЃЁЃ
2.5 ПЩЛжИДад
ЯЕЭГЕФвЛВПЗжзщМўЪЇаЇЪБЃЌВЛЛсгАЯьЕНећИіЯЕЭГЁЃЯћЯЂЖгСаНЕЕЭСЫНјГЬМфЕФёюКЯЖШЃЌЫљвдМДЪЙвЛИіДІРэЯћЯЂЕФНјГЬЙвЕєЃЌМгШыЖгСажаЕФЯћЯЂШдШЛПЩвддкЯЕЭГЛжИДКѓБЛДІРэЁЃ
2.6 ЫГађБЃжЄ
дкДѓЖрЪЙгУГЁОАЯТЃЌЪ§ОнДІРэЕФЫГађЖМКмживЊЁЃДѓВПЗжЯћЯЂЖгСаБОРДОЭЪЧХХађЕФЃЌВЂЧвФмБЃжЄЪ§ОнЛсАДееЬиЖЈЕФЫГађРДДІРэЁЃЃЈKafka
БЃжЄвЛИі Partition ФкЕФЯћЯЂЕФгаађадЃЉ
2.7 ЛКГх
гажњгкПижЦКЭгХЛЏЪ§ОнСїОЙ§ЯЕЭГЕФЫйЖШЃЌНтОіЩњВњЯћЯЂКЭЯћЗбЯћЯЂЕФДІРэЫйЖШВЛвЛжТЕФЧщПіЁЃ
2.8 вьВНЭЈаХ
КмЖрЪБКђЃЌгУЛЇВЛЯывВВЛашвЊСЂМДДІРэЯћЯЂЁЃЯћЯЂЖгСаЬсЙЉСЫвьВНДІРэЛњжЦЃЌдЪаэгУЛЇАбвЛИіЯћЯЂЗХШыЖгСаЃЌЕЋВЂВЛСЂМДДІРэЫќЁЃЯыЯђЖгСажаЗХШыЖрЩйЯћЯЂОЭЗХЖрЩйЃЌШЛКѓдкашвЊЕФЪБКђдйШЅДІРэЫќУЧЁЃ
3 KafkaМмЙЙ
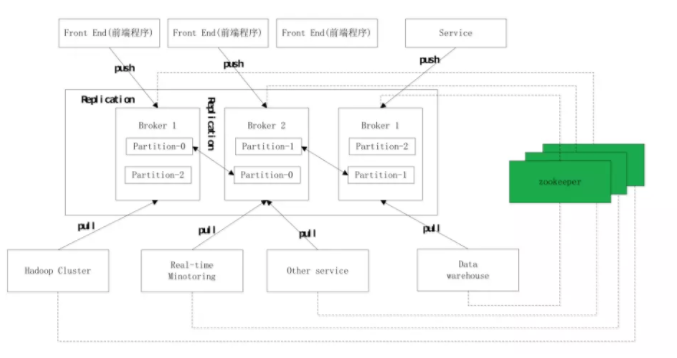
3.1 Broker
kafka МЏШКжаАќКЌЕФЗўЮёЦїЁЃвЛИіЕЅЖРЕФKafka serverОЭЪЧвЛИіBrokerЁЃBrokerЕФжївЊЙЄзїОЭЪЧНгЪмЩњВњепЗЂЙ§РДЕФЯћЯЂЃЌЗжХфoffsetЃЌжЎКѓБЃДцЕНДХХЬжаЃЌЭЌЪБЃЌНгЪеЯћЗбепЁЂЦфЫћBorkerЕФЧыЧѓЃЌИљОнЧыЧѓРраЭНјааЯргІДІРэВЂЗЕЛиЯьгІЁЃЖрИіBrokerПЩвдзіГЩвЛИіClusterЖдЭтЬсЙЉЗўЮёЃЌУПИіClusterЕБжаЛсбЁОйГівЛИіBrokerРДЕЃШЮControllerЃЌControllerЪЧKafkaМЏШКЕФжИЛгжааФЃЌЖјЦфЫћBrokerдђЬ§ДгControllerжИЛгЪЕЯжЯргІЕФЙІФмЁЃControllerИКд№ЙмРэЗжЧјЕФзДЬЌЁЂЙмРэУПИіЗжЧјЕФИББОЕФзДЬЌЁЂМрЬ§ZookeeperжаЪ§ОнЕФБфЛЏЕШЙЄзїЁЃControllerвВЪЧвЛжїЖрДгЕФЪЕЯжЃЌЫљгаЕФBrokerЖМЛсМрЬ§Controller
LeaderЕФзДЬЌЃЌЕБController LeaderГіЯжЙЪеЯЪБдђжиаТбЁОйаТЕФController
LeaderЁЃ
3.2 Producer
producer ЗЂЫЭЯћЯЂЕН broker ЪБЃЌЛсИљОнЗжЧјЫуЗЈбЁдёНЋЦфДцДЂЕНФФвЛИі
partitionЁЃЦфТЗгЩЛњжЦЮЊЃК
1 жИЖЈСЫ patitionЃЌдђжБНгЪЙгУЁЃ
2 ЮДжИЖЈ patition ЕЋжИЖЈ keyЃЌЭЈЙ§Жд key ЕФ
value Нјааhash бЁГівЛИі patitionЁЃ
3 patition КЭ key ЖМЮДжИЖЈЃЌЪЙгУТжбЏбЁГівЛИі patitionЁЃ
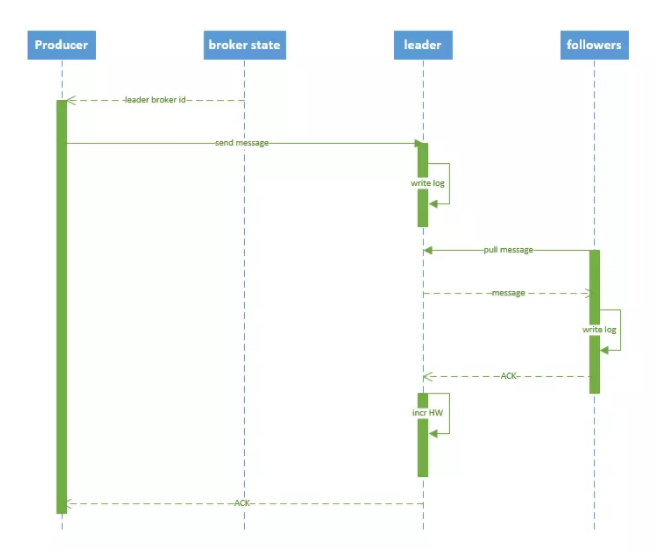
СїГЬЫЕУїЃК
1 producer ЯШДг zookeeper ЕФ "/brokers/.../state"
НкЕуевЕНИУ partition ЕФ leaderЁЃ
2 producer НЋЯћЯЂЗЂЫЭИјИУ leaderЁЃ
3 leader НЋЯћЯЂаДШыБОЕи logЁЃ
4 followers Дг leader pull ЯћЯЂЃЌаДШыБОЕи
log Кѓ leader ЗЂЫЭ ACKЁЃ
5 leader ЪеЕНЫљга ISR жаЕФ replica ЕФ ACK
КѓЃЌдіМг HWЃЈhigh watermarkЃЌзюКѓ commit ЕФ offsetЃЉ ВЂЯђ producer
ЗЂЫЭ ACKЁЃ
ЯТУцРДНщЩмЯћЯЂДЋЕнЕФБЃжЄЃЈDelivery guarantee semanticЃЉЕФЯрЙиФкШнЃЌДЋЕнБЃжЄгявхгавдЯТШ§ИіМЖБ№ЁЃ
1 At most onceЃКЯћЯЂПЩФмЛсЖЊЃЌЕЋОјВЛЛсжиИДДЋЕнЁЃ
2 At least onceЃКЯћЯЂОјВЛЛсЖЊЃЌЕЋПЩФмЛсжиИДДЋЕнЁЃ
3 Exactly onceЃКУПЬѕЯћЯЂЖМжЛБЛДЋЕнвЛДЮЁЃ
ЕБ producer Яђ broker ЗЂЫЭЯћЯЂЪБЃЌвЛЕЉетЬѕЯћЯЂБЛ
commitЃЌгЩгк replication ЕФДцдкЃЌЫќОЭВЛЛсЖЊЁЃЕЋЪЧШчЙћ producer ЗЂЫЭЪ§ОнИј
broker КѓЃЌгіЕНЭјТчЮЪЬтЖјдьГЩЭЈаХжаЖЯЃЌФЧ Producer ОЭЮоЗЈХаЖЯИУЬѕЯћЯЂЪЧЗёвбО commitЁЃЫфШЛ
Kafka ЮоЗЈШЗЖЈЭјТчЙЪеЯЦкМфЗЂЩњСЫЪВУДЁЃЮЊСЫЪЕЯжExactly onceгявхЃЌетРяЬсЙЉСНжжПЩбЁЗНАИЃК
1 УПИіЗжЧјжЛгавЛИіЩњВњепаДШыЯћЯЂЃЌЕБГіЯжвьГЃЛђГЌЪБЕФЧщПіЪБЃЌЩњВњепОЭвЊВщбЏДЫЗжЧјЕФзюКѓвЛИіЯћЯЂЃЌгУРДОіЖЈКѓајВйзїЕФЯћЯЂжиДЋЛЙЪЧМЬајЗЂЫЭЁЃ
2 ЮЊУПИіЯћЯЂЬэМгвЛИіШЋОжЮЈвЛжїМќЃЌЩњВњепВЛзіЦфЫћЬиЪтДІРэЃЌАДеежЎЧАЗжЮіЕФЗНЪННјаажиДЋЃЌгЩЯћЗбепНјааШЅжиЁЃ
3.3 Topic&Log
УПЬѕЗЂВМЕН kafka МЏШКЕФЯћЯЂЪєгкЕФРрБ№ЃЌМД kafka ЪЧУцЯђ
TopicЕФЁЃУПИіTopicПЩвдЛЎЗжГЩЖрИіЗжЧјЃЌЭЌвЛИіTopicЯТЕФВЛЭЌЗжЧјАќКЌЕФЯћЯЂЪЧВЛЭЌЕФЁЃУПИіЯћЯЂдкБЛЬэМгЕНЗжЧјЪБЃЌЖМЛсБЛЗжХфЕНвЛИіoffsetЃЌЫќЪЧЯћЯЂдкДЫЗжЧјжаЕФЮЈвЛБрКХЃЌKafkaЭЈЙ§offsetБЃжЄЯћЯЂЕФЗжЧјФкЕФЫГађЃЌoffsetЕФЫГађадВЛПфЗжЧјЃЌМДKafkaжЛБЃжЄдкЭЌвЛИіЗжЧјФкЕФЯћЯЂЪЧгаађЕФЁЃ
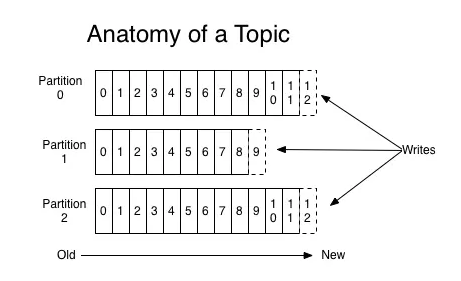
ЭЌвЛTopicЕФВЛЭЌЗжЧјЛсЗжХфдкВЛЭЌЕФBrokerЩЯЁЃЗжЧјЪЧKafkaЫЎЦНРЉеЙадЕФЛљДЁЃЌЮвУЧПЩвдЭЈЙ§діМгЗўЮёЦїВЂдкЦфЩЯЗжХфPartitionЕФЗНЪНРДдіМгKafkaЕФВЂааДІРэФмСІЁЃ
ЗжЧјдкТпМЩЯЖдгІзХвЛИіLogЃЌЕБЩњВњепНЋЯћЯЂаДШыЗжЧјЪБЃЌЪЕМЪЩЯЪЧаДШыЕНСЫЗжЧјЖдгІЕФLogжаЁЃLogЪЧвЛИіТпМИХФюЃЌПЩвдЖдгІЕНДХХЬЩЯЕФвЛИіЮФМўМаЁЃLogгаЖрИіSegmentзщГЩЃЌУПИіSegmentЖдгІвЛИіШежОЮФМўКЭЫїв§ЮФМўЁЃдкУцЖдКЃСПЪ§ОнЪБЃЌЮЊБмУтSegmentГіЯжГЌДѓЮФМўЃЌУПИіШежОЮФМўЕФДѓаЁЪЧгаЯожЦЕФЃЌЕБГЌГіЯожЦКѓЛсДДНЈаТЕФSegmentМЬајЖдЭтЬсЙЉЗўЮёЁЃетРявЊзЂвтЃЌвђЮЊKafkaВЩгУЫГађIOЃЌЫљвджЛЯђзюаТЕФSegmentзЗМгЪ§ОнЁЃЮЊСЫШЈКтЮФМўДѓаЁЁЂЫїв§ЫйЖШЁЂеМгУФкДцДѓаЁЕШЖрЗНУцвђЫиЃЌЫїв§ЮФМўВЩгУЯЁЪшЫїв§ЕФЗНЪНЃЌДѓаЁВЂВЛЛсКмДѓЃЌдкдЫааЪБЛсНЋЦфФкШнгГЩфЕНФкДцЃЌЬсИпЫїв§ЫйЖШЁЃ
3.4 Partition
УПвЛИіTopicЖМПЩвдЛЎЗжГЩЖрИіPartition(УПвЛИіTopicЖМжСЩйгавЛИіPartition),ВЛЭЌЕФPartitionЛсЗжХфдкВЛЭЌЕФBrokerЩЯвдЖдKafkaНјааЫЎЦНРЉеЙДгЖјдіМгKafkaЕФВЂааДІРэФмСІЁЃЭЌвЛИіTopicЯТЕФВЛЭЌPartitionАќКЌЕФЯћЯЂЪЧВЛЭЌЕФЁЃУПвЛИіЯћЯЂдкБЛЬэМгЕНPartitionЕФЪБКђ,ЖМЛсБЛЗжХфвЛИіoffset,ЫћЪЧЯћЯЂдкДЫЗжЧјжаЕФЮЈвЛБрКХ,ДЫЭт,KafkaЭЈЙ§offsetБЃжЄЯћЯЂдкPartitionжаЕФЫГађ,offsetЕФЫГађадВЛПчPartition,вВОЭЪЧЫЕдкKafkaЕФЭЌвЛИіPartitionжаЕФЯћЯЂЪЧгаађЕФ,ВЛЭЌPartitionЕФЯћЯЂПЩФмВЛЪЧгаађЕФЁЃ
3.5 Consumer
ЯћЗбепЃЈConsumerЃЉЕФжївЊЙЄзїЪЧДгTopicжаРШЁЯћЯЂЃЌВЂЖдЯћЯЂНјааЯћЗбЁЃФГИіЯћЯЂЯћЗбЕНPartitionЕФФФИіЮЛжУЃЈoffsetЃЉЕФЯрЙиаХЯЂЃЌЪЧConsumerздМКЮЌЛЄЕФЁЃ
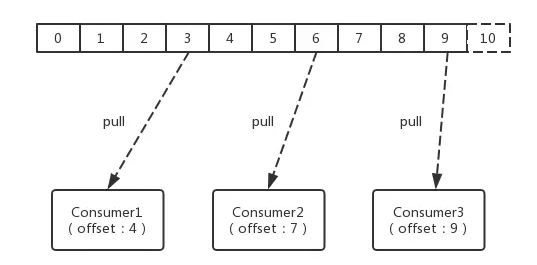
етбљЩшМЦЗЧГЃЧЩУюЁЃБмУтСЫKafka ServerЖЫЮЌЛЄЯћЗбепЯћЗбЮЛжУЕФПЊЯњЃЌгШЦфЪЧдкЯћЗбЪ§СПНЯЖрЕФЧщПіЯТЁЃСэвЛЗНУцЃЌШчЙћЪЧгЩKafka
ServerЖЫЙмРэУПИіConsumerЯћЗбзДЬЌЃЌвЛЕЉKafka ServerЖЫГіЯжбгЪБЛђЪЧЯћЗбзДЬЌЖЊЪЇЃЌНЋЛсгАЯьДѓСПЕФConsumerЁЃЭЌЪБЃЌетвЛЩшМЦвВЬсИпСЫConsumerЕФСщЛюадЃЌConsumerПЩвдАДеездМКашвЊЕФЫГађКЭФЃЪНРШЁЯћЯЂНјааЯћЗбЁЃР§ШчЃКConsumerПЩвдЭЈЙ§аоИФЦфЯћЗбепЕФЮЛжУЪЕЯжеыЖдФГаЉЬиЪтkeyЕФЯћЯЂНјааЗДИДЯћЗбЃЌЛђЪЧЬјЙ§ФГаЉЯћЯЂЕФашЧѓЁЃ
3.6 Consumer group
high-level consumer API жаЃЌУПИі consumer
ЖМЪєгквЛИі consumer groupЃЌУПЬѕЯћЯЂжЛФмБЛ consumer group жаЕФвЛИі Consumer
ЯћЗбЃЌЕЋПЩвдБЛЖрИі consumer group ЯћЗбЁЃ
3.7 Replica
KafkaЖдЯћЯЂНјааСЫШпгрБИЗн,УПИіPartitionЗжЧјЖМПЩвдгаЖрИіИББО,УПвЛИіИББОжаАќКЌЕФЯћЯЂЪЧЯрЭЌЕФ(ЕЋВЛБЃжЄЭЌвЛЪБПЬЯТЭъШЋЯрЭЌ)ЁЃУПИіЗжЧјжСЩйгавЛИіИББОЃЌЕБЗжЧјжЛгавЛИіИББОЕФЪБКђЃЌОЭжЛгаLeaderИББОЃЌУЛга
FollowerЁЃдкУПИіИББОМЏКЯжа,ЖМЛсбЁОйГівЛИіИББОзїЮЊLeaderИББО,KafkaдкВЛЭЌЕФГЁОАжаЛсВЩгУВЛЭЌЕФбЁОйВпТдЁЃKafkaжаЫљгаЕФЖСаДЧыЧѓЖМгЩбЁОйГіЕФLeaderИББОДІРэ,ЦфЫћЕФЖМзїЮЊFollowerИББО,FollowerИББОНіНіЪЧДгLeaderИББОжаАбЪ§ОнРШЁЕНБОЕижЎКѓЃЌЭЌВНИќаТЕНздМКЕФLogжаЁЃ
3.8 ISR
ISRЃЈIn-Sync-ReplicaЃЉМЏКЯБэЪОЕФЪЧФПЧАПЩгУЃЈaliveЃЉЧвЯћЯЂСПгыLeaderЯрВюВЛЖрЕФИББОМЏКЯЃЌетЪЧећИіИББОМЏКЯЕФвЛИізгМЏЁЃISRМЏКЯжаЕФИББОБиаыТњзуЯТУцСНИіЬѕМўЃК
ЃЈ1ЃЉИББОЫљдкНкЕуБиаыЮЌГжзХгыZooKeeperЕФСДНгЁЃ
ЃЈ2ЃЉИББОзюКѓвЛЬѕЯћЯЂЕФoffsetгыLeaderИББОЕФзюКѓвЛЬѕЯћЯЂЕФoffsetжЎМфЕФВюжЕВЛФмГЌГіжИЖЈЕФуажЕЁЃ
УПИіЗжЧјжаЕФLeaderЖМЛсЮЌЛЄДЫЗжЧјЕФISRМЏКЯЃЌаДЧыЧѓЪзЯШгЩLeaderИББОДІРэЃЌжЎКѓFollowerИББОЖМЛсДгLeaderЩЯРШЁаДШыЕФЯћЯЂЃЌетИіЙ§ГЬЛсгавЛЖЈЕФбгГйЃЌЕМжТFollowerИББОжаБЃДцЕФЯћЯЂТдЩйгкLeaderИББОЃЌжЛвЊЮДГЌГіуажЕЖМЪЧПЩвдШнШЬЕФЁЃШчЙћвЛИіFollowerИББОГіЯжвьГЃЃЌБШШчЃКхДЛњЃЌЗЂЩњГЄЪБМфGCЖјЕМжТKafkaНЉЫРЛђЪЧЭјТчЖЯПЊСЌНгЕМжТГЄЪБМфУЛгаРШЁЯћЯЂНјааЭЌВНЃЌОЭЛиЮЅЗДЩЯУцСНИіЬѕМўЃЌДгЖјБЛLeaderИББОЬпГіISRМЏКЯЁЃЕБFollowerИББОДгвьГЃжаЛжИДжЎКѓЃЌЛсМЬајгыLeaderИББОНјааЭЌВНЃЌЕБFollowerИББОзЗЩЯЃЈМДзюКѓвЛЬѕЯћЯЂЕФoffsetЕФВюжЕаЁгкжИЖЈуажЕЃЉLeaderИББОЕФЪБКђЃЌДЫFollowerИББОЛсБЛLeaderИББОжиаТМгШыЕНISRжаЁЃ
3.9 HW&LEO
HWЃЈHigh WatermarkЃЉКЭLEOгыISRМЏКЯНєУмЯрЙиЁЃHWБъМЧСЫвЛИіЬиЪтЕФoffsetЃЌЕБЯћЗбепДІРэЯћЯЂЕФЪБКђЃЌжЛФмРШЁЕНHWжЎЧАЕФЯћЯЂЃЌHWжЎКѓЕФЯћЯЂЖдЯћЗбепРДЫЕЪЧВЛПЩМћЕФЁЃгыISRМЏКЯРрЫЦЃЌHWвВЪЧгЩLeaderИББОЙмРэЕФЁЃЕБISRМЏКЯжаШЋВПЕФFollowerИББОЖМРШЁHWжИЖЈЯћЯЂНјааЭЌВНКѓЃЌLeaderИББОЛсЕндіHWЕФжЕЁЃKafkaЙйЗНЭјеОНЋHWжЎЧАЕФЯћЯЂЕФзДЬЌГЦЮЊcommitЃЌЦфКЌвхЪЧетаЉЯћЯЂдкЖрИіИББОжаЭЌЪБДцдкЃЌМДЪЙLeaderИББОЫ№ЛЕЃЌвВВЛЛсГіЯжЪ§ОнЖЊЪЇЁЃ
LEO(Log End Offset)ЪЧЫљгаЕФИББОЖМЛсгаЕФвЛИіoffsetБъМЧЃЌЫќжИЯђзЗМгЕНЕБЧАИББОЕФзюКѓвЛИіЯћЯЂЕФoffsetЁЃЕБЩњВњепЯђLeaderИББОзЗМгЯћЯЂЕФЪБКђЃЌLeaderИББОЕФLEOБъМЧЛсЕндіЃЛЕБFollowerИББОГЩЙІДгLeaderИББОРШЁЯћЯЂВЂИќаТЕНБОЕиЕФЪБКђЃЌFollowerИББОЕФLEOОЭЛсдіМгЁЃ
ЮЊСЫШУЖСепИќКУЕФРэНтHWКЭLEOжЎМфЕФЙиЯЕЃЌЯТУцЭЈЙ§вЛИіЪОР§НјааЗжЮіISRМЏКЯЃЌHWКЭLEOЪЧШчКЮаЕїЙЄзїЕФЁЃ
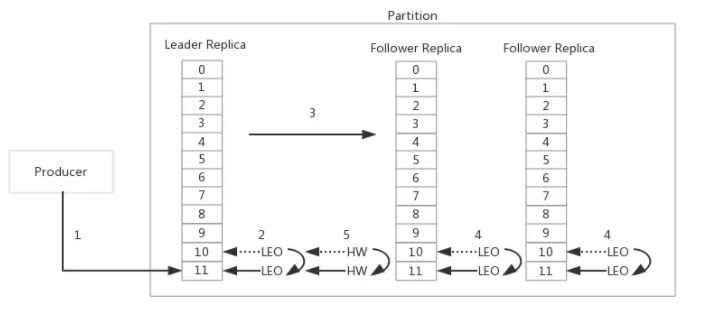
1 PoducerЯђДЫPartitionЭЦЫЭЯћЯЂЁЃ
2 LeaderИББОНЋЯћЯЂзЗМгЕНLogжаЃЌВЂЕндіЦфLEOЁЃ
3 FollowerИББОДгLeaderИББОРШЁЯћЯЂВЂНјааЭЌВНЁЃ
4 FollowerИББОНЋРШЁЕНЕФЯћЯЂИќаТЕНБОЕиLogжаЃЌВЂЕндіЦфLEOЁЃ
5 ЕБISRМЏКЯжаЫљгаИББОЖМЭъГЩСЫЖдoffsetЯћЯЂЕФЭЌВНЃЌLeaderИББОЛсЕндіHWЁЃ
3.10 ZooKeeper
kafka ЭЈЙ§ zookeeper РДДцДЂМЏШКЕФ meta аХЯЂЁЃ
|









