| БрМЭЦМі: |
ЮФеТжївЊНВЪігаFlink
ЕФЙиЯЕ APIЃКTable API КЭ SQLЃЌЖЏЬЌБэЕФГжајВщбЏ,дкСїжаЖЈвхЖЏЬЌ,
ВщбЏЖЏЬЌ, ЩњГЩЖЏЬЌБэЕШЯЃЭћЖдДѓМвгаАяжњЁЃ
БОЮФРДздгкЮЂаХКХiteblog_hadoopЃЌгЩЛ№СњЙћШэМўDeloresБрМЃЌЭЦМі
|
|
дНРДдНЖрЕФЙЋЫОВЩгУСїДІРэЃЌВЂНЋЯжгаЕФХњДІРэгІгУЧЈвЦЕНСїДІРэЃЌЛђепЖдаТЕФгУР§ВЩгУСїДІРэЪЕЯжЕФНтОіЗНАИЁЃЦфжааэЖргІгУМЏжадкСїЪ§ОнЗжЮіЩЯЃЌЗжЮіЕФЪ§ОнСїРДздИїжждДЃЌР§ШчЪ§ОнПтЪТЮёЁЂЕуЛїЁЂДЋИаЦїВтСПЛђ IoT ЩшБИЁЃ

Apache Flink ЗЧГЃЪЪгУгкСїЗжЮігІгУГЬађЃЌвђЮЊЫќжЇГжЪТМўЪБМфгявхЃЌШЗБЃжЛДІРэвЛДЮЃЌвдМАЭЌЪБЪЕЯжСЫИпЭЬЭТСПКЭЕЭбгГйЁЃвђЮЊетаЉЬиадЃЌFlink ФмЙЛНќЪЕЪБЖдДѓСПЕФЪфШыЪ§ОнМЦЫуГівЛИіШЗЖЈКЭОЋШЗЕФНсЙћЃЌВЂЧвдкЗЂЩњЙЪеЯЕФЪБКђЬсЙЉвЛДЮадгявхЁЃ
Flink ЕФКЫаФСїДІРэ APIЃЌDataStream APIЃЌЗЧГЃОпгаБэЯжСІЃЌВЂЧвЮЊаэЖрГЃМћВйзїЬсЙЉСЫдгяЁЃдкЦфЫћЬиаджаЃЌЫќЬсЙЉСЫИпЖШПЩЖЈжЦЕФДАПкТпМЃЌВЛЭЌБэЯжЬиеїЯТЕФВЛЭЌзДЬЌдгяЃЌзЂВсКЭЯьгІЖЈЪБЦїЕФЙГзгЃЌвдМАИпаЇЕФвьВНЧыЧѓЭтВПЯЕЭГЕФЙЄОпЁЃСэвЛЗНУцЃЌаэЖрСїЗжЮігІгУзёбЯрЫЦЕФФЃЪНЃЌВЂВЛашвЊ DataStream API ЬсЙЉЕФБэЯжСІМЖБ№ЁЃЫћУЧПЩвдЪЙгУСьгђЬиЖЈЕФгябдРДЪЙгУИќздШЛКЭМђНрЕФЗНЪНБэДяЁЃжкЫљжмжЊЃЌSQL ЪЧЪ§ОнЗжЮіЕФЪТЪЕБъзМЁЃЖдгкСїЗжЮіЃЌSQL ПЩвдШУИќЖрЕФШЫдкЪ§ОнСїЕФЬиЖЈгІгУжаЛЈЗбИќЩйЕФЪБМфЁЃШЛЖјЃЌФПЧАЛЙУЛгаПЊдДЕФСїДІРэЦїЬсЙЉСюШЫТњвтЕФ SQL жЇГжЁЃ
ЮЊЪВУДСїжаЕФ SQL КмживЊ
SQL ЪЧЪ§ОнЗжЮіЪЙгУзюЙуЗКЕФгябдЃЌгаКмЖрдвђЃК
SQL ЪЧЩљУїЪНЕФЃКФужИЖЈФуЯывЊЕФЖЋЮїЃЌЖјВЛЪЧШчКЮШЅМЦЫуЃЛ
SQL ПЩвдНјаагааЇЕФгХЛЏЃКгХЛЏЦїМЦЙРЫугааЇЕФМЦЛЎРДМЦЫуНсЙћЃЛ
SQL ПЩвдНјаагааЇЕФЦРЙРЃКДІРэв§ЧцзМШЗЕФжЊЕРМЦЫуФкШнЃЌвдМАШчКЮгааЇЕФжДааЃЛ
зюКѓЃЌЫљгаШЫЖМжЊЕРЕФЃЌаэЖрЙЄОпЖМРэНт SQLЁЃ
вђДЫЃЌЪЙгУ SQL ДІРэКЭЗжЮіЪ§ОнСїЃЌПЩвдЮЊИќЖрШЫЬсЙЉСїДІРэММЪѕЁЃДЫЭтЃЌвђЮЊ SQL ЕФЩљУїаджЪКЭЧБдкЕФздЖЏгХЛЏЃЌЫќПЩвдДѓДѓМѕЩйЖЈвхИпаЇСїЗжЮігІгУЕФЪБМфКЭОЋСІЁЃ
ЕЋЪЧЃЌSQLЃЈвдМАЙиЯЕЪ§ОнФЃаЭКЭДњЪ§ЃЉВЂВЛЪЧЮЊСїЪ§ОнЩшМЦЕФЁЃЙиЯЕЪЧЃЈЖрЃЉМЏКЯЖјВЛЪЧЮоЯоађСаЕФдЊзщЁЃЕБжДаа SQL ВщбЏЪБЃЌДЋЭГЪ§ОнПтЯЕЭГКЭВщбЏв§ЧцЖСШЁКЭДІРэЭъећЕФПЩгУЪ§ОнМЏЃЌВЂВњЩњЙЬЖЈДѓаЁЕФНсЙћЁЃЯрБШжЎЯТЃЌЪ§ОнСїГжајЬсЙЉаТЕФМЧТМЃЌЪЙЪ§ОнЫцзХЪБМфЕНДяЁЃвђДЫЃЌСїВщбЏашвЊВЛЖЯЕФДІРэЕНДяЕФЪ§ОнЃЌДгРДЖМВЛЪЧЁАЭъећЕФЁБЁЃ
ЛАЫфШчДЫЃЌЪЙгУ SQL ДІРэСїВЂВЛЪЧВЛПЩФмЕФЁЃвЛаЉЙиЯЕаЭЪ§ОнПтЯЕЭГЮЌЛЄСЫЮяЛЏЪгЭМЃЌРрЫЦгкдкСїЪ§ОнжаЦРЙР SQL ВщбЏЁЃЮяЛЏЪгЭМБЛЖЈвхЮЊвЛИі SQL ВщбЏЃЌОЭЯёГЃЙцЃЈащФтЃЉЪгЭМвЛбљЁЃЕЋЪЧЃЌВщбЏЕФНсЙћЪЕМЪЩЯБЛБЃДцЃЈЛђепЪЧЮяЛЏЃЉдкФкДцЛђгВХЬжаЃЌетбљЪгЭМдкВщбЏЪБВЛашвЊЪЕЪБМЦЫуЁЃЮЊСЫЗРжЙЮяЛЏЪгЭМЕФЪ§ОнЙ§ЪБЃЌЪ§ОнПтЯЕЭГашвЊдкЦфЛљДЁЙиЯЕЃЈЖЈвхЕФ SQL ВщбЏв§гУЕФБэЃЉБЛаоИФЪБИќаТИќаТЪгЭМЁЃШчЙћЮвУЧНЋЪгЭМЕФЛљДЁЙиЯЕаоИФЪгзїаоИФСїЃЈЛђепЪЧИќИФШежОСїЃЉЃЌЮяЛЏЪгЭМЕФЮЌЛЄКЭСїжаЕФ SQL ЕФЙиЯЕОЭБфЕУКмУїШЗСЫЁЃ
Flink ЕФЙиЯЕ APIЃКTable API КЭ SQL
Дг 1.1.0 АцБОЃЈ2016 Фъ 8 дТЗЂВМЃЉвдРДЃЌFlink ЬсЙЉСЫСНИігявхЯрЕБЕФЙиЯЕ APIЃЌгябдФкЧЖЕФ Table APIЃЈгУгк Java КЭ ScalaЃЉвдМАБъзМ SQLЁЃетСНжж API БЛЩшМЦгУгкдкЯпСїКЭвХСєЕФХњДІРэЪ§Он API ЕФЭГвЛЃЌетвтЮЖзХЮоТлЪфШыЪЧОВЬЌХњДІРэЪ§ОнЛЙЪЧСїЪ§ОнЃЌВщбЏВњЩњЭъШЋЯрЭЌЕФНсЙћЁЃ
ЭГвЛСїКЭХњДІРэЕФ API ЗЧГЃживЊЁЃЪзЯШЃЌгУЛЇжЛашвЊбЇЯАвЛИі API РДДІРэОВЬЌКЭСїЪ§ОнЁЃДЫЭтЃЌПЩвдЪЙгУЭЌбљЕФВщбЏРДЗжЮіХњДІРэКЭСїЪ§ОнЃЌетбљПЩвддкЭЌвЛИіВщбЏРяУцЭЌЪБЗжЮіРњЪЗКЭдкЯпЪ§ОнЁЃдкФПЧАЕФзДПіЯТЃЌЮвУЧЩаЮДЭъШЋЪЕЯжХњДІРэКЭСїЪНгявхЕФЭГвЛЃЌЕЋЩчЧјдкетИіФПБъЩЯШЁЕУСЫКмДѓЕФНјеЙЁЃ
ЯТУцЕФДњТыЦЌЖЮеЙЪОСЫСНИіЕШаЇЕФ Table API КЭ SQL ВщбЏЃЌгУРДдкЮТЖШДЋИаЦїВтСПЪ§ОнСїжаМЦЫувЛИіМђЕЅЕФДАПкОлКЯЁЃSQL ВщбЏЕФгяЗЈЛљгк Apache Calcite ЕФЗжзщДАПкКЏЪ§бљЪНЃЌВЂНЋдк Flink 1.3.0 АцБОжаЕУЕНжЇГжЁЃ
val env = StreamExecutionEnvironment.
getExecutionEnvironment
env.setStreamTimeCharacteristic
(TimeCharacteristic.EventTime)
val tEnv = TableEnvironment.
getTableEnvironment(env)
// define a table source to read sensor data
(sensorId,
time, room, temp)
val sensorTable = ??? // can be a CSV file,
Kafka
topic, database, or ...
// register the table source
tEnv.registerTableSource("sensors",
sensorTable)
// Table API
val tapiResult: Table = tEnv.scan
("sensors")
// scan sensors table
.window(Tumble over 1.hour on 'rowtime as 'w)
// define 1-hour window
.groupBy('w, 'room) // group by window and room
.select('room, 'w.end, 'temp.avg as 'avgTemp)
// compute average temperature
// SQL
val sqlResult: Table = tEnv.sql("""
|SELECT room, TUMBLE_END(rowtime,
INTERVAL '1'
HOUR), AVG(temp) AS avgTemp
|FROM sensors
|GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR),
room
|""".stripMargin) |
ОЭЯёФуПДЕНЕФЃЌСНжж API вдМА Flink жївЊЕФЕФ DataStream КЭ DataSet API ЪЧНєУмНсКЯЕФЁЃTable ПЩвдКЭ DataSet Лђ DataStream ЯрЛЅзЊЛЛЁЃвђДЫЃЌПЩвдКмМђЕЅЕФШЅЩЈУшвЛИіЭтВПЕФБэЃЌР§ШчЪ§ОнПтЛђепЪЧ Parquet ЮФМўЃЌЪЙгУ Table API ВщбЏзівЛаЉдЄДІРэЃЌНЋНсЙћзЊЛЛЮЊ DataSetЃЌВЂЖдЦфдЫаа Gelly ЭМаЮЫуЗЈЁЃЩЯЪіЪОР§жаЖЈвхЕФВщбЏвВПЩвдЭЈЙ§ИќИФжДааЛЗОГРДДІРэХњСПЪ§ОнЁЃ
дкФкВПЃЌСНжж API ЖМБЛзЊЛЛГЩЯрЭЌЕФТпМБэЪОЃЌгЩ Apache Calcite НјаагХЛЏЃЌВЂБЛБрвыГЩ DataStream ЛђЪЧ DataSet ГЬађЁЃЪЕМЪЩЯЃЌгХЛЏКЭзЊЛЛГЬађВЂВЛжЊЕРВщбЏЪЧЭЈЙ§ Table API ЛЙЪЧ SQL РДЖЈвхЕФЁЃШчЙћФуЖдгХЛЏЙ§ГЬЕФЯИНкИааЫШЄЃЌПЩвдПДПДЮвУЧШЅФъЗЂВМЕФвЛЦЊВЉПЭЮФеТЁЃгЩгк Table API КЭ SQL дкгявхЗНУцЕШЭЌЃЌжЛЪЧдкбљЪНЩЯгааЉЧјБ№ЃЌдкетЦЊЮФеТжаЕБЮвУЧЬИТл SQL ЪБЮвУЧЭЈГЃв§гУетСНжж APIЁЃ
дкЕБЧАЕФ 1.2.0 АцБОжаЃЌFlink ЕФЙиЯЕ API дкЪ§ОнСїжаЃЌжЇГжгаЯоЕФЙиЯЕВйзїЃЌАќРЈЭЖгАЁЂЙ§ТЫКЭДАПкОлКЯЁЃЫљгажЇГжЕФВйзїгавЛИіЙВЭЌЕуЃЌОЭЪЧЫќУЧгРдЖВЛЛсИќаТвбОВњЩњЕФНсЙћМЧТМЁЃетЖдгкЪБМфМЧТМВйзїЃЌР§ШчЭЖгАКЭЙ§ТЫЯдШЛВЛЪЧЮЪЬтЁЃЕЋЪЧЃЌЫќЛсгАЯьЪеМЏКЭДІРэЖрЬѕМЧТМЕФВйзїЃЌР§ШчДАПкОлКЯЁЃгЩгкВњЩњЕФНсЙћВЛФмБЛИќаТЃЌдк Flink 1.2.0 жаЃЌЪфШыЕФМЧТМдкВњЩњНсЙћжЎКѓВЛЕУВЛБЛЖЊЦњЁЃ
ЕБЧААцБОЕФЯожЦЖдгкНЋВњЩњЕФЪ§ОнЗЂЭљ Kafka жїЬтЁЂЯћЯЂЖгСаЛђепЪЧЮФМўетаЉДцДЂЯЕЭГЕФгІгУЪЧПЩвдБЛНгЪмЕФЃЌвђЮЊЫќУЧжЛжЇГжзЗМгВйзїЃЌУЛгаИќаТКЭЩОГ§ЁЃзёбетжжФЃЪНЕФГЃМћгУР§ЪЧГжајЕФ ETL КЭСїДцЕЕгІгУЃЌНЋСїНјааГжОУЛЏДцЕЕЃЌЛђепЪЧзМБИЪ§ОнгУгкНјвЛВНЕФдкЯпЃЈСїЃЉЛђепЪЧРыЯпЗжЮіЁЃгЩгкВЛПЩФмИќаТжЎЧАВњЩњЕФНсЙћЃЌетвЛРргІгУБиаыШЗБЃВњЩњЕФНсЙћЪЧе§ШЗЕФЃЌВЂЧвНЋРДВЛашвЊИќе§ЁЃЯТЭМЫЕУїСЫетбљЕФгІгУЁЃ
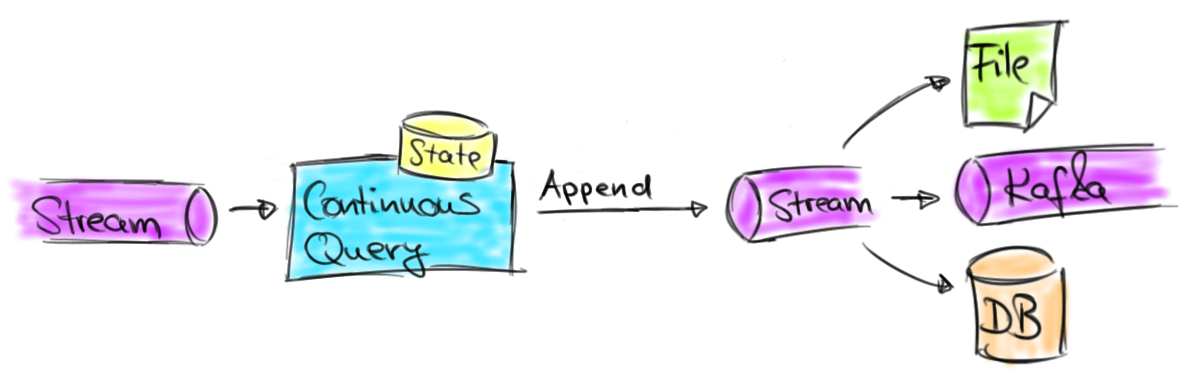
ЫфШЛжЛжЇГжзЗМгВщбЏЖдгааЉРраЭЕФгІгУКЭДцДЂЯЕЭГгагУЃЌЕЋЪЧЛЙЪЧгавЛаЉСїЗжЮіЕФгУР§ашвЊИќаТНсЙћЁЃетаЉСїгІгУАќРЈВЛФмЖЊЦњбгГйЕНДяЕФМЧТМЃЌашвЊдчЦкЕФНсЙћгУгкЃЈГЄЦкдЫааЃЉДАПкОлКЯЃЌЛђепЪЧашвЊЗЧДАПкЕФОлКЯЁЃдкУПжжЧщПіЯТЃЌжЎЧАВњЩњЕФНсЙћМЧТМЖМашвЊБЛИќаТЁЃНсЙћИќаТВщбЏЭЈГЃНЋЦфНсЙћБЃДцдкЭтВПЪ§ОнПтЛђепЪЧМќжЕДцДЂЃЌЪЙЦфПЩвдШУЭтВПгІгУЗУЮЪЛђепЪЧВщбЏЁЃЪЕЯжетжжФЃЪНЕФгІгУгавЧБэАхЁЂБЈИцгІгУЛђепЪЧЦфЫћЕФгІгУЃЌЫќУЧашвЊМАЪБЕФЗУЮЪГжајИќаТЕФНсЙћЁЃЯТЭМЫЕУїСЫетвЛРргІгУЁЃ
ЖЏЬЌБэЕФГжајВщбЏ
жЇГжВщбЏИќаТжЎЧАВњЩњЕФНсЙћЪЧ Flink ЕФЙиЯЕ API ЕФЯТвЛИіживЊВНжшЁЃетИіЙІФмЗЧГЃживЊЃЌвђЮЊЫќДѓДѓдіМгСЫ API жЇГжЕФгУР§ЕФЗЖЮЇКЭжжРрЁЃДЫЭтЃЌвЛаЉаТЕФгУР§ПЩвдВЩгУ DataStream API РДЪЕЯжЁЃ
вђДЫЃЌЕБЬэМгЖдНсЙћИќаТВщбЏЕФжЇГжЪБЃЌЮвУЧБиаыБЃСєжЎЧАЕФСїКЭХњДІРэЪфШыЕФгявхЁЃЮвУЧЭЈЙ§ЖЏЬЌБэЕФИХФюРДЪЕЯжЁЃЖЏЬЌБэЪЧГжајИќаТЃЌВЂЧвФмЙЛЯёГЃЙцЕФОВЬЌБэвЛбљВщбЏЕФБэЁЃЕЋЪЧЃЌгыХњДІРэБэВщбЏжежЙКѓЗЕЛивЛИіОВЬЌБэзїЮЊНсЙћВЛЭЌЕФЪЧЃЌЖЏЬЌБэжаЕФВщбЏЛсГжајдЫааЃЌВЂИљОнЪфШыБэЕФаоИФВњЩњвЛИіГжајИќаТЕФБэЁЃвђДЫЃЌНсЙћБэвВЪЧЖЏЬЌЕФЁЃетИіИХФюЗЧГЃРрЫЦЮвУЧжЎЧАЬжТлЕФЮяЛЏЪгЭМЕФЮЌЛЄЁЃ МйЩшЮвУЧПЩвддкЖЏЬЌБэжадЫааВщбЏВЂВњЩњвЛИіаТЕФЖЏЬЌБэЃЌФЧЛсДјРДвЛИіЮЪЬтЃЌСїКЭЖЏЬЌБэШчКЮЯрЛЅЙиСЊЃПД№АИЪЧСїКЭЖЏЬЌБэПЩвдЯрЛЅзЊЛЛЁЃЯТЭМеЙЪОСЫдкСїжаДІРэЙиЯЕВщбЏЕФИХФюФЃаЭЁЃ

ЪзЯШЃЌСїБЛзЊЛЛЮЊЖЏЬЌБэЃЌЖЏЬЌБэЪЙгУвЛИіГжајВщбЏНјааВщбЏЃЌВњЩњвЛИіаТЕФЖЏЬЌБэЁЃзюКѓЃЌНсЙћБэБЛзЊЛЛГЩСїЁЃвЊзЂвтЃЌетИіжЛЪЧТпМФЃаЭЃЌВЂВЛвтЮЖзХВщбЏЪЧШчКЮЪЕМЪжДааЕФЁЃЪЕМЪЩЯЃЌГжајВщбЏдкФкВПБЛзЊЛЛГЩДЋЭГЕФ DataStream ГЬађЁЃ
ЫцКѓЃЌЮвУЧУшЪіСЫетИіФЃаЭЕФВЛЭЌВНжшЃК
дкСїжаЖЈвхЖЏЬЌБэ
ВщбЏЖЏЬЌБэ
ЩњГЩЖЏЬЌБэ
дкСїжаЖЈвхЖЏЬЌБэ
ЦРЙРЖЏЬЌБэЩЯЕФ SQL ВщбЏЕФЕквЛВНЪЧдкСїжаЖЈвхвЛИіЖЏЬЌБэЁЃетвтЮЖзХЮвУЧБиаыжИЖЈСїжаЕФМЧТМШчКЮаоИФЖЏЬЌБэЁЃСїаЏДјЕФМЧТМБиаыОпгагГЩфЕНБэЕФЙиЯЕФЃЪНЕФФЃЪНЁЃдкСїжаЖЈвхЖЏЬЌБэгаСНжжФЃЪНЃКИНМгФЃЪНКЭИќаТФЃЪНЁЃ
дкИНМгФЃЪНжаЃЌСїжаЕФУПЬѕМЧТМЪЧЖдЖЏЬЌБэЕФВхШыаоИФЁЃвђДЫЃЌСїжаЕФЫљгаМЧТМЖМИНМгЕНЖЏЬЌБэжаЃЌЪЙЕУЫќЕФДѓаЁВЛЖЯдіГЄВЂЧвЮоЯоДѓЁЃЯТЭМЫЕУїСЫИНМгФЃЪНЁЃ
дкИќаТФЃЪНжаЃЌСїжаЕФМЧТМПЩвдзїЮЊЖЏЬЌБэЕФВхШыЁЂИќаТЛђепЩОГ§аоИФЃЈИНМгФЃЪНЪЕМЪЩЯЪЧвЛжжЬиЪтЕФИќаТФЃЪНЃЉЁЃЕБдкСїжаЭЈЙ§ИќаТФЃЪНЖЈвхвЛИіЖЏЬЌБэЪБЃЌЮвУЧПЩвддкБэжажИЖЈвЛИіЮЈвЛЕФМќЪєадЁЃдкетжжЧщПіЯТЃЌИќаТКЭЩОГ§ВйзїЛсДјзХМќЪєадвЛЦ№жДааЁЃИќаТФЃЪНШчЯТЭМЫљЪОЁЃ

ВщбЏЖЏЬЌБэ
вЛЕЉЮвУЧЖЈвхСЫЖЏЬЌБэЃЌЮвУЧПЩвддкЩЯУцдЫааВщбЏЁЃгЩгкЖЏЬЌБэЫцзХЪБМфНјааИФБфЃЌЮвУЧБиаыЖЈвхВщбЏЖЏЬЌБэЕФвтвхЁЃМйЖЈЮвУЧгавЛИіЬиЖЈЪБМфЕФЖЏЬЌБэЕФПьееЃЌетИіПьееПЩвдзїЮЊвЛИіБъзМЕФОВЬЌХњДІРэБэЁЃЮвУЧНЋЖЏЬЌБэ A дкЕу t ЕФПьееБэЪОЮЊ A[t]ЃЌПЩвдЪЙгУШЫвтЕФ SQL ВщбЏРДВщбЏПьееЃЌИУВщбЏВњЩњСЫвЛИіБъзМЕФОВЬЌБэзїЮЊНсЙћЃЌЮвУЧАбдкЪБМф t ЖдЖЏЬЌБэ A зіЕФВщбЏ q ЕФНсЙћБэЪОЮЊ q(A[t])ЁЃШчЙћЮвУЧЗДИДдкЖЏЬЌБэЕФПьееЩЯМЦЫуВщбЏНсЙћЃЌвдЛёШЁНјЖШЪБМфЕуЃЌЮвУЧНЋЛёЕУаэЖрОВЬЌНсЙћБэЃЌЫќУЧЫцзХЪБМфЕФЭЦвЦЖјИФБфЃЌВЂЧвгааЇЕФЙЙГЩвЛИіЖЏЬЌБэЁЃЮвУЧдкЖЏЬЌБэЕФВщбЏжаЖЈвхШчЯТгявхЁЃ
ВщбЏ q дкЖЏЬЌБэ A ЩЯВњЩњСЫвЛИіЖЏЬЌБэ RЃЌЫќдкУПИіЪБМфЕу t ЕШМлгкдк A[t] ЩЯжДаа q ЕФНсЙћЃЌМД R[t]=q(A[t])ЁЃИУЖЈвхвтЮЖзХдкХњДІРэБэКЭСїБэЩЯжДааЯрЭЌЕФВщбЏ q ЛсВњЩњЯрЭЌЕФНсЙћЁЃдкЯТУцЕФР§згжаЃЌЮвУЧИјГіСЫСНИіР§згРДЫЕУїЖЏЬЌБэВщбЏЕФгявхЁЃ
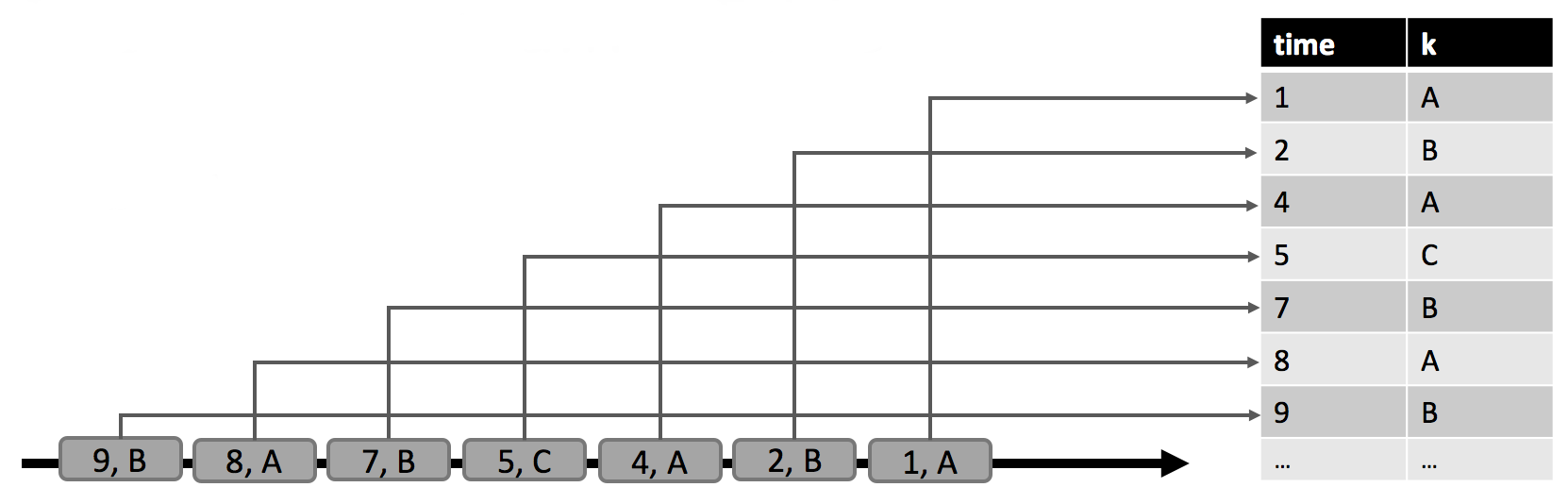
дкЯТЭМжаЃЌЮвУЧПДЕНзѓВрЕФЖЏЬЌЪфШыБэ AЃЌЖЈвхГЩзЗМгФЃЪНЁЃдкЪБМф t=8 ЪБЃЌA гЩ 6 ааЃЈБъМЧГЩРЖЩЋЃЉзщГЩЁЃдкЪБМф t=9 КЭ t=12 ЪБЃЌгавЛаазЗМгЕН AЃЈЗжБ№гУТЬЩЋКЭГШЩЋБъМЧЃЉЁЃЮвУЧдкБэ A ЩЯдЫаавЛИіШчЭМжаМфЫљЪОЕФМђЕЅВщбЏЃЌетИіВщбЏИљОнЪєад k ЗжзщЃЌВЂЭГМЦУПзщЕФМЧТМЪ§ЁЃдкгвВрЮвУЧПДЕНСЫ t=8ЃЈРЖЩЋЃЉЃЌt=9ЃЈТЬЩЋЃЉКЭ t=12ЃЈГШЩЋЃЉЪБВщбЏ q ЕФНсЙћЁЃдкУПИіЪБМфЕу tЃЌНсЙћБэЕШМлгкдкЪБМф t ЪБдйЖЏЬЌБэ A ЩЯжДааХњВщбЏЁЃ
етИіР§згжаЕФВщбЏЪЧвЛИіМђЕЅЕФЗжзщЃЈЕЋЪЧУЛгаДАПкЃЉОлКЯВщбЏЁЃвђДЫЃЌНсЙћБэЕФДѓаЁвРРЕгкЪфШыБэЕФЗжзщМќЕФЪ§СПЁЃДЫЭтЃЌжЕЕУзЂвтЕФЪЧЃЌетИіВщбЏЛсГжајИќаТжЎЧАВњЩњЕФНсЙћааЃЌЖјВЛжЛЪЧЬэМгаТааЁЃ
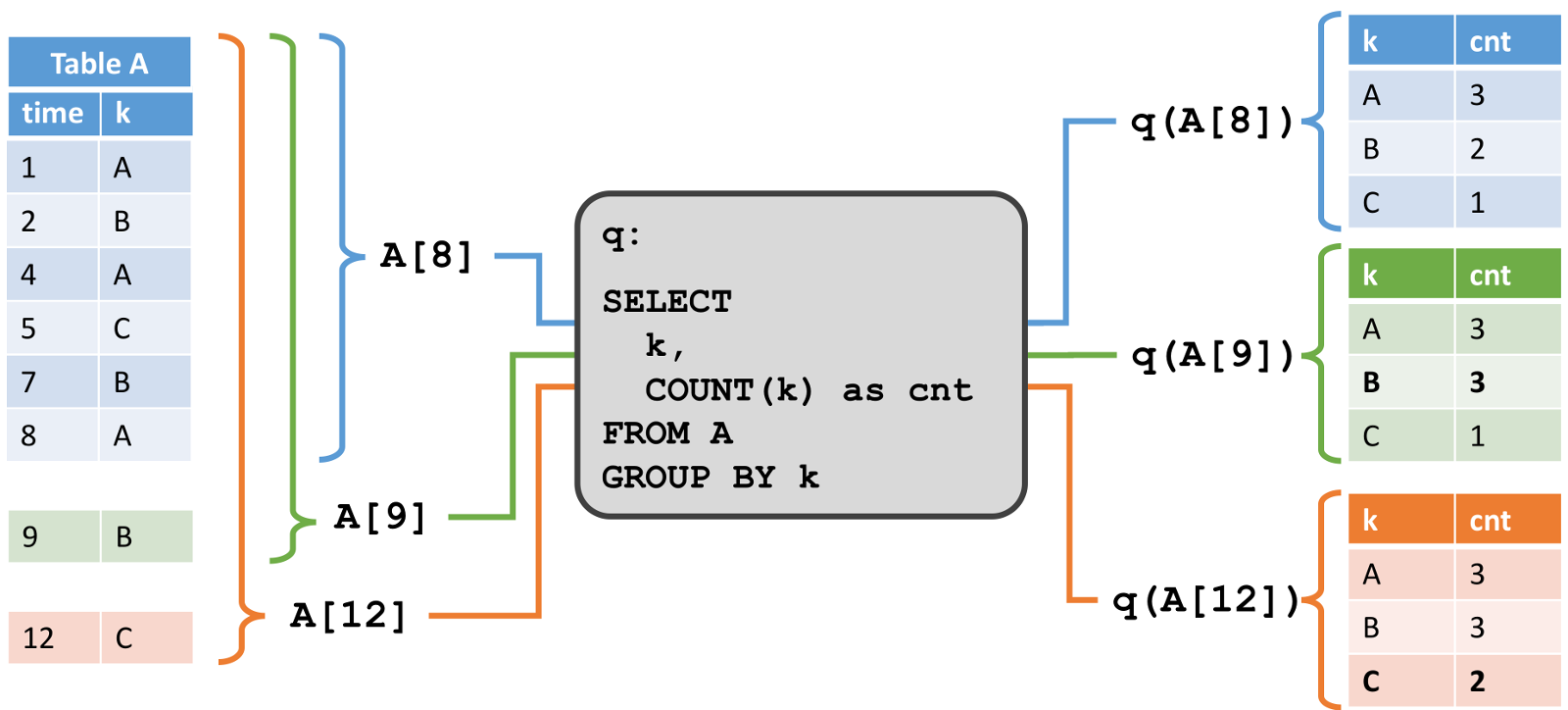
ЕкЖўИіР§згеЙЪОСЫвЛИіРрЫЦЕФВщбЏЃЌЕЋЪЧгавЛИіКмживЊЕФВювьЁЃГ§СЫЖдЪєад k ЗжзщвдЭтЃЌВщбЏЛЙНЋМЧТМУП 5 УыжгЗжзщЮЊвЛИіЙіЖЏДАПкЃЌетвтЮЖзХЫќУП 5 УыжгМЦЫувЛДЮ k ЕФзмЪ§ЁЃдйвЛДЮЕФЃЌЮвУЧЪЙгУ Calcite ЕФЗжзщДАПкКЏЪ§РДжИЖЈетИіВщбЏЁЃдкЭМЕФзѓВрЃЌЮвУЧПДЕНЪфШыБэ A ЃЌвдМАЫќдкИНМгФЃЪНЯТЫцзХЪБМфЖјИФБфЁЃдкгвВрЃЌЮвУЧПДЕННсЙћБэЃЌвдМАЫќЫцзХЪБМфбнБфЁЃ
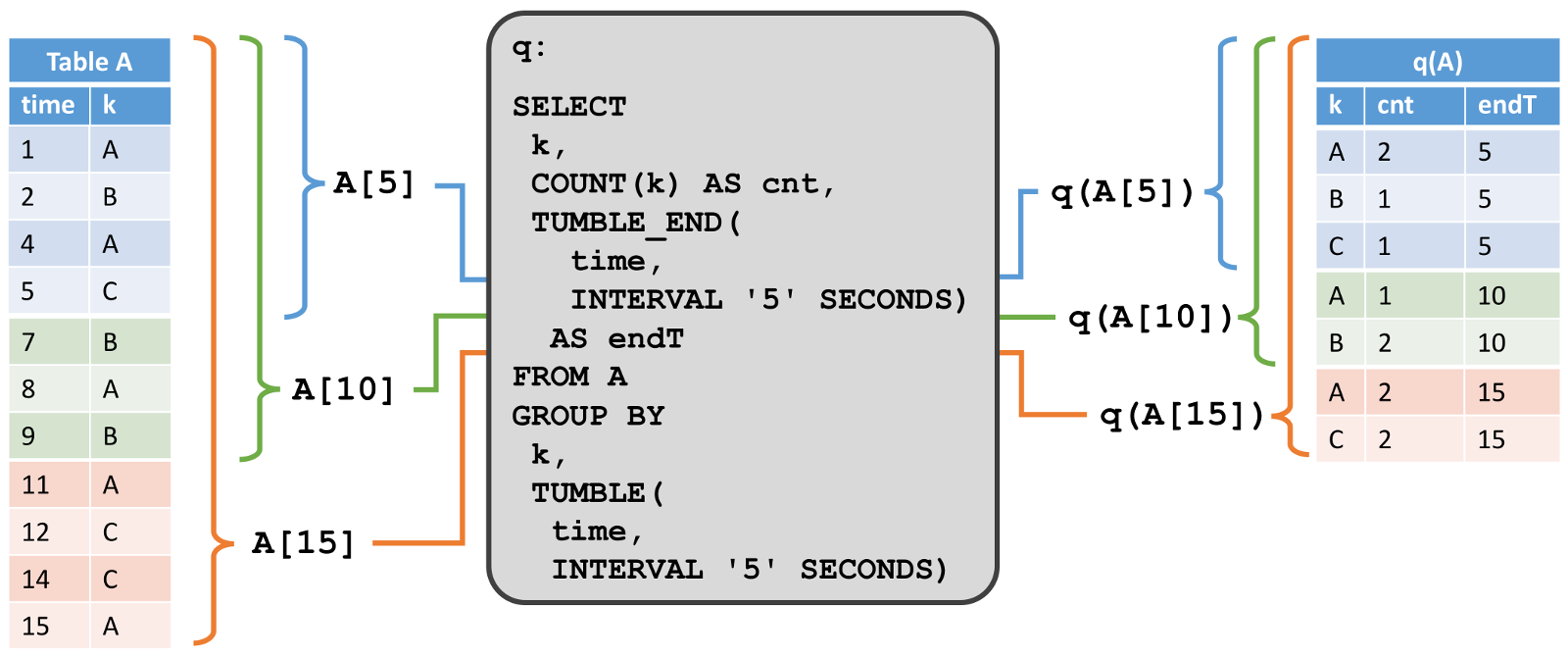
гыЕквЛИіР§згЕФНсЙћВЛЭЌЕФЪЧЃЌетИіНсЙћБэЫцзХЪБМфдіГЄЃЌР§ШчУП 5 УыжгМЦЫуГіаТЕФНсЙћааЃЈПМТЧЕНЪфШыБэдкЙ§ШЅ 5 УыЪеЕНИќЖрЕФМЧТМЃЉЁЃЫфШЛЗЧДАПкВщбЏЃЈжївЊЪЧЃЉИќаТНсЙћБэЕФааЃЌЕЋЪЧДАПкОлКЯВщбЏжЛзЗМгаТааЕННсЙћБэжаЁЃ
ЫфШЛетЦЊВЉПЭзЈзЂгкЖЏЬЌБэЕФ SQL ВщбЏЕФгявхЃЌЖјВЛЪЧШчКЮгааЇЕФДІРэетбљЕФВщбЏЃЌЕЋЪЧЮвУЧвЊжИГіЕФЪЧЃЌЮоТлЪфШыБэЪВУДЪБКђИќаТЃЌЖМВЛПЩФмМЦЫуВщбЏЕФЭъећНсЙћЁЃЯрЗДЃЌВщбЏБрвыГЩСїгІгУЃЌИљОнЪфШыЕФБфЛЏГжајИќаТЫќЕФНсЙћЁЃетвтЮЖзХВЛЪЧЫљгаЕФгааЇ SQL ЖМжЇГжЃЌжЛгаФЧаЉГжајадЕФЁЂЕндіЕФКЭИпаЇМЦЫуЕФБЛжЇГжЁЃ
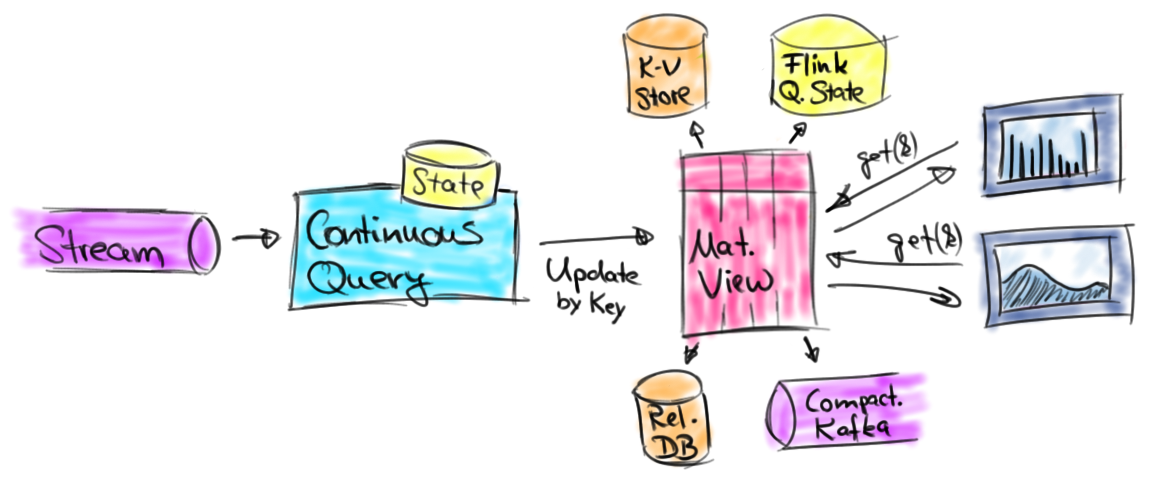
ЩњГЩЖЏЬЌБэ
ВщбЏЖЏЬЌБэЩњГЩЕФЖЏЬЌБэЃЌЦфЯрЕБгкВщбЏНсЙћЁЃИљОнВщбЏКЭЫќЕФЪфШыБэЃЌНсЙћБэЛсЭЈЙ§ВхШыЁЂИќаТКЭЩОГ§ГжајИќИФЃЌОЭЯёЦеЭЈЕФЪ§ОнБэвЛбљЁЃЫќПЩФмЪЧвЛИіВЛЖЯБЛИќаТЕФЕЅааБэЃЌвЛИіжЛВхШыВЛИќаТЕФБэЃЌЛђепНщгкСНепжЎМфЁЃ
ДЋЭГЕФЪ§ОнПтЯЕЭГдкЙЪеЯКЭИДжЦЕФЪБКђЃЌЭЈЙ§ШежОжиНЈБэЁЃгавЛаЉВЛЭЌЕФШежОММЪѕЃЌБШШч UNDOЁЂREDO КЭ UNDO/REDO ШежОЁЃМђЖјбджЎЃЌUNDO ШежОМЧТМБЛаоИФдЊЫижЎЧАЕФжЕРДЛиЙіВЛЭъећЕФЪТЮёЃЌREDO ШежОМЧТМдЊЫиаоИФЕФаТжЕРДжизівбЭъГЩЪТЮёЖЊЪЇЕФИФБфЃЌUNDO/REDO ШежОЭЌЪБМЧТМСЫБЛаоИФдЊЫиЕФОЩжЕКЭаТжЕРДГЗЯњЮДЭъГЩЕФЪТЮёЃЌВЂжизівбЭъГЩЪТЮёЖЊЪЇЕФИФБфЁЃЛљгкетаЉШежОММЪѕЕФдРэЃЌЖЏЬЌБэПЩвдзЊЛЛГЩСНРрИќИФШежОСїЃКREDO СїКЭ REDO+UNDO СїЁЃ
ЭЈЙ§НЋБэжаЕФаоИФзЊЛЛЮЊСїЯћЯЂЃЌЖЏЬЌБэБЛзЊЛЛЮЊ redo+undo СїЁЃВхШыаоИФЩњГЩвЛЬѕаТааЕФВхШыЯћЯЂЃЌЩОГ§аоИФЩњГЩвЛЬѕОЩааЕФЩОГ§ЯћЯЂЃЌИќаТаоИФЩњГЩвЛЬѕОЩааЕФЩОГ§ЯћЯЂвдМАвЛЬѕаТааЕФВхШыЯћЯЂЁЃааЮЊШчЯТЭМЫљЪОЁЃ
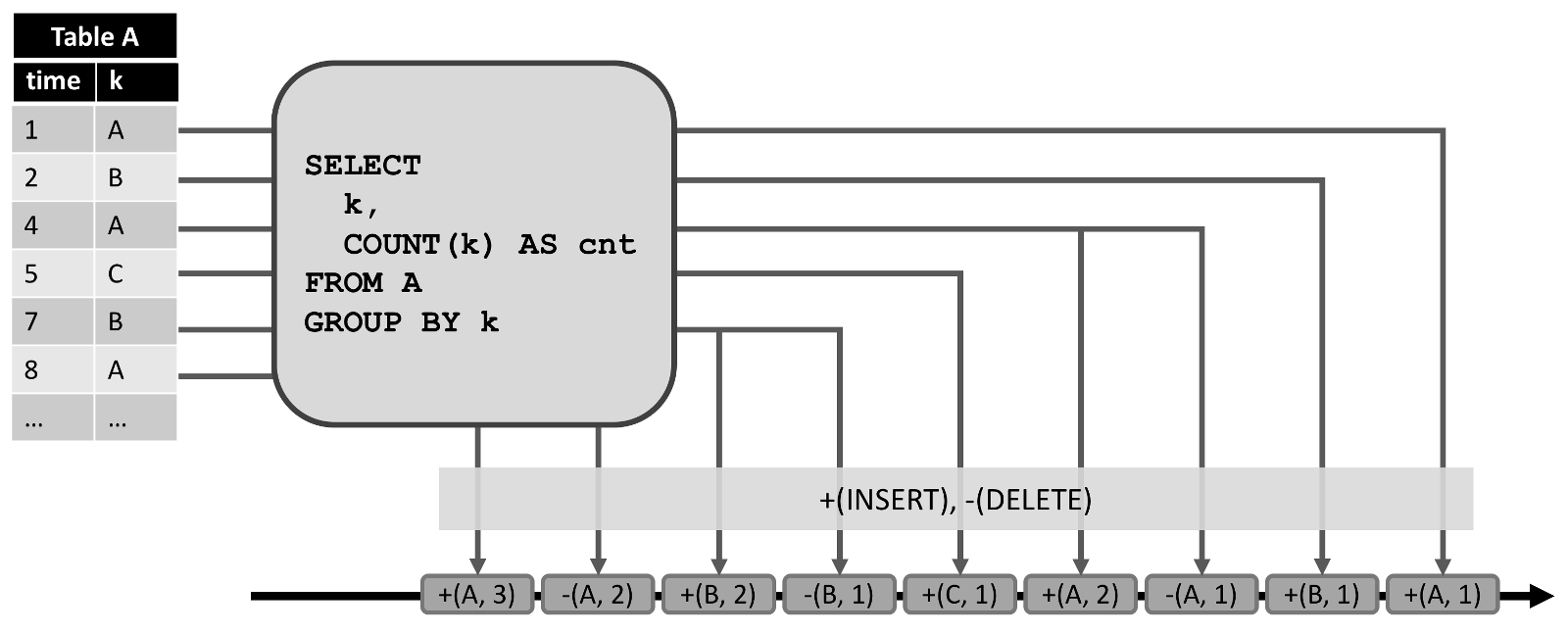
зѓВрЯдЪОСЫвЛИіЮЌЛЄдкИНМгФЃЪНЯТЕФЖЏЬЌБэЃЌзїЮЊжаМфВщбЏЕФЪфШыЁЃВщбЏЕФНсЙћзЊЛЛЮЊЯдЪОдкЕзВПЕФ redo+undo СїЁЃЪфШыБэЕФЕквЛЬѕМЧТМ (1,A) зїЮЊНсЙћБэЕФвЛЬѕаТМЭТМЃЌвђДЫВхШыСЫвЛЬѕЯћЯЂ +(A,1) ЕНСїжаЁЃЕкЖўЬѕЪфШыМЧТМ k=ЁЎAЁЏ(4,A) ЕМжТСЫНсЙћБэжа (A,1) МЧТМЕФИќаТЃЌДгЖјВњЩњСЫвЛЬѕЩОГ§ЯћЯЂ -(A,1) КЭвЛЬѕВхШыЯћЯЂ +(A,2)ЁЃЫљгаЕФЯТгЮВйзїЛђЪ§ОнЛузмЖМашвЊФмЙЛе§ШЗДІРэетСНжжРраЭЕФЯћЯЂЁЃ
дкСНжжЧщПіЯТЃЌЖЏЬЌБэЛсзЊЛЛГЩ redo СїЃКвЊУДЫќжЛЪЧвЛИіИНМгБэЃЈМДжЛгаВхШыаоИФЃЉЃЌвЊУДЫќгавЛИіЮЈвЛЕФМќЪєадЁЃЖЏЬЌБэЩЯЕФУПвЛИіВхШыаоИФЛсВњЩњвЛЬѕаТааЕФВхШыЯћЯЂЕН redo СїЁЃгЩгк redo СїЕФЯожЦЃЌжЛгаДјгаЮЈвЛМќЕФБэФмЙЛНјааИќаТКЭЩОГ§аоИФЁЃШчЙћвЛИіМќДгЖЏЬЌБэжаЩОГ§ЃЌвЊУДЪЧвђЮЊааБЛЩОГ§ЃЌвЊУДЪЧвђЮЊааЕФМќЪєаджЕБЛаоИФСЫЃЌЫљвдвЛЬѕДјгаБЛвЦГ§МќЕФЩОГ§ЯћЯЂЗЂЫЭЕН redo СїЁЃИќаТаоИФЩњГЩДјгаИќаТЕФИќаТЯћЯЂЃЌБШШчаТааЁЃгЩгкЩОГ§КЭИќаТаоИФИљОнЮЈвЛМќРДЖЈвхЃЌЯТгЮВйзїашвЊФмЙЛИљОнМќРДЗУЮЪжЎЧАЕФжЕЁЃЯТЭМеЙЪОСЫШчКЮНЋЩЯЪіЯрЭЌВщбЏЕФНсЙћБэзЊЛЛЮЊ redo СїЁЃ
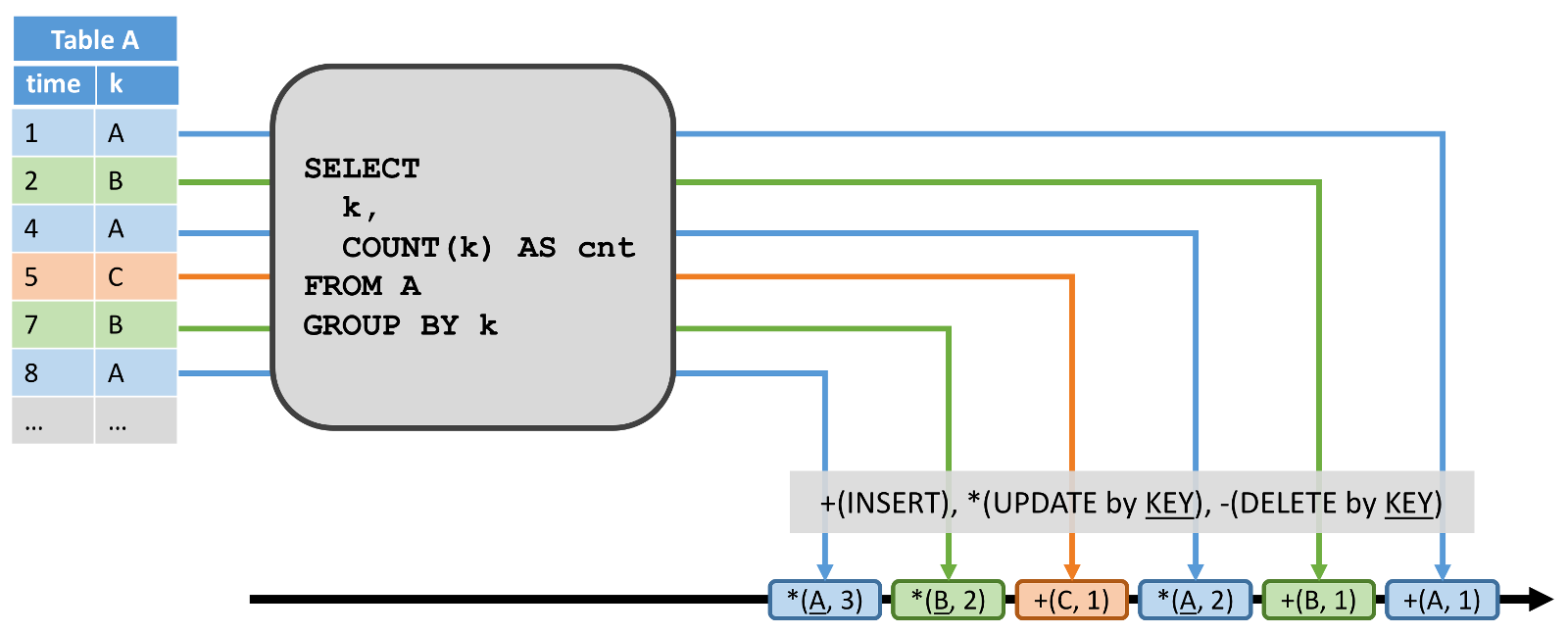
ВхШыЕНЖЏЬЌБэЕФ (1,A) ВњЩњСЫ +(A,1) ВхШыЯћЯЂЁЃВњЩњИќаТЕФ (4,A) ЩњГЩСЫ *(A,2) ЕФИќаТЯћЯЂЁЃ
Redo СїЕФЭЈГЃзіЗЈЪЧНЋВщбЏНсЙћаДЕННіИНМгЕФДцДЂЯЕЭГЃЌБШШчЙіЖЏЮФМўЛђеп Kafka жїЬтЃЌЛђепЪЧЛљгкМќЗУЮЪЕФЪ§ОнДцДЂЃЌБШШч CassandraЁЂЙиЯЕаЭ DBMS вдМАбЙЫѕЕФ Kafka жїЬтЁЃЛЙПЩвдЪЕЯжНЋЖЏЬЌБэзїЮЊСїгІгУЕФЙиМќЕФФкЧЖВПЗжЃЌРДЦРМлГжајВщбЏКЭЖдЭтВПЯЕЭГЕФВщбЏФмСІЃЌР§ШчвЛИівЧБэХЬгІгУЁЃ
ЧаЛЛЕНЖЏЬЌБэЗЂЩњЕФИФБф
дк 1.2 АцБОжаЃЌFlink ЙиЯЕ API ЕФЫљгаСїВйзїЃЌР§ШчЙ§ТЫКЭЗжзщДАПкОлКЯЃЌжЛЛсВњЩњаТааЃЌВЂЧвВЛФмИќаТЯШЧАЗЂВМЕФНсЙћЁЃ ЯрБШжЎЯТЃЌЖЏЬЌБэФмЙЛДІРэИќаТКЭЩОГ§аоИФЁЃ ЯждкФуПЩФмЛсЮЪздМКЃЌЕБЧААцБОЕФДІРэФЃЪНШчКЮгыаТЕФЖЏЬЌБэФЃаЭЯрЙиЃП API ЕФгявхЛсЭъШЋИФБфЃЌЮвУЧашвЊДгЭЗПЊЪМжиаТЪЕЯж APIЃЌвдДяЕНЫљашЕФгявхЃП
ЫљгаетаЉЮЪЬтЕФД№АИКмМђЕЅЁЃЕБЧАЕФДІРэФЃаЭЪЧЖЏЬЌБэФЃаЭЕФвЛИізгМЏЁЃ ЪЙгУЮвУЧдкетЦЊЮФеТжаНщЩмЕФЪѕгяЃЌЕБЧАЕФФЃаЭЭЈЙ§ИНМгФЃЪННЋСїзЊЛЛЮЊЖЏЬЌБэЃЌМДвЛИіЮоЯодіГЄЕФБэЁЃ гЩгкЫљгаВйзїНіНгЪмВхШыИќИФВЂдкЦфНсЙћБэЩЯЩњГЩВхШыИќИФЃЈМДЃЌВњЩњаТааЃЉЃЌвђДЫЫљгадкЖЏЬЌИНМгБэЩЯвбОжЇГжЕФВщбЏЃЌНЋЪЙгУжизіФЃаЭзЊЛЛЛи DataStreamsЃЌНігУгкИНМгБэЁЃ вђДЫЃЌЕБЧАФЃаЭЕФгявхБЛаТЕФЖЏЬЌБэФЃаЭЭъШЋИВИЧКЭБЃСєЁЃ
НсТлгыеЙЭћ
Flink ЕФЙиЯЕ API дкШЮКЮЪБКђЖМЗЧГЃЪЪКЯгУгкСїЗжЮігІгУЃЌВЂдкВЛЭЌЕФЩњВњЛЗОГжаЪЙгУЁЃдкетЦЊВЉЮФжаЃЌЮвУЧЬжТлСЫ Table API КЭ SQL ЕФЮДРДЁЃ етвЛХЌСІНЋЪЙ Flink КЭСїДІРэИќвзгкЗУЮЪЁЃ ДЫЭтЃЌгУгкВщбЏРњЪЗКЭЪЕЪБЪ§ОнЕФЭГвЛгявхвдМАВщбЏКЭЮЌЛЄЖЏЬЌБэЕФИХФюЃЌНЋФмЙЛЯдзХМђЛЏаэЖрСюШЫаЫЗмЕФгУР§КЭгІгУГЬађЕФЪЕЯжЁЃ етЦЊЮФеТзЈзЂгкСїКЭЖЏЬЌБэЕФЙиЯЕВщбЏЕФгявхЃЌЮвУЧУЛгаЬжТлВщбЏжДааЕФЯИНкЃЌАќРЈФкВПжДааГЗЯњЃЌДІРэКѓЦкЪТМўЃЌжЇГжНсЙћдЄРРЃЌвдМАБпНчПеМфвЊЧѓЁЃ
|









