| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫFlinkЕФЛљБОМмЙЙвдМАFlinkжДааЕФЛљБОдРэЃЌжиЕуЫЕУїСЫFlinkЪЕЯжИпадФмЕФвЛаЉЛљБОдРэЁЃ
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўLucaБрМЁЂЭЦМіЁЃ |
|
FlinkЪЧаТЕФstreamМЦЫув§ЧцЃЌгУjavaЪЕЯжЁЃМШПЩвдДІРэstream
dataвВПЩвдДІРэbatch dataЃЌПЩвдЭЌЪБМцЙЫSparkвдМАSpark streamingЕФЙІФмЃЌгыSparkВЛЭЌЕФЪЧЃЌFlinkБОжЪЩЯжЛгаstreamЕФИХФюЃЌbatchБЛШЯЮЊЪЧspecial
streamЁЃFlinkдкдЫаажажївЊгаШ§ИізщМўзщГЩЃЌJobClientЃЌJobManager КЭ TaskManagerЁЃжївЊЙЄзїдРэШчЯТЭМ
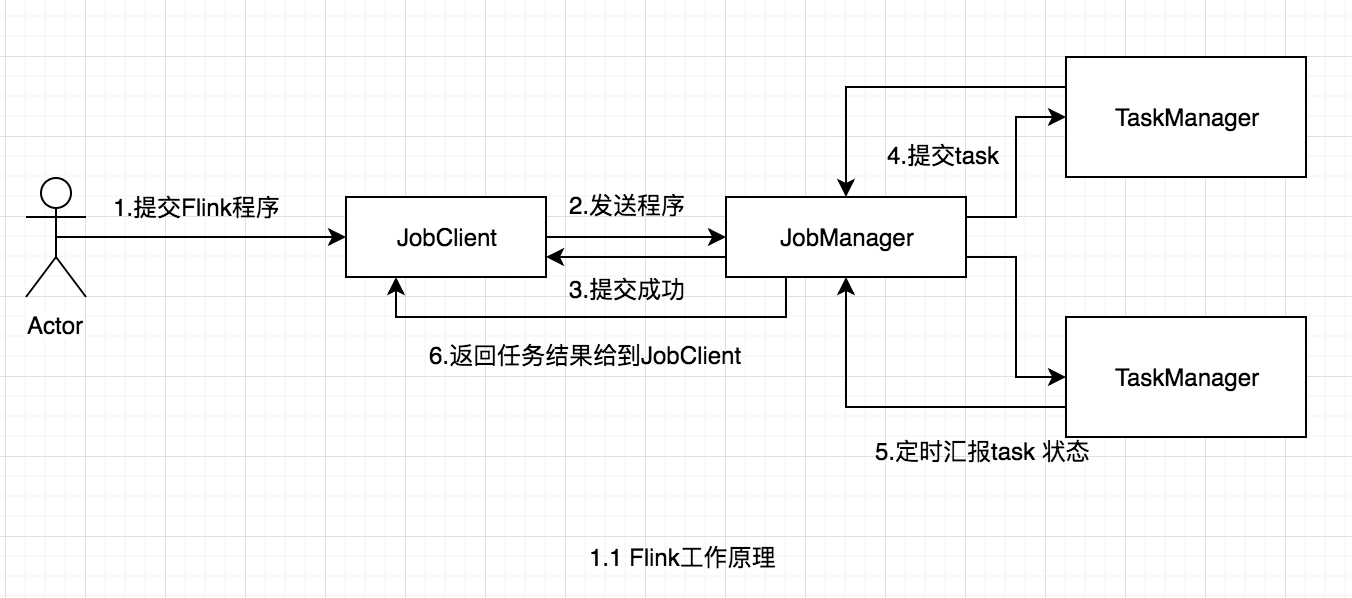
гУЛЇЪзЯШЬсНЛFlinkГЬађЕНJobClientЃЌОЙ§JobClientЕФДІРэЁЂНтЮіЁЂгХЛЏЬсНЛЕНJobManagerЃЌзюКѓгЩTaskManagerдЫааtaskЁЃ
JobClient
JobClientЪЧFlinkГЬађКЭJobManagerНЛЛЅЕФЧХСКЃЌжївЊИКд№НгЪеГЬађЁЂНтЮіГЬађЕФжДааМЦЛЎЁЂгХЛЏГЬађЕФжДааМЦЛЎЃЌШЛКѓЬсНЛжДааМЦЛЎЕНJobManagerЁЃЮЊСЫСЫНтFlinkЕФНтЮіЙ§ГЬЃЌашвЊМђЕЅНщЩмвЛЯТFlinkЕФOperatorЃЌдкFlinkжївЊгаШ§РрOperatorЃЌ
Source Operator ЃЌЙЫУћЫМвхетРрВйзївЛАуЪЧЪ§ОнРДдДВйзїЃЌБШШчЮФМўЁЂsocketЁЂkafkaЕШЃЌвЛАуДцдкгкГЬађЕФзюПЊЪМ
Transformation Operator етРрВйзїжївЊИКд№Ъ§ОнзЊЛЛЃЌmapЃЌflatMapЃЌreduceЕШЫузгЖМЪєгкTransformation
OperatorЃЌ
Sink OperatorЃЌвтЫМЪЧЯТГСВйзїЃЌетРрВйзївЛАуЪЧЪ§ОнТфЕиЃЌЪ§ОнДцДЂЕФЙ§ГЬЃЌЗХдкJobзюКѓЃЌБШШчЪ§ОнТфЕиЕНHdfsЁЂMysqlЁЂKafkaЕШЕШЁЃ
FlinkЛсНЋГЬађжаУПвЛИіЫуМЦНтЮіГЩOperatorЃЌШЛКѓАДееЫузгжЎМфЕФЙиЯЕЃЌНЋoperatorзщКЯЦ№РДЃЌаЮГЩвЛИіOperatorзщКЯГЩЕФGraphЁЃШчЯТУцЕФДњТыНтЮіжЎКѓаЮГЩЕФжДааМЦЛЎЃЌ
DataStream<String>
data = env.addSource(...);
data.map(x->new Tuple2(x,1)).keyBy(0).timeWindow
(Time.seconds(60)).sum(1).addSink(...) |
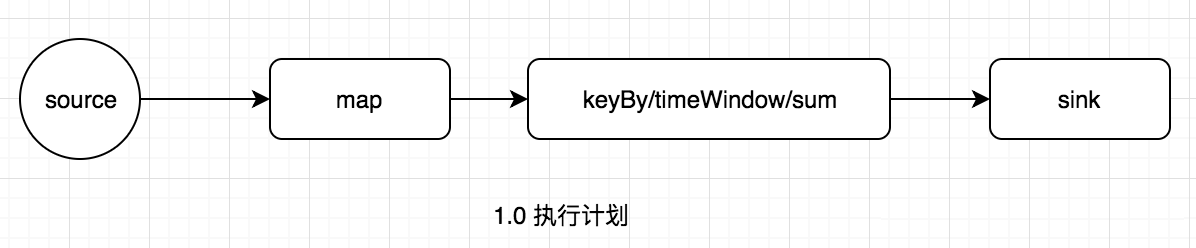
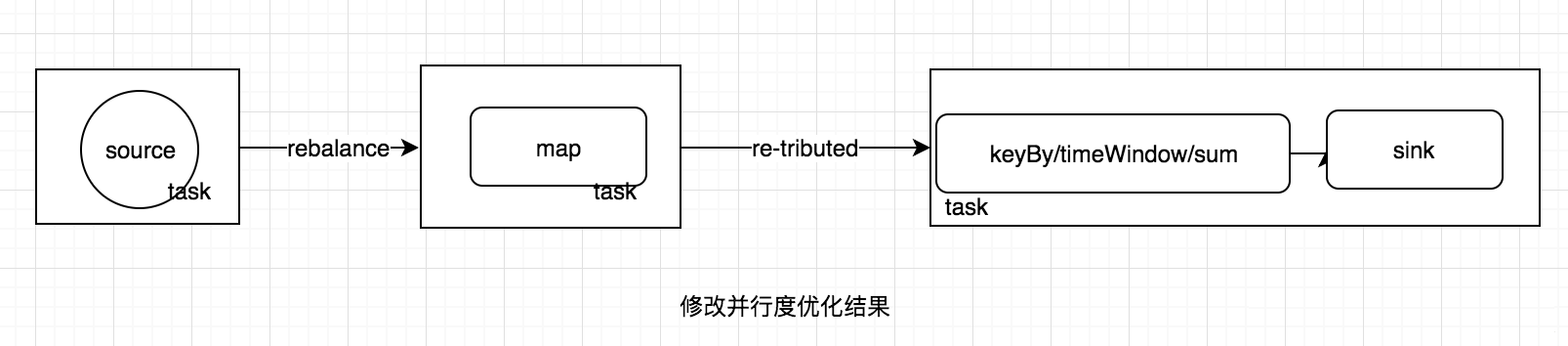
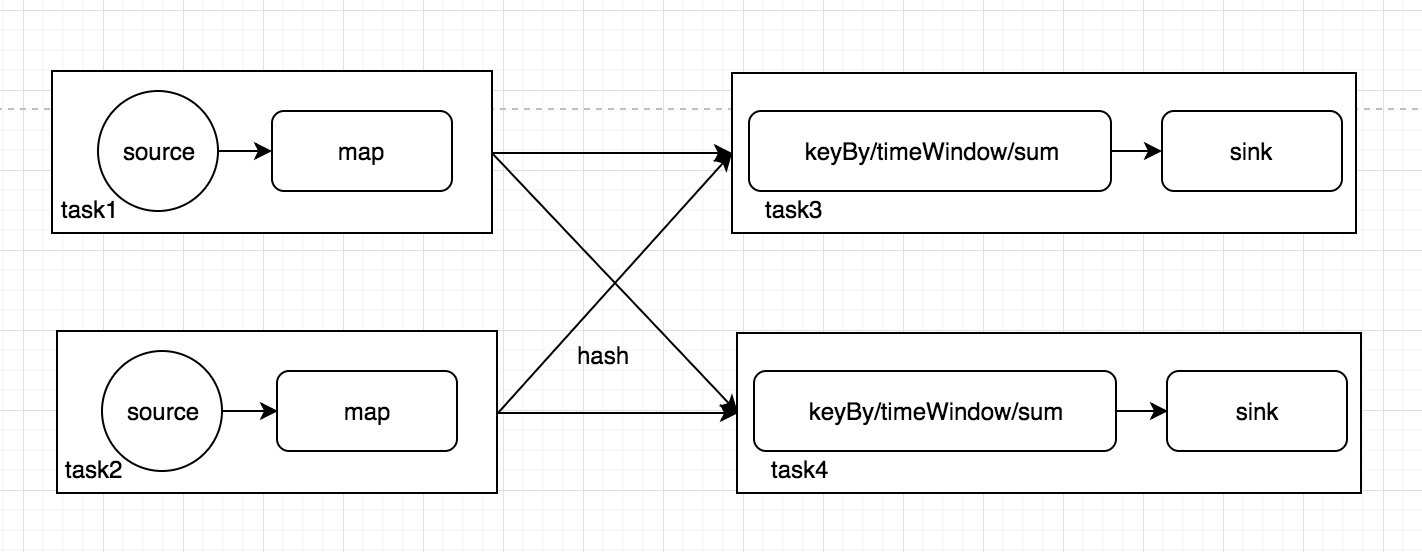
НтЮіаЮГЩжДааМЦЛЎжЎКѓЃЌJobClientЕФШЮЮёЛЙУЛгаЭъЃЌЛЙИКд№жДааМЦЛЎЕФгХЛЏЃЌетРяжДааЕФжївЊгХЛЏЪЧНЋЯрСкЕФOperatorШкКЯЃЌаЮГЩOperatorChainЃЌвђЮЊFlinkЪЧЗжВМЪНдЫааЕФЃЌГЬађжаУПвЛИіЫузгЃЌдкЪЕМЪжДаажаБЛЗжИєЮЊЖрИіSubTaskЃЌЪ§ОнСїдкЫузгжЎМфЕФСїЖЏЃЌОЭЖдгІЕНSubTaskжЎМфЕФЪ§ОнДЋЕнЃЌSubTaskжЎМфНјааЪ§ОнДЋЕнФЃЪНгаСНжжвЛжжЪЧone-to-oneЕФЃЌЪ§ОнВЛашвЊжиаТЗжВМЃЌвВОЭЪЧЪ§ОнВЛашвЊОЙ§IOЃЌНкЕуБОЕиОЭФмЭъГЩЃЌБШШчЩЯЭМжаЕФsourceЕНmapЃЌвЛжжЪЧre-distributedЃЌЪ§ОнашвЊЭЈЙ§shuffleЙ§ГЬжиаТЗжЧјЃЌашвЊОЙ§IOЃЌБШШчЩЯЭМжаЕФmapЕНkeyByЁЃЯдШЛre-distributedетжжФЃЪНИќМгРЫЗбЪБМфЃЌЭЌЪБгАЯьећИіJobЕФадФмЁЃЫљвдЃЌFlinkЮЊСЫЬсИпадФмЃЌНЋone-to-oneЙиЯЕЕФЧАКѓСНРрsubtaskЃЌШкКЯаЮГЩвЛИіtaskЁЃЖјTaskManagerжавЛИіtaskдЫаавЛИіЖРСЂЕФЯпГЬжаЃЌЭЌвЛИіЯпГЬжаЕФSubTaskНјааЪ§ОнДЋЕнЃЌВЛашвЊОЙ§IOЃЌВЛашвЊОЙ§ађСаЛЏЃЌжБНгЗЂЫЭЪ§ОнЖдЯѓЕНЯТвЛИіSubTaskЃЌадФмЕУЕНЬсЩ§ЃЌГ§ДЫжЎЭтЃЌsubTaskЕФШкКЯПЩвдМѕЩйtaskЕФЪ§СПЃЌЬсИпtaskManagerЕФзЪдДРћгУТЪЁЃЭМ1.0жаЕФжДааМЦЛЎЃЌгХЛЏНсЙћШчЯТЭМЃЌFlinkЕФsubTaskШкКЯЙцдђПЩвдВЮПМЙйЗНЮФЕЕЁЃ
жЕЕУзЂвтЕФЪЧЃЌВЂВЛЪЧУПвЛИіSubTaskЖМПЩвдБЛШкКЯЃЌЖдгкВЛФмШкКЯЕФSubTaskЛсЖРСЂаЮГЩвЛИіTaskдЫаадкTaskManagerжаЁЃ
ИФБфoperatorЕФВЂааЖШЃЌПЩФмЛсЕМжТВЛЭЌЕФгХЛЏНсЙћЃЌЭЌЪБетвВЪЧадФмЕїгХЕФвЛИіживЊЗНЪНЃЌР§ШчВЛЯдЪНЩшжУoperatorЕФВЂааЖШЕФЪБКђЃЌФЌШЯЫљгаЫузгЕФВЂааЖШЪЧвЛбљЕФЃЌЫљвдЛсгаЯТЭМжаЕФгХЛЏНсЙћЁЃ

ЮвУЧРДЗжЮівЛЯТФЌШЯЧщПіЯТПЩФмЗЂЩњЕФЮЪЬтЃЌМйШчЩшжУзївЕЕФВЂааЖШЮЊ10ЃЌsourceУїШЗЮЊkafkaЃЌЖдгІtopicжЛгавЛИіtopicЃЌвђЮЊsourceФЌШЯЛсИљОнtopicЕФЗжЧјЪ§ЃЌОіЖЈздМКЕФЗжЧјЪ§ЃЌФЧУД10Иіsource
subtaskжЛгавЛИіЛсЙЄзїЃЌЖјЧвШЮЮёБШНЯжиЁЃетбљЛсЕМжТКѓУцЕФmapЪЕМЪвВЪЧгавЛИіsubTaskдкЙЄзїЃЌДІРэЫљгаЕФЪ§ОнЃЌМйШчmapжаЕФШЮЮёБШНЯжиЃЌФЧУДЛсЕМжТЪ§ОнЧуаБЃЌадФмЕЭЯТЁЃдкsourceВЛФмИФдьЕФЧщПіЯТЃЌЮвУЧЯдЪНМѕЩйsourceЕФВЂааЖШЃЈЮЊСЫНкЪЁзЪдДЃЌЩшжУ1ЃЉЃЌЬсИпmapЕФВЂааЖШЃЈдіМгДІРэЫйЖШЃЌЩшЮЊ20ЃЉЁЃЕквЛблПДЩЯШЅЃЌИаОѕадФмЬсЩ§СЫВЛЩйЃЌЕЋЪЧдкЪЕМЪЧщПіжаШДВЛвЛЖЈетбљЁЃвђЮЊЕїећsourceКЭmapЕФВЂЗЂЖШЃЌЪЇШЅСЫдгаone-to-oneЪ§ОнДЋЕнЕФгХЪЦЃЌЕМжТsubTaskВЛФмШкКЯЃЌЪ§ОнашвЊreblanceЃЌВњЩњДѓСПЕФIOЃЌЫљвдаоИФВЂааЖШвВВЛвЛЖЈПЩвдЬсЩ§адФмЁЃаоИФВЂааЖШжЎКѓЃЌжДааМЦЛЎЕФгХЛЏНсЙћШчЯТЭМЁЃЫљвддкЪЕМЪгХЛЏЕФЙ§ГЬжаЃЌЛЙЪЧвЊзЂвтНсКЯЪ§ОнЗжВМКЭжДааМЦЛЎЕїгХЃЌРэНтFlinkжДааМЦЛЎЕФЩњГЩЙ§ГЬКмгаБивЊЁЃ
JobManager
JobManagerЪЧвЛИіНјГЬЃЌжївЊИКд№ЩъЧызЪдДЃЌаЕївдМАПижЦећИіjobЕФжДааЙ§ГЬЃЌОпЬхАќРЈЃЌЕїЖШШЮЮёЁЂДІРэcheckpointЁЂШнДэЕШЕШЃЌдкНгЪеЕНJobClientЬсНЛЕФжДааМЦЛЎжЎКѓЃЌеыЖдЪеЕНЕФжДааМЦЛЎЃЌМЬајНтЮіЃЌвђЮЊJobClientжЛЪЧаЮГЩвЛИіoperaorВуУцЕФжДааМЦЛЎЃЌЫљвдJobManagerМЬајНтЮіжДааМЦЛЎЃЈИљОнЫузгЕФВЂЗЂЖШЃЌЛЎЗжtaskЃЉЃЌаЮГЩвЛИіПЩвдБЛЪЕМЪЕїЖШЕФгЩtaskзщГЩЕФЭиЦЫЭМЃЌШчЩЯЭМБЛНтЮіжЎКѓаЮГЩЯТЭМЕФжДааМЦЛЎЃЌзюКѓЯђМЏШКЩъЧызЪдДЃЌвЛЕЉзЪдДОЭаїЃЌОЭЕїЖШtaskЕНTaskManagerЁЃ
ЮЊСЫБЃжЄИпПЩгУЃЌвЛАуЛсгаЖрИіJobManagerНјГЬЭЌЪБДцдкЃЌЫќУЧжЎМфвВЪЧВЩгУжїДгФЃЪНЃЌвЛИіНјГЬБЛбЁОйЮЊLeaderЃЌЦфЫћНјГЬЮЊfollowerЁЃJobдЫааЦкМфЃЌжЛгаLeaderдкЙЄзїЃЌfollowerдкЯажУЃЌвЛЕЉLeaderЙвЕєЃЌЫцМДв§ЗЂвЛДЮбЁОйЃЌВњЩњаТЕФLeaderМЬајДІРэJobЁЃJobManagerГ§СЫЕїЖШШЮЮёЃЌСэЭтвЛИіжївЊЙЄзїОЭЪЧШнДэЃЌжївЊвРППcheckpointНјааШнДэЃЌcheckpointЦфЪЕЪЧstreamвдМАexecutorЃЈTaskManagerжаЕФSlotЃЉЕФПьееЃЌвЛАуНЋcheckpointБЃДцдкПЩППЕФДцДЂжаЃЈБШШчhdfsЃЉЃЌЮЊСЫШнДэFlinkЛсГжајНЈСЂетРрПьееЁЃЕБFlinkзївЕжиаТЦєЖЏЕФЪБКђЃЌЛсбАевзюаТПЩгУЕФcheckpointРДЛжИДжДаазДЬЌЃЌвбДяЕНЪ§ОнВЛЖЊЪЇЃЌВЛжиИДЃЌзМШЗБЛДІРэвЛДЮЕФгявхЁЃвЛАуЧщПіЯТЃЌЖМВЛЛсгУЕНcheckpointЃЌжЛгадкЪ§ОнашвЊЛ§РлЛђДІРэРњЪЗзДЬЌЕФЪБКђЃЌВХашвЊЩшЖЈcheckpointЃЌБШШчupdateStateByKeyетИіЫузгЃЌФЌШЯЛсЦєгУcheckpointЃЌШчЙћУЛгаХфжУcheckpointФПТМЕФЛАЃЌГЬађЛсХзвьГЃЁЃ
TaskManager
TaskManagerЪЧвЛИіНјГЬЃЌМАвЛИіJVMЃЈFlinkгУjavaЪЕЯжЃЉЁЃжївЊзїгУЪЧНгЪеВЂжДааJobManagerЗЂЫЭЕФtaskЃЌВЂЧвгыJobManagerЭЈаХЃЌЗДРЁШЮЮёзДЬЌаХЯЂЃЌБШШчШЮЮёЗжжДаажаЃЌжДааЭъЕШзДЬЌЃЌЩЯЮФЬсЕНЕФcheckpointЕФВПЗжаХЯЂвВЪЧTaskManagerЗДРЁИјJobManagerЕФЁЃШчЙћЫЕJobManagerЪЧmasterЕФЛАЃЌФЧУДTaskManagerОЭЪЧworkerжївЊгУРДжДааШЮЮёЁЃдкTaskManagerФкПЩвддЫааЖрИіtaskЁЃЖрИіtaskдЫаадквЛИіJVMФкгаМИИіКУДІЃЌЪзЯШtaskПЩвдЭЈЙ§ЖрТЗИДгУЕФЗНЪНTCPСЌНгЃЌЦфДЮtaskПЩвдЙВЯэНкЕужЎМфЕФаФЬјаХЯЂЃЌМѕЩйСЫЭјТчДЋЪфЁЃTaskManagerВЂВЛЪЧзюЯИСЃЖШЕФИХФюЃЌУПИіTaskManagerЯёвЛИіШнЦївЛбљЃЌАќКЌвЛИіЖрЛђЖрИіSlotЃЌШчЭМ1.2ЁЃ
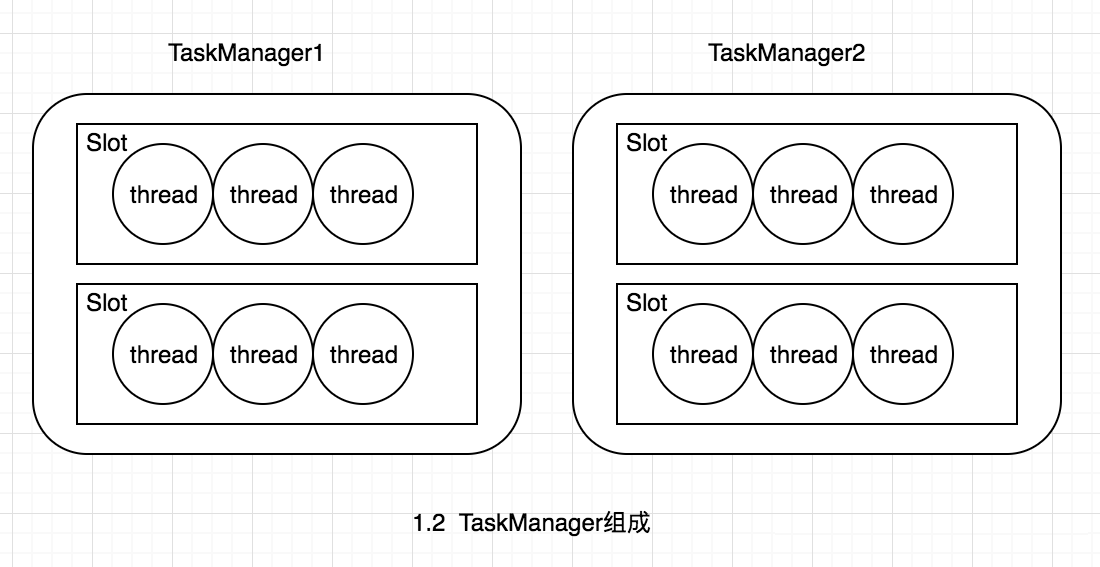
SlotЪЧTaskManagerзЪдДСЃЖШЕФЛЎЗжЃЌУПИіSlotЖМгаздМКЖРСЂЕФФкДцЁЃЫљгаSlotЦНОљЗжХфTaskMangerЕФФкДцЃЌБШШчTaskManagerЗжХфИјSoltЕФФкДцЮЊ8GЃЌСНИіSlotЃЌУПИіSlotЕФФкДцЮЊ4GЃЌЫФИіSlotЃЌУПИіSlotЕФФкДцЮЊ2GЃЌжЕЕУзЂвтЕФЪЧЃЌSlotНіЛЎЗжФкДцЃЌВЛЩцМАcpuЕФЛЎЗжЁЃЭЌЪБSlotЪЧFlinkжаЕФШЮЮёжДааЦїЃЈРрЫЦStormжаExecutorЃЉЃЌУПИіSlotПЩвддЫааЖрИіtaskЃЌЖјЧввЛИіtaskЛсвдЕЅЖРЕФЯпГЬРДдЫааЁЃSlotжївЊЕФКУДІгавдЯТМИЕуЃК
ПЩвдЦ№ЕНИєРыФкДцЕФзїгУЃЌЗРжЙЖрИіВЛЭЌjobЕФtaskОКељФкДцЁЃ
SlotЕФИіЪ§ОЭДњБэСЫвЛИіFlinkГЬађЕФзюИпВЂааЖШЃЌМђЛЏСЫадФмЕїгХЕФЙ§ГЬ
дЪаэЖрИіTaskЙВЯэSlotЃЌЬсЩ§СЫзЪдДРћгУТЪЃЌОйвЛИіЪЕМЪЕФР§згЃЌkafkaга3ИіpartitionЃЌЖдгІflinkЕФsourceга3ИіtaskЃЌЖјkeyByЮвУЧЩшжУЕФВЂааЖШЮЊ20ЃЌетИіЪБКђШчЙћSlotВЛФмЙВЯэЕФЛАЃЌашвЊеМгУ23ИіSlotЃЌШчЙћдЪаэЙВЯэЕФЛАЃЌФЧУДжЛашвЊ20ИіSlotМДПЩЃЈSlotЕФФЌШЯЙВЯэЙцдђМЦЫуЮЊ20ИіЃЉЁЃ
ЙВЯэSlotЃЌЫфШЛдкflinkжадЪаэtaskЙВЯэSlotЬсЩ§зЪдДРћгУТЪЃЌЕЋЪЧШчЙћвЛИіSlotжаШнФЩЙ§ЖрtaskЗДЖјЛсдьГЩзЪдДЕЭЯТЃЈБШШчМЋЖЫЧщПіЯТЫљгаtaskЖМЗжВМдквЛИіSlotФкЃЉЃЌдкFlinkжаtaskашвЊАДеевЛЖЈЙцдђЙВЯэSlotЁЃЙВЯэSlotЕФЗНЪНгаСНжжЃЌSlotShardingGroupКЭCoLocationGroupЃЌCoLocationGroupетжжЗНЪНФПЧАЛЙУЛгаНгДЅЙ§ЃЌШчЙћИааЫШЄПЩвдВщдФЙйЗНЮФЕЕЁЃЯТУцжївЊНщЩмвЛЯТSlotShardingGroupЕФгУЗЈЃЌетжжЙВЯэЕФЛљБОЫМТЗОЭЪЧИјoperatorЗжзщЃЌЭЌвЛзщЕФВЛЭЌoperatorЕФtaskЃЌПЩвдЙВЯэвЛИіSlotЁЃФЌШЯЫљгаЕФoperatorЪєгкЭЌвЛИізщЁАdefaultЁБЃЌМАЫљгаoperatorЕФtaskПЩвдЙВЯэвЛИіSlotЃЌПЩвдИјoperatorЩшжУВЛЭЌЕФgroupЃЌЗРжЙВЛКЯРэЕФЙВЯэЁЃFlinkдкЕїЖШtaskЗжХфSlotЕФЪБКђгаСНИіживЊддђЃК
ЭЌвЛИіjobжаЃЌЭЌвЛИіgroupжаВЛЭЌoperatorЕФtaskПЩвдЙВЯэвЛИіSlot
FlinkЪЧАДееЭиЦЫЫГађДгSourceвРДЮЕїЖШЕНSinkЕФ
ЛЙФУЩЯЪіЕФР§згРДЫЕУїSlotЙВЯэвдМАtaskЕїЖШЕФдРэЃЌШчЭМ1.3МйЩшгаСНИіTaskManagerЃЈTaskManager1КЭTaskManager2ЃЉЃЌУПИіTaskManagerга2ИіSlotЃЈSlot1КЭSlot2ЃЉЁЃЮЊСЫЗНБуРэНтSlotЙВЯэЕФСїГЬашвЊЬсЧАЖЈвхoperatorЕФВЂЗЂЖШЃЌРДОіЖЈtaskЕФЕїЖШЫГађЁЃМйЩшsource/mapЕФВЂЗЂЖШЮЊ2ЃЌkeyBy/window/sinkЕФВЂЗЂЖШЮЊ4ЃЌФЧУДЕїЖШЕФЫГађвРДЮЮЊsource/map[1]
->source/map[2] ->keyBy/window/sink[1]->keyBy/window/sink[2]->keyBy/window/sink[3]->keyBy/window/sink[4]ЁЃШчЭМ1.3ЮЊСЫБугкЫЕУїСїГЬЃЌНЋsource/mapЕФВЂЗЂЖШЩшЮЊ4ЃЌkeyBy/window/sinkЕФВЂЗЂЖШЩшЮЊ4ЁЃФЧУДЪзЯШЗжХфtask
source/map[1]ЃЌетИіЪБКђSlotжаЛЙУЛгаtaskЃЌЗжХфЕНTaskManager1жаЃЌШЛКѓЗжХфsource/map[2]ЃЌИљОнSlotЙВЯэЙцдђЃЌsource/map[1]КЭsource/map[2]
ЪєгкЭЌвЛoperatorЕФВЛЭЌtaskЃЌЫљвдsource/map[2]ВЛФмЙВЯэSlot1ЃЌБЛЗжХфЕНTaskManager1ЕФSlot2ЃЌsource/map[3]КЭsource/map[4]ЭЌбљЛсвРДЮЗжХфВЛЭЌЕФSlotЃЌНгЯТРДЗжХфkeyBy/window/sink[1],ИљОнSlotЙВЯэЙцдђЃЌЫќПЩвдКЭsource/map[1]ЃЌЙВЯэЭЌвЛИіslotЃЌЫљвдвВБЛЗжХфЕНTaskManager1ЕФSlot1жаЃЌkeyBy/window/sinkЕФЦфЫћШЮЮёвРДЮБЛЗжХфЕНВЛЭЌSlotжаЁЃЭМ1.4ЮЊВЂааЖШЗжБ№ЩшжУЮЊ2КЭ4ЕФЗжХфЙ§ГЬЃЌетРяВЛдйеЙПЊЫЕУїЁЃ 
змНс
ЩЯЪіФкШнЃЌжївЊНщЩмСЫЃЌFlinkЕФЛљБОМмЙЙвдМАFlinkжДааЕФЛљБОдРэЃЌжиЕуЫЕУїСЫFlinkЪЕЯжИпадФмЕФвЛаЉЛљБОдРэЃЌвђЮЊаДЕФБШНЯДвУІЃЌШчгаДэЮѓжЎДІЃЌЛЖгДѓМвЦРТлжИе§ЁЃ |









