| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫРћгУSpark
GraphxЪЕЯжСЫвЛИіМђЕЅЕФСЌЭЈЭМЩчШКЗЂЯжЪОР§ЃЌВЂНЋЩчШКДцШыЕНЭМЪ§ОнПтNeo4jжаЃЌЭЌЪБНјвЛВННщЩмСЫNeo4jЕФвЛаЉИХФюКЭЪЙгУЃЌзюКѓгУNeo4jбнЪОСЫвЛИіЩчНЛЭјТчЕФЭММьЫїЪОР§ЁЃ
БОЮФРДздгкЮЂаХЃЌгЩЛ№СњЙћШэМўчїчїБрМЁЂЭЦМіЁЃ |
|
жаЙњгаОфРЯЛАЃЌНаЮявдРрОлЃЌШЫвдШКЗжЃЌдкЗДзїБзКЭЪаГЁгЊЯњЕШгІгУжаЃЌШчЙћЮвУЧФмИљОнгУЛЇМфЕФФГаЉСЊЯЕЗЂЯжЩчШКЃЌШЛКѓЖдетаЉЩчШКНјааЗДзїБзЗжЮіЛђЩЬЦЗЭЦМіЃЌЭљЭљЛсЦ№ЕНвтЯыВЛЕНЕФаЇЙћЁЃ
БОЮФОЭРДНщЩмвЛИіМђЕЅЕФЩчШКЗЂЯжЕФЪЕМљЁЃЙЙНЈЩчШКЮвУЧЪзЯШашвЊевЕНЩчШКгУЛЇЕФФГжжСЊЯЕЃЌЩЯЮФЬсЕНЕФЪеЭНФЃЪНБОЩэОЭЪЧгУЛЇМфЕФвЛИіЬьШЛСЊЯЕЃЌЮвУЧПЩвдИљОнгУЛЇЕФЪІЭНЙиЯЕРДЙЙНЈЩчШКЁЃШчЯТЭМЫљЪОЃЌИљОнЪІЭНЙиЯЕЮвУЧЙЙНЈСЫвЛИіЩчШКЃЌЕуБэЪОгУЛЇЃЌБпБэЪОЪІЭНЙиЯЕЁЃ

гаСЫетбљЕФЩчШКжЎКѓЃЌЮвУЧОЭПЩвдЛљгкЩчШКЮЌЖШЗжЮіЩшБИМАгУЛЇааЮЊЕФвьГЃЃЌБШШчЕЅИіЩшБИЕЧТНЙ§ЖрЕФгУЛЇЃЌЩшБИвЛжБДІгкГфЕчзДЬЌЃЌЫљгагУЛЇааЮЊИпЖШвЛжТЕШЃЌЭЌЪБПЩвдМЦЫуЩчШКгУЛЇзїБзТЪРДЭЈЙ§вбжЊзїБзгУЛЇРДЗЂЯжаТЕФзїБзгУЛЇЁЃ
РэЧхСЫашЧѓжЎКѓЮвУЧПЊЪМзХЪжИљОнгУЛЇЪІЭНЙиЯЕЙЙНЈЩчШКЁЃЖдЁАНєУмСЊЯЕЁБЕФВЛЭЌРэНтВњЩњСЫКмЖрЩчЧјЗЂЯжЫуЗЈЁЃЯТЭМЪЧМИжжОЕфЕФЩчШКЗЂЯжЫуЗЈЁЃ
ЩчШКЫуЗЈ
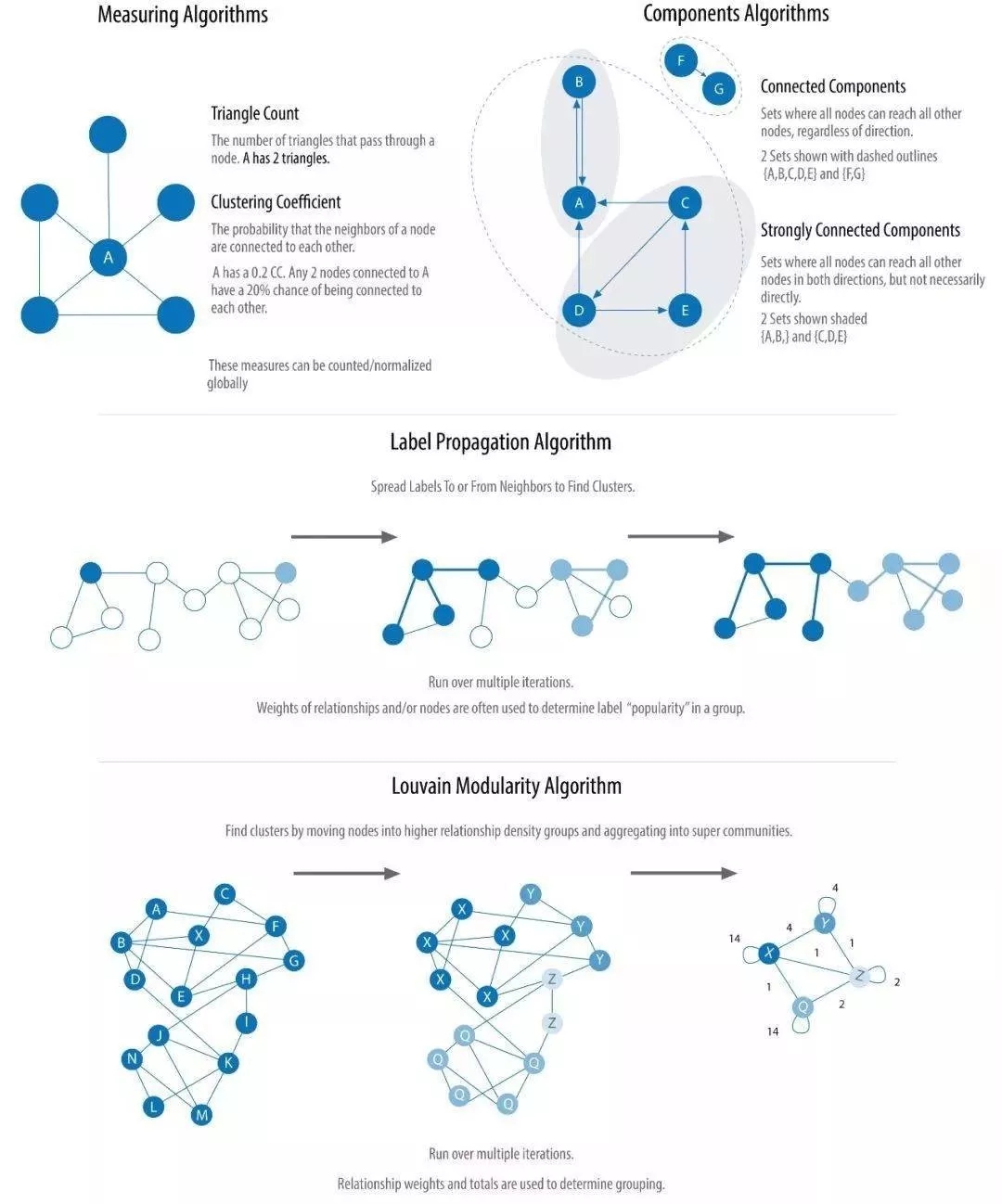
Triangle CountingЃКШ§НЧЙиЯЕЃЌЭМТлЛљДЁжЊЪЖЁЃ
Connected ComponentsЃКСЌЭЈЭМЃЌЭМТлЛљДЁжЊЪЖЁЃ
Strongly Connected ComponentsЃКЧПСЌЭЈЭМЃЌЭМТлЛљДЁжЊЪЖЁЃ
Label PropagationЃКБъЧЉДЋВЅЫуЗЈЁЃ
LouvainЃКвЛжжЛљгкЁАФЃПщЖШЁБЕФОЕфЫуЗЈЁЃ
вђЮЊБОЮФжиЕуВЛЪЧНВЪіЩчШКЗЂЯжЫуЗЈЃЌЫљвдетИіЫуЗЈОпЬхЕФКЌвхДЫДІТдЙ§ЃЌгаИааЫШЄЕФЖСепПЩздаабаОПЁЃБОЮФбЁгУСЫзюМђЕЅЕФСЌЭЈЭМЫуЗЈРДЪЕЯжЩчШКЗЂЯжЃЌМДжЛвЊСНИіНкЕужЎМфгаБпЮвУЧОЭАбЫќУЧЙщЪєЮЊвЛИіЩчШКЁЃЯТУцЮвУЧНјШыИљОнгУЛЇЪІЭНЙиЯЕЩњГЩЩчШКНзЖЮЁЃ
Spark GraphxЙЙНЈЩчШК
Spark GraphxБОЩэОЭЬсЙЉСЫЙЙНЈЭМВЂЩњГЩСЌЭЈЭМЕФНгПкЃЌЮвУЧжЛашвЊАДвЊЧѓЪфШыЪ§ОнОЭКУСЫЁЃШчЯТЭМЫљЪОЃК
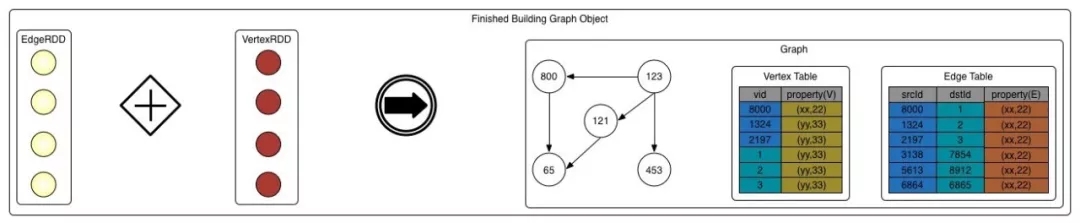
ЮвУЧЙЙНЈЕуКЭБпЃЌШЛКѓЕїгУGraphxНгПкЩњГЩЭМЃЌзюКѓЕїгУЭМЕФНгПкжБНгЛёШЁСЌЭЈЭМЁЃашвЊзЂвтЕФЪЧЃЌSpark GraphxЙЙНЈЕуКЭБпЪБЃЌidашвЊгУLongРраЭЕФЪ§зжБэЪОЃЌЫљвдЮвУЧашвЊЮЌЛЄвЛеХгУЛЇidЕНЪ§зжidЕФЮЌБэЁЃ
//ЙЙНЈгУЛЇНкЕу
val users: RDD[(VertexId, String)] =
spark.sparkContext.parallelize(Array((3L, "u3"),
(7L, "u7"),(5L, "u5"), (2L,
"u2"), (4L, "u4"),(6L, "u6"),(8L,
"u8")))
//ЙЙНЈгУЛЇБп
val relationships: RDD[Edge[String]] =
spark.sparkContext.parallelize(Array(Edge(7L,
3L,""),
Edge(5L, 3L,""),Edge(5L,
2L,""),
Edge(6L, 4L,""),Edge(8L,
6L,"")))
//зщКЯНкЕуКЭБпЙЙНЈЭМ
val graph = Graph(users, relationships)
//ДгЭМжаГщШЁГіСЌЭЈЭМ
val components = graph.connectedComponents()
//ЛёШЁСЌЭЈЭМжаЕФЕуЃЌverticesЪЧвЛИіtupleРраЭЃЌ
keyЗжБ№ЮЊЫљгаЕФЖЅЕуidЃЌ
valueЮЊkeyЫљдкЕФСЌЭЈЭМid(СЌЭЈЭМжаЖЅЕуidзюаЁжЕ)
val vertices = components.vertices |
ЕУЕНЕФverticesЪЧШчЯТЕФk-vЪ§ОнЃК
/**
* verticesЃК
* (6,4)
* (8,4)
* (3,2)
* (7,2)
* (5,2)
*
* ЪЧвЛИіtupleРраЭЃЌkeyЗжБ№ЮЊЫљгаЕФЖЅЕуidЃЌ
valueЮЊkeyЫљдкЕФСЌЭЈЭМid(СЌЭЈЭМжаЖЅЕуidзюаЁжЕ)
*/ |
GraphStream: гУгкЛГіЭјТчЭМ
BreezeViz: гУЛЇЛцжЦЭМЕФНсЙЙЛЏаХЯЂ, БШШчЖШЕФЗжВМ.
ШЛКѓЮвУЧНЋБпrelationshipsгыverticesЧѓГіУПЬѕБпЫљдкСЌЭЈЭМРяЖЅЕуidзюаЁжЕЁЃ
val result =
relationships.map(x =>{
(x.srcId,x.dstId.toString)
}).join(vertices)
.map(y =>{
// (7,(3,2)) => (2,(7,3))
(y._2._2,(y._1,y._2._1))
}) |
ЮвУЧНЋНсЙћДцШыЭМЪ§ОнNeo4jЃЌПЩЪгЛЏКѓШчЯТЫљЪОЃЌПЩвдПДЕНЮвУЧЕУЕНСЫСНИіЩчШКЁЃ
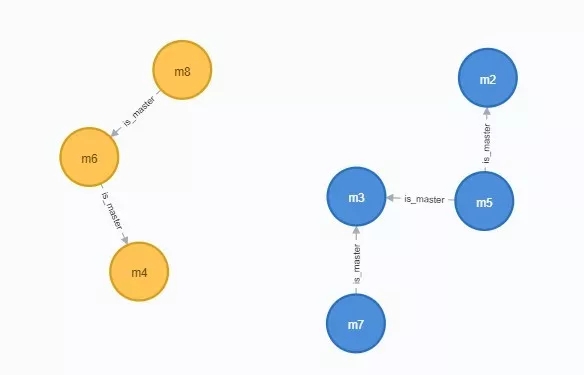
жСДЫЃЌЮвУЧРћгУSpark GraphxЙЙНЈГіСЫЩчШКЃЌУПИіЩчШКЖМгаздМКЕФвЛИіЩчШКidЃЌШЛКѓЮвУЧОЭПЩвдЛљгкЩчШКзівЛаЉОпЬхЗжЮіСЫЃЌБШШчЃЌЮвПЩвдМЦЫуЩчШКзїБзТЪЃЌВЂШЁГіTOP NЕФЩчШКЃЌШчЯТЫљЪОЁЃ 
ЩЯУцжЛЪЧвЛИіМђЕЅЕФЪОР§ЃЌЦфЪЕЮвУЧПЩвдИјЕуКЭБпМгЩЯИќЖрЕФЪєадЃЌРћгУЭМЕФЬиадНјааМьЫїЃЌПЩвдИќИпаЇЕФМьЫїГіИќЖрЕФаХЯЂЁЃЮЊСЫИќЗНБуЕФДцДЂКЭВщбЏЩчШКФкЕФЪ§ОнЃЌЮвУЧПЩвдНЋЩчШКДцДЂЕНЭМЪ§ОнПтNeo4jЁЃЩЯУцЕФЩчШКЭМОЭЪЧгУNeo4jеЙЪОЕФЃЌФЧУДЪВУДЪЧNeo4jФиЃПЯТУцЮвУЧМђЕЅЕФНщЩмЯТЁЃ
Neo4jМђНщ
Neo4jЪЧвЛИіЧЖШыЪНЕФЁЂЛљгкДХХЬЕФЁЂОпБИЭъШЋЕФЪТЮёЬиадЕФЭМЪ§ОнДцДЂв§ЧцЁЃзїЮЊЭМЪ§ОнПтЃЌNeo4jзюДѓЕФЬиЕуЪЧЙиЯЕЪ§ОнЕФДцДЂЁЃЭМЪ§ОнПтГ§СЫФмЙЛЯёЦеЭЈЕФЪ§ОнПтвЛбљДцДЂвЛаавЛааЕФЪ§ОнжЎЭтЃЌЛЙПЩвдКмЗНБуЕФДцДЂЪ§ОнжЎМфЕФЙиЯЕаХЯЂЁЃ
Р§ШчЃЌЖдгквЛИіЩчНЛЭјТчЕФгУЛЇЪ§ОнПтЃЌФуГ§СЫвЊДцДЂУПИігУЛЇЕФаеУћЁЂадБ№ЁЂЯВКУетаЉЛљБОаХЯЂЭтЃЌФуЛЙашвЊДцДЂвЛИігУЛЇКЭФФаЉгУЛЇЪЧХѓгбЃЌКЭФФИігУЛЇЪЧЧщТТетаЉЙиЯЕЪ§ОнЃЌетИіЪБКђNeo4jетбљЕФЭМЪ§ОнПтОЭПЩвдХЩЩЯгУГЁРВЁЃ
ЭЈЙ§ЯТЭМЃЌДѓМвПЩвдСЫНтЯТЪВУДЪЧЭМЪ§ОнПтвдМАЪВУДЪЧЙиЯЕЪ§ОнЁЃ
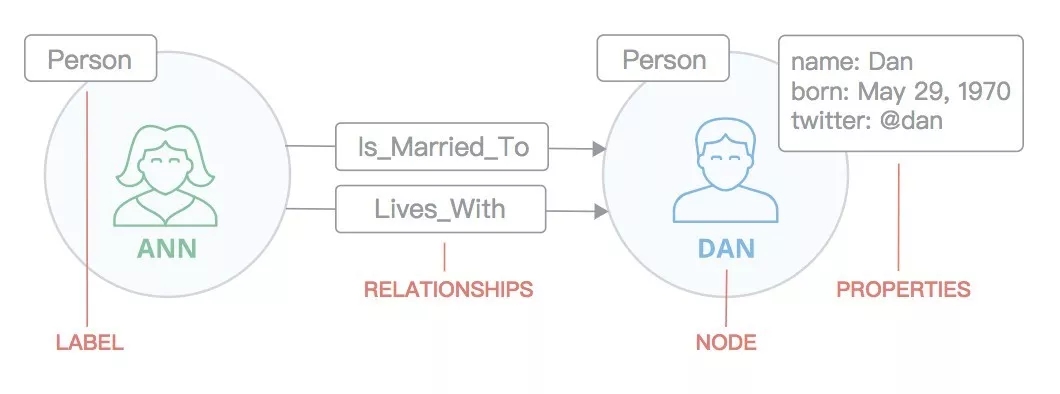
дкЩЯЭМжаЃЌАќКЌСНИіБъЧЉЮЊЁАШЫЁБЕФЪ§ОнНкЕуЃЌЗжБ№ДњБэAnnКЭDanСНИігУЛЇЁЃетСНИіЪ§ОнНкЕуЛЙАќКЌаеУћЁЂГіЩњЕиЕШЪєадаХЯЂЃЌгУгкБэЪОСНИігУЛЇЕФЛљБОаХЯЂЃЌОЭШчЭЌГЃЙцЪ§ОнПтжаЕФСНааЪ§ОнЁЃ
Г§ДЫжЎЭтЃЌСНИіЪ§ОнНкЕужЎМфЛЙАќКЌСНЬѕЙиЯЕЪ§ОнЃЌМДAnnМоИјСЫDanЃЌAnnКЭDanЭЌОгЁЃ РћгУетаЉЙиЯЕЪ§ОнЃЌФуОЭПЩвдЗНБуЕФзїГіЛљгкЙиЯЕЕФВщбЏЃЌР§ШчФуПЩвдВщбЏAnnИњЫНсЛщСЫЃЌетОЭЪЧЭМЪ§ОнПтЕФгХЪЦЁЃ
ПЩФмгаШЫЛсЫЕЃЌЩЯБпаДЕФетжжЙиЯЕЪ§ОнНсЙЙЃЌSQLвВПЩвдЭЈЙ§ЖрБэjoinЕШЗНЗЈЪЕЯжЃЌФЧвЊNeo4jЛЙгаЪВУДгУЃПЕЋБЯОЙЪѕвЕгазЈЙЅЃЌЖдгкДѓСПЁЂИДдгЕФЙиЯЕЪ§ОнДІРэЃЌNeo4jдкадФмКЭЪЙгУЗНБуГЬЖШЩЯЖМЪЧвЊдЖЪЄгкSQLЕФЁЃЯТБпИјДѓМвМђЕЅзмНсЯТNeo4jЕФЬиЕуЁЃ
Neo4jЕФЬиЕу
ЯёSQLвЛбљЕФВщбЏгябдcypher
ЫќзёбЪєадЭМЪ§ОнФЃаЭ
ЫќЭЈЙ§ЪЙгУApache LucenceжЇГжЫїв§
ЫќжЇГжUNIQUEдМЪј
ЫќАќКЌвЛИігУгкжДааcypherУќСюЕФUIЃКNeo4jЪ§ОнфЏРРЦї
ЫќжЇГжЭъећЕФACIDЃЈдзгадЃЌвЛжТадЃЌИєРыадКЭГжОУадЃЉЙцдђ
ЫќжЇГжВщбЏЕФЪ§ОнЕМГіЕНJSONКЭXLSИёЪН
ЫќЬсЙЉСЫREST APIЃЌПЩвдБЛШЮКЮБрГЬгябдЃЈШчJavaЃЌSpringЃЌScalaЕШЃЉЗУЮЪ
ЫќЬсЙЉСЫПЩвдЭЈЙ§ШЮКЮUI MVCПђМмЃЈШчNode JSЃЉЗУЮЪЕФJavaНХБО
ЫќжЇГжСНжжJava APIЃКCypher APIКЭNative Java APIРДПЊЗЂJavaгІгУГЬађ
жЇГжИпПЩгУаджїДгМЏШКВПЪ№ЁЃ
Cypherгябд
CypherЪЧNeo4jЕФЭМаЮВщбЏгябдЃЌЙиМќзжДѓаЁаДВЛУєИаЁЃгяЗЈКЭSQLКмЯёЃЌбЇЦ№РДЯрЖдМђЕЅЁЃ
ЛљБОИёЪН
MATCHWHERERETURN
ФЃЪН
() БэЪОНкЕу
[] БэЪОЙиЯЕЃЌЙиЯЕЪЧгаЯђЕФЃЌСЌНгЕФЕуЗжЮЊдДЕуКЭФПБъЕу
{} БэЪОЪєадЃЌУПИіЪєадЭЈЙ§key:valueЕФаЮЪНБэЪОЃЌЖрИіЪєаджЎМфгУЖККХИєПЊЃЌЙиЯЕвВПЩвдгаЪєад
БъЧЉ
гУРДБъЪЖвЛИіНкЕуЪєгкФФвЛРрЁЃвЛИіНкЕуПЩвдгаЖрИіЛђ0ИіБъЧЉЁЃБъЧЉУЛгаЪєадЁЃ
node:label1:label2 ЭЈЙ§УАКХИјНкЕуЬэМгБъЧЉ,ЭЈЙ§УАКХЗжИєЖрИіБъЧЉ
ЛљБОЕФдіЩОИФВщ
ВхШывЛИіНкЕу
CREATE (n:Person {name : 'Andres'});
ВхШывЛЬѕБп
MATCH (a:Person),(b:Person) WHERE a.name = 'Node
A'
AND b.name = 'Node BЁЎ CREATE (a)-[r:Follow]->(b);
ИќаТНкЕу
MATCH (n:Person { name: 'Andres' }) SET n.name
= 'Taylor';
ЩОГ§НкЕу
MATCH (n:Person { name:'Taylor' }) DETACH DELETE
n;
ЩОГ§Бп
MATCH (a:Person)-[r:Follow]->(b:Person) WHERE
a.name =
'Node A' AND b.name = 'Node BЁЎ DELETE
r;
ВщбЏвЛИіНкЕуЕФЫљгаFollow
MATCH (:Person { name:'Taylor' })-[r:Follow]->(Person)
RETURN Person.name;
ВщбЏвЛИіНкЕузюЖЬТЗОЖ
MATCH (ms:Person { name:'Node A' }),(cs:Person
{ name:'Node B' }), p = shortestPath((ms)-
[r:Follow]-(cs))
RETURN p;
ЧхПеЪ§ОнПт
MATCH (n) DETACH DELETE n |
Neo4jЪ§ОнфЏРРЦї
ЭЈЙ§Neo4jфЏРРЦїОЭПЩвджБНгНјааЭМЕФВщбЏЁЃ
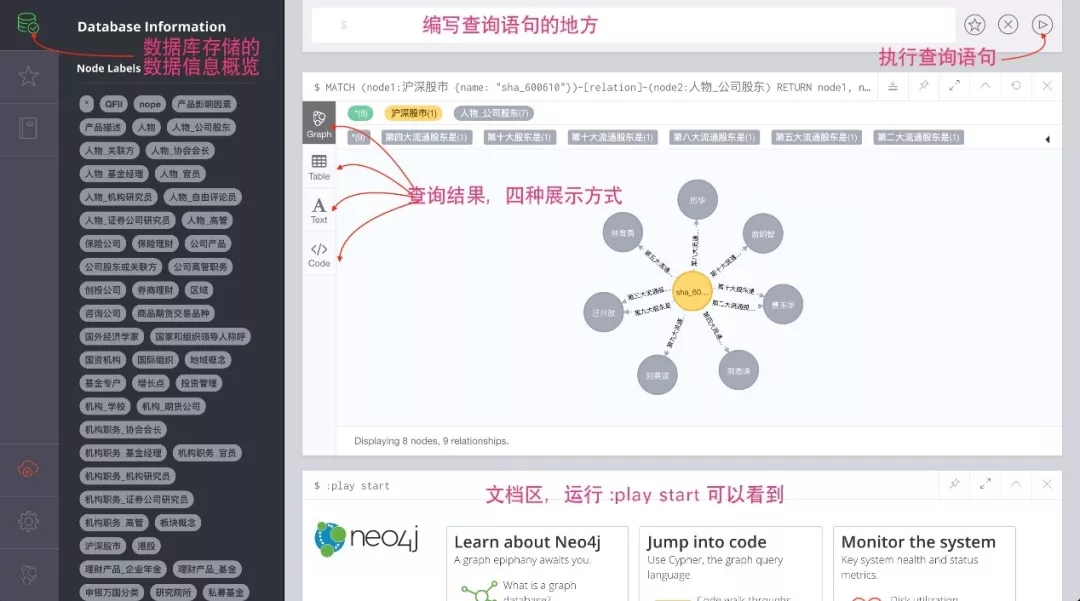
CypherбнЪОЪОР§
ЮвУЧЪЙгУCypherВщбЏгябдЖдNeo4jжаЕФвЛИіМвЭЅНјааНЈФЃЃЌАќРЈФъСфЃЌадБ№КЭМвЭЅГЩдБжЎМфЕФЙиЯЕЕШИіШЫЪєадЁЃЮвУЧДДНЈСЫвЛаЉХѓгбРДРЉДѓЮвУЧЕФЩчНЛЭМЃЌШЛКѓЬэМгМќ/жЕЖдРДЩњГЩУПИігУЛЇПДЙ§ЕФЕчгАСаБэЁЃзюКѓЃЌЮвУЧВщбЏСЫЮвУЧЕФЪ§ОнЃЌЪЙгУЭМаЮЗжЮіРДЫбЫївЛИігУЛЇУЛгаПДЕНЕЋПЩФмЯВЛЖЕФЕчгАЁЃ
ДДНЈМвЭЅГЩдБНкЕуМАЙиЯЕ
CREATE (person:Person
{name: "Steven", age: 45}) RETURN person
CREATE (person:Person {name: "Michael",
age: 16}) RETURN person
CREATE (person:Person {name: "Rebecca",
age: 7}) RETURN person
CREATE (person:Person {name: "Linda",age:40})
RETURN person
MATCH (steven:Person {name: "Steven"}),
(linda:Person {name: "Linda"}) CREATE
(steven)-
[:IS_MARRIED_TO]->(linda) return steven,
linda
MATCH (michael:Person {name: "Michael"}),
(rebecca:Person {name: "Rebecca"}) CREATE
(michael)-
[:IS_SIBLILNG]->(rebecca) return
michael, rebecca
MATCH (steven:Person {name: "Steven"}),
(michael:Person {name: "Michael"}) CREATE
(steven)-[:HAS_CHILD]->(michael) return steven,
michael
MATCH (steven:Person {name: "Steven"}),
(rebecca:Person
{name: "Rebecca"}) CREATE
(steven)-[:HAS_CHILD]->
(rebecca) return steven,
rebecca
MATCH (linda:Person {name: "Linda"}),
(michael:Person {name: "Michael"})
CREATE
(linda)-[:HAS_CHILD]->(michael) return linda,
michael
MATCH (linda:Person {name: "Linda"}),
(rebecca:Person {name: "Rebecca"})
CREATE
(linda)-[:HAS_CHILD]->(rebecca) return linda,
Rebecca |
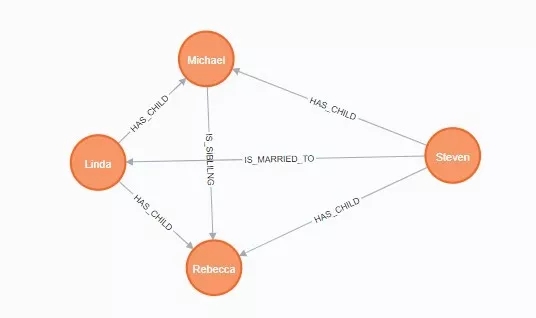
ЬэМгХѓгбНкЕуМАЙиЯЕЃЌзщГЩЩчНЛЭјТч
MATCH (michael:Person
{name: "Michael"}) CREATE (michael)-[:FRIEND]->(charlie:Person
{name: "Charlie", age: 16}) RETURN michael,
charlie
MATCH (michael:Person {name: "Michael"})
CREATE (michael)-[:FRIEND]->(koby:Person
{name:
"Koby"}) RETURN michael, koby
MATCH (michael:Person
{name: "Michael"})
CREATE (michael)-[:FRIEND]->
(grant:Person {name:
"Grant"}) RETURN michael, grant
MATCH (rebecca:Person {name: "Rebecca"})
CREATE (rebecca)-[:FRIEND]->(jordyn:Person
{name: "Jordyn"})
RETURN rebecca, jordyn
MATCH (rebecca:Person {name: "Rebecca"})
CREATE (rebecca)-[:FRIEND]->(katie:Person
{name:
"Katie"}) RETURN rebecca, katie |
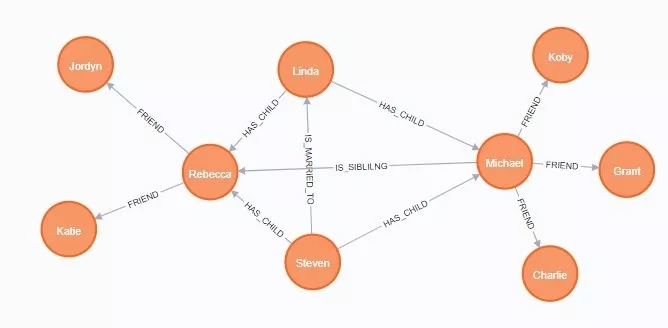
ЬэМгЕчгАНкЕуМАЙиЯЕЃЌВЂаЏДјДђЗжЪєад
CREATE (movie:Movie
{title:"Avengers"}) RETURN movie
MATCH (michael:Person {name:"Michael"}),
(avengers:Movie {title:"Avengers"})
CREATE (michael)-
[:HAS_SEEN {rating:5}]->
(avengers)
return michael, avengers
CREATE (movie:Movie {title:"Batman"})
RETURN movie
CREATE (movie:Movie {title:"Gone with the
Wind"}) RETURN movie
CREATE (movie:Movie {title:"Spongebob Square
Pants"}) RETURN movie
CREATE (movie:Movie {title:"Avengers 2"})
RETURN movie
MATCH (charlie:Person {name:"Charlie"}),
(movie:Movie {title:"Batman"}) CREATE
(charlie)-
[:HAS_SEEN {rating:4}]->(movie) return
charlie, movie
MATCH (charlie:Person {name:"Charlie"}),
(movie:Movie {title:"Gone with the Wind"})
CREATE (charlie)-[:HAS_SEEN {rating:0}]->(movie)
return charlie, movie
MATCH (koby:Person {name:"Koby"}),
(movie:Movie
{title:"Batman"}) CREATE (koby)-
[:HAS_SEEN
{rating:4}]->(movie) return koby, movie
MATCH (koby:Person {name:"Koby"}), (movie:Movie
{title:"Avengers 2"}) CREATE (koby)-[:HAS_SEEN
{rating:5}]->
(movie) return koby, movie
MATCH (grant:Person {name:"Grant"}),
(movie:Movie {title:"Spongebob Square Pants"})
CREATE (grant)-[:HAS_SEEN {rating:1}]->
(movie)
return grant, movie
MATCH (jordyn:Person {name:"Jordyn"}),
(movie:Movie {title:"Spongebob Square Pants"})
CREATE (jordyn)-[:HAS_SEEN {rating:5}]->
(movie)
return jordyn, movie
MATCH (michael:Person {name: "Michael"})
SET
michael.gender = "male" RETURN michael
MATCH (rebecca:Person {name: "Rebecca"})
SET
rebecca.gender = "female" RETURN
rebecca
|
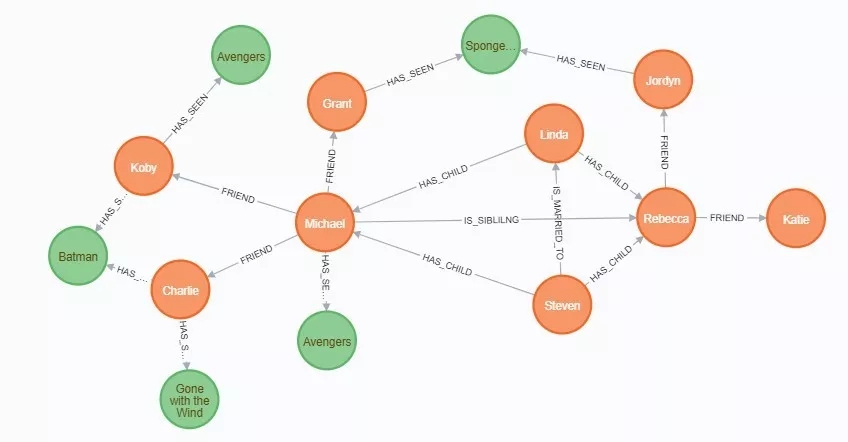
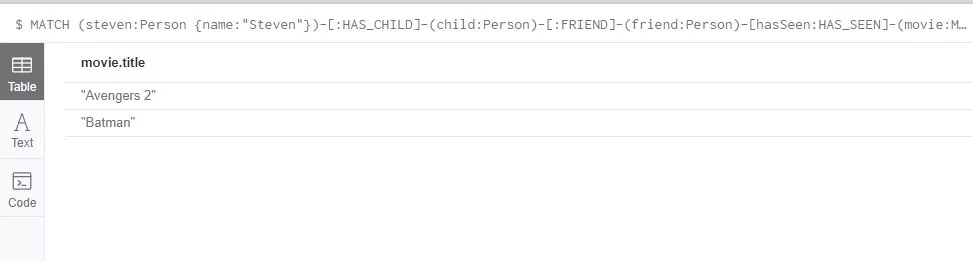
зюКѓЮвУЧЭЈЙ§ЯТУцгяОфВщбЏstevenЕФКЂзгЕФФаадХѓгбПДЙ§ЖјЧвДђЗжДѓгк3ЗжЕФЕчгА
MATCH (steven:Person
{name:"Steven"})-
[:HAS_CHILD]-(child:Person)-[:FRIEND]-(friend:Person)-
[hasSeen:HAS_SEEN]-(movie:Movie)
WHERE child.gender =
"male" AND hasSeen.rating
> 3 RETURN DISTINCT movie.title |
|









