| БрМЭЦМі: |
| БОЮФРДздjianshu
ЃЌЮФеТНщЩмСЫЪВУДЪЧЭМЃЌЭМЕФГіЖШЧѓЗЈЃЌжиИДЖЅЕуЪгЭМЕФЫФжжФЃЪНЃЌЗжЧјЗНЪНЕШЯрЙиФкШнЃЌЯЃЭћФмЖдФњгаЫљАяжњЁЃ |
|
аДдкЧАУц
ЬЌЖШОіЖЈИпЖШЃЁШУгХауГЩЮЊвЛжжЯАЙпЃЁ
ЪРНчЩЯУЛгаЪВУДЪТЖљЪЧМгвЛДЮАрНтОіВЛСЫЕФЃЌШчЙћгаЃЌОЭМгСНДЮЃЁЃЈ- - -УЏЧПЃЉ
ЪВУДЪЧвЛИіЭМ
вЛИіЭјТч

Network
вЛИіЪї
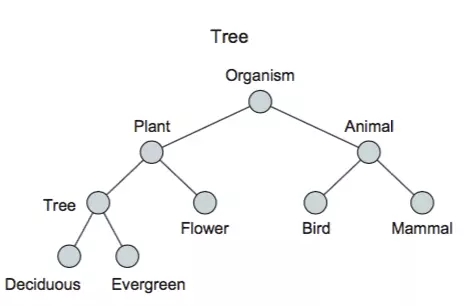
Tree
вЛИіRDBMS
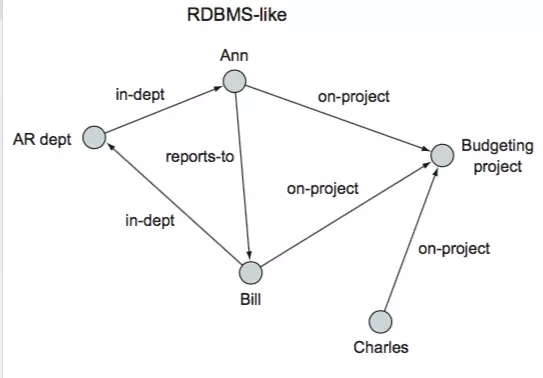
RDMBMS
вЛИіЯЁЪшОиеѓ
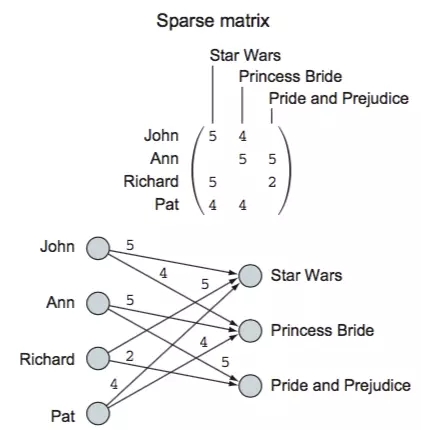
ЯЁЪшОиеѓЭјТч
Лђеп
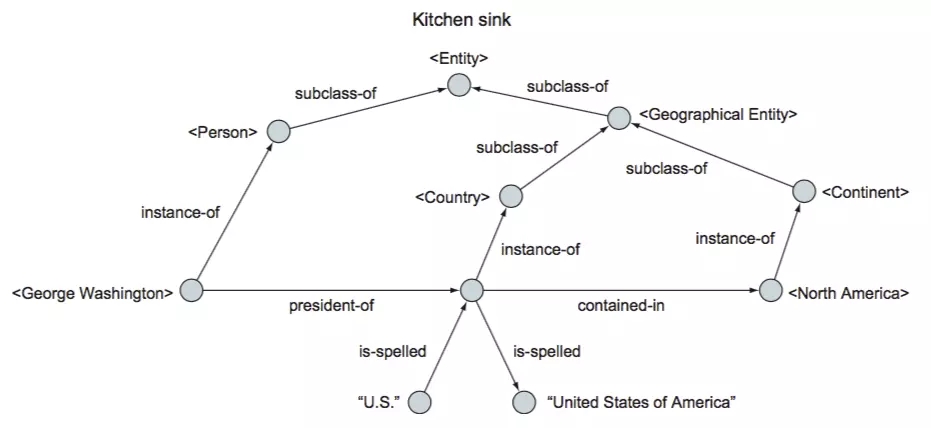
Kitchen sink
ЪєадЭМ
ЖЅЕу
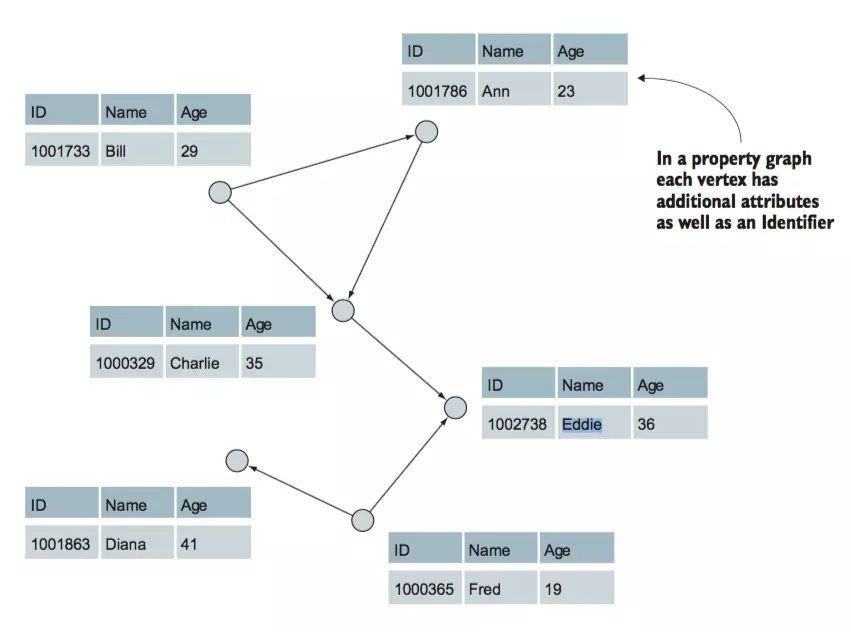
ЖЅЕу
Бп
Бп
GRAPHX
graphxЪЧвЛИіЭММЦЫув§ЧцЃЌЖјВЛЪЧвЛИіЭМЪ§ОнПтЃЌЫќПЩвдДІРэЯёЕЙХХЫїв§ЃЌЭЦМіЯЕЭГЃЌзюЖЬТЗОЖЃЌШКЬхМьВтЕШЕШ
гаЯђЭМгыЮоЯђЭМ
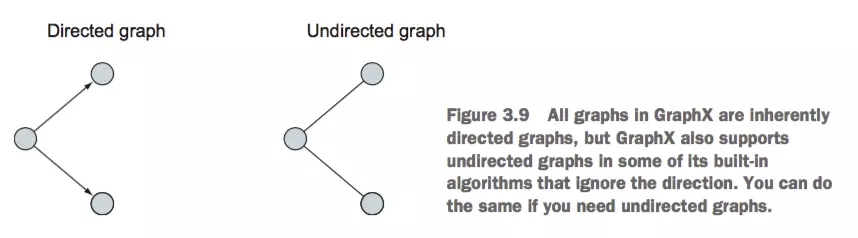
гаЯђЭМЮоЯђЭМ
гаЛЗЭМгыЮоЛЗЭМ
СНепЕФЧјБ№дкгкЪЧЗёФмЙЛбизХЗНЯђЙЙГЩвЛИіБеЛЗ
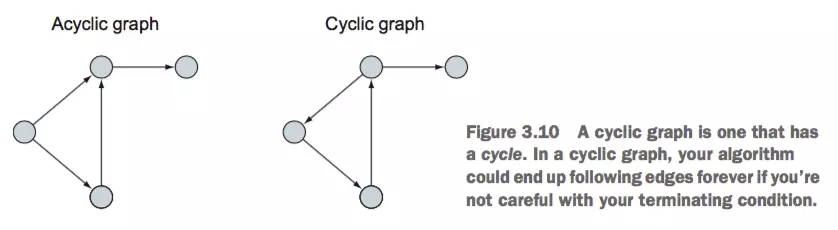
гаЛЗЭМЮоЛЗЭМ
гаБъЧЉЭМгыЮоБъЧЉЭМ
гаБъЧЉЮоБъЧЉЭМ
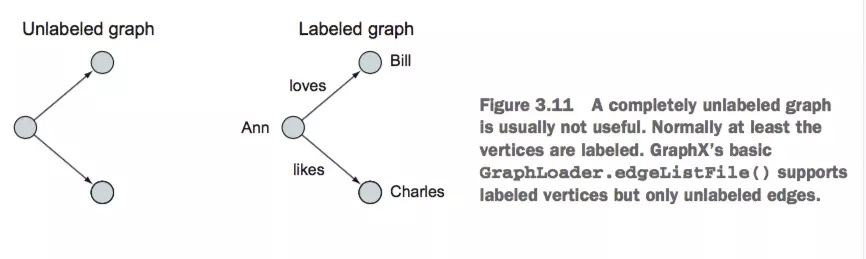
ЮБЭМгыбЛЗ
ДгМђЕЅЕФЭМПЊЪМЃЌЕБдЪаэСНИіНкЕужЎМфгаЖрИіБпЕФЪБКђЃЌОЭЪЧвЛИіИДКЯЭМЃЌШчЙћдкФГИіНкЕуЩЯМгИібЛЗОЭГЩСЫЮБЭМЃЌGRAPHXжаЕФЭМЖМЪЧЮБЭМ
ЮБЭМгыбЛЗ
ЖўВПЭМ/ХМЭМ
ХМЭМгаИіЬиЪтЕФНсЙЙЃЌОЭЪЧЫљгаЕФЖЅЕуЗжЮЊСНИіЪ§ОнМЏЃЌЫљгаЕФБпЖМЪЧНЈСЂдкетСНИіЪ§ОнМЏжЎМфЕФЃЌдквЛИіЪ§ОнМЏжаВЛЛсДцдкБп

ХМЭМ
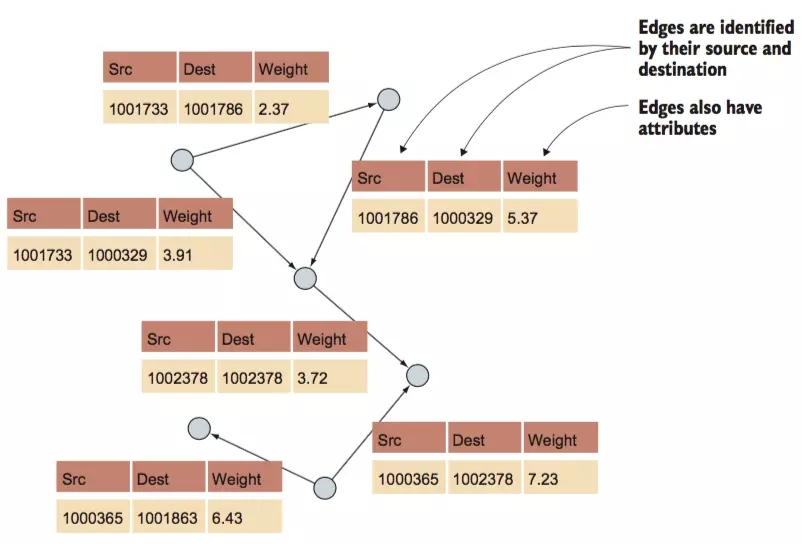
RDFЃЈResource Description Framework ЃЉЭМгыЪєадЭМ
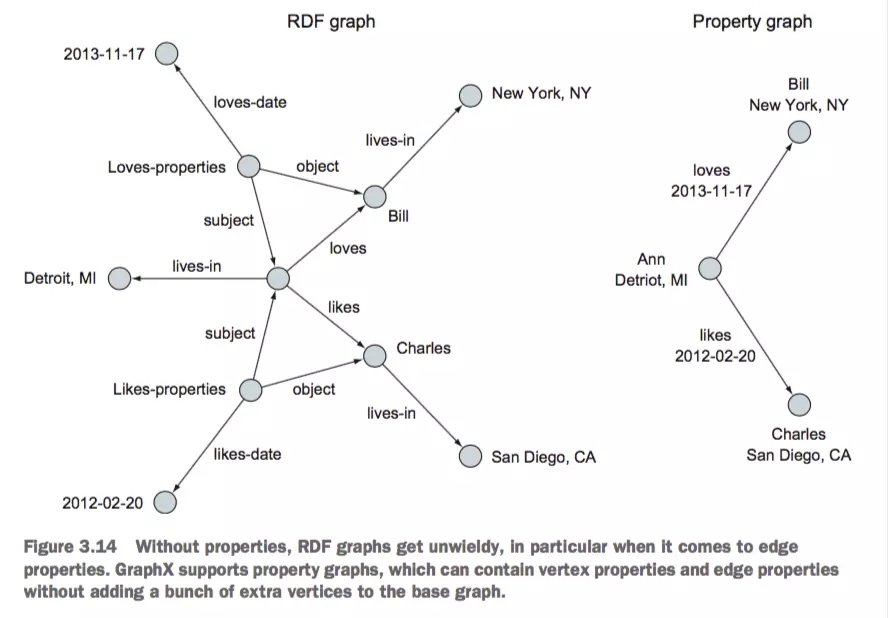
RDFЭМгыЪєадЭМ
СкНгОиеѓ
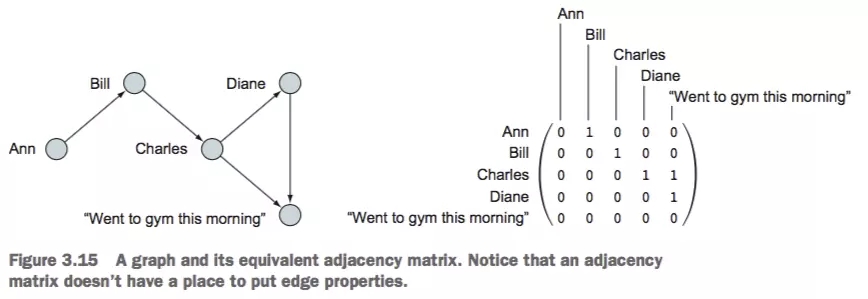
СкНгОиеѓ
SPARK GRAPHX
RDD
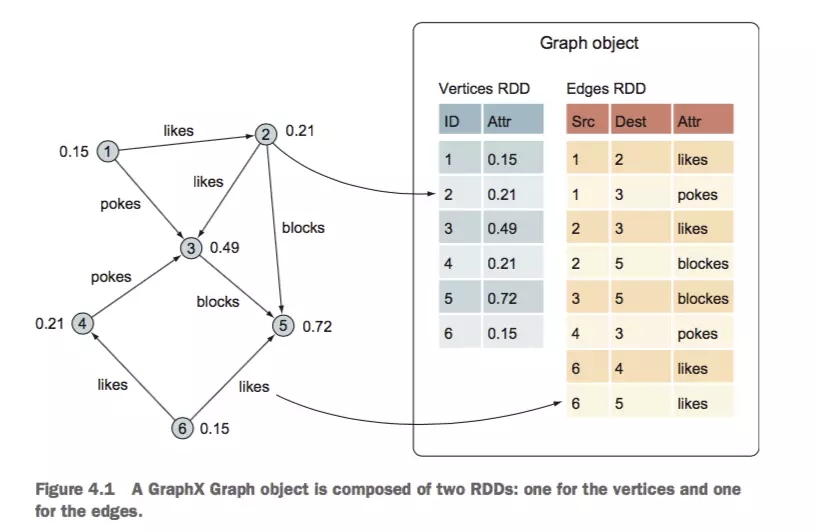
DATA IN GRAPHX
graphxжаЕФGraphгаСНИіRDDЃЌвЛИіЪЧБпRDDЃЌвЛИіЪЧЕуRDD
ЦфжаUMLШчЯТ

Graph UML
РэНтШ§дЊзщ
ЦфЪЕОЭЪЧгЩЃЈЕуЁЂБпЃЌЕуЃЉЕФвЛИігааЇзщКЯЃЌгЩtriplets()НгПкЛёШЁ
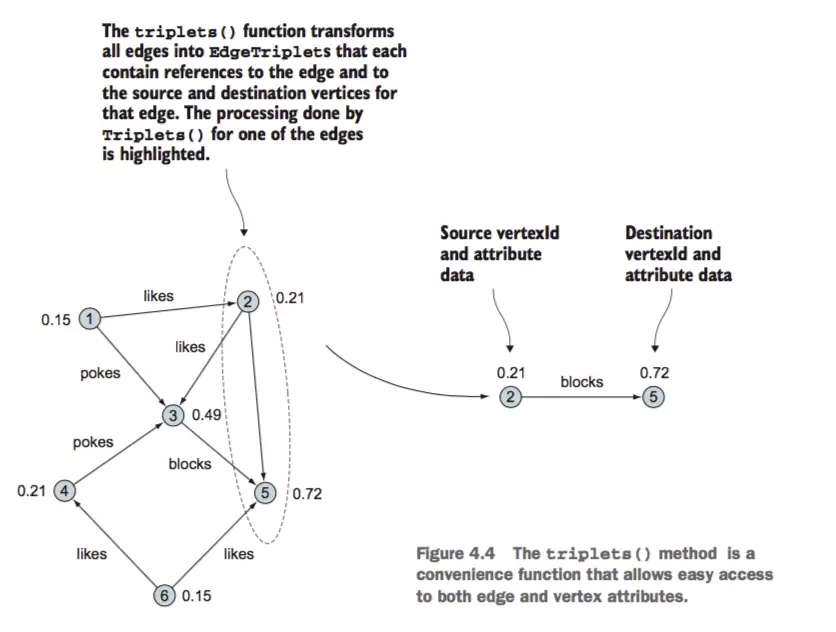
Ш§дЊзщ
Цфжаtriplets()ЗЕЛиЕФНсЙћЪЧEdgeTriplet[VD,ED]ЃЌEdgeTriplet[VD,ED]ЕФЪєадНгПкгаЃК
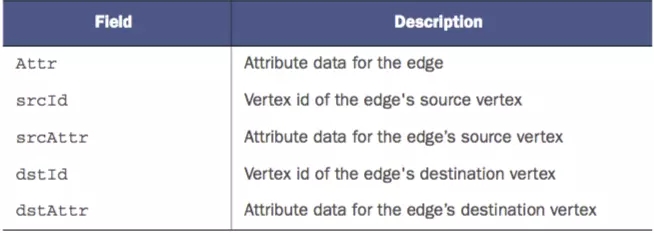
ЪєадНгПк
РэНтaggregateMessages
ЪзЯШПДЯТдДТыЃК
def aggregateMessages[A:
ClassTag](
sendMsg: EdgeContext[VD, ED, A] => Unit,
mergeMsg: (A, A) => A,
tripletFields: TripletFields = TripletFields.All):
VertexRDD[A] = {
aggregateMessagesWithActiveSet(sendMsg, mergeMsg,
tripletFields, None)
} |
EdgeContext
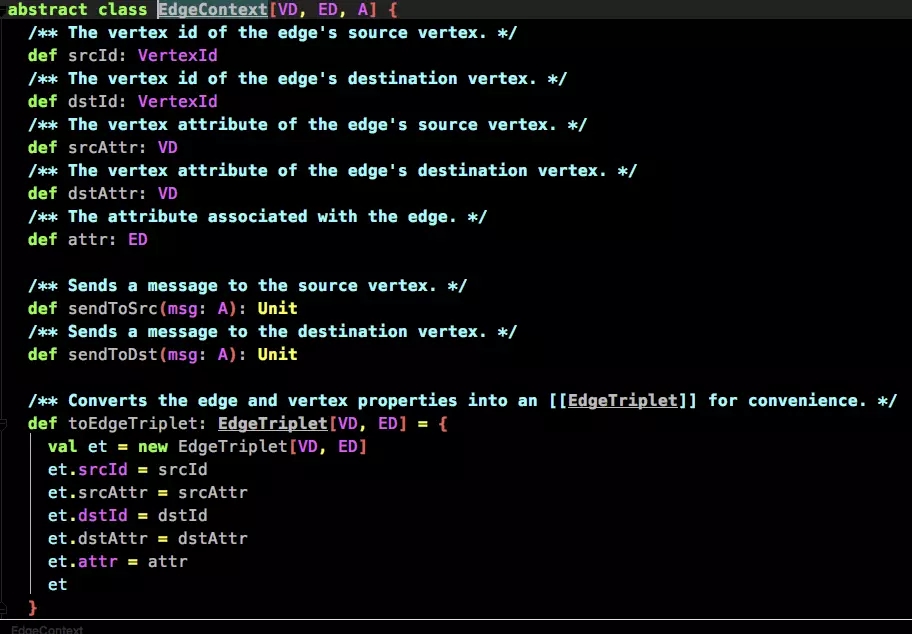
EdgeContext
жївЊПМТЧ

sendmsg
етСНИіЗНЗЈ
етСНИіЗНЗЈвЛИіАЩtripletsжаЪ§ОнЗЂЫЭЕНдДНкЕу
вЛИіЪЧАбtripletsжаЕФЪ§ОнЗЂЫЭЕНФПЕФНкЕу
етбљОЭПЩвддкдДЛђепФПЕФНкЕуНјааОлКЯВйзїСЫ
ПДИіР§згЃК
| graph.aggregateMessages[Int](_.sendToSrc(1),
_ + _).foreach(println) |
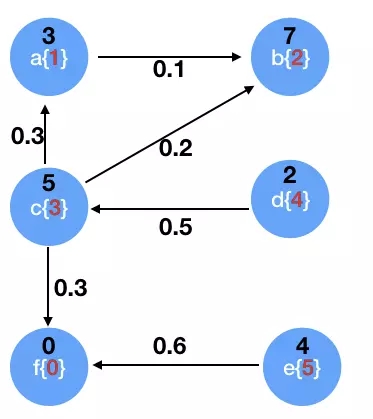
етИіР§згОЭЪЧЧѓГіЭМЕФГіЖШ
sendToSrc(1)ЛсеыЖдУПвЛИіtripletsЯђдДНкЕуЗЂЫЭ1
ШчЭМ

Ш§дЊзщ
ЛсЯђ2НкЕуЗЂЫЭвЛИі1
_ + _ ЃКБэЪОеыЖдУПИіНкЕузіЯрМгЕФОлКЯ
БШШчЯТЭМ5НкЕуга4ИіtripletsЃЌВЩгУsendToSrcЗНЗЈКѓЃЌЫќЕФОлКЯОЭЪЧ1+1 = 2
вВОЭЪЧЫќЕФГіЖШ
ЭМ
НсЙћЪЧ
Pregel
ЯШПДдДТы
def apply[VD:
ClassTag, ED: ClassTag, A: ClassTag]
(graph: Graph[VD, ED],
initialMsg: A,
maxIterations: Int = Int.MaxValue,
activeDirection: EdgeDirection = EdgeDirection.Either)
(vprog: (VertexId, VD, A) => VD,
sendMsg: EdgeTriplet[VD, ED] => Iterator[(VertexId,
A)],
mergeMsg: (A, A) => A)
: Graph[VD, ED]
ЃЈ1ЃЉgraphЃК
ЪфШыЕФЭМ
ЃЈ2ЃЉ initialMsg:
ГѕЪМЛЏЯћЯЂЃЌдкЕквЛДЮЕќДњЕФЪБКђЃЌетИіГѕЪМЯћЯЂЛсБЛгУРДГѕЪМЛЏЭМжаЕФУПИіНкЕуЃЌдкpregelНјааЕїгУЪБЃЌЛсЪзЯШдкЭМЩЯЪЙгУmapVerticesРДИљОнinitialMsgЕФжЕИќаТУПИіНкЕуЕФжЕЃЌжСгкШчКЮИќаТЃЌдђгЩvprogВЮЪ§ЖјЖЈЃЌvprogКЏЪ§ОЭНгЪеСЫinitialMsgЯћЯЂзіЮЊВЮЪ§РДИќаТЖдгІНкЕуЕФжЕ
ЃЈ3ЃЉ maxIterationsЃК
зюДѓЕќДњЕФДЮЪ§
ЃЈ4ЃЉ activeDirection:
ЛюдОЗНЯђЃЌЪзЯШРэНтЛюдОЯћЯЂгыЛюдОЖЅЕуЃЌЛюдОНкЕуЪЧжИдкФГвЛТжЕќДњжаpregelвдsendMsgКЭmergeMsgЮЊВЮЪ§РДЕїгУgraphЕФaggregateMessageЗНЗЈКѓЪеЕНЯћЯЂЕФНкЕуЃЌЛюдОЯћЯЂОЭЪЧетТжЕќДњжаЫљгаБЛГЩЙІЪеЕНЕФЯћЯЂЁЃетбљвЛРДЃЌгаЕФБпЕФsrcНкЕуЪЧЛюдОНкЕуЃЌгаЕФdstНкЕуЪЧЛюдОНкЕуЃЌЖјгаЕФБпСНЖЫНкЕуЖМЪЧЛюдОНкЕуЁЃШчЙћactiveDirectionВЮЪ§жИЖЈЮЊЁАEdgeDirection.OutЁБ,дђдкЯТвЛТжЕќДњЪБЃЌжЛгаНгЪеЯћЯЂЕФГіБп(srcЁЊ>dst)ВХЛсжДааsendMsgКЏЪ§ЃЌвВОЭЪЧЫЕЃЌsendMsgЛиЕїКЏЪ§ЛсЙ§ТЫЕєЁБdstЁЊ>srcЁБЕФedgeTripletЩЯЯТЮФВЮЪ§
EdgeDirection.Out ЁЊsendMsg gets called if srcId
received a message during the previous iteration,
meaning this edge is considered an ЁАout-edgeЁБ
of srcId.
EdgeDirection.InЁЊsendMsg gets called if dstId
received a message during the previous iteration,
meaning this edge is considered an ЁАin-edgeЁБ of
dstId.
EdgeDirection.EitherЁЊsendMsg gets called if either
srcId or dstId received a message during the previous
iteration.
EdgeDirection.Both ЁЊsendMsg gets called if both
srcId and dstId received mes- sages during the
previous iteration.
ЃЈ5ЃЉ vprog:
НкЕуБфЛЛКЏЪ§ЃЌдкГѕЪМЪБЃЌдкУПТжЕќДњКѓЃЌpregelЛсИљОнЩЯвЛТжЪЙгУЕФmsgКЭетРяЕФvprodКЏЪ§дкЭМЩЯЕїгУjoinVerticesЗНЗЈБфЛЏУПИіЪеЕНЯћЯЂЕФНкЕуЃЌзЂвтетȳʏڧçþЪМЪБЭтЃЌЖМЪЧНідкНгЪеЕНЯћЯЂЕФНкЕуЩЯдЫааЃЌетвЛЕуПЩвдДгдДТыжаПДЕНЃЌдДТыжагУЕФЪЧjoinVertices(message)(vprog)ЃЌвђДЫЃЌУЛгаЪеЕНЯћЯЂЕФНкЕудкjoinжЎКѓОЭТЫЕєСЫ
ЃЈ6ЃЉ sendMsg:
ЯћЯЂЗЂЫЭКЏЪ§ЃЌИУКЏЪ§ЕФдЫааВЮЪ§ЪЧвЛИіДњБэБпЕФЩЯЯТЮФЃЌpregelдкЕїгУaggregateMessagesЪБЃЌЛсНЋEdgeContextзЊЛЛГЩEdgeTripletЖдЯѓ(ctx.toEdgeTriplet)РДЪЙгУЃЌгУЛЇашвЊЭЈЙ§Iterator[(VertexId,A)]жИЖЈЗЂЫЭФФаЉЯћЯЂЃЌЗЂИјФЧаЉНкЕуЃЌЗЂЫЭЕФФкШнЪЧЪВУДЃЌвђЮЊдквЛЬѕБпЩЯПЩвдЗЂЫЭЖрИіЯћЯЂЃЌгаsendToDstКЭsendToSrcЃЌЫљвдетРяЪЧИіIteratorЃЌУПвЛИідЊЫиЪЧвЛИіtupleЃЌЦфжаЕФvertexIdБэЪОвЊНгЪеДЫЯћЯЂЕФНкЕуЕФidЃЌЫќжЛФмЪЧИУБпЩЯЕФsrcIdЛђdstIdЃЌЖјAОЭЪЧвЊЗЂЫЭЕФФкШнЃЌвђДЫШчЙћЪЧашвЊгЩsrcЗЂЫЭвЛЬѕЯћЯЂAИјdstЃЌдђгаЃКIterator((dstId,A))ЃЌШчЙћЪВУДЯћЯЂвВВЛЗЂЫЭЃЌдђПЩвдЗЕЛивЛИіПеЕФIteratorЃКIterator.empty
ЃЈ7ЃЉ mergeMsg:
СкОгНкЕуЪеЕНЖрЬѕЯћЯЂЪБЕФКЯВЂТпМЃЌзЂвтЫќЧјБ№гкvprogКЏЪ§ЃЌmergeMsgНіФмКЯВЂЯћЯЂФкШнЃЌЕЋКЯВЂКѓВЂВЛЛсИќаТЕННкЕужаШЅЃЌЖјvprogКЏЪ§ПЩвдИљОнЪеЕНЕФЯћЯЂ(ОЭЪЧmergeMsgВњЩњЕФНсЙћ)ИќаТНкЕуЪєад |
ЃЈзюаЁТЗОЖЫуЗЈЃЉ
ДгЭМЩЯПЩвдПДГізюаЁТЗОЖЫуЗЈDijkstraЕФдРэ
a. ГѕЪМЪБЃЌSжЛАќКЌдДЕуЃЌМДSЃН{v}ЃЌvЕФОрРыЮЊ0ЁЃUАќКЌГ§vЭтЕФЦфЫћЖЅЕуЃЌМД:U={ЦфгрЖЅЕу}ЃЌШєvгыUжаЖЅЕуuгаБпЃЌдђ<u,v>е§ГЃгаШЈжЕЃЌШєuВЛЪЧvЕФГіБпСкНгЕуЃЌдђ<u,v>ШЈжЕЮЊЁоЁЃ
b. ДгUжабЁШЁвЛИіОрРыvзюаЁЕФЖЅЕуkЃЌАбkЃЌМгШыSжаЃЈИУбЁЖЈЕФОрРыОЭЪЧvЕНkЕФзюЖЬТЗОЖГЄЖШЃЉЁЃ
c. вдkЮЊаТПМТЧЕФжаМфЕуЃЌаоИФUжаИїЖЅЕуЕФОрРыЃЛШєДгдДЕуvЕНЖЅЕуuЕФОрРыЃЈОЙ§ЖЅЕуkЃЉБШдРДОрРыЃЈВЛОЙ§ЖЅЕуkЃЉЖЬЃЌдђаоИФЖЅЕуuЕФОрРыжЕЃЌаоИФКѓЕФОрРыжЕЕФЖЅЕуkЕФОрРыМгЩЯБпЩЯЕФШЈЁЃ
d. жиИДВНжшbКЭcжБЕНЫљгаЖЅЕуЖМАќКЌдкSжаЁЃ

зюаЁТЗОЖ
дкGRAPHXжа
GraphX ВЩгУЖЅЕуЧаЗжЗНЪННјааЗжВМЪНЭМЗжИю
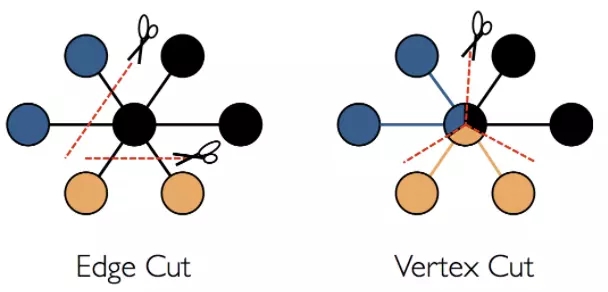
БпЧаЗжгыЖЅЕуЧаЗж
GraphX ВЛЪЧбизХБпбиЗжИюЭМаЮЃЌЖјЪЧбизХЖЅЕуЗжИюЭМаЮЃЌетПЩвдМѕЩйЭЈаХКЭДцДЂПЊЯњЃЌдкТпМЩЯЃЌетЖдгІгкНЋБпдЕЗжХфИјЛњЦїВЂдЪаэЖЅЕуПчдНЖрЬЈЛњЦїЁЃЗжХфБпдЕЕФШЗЧаЗНЗЈШЁОігкPartitionStrategyИїжжЦєЗЂЪНЕФМИжжелждЁЃгУЛЇПЩвдЭЈЙ§гыGraph.partitionByдЫЫуЗћжиаТЗжЧјЭМРДбЁдёВЛЭЌЕФВпТдЁЃФЌШЯЗжЧјВпТдЪЧЪЙгУЭМаЮЙЙНЈжаЬсЙЉЕФБпЕФГѕЪМЗжЧјЃЈЪЙгУБпЕФ
srcId НјааЙўЯЃЗжЧјЃЌНЋБпЪ§ОнвдЖрЗжЧјаЮЪНЗжВМдкМЏШКЃЉЃЌСэЭтЃЌЖЅЕу RDD жаЛЙгЕгаЖЅЕуЕНБп RDD
ЗжЧјЕФТЗгЩаХЯЂЁЊЁЊТЗгЩБэЃЎТЗгЩБэДцдкЖЅЕу RDD ЕФЗжЧјжаЃЌЫќМЧТМЗжЧјФкЖЅЕуИњЫљгаБп RDD ЗжЧјЕФЙиЯЕЃЎдкБп
RDD ашвЊЖЅЕуЪ§ОнЪБЃЈШчЙЙдьБпШ§дЊзщЃЉЃЌЖЅЕу RDD ЛсИљОнТЗгЩБэАбЖЅЕуЪ§ОнЗЂЫЭжСБп RDD ЗжЧјЁЃ
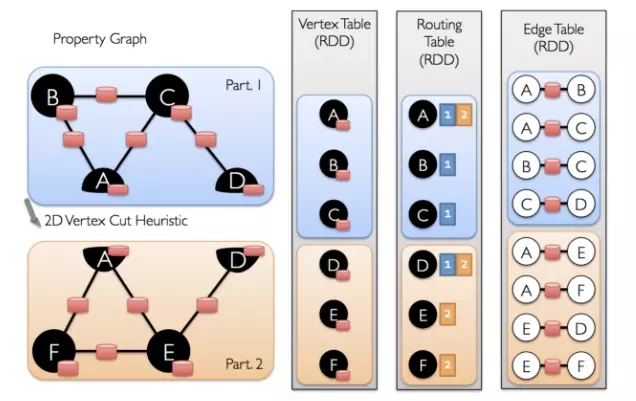
ЗжЧј
ШчЯТЭМАДЖЅЕуЗжИюЗНЗЈНЋЭМЗжНтКѓЕУЕНЖЅЕу RDDЁЂБп RDD КЭТЗгЩБэ
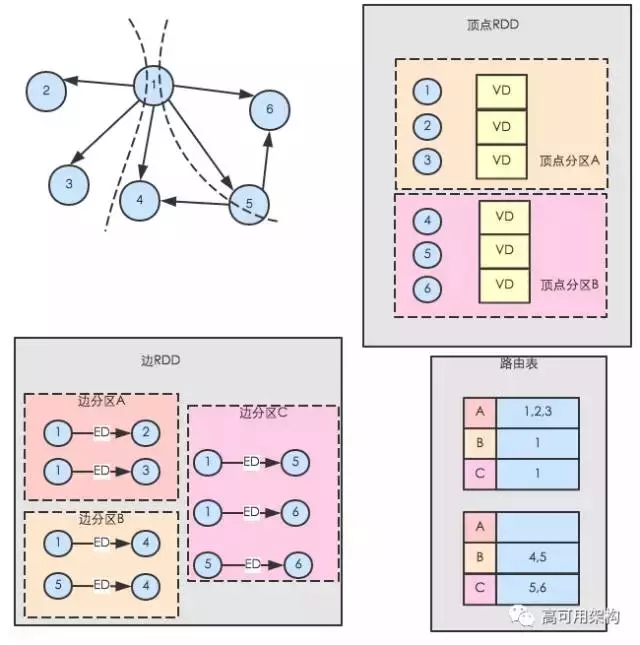
ЗжЧјНтЪЭЭМ
GraphX ЛсвРОнТЗгЩБэЃЌДгЖЅЕу RDD жаЩњГЩгыБп RDD ЗжЧјЯрЖдгІЕФжиИДЖЅЕуЪгЭМЃЈ ReplicatedVertexViewЃЉЃЌЫќЕФзїгУЪЧзїЮЊжаМф
RDDЃЌНЋЖЅЕуЪ§ОнДЋЫЭжСБп RDD ЗжЧјЁЃжиИДЖЅЕуЪгЭМАДБп RDD ЗжЧјВЂаЏДјЖЅЕуЪ§ОнЕФ RDDЃЌШчЭМЯТЭМЫљЪОЃЌжиИДЖЅЕуЗжЧј
A жаБуаЏСЫДјБп RDD ЗжЧј A жаЕФЫљгаЕФЖЅЕуЃЌЫќгыБп RDD жаЕФЖЅЕуЪЧ co-partitionЃЈМДЗжЧјИіЪ§ЯрЭЌЃЌЧвЗжЧјЗНЗЈЯрЭЌЃЉЃЌдкЭММЦЫуЪБЃЌ
GraphX НЋжиИДЖЅЕуЪгЭМКЭБп RDD АДЗжЧјНјааРСДЃЈ zipPartitionЃЉВйзїЃЌМДНЋжиИДЖЅЕуЪгЭМКЭБп
RDD ЕФЗжЧјвЛвЛЖдгІЕизщКЯЦ№РДЃЌДгЖјНЋБпгыЖЅЕуЪ§ОнСЌНгЦ№РДЃЌЪЙБпЗжЧјгЕгаЖЅЕуЪ§ОнЁЃдкећИіаЮГЩБпШ§дЊзщЙ§ГЬжаЃЌжЛгадкЖЅЕу
RDD аЮГЩЕФжиИДЖЅЕуЪгЭМжаДцдкЗжЧјМфЪ§ОнвЦЖЏЃЌРСДВйзїВЛашвЊвЦЖЏЖЅЕуЪ§ОнКЭБпЪ§ОнЃЎгЩгкЖЅЕуЪ§ОнвЛАуБШБпЪ§ОнвЊЩйЕФЖрЃЌЖјЧвЫцзХЕќДњДЮЪ§ЕФдіМгЃЌашвЊИќаТЕФЖЅЕуЪ§ФПвВдНРДдНЩйЃЌжиИДЖЅЕуЪгЭМжааЏДјЕФЖЅЕуЪ§ОнвВЛсЯргІМѕЩйЃЌетбљОЭПЩвдДѓДѓМѕЩйМЏШКжаЪ§ОнЕФвЦЖЏСПЃЌМгПьжДааЫйЖШЁЃ
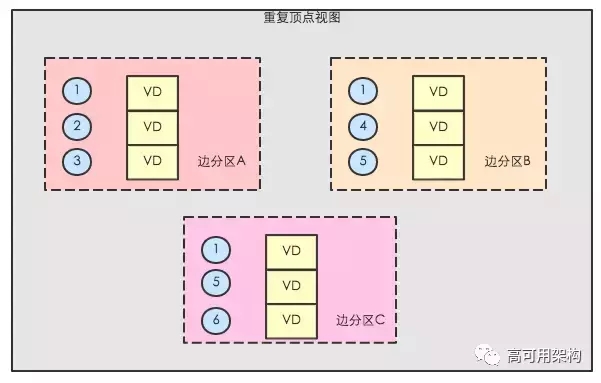
жиИДЖЅЕуЪгЭМ
жиИДЖЅЕуЪгЭМгаЫФжжФЃЪН
ЃЈ1ЃЉbothAttr: МЦЫужаашвЊУПЬѕБпЕФдДЖЅЕуКЭФПЕФЖЅЕуЕФЪ§Он
ЃЈ2ЃЉsrcAttrOnlyЃКМЦЫужажЛашвЊУПЬѕБпЕФдДЖЅЕуЕФЪ§Он
ЃЈ3ЃЉdestAttrOnlyЃКМЦЫужажЛашвЊУПЬѕБпЕФФПЕФЖЅЕуЕФЪ§Он
ЃЈ4ЃЉnoAttrЃКМЦЫужаВЛашвЊЖЅЕуЕФЪ§Он
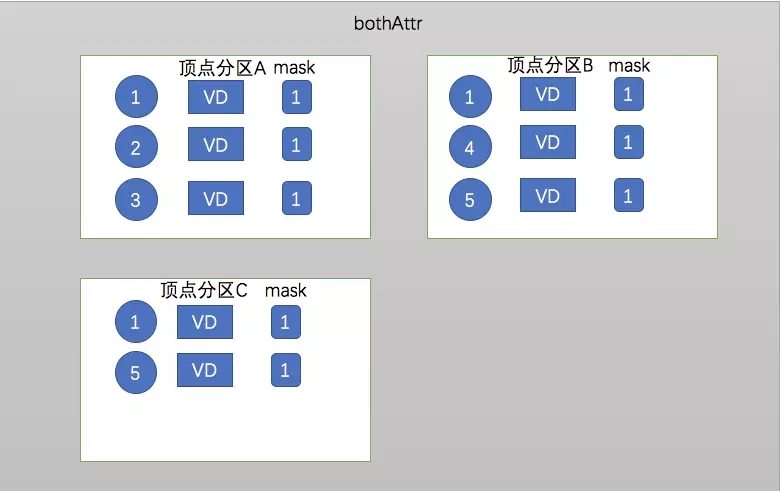
bothAttr
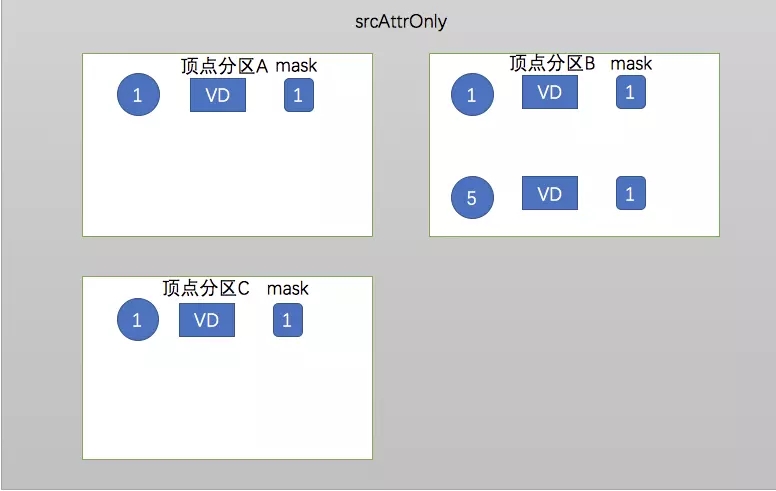
srcAttrOnly
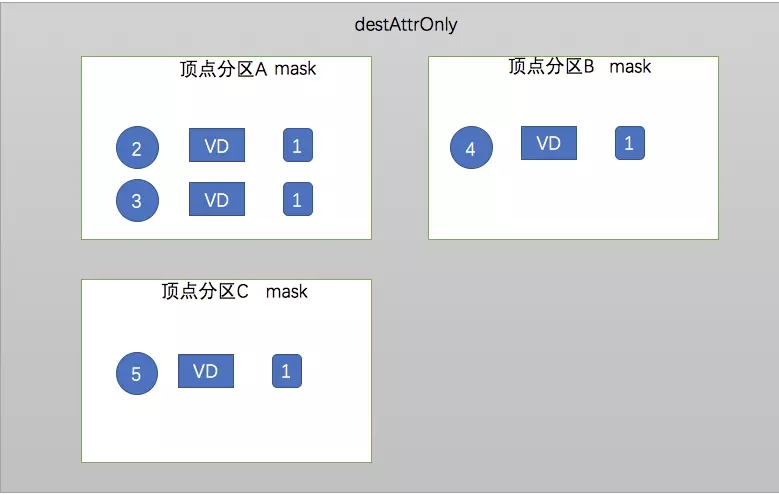
destAttrOnly
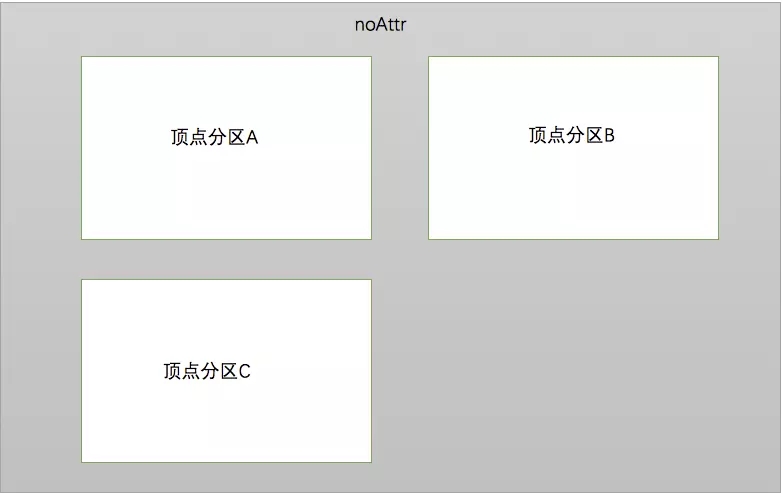
noAttr
жиИДЖЅЕуЪгЭМДДНЈжЎКѓОЭЛсБЛМгдиЕНФкДцЃЌвђЮЊЭММЦЫуЙ§ГЬжаЃЌЫћПЩФмЛсБЛЖрДЮЪЙгУЃЌШчЙћГЬађВЛдйЪЙгУжиИДЖЅЕуЪгЭМЃЌФЧУДОЭашвЊЪжЖЏЕїгУGraphImplжаЕФunpersistVerticesЃЌНЋЦфДгФкДцжаЩОГ§ЁЃ
ЩњГЩжиИДЖЅЕуЪгЭМЪБЃЌдкБпRDDЕФУПИіЗжЧјжаДДНЈМЏКЯЃЌДцДЂИУЗжЧјАќКЌЕФдДЖЅЕуКЭФПЕФЖЅЕуЕФIDМЏКЯЃЌИУМЏКЯБЛГЦзїБОЕиЖЅЕуIDгГЩфЃЈlocal
VertexId MapЃЉЃЌдкЩњГЩжиИДЖЅЕуЪгЭМЪБЃЌШєжиИДЖЅЕуЪгЭМЪБЕквЛДЮБЛДДНЈЃЌдђАбБОЕиЖЅЕуIDгГЩфКЭЗЂЫЭИјБпRDDИїЗжЧјЕФЖЅЕуЪ§ОнзщКЯЦ№РДЃЌдкУПИіЗжЧјжавдЗжЧјЕФБОЕиЖЅЕуIDгГЩфЮЊЫїв§ДцДЂЖЅЕуЪ§ОнЃЌЩњГЩаТЕФЖЅЕуЗжЧјЃЌзюКѓЕУЕНвЛИіаТЕФЖЅЕуRDDЃЌШєжиИДЖЅЕуЪгЭМВЛЪЧЕквЛДЮБЛДДНЈЃЌдђЪЙгУжЎЧАжиИДЖЅЕуЪгЭМДДНЈЕФЖЅЕуRDDдЄЗЂЫЭИјБпRDDИїЗжЧјЕФЖЁДјФуИќаТЪ§ОнНјааСЌНгЃЈjoinЃЉВйзїЃЌИќаТЖЅЕуRDDжаЖЅЕуЕФЪ§ОнЃЌЩњГЩаТЕФЖЅЕуRDDЁЃ
GraphX дкЖЅЕу RDD КЭБп RDD ЕФЗжЧјжавдЪ§зщаЮЪНДцДЂЖЅЕуЪ§ОнКЭБпЪ§ОнЃЌФПЕФЪЧЮЊСЫВЛЫ№ЪЇдЊЫиЗУЮЪадФмЁЃЭЌЪБЃЌGraphX
дкЗжЧјРяНЈСЂСЫжкЖрЫїв§НсЙЙЃЌИпаЇЕиЪЕЯжПьЫйЗУЮЪЖЅЕуЪ§ОнЛђБпЪ§ОнЁЃдкЕќДњЙ§ГЬжаЃЌЭМЕФНсЙЙВЛЛсЗЂЩњБфЛЏЃЌвђЖјЖЅЕу
RDDЁЂБп RDD вдМАжиИДЖЅЕуЪгЭМжаЕФЫїв§НсЙЙШЋВППЩвджигУЃЌЕБгЩвЛИіЭМЩњГЩСэвЛИіЭМЪБЃЌжЛаыИќаТЖЅЕу
RDD КЭБп RDD ЕФЪ§ОнДцДЂЪ§зщЃЌвђДЫЃЌЫїв§НсЙЙЕФжигУБЃГжСЫGraphX ИпадФмЃЌвВЪЧЯрЖдгкдЩњ
RDD ЪЕЯжЭМФЃаЭадФмФмЙЛДѓЗљЬсИпЕФжївЊдвђЁЃ
-ЗжЧјЗНЪНМђНщ
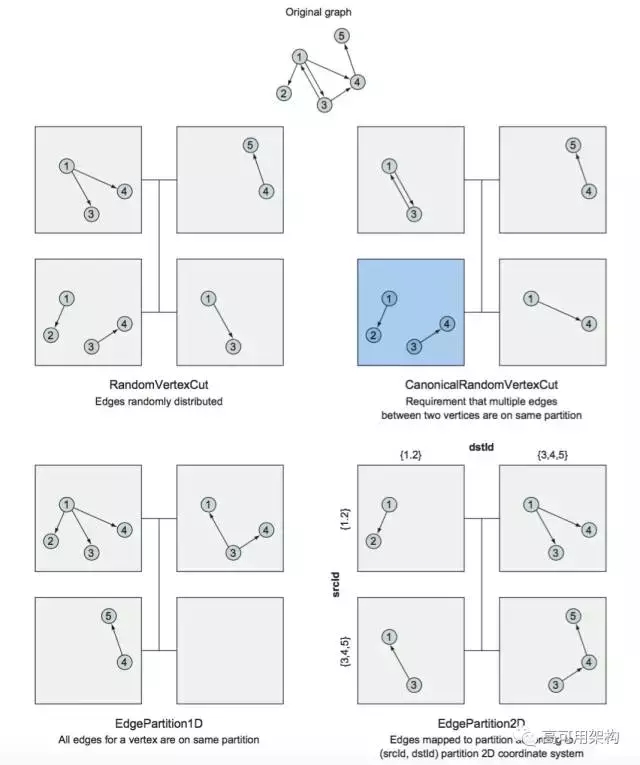
ЗжЧјЗНЪН
ЫуЗЈ
зюаЁТЗОЖЫуЗЈ
val sourceId:
VertexId = 5L
val initialGraph = graph.mapVertices((id, _) =>
if (id == sourceId) 0.0 else Double.PositiveInfinity)
val sssp = initialGraph.pregel(
Double.PositiveInfinity,
activeDirection = EdgeDirection.Out
)(
(vertexId, vertexValue, msg) =>
math.min(vertexValue, msg),//vprog,зїгУЪЧДІРэЕНДяЖЅЕуЕФВЮЪ§ЃЌШЁНЯаЁЕФФЧИізїЮЊЖЅЕуЕФжЕ
triplet => { //sendMsg,МЦЫуШЈжиЃЌШчЙћСкОгНкЕуЕФЪєадМгЩЯБпЩЯЕФОрРыаЁгкИУНкЕуЕФЪєадЃЌЫЕУїДгдДНкЕуБШДгСкОгНкЕуЕНИУЖЅЕуЕФОрРыИќаЁЃЌИќаТжЕ
if (triplet.srcAttr + triplet.attr < triplet.dstAttr)
{
Iterator((triplet.dstId, triplet.srcAttr + triplet.attr))
} else {
Iterator.empty
}
},
(a, b) => math.min(a, b) //mergeMsgЃЌКЯВЂЕНДяЖЅЕуЕФЫљгааХЯЂ
)
println(sssp.vertices.collect.mkString("\n")) |
вдЩЯДњТыЪЧЧѓНкЕуIDЮЊ5ЕФЫљгаПЩЕНДяНкЕуЕФзюЖЬТЗОЖ
ЫуЗЈЯъНтЃКЪзЯШinitialGraphОЭЯШБщРњЫљгаЕФНкЕуАЩЮвУЧЩшжУЕФФПБъНкЕуЩшжУЕФЪєаджЕЩшжУГЩ0.0ЦфЫћЕФЫљгаНкЕуЩшжУГЩе§ЮоЧюЃЌpregelжаЕФDouble.PositiveInfinityЪЧГѕЪМЛЏВЮЪ§ЃЌдкpregelжДааЕФЙ§ГЬжаЕФЕквЛДЮЕќДњЪБЃЌЛсГѕЪМЛЏЫљгаЕФНкЕуЪєаджЕЃЌЛсИљОнЯТБпЕФvprog
= (vertexId, vertexValue, msg) => math.min(vertexValue,
msg),//ЃЈvprog,зїгУЪЧДІРэЕНДяЖЅЕуЕФВЮЪ§ЃЌШЁНЯаЁЕФФЧИізїЮЊЖЅЕуЕФжЕЃЉШЅДІРэЫљгаЕФНкЕуЃЌЫљвдЃЌГѕЪМЛЏКѓГ§СЫ5НкЕуЕФЪєаджЕЮЊ0.0ЭтЃЌЦфЫћЕФЖМЪЧе§ЮоЧюЁЃactiveDirection
= EdgeDirection.OutЯоЖЈЫљгаЕФгааЇЗНЯђЪЧГіБпЃЌtripletЯоЖЈСЫжЛгадкУПДЮЕќДњжаТњзуtriplet.srcAttr
+ triplet.attr < triplet.dstAttrЬѕМўЕФВХЛсИќаТЕБЧАНкЕужЕЃЌзюКѓ(a,
b) => math.min(a, b)ЗНЗЈКЯВЂСЫЕќДњЕНЕБЧАЫљгаНгЪмЕНЯћЯЂЕФЖЅЕуЕФЪєаджЕЃЌвВОЭЪЧЫЕевЕНдДЖЅЕуЕНПЩДяЖЅЕужаЕФТЗОЖзюаЁЕФФЧИіПЩДяЖЅЕуЁЃВЛЖЯЕФЕќДњЯТШЅЃЌзюКѓЩЈУшЭъећИіЭМЃЌзюжеЕУГіЕНЫљгаПЩДяЖЅЕузюЖЬТЗОЖЁЃ
евГіФПБъНкЕуЫљгаЕФ2ЬјНкЕу
val friends
= Pregel(
graph.mapVertices((vid,value) => if(vid ==2)
2 else -1),//ГѕЪМЛЏаХЯЂЃЌдДНкЕуЮЊ2ЃЌЦфЫћНкЕуЮЊ-1
-1,
2,
EdgeDirection.Either
)(
vprog = (vid,attr,msg) =>math.max(attr, msg),//ЖЅЕуВйзїЃЌЕНРДЕФЪєадКЭдЪєадБШНЯЃЌНЯДѓЕФзїЮЊИУНкЕуЕФЪєад
edge => {
if (edge.srcAttr <= 0) {
if (edge.dstAttr <= 0) {
Iterator.empty//ЖМаЁгк0ЃЌЫЕУїДгдДНкЕуЛЙУЛгаДЋЕнЕНетРя
}else {
Iterator((edge.srcId,edge.dstAttr - 1))//ФПЕФНкЕуДѓгк0ЃЌНЋФПЕФНкЕуЪєадМѕвЛИГжЕИјдДНкЕу
}
}else {
if(edge.dstAttr <= 0) {
Iterator((edge.dstId,edge.srcAttr -1))//дДНкЕуДѓгк0ЃЌНЋдДНкЕуЪєадМѕвЛИГжЕИјФПЕФНкЕу
}else {
Iterator.empty//ЖМДѓгк0ЃЌЫЕУїдкЖўЬјНкЕувдФкЃЌВЛВйзї
}
}
},
(a,b) => math.max(a, b)//ЕБгаЖрИіЪєадДЋЕнЕНвЛИіНкЕуЃЌШЁДѓЕФЃЌвђЮЊДѓЕФРыдДНкЕуИќНќ
).subgraph(vpred =(vid,v) =>v >= 0)
friends.vertices.collect.foreach(println(_)) |
ЫуЗЈЯъНтЃКЪзЯШЃЌАбФПБъНкЕуЕФЪєаджЕжУЮЊ2ЃЌГѕЪМЛЏЦфЫћЕФЫљгаЕФНкЕуЕФЪєаджЕЮЊ-1ЃЌЕквЛДЮЕќДњЯћЯЂЃЈ-1ЃЉГѕЪМЛЏОЭЪЧИљОнvprog
= (vid, attr, msg) => math.max(attr, msg)дйЙ§ТЫвЛБщНкЕуЃЌдкЪЃЯТЕФЕќДњЙ§ГЬжаЃЌedgeжаЕФЬѕМўЯоЖЈжЛЩЈУшЃК
ЃЈ1ЃЉШчЙћдДаЁгк0ЃЌФПБъвВаЁгк0ЃЌдђВЛЗЂЯћЯЂ
ЃЈ2ЃЉШчЙћдДаЁгк0ЃЌФПБъДѓгк0ЃЌдђФПБъжЕ-1ИГИјдДНкЕу
ЃЈ3ЃЉШчЙћдДДѓгк0ЃЌФПБъжЕвВДѓгк0ЃЌдђВЛЗЂЯћЯЂ
ЃЈ4ЃЉШчЙћдДДѓгк0ЃЌФПБъжЕаЁгк0ЃЌдђАбдД-1ИГИјФПБъНкЕу
вВОЭЪЧЫЕжЛЛсдкгае§ИКВюОрЕФЕФНкЕужЎМфВХЛсгаЯћЯЂДЋЕн
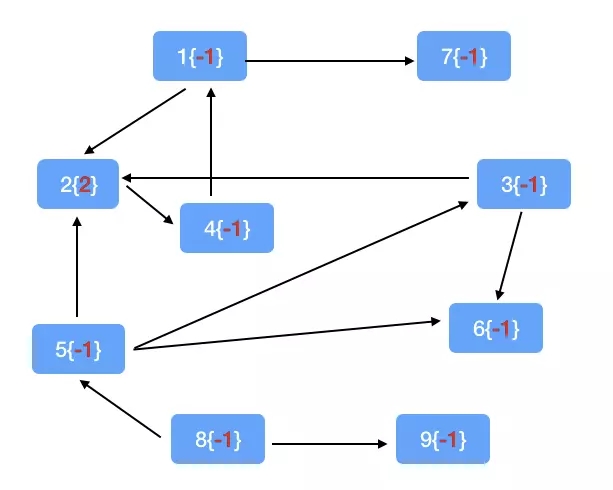
ГѕЪМЛЏЭМ
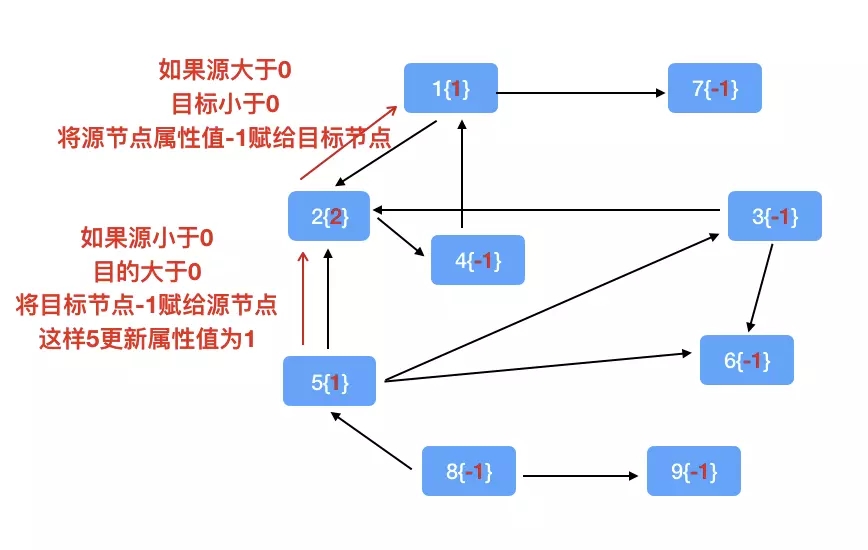
ЬѕМўБщРњ
ЫуЗЈ
pageRank
ИУЫуЗЈОЭВЛЙ§ЖрНщЩмСЫЃЌжБНгЩЯДњТыЃЌЛљгкgraphxЕФЪЕЯжЃЌЯыСЫНтОпЬхЫуЗЈЕФЧыАйЖШЛђепgoogleвЛДѓЖб
етРяЪзЯШМйЩшСЫФувбОМгдиСЫвЛИіЭМ
graph.pageRank(0.001,0.15)
.vertices //СаГіЫљгаЕу
.sortBy(_._2, false) //ИљОнpagerankНЕађХХађ
.take(20) //ШЁГіЧА20Иі
.foreach(println) |
КмМђЕЅЃЌНтЪЭЯТВЮЪ§ЃК0.001ЪЧИіШнШЬЖШЃЌЪЧдкЖдЯТБпЙЋЪННјааЕќДњЙ§ГЬжаЭЫГіЕќДњЕФЬѕМўЃЌ0.15вВЪЧФЌШЯЕФГѕЪМЬјзЊИХТЪЃЌвВОЭЪЧЙЋЪНжаЕФresetProb
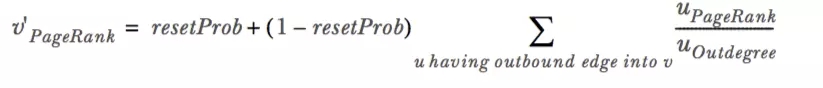
ЙЋЪН
ИіадЛЏpageRank
ИУЫуЗЈжївЊгУгкЭЦМіжаЃЌБШШчЩчНЛЭјТчжаЃЌЖдгкФГИіШЫРДЫЕЃЌФуЯыИјЫћдйЭЦМівЛИіШЫЃЌЕБШЛетИіБЛЭЦМіЕФетИіШЫПЯЖЈЪЧФЧИіФГШЫИааЫШЄЕФЁЃЛђепЖдгкгУЛЇЩЬЦЗЕФЭЦМіжаЃЌгУЛЇЩЬЦЗСНИіЪЕЬхПЩвдаЮГЩвЛИіЭМЃЌЮвУЧОЭПЩвдИљОнОпЬхЕФФГИігУЛЇРДИјЫћЭЦМівЛаЉЩЬЦЗ
graph.personalizedPageRank(34175,
0.001) //ФГШЫЪЧ34175
.vertices
.filter(_._1 != 34175)
.reduce((a,b) => if (a._2 > b._2) a else
b) //евГіФЧИі34175ИааЫШЄЕФШЫ |
Ш§НЧЛЗЭГМЦ
Ш§НЧЛЗЭГМЦгІгУГЁОАЃКДѓЙцФЃЕФЩчЧјЗЂЯжЃЌЭЈЙ§ИУЫуЗЈПЩвдзіШКЬхадМьВтЃЌЩчНЛЭјТчжаОЭЪЧФЧжжзщЭХЕФЁЂЙиЯЕИДдгЕФЃЌЛЅЯргавЛЭШЧщПіБШНЯЖрЕФЁЃвВОЭЪЧЫЕЃЌдкФГИігУЛЇЯТБпЃЌетИіШЫгЕгадНЖрЕФШ§НЧаЮЛЗЃЌФЧУДетИіШЫОЭгЕгадНЖрЕФСЌНгЃЌетбљОЭПЩвдМьВтвЛаЉаЁЭХЬхЃЌаЁХЩЯЕЕШЃЌЭЌЪБвВПЩвджЇГжвЛаЉЭЦМіЃЌШЗШЯвЛаЉдьвЅЩњЪТепЃЈФмЙЛИљОнЭМШЅевЕНвЅбдЕФЩЂВЅепЃЉЃЌжЛвЊЪЧИњДѓЙцФЃаЁЭХЬхМьВтЗНУцИУЫуЗЈЖМПЩвдКмКУЕФжЇГж
graph.triangleCount()
.vertices
.sortBy(_._2, false)
.take(20)
.foreach(println) |
евГігЕгаШ§НЧаЮЛЗЙиЯЕЕФзюЖрЕФЖЅЕу
зюЖЬТЗОЖЫуЗЈ
зюЫсТЗОЖЫуЗЈЕФдРэЩЯУцвбОЫЕЙ§СЫЃЌЯждкРћгУgraphxФкжУЕФЗНЪНЪЕЯж
ShortestPaths.run(diseaseSymptom,Array(19328L))
.vertices
.filter(!_._2.isEmpty)
.foreach(println) |
Цфжа19328LЪЧздЖЈвхЕФЦ№ЪМЕу
(266,Map(19328
-> 15))
(282,Map(19328 -> 12))
(770,Map(19328 -> 9))
(1730,Map(19328 -> 11))
(2170,Map(19328 -> 6))
(1530,Map(19328 -> 13))
(1346,Map(19328 -> 14))
(378,Map(19328 -> 3))
(1378,Map(19328 -> 11))
(970,Map(19328 -> 10))
... |
НсЙћШчЩЯЃЌ(266,Map(19328 -> 15))БэЪО19328ЕН266ЕФзюЖЬТЗОЖЮЊ15
ЖРСЂШКЬхМьВтЃК
ЖРСЂШКЬхМьВтОЭЪЧЗЂЯжФЧаЉВЛКЯШКЕФГЩЗжЃЌШчЯТЭМЃК
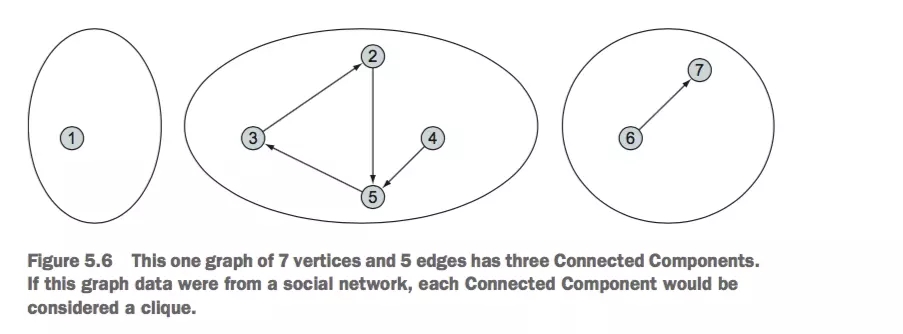
ЖРСЂГЩЗж
val g = Graph(sc.makeRDD((1L
to 7L).map((_,""))),
sc.makeRDD(Array(Edge(2L,5L,""), Edge(5L,3L,""),
Edge(3L,2L,""),
Edge(4L,5L,""), Edge(6L,7L,""))))
g.connectedComponents
.vertices
.map(_.swap)
.groupByKey()
.map(_._2)
.foreach(println) |
ЪфГіНсЙћЃК
CompactBuffer(6,
7)
CompactBuffer(4, 2, 3, 5)
CompactBuffer(1) |
ЧПСЌНгЭјТч
ЫљЮНЕФЧПСЌНгЭјТчОЭЪЧЃКдкетИіЭјТчжаЮоТлФуДгФФИіЖЅЕуПЊЪМЃЌЦфЫћЫљгаЖЅЕуЖМЪЧПЩДяЕФЃЌОЭШчЯТЭМЃК
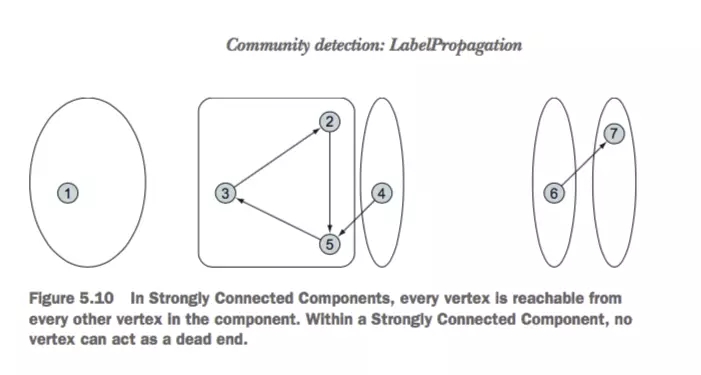
ЧПСЌНгЭјТч
g.stronglyConnectedComponents(3)
.vertices.map(_.swap)
.groupByKey()
.map(_._2)
.foreach(println) |
Цфжа3ЪЧзюДѓЕќДњДЮЪ§ЃЌдкЩЯБпЭМжаЃЌЕќДњШ§ДЮИеКУЃЌвВПЩвдЩшжУЕФДѓвЛЕуЃЌВЛЙ§НсЙћЖМЪЧвЛбљЕФ
БъЧЉДЋВЅЫуЗЈЃЈLPAЃЉ
жївЊЪЧгУгкЭХЬхМьВтЃЌLPAФмЙЛвдНгНќЯпадИДдгЖШШЅМьВтвЛИіДѓЙцФЃЭМжаЕФЭХЬхНсЙЙЃЌжївЊЫМЯыЪЧИјЫљгаЖЅЕужаЕФУмМЏСЌНгзщДђЩЯвЛИіЮЈвЛБъЧЉЃЌетаЉгЕгаЯрЭЌБъЧЉЕФзщОЭЪЧЫљЮНЕФЭХЬх
ИУЫуЗЈГЃГЃЪЧВЛЪеСВЕФЃЌШчЯТЭМ
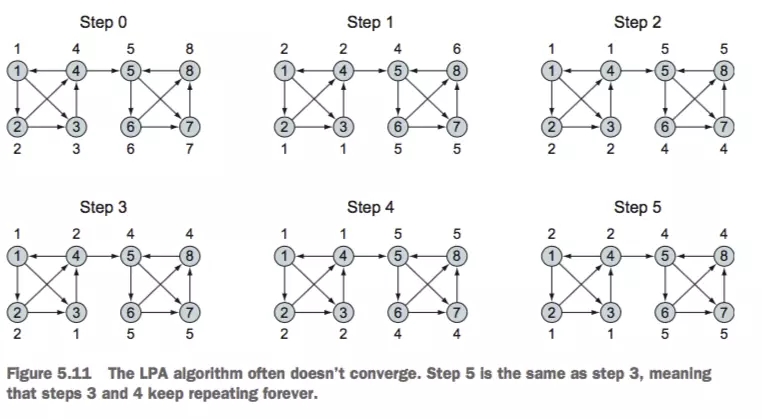
БъЧЉДЋВЅЫуЗЈ
ИУЫуЗЈвВПЩвдгУгкАыМрЖНбЇЯАЃЈДѓВПЗжУЛгаБъЧЉЃЌаЁВПЗжгаБъЧЉЃЉЃЌИјФЧаЉУЛгаБъЧЉЕФЭЈЙ§БъЧЉДЋВЅЫуЗЈНјааДђБъЧЉЁЃвВПЩвдгІгУгкЗчПиЃЌЖдгкЭЈЙ§вбгаЗчЯеЦРЙРЕФШЫЃЌЭЈЙ§ЩчНЛЭјТчШЅЦРЙРКЮЦфгаЙиЯЕЕФШЫЕФЗчЯе
DijkstraЫуЗЈЕФЪЕЯж
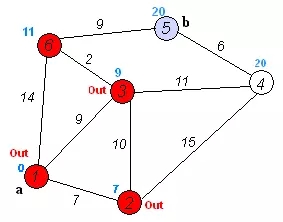
ЫуЗЈЭМ
ОЭФУетИіЭМЮЊР§
ЫуЗЈВНжшОЭЪЧЃК
ЃЈ1ЃЉЪзЯШГѕЪМЛЏЭМЃЌАбЦ№ЪМФПБъНкЕуЪєаджЕЩшжУГЩ0ЃЌЦфЫћЕФНкЕуЩшжУГЩе§ЮоЧюЃЌЭЌЪБАбНкЕузДЬЌШЋВПЩшжУГЩЮДМЄЛюзДЬЌ
ЃЈ2ЃЉШЛКѓНјШыЕќДњВйзїЃЌЕќДњЕФДЮЪ§ЮЊЫљгаЖЅЕуЕФИіЪ§ЃЌНјШыЕќДњЙ§ГЬЃКевЕНЕБЧАЕФНкЕуЃЈОЭЪЧУПДЮЕќДњЙ§ГЬжаКьЩЋЕФЕуЃЉЃЌУПДЮЕќДњЖМЛсЩњГЩвЛИіаТЕФЭМЃЌжївЊЪЧвђЮЊRDDЪЧВЛПЩБфЕФЃЌШчЙћЯыИќаТвЛИіRDDОЭБиаыЩњГЩвЛИіаТЕФRDDШЛКѓАбСНИіRDDдйjoinЦ№РДЃЌЫљвдНгЯТРДОЭЪЧЩњГЩаТЭМЕФЙ§ГЬЃЌеыЖдИеВХевЕНЕФЕБЧАНкЕуЃЌЮвУЧЯђЫќЕФФПЕФжИЯђЖЅЕуЗЂЫЭЯћЯЂЃЌЯћЯЂОЭЪЧЕБЧАНкЕуЕФЪєаджЕМгЩЯжИЯђБпЩЯЕФШЈжиЃЌШЛКѓдйКЯВЂФПЕФНкЕуЕФЪєаджЕЃЌШЁЦфжазюаЁЕФЪєаджЕЃЌЦфЪЕОЭЪЧбЁдёЕБЧАНкЕуЕФФПЕФвЛИізюгХФПЕФНкЕузїЮЊЯТвЛТжЕќДњЕФЕБЧАНкЕуЁЃдкЕБЧАНкЕужаЃЌЗЂЫЭЯћвдМАКЯВЂФПЕФНкЕуЕФЪєаджЕвдКѓОЭЛсЩњГЩвЛИіаТЕФЭМЃЌЮЊСЫИќаТГѕЪМЭМЃЌЮвУЧетРяжЛФмouterJoinVerticesЃЌАбСНИіЭМjoinЦ№РДЃЌетбљВЛЭЃЕФЕќДњЃЌжБЕНЫљгаЖЅЕуЖМЪЧМЄЛюЕФ
def dijkstra[VD](g:Graph[VD,Double],
origin:VertexId) = {
//ГѕЪМЛЏЦ№ЪМНкЕуЕФЪєаджЕ
var g2 = g.mapVertices(
(vid,vd) => (false, if (vid == origin) 0 else
Double.MaxValue))
for (i <- 1L to g.vertices.count-1) {
val currentVertexId =
g2.vertices.filter(!_._2._1)
.fold((0L,(false,Double.MaxValue)))((a,b) =>
if (a._2._2 < b._2._2) a else b)
._1
val newDistances = g2.aggregateMessages[Double](
ctx => if (ctx.srcId == currentVertexId)
ctx.sendToDst(ctx.srcAttr._2 + ctx.attr),
(a,b) => math.min(a,b))
g2 = g2.outerJoinVertices(newDistances)((vid,
vd, newSum) =>
(vd._1 || vid == currentVertexId,
math.min(vd._2, newSum.getOrElse(Double.MaxValue))))
}
g.outerJoinVertices(g2.vertices)((vid, vd, dist)
=>
(vd, dist.getOrElse((false,Double.MaxValue))._2))
} |
|









