| БрМЭЦМі: |
| БОЮФРДздcsdn
ЃЌЮФеТжївЊНщЩмСЫhdfsЕФЙЄзїЛњжЦКЭHDFSЖСЁЂаДЪ§ОнСїГЬЃЌNAMENODEКЭDATANODEЕФЙЄзїЛњжЦЕШЯрЙиФкШнЃЌЯЃЭћФмЖдФњгаЫљАяжњЁЃ |
|
ПЮГЬДѓИйЃЈHDFSЯъНтЃЉ
Hadoop HDFS ЗжВМЪНЮФМўЯЕЭГDFSМђНщ
HDFSЕФЯЕЭГзщГЩНщЩм
HDFSЕФзщГЩВПЗжЯъНт
ИББОДцЗХВпТдМАТЗгЩЙцдђ
УќСюааНгПк
JavaНгПк
ПЭЛЇЖЫгыHDFSЕФЪ§ОнСїНВНт
бЇЯАФПБъЃК
еЦЮеhdfsЕФshellВйзї
еЦЮеhdfsЕФjava apiВйзї
РэНтhdfsЕФЙЄзїдРэ
HDFSЛљБОИХФюЦЊ
1.1HDFSЧАбд
ЩшМЦЫМЯы
ЗжЖјжЮжЎЃКНЋДѓЮФМўЁЂДѓХњСПЮФМўЃЌЗжВМЪНДцЗХдкДѓСПЗўЮёЦїЩЯЃЌвдБугкВЩШЁЗжЖјжЮжЎЕФЗНЪНЖдКЃСПЪ§ОнНјаадЫЫуЗжЮіЃЛ
дкДѓЪ§ОнЯЕЭГжазїгУЃК
ЮЊИїРрЗжВМЪНдЫЫуПђМмЃЈШчЃКmapreduceЃЌsparkЃЌtezЃЌЁЁЃЉЬсЙЉЪ§ОнДцДЂЗўЮё
жиЕуИХФюЃКЮФМўЧаПщЃЌИББОДцЗХЃЌдЊЪ§Он
ВЙГфЃК
hdfsЪЧМмдкБОЕиЮФМўЯЕЭГЩЯУцЕФЗжВМЪНЮФМўЯЕЭГЃЌЫќОЭЪЧИіШэМўЃЌвВОЭЪЧгУвЛЬзДњТыАбЕзЯТЫљгаЛњЦїЕФгВХЬБфГЩвЛИіШэМўЯТЕФФПТМЃЌКЭmysqlУЛгаЪВУДЧјБ№ЃЌЫМЯывЛбљЁЃ
mysql БОжЪЪЧвЛИіНтЮіЦїЃЌАбsqlБфГЩioШЅЖСЮФМўЃЌдйАбЪ§ОнзЊЛЛГіРДИјгУЛЇЃЌДцЮФМўЕФЕзВуОЭЪЧЪЙгУlinuxЛђепwindowsЕФЮФМўЯЕЭГЃЌЮФМўУћОЭЪЧБэУћЃЌФПТМУћОЭЪЧПтУћЁЃ
1.2HDFSЕФИХФюКЭЬиад
ЪзЯШЃЌЫќЪЧвЛИіЮФМўЯЕЭГЃЌгУгкДцДЂЮФМўЃЌЭЈЙ§ЭГвЛЕФУќУћПеМфЁЊЁЊФПТМЪїРДЖЈЮЛЮФМў
ЦфДЮЃЌЫќЪЧЗжВМЪНЕФЃЌгЩКмЖрЗўЮёЦїСЊКЯЦ№РДЪЕЯжЦфЙІФмЃЌМЏШКжаЕФЗўЮёЦїгаИїздЕФНЧЩЋЃЛ
живЊЬиадШчЯТЃК
ЃЈ1ЃЉHDFSжаЕФЮФМўдкЮяРэЩЯЪЧЗжПщДцДЂЃЈblockЃЉЃЌПщЕФДѓаЁПЩвдЭЈЙ§ХфжУВЮЪ§( dfs.blocksize)РДЙцЖЈЃЌФЌШЯДѓаЁдкhadoop2.xАцБОжаЪЧ128MЃЌРЯАцБОжаЪЧ64M
ЃЈ2ЃЉHDFSЮФМўЯЕЭГЛсИјПЭЛЇЖЫЬсЙЉвЛИіЭГвЛЕФГщЯѓФПТМЪїЃЌПЭЛЇЖЫЭЈЙ§ТЗОЖРДЗУЮЪЮФМўЃЌаЮШчЃКhdfs://namenode:port/dir-a/dir-b/dir-c/file.data
ЃЈ3ЃЉ**ФПТМНсЙЙМАЮФМўЗжПщаХЯЂ(дЊЪ§Он)**ЕФЙмРэгЩnamenodeНкЕуГаЕЃ
ЁЊЁЊnamenodeЪЧHDFSМЏШКжїНкЕуЃЌИКд№ЮЌЛЄећИіhdfsЮФМўЯЕЭГЕФФПТМЪїЃЌвдМАУПвЛИіТЗОЖЃЈЮФМўЃЉЫљЖдгІЕФblockПщаХЯЂЃЈblockЕФidЃЌМАЫљдкЕФdatanodeЗўЮёЦїЃЉ
ЃЈ4ЃЉЮФМўЕФИїИіblockЕФДцДЂЙмРэгЩdatanodeНкЕуГаЕЃ
---- datanodeЪЧHDFSМЏШКДгНкЕуЃЌУПвЛИіblockЖМПЩвддкЖрИіdatanodeЩЯДцДЂЖрИіИББОЃЈИББОЪ§СПвВПЩвдЭЈЙ§ВЮЪ§ЩшжУdfs.replicationЃЉ
ВЙГфЃКЭЌвЛИіblockВЛЛсДцДЂЖрЗн(Дѓгк1)дкЭЌвЛИіdatanodeЩЯЃЌвђЮЊетбљУЛгавтвхЁЃ
ЃЈ5ЃЉHDFSЪЧЩшМЦГЩЪЪгІвЛДЮаДШыЃЌЖрДЮЖСГіЕФГЁОАЃЌЧвВЛжЇГжЮФМўЕФаоИФ
(зЂЃКЪЪКЯгУРДзіЪ§ОнЗжЮіЃЌВЂВЛЪЪКЯгУРДзіЭјХЬгІгУЃЌвђЮЊЃЌВЛБуаоИФЃЌбгГйДѓЃЌЭјТчПЊЯњДѓЃЌГЩБОЬЋИп)
HDFSЛљБОВйзїЦЊ
2.1HDFSЕФshell(УќСюааПЭЛЇЖЫ)Вйзї
2.1.1 HDFSУќСюааПЭЛЇЖЫЪЙгУ
HDFSЬсЙЉshellУќСюааПЭЛЇЖЫЃЌЪЙгУЗНЗЈШчЯТЃК

2.2 УќСюааПЭЛЇЖЫжЇГжЕФУќСюВЮЪ§
[-appendToFile
<localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE>
PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] <localsrc> ...
<dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src>
... <localdst>]
[-count [-q] <path> ...]
[-cp [-f] [-p] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-get [-p] [-ignoreCrc] [-crc] <src> ...
<localdst>]
[-getfacl [-R] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName>
<newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir>
...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>}
<path>]|[--set <acl_spec> <path>]]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-usage [cmd ...]] |
2.3 ГЃгУУќСюВЮЪ§НщЩм
-help
ЙІФмЃКЪфГіетИіУќСюВЮЪ§ЪжВс
-ls
ЙІФмЃКЯдЪОФПТМаХЯЂ
ЪОР§ЃК hadoop fs -ls hdfs://hadoop-server01:9000/
БИзЂЃКетаЉВЮЪ§жаЃЌЫљгаЕФhdfsТЗОЖЖМПЩвдМђаД
ЈC>hadoop fs -ls / ЕШЭЌгкЩЯвЛЬѕУќСюЕФаЇЙћ
==-mkdir ==
ЙІФмЃКдкhdfsЩЯДДНЈФПТМ
ЪОР§ЃКhadoop fs -mkdir -p /aaa/bbb/cc/dd
-moveFromLocal
ЙІФмЃКДгБОЕиМєЧаеГЬљЕНhdfs
ЪОР§ЃКhadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd
-moveToLocal
ЙІФмЃКДгhdfsМєЧаеГЬљЕНБОЕи
ЪОР§ЃКhadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt
ЈCappendToFile
ЙІФмЃКзЗМгвЛИіЮФМўЕНвбОДцдкЕФЮФМўФЉЮВ
ЪОР§ЃКhadoop fs -appendToFile ./hello.txt hdfs://hadoop-server01:9000/hello.txt
ПЩвдМђаДЮЊЃК
Hadoop fs -appendToFile ./hello.txt /hello.txt
-cat
ЙІФмЃКЯдЪОЮФМўФкШн
ЪОР§ЃКhadoop fs -cat /hello.txt
-tail
ЙІФмЃКЯдЪОвЛИіЮФМўЕФФЉЮВ
ЪОР§ЃКhadoop fs -tail /weblog/access_log.1
-text
ЙІФмЃКвдзжЗћаЮЪНДђгЁвЛИіЮФМўЕФФкШн
ЪОР§ЃКhadoop fs -text /weblog/access_log.1
-chgrp
-chmod
-chown
ЙІФмЃКетШ§ИіУќСюИњlinuxЮФМўЯЕЭГжаЕФгУЗЈвЛбљЃЌЖдЮФМўЫљЪєШЈЯо
ЪОР§ЃК
hadoop fs -chmod 666 /hello.txt
hadoop fs -chown someuser:somegrp /hello.txt
-copyFromLocal
ЙІФмЃКДгБОЕиЮФМўЯЕЭГжаПНБДЮФМўЕНhdfsТЗОЖШЅ
ЪОР§ЃКhadoop fs -copyFromLocal ./jdk.tar.gz /aaa/
-copyToLocal
ЙІФмЃКДгhdfsПНБДЕНБОЕи
ЪОР§ЃКhadoop fs -copyToLocal /aaa/jdk.tar.gz
-cp
ЙІФмЃКДгhdfsЕФвЛИіТЗОЖПНБДhdfsЕФСэвЛИіТЗОЖ
ЪОР§ЃК hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
-mv
ЙІФмЃКдкhdfsФПТМжавЦЖЏЮФМў
ЪОР§ЃК hadoop fs -mv /aaa/jdk.tar.gz /
-get
ЙІФмЃКЕШЭЌгкcopyToLocalЃЌОЭЪЧДгhdfsЯТдиЮФМўЕНБОЕи
ЪОР§ЃКhadoop fs -get /aaa/jdk.tar.gz
-getmerge
ЙІФмЃККЯВЂЯТдиЖрИіЮФМў
ЪОР§ЃКБШШчhdfsЕФФПТМ /aaa/ЯТгаЖрИіЮФМў:log.1, log.2,log.3,Ё
hadoop fs -getmerge /aaa/log.* ./log.sum
-put
ЙІФмЃКЕШЭЌгкcopyFromLocal
ЪОР§ЃКhadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
-rm
ЙІФмЃКЩОГ§ЮФМўЛђЮФМўМа
ЪОР§ЃКhadoop fs -rm -r /aaa/bbb/
-rmdir
ЙІФмЃКЩОГ§ПеФПТМ
ЪОР§ЃКhadoop fs -rmdir /aaa/bbb/ccc
-df
ЙІФмЃКЭГМЦЮФМўЯЕЭГЕФПЩгУПеМфаХЯЂ
ЪОР§ЃКhadoop fs -df -h /
-du
ЙІФмЃКЭГМЦЮФМўМаЕФДѓаЁаХЯЂ
ЪОР§ЃК
hadoop fs -du -s -h /aaa/*
-count
ЙІФмЃКЭГМЦвЛИіжИЖЈФПТМЯТЕФЮФМўНкЕуЪ§СП
ЪОР§ЃКhadoop fs -count /aaa/
-setrep
ЙІФмЃКЩшжУhdfsжаЮФМўЕФИББОЪ§СП
ЪОР§ЃКhadoop fs -setrep 3 /aaa/jdk.tar.gz
ВЙГфЃК hadoop dfsadmin -report гУетИіУќСюПЩвдПьЫйЖЈЮЛГіФФаЉНкЕуdownЕєСЫЃЌHDFSЕФШнСПвдМАЪЙгУСЫЖрЩйЃЌвдМАУПИіНкЕуЕФгВХЬЪЙгУЧщПіЁЃ
HDFSдРэЦЊ
hdfsЕФЙЄзїЛњжЦ
ЃЈЙЄзїЛњжЦЕФбЇЯАжївЊЪЧЮЊМгЩюЖдЗжВМЪНЯЕЭГЕФРэНтЃЌвдМАдіЧПгіЕНИїжжЮЪЬтЪБЕФЗжЮіНтОіФмСІЃЌаЮГЩвЛЖЈЕФМЏШКдЫЮЌФмСІЃЉ
зЂЃККмЖрВЛЪЧеце§РэНтhadoopММЪѕЬхЯЕЕФШЫЛсГЃГЃОѕЕУHDFSПЩгУгкЭјХЬРргІгУЃЌЕЋЪЕМЪВЂЗЧШчДЫЁЃвЊЯыНЋММЪѕзМШЗгУдкЧЁЕБЕФЕиЗНЃЌБиаыЖдММЪѕгаЩюПЬЕФРэНт
3.1 ИХЪі
HDFSМЏШКЗжЮЊСНДѓНЧЩЋЃКNameNodeЁЂDataNode (Secondary Namenode)
NameNodeИКд№ЙмРэећИіЮФМўЯЕЭГЕФдЊЪ§Он(ећИіhdfsЮФМўЯЕЭГЕФФПТМЪїКЭУПИіЮФМўЕФblockаХЯЂ)
DataNode ИКд№ЙмРэгУЛЇЕФЮФМўЪ§ОнПщ
ЮФМўЛсАДееЙЬЖЈЕФДѓаЁЃЈblocksizeЃЉЧаГЩШєИЩПщКѓЗжВМЪНДцДЂдкШєИЩЬЈdatanodeЩЯ
УПвЛИіЮФМўПщПЩвдгаЖрИіИББОЃЌВЂДцЗХдкВЛЭЌЕФdatanodeЩЯ
DatanodeЛсЖЈЦкЯђNamenodeЛуБЈздЩэЫљБЃДцЕФЮФМўblockаХЯЂЃЌЖјnamenodeдђЛсИКд№БЃГжЮФМўЕФИББОЪ§СП
HDFSЕФФкВПЙЄзїЛњжЦЖдПЭЛЇЖЫБЃГжЭИУїЃЌПЭЛЇЖЫЧыЧѓЗУЮЪHDFSЖМЪЧЭЈЙ§ЯђnamenodeЩъЧыРДНјаа
3.2 HDFSаДЪ§ОнСїГЬ
3.2.1 ИХЪі
ПЭЛЇЖЫвЊЯђHDFSаДЪ§ОнЃЌЪзЯШвЊИњnamenodeЭЈаХвдШЗШЯПЩвдаДЮФМўВЂЛёЕУНгЪеЮФМўblockЕФdatanodeЃЌШЛКѓЃЌПЭЛЇЖЫАДЫГађНЋЮФМўж№ИіblockДЋЕнИјЯргІdatanodeЃЌВЂгЩНгЪеЕНblockЕФdatanodeИКд№ЯђЦфЫћdatanodeИДжЦblockЕФИББО
3.2.2 ЯъЯИВНжшЭМ
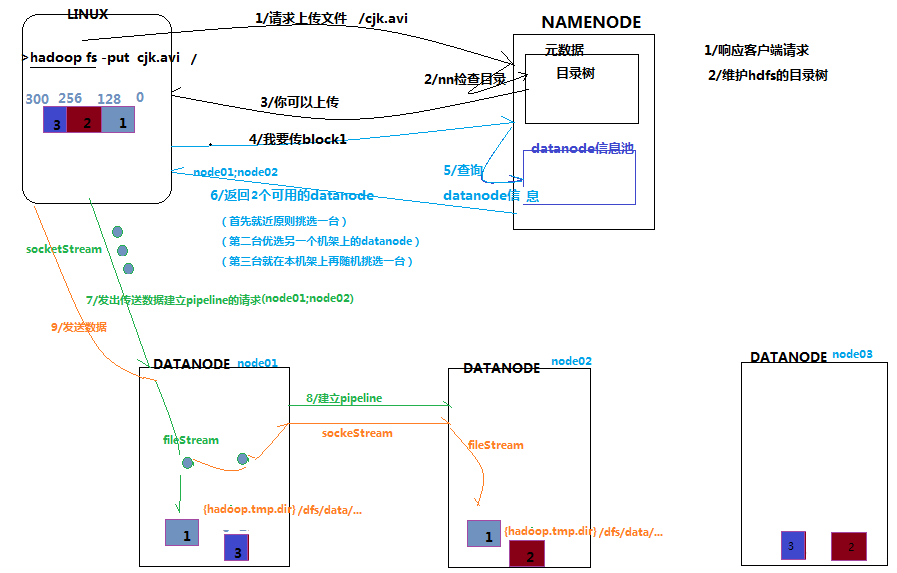
3.2.3 ЯъЯИВНжшНтЮі
ИљnamenodeЭЈаХЧыЧѓЩЯДЋЮФМўЃЌnamenodeМьВщФПБъЮФМўЪЧЗёвбДцдкЃЌИИФПТМЪЧЗёДцдк
namenodeЗЕЛиЪЧЗёПЩвдЩЯДЋ
clientЧыЧѓЕквЛИі blockИУДЋЪфЕНФФаЉdatanodeЗўЮёЦїЩЯ
namenodeЗЕЛи3ИіdatanodeЗўЮёЦїABC
clientЧыЧѓ3ЬЈdnжаЕФвЛЬЈAЩЯДЋЪ§ОнЃЈБОжЪЩЯЪЧвЛИіRPCЕїгУЃЌНЈСЂpipelineЃЉЃЌAЪеЕНЧыЧѓЛсМЬајЕїгУBЃЌШЛКѓBЕїгУCЃЌНЋецИіpipelineНЈСЂЭъГЩЃЌж№МЖЗЕЛиПЭЛЇЖЫ
clientПЊЪМЭљAЩЯДЋЕквЛИіblockЃЈЯШДгДХХЬЖСШЁЪ§ОнЗХЕНвЛИіБОЕиФкДцЛКДцЃЉЃЌвдpacketЮЊЕЅЮЛЃЌAЪеЕНвЛИіpacketОЭЛсДЋИјBЃЌBДЋИјCЃЛAУПДЋвЛИіpacketЛсЗХШывЛИігІД№ЖгСаЕШД§гІД№
ЕБвЛИіblockДЋЪфЭъГЩжЎКѓЃЌclientдйДЮЧыЧѓnamenodeЩЯДЋЕкЖўИіblockЕФЗўЮёЦїЁЃ
3.3. HDFSЖСЪ§ОнСїГЬ
3.3.1 ИХЪі
ПЭЛЇЖЫНЋвЊЖСШЁЕФЮФМўТЗОЖЗЂЫЭИјnamenodeЃЌnamenodeЛёШЁЮФМўЕФдЊаХЯЂЃЈжївЊЪЧblockЕФДцЗХЮЛжУаХЯЂЃЉЗЕЛиИјПЭЛЇЖЫЃЌПЭЛЇЖЫИљОнЗЕЛиЕФаХЯЂевЕНЯргІdatanodeж№ИіЛёШЁЮФМўЕФblockВЂдкПЭЛЇЖЫБОЕиНјааЪ§ОнзЗМгКЯВЂДгЖјЛёЕУећИіЮФМў
3.3.2 ЯъЯИВНжшЭМ
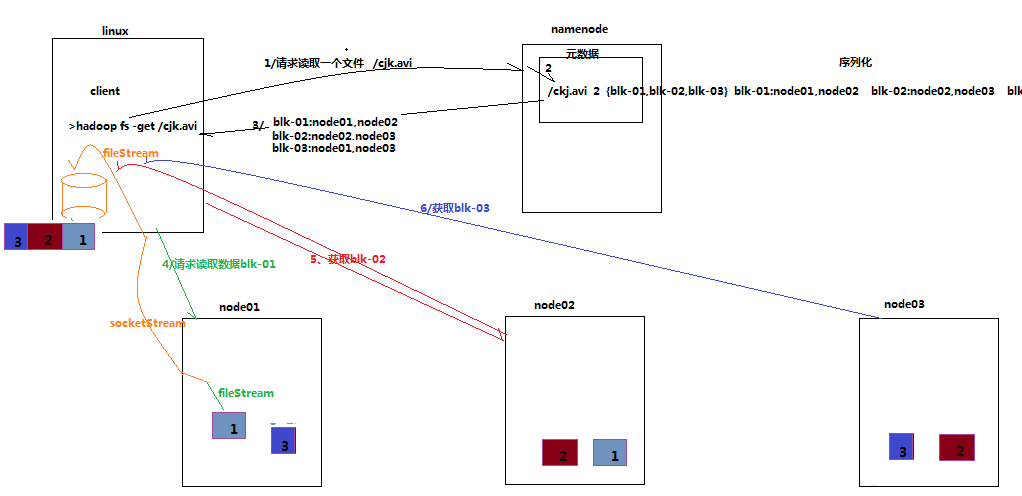
3.3.3 ЯъЯИВНжшНтЮі
ИњnamenodeЭЈаХВщбЏдЊЪ§ОнЃЌnamenodeевЕНЮФМўПщЫљдкЕФdatanodeЗўЮёЦї
ЬєбЁвЛЬЈdatanodeЃЈОЭНќддђЃЌШЛКѓЫцЛњЃЉЗўЮёЦїЃЌЧыЧѓНЈСЂsocketСї
datanodeПЊЪМЗЂЫЭЪ§ОнЃЈДгДХХЬРяУцЖСШЁЪ§ОнЗХШыСїЃЌвдpacketЮЊЕЅЮЛРДзіаЃбщЃЉ
ПЭЛЇЖЫвдpacketЮЊЕЅЮЛНгЪеЃЌЯждкБОЕиЛКДцЃЌШЛКѓаДШыФПБъЮФМў
4 NAMENODEЙЄзїЛњжЦ
бЇЯАФПБъЃКРэНтnamenodeЕФЙЄзїЛњжЦгШЦфЪЧдЊЪ§ОнЙмРэЛњжЦЃЌвддіЧПЖдHDFSЙЄзїдРэЕФРэНтЃЌМАХрбјhadoopМЏШКдЫгЊжаЁАадФмЕїгХЁБЁЂЁАnamenodeЁБЙЪеЯЮЪЬтЕФЗжЮіНтОіФмСІ
ЮЪЬтГЁОАЃК
МЏШКЦєЖЏКѓЃЌПЩвдВщПДЮФМўЃЌЕЋЪЧЩЯДЋЮФМўЪББЈДэЃЌДђПЊwebвГУцПЩПДЕНnamenodeе§ДІгкsafemodeзДЬЌЃЌдѕУДДІРэЃП
NamenodeЗўЮёЦїЕФДХХЬЙЪеЯЕМжТnamenodeхДЛњЃЌШчКЮЭьОШМЏШКМАЪ§ОнЃП
NamenodeЪЧЗёПЩвдгаЖрИіЃПnamenodeФкДцвЊХфжУЖрДѓЃПnamenodeИњМЏШКЪ§ОнДцДЂФмСІгаЙиЯЕТ№ЃП
ЮФМўЕФblocksizeОПОЙЕїДѓКУЛЙЪЧЕїаЁКУЃП
ЁЁ
жюШчДЫРрЮЪЬтЕФЛиД№ЃЌЖМашвЊЛљгкЖдnamenodeздЩэЕФЙЄзїдРэЕФЩюПЬРэНт
4.1 NAMENODEжАд№
NAMENODEжАд№ЃК
ИКд№ПЭЛЇЖЫЧыЧѓЕФЯьгІ
дЊЪ§ОнЕФЙмРэЃЈВщбЏЃЌаоИФЃЉ
4.2 дЊЪ§ОнЙмРэ
namenodeЖдЪ§ОнЕФЙмРэВЩгУСЫШ§жжДцДЂаЮЪНЃК
ФкДцдЊЪ§Он(NameSystem)
ДХХЬдЊЪ§ОнОЕЯёЮФМў(fsimage)
Ъ§ОнВйзїШежОЮФМўЃЈeditsПЩЭЈЙ§ШежОдЫЫуГідЊЪ§ОнЃЉ
4.2.1 дЊЪ§ОнДцДЂЛњжЦ(дЊЪ§ОнЪЧЖдЯѓЃЌгаЬиЖЈЕФЪ§ОнНсЙЙЃЌПЩвдРэНтЮЊhashmapНсЙЙ)
AЁЂФкДцжагавЛЗнЭъећЕФдЊЪ§Он(ФкДцmeta data)
BЁЂДХХЬгавЛИіЁАзМЭъећЁБЕФдЊЪ§ОнОЕЯёЃЈfsimageЃЉЮФМў(дкnamenodeЕФЙЄзїФПТМжа)
CЁЂгУгкЯЮНгФкДцmetadataКЭГжОУЛЏдЊЪ§ОнОЕЯёfsimageжЎМфЕФВйзїШежОЃЈeditsЮФМўЃЉзЂЃКЕБПЭЛЇЖЫЖдhdfsжаЕФЮФМўНјаааТдіЛђепаоИФВйзїЃЌВйзїМЧТМЪзЯШБЛМЧШыeditsШежОЮФМўжаЃЌЕБПЭЛЇЖЫВйзїГЩЙІКѓЃЌЯргІЕФдЊЪ§ОнЛсИќаТЕНФкДцmeta.dataжа
ВЙГф:
1ЁЂfsimageЮФМўЪЧЯпадНсЙЙЃЌЖМЪЧ0КЭ1ЃЌКмФбВщевЛђепаоИФФГЬѕЪ§ОнЃЌЫљвдВХЛсЖЈЦкcheckpointЁЃ
2ЁЂeditsМЧТМЕФЪЧВйзїВНжшЃЌРрЫЦгкmysqlЕФbinlog
3ЁЂfsimageМЧТМЕФЪЧетИіЮФМўБИЗнСЫМИЗнЃЌЗжБ№НаЪВУДУћГЦ

4ЁЂsecondary namenodeНЈвщВЛКЭnamenodeдквЛИіНкЕуЦєЖЏЃЌвђЮЊЫќЛсПНБДдЊЪ§ОнЃЌМгдиЕНФкДцЩњГЩfsimageЃЌЛсеМгУnamenodeЕФФкДцЁЃ(зюМђАц)
5ЁЂдкhadoopЕФИпПЩгУЛњжЦ+FederationЛњжЦжаЃЌУЛгаSecondaryNamenodeЃЌПЩвдЭЈЙ§ЦєЖЏSecondaryNamenodeНјаабщжЄЃЌЛсБЈвЛИіДэЮѓ:ЁАЫќЕФЙІФмБЛStandbyNamenodeШЁДњЁБЁЃ(дкЦєЖЏЕФФЧЬЈЛњЦїЕФlogsЮФМўМаРяУцЕФSecondaryNamenode.log)ЁЃ(ЭъШЋАц)
4.2.2 дЊЪ§ОнЪжЖЏВщПД
ПЩвдЭЈЙ§hdfsЕФвЛИіЙЄОпРДВщПДeditsжаЕФаХЯЂ
bin/hdfs oev -i edits -o edits.xml
bin/hdfs oiv -i fsimage_0000000000000000087 -p XML
-o fsimage.xml
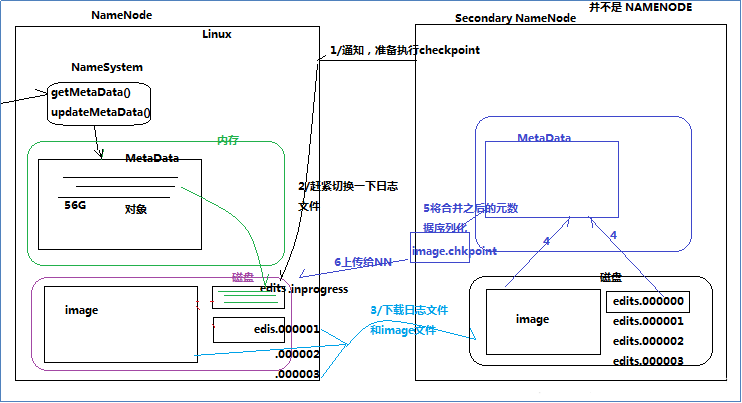
4.2.3 дЊЪ§ОнЕФcheckpoint
УПИєвЛЖЮЪБМфЃЌЛсгЩsecondary namenodeНЋnamenodeЩЯзюаТЕФedits(ЯТдиЙ§ЕФnamenodeЛсЩОГ§)КЭfsimage(ЕквЛДЮЪБЛсЯТдиfsimage,вдКѓВЛЛс)ЯТдиЕНsecondary
namenodeжаЃЌВЂМгдиЕНФкДцНјааmergeЃЈетИіЙ§ГЬГЦЮЊcheckpointЃЉ
checkpointЕФЯъЯИЙ§ГЬ
checkpointВйзїЕФДЅЗЂЬѕМўХфжУВЮЪ§
dfs.namenode.checkpoint.check.period=60
#МьВщДЅЗЂЬѕМўЪЧЗёТњзуЕФЦЕТЪЃЌ60Уы
dfs.namenode.checkpoint.dir=file://KaTeX parse
error: Expected 'EOF', got '#' at position 36:
Ё/namesecondary #?вдЩЯСНИіВЮЪ§зіcheckpoiЁ{dfs.namenode.checkpoint.dir} |
dfs.namenode.checkpoint.max-retries=3
#зюДѓжиЪдДЮЪ§
dfs.namenode.checkpoint.period=3600 #СНДЮcheckpointжЎМфЕФЪБМфМфИє3600Уы
dfs.namenode.checkpoint.txns=1000000 #СНДЮcheckpointжЎМфзюДѓЕФВйзїМЧТМ |
checkpointЕФИНДјзїгУ
namenodeКЭsecondary namenodeЕФЙЄзїФПТМДцДЂНсЙЙЭъШЋЯрЭЌЃЌЫљвдЃЌЕБnamenodeЙЪеЯЭЫГіашвЊжиаТЛжИДЪБЃЌПЩвдДгsecondary
namenodeЕФЙЄзїФПТМжаНЋfsimageПНБДЕНnamenodeЕФЙЄзїФПТМЃЌвдЛжИДnamenodeЕФдЊЪ§ОнЁЃ
4.2.4 дЊЪ§ОнФПТМЫЕУї
дкЕквЛДЮВПЪ№КУHadoopМЏШКЕФЪБКђЃЌЮвУЧашвЊдкNameNodeЃЈNNЃЉНкЕуЩЯИёЪНЛЏДХХЬЃК
| $HADOOP_HOME/bin/hdfs
namenode -format |
ИёЪНЛЏЭъГЩжЎКѓЃЌНЋЛсдк$ dfs. namenode .name.dir/currentФПТМЯТШчЯТЕФЮФМўНсЙЙ
current/
|-- VERSION
|-- edits_*
|-- fsimage_0000000000008547077
|-- fsimage_0000000000008547077.md5
`-- seen_txid |
ЦфжаЕФdfs.name.dirЪЧдкhdfs-site.xmlЮФМўжаХфжУЕФЃЌФЌШЯжЕШчЯТЃК
<property>
<name>dfs.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property> |
hadoop.tmp.dirЪЧдкcore-site.xmlжаХфжУЕФЃЌФЌШЯжЕШчЯТ
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-${user.name}</value>
<description>A base for other temporary
directories.</description>
</property> |
dfs. namenode.name.dirЪєадПЩвдХфжУЖрИіФПТМЃЌ
Шч/data1/dfs/name,/data2/dfs/name,/data3/dfs/name,ЁЁЃИїИіФПТМДцДЂЕФЮФМўНсЙЙКЭФкШнЖМЭъШЋвЛбљЃЌЯрЕБгкБИЗнЃЌетбљзіЕФКУДІЪЧЕБЦфжавЛИіФПТМЫ№ЛЕСЫЃЌвВВЛЛсгАЯьЕНHadoopЕФдЊЪ§ОнЃЌЬиБ№ЪЧЕБЦфжавЛИіФПТМЪЧNFSЃЈЭјТчЮФМўЯЕЭГNetwork
File SystemЃЌNFSЃЉжЎЩЯЃЌМДЪЙФуетЬЈЛњЦїЫ№ЛЕСЫЃЌдЊЪ§ОнвВЕУЕНБЃДцЁЃ
ЯТУцЖд$dfs. namenode .name.dir/current/ФПТМЯТЕФЮФМўНјааНтЪЭЁЃ
VERSIONЮФМўЪЧJavaЪєадЮФМўЃЌФкШнДѓжТШчЯТЃК
#Fri Nov 15 19:47:46
CST 2013
namespaceID=934548976
clusterID=CID-cdff7d73-93cd-4783-9399-0a22e6dce196
cTime=0
storageType=NAME_NODE
blockpoolID=BP-893790215-192.168.24.72-1383809616115
layoutVersion=-47 |
Цфжа
ЃЈ1ЃЉЁЂnamespaceIDЪЧЮФМўЯЕЭГЕФЮЈвЛБъЪЖЗћЃЌдкЮФМўЯЕЭГЪзДЮИёЪНЛЏжЎКѓЩњГЩЕФЃЛ
ЃЈ2ЃЉЁЂstorageTypeЫЕУїетИіЮФМўДцДЂЕФЪЧЪВУДНјГЬЕФЪ§ОнНсЙЙаХЯЂЃЈШчЙћЪЧDataNodeЃЌstorageType=DATA_NODEЃЉЃЛ
ЃЈ3ЃЉЁЂcTimeБэЪОNameNodeДцДЂЪБМфЕФДДНЈЪБМфЃЌгЩгкЮвЕФNameNodeУЛгаИќаТЙ§ЃЌЫљвдетРяЕФМЧТМжЕЮЊ0ЃЌвдКѓЖдNameNodeЩ§МЖжЎКѓЃЌcTimeНЋЛсМЧТМИќаТЪБМфДСЃЛ
ЃЈ4ЃЉЁЂlayoutVersionБэЪОHDFSгРОУадЪ§ОнНсЙЙЕФАцБОаХЯЂЃЌ
жЛвЊЪ§ОнНсЙЙБфИќЃЌАцБОКХвВвЊЕнМѕЃЌДЫЪБЕФHDFSвВашвЊЩ§МЖЃЌЗёдђДХХЬШдОЩЪЧЪЙгУОЩАцБОЕФЪ§ОнНсЙЙЃЌетЛсЕМжТаТАцБОЕФNameNodeЮоЗЈЪЙгУЃЛ
ЃЈ5ЃЉЁЂclusterIDЪЧЯЕЭГЩњГЩЛђЪжЖЏжИЖЈЕФМЏШКIDЃЌдк-clusteridбЁЯюжаПЩвдЪЙгУЫќЃЛШчЯТЫЕУї
aЁЂЪЙгУШчЯТУќСюИёЪНЛЏвЛИіNamenodeЃК
| $HADOOP_HOME/bin/hdfs
namenode -format [-clusterId <cluster_id>] |
бЁдёвЛИіЮЈвЛЕФcluster_idЃЌВЂЧветИіcluster_idВЛФмгыЛЗОГжаЦфЫћМЏШКгаГхЭЛЁЃШчЙћУЛгаЬсЙЉcluster_idЃЌдђЛсздЖЏЩњГЩвЛИіЮЈвЛЕФClusterIDЁЃ
bЁЂЪЙгУШчЯТУќСюИёЪНЛЏЦфЫћNamenodeЃК
| $HADOOP_HOME/bin/hdfs
namenode -format -clusterId <cluster_id> |
cЁЂЩ§МЖМЏШКжСзюаТАцБОЁЃдкЩ§МЖЙ§ГЬжаашвЊЬсЙЉвЛИіClusterIDЃЌР§ШчЃК
$ HADOOP_PREFIX_HOME/bin/hdfs
start namenode --config
$ HADOOP_CONF_DIR -upgrade -clusterId <cluster_ID> |
ШчЙћУЛгаЬсЙЉClusterIDЃЌдђЛсздЖЏЩњГЩвЛИіClusterIDЁЃ
ЃЈ6ЃЉЁЂblockpoolIDЃКЪЧеыЖдУПвЛИіNamespaceЫљЖдгІЕФblockpoolЕФIDЃЌЩЯУцЕФетИіBP-893790215-192.168.24.72-1383809616115ОЭЪЧдкЮвЕФns1ЕФnamespaceЯТЕФДцДЂПщГиЕФIDЃЌетИіIDАќРЈСЫЦфЖдгІЕФNameNodeНкЕуЕФipЕижЗЁЃ
ЁЁЁЁ
2. $dfs.namenode.name.dir/current/seen_txidЗЧГЃживЊЃЌЪЧДцЗХtransactionIdЕФЮФМўЃЌformatжЎКѓЪЧ0ЃЌЫќДњБэЕФЪЧnamenodeРяУцЕФedits_*ЮФМўЕФЮВЪ§ЃЌnamenodeжиЦєЕФЪБКђЃЌЛсАДееseen_txidЕФЪ§зжЃЌбађДгЭЗХмedits_0000001~ЕНseen_txidЕФЪ§зжЁЃЫљвдЕБФуЕФhdfsЗЂЩњвьГЃжиЦєЕФЪБКђЃЌвЛЖЈвЊБШЖдseen_txidФкЕФЪ§зжЪЧВЛЪЧФуeditsзюКѓЕФЮВЪ§ЃЌВЛШЛЛсЗЂЩњНЈжУnamenodeЪБmetaDataЕФзЪСЯгаШБЩйЃЌЕМжТЮѓЩОDatanodeЩЯЖргрBlockЕФзЪбЖЁЃ
$dfs.namenode.name.dir/currentФПТМЯТдкformatЕФЭЌЪБвВЛсЩњГЩfsimageКЭeditsЮФМўЃЌМАЦфЖдгІЕФmd5аЃбщЮФМўЁЃ
ВЙГфЃКseen_txid
ЮФМўжаМЧТМЕФЪЧeditsЙіЖЏЕФађКХЃЌУПДЮжиЦєnamenodeЪБЃЌnamenodeОЭжЊЕРвЊНЋФФаЉeditsНјааМгдиedits
5 DATANODEЕФЙЄзїЛњжЦ
ЮЪЬтГЁОАЃК
1ЁЂМЏШКШнСПВЛЙЛЃЌдѕУДРЉШнЃП
2ЁЂШчЙћгавЛаЉdatanodeхДЛњЃЌИУдѕУДАьЃП
3ЁЂdatanodeУїУївбЦєЖЏЃЌЕЋЪЧМЏШКжаЕФПЩгУdatanodeСаБэжаОЭЪЧУЛгаЃЌдѕУДАьЃП
вдЩЯетРрЮЪЬтЕФНтД№ЃЌгаРЕгкЖдdatanodeЙЄзїЛњжЦЕФЩюПЬРэНт
5.1 ИХЪі
1ЁЂDatanodeЙЄзїжАд№ЃК
ДцДЂЙмРэгУЛЇЕФЮФМўПщЪ§Он
ЖЈЦкЯђnamenodeЛуБЈздЩэЫљГжгаЕФblockаХЯЂЃЈЭЈЙ§аФЬјаХЯЂЩЯБЈЃЉ
ЃЈетЕуКмживЊЃЌвђЮЊЃЌЕБМЏШКжаЗЂЩњФГаЉblockИББОЪЇаЇЪБЃЌМЏШКШчКЮЛжИДblockГѕЪМИББОЪ§СПЕФЮЪЬтЃЉ
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>3600000</value>
<description>Determines
block reporting interval in milliseconds.</description>
</property> |
2ЁЂDatanodeЕєЯпХаЖЯЪБЯоВЮЪ§
datanodeНјГЬЫРЭіЛђепЭјТчЙЪеЯдьГЩdatanodeЮоЗЈгыnamenodeЭЈаХЃЌnamenodeВЛЛсСЂМДАбИУНкЕуХаЖЈЮЊЫРЭіЃЌвЊОЙ§вЛЖЮЪБМфЃЌетЖЮЪБМфднГЦзїГЌЪБЪБГЄЁЃHDFSФЌШЯЕФГЌЪБЪБГЄЮЊ10Зжжг+30УыЁЃШчЙћЖЈвхГЌЪБЪБМфЮЊtimeoutЃЌдђГЌЪБЪБГЄЕФМЦЫуЙЋЪНЮЊЃК
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.intervalЁЃ
ЖјФЌШЯЕФheartbeat.recheck.interval ДѓаЁЮЊ5ЗжжгЃЌdfs.heartbeat.intervalФЌШЯЮЊ3УыЁЃ
ашвЊзЂвтЕФЪЧhdfs-site.xml ХфжУЮФМўжаЕФheartbeat.recheck.intervalЕФЕЅЮЛЮЊКСУыЃЌdfs.heartbeat.intervalЕФЕЅЮЛЮЊУыЁЃЫљвдЃЌОйИіР§згЃЌШчЙћheartbeat.recheck.intervalЩшжУЮЊ5000ЃЈКСУыЃЉЃЌdfs.heartbeat.intervalЩшжУЮЊ3ЃЈУыЃЌФЌШЯЃЉЃЌдђзмЕФГЌЪБЪБМфЮЊ40УыЁЃ
<property>
<name>heartbeat.recheck.interval</name>
<value>2000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>1</value>
</property> |
5.2 ЙлВьбщжЄDATANODEЙІФм
ЩЯДЋвЛИіЮФМўЃЌЙлВьЮФМўЕФblockОпЬхЕФЮяРэДцЗХЧщПіЃК
дкУПвЛЬЈdatanodeЛњЦїЩЯЕФетИіФПТМжаФмевЕНЮФМўЕФЧаПщЃК
/home/hadoop/app/hadoop-2.4.1/tmp/dfs/data/current/BP-193442119-192.168.2.120-1432457733977/current/finalized
5.3дЊЪ§ОнФПТМ(здМКЬэМг,ЪЕВтгааЇ)
ЦфжаЕФdfs.data.dirЪЧдкhdfs-site.xmlЮФМўжаХфжУЕФЃЌФЌШЯжЕШчЯТЃК
<property>
<name>dfs.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property> |
dfs. datanode data.dirЪєадПЩвдХфжУЖрИіФПТМЃЌ
Шч/data1/dfs/ data,/data2/dfs/ data,/data3/dfs/ data,ЁЁЃdatanodeХфжУЖрПщДХХЬКѓЃЌЛсНЋетаЉДХХЬЭГвЛПДГЩЫќЕФПеМфЁЃВЂЗЂЪБгагХЪЦЃЌПЩвдЭљВЛЭЌЕФДХХЬаДЪ§ОнЃЌДХХЬПЩвдВЂааЁЃЯрЕБгкРЉШнЁЃ
ВЙГфЃКblockПщФЌШЯ128MЃЌзюаЁХфжУЮЊ1M
HDFSгІгУПЊЗЂЦЊ
6. HDFSЕФjavaВйзї
hdfsдкЩњВњгІгУжажївЊЪЧПЭЛЇЖЫЕФПЊЗЂЃЌЦфКЫаФВНжшЪЧДгhdfsЬсЙЉЕФapiжаЙЙдьвЛИіHDFSЕФЗУЮЪПЭЛЇЖЫЖдЯѓЃЌШЛКѓЭЈЙ§ИУПЭЛЇЖЫЖдЯѓВйзїЃЈдіЩОИФВщЃЉHDFSЩЯЕФЮФМў
6.1 ДюНЈПЊЗЂЛЗОГ
в§ШывРРЕ
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.1</version>
</dependency> |
зЂЃКШчашЪжЖЏв§ШыjarАќЃЌhdfsЕФjarАќ----hadoopЕФАВзАФПТМЕФshareЯТ
windowЯТПЊЗЂЕФЫЕУї
НЈвщдкlinuxЯТНјааhadoopгІгУЕФПЊЗЂЃЌВЛЛсДцдкМцШнадЮЪЬтЁЃШчдкwindowЩЯзіПЭЛЇЖЫгІгУПЊЗЂЃЌашвЊЩшжУвдЯТЛЗОГЃК
AЁЂдкwindowsЕФФГИіФПТМЯТНтбЙвЛИіhadoopЕФАВзААќ
BЁЂНЋАВзААќЯТЕФlibКЭbinФПТМгУЖдгІwindowsАцБОЦНЬЈБрвыЕФБОЕиПтЬцЛЛ
CЁЂдкwindowЯЕЭГжаХфжУHADOOP_HOMEжИЯђФуНтбЙЕФАВзААќ
DЁЂдкwindowsЯЕЭГЕФpathБфСПжаМгШыhadoopЕФbinФПТМ
6.2 ЛёШЁapiжаЕФПЭЛЇЖЫЖдЯѓ
дкjavaжаВйзїhdfsЃЌЪзЯШвЊЛёЕУвЛИіПЭЛЇЖЫЪЕР§
Configuration
conf = new Configuration()
FileSystem fs = FileSystem.get(conf) |
ЖјЮвУЧЕФВйзїФПБъЪЧHDFSЃЌЫљвдЛёШЁЕНЕФfsЖдЯѓгІИУЪЧDistributedFileSystemЕФЪЕР§ЃЛ
getЗНЗЈЪЧДгКЮДІХаЖЯОпЬхЪЕР§ЛЏФЧжжПЭЛЇЖЫРрФиЃП
ЁЊЁЊДгconfжаЕФвЛИіВЮЪ§ fs.defaultFSЕФХфжУжЕХаЖЯЃЛ
ШчЙћЮвУЧЕФДњТыжаУЛгажИЖЈfs.defaultFSЃЌВЂЧвЙЄГЬclasspathЯТвВУЛгаИјЖЈЯргІЕФХфжУЃЌconfжаЕФФЌШЯжЕОЭРДздгкhadoopЕФjarАќжаЕФcore-default.xmlЃЌФЌШЯжЕЮЊЃК
file:///ЃЌдђЛёШЁЕФНЋВЛЪЧвЛИіDistributedFileSystemЕФЪЕР§ЃЌЖјЪЧвЛИіБОЕиЮФМўЯЕЭГЕФПЭЛЇЖЫЖдЯѓ
6.3 DistributedFileSystemЪЕР§ЖдЯѓЫљОпБИЕФЗНЗЈ6.4 HDFSПЭЛЇЖЫВйзїЪ§ОнДњТыЪОР§ЃК
6.4.1 ЮФМўЕФдіЩОИФВщ
public class
HdfsClient {
FileSystem fs = null;
@Before
public void init() throws Exception {
// ЙЙдьвЛИіХфжУВЮЪ§ЖдЯѓЃЌЩшжУвЛИіВЮЪ§ЃКЮвУЧвЊЗУЮЪЕФhdfsЕФURI
// ДгЖјFileSystem.get()ЗНЗЈОЭжЊЕРгІИУЪЧШЅЙЙдьвЛИіЗУЮЪhdfsЮФМўЯЕЭГЕФПЭЛЇЖЫЃЌвдМАhdfsЕФЗУЮЪЕижЗ
// new Configuration();ЕФЪБКђЃЌЫќОЭЛсШЅМгдиjarАќжаЕФhdfs-default.xml
// ШЛКѓдйМгдиclasspathЯТЕФhdfs-site.xml
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hdp-node01:9000");
/**
* ВЮЪ§гХЯШМЖЃК 1ЁЂПЭЛЇЖЫДњТыжаЩшжУЕФжЕ 2ЁЂclasspathЯТЕФгУЛЇздЖЈвхХфжУЮФМў 3ЁЂШЛКѓЪЧЗўЮёЦїЕФФЌШЯХфжУ
*/
conf.set("dfs.replication", "3");
// ЛёШЁвЛИіhdfsЕФЗУЮЪПЭЛЇЖЫЃЌИљОнВЮЪ§ЃЌетИіЪЕР§гІИУЪЧDistributedFileSystemЕФЪЕР§
// fs = FileSystem.get(conf);
// ШчЙћетбљШЅЛёШЁЃЌФЧconfРяУцОЭПЩвдВЛвЊХф"fs.defaultFS"ВЮЪ§ЃЌЖјЧвЃЌетИіПЭЛЇЖЫЕФЩэЗнБъЪЖвбОЪЧhadoopгУЛЇ
fs = FileSystem.get(new URI("hdfs://hdp-node01:9000"),
conf, "hadoop");
}
/**
* ЭљhdfsЩЯДЋЮФМў
*
* @throws Exception
*/
@Test
public void testAddFileToHdfs() throws Exception
{
// вЊЩЯДЋЕФЮФМўЫљдкЕФБОЕиТЗОЖ
Path src = new Path("g:/redis-recommend.zip");
// вЊЩЯДЋЕНhdfsЕФФПБъТЗОЖ
Path dst = new Path("/aaa");
fs.copyFromLocalFile(src, dst);
fs.close();
}
/**
* ДгhdfsжаИДжЦЮФМўЕНБОЕиЮФМўЯЕЭГ
*
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void testDownloadFileToLocal() throws IllegalArgumentException,
IOException {
fs.copyToLocalFile(new Path("/jdk-7u65-linux-i586.tar.gz"),
new Path("d:/"));
fs.close();
}
@Test
public void testMkdirAndDeleteAndRename() throws
IllegalArgumentException, IOException {
// ДДНЈФПТМ
fs.mkdirs(new Path("/a1/b1/c1"));
// ЩОГ§ЮФМўМа ЃЌШчЙћЪЧЗЧПеЮФМўМаЃЌВЮЪ§2БиаыИјжЕtrue
fs.delete(new Path("/aaa"), true);
// жиУќУћЮФМўЛђЮФМўМа
fs.rename(new Path("/a1"), new Path("/a2"));
}
/**
* ВщПДФПТМаХЯЂЃЌжЛЯдЪОЮФМў
*
* @throws IOException
* @throws IllegalArgumentException
* @throws FileNotFoundException
*/
@Test
public void testListFiles() throws FileNotFoundException,
IllegalArgumentException, IOException {
// ЫМПМЃКЮЊЪВУДЗЕЛиЕќДњЦїЃЌЖјВЛЪЧListжЎРрЕФШнЦї
RemoteIterator<LocatedFileStatus> listFiles
= fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println(fileStatus.getPath().getName());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getLen());
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
for (BlockLocation bl : blockLocations) {
System.out.println("block-length:" +
bl.getLength() + "--" + "block-offset:"
+ bl.getOffset());
String[] hosts = bl.getHosts();
for (String host : hosts) {
System.out.println(host);
}
}
System.out.println("--------------ЮЊangelababyДђгЁЕФЗжИюЯп--------------");
}
}
/**
* ВщПДЮФМўМАЮФМўМааХЯЂ
*
* @throws IOException
* @throws IllegalArgumentException
* @throws FileNotFoundException
*/
@Test
public void testListAll() throws FileNotFoundException,
IllegalArgumentException, IOException {
FileStatus[] listStatus = fs.listStatus(new Path("/"));
String flag = "d-- ";
for (FileStatus fstatus : listStatus) {
if (fstatus.isFile()) flag = "f-- ";
System.out.println(flag + fstatus.getPath().getName());
}
}
} |
6.4.2 ЭЈЙ§СїЕФЗНЪНЗУЮЪhdfs
/**
* ЯрЖдФЧаЉЗтзАКУЕФЗНЗЈЖјбдЕФИќЕзВувЛаЉЕФВйзїЗНЪН
* ЩЯВуФЧаЉmapreduce sparkЕШдЫЫуПђМмЃЌШЅhdfsжаЛёШЁЪ§ОнЕФЪБКђЃЌОЭЪЧЕїЕФетжжЕзВуЕФapi
* @author
*
*/
public class StreamAccess {
FileSystem fs = null;
@Before
public void init() throws Exception {
Configuration conf = new Configuration();
fs = FileSystem.get(new URI("hdfs://hdp-node01:9000"),
conf, "hadoop");
}
/**
* ЭЈЙ§СїЕФЗНЪНЩЯДЋЮФМўЕНhdfs
* @throws Exception
*/
@Test
public void testUpload() throws Exception {
FSDataOutputStream outputStream = fs.create(new
Path("/angelababy.love"), true);
FileInputStream inputStream = new FileInputStream("c:/angelababy.love");
IOUtils.copy(inputStream, outputStream);
}
@Test
public void testDownLoadFileToLocal() throws IllegalArgumentException,
IOException{
//ЯШЛёШЁвЛИіЮФМўЕФЪфШыСї----еыЖдhdfsЩЯЕФ
FSDataInputStream in = fs.open(new Path("/jdk-7u65-linux-i586.tar.gz"));
//дйЙЙдьвЛИіЮФМўЕФЪфГіСї----еыЖдБОЕиЕФ
FileOutputStream out = new FileOutputStream(new
File("c:/jdk.tar.gz"));
//дйНЋЪфШыСїжаЪ§ОнДЋЪфЕНЪфГіСї
IOUtils.copyBytes(in, out, 4096);
}
/**
* hdfsжЇГжЫцЛњЖЈЮЛНјааЮФМўЖСШЁЃЌЖјЧвПЩвдЗНБуЕиЖСШЁжИЖЈГЄЖШ
* гУгкЩЯВуЗжВМЪНдЫЫуПђМмВЂЗЂДІРэЪ§Он
* @throws IllegalArgumentException
* @throws IOException
*/
@Test
public void testRandomAccess() throws IllegalArgumentException,
IOException{
//ЯШЛёШЁвЛИіЮФМўЕФЪфШыСї----еыЖдhdfsЩЯЕФ
FSDataInputStream in = fs.open(new Path("/iloveyou.txt"));
//ПЩвдНЋСїЕФЦ№ЪМЦЋвЦСПНјааздЖЈвх
in.seek(22);
//дйЙЙдьвЛИіЮФМўЕФЪфГіСї----еыЖдБОЕиЕФ
FileOutputStream out = new FileOutputStream(new
File("c:/iloveyou.line.2.txt"));
IOUtils.copyBytes(in,out,19L,true);
}
/**
* ЯдЪОhdfsЩЯЮФМўЕФФкШн
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void testCat() throws IllegalArgumentException,
IOException{
FSDataInputStream in = fs.open(new Path("/iloveyou.txt"));
IOUtils.copyBytes(in, System.out, 1024);
}
} |
6.4.3 ГЁОАБрГЬ
дкmapreduce ЁЂsparkЕШдЫЫуПђМмжаЃЌгавЛИіКЫаФЫМЯыОЭЪЧНЋдЫЫувЦЭљЪ§ОнЃЌЛђепЫЕЃЌОЭЪЧвЊдкВЂЗЂМЦЫужаОЁПЩФмШУдЫЫуБОЕиЛЏЃЌетОЭашвЊЛёШЁЪ§ОнЫљдкЮЛжУЕФаХЯЂВЂНјааЯргІЗЖЮЇЖСШЁ
вдЯТФЃФтЪЕЯжЃКЛёШЁвЛИіЮФМўЕФЫљгаblockЮЛжУаХЯЂЃЌШЛКѓЖСШЁжИЖЈblockжаЕФФкШн
@Test
public void testCat() throws IllegalArgumentException,
IOException{
FSDataInputStream in = fs.open(new Path("/weblog/input/access.log.10"));
//ФУЕНЮФМўаХЯЂ
FileStatus[] listStatus = fs.listStatus(new Path("/weblog/input/access.log.10"));
//ЛёШЁетИіЮФМўЕФЫљгаblockЕФаХЯЂ
BlockLocation[] fileBlockLocations = fs.getFileBlockLocations(listStatus[0],
0L, listStatus[0].getLen());
//ЕквЛИіblockЕФГЄЖШ
long length = fileBlockLocations[0].getLength();
//ЕквЛИіblockЕФЦ№ЪМЦЋвЦСП
long offset = fileBlockLocations[0].getOffset();
System.out.println(length);
System.out.println(offset);
//ЛёШЁЕквЛИіblockаДШыЪфГіСї
// IOUtils.copyBytes(in, System.out, (int)length);
byte[] b = new byte[4096];
FileOutputStream os = new FileOutputStream(new
File("d:/block0"));
while(in.read(offset, b, 0, 4096)!=-1){
os.write(b);
offset += 4096;
if(offset>=length) return;
};
os.flush();
os.close();
in.close();
} |
7. АИР§1ЃКПЊЗЂshellВЩМЏНХБО
7.1ашЧѓЫЕУї
ЕуЛїСїШежОУПЬьЖМ10TЃЌдквЕЮёгІгУЗўЮёЦїЩЯЃЌашвЊзМЪЕЪБЩЯДЋжСЪ§ОнВжПтЃЈHadoop HDFSЃЉЩЯ
7.2ашЧѓЗжЮі
вЛАуЩЯДЋЮФМўЖМЪЧдкСшГП24ЕуВйзїЃЌгЩгкКмЖржжРрЕФвЕЮёЪ§ОнЖМвЊдкЭэЩЯНјааДЋЪфЃЌЮЊСЫМѕЧсЗўЮёЦїЕФбЙСІЃЌБмПЊИпЗхЦкЁЃ
ШчЙћашвЊЮБЪЕЪБЕФЩЯДЋЃЌдђВЩгУЖЈЪБЩЯДЋЕФЗНЪН
7.3ММЪѕЗжЮі
HDFS SHELL: hadoop fs ЈCput xxxx.tar /data ЛЙПЩвдЪЙгУ Java
Api
ТњзуЩЯДЋвЛИіЮФМўЃЌВЛФмТњзуЖЈЪБЁЂжмЦкадДЋШыЁЃ
ЖЈЪБЕїЖШЦїЃК
Linux crontab
crontab -e
*/5 * * * * $home/bin/command.sh //ЮхЗжжгжДаавЛДЮ
ЯЕЭГЛсздЖЏжДааНХБОЃЌУП5ЗжжгвЛДЮЃЌжДааЪБХаЖЯЮФМўЪЧЗёЗћКЯЩЯДЋЙцдђЃЌЗћКЯдђЩЯДЋ
7.4ЪЕЯжСїГЬ
7.4.1ШежОВњЩњГЬађ
ШежОВњЩњГЬађНЋШежОЩњГЩКѓЃЌВњЩњвЛИівЛИіЕФЮФМўЃЌЪЙгУЙіЖЏФЃЪНДДНЈЮФМўУћЁЃ

ШежОЩњГЩЕФТпМгЩвЕЮёЯЕЭГОіЖЈЃЌБШШчдкlog4jХфжУЮФМўжаХфжУЩњГЩЙцдђЃЌШчЃКЕБxxxx.log
ЕШгк10GЪБЃЌЙіЖЏЩњГЩаТШежО
log4j.logger.msg=info,msg
log4j.appender.msg=cn.maoxiangyi.MyRollingFileAppender
log4j.appender.msg.layout=org.apache.log4j.PatternLayout
log4j.appender.msg.layout.ConversionPattern=%m%n
log4j.appender.msg.datePattern='.'yyyy-MM-dd
log4j.appender.msg.Threshold=info
log4j.appender.msg.append=true
log4j.appender.msg.encoding=UTF-8
log4j.appender.msg.MaxBackupIndex=100
log4j.appender.msg.MaxFileSize=10GB
log4j.appender.msg.File=/home/hadoop/logs/log/access.log |
ЯИНкЃК
1ЁЂШчЙћШежОЮФМўКѓзКЪЧ1\2\3ЕШЪ§зжЃЌИУЮФМўТњзуашЧѓПЩвдЩЯДЋЕФЛАЁЃАбИУЮФМўвЦЖЏЕНзМБИЩЯДЋЕФЙЄзїЧјМфЁЃ
2ЁЂЙЄзїЧјМфгаЮФМўжЎКѓЃЌПЩвдЪЙгУhadoop putУќСюНЋЮФМўЩЯДЋЁЃ
НзЖЮЮЪЬтЃК
1ЁЂД§ЩЯДЋЮФМўЕФЙЄзїЧјМфЕФЮФМўЃЌдкЩЯДЋЭъГЩжЎКѓЃЌЪЧЗёашвЊЩОГ§ЕєЁЃ
7.4.2ЮБДњТы
ЪЙгУlsУќСюЖСШЁжИЖЈТЗОЖЯТЕФЫљгаЮФМўаХЯЂЃЌ
ls | while read line
//ХаЖЯlineетИіЮФМўУћГЦЪЧЗёЗћКЯЙцдђ
if line=access.log.* (
НЋЮФМўвЦЖЏЕНД§ЩЯДЋЕФЙЄзїЧјМф
) |
//ХњСПЩЯДЋЙЄзїЧјМфЕФЮФМў
hadoop fs ЈCput xxx
НХБОаДЭъжЎКѓЃЌХфжУlinuxЖЈЪБШЮЮёЃЌУП5ЗжжгдЫаавЛДЮЁЃ
7.5ДњТыЪЕЯж
ДњТыЕквЛАцБОЃЌЪЕЯжЛљБОЕФЩЯДЋЙІФмКЭЖЈЪБЕїЖШЙІФмДњТы

ЕкЖўАцБОЃКдіЧПАцV2(ЛљБОФмгУЃЌЛЙЪЧВЛЙЛНЁШЋ)

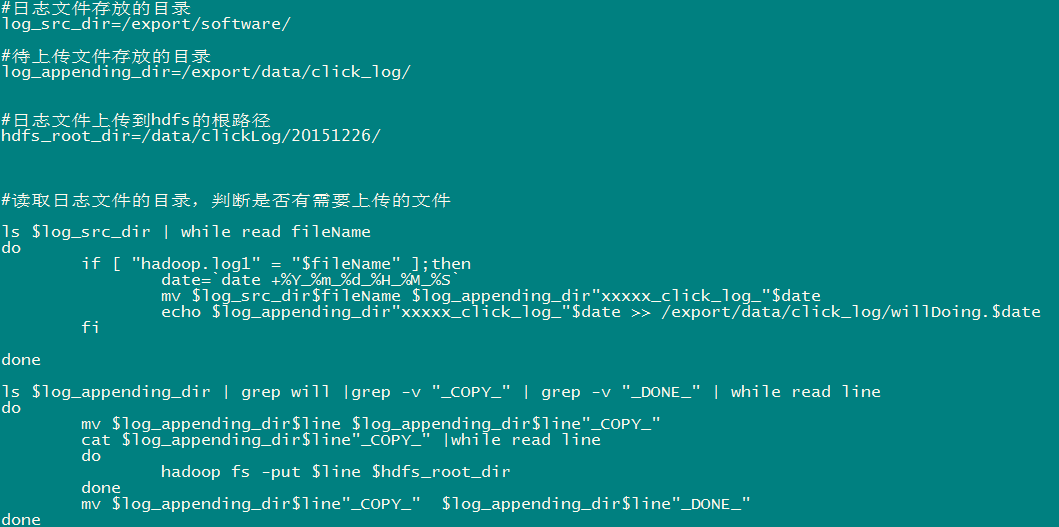
7.6аЇЙћеЙЪОМАВйзїВНжш
1ЁЂШежОЪеМЏЮФМўЪеМЏЪ§ОнЃЌВЂНЋЪ§ОнБЃДцЦ№РДЃЌаЇЙћШчЯТЃК

2ЁЂЩЯДЋГЬађЭЈЙ§crontabЖЈЪБЕїЖШ

3ЁЂГЬађдЫааЪБВњЩњЕФСйЪБЮФМў

4ЁЂHadoo hdfsЩЯЕФаЇЙћ8. АИР§2ЃКПЊЗЂJAVAВЩМЏГЬађ

8.1 ашЧѓ
ДгЭтВПЙКТђЪ§ОнЃЌЪ§ОнЬсЙЉЗНЛсЪЕЪБНЋЪ§ОнЭЦЫЭЕН6ЬЈFTPЗўЮёЦїЩЯЃЌЮвЗНВПЪ№6ЬЈНгПкВЩМЏЛњРДЖдНгВЩМЏЪ§ОнЃЌВЂЩЯДЋЕНHDFSжа
ЬсЙЉЩЬдкFTPЩЯЩњГЩЪ§ОнЕФЙцдђЪЧвдаЁЪБЮЊЕЅЮЛНЈСЂЮФМўМа(2016-03-11-10)ЃЌУПЗжжгЩњГЩвЛИіЮФМўЃЈ00.dat,01.data,02.dat,ЁЃЉ
ЬсЙЉЗНВЛЬсЙЉЪ§ОнБИЗнЃЌЭЦЫЭЕНFTPЗўЮёЦїЕФЪ§ОнШчЙћЖЊЪЇЃЌВЛдйжиаТЬсЙЉЃЌЧвFTPЗўЮёЦїДХХЬПеМфгаЯоЃЌзюЖрДцДЂзюНќ10аЁЪБФкЕФЪ§Он
гЩгкУПвЛИіЮФМўБШНЯаЁЃЌжЛга150MзѓгвЃЌвђДЫЃЌЮвЗНдкЩЯДЋЕНHDFSЙ§ГЬжаЃЌашвЊНЋ15ЗжжгЪБЖЮЕФЪ§ОнКЯВЂГЩвЛИіЮФМўЩЯДЋЕНHDFS
ЮЊСЫЧјЗжЪ§ОнЖЊЪЇЕФд№ШЮЃЌЮвЗНдкЯТдиЪ§ОнЪБзюКУНјаааЃбщ
8.2 ЩшМЦЗжЮі 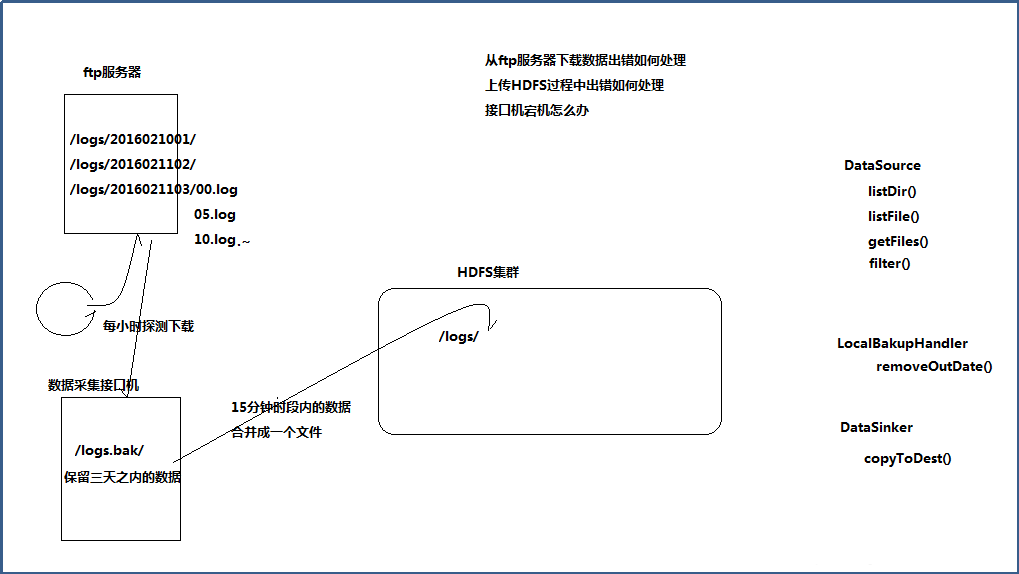
|









