| БрМЭЦМі: |
| БОЮФРДздcsdn,БОЮФжївЊНщЩмСЫДѓЪ§ОнSparkМђНщгыhadoopМЏШКДюНЈЃЌscalaАВзАвдМАSparkАВзАвдМАХфжУЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ |
|
Spark ЪЧ Apache ЖЅМЖЯюФПРяУцзюЛ№ЕФДѓЪ§ОнДІРэЕФМЦЫув§ЧцЃЌЫќФПЧАЪЧИКд№ДѓЪ§ОнМЦЫуЕФЙЄзїЁЃАќРЈРыЯпМЦЫуЛђНЛЛЅЪНВщбЏЁЂЪ§ОнЭкОђЫуЗЈЁЂСїЪНМЦЫувдМАЭММЦЫуЕШЁЃ

sparkЩњЬЌЯЕЭГ
КЫаФзщМўШчЯТЃК
Spark CoreЃКАќКЌSparkЕФЛљБОЙІФмЃЛгШЦфЪЧЖЈвхRDDЕФAPIЁЂВйзївдМАетСНепЩЯЕФЖЏзїЁЃЦфЫћSparkЕФПтЖМЪЧЙЙНЈдкRDDКЭSpark
CoreжЎЩЯЕФЁЃ
Spark SQLЃКЬсЙЉЭЈЙ§Apache HiveЕФSQLБфЬхHiveВщбЏгябдЃЈHiveQLЃЉгыSparkНјааНЛЛЅЕФAPIЁЃУПИіЪ§ОнПтБэБЛЕБзівЛИіRDDЃЌSpark
SQLВщбЏБЛзЊЛЛЮЊSparkВйзїЁЃЖдЪьЯЄHiveКЭHiveQLЕФШЫЃЌSparkПЩвдФУРДОЭгУЁЃ
Spark StreamingЃКдЪаэЖдЪЕЪБЪ§ОнСїНјааДІРэКЭПижЦЁЃКмЖрЪЕЪБЪ§ОнПтЃЈШчApache StoreЃЉПЩвдДІРэЪЕЪБЪ§ОнЁЃSpark
StreamingдЪаэГЬађФмЙЛЯёЦеЭЈRDDвЛбљДІРэЪЕЪБЪ§ОнЁЃ
MLlibЃКвЛИіГЃгУЛњЦїбЇЯАЫуЗЈПтЃЌЫуЗЈБЛЪЕЯжЮЊЖдRDDЕФSparkВйзїЁЃетИіПтАќКЌПЩРЉеЙЕФбЇЯАЫуЗЈЃЌБШШчЗжРрЁЂЛиЙщЕШашвЊЖдДѓСПЪ§ОнМЏНјааЕќДњЕФВйзїЁЃжЎЧАПЩбЁЕФДѓЪ§ОнЛњЦїбЇЯАПтMahoutЃЌНЋЛсзЊЕНSparkЃЌВЂдкЮДРДЪЕЯжЁЃ
GraphXЃКПижЦЭМЁЂВЂааЭМВйзїКЭМЦЫуЕФвЛзщЫуЗЈКЭЙЄОпЕФМЏКЯЁЃGraphXРЉеЙСЫRDD APIЃЌАќКЌПижЦЭМЁЂДДНЈзгЭМЁЂЗУЮЪТЗОЖЩЯЫљгаЖЅЕуЕФВйзїЁЃ
гЩгкетаЉзщМўТњзуСЫКмЖрДѓЪ§ОнашЧѓЃЌвВТњзуСЫКмЖрЪ§ОнПЦбЇШЮЮёЕФЫуЗЈКЭМЦЫуЩЯЕФашвЊЃЌSparkПьЫйСїааЦ№РДЁЃВЛНіШчДЫЃЌSparkвВЬсЙЉСЫЪЙгУScalaЁЂJavaКЭPythonБраДЕФAPIЃЛТњзуСЫВЛЭЌЭХЬхЕФашЧѓЃЌдЪаэИќЖрЪ§ОнПЦбЇМвМђБуЕиВЩгУSparkзїЮЊЫћУЧЕФДѓЪ§ОнНтОіЗНАИ
sparkЕФДцДЂВуДЮ
sparkВЛНіПЩвдНЋШЮКЮЕФhadoopЗжВМЪНЮФМўЯЕЭГЩЯЕФЮФМўЖСШЁЮЊЗжВМЪНЪ§ОнМЏЃЌвВПЩвджЇГжЦфЫћжЇГжhadoopНгПкЕФЯЕЭГЃЌБШШчБОЕиЮФМўЁЂбЧТэбЗS3ЁЂHiveЁЂHBaseЕШЁЃ
ЯТЭМЮЊhadoopгыНкЕужЎМфЕФЙиЯЕЃК

spark on yarn
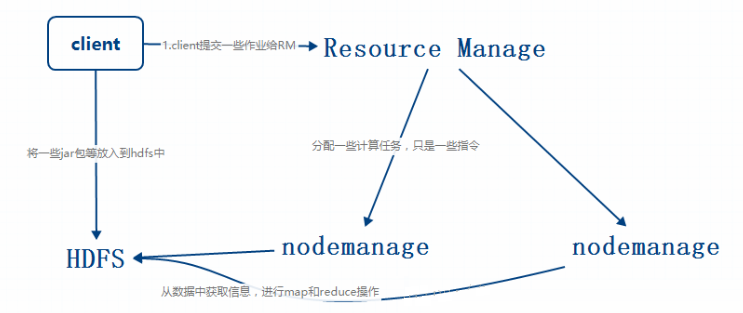
Apache Hadoop YARN ЃЈYet Another Resource NegotiatorЃЌСэвЛжжзЪдДаЕїепЃЉЪЧвЛжжаТЕФ
Hadoop зЪдДЙмРэЦїЃЌЫќЪЧвЛИіЭЈгУзЪдДЙмРэЯЕЭГЃЌПЩЮЊЩЯВугІгУЬсЙЉЭГвЛЕФзЪдДЙмРэКЭЕїЖШ.YARN
ЗжВуНсЙЙЕФБОжЪЪЧ ResourceManagerЁЃетИіЪЕЬхПижЦећИіМЏШКВЂЙмРэгІгУГЬађЯђЛљДЁМЦЫузЪдДЕФЗжХфЁЃResourceManager
НЋИїИізЪдДВПЗжЃЈМЦЫуЁЂФкДцЁЂДјПэЕШЃЉОЋаФАВХХИјЛљДЁ NodeManagerЃЈYARN ЕФУПНкЕуДњРэЃЉ?Hadoop2АцБОвдЩЯЃЌв§ШыYARNжЎКѓЃЌВЛНіНіПЩвдЪЙгУMapReduceЃЌЛЙПЩвдв§гУsparkЕШЕШМЦЫу?
1.hadoopМЏШКДюНЈ(master+slave01)
МЏШКЛњЦїзМБИ
<1>дкVMwareжазМБИСЫСНЬЈubuntu14.04ЕФащФтЛњЃЌаоИФжїЛњУћЮЊmaster,slave01,ВЂЧвСНЬЈЛњЦїЕФжїЛњУћвдМАipШчЯТ(ИљОнздМКЫљдкЭјТчЛЗОГаоИФ)ЃК

<2>аоИФmasterКЭslave01ЕФ/etc/hostsЮФМўШчЯТЃК
127.0.0.1 localhost
192.168.1.123 master
192.168.1.124 slave01 |
ЭЈЙ§pingУќСюВтЪдСНЬЈжїЛњЕФСЌЭЈад
ХфжУsshЮоУмТыЗУЮЪМЏШК
<1>ЗжБ№дкСНЬЈжїЛњЩЯдЫаавЛЯТУќСю
ssh-keygen -t
dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
|
<2>НЋslave01ЕФЙЋдПid_dsa.pubДЋИјmaster
| scp ~/.ssh/id_dsa.pub
itcast@master:/home/itcast/.ssh/id_dsa.pub.slave01
|
<3>НЋ slave01ЕФЙЋдПаХЯЂзЗМгЕН master ЕФ authorized_keysЮФМўжа
| cat id_dsa.pub.slave01
>> authorized_keys |
<4>НЋ master ЕФЙЋдПаХЯЂ authorized_keys ИДжЦЕНslave02
ЕФ .ssh ФПТМЯТ
| scp authorized_keys
itcast@slave01:/home/itcast/.ssh/authorized_keys
|
sshЕНslave01ЩЯЃК

sshЕНmasterЩЯЃК
jdkгыhadoopАВзААќАВзА
<1>ЪЙгУjdk_u780АцБОЕФАВзААќЃЌЫљгаЛЗОГЭГвЛНтбЙЕН/opt/software/ФПТМЯТЃЌЗжБ№дкmasterКЭslave01жаЬэМгЛЗОГБфСПЃК
export JAVA_HOME=/opt/software/java/jdk1.7.0_80
export JRE_HOME=/opt/software/java/jdk1.7.0_80/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin |
<2>ЪЙгУHadoop-2.6.0БОЕФАВзААќЃЌЫљгаЛЗОГЭГвЛНтбЙЕН/opt/software/ФПТМЯТЃЌЗжБ№дкmasterКЭslave01жаЬэМгЛЗОГБфСП,МЧзЁНЋbinФПТМЬэМгЕНPATHжаЃК
| export HADOOP_HOME=/opt/software/hadoop/hadoop-2.6.0
|
1.2.ХфжУhadoopЛЗОГ
МЏШКХфжУ
<1>дк/opt/software/hadoop/hadoop-2.6.0/etc/hadoopФПТМЯТаоИФhadoop-env.sh
діМгШчЯТХфжУЃК
export JAVA_HOME=/opt/software/java/jdk1.7.0_80
export HADOOP_PREFIX=/opt/software/hadoop/hadoop-2.6.0
|
<2>аоИФcore-site.xml,tmpФПТМашвЊЬсЧАДДНЈКУ
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/software/hadoop/hadoop-2.6.0/tmp</value>
</property>
</configuration> |
<3>аоИФhdfs-site.xml,жИЖЈЪ§ОнЕФИББОИіЪ§
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration> |
<4>аоИФmapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> |
<5>yarn-env.shжадіМгJAVA_HOMEЕФЛЗОГ
<6>аоИФyarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties
-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration> |
<7>slavesжадіМгМЏШКжїЛњУћ
дкslave01ЩЯзіЭЌбљЕФХфжУ
ЦєЖЏhadoopМЏШК
<1>start-dfs.sh,ЦєЖЏnamenodeКЭdatanode
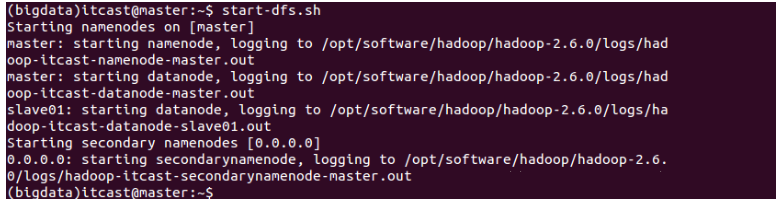
дкmasterКЭslave01ЩЯЪЙгУjpsУќСюВщПДjavaНјГЬЃЌвВПЩвддкhttp://master:50070/
ЩЯВщПД
<2>start-yarn.sh,ЦєЖЏ ResourceManager
КЭ NodeManager,дкmasterКЭslave01ЩЯ

ЪЙгУjpsУќСюВщПДjavaНјГЬ

ШчЙћЩЯЪіЖМГЩЙІСЫЃЌФЧУДМЏШКЦєЖЏОЭГЩЙІСЫ
1.3.scalaАВзА
<1>ЪЙгУscala-2.10.6АцБОЕФАВзААќЃЌЭЌбљНтбЙЗХдк/opt/software/scala/ЯТЃЌЯрЙиЮФМўМаашздМКДДНЈ
<2>аоИФМвФПТМЯТЕФ.bashrcЮФМўЃЌЬэМгШчЯТЛЗОГ,МЧзЁЬэМгscalaЕФPATHТЗОЖЃК
export SCALA_HOME=/opt/software/scala/scala-2.10.6
export SPARK_HOME=/opt/software/spark/spark-1.6.0-bin-hadoop2.6
|
дЫааsource .barhrcЪЙЛЗОГБфСПЩњаЇ
<3>ЭЌбљдкslave01ЩЯХфжУ
<4>ЪфШыscalaУќСюЃЌВщПДЪЧЗёЩњаЇ

1.4.SparkАВзАвдМАХфжУ
SparkАВзА
<1>sparkАВзААќЪЙгУspark-1.6.0-bin-hadoop2.6ЃЌЭЌбљНтбЙЕН/opt/software/hadoop
<2>аоИФЛЗОГБфСПЮФМў.bashrcЃЌЬэМгШчЯТФкШн
export SPARK_HOME=/opt/software/spark/spark-1.6.0-bin-hadoop2.6
#вдЯТЪЧШЋВПЕФPATHБфСП
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP
_HOME/sbin:$HADOOP_HOM E/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin
|
дЫааsource .bashrcЪЙЛЗОГБфСПЩњаЇ
SparkХфжУ
<1>НјШыSparkЕФАВзАФПТМЯТЕФconfФПТМЃЌПНБДspark-env.sh.templateЕНspark-env.sh
| cp spark-env.sh.template
spark-env.sh |
БрМspark-env.sh,дкЦфжаЬэМгвдЯТХфжУаХЯЂЃК
export SCALA_HOME=/opt/software/scala/scala-2.10.6
export JAVA_HOME=/opt/software/java/jdk1.7.0_80
export SPARK_MASTER_IP=192.168.0.114
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/opt/software/hadoop/hadoop-2.6.0/etc/hadoop
|
<2>НЋslaves.templateПНБДЕНslavesЃЌБрМЦ№ФкШнЮЊЃК
ДЫХфжУБэЪОвЊПЊЦєЕФworkerжїЛњ?<3>slave01ЭЌбљВЮееmasterХфжУ
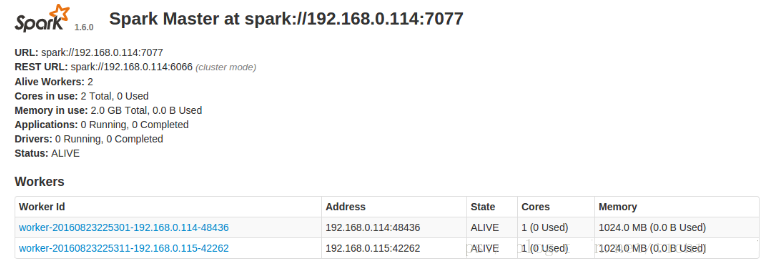
SparkМЏШКЦєЖЏ
<1>ЦєЖЏMasterНкЕуЃЌдЫааstart-master.sh,НсЙћШчЯТЃК

<2>ЦєЖЏЫљгаЕФworkerНкЕуЃЌдЫааstart-slaves.shЃЌдЫааНсЙћШчЯТЃК

<3>ЪфШыjpsУќСюВщПДЦєЖЏЧщПі

<4>фЏРРЦїЗУЮЪhttp://master:8080
ПЩВщПДSparkМЏШКаХЯЂ
|









