| БрМЭЦМі: |
БОЮФРДздгкcnblogs,ЮФеТжївЊНщЩмСЫЪВУДЪЧHDFSЃЌУќСюааНгПкЃЌJavaНгПкЃЌЪ§ОнСїЃЌЭЈЙ§FlumeКЭSqoopЕМШыЪ§ОнЃЌЭЈЙ§distcpВЂааИДжЦЕШЯрЙиЁЃ
|
|
бЇЯАЭъHadoopШЈЭўжИФЯгавЛЖЮЪБМфСЫЃЌЯждкдйЛиЙЫКЭзмНсвЛЯТHDFSЕФжЊЪЖЕуЁЃ
1ЁЂHDFSЕФЩшМЦ
HDFSЪЧЪВУДЃКHDFSМДHadoopЗжВМЪНЮФМўЯЕЭГЃЈHadoop Distributed FilesystemЃЉЃЌвдСїЪНЪ§ОнЗУЮЪФЃЪНРДДцДЂГЌДѓЮФМўЃЌдЫаагкЩЬгУгВМўМЏШКЩЯЃЌЪЧЙмРэЭјТчжаПчЖрЬЈМЦЫуЛњДцДЂЕФЮФМўЯЕЭГЁЃ
HDFSВЛЪЪКЯгУдкЃКвЊЧѓЕЭЪБМфбгГйЪ§ОнЗУЮЪЕФгІгУЃЌДцДЂДѓСПЕФаЁЮФМўЃЌЖргУЛЇаДШыЃЌШЮвтаоИФЮФМўЁЃ
2ЁЂHDFSЕФИХФю
HDFSЪ§ОнПщЃКHDFSЩЯЕФЮФМўБЛЛЎЗжЮЊПщДѓаЁЕФЖрИіЗжПщЃЌзїЮЊЖРСЂЕФДцДЂЕЅдЊЃЌГЦЮЊЪ§ОнПщЃЌФЌШЯДѓаЁЪЧ64MBЁЃ
ЪЙгУЪ§ОнПщЕФКУДІЪЧЃК
вЛИіЮФМўЕФДѓаЁПЩвдДѓгкЭјТчжаШЮвтвЛИіДХХЬЕФШнСПЁЃЮФМўЕФЫљгаПщВЛашвЊДцДЂдкЭЌвЛИіДХХЬЩЯЃЌвђДЫЫќУЧПЩвдРћгУМЏШКЩЯЕФШЮвтвЛИіДХХЬНјааДцДЂЁЃ
МђЛЏСЫДцДЂзгЯЕЭГЕФЩшМЦЃЌНЋДцДЂзгЯЕЭГПижЦЕЅдЊЩшжУЮЊПщЃЌПЩМђЛЏДцДЂЙмРэЃЌЭЌЪБдЊЪ§ОнОЭВЛашвЊКЭПщвЛЭЌДцДЂЃЌгУвЛИіЕЅЖРЕФЯЕЭГОЭПЩвдЙмРэетаЉПщЕФдЊЪ§ОнЁЃ
Ъ§ОнПщЪЪКЯгУгкЪ§ОнБИЗнНјЖјЬсЙЉЪ§ОнШнДэФмСІКЭЬсИпПЩгУадЁЃ
ВщПДПщаХЯЂ

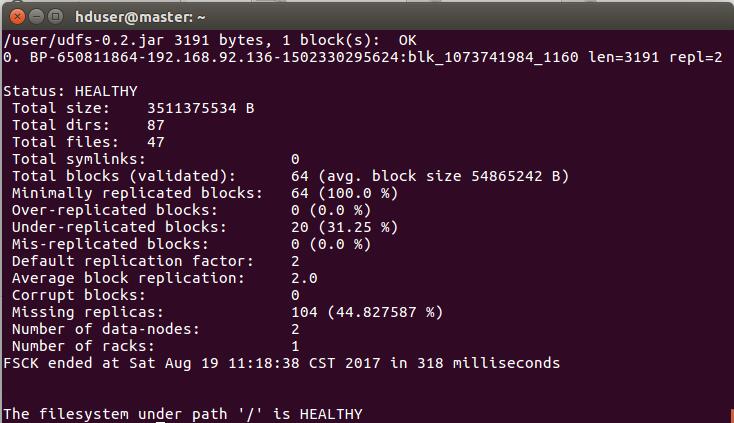
HDFSЕФШ§ИіНкЕуЃКNamenodeЃЌDatanodeЃЌSecondary Namenode
NamenodeЃКHDFSЕФЪиЛЄНјГЬЃЌгУРДЙмРэЮФМўЯЕЭГЕФУќУћПеМфЃЌИКд№МЧТМЮФМўЪЧШчКЮЗжИюГЩЪ§ОнПщЃЌвдМАетаЉЪ§ОнПщЗжБ№БЛДцДЂЕНФЧаЉЪ§ОнНкЕуЩЯЃЌЫќЕФжївЊЙІФмЪЧЖдФкДцМАIOНјааМЏжаЙмРэЁЃ
DatanodeЃКЮФМўЯЕЭГЕФЙЄзїНкЕуЃЌИљОнашвЊДцДЂКЭМьЫїЪ§ОнПщЃЌВЂЧвЖЈЦкЯђnamenodeЗЂЫЭЫћУЧЫљДцДЂЕФПщЕФСаБэЁЃ
Secondary NamenodeЃКИЈжњКѓЬЈГЬађЃЌгыNameNodeНјааЭЈаХЃЌвдБуЖЈЦкБЃДцHDFSдЊЪ§ОнЕФПьееЁЃ
HDFS FederationЃЈСЊАюHDFSЃЉЃК
ЭЈЙ§ЬэМгnamenodeЪЕЯжРЉеЙЃЌЦфжаУПИіnamenodeЙмРэЮФМўЯЕЭГУќУћПеМфжаЕФвЛВПЗжЁЃУПИіnamenodeЮЌЛЄвЛИіУќУћПеМфОэЃЌАќРЈУќУћПеМфЕФдДЪ§ОнКЭИУУќУћПеМфЯТЕФЮФМўЕФЫљгаЪ§ОнПщЕФЪ§ОнПщГиЁЃ
HDFSЕФИпПЩгУадЃЈHigh-AvailabilityЃЉ
HadoopЕФ2.xЗЂааАцБОдкHDFSжадіМгСЫЖдИпПЩгУадЃЈHAЃЉЕФжЇГжЁЃдкетвЛЪЕЯжжаЃЌХфжУСЫвЛЖдЛюЖЏ-БИгУЃЈactive-standbyЃЉnamenodeЁЃЕБЛюЖЏnamenodeЪЇаЇЃЌБИгУnamenodeОЭЛсНгЙмЫќЕФШЮЮёВЂПЊЪМЗўЮёгкРДздПЭЛЇЖЫЕФЧыЧѓЃЌВЛЛсгаУїЯдЕФжаЖЯЁЃ
МмЙЙЕФЪЕЯжАќРЈЃК
namenodeжЎМфЭЈЙ§ИпПЩгУЕФЙВЯэДцДЂЪЕЯжБрМШежОЕФЙВЯэЁЃ
datanodeЭЌЪБЯђСНИіnamenodeЗЂЫЭЪ§ОнПщДІРэБЈИцЁЃ
ПЭЛЇЖЫЪЙгУЬиЖЈЕФЛњжЦРДДІРэnamenodeЕФЪЇаЇЮЪЬтЃЌетвЛЛњжЦЖдгУЛЇЪЧЭИУїЕФЁЃ
ЙЪеЯзЊвЦПижЦЦїЃКЙмРэзХНЋЛюЖЏnamenodeзЊвЦИјБИгУnamenodeЕФзЊЛЛЙ§ГЬЃЌЛљгкZooKeeperВЂгЩДЫШЗБЃгаЧвНігавЛИіЛюЖЏnamenodeЁЃУПвЛИіnamenodeдЫаазХвЛИіЧсСПМЖЕФЙЪеЯзЊвЦПижЦЦїЃЌЦфЙЄзїОЭЪЧМрЪгЫожїnamenodeЪЧЗёЪЇаЇВЂдкnamenodeЪЇаЇЪБНјааЙЪеЯЧаЛЛЁЃ
3ЁЂУќСюааНгПк
СНИіЪєадЯюЃК fs.default.name гУРДЩшжУHadoopЕФФЌШЯЮФМўЯЕЭГЃЌЩшжУhdfs URLдђЪЧХфжУHDFSЮЊHadoopЕФФЌШЯЮФМўЯЕЭГЁЃdfs.replication
ЩшжУЮФМўЯЕЭГПщЕФИББОИіЪ§
ЮФМўЯЕЭГЕФЛљБОВйзїЃКhadoop fs -helpПЩвдЛёШЁЫљгаЕФУќСюМАЦфНтЪЭ
ГЃгУЕФгаЃК
hadoop fs -ls / СаГіhdfsЮФМўЯЕЭГИљФПТМЯТЕФФПТМКЭЮФМў
hadoop fs -copyFromLocal <local path> <hdfs
path> ДгБОЕиЮФМўЯЕЭГНЋвЛИіЮФМўИДжЦЕНHDFS
hadoop fs -rm -r <hdfs dir or file> ЩОГ§ЮФМўЛђЮФМўМаМАЮФМўМаЯТЕФЮФМў
hadoop fs -mkdir <hdfs dir>дкhdfsжааТНЈЮФМўМа
HDFSЕФЮФМўЗУЮЪШЈЯоЃКжЛЖСШЈЯоЃЈrЃЉЃЌаДШыШЈЯоЃЈwЃЉЃЌПЩжДааШЈЯоЃЈxЃЉ
4ЁЂHadoopЮФМўЯЕЭГ
HadoopгавЛИіГщЯѓЕФЮФМўЯЕЭГИХФюЃЌHDFSжЛЪЧЦфжаЕФвЛИіЪЕЯжЁЃJavaГщЯѓНгПкorg.apache.hadoop.fs.FileSystemЖЈвхСЫHadoopжаЕФвЛИіЮФМўЯЕЭГНгПкЁЃИУГщЯѓРрЪЕЯжHDFSЕФОпЬхЪЕЯжЪЧ
hdfs.DistributedFileSystem
5ЁЂJavaНгПк
зюМђЕЅЕФДгHadoop URLЖСШЁЪ§Он ЃЈетРядкEclipseЩЯСЌНгHDFSБрвыдЫааЃЉ
| package filesystem;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.io.IOUtils;
public class URLCat {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) throws
MalformedURLException, IOException {
InputStream in = null;
String input = "hdfs://192.168.92.138:9000/user/test.txt";
try {
in = new URL(input).openStream();
IOUtils.copyBytes(in, System.out, 4096,false);
}finally {
IOUtils.closeStream(in);
}
}
} |
етРяЕїгУHadoopЕФIOUtilsРрЃЌдкЪфШыСїКЭЪфГіСїжЎМфИДжЦЪ§ОнЃЈinКЭSystem.outЃЉзюКѓСНИіВЮЪ§гУгкЕквЛИіЩшжУИДжЦЕФЛКГхЧјДѓаЁЃЌЕкЖўИіЩшжУНсЪјКѓЪЧЗёЙиБеЪ§ОнСїЁЃ
ЛЙПЩвдЭЈЙ§FileSystem APIЖСШЁЪ§Он
ДњТыШчЯТЃК
| package filesystem;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class FileSystemCat {
public static void main(String[] args) throws
IOException {
String uri = "hdfs://192.168.92.136:9000/user/test.txt";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri),conf);
InputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 1024,false);
}finally {
IOUtils.closeStream(in);
}
}
} |
етРяЕїгУopen()КЏЪ§РДЛёШЁЮФМўЕФЪфШыСїЃЌFileSystemЕФget()ЗНЗЈЛёШЁFileSystemЪЕР§ЁЃ
ЪЙгУFileSystem APIаДШыЪ§Он
ДњТыШчЯТЃК
| package filesystem;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Progressable;
public class FileCopyWithProgress {
public static void main(String[] args) throws
Exception {
String localSrc = "E:\\share\\input\\2007_12_1.txt";
String dst = "hdfs://192.168.92.136:9000/user/logs/2008_10_2.txt";
InputStream in = new BufferedInputStream(new
FileInputStream(localSrc));
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(dst),conf);
OutputStream out = fs.create(new Path(dst),new
Progressable() {
public void progress() {
System.out.print("*");
}
});
IOUtils.copyBytes(in, out, 1024,true);
}
} |
FileSystemЕФcreate()ЗНЗЈгУгкаТНЈЮФМў,ЗЕЛиFSDataOutputStreamЖдЯѓЁЃ
Progressable()гУгкДЋЕнЛиЕєДАПкЃЌПЩвдгУРДАбЪ§ОнаДШыdatanodeЕФНјЖШЭЈжЊИјгІгУЁЃ
ЪЙгУFileSystem APIЩОГ§Ъ§Он
ДњТыШчЯТЃК
| package filesystem;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class FileDelete {
public static void main(String[] args) throws
Exception{
String uri = "hdfs://192.168.92.136:9000/user/1400.txt";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri),conf);
fs.delete(new Path(uri));
}
} |
ЪЙгУdelete()ЗНЗЈРДгРОУадЩОГ§ЮФМўЛђФПТМЁЃ
FileSystemЕФЦфЫќвЛаЉЗНЗЈЃК
public boolean mkdirs(Path f) throws IOException
гУРДДДНЈФПТМЃЌДДНЈГЩЙІЗЕЛиtrueЁЃ
public FileStatus getFileStates(Path f) throws FIleNotFoundException
гУРДЛёШЁЮФМўЛђФПТМЕФFileStatusЖдЯѓЁЃ
public FileStatus[ ] listStatus(Path f)throws IOException
СаГіФПТМжаЕФФкШн
public FileStatus[ ] globStatu(Path pathPattern) throws
IOException ЗЕЛигыЦфТЗОЖЦЅХфгкжИЖЈФЃЪНЕФЫљгаЮФМўЕФFileStatusЖдЯѓЪ§зщЃЌВЂАДТЗОЖХХађ
6ЁЂЪ§ОнСї
HDFSЖСШЁЮФМўЙ§ГЬЃК
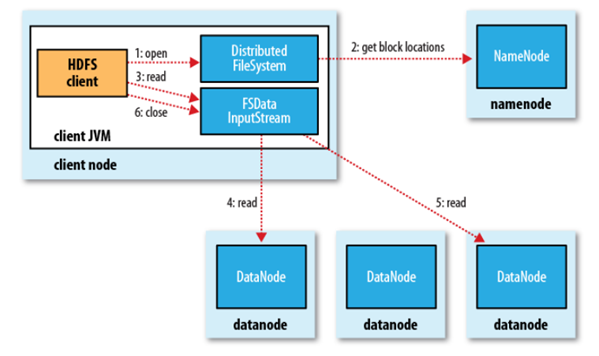
Й§ГЬУшЪіЃК
ЃЈ1ЃЉПЭЛЇЖЫЕїгУFileSysteЖдЯѓЕФopen()ЗНЗЈдкЗжВМЪНЮФМўЯЕЭГжаДђПЊвЊЖСШЁЕФЮФМўЁЃ
ЃЈ2ЃЉЗжВМЪНЮФМўЯЕЭГЭЈЙ§ЪЙгУRPCЃЈдЖГЬЙ§ГЬЕїгУЃЉРДЕїгУnamenodeЃЌШЗЖЈЮФМўЦ№ЪМПщЕФЮЛжУЁЃ
ЃЈ3ЃЉЗжВМЪНЮФМўЯЕЭГЕФDistributedFileSystemРрЗЕЛивЛИіжЇГжЮФМўЖЈЮЛЕФЪфШыСїFSDataInputStreamЖдЯѓЃЌFSDataInputStreamЖдЯѓНгзХЗтзАDFSInputStreamЖдЯѓЃЈДцДЂзХЮФМўЦ№ЪММИИіПщЕФdatanodeЕижЗЃЉЃЌПЭЛЇЖЫЖдетИіЪфШыСїЕїгУread()ЗНЗЈЁЃ
ЃЈ4ЃЉDFSInputStreamСЌНгОрРызюНќЕФdatanodeЃЌЭЈЙ§ЗДИДЕїгУreadЗНЗЈЃЌНЋЪ§ОнДгdatanodeДЋЪфЕНПЭЛЇЖЫЁЃ
ЃЈ5ЃЉ ЕНДяПщЕФФЉЖЫЪБЃЌDFSInputStreamЙиБегыИУdatanodeЕФСЌНгЃЌбАевЯТвЛИіПщЕФзюМбdatanodeЁЃ
ЃЈ6ЃЉПЭЛЇЖЫЭъГЩЖСШЁЃЌЖдFSDataInputStreamЕїгУclose()ЗНЗЈЙиБеСЌНгЁЃ
HDFSЮФМўаДШыЕФЙ§ГЬЃК
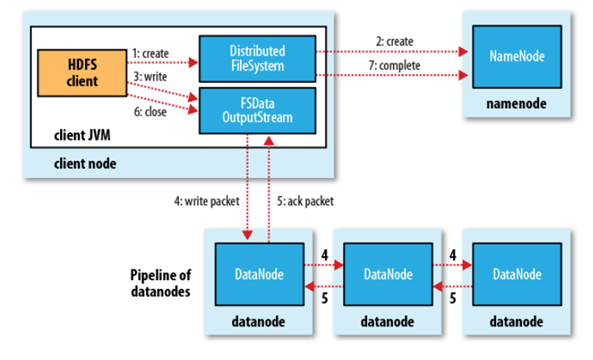
Й§ГЬУшЪіЃК
аДЮФМўЙ§ГЬЗжЮіЃК
ЃЈ1ЃЉ ПЭЛЇЖЫЭЈЙ§ЖдDistributedFileSystemЖдЯѓЕїгУcreate()КЏЪ§РДаТНЈЮФМўЁЃ
ЃЈ2ЃЉ ЗжВМЪНЮФМўЯЕЭГЖдnamenodДДНЈвЛИіRPCЕїгУЃЌдкЮФМўЯЕЭГЕФУќУћПеМфжааТНЈвЛИіЮФМўЁЃ
ЃЈ3ЃЉNamenodeЖдаТНЈЮФМўНјааМьВщЮоЮѓКѓЃЌЗжВМЪНЮФМўЯЕЭГЗЕЛиИјПЭЛЇЖЫвЛИіFSDataOutputStreamЖдЯѓЃЌFSDataOutputStreamЖдЯѓЗтзАвЛИіDFSoutPutstreamЖдЯѓЃЌИКд№ДІРэnamenodeКЭdatanodeжЎМфЕФЭЈаХЃЌПЭЛЇЖЫПЊЪМаДШыЪ§ОнЁЃ
ЃЈ4ЃЉFSDataOutputStreamНЋЪ§ОнЗжГЩвЛИівЛИіЕФЪ§ОнАќЃЌаДШыФкВПЖгСаЁАЪ§ОнЖгСаЁБЃЌDataStreamerИКд№НЋЪ§ОнАќвРДЮСїЪНДЋЪфЕНгЩвЛзщnamenodeЙЙГЩЕФЙмЯпжаЁЃ
ЃЈ5ЃЉDFSOutputStreamЮЌЛЄзХШЗШЯЖгСаРДЕШД§datanodeЪеЕНШЗШЯЛижДЃЌЪеЕНЙмЕРжаЫљгаdatanodeШЗШЯКѓЃЌЪ§ОнАќДгШЗШЯЖгСаЩОГ§ЁЃ
ЃЈ6ЃЉПЭЛЇЖЫЭъГЩЪ§ОнЕФаДШыЃЌЖдЪ§ОнСїЕїгУclose()ЗНЗЈЁЃ
ЃЈ7ЃЉnamenodeШЗШЯЭъГЩЁЃ
namenodeШчКЮбЁдёдкФЧИіdatanodeДцДЂИДБОЃП
ашвЊЖдПЩППадЃЌаДШыДјПэКЭЖСШЁДјПэНјааШЈКтЁЃФЌШЯВМОжЪЧЃКдкдЫааПЭЛЇЖЫЕФНкЕуЩЯЗХЕквЛИіИДБОЃЈШчЙћПЭЛЇЖЫдЫаадкМЏШКжЎЭтЃЌдђдкБмУтЬєбЁДцДЂЬЋТњЛђЬЋУІЕФНкЕуЕФЧщПіЯТЫцЛњбЁдёвЛИіНкЕуЁЃЃЉЕкЖўИіИДБОЗХдкгыЕквЛИіВЛЭЌЧвЫцЛњСэЭтбЁдёЕФЛњМмжаНкЕуЩЯЁЃЕкШ§ИіИДБОгыЕкЖўИіИДБОЗХдкЭЌвЛИіЛњМмЩЯЃЌЧвЫцЛњбЁдёСэвЛИіНкЕуЁЃЦфЫќИДБОЗХдкМЏШКжаЫцЛњбЁдёЕФНкЕужаЃЌОЁСПБмУтдкЭЌвЛИіЛњМмЩЯЗХЬЋЖрИДБОЁЃ
вЛИіИДБОИіЪ§ЮЊ3ЕФМЏШКЗХжУЮЛжУШчЭМЃК
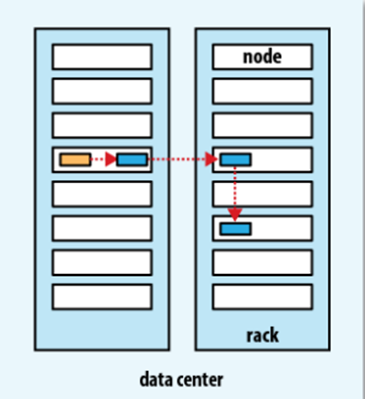
HDFSвЛжТадЃКHDFSдкаДЪ§ОнЮёБивЊБЃжЄЪ§ОнЕФвЛжТадгыГжОУадЃЌФПЧАHDFSЬсЙЉЕФСНжжСНИіБЃжЄЪ§ОнвЛжТадЕФЗНЗЈ
hsync()ЗНЗЈКЭhflush()ЗНЗЈЁЃ
hflush: БЃжЄflushЕФЪ§ОнБЛаТЕФreaderЖСЕНЃЌЕЋЪЧВЛБЃжЄЪ§ОнБЛdatanodeГжОУЛЏЁЃ
hsync: гыhflushМИКѕвЛбљЃЌВЛЭЌЕФЪЧhsyncБЃжЄЪ§ОнБЛdatanodeГжОУЛЏЁЃ
7ЁЂЭЈЙ§FlumeКЭSqoopЕМШыЪ§Он
ПЩвдПМТЧЪЙгУвЛаЉЯжГЩЕФЙЄОпНЋЪ§ОнЕМШыЁЃ
Apache FluemЪЧвЛИіНЋДѓЙцФЃСїЪ§ОнЕМШыHDFSЕФЙЄОпЁЃЕфаЭгІгУЪЧДгСэЭтвЛИіЯЕЭГжаЪеМЏШежОЪ§ОнВЂЪЕЯждкHDFSжаЕФОлМЏВйзївдБугУгкКѓЦкЕФЗжЮіВйзїЁЃ
Apache SqoopгУРДНЋЪ§ОнДгНсЙЙЛЏДцДЂЩшБИХњСПЕМШыHDFSжаЃЌР§ШчЙиЯЕЪ§ОнПтЁЃSqoopгІгУГЁОАЪЧзщжЏНЋАзЬьЩњВњЕФЪ§ОнПтжаЕФЪ§ОндкЭэМфЕМШыHiveЪ§ОнВжПтжаНјааЗжЮіЁЃ
8ЁЂЭЈЙ§distcpВЂааИДжЦ
distcpЗжВМЪНИДжЦГЬађЃЌЫќДгHadoopЮФМўЯЕЭГМфИДжЦДѓСПЪ§ОнЃЌвВПЩвдНЋДѓСПЕФЪ§ОнИДжЦЕНHadoopЁЃ
ЕфаЭгІгУГЁОАЪЧдкHDFSМЏШКжЎМфДЋЪфЪ§ОнЁЃ
% hadoop distcp hdfs://namenode1/foo hdfs://namenode2/bar
9ЁЂHadoopДцЕЕ
HDFSжаУПИіЮФМўОљАДПщЗНЪНДцДЂЃЌУПИіПщЕФдЊЪ§ОнДцДЂдкnamenodeЕФФкДцжаЃЌвђДЫHadoopДцДЂаЁЮФМўЛсЗЧГЃЕЭаЇЁЃвђЮЊДѓСПЕФаЁЮФМўЛсКФОЁnamenodeжаЕФДѓВПЗжФкДцЁЃHadoopЕФДцЕЕЮФМўЛђHARЮФМўЃЌНЋЮФМўДцШыHDFSПщЃЌМѕЩйnamenodeФкДцЪЙгУЃЌдЪаэЖдЮФМўНјааЭИУїЕиЗУЮЪЁЃ
HadoopДцЕЕЪЧЭЈЙ§archiveЙЄОпИљОнвЛзщЮФМўДДНЈЖјРДЕФЁЃдЫааarchiveжИСюЃК
% hadoop archive -archiveName files.har /my/files
/my
СаГіHARЮФМўЕФзщГЩВПЗжЃК
% hadoop fs -ls /my/files.har
files.harЪЧДцЕЕЮФМўЕФУћГЦЃЌетОфжИСюДцДЂ HDFSЯТ/my/filesжаЕФЮФМўЁЃ
HARЮФМўЕФзщГЩВПЗжЃКСНИіЫїв§ЮФМўвдМАВПЗжЮФМўЕФМЏКЯЁЃ
ДцЕЕЕФВЛзуЃК
аТНЈвЛИіДцЕЕЮФМўЛсДДНЈдЪМЮФМўЕФвЛИіИББОЃЌвђДЫашвЊгывЊДцЕЕЕФЮФМўШнСПЯрЭЌДѓаЁЕФДХХЬПеМфЁЃ
вЛЕЉДцЕЕЮФМўЃЌВЛФмДгжадіМгЛђЩОГ§ЮФМўЁЃ
|









