| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌБОЮФжївЊНщЩмШчКЮЪЙгУ
Scala БраД Spark гІгУГЬађДІРэДѓЪ§ОнЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
|
|
ДюНЈПЊЗЂЛЗОГ
АВзА Scala IDE
ДюНЈ Scala гябдПЊЗЂЛЗОГКмШнвзЃЌScala IDE ЙйЭј ЯТдиКЯЪЪЕФАцБОВЂНтбЙОЭПЩвдЭъГЩАВзАЃЌБОЮФЪЙгУЕФАцБОЪЧ
4.1.0
АВзА Scala гябдАќ
ШчЙћЯТдиЕФ Scala IDE здДјЕФ Scala гябдАќгы Spark
1.3.1 ЪЙгУЕФ Scala АцБО (2.10.x) ВЛвЛжТЃЌФЧУДОЭашвЊЯТдиКЭБОЮФЫљЪЙгУЕФ Spark
ЫљЦЅХфЕФАцБОЃЌвдШЗБЃЪЕЯжЕФ Scala ГЬађВЛЛсвђЮЊАцБОЮЪЬтЖјдЫааЪЇАм
ЧыЯТдиВЂАВзА Scala 2.10.5 Ац
АВзА JDK
ШчЙћФњЕФЛњЦїЩЯУЛгаАВзА JDKЃЌЧыЯТдиВЂАВзА 1.6 АцБОвдЩЯЕФ
JDK
ДДНЈВЂХфжУ Spark ЙЄГЬ
ДђПЊ Scala IDEЃЌДДНЈвЛИіУћГЦЮЊ spark-exercise
ЕФ Scala ЙЄГЬ
ЭМ 1. ДДНЈ scala ЙЄГЬ

дкЙЄГЬФПТМЯТДДНЈвЛИі lib ЮФМўМаЃЌВЂЧвАбФњЕФ Spark АВзААќЯТЕФ
spark-assembly jar АќПНБДЕН lib ФПТМЯТ
ЭМ 2. Spark ПЊЗЂ jar Аќ
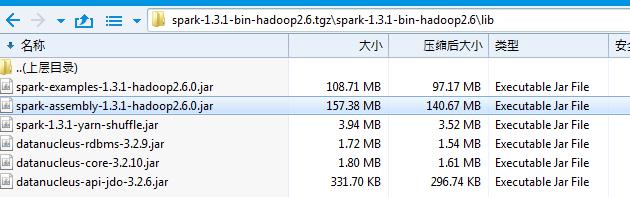
ВЂЧвЬэМгИУ jar АќЕНЙЄГЬЕФ classpath ВЂХфжУЙЄГЬЪЙгУИеИеАВзАЕФ
Scala 2.10.5 АцБО.ЃЌЙЄГЬФПТМНсЙЙШчЯТ
ЭМ 3. ЬэМг jar АќЕН classpath
дЫааЛЗОГНщЩм
ЮЊСЫБмУтЖСепЖдБОЮФАИР§дЫааЛЗОГВњЩњРЇЛѓЃЌБОНкЛсЖдБОЮФгУЕНЕФМЏШКЛЗОГЕФЛљБОЧщПізіИіМђЕЅНщЩм
БОЮФЫљгаЪЕР§Ъ§ОнДцДЂЕФЛЗОГЪЧвЛИі 8 ИіЛњЦїЕФ Hadoop МЏШКЃЌЮФМўЯЕЭГзмШнСПЪЧ 1.12TЃЌNameNode
На hadoop036166, ЗўЮёЖЫПкЪЧ 9000ЁЃЖСепПЩвдВЛЙиаФОпЬхЕФНкЕуЗжВМЃЌвђЮЊетИіВЛЛсгАЯьЕНФњдФЖСКѓУцЕФЮФеТЁЃ
БОЮФдЫааЪЕР§ГЬађЪЙгУЕФ Spark МЏШКЪЧвЛИіАќКЌЫФИіНкЕуЕФ Standalone ФЃЪНЕФМЏШК, ЦфжаАќКЌвЛИі
Master НкЕу (МрЬ§ЖЫПк 7077) КЭШ§Иі Worker НкЕуЃЌОпЬхЗжВМШчЯТЃК
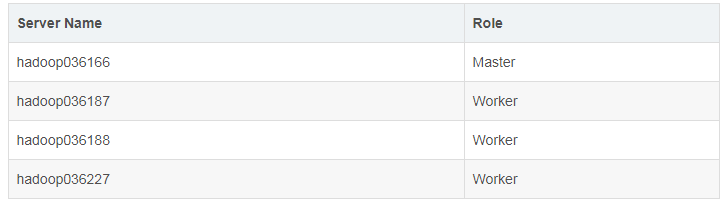
Spark ЬсЙЉвЛИі Web UI ШЅВщПДМЏШКаХЯЂВЂЧвМрПижДааНсЙћЃЌФЌШЯЕижЗЪЧ:http://<spark_master_ip>:8080
ЃЌЖдгкИУЪЕР§ЬсНЛКѓЮвУЧвВПЩвдЕН web вГУцЩЯШЅВщПДжДааНсЙћЃЌЕБШЛвВПЩвдЭЈЙ§ВщПДШежОШЅевЕНжДааНсЙћЁЃ
ЭМ 4. Spark ЕФ web console
АИР§ЗжЮігыБрГЬЪЕЯж
АИР§вЛ
a. АИР§Уш
ЬсЦ№ Word Count(ДЪЦЕЪ§ЭГМЦ)ЃЌЯраХДѓМвЖМВЛФАЩњЃЌОЭЪЧЭГМЦвЛИіЛђепЖрИіЮФМўжаЕЅДЪГіЯжЕФДЮЪ§ЁЃБОЮФНЋДЫзїЮЊвЛИіШыУХМЖАИР§ЃЌгЩЧГШыЩюЕФПЊЦєЪЙгУ
Scala БраД Spark ДѓЪ§ОнДІРэГЬађЕФДѓУХ
bЃЎАИР§Зж
ЖдгкДЪЦЕЪ§ЭГМЦЃЌгУ Spark ЬсЙЉЕФЫузгРДЪЕЯжЃЌЮвУЧЪзЯШашвЊНЋЮФБОЮФМўжаЕФУПвЛаазЊЛЏГЩвЛИіИіЕФЕЅДЪ,
ЦфДЮЪЧЖдУПвЛИіГіЯжЕФЕЅДЪНјааМЧвЛДЮЪ§ЃЌзюКѓОЭЪЧАбЫљгаЯрЭЌЕЅДЪЕФМЦЪ§ЯрМгЕУЕНзюжеЕФНсЙћ
ЖдгкЕквЛВНЮвУЧздШЛЕФЯыЕНЪЙгУ flatMap ЫузгАбвЛааЮФБО split ГЩЖрИіЕЅДЪЃЌШЛКѓЖдгкЕкЖўВНЮвУЧашвЊЪЙгУ
map ЫузгАбЕЅИіЕФЕЅДЪзЊЛЏГЩвЛИігаМЦЪ§ЕФ Key-Value ЖдЃЌМД word -> (word,1).
ЖдгкзюКѓвЛВНЭГМЦЯрЭЌЕЅДЪЕФГіЯжДЮЪ§ЃЌЮвУЧашвЊЪЙгУ reduceByKey ЫузгАбЯрЭЌЕЅДЪЕФМЦЪ§ЯрМгЕУЕНзюжеНсЙћЁЃ
c. БрГЬЪЕ
ЧхЕЅ 1.SparkWordCount РрдДТы
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
object SparkWordCount {
def FILE_NAME:String = "word_count_results_";
def main(args:Array[String]) {
if (args.length < 1) {
println("Usage:SparkWordCount FileName");
System.exit(1);
}
val conf = new SparkConf().setAppName("Spark
Exercise: Spark Version Word Count Program");
val sc = new SparkContext(conf);
val textFile = sc.textFile(args(0));
val wordCounts = textFile.flatMap(line =>
line.
split(" ")).map(
word => (word, 1)).reduceByKey((a, b) =>
a + b)
//print the results,for debug use.
//println("Word Count program running results:");
//wordCounts.collect().foreach(e => {
//val (k,v) = e
//println(k+"="+v)
//});
wordCounts.saveAsTextFile(FILE_NAME+System.
currentTimeMillis());
println("Word Count program running results
are successfully saved.");
}
} |
d. ЬсНЛЕНМЏШКжД
БОЪЕР§жа, ЮвУЧНЋЭГМЦ HDFS ЮФМўЯЕЭГжа/user/fams ФПТМЯТЫљга
txt ЮФМўжаДЪЦЕЪ§ЁЃЦфжа spark-exercise.jar ЪЧ Spark ЙЄГЬДђАќКѓЕФ jar
АќЃЌетИі jar АќжДааЪБЛсБЛЩЯДЋЕНФПБъЗўЮёЦїЕФ/home/fams ФПТМЯТЁЃдЫааДЫЪЕР§ЕФОпЬхУќСюШчЯТ
ЧхЕЅ 2.SparkWordCount РржДааУќСю
./spark-submit
\
--class com.ibm.spark.exercise.basic.SparkWordCount
\
--master spark://hadoop036166:7077 \
--num-executors 3 \
--driver-memory 6g --executor-memory 2g \
--executor-cores 2 \
/home/fams/sparkexercise.jar \
hdfs://hadoop036166:9000/user/fams/*.txt |
e. МрПижДаазДЬЌ
ИУЪЕР§АбзюжеЕФНсЙћДцДЂдкСЫ HDFS ЩЯЃЌФЧУДШчЙћГЬађдЫаае§ГЃЮвУЧПЩвддк
HDFS ЩЯевЕНЩњГЩЕФЮФМўаХ
ЭМ 5. АИР§вЛЪфГіНсЙћ
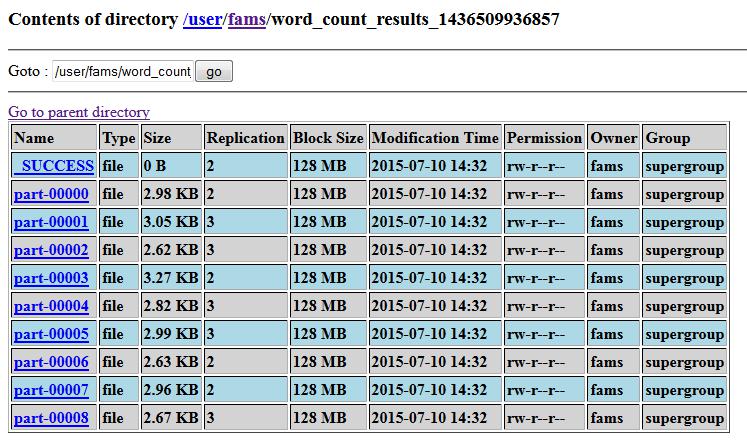
ДђПЊ Spark МЏШКЕФ Web UI, ПЩвдПДЕНИеВХЬсНЛЕФ job
ЕФжДааНсЙћ
ЭМ 6. АИР§вЛЭъГЩзДЬЌ

ШчЙћГЬађЛЙУЛдЫааЭъГЩЃЌФЧУДЮвУЧПЩвддк Running Applications
СаБэРяевЕНЫќ
АИР§Жў
a. АИР§Уш
ИУАИР§жаЃЌЮвУЧНЋМйЩшЮвУЧашвЊЭГМЦвЛИі 1000 ЭђШЫПкЕФЫљгаШЫЕФЦНОљФъСфЃЌЕБШЛШчЙћФњЯыВтЪд
Spark ЖдгкДѓЪ§ОнЕФДІРэФмСІЃЌФњПЩвдАбШЫПкЪ§ЗХЕФИќДѓЃЌБШШч 1 вкШЫПкЃЌЕБШЛетИіШЁОігкВтЪдЫљгУМЏШКЕФДцДЂШнСПЁЃМйЩшетаЉФъСфаХЯЂЖМДцДЂдквЛИіЮФМўРяЃЌВЂЧвИУЮФМўЕФИёЪНШчЯТЃЌЕквЛСаЪЧ
IDЃЌЕкЖўСаЪЧФъСф
ЭМ 7. АИР§ЖўВтЪдЪ§ОнИёЪНдЄРР
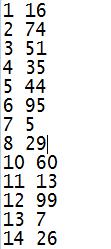
ЯждкЮвУЧашвЊгУ Scala аДвЛИіЩњГЩ 1000 ЭђШЫПкФъСфЪ§ОнЕФЮФМўЃЌдДГЬађШчЯТ
ЧхЕЅ 3. ФъСфаХЯЂЮФМўЩњГЩРрдДТы
import java.io.FileWriter
import java.io.File
import scala.util.Random
object SampleDataFileGenerator {
def main(args:Array[String]) {
val writer = new FileWriter(new File("C:
\\sample_age_data.txt"),false)
val rand = new Random()
for ( i <- 1 to 10000000) {
writer.write( i + " " + rand.nextInt(100))
writer.write(System.getProperty("line.separator"))
}
writer.flush()
writer.close()
}
} |
b. АИР§ЗжЮі
вЊМЦЫуЦНОљФъСфЃЌФЧУДЪзЯШашвЊЖддДЮФМўЖдгІЕФ RDD НјааДІРэЃЌвВОЭЪЧНЋЫќзЊЛЏГЩвЛИіжЛАќКЌФъСфаХЯЂЕФ
RDDЃЌЦфДЮЪЧМЦЫудЊЫиИіЪ§МДЮЊзмШЫЪ§ЃЌШЛКѓЪЧАбЫљгаФъСфЪ§МгЦ№РДЃЌзюКѓЦНОљФъСф=змФъСф/ШЫЪ§
ЖдгкЕквЛВНЮвУЧашвЊЪЙгУ map ЫузгАбдДЮФМўЖдгІЕФ RDD гГЩфГЩвЛИіаТЕФжЛАќКЌФъСфЪ§ОнЕФ
RDDЃЌКмЯдШЛашвЊЖддк map ЫузгЕФДЋШыКЏЪ§жаЪЙгУ split ЗНЗЈЃЌЕУЕНЪ§зщКѓжЛШЁЕкЖўИідЊЫиМДЮЊФъСфаХЯЂЃЛЕкЖўВНМЦЫуЪ§ОндЊЫизмЪ§ашвЊЖдгкЕквЛВНгГЩфЕФНсЙћ
RDD ЪЙгУ count ЫузгЃЛЕкШ§ВНдђЪЧЪЙгУ reduce ЫузгЖджЛАќКЌФъСфаХЯЂЕФ RDD ЕФЫљгадЊЫигУМгЗЈЧѓКЭЃЛзюКѓЪЙгУГ§ЗЈМЦЫуЦНОљФъСфМДПЩ
гЩгкБОР§ЪфГіНсЙћКмМђЕЅЃЌЫљвджЛДђгЁдкПижЦЬЈМДПЩ
c. БрГЬЪЕЯж
ЧхЕЅ 4.AvgAgeCalculator РрдДТы
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object AvgAgeCalculator {
def main(args:Array[String]) {
if (args.length < 1){
println("Usage:AvgAgeCalculator datafile")
System.exit(1)
}
val conf = new SparkConf().setAppName("Spark
Exercise:Average Age Calculator")
val sc = new SparkContext(conf)
val dataFile = sc.textFile(args(0), 5);
val count = dataFile.count()
val ageData = dataFile.map(line => line.split("
")(1))
val totalAge = ageData.map(age => Integer.parseInt(
String.valueOf(age))).collect().reduce((a,b) =>
a+b)
println("Total Age:" + totalAge + ";Number
of People:" + count )
val avgAge : Double = totalAge.toDouble / count.toDouble
println("Average Age is " + avgAge)
}
} |
d. ЬсНЛЕНМЏШКжДаа
вЊжДааБОЪЕР§ЕФГЬађЃЌашвЊНЋИеИеЩњГЩЕФФъСфаХЯЂЮФМўЩЯДЋЕН HDFS ЩЯЃЌМйЩшФњИеВХвбОдкФПБъЛњЦїЩЯжДааЩњГЩФъСфаХЯЂЮФМўЕФ
Scala РрЃЌВЂЧвЮФМўБЛЩњГЩЕНСЫ/home/fams ФПТМЯТ
ФЧУДФњашвЊдЫаавЛЯТ HDFS УќСюАбЮФМўПНБДЕН HDFS ЕФ/user/fams
ФПТМ
ЧхЕЅ 5. ФъСфаХЯЂЮФМўПНБДЕН HDFS ФПТМЕФУќСю
| hdfs dfs ЈCcopyFromLocal
/home/fams /user/fams |
ЧхЕЅ 6.AvgAgeCalculator РрЕФжДааУќСю
e. МрПижДаазДЬЌ
./spark-submit
\
--class com.ibm.spark.exercise.basic.AvgAgeCalculator
\
--master spark://hadoop036166:7077 \
--num-executors 3 \
--driver-memory 6g \
--executor-memory 2g \
--executor-cores 2 \
/home/fams/sparkexercise.jar \
hdfs://hadoop036166:9000/user/fams/
inputfiles/sample_age_data.txt |
дкПижЦЬЈФњПЩвдПДЕНШчЯТЫљЪОаХЯЂ
ЭМ 8. АИР§ЖўЪфГіНсЙћ

ЮвУЧвВПЩвдЕН Spark Web Console ШЅВщПД Job ЕФжДаазД
ЭМ 9. АИР§ЖўЭъГЩзДЬЌ

АИР§Ш§
a. АИР§УшЪі
БОАИР§МйЩшЮвУЧашвЊЖдФГИіЪЁЕФШЫПк (1 вк) адБ№ЛЙгаЩэИпНјааЭГМЦЃЌашвЊМЦЫуГіФаХЎШЫЪ§ЃЌФааджаЕФзюИпКЭзюЕЭЩэИпЃЌвдМАХЎаджаЕФзюИпКЭзюЕЭЩэИпЁЃБОАИР§жагУЕНЕФдДЮФМўгавдЯТИёЪН,
Ш§СаЗжБ№ЪЧ IDЃЌадБ№ЃЌЩэИп (cm)
ЭМ 10. АИР§Ш§ВтЪдЪ§ОнИёЪНдЄРР

ЮвУЧНЋгУвдЯТ Scala ГЬађЩњГЩетИіЮФМўЃЌдДТыШчЯТ
ЧхЕЅ 7. ШЫПкаХЯЂЩњГЩРрдДТы
import java.io.FileWriter
import java.io.File
import scala.util.Random
object PeopleInfoFileGenerator {
def main(args:Array[String]) {
val writer = new FileWriter(new File("C:\\LOCAL_DISK_D\\sample_people_info.txt"),false)
val rand = new Random()
for ( i <- 1 to 100000000) {
var height = rand.nextInt(220)
if (height < 50) {
height = height + 50
}
var gender = getRandomGender
if (height < 100 && gender == "M")
height = height + 100
if (height < 100 && gender == "F")
height = height + 50
writer.write( i + " " + getRandomGender
+ " " + height)
writer.write(System.getProperty("line.separator"))
}
writer.flush()
writer.close()
println("People Information File generated
successfully.")
}
def getRandomGender() :String = {
val rand = new Random()
val randNum = rand.nextInt(2) + 1
if (randNum % 2 == 0) {
"M"
} else {
"F"
}
}
} |
b. АИР§Зж
ЖдгкетИіАИР§ЃЌЮвУЧвЊЗжБ№ЭГМЦФаХЎЕФаХЯЂЃЌФЧУДКмздШЛЕФЯыЕНЪзЯШашвЊЖдгкФаХЎаХЯЂДгдДЮФМўЕФЖдгІЕФ
RDD жаНјааЗжРыЃЌетбљЛсВњЩњСНИіаТЕФ RDDЃЌЗжБ№АќКЌФаХЎаХЯЂЃЛЦфДЮЪЧЗжБ№ЖдФаХЎаХЯЂЖдгІЕФ RDD
ЕФЪ§ОнНјааНјвЛВНгГЩфЃЌЪЙЦфжЛАќКЌЩэИпЪ§ОнЃЌетбљЮвУЧгжЕУЕНСНИі RDDЃЌЗжБ№ЖдгІФаадЩэИпКЭХЎадЩэИпЃЛзюКѓашвЊЖдетСНИі
RDD НјааХХађЃЌНјЖјЕУЕНзюИпКЭзюЕЭЕФФаадЛђХЎадЩэИп
ЖдгкЕквЛВНЃЌвВОЭЪЧЗжРыФаХЎаХЯЂЃЌЮвУЧашвЊЪЙгУ filter ЫузгЃЌЙ§ТЫЬѕМўОЭЪЧАќКЌЁБMЁБ
ЕФааЪЧФаадЃЌАќКЌЁБFЁБЕФааЪЧХЎадЃЛЕкЖўВНЮвУЧашвЊЪЙгУ map ЫузгАбФаХЎИїздЕФЩэИпЪ§ОнДг RDD жаЗжРыГіРДЃЛЕкШ§ВНЮвУЧашвЊЪЙгУ
sortBy ЫузгЖдФаХЎЩэИпЪ§ОнНјааХХађ
c. БрГЬЪЕЯж
дкЪЕЯжЩЯЃЌгавЛИіашвЊзЂвтЕФЕуЪЧдк RDD зЊЛЏЕФЙ§ГЬжаашвЊАбЩэИпЪ§ОнзЊЛЛГЩећЪ§ЃЌЗёдђ
sortBy ЫузгЛсАбЫќЪгЮЊзжЗћДЎЃЌФЧУДХХађНсЙћОЭЛсЪмЕНгАЯьЃЌР§Шч ЩэИпЪ§ОнШчЙћЪЧЃК123,110,84,72,100ЃЌФЧУДЩ§ађХХађНсЙћНЋЛсЪЧ
100,110,123,72,84ЃЌЯдШЛетЪЧВЛЖдЕФ
ЧхЕЅ 8.PeopleInfoCalculator РрдДТы
object PeopleInfoCalculator
{
def main(args:Array[String]) {
if (args.length < 1){
println("Usage:PeopleInfoCalculator datafile")
System.exit(1)
}
val conf = new SparkConf().setAppName("Spark
Exercise:People Info(Gender & Height) Calculator")
val sc = new SparkContext(conf)
val dataFile = sc.textFile(args(0), 5);
val maleData = dataFile.filter(line => line.contains("M")).map(
line => (line.split(" ")(1) + "
" + line.split(" ")(2)))
val femaleData = dataFile.filter(line => line.contains("F")).map(
line => (line.split(" ")(1) + "
" + line.split(" ")(2)))
//for debug use
//maleData.collect().foreach { x => println(x)}
//femaleData.collect().foreach { x => println(x)}
val maleHeightData = maleData.map(line => line.split("
")(1).toInt)
val femaleHeightData = femaleData.map(line =>
line.split(" ")(1).toInt)
//for debug use
//maleHeightData.collect().foreach { x => println(x)}
//femaleHeightData.collect().foreach { x =>
println(x)}
val lowestMale = maleHeightData.sortBy(x =>
x,true).first()
val lowestFemale = femaleHeightData.sortBy(x =>
x,true).first()
//for debug use
//maleHeightData.collect().sortBy(x => x).foreach
{ x => println(x)}
//femaleHeightData.collect().sortBy(x => x).foreach
{ x => println(x)}
val highestMale = maleHeightData.sortBy(x =>
x, false).first()
val highestFemale = femaleHeightData.sortBy(x
=> x, false).first()
println("Number of Male Peole:" + maleData.count())
println("Number of Female Peole:" +
femaleData.count())
println("Lowest Male:" + lowestMale)
println("Lowest Female:" + lowestFemale)
println("Highest Male:" + highestMale)
println("Highest Female:" + highestFemale)
}
} |
d. ЬсНЛЕНМЏШКжД
дкЬсНЛИУГЬађЕНМЏШКжДаажЎЧАЃЌЮвУЧашвЊНЋИеВХЩњГЩЕФШЫПкаХЯЂЪ§ОнЮФМўЩЯДЋЕН
HDFS МЏШКЃЌОпЬхУќСюПЩвдВЮееЩЯЮФ
ЧхЕЅ 9.PeopleInfoCalculator РрЕФжДааУќСю
./spark-submit
\
--class com.ibm.spark.exercise.basic.PeopleInfoCalculator
\
--master spark://hadoop036166:7077 \
--num-executors 3 \
--driver-memory 6g \
--executor-memory 3g \
--executor-cores 2 \
/home/fams/sparkexercise.jar \
hdfs://hadoop036166:9000/user/fams/inputfiles
/sample_people_info.txt |
e. МрПижДаазДЬЌ
ЖдгкИУЪЕР§ЃЌШчГЬађжаДђгЁЕФвЛбљЃЌЛсдкПижЦЬЈЯдЪОШчЯТаХЯЂ
ЭМ 11. АИР§Ш§ЪфГіНсЙћ

дк Spark Web Console РяПЩвдПДЕНОпЬхЕФжДаазДЬЌаХ
ЭМ 12. АИР§Ш§ЭъГЩзДЬЌ

АИР§ЫФ
a. АИР§УшЪі
ИУАИР§жаЮвУЧМйЩшФГЫбЫїв§ЧцЙЋЫОвЊЭГМЦЙ§ШЅвЛФъЫбЫїЦЕТЪзюИпЕФ K ИіПЦММЙиМќДЪЛђДЪзщЃЌЮЊСЫМђЛЏЮЪЬтЃЌЮвУЧМйЩшЙиМќДЪзщвбОБЛећРэЕНвЛИіЛђепЖрИіЮФБОЮФМўжаЃЌВЂЧвЮФЕЕОпгавдЯТИёЪН
ЭМ 13. АИР§ЫФВтЪдЪ§ОнИёЪНдЄРР

ЮвУЧПЩвдПДЕНвЛИіЙиМќДЪЛђепДЪзщПЩФмГіЯжЖрДЮЃЌВЂЧвДѓаЁаДИёЪНПЩФмВЛвЛжТ
b. АИР§ЗжЮі
вЊНтОіетИіЮЪЬтЃЌЪзЯШЮвУЧашвЊЖдУПИіЙиМќДЪГіЯжЕФДЮЪ§НјааМЦЫуЃЌдкетИіЙ§ГЬжаашвЊЪЖБ№ВЛЭЌДѓаЁаДЕФЯрЭЌЕЅДЪЛђепДЪзщЃЌШчЁБSparkЁБКЭЁАsparkЁБ
ашвЊБЛШЯЖЈЮЊвЛИіЕЅДЪЁЃЖдгкГіЯжДЮЪ§ЭГМЦЕФЙ§ГЬКЭ word count АИР§РрЫЦЃЛЦфДЮЮвУЧашвЊЖдЙиМќДЪЛђепДЪзщАДееГіЯжЕФДЮЪ§НјааНЕађХХађЃЌдкХХађЧАашвЊАб
RDD Ъ§ОндЊЫиДг (k,v) зЊЛЏГЩ (v,k)ЃЛзюКѓШЁХХдкзюЧАУцЕФ K ИіЕЅДЪЛђепДЪзщ
ЖдгкЕквЛВНЃЌЮвУЧашвЊЪЙгУ map ЫузгЖддДЪ§ОнЖдгІЕФ RDD Ъ§ОнНјааШЋаЁаДзЊЛЏВЂЧвИјДЪзщМЧвЛДЮЪ§ЃЌШЛКѓЕїгУ
reduceByKey ЫузгМЦЫуЯрЭЌДЪзщЕФГіЯжДЮЪ§ЃЛЕкЖўВНЮвУЧашвЊЖдЕквЛВНВњЩњЕФ RDD ЕФЪ§ОндЊЫигУ
sortByKey ЫузгНјааНЕађХХађЃЛЕкШ§ВНдйЖдХХКУађЕФ RDD Ъ§ОнЪЙгУ take ЫузгЛёШЁЧА K
ИіЪ§ОндЊЫи
c. БрГЬЪЕ
ЧхЕЅ 10.TopKSearchKeyWords РрдДТы
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object TopKSearchKeyWords {
def main(args:Array[String]){
if (args.length < 2) {
println("Usage:TopKSearchKeyWords KeyWordsFile
K");
System.exit(1)
}
val conf = new SparkConf().setAppName("Spark
Exercise:Top K Searching Key Words")
val sc = new SparkContext(conf)
val srcData = sc.textFile(args(0))
val countedData = srcData.map(line => (line.toLowerCase(),1)).reduceByKey((a,b)
=> a+b)
//for debug use
//countedData.foreach(x => println(x))
val sortedData = countedData.map{ case (k,v)
=> (v,k) }.sortByKey(false)
val topKData = sortedData.take(args(1).toInt).map{
case (v,k) => (k,v) }
topKData.foreach(println)
}
} |
d. ЬсНЛЕНМЏШКжД
ЧхЕЅ 11.TopKSearchKeyWords РрЕФжДааУќСю
./spark-submit
\
--class com.ibm.spark.exercise.basic.TopKSearchKeyWords
\
--master spark://hadoop036166:7077 \
--num-executors 3 \
--driver-memory 6g \
--executor-memory 2g \
--executor-cores 2 \
/home/fams/sparkexercise.jar \
hdfs://hadoop036166:9000/user/fams/inputfiles
/search_key_words.txt |
e. МрПижДаазДЬЌ
ШчЙћГЬађГЩЙІжДааЃЌЮвУЧНЋдкПижЦЬЈПДЕНвдЯТаХЯЂЁЃЕБШЛЖСепвВПЩвдЗТееАИР§ЖўКЭАИР§Ш§ФЧбљЃЌздМКГЂЪдЪЙгУ
Scala аДвЛЖЮаЁГЬађЩњГЩДЫАИР§ашвЊЕФдДЪ§ОнЮФМўЃЌПЩвдИљОнФњЕФ HDFS МЏШКЕФШнСПЃЌЩњГЩОЁПЩФмДѓЕФЮФМўЃЌгУРДВтЪдБОАИР§ЬсЙЉЕФГЬађ
ЭМ 14. АИР§ЫФЪфГіНсЙћ

ЭМ 15. АИР§ЫФЭъГЩзДЬЌ

Spark job ЕФжДааСїГЬМђНщ
ЮвУЧПЩвдЗЂЯжЃЌSpark гІгУГЬађдкЬсНЛжДааКѓЃЌПижЦЬЈЛсДђгЁКмЖрШежОаХЯЂЃЌетаЉаХЯЂПДЦ№РДЪЧдгТвЮоеТЕФЃЌЕЋЪЧШДдквЛЖЈГЬЖШЩЯЬхЯжСЫвЛИіБЛЬсНЛЕФ
Spark job дкМЏШКжаЪЧШчКЮБЛЕїЖШжДааЕФЃЌФЧУДдкетвЛНкЃЌНЋЛсЯђДѓМвНщЩмвЛИіЕфаЭЕФ Spark
job ЪЧШчКЮБЛЕїЖШжДааЕФ
ЮвУЧЯШРДСЫНтвдЯТМИИіИХФю
DAG: МД Directed Acyclic GraphЃЌгаЯђЮоЛЗЭМЃЌетЪЧвЛИіЭМТлжаЕФИХФюЁЃШчЙћвЛИігаЯђЭМЮоЗЈДгФГИіЖЅЕуГіЗЂОЙ§ШєИЩЬѕБпЛиЕНИУЕуЃЌдђетИіЭМЪЧвЛИігаЯђЮоЛЗЭМ
JobЃКЮвУЧжЊЕРЃЌSpark ЕФМЦЫуВйзїЪЧ lazy жДааЕФЃЌжЛгаЕБХіЕНвЛИіЖЏзї
(Action) ЫузгЪБВХЛсДЅЗЂеце§ЕФМЦЫуЁЃвЛИі Job ОЭЪЧгЩЖЏзїЫузгЖјВњЩњАќКЌвЛИіЛђЖрИі Stage
ЕФМЦЫузївЕ
StageЃКJob БЛШЗЖЈКѓ,Spark ЕФЕїЖШЦї (DAGScheduler)
ЛсИљОнИУМЦЫузївЕЕФМЦЫуВНжшАбзївЕЛЎЗжГЩвЛИіЛђепЖрИі StageЁЃStage гжЗжЮЊ ShuffleMapStage
КЭ ResultStageЃЌЧАепвд shuffle ЮЊЪфГіБпНчЃЌКѓепЛсжБНгЪфГіНсЙћЃЌЦфБпНчПЩвдЪЧЛёШЁЭтВПЪ§ОнЃЌвВПЩвдЪЧвдвЛИі
ShuffleMapStage ЕФЪфГіЮЊБпНчЁЃУПвЛИі Stage НЋАќКЌвЛИі TaskSet
TaskSetЃК ДњБэвЛзщЯрЙиСЊЕФУЛга shuffle вРРЕЙиЯЕЕФШЮЮёзщГЩШЮЮёМЏЁЃвЛзщШЮЮёЛсБЛвЛЦ№ЬсНЛЕНИќМгЕзВуЕФ
TaskScheduler
TaskЃКДњБэЕЅИіЪ§ОнЗжЧјЩЯЕФзюаЁДІРэЕЅдЊЁЃЗжЮЊ ShuffleMapTask
КЭ ResultTaskЁЃShuffleMapTask жДааШЮЮёВЂАбШЮЮёЕФЪфГіЛЎЗжЕН (Лљгк task
ЕФЖдгІЕФЪ§ОнЗжЧј) ЖрИі bucket(ArrayBuffer) жа,ResultTask жДааШЮЮёВЂАбШЮЮёЕФЪфГіЗЂЫЭИјЧ§ЖЏГЬађ
Spark ЕФзївЕШЮЮёЕїЖШЪЧИДдгЕФЃЌашвЊНсКЯдДТыРДНјааНЯЮЊЯъОЁЕФЗжЮіЃЌЕЋЪЧетвбОГЌЙ§БОЮФЕФЗЖЮЇЃЌЫљвдетвЛНкЮвУЧжЛЪЧЖдДѓжТЕФСїГЬНјааЗжЮі
Spark гІгУГЬађБЛЬсНЛКѓЃЌЕБФГИіЖЏзїЫузгДЅЗЂСЫМЦЫуВйзїЪБЃЌSparkContext
ЛсЯђ DAGScheduler ЬсНЛвЛИізївЕЃЌНгзХ DAGScheduler ЛсИљОн RDD ЩњГЩЕФвРРЕЙиЯЕЛЎЗж
StageЃЌВЂОіЖЈИїИі Stage жЎМфЕФвРРЕЙиЯЕЃЌStage жЎМфЕФвРРЕЙиЯЕОЭаЮГЩСЫ DAGЁЃStage
ЕФЛЎЗжЪЧвд ShuffleDependency ЮЊвРОнЕФЃЌвВОЭЪЧЫЕЕБФГИі RDD ЕФдЫЫуашвЊНЋЪ§ОнНјаа
Shuffle ЪБЃЌетИіАќКЌСЫ Shuffle вРРЕЙиЯЕЕФ RDD НЋБЛгУРДзїЮЊЪфШыаХЯЂЃЌНјЖјЙЙНЈвЛИіаТЕФ
StageЁЃЮвУЧПЩвдПДЕНгУетбљЕФЗНЪНЛЎЗж StageЃЌФмЙЛБЃжЄгавРРЕЙиЯЕЕФЪ§ОнПЩвдвде§ШЗЕФЫГађжДааЁЃИљОнУПИі
Stage ЫљвРРЕЕФ RDD Ъ§ОнЕФ partition ЕФЗжВМЃЌЛсВњЩњГігы partition Ъ§СПЯрЕШЕФ
TaskЃЌетаЉ Task ИљОн partition ЕФЮЛжУНјааЗжВМЁЃЦфДЮЖдгк finalStage
ЛђЪЧ mapStage ЛсВњЩњВЛЭЌЕФ TaskЃЌзюКѓЫљгаЕФ Task ЛсЗтзАЕН TaskSet ФкЬсНЛЕН
TaskScheduler ШЅжДааЁЃгааЫШЄЕФЖСепПЩвдЭЈЙ§дФЖС DAGScheduler КЭ TaskScheduler
ЕФдДТыЛёШЁИќЯъЯИЕФжДааСїГЬ
НсЪјгя
ЭЈЙ§БОЮФЃЌЯраХЖСепЖдШчКЮЪЙгУ Scala БраД Spark гІгУГЬађДІРэДѓЪ§ОнвбОгаСЫНЯЮЊЩюШыЕФСЫНтЁЃЕБШЛдкДІРэЪЕМЪЮЪЬтЪБЃЌЧщПіПЩФмБШБОЮФОйЕУР§згИДдгКмЖрЃЌЕЋЪЧНтОіЮЪЬтЕФЛљБОЫМЯыЪЧвЛжТЕФЁЃдкХіЕНЪЕМЪЮЪЬтЕФЪБКђЃЌЪзЯШвЊЖддДЪ§ОнНсЙЙИёЪНЕШНјааЗжЮіЃЌШЛКѓШЗЖЈШчКЮШЅЪЙгУ
Spark ЬсЙЉЕФЫузгЖдЪ§ОнНјаазЊЛЏЃЌзюжеИљОнЪЕМЪашЧѓбЁдёКЯЪЪЕФЫузгВйзїЪ§ОнВЂМЦЫуНсЙћЁЃ
|









