| БрМЭЦМі: |
| БОЮФРДздгкCSDNЃЌБОЮФжївЊНщЩмСЫAzkabanдЫааФЃЪНЃЌзщМўЙЙГЩвдМАAzkabanЕФХфжУЕШЯрЙиФкШнЁЃ |
|
1. AzkabanИХЪі
AzkabanММЪѕВњЩњЧАОАЃК
дкДѓЪ§ОнЗжЮіГЁОАжаЃЌвдETLЃЈ ExtractГщШЁ -TransformНЛЛЅзЊЛЛ -LoadМгди
ЃЉЮЊР§ ЃЌЪ§ОнЕФВйзїАќКЌСЫШчЯТСїГЬЃКRDBMS ==>Sqoop ==>Hadoop ==>Sqoop
==>RDBMS/NoSQL/...,етРяЩцМАСЫШ§ИіСїГЬЃКЪ§ОнГщШЁ ==> Ъ§ОнЧхЯД ==>
Ъ§ОнШыПтЁЃ
етШ§ИіВНжшГіЯжСЫУїЯдЕФЫГађЮЪЬтЁЃМйЩшЪ§ОнГщШЁашвЊ3h,Ъ§ОнЧхЯДашвЊ2h,Ъ§ОнШыПташвЊ1hЁЃЮвУЧПЩвдЪЙгУlinux
shellЬсЙЉЕФcrontab РДЪЕЯжЁЃЫћЕФгХЕуЪЧЪЙгУМђЕЅЃЌШБЕуШДгаКмЖрЃК
1. СїГЬВЛБугкИњзйКЭМрПиЃЈСїГЬФГИіЛЗОГГіДэУЛАьЗЈМрПиЃЉЁЃ
2. дкетИіСїГЬжагааЉФЃПщжДааЕФЪБМфПЩФмГіЯжбгГй/ЬсЧАЁЃБШШчЪ§ОнЧхЯДдЄВташвЊ2h,НсЙћгУСЫ3hЃЌДЫПЬЪ§ОнШыПтдкЧАвЛИіШЮЮёЛЙУЛжДааЭъОЭвбОПЊЪМжДааСЫЃЛБШШчЧхЯДдЄВташвЊ2h,НсЙћгУСЫ1hЃЌЕМжТКѓУцЕФСїГЬГіЯжЮоаЇЕШД§ЕФзДЬЌЁЃ
вђДЫЃЌЯёAzkabanетбљЕФЕїЖШПђМмдкЮвУЧЪ§ОнЦНЬЈжаОЭАчбнзХКмживЊЕФНЧЩЋЁЃ
ДѓЪ§ОнжаГЃМћЕФЕїЖШПђМм
ДѓЪ§ОнжаГЃМћЕФЕїЖШПђМмЃЌзюГЃМћЕФОЭЪЧcrontabЁЃГ§ДЫжЎЭтЛЙгаКмЖрМЏГЩПђМмЃК
QuartzЃКQuartzЪЧOpenSymphony[pn smfni] ПЊдДзщжЏдкJob
schedulingСьгђгжвЛИіПЊдДЯюФПЃЌЫќПЩвдгыJ2EEгыJ2SEгІгУГЬађЯрНсКЯвВПЩвдЕЅЖРЪЙгУЁЃ
AzkabanЃКAzkabanЪЧгЩLinkedinЙЋЫОЭЦГіЕФвЛИіХњСПЙЄзїСїШЮЮёЕїЖШЦїЃЌ ЦфЪЙгУjobХфжУЮФМўНЈСЂШЮЮёжЎМфЕФвРРЕЙиЯЕЃЌВЂЬсЙЉвЛИівзгкЪЙгУЕФwebгУЛЇНчУцЮЌЛЄКЭИњзйФуЕФЙЄзїСї
ЁЃ
OozieЃКOozieЪЧвЛИіЙЄзїСїв§ЧцЗўЮёЦїЃЌгУгкдЫааhadoop map/reduceКЭhiveЕШШЮЮёЙЄзїСїЁЃЭЌЪБOozieЛЙЪЧвЛИіjava
webГЬађЃЌдЫаадкjava servletШнЦїжаЃЌШчtomcatжаЁЃOozieвдactionЮЊЛљБОЕЅЮЛЃЌПЩвдНЋЖрИіactionЙЙГЩвЛИіDAGЭМЕФФЃЪНдЫааЁЃOozieЙЄзїСїЭЈЙ§HPDLЃЈвЛжжЭЈЙ§XMLздЖЈвхДІРэЕФгябдЃЉРДЙЙдьOozieЙЄзїСїЁЃ
ZeusЃКжцЫЙЪЧАЂРяАЭАЭПЊдДЕФвЛПюЗжВМЪНHadoopзївЕЕїЖШЦНЬЈЃЌЪЕЯжШЮЮёЕФЗжВМЪНЕїЖШЃЌжЇГжЖрЛњЦїЕФЫЎЦНРЉеЙЁЃ
AzkabanИХЪі
AzkabanЪЧвЛИігЩLinkedIn ДДНЈЕФгУРДХмHadoop ШЮЮёЕФХњСПЕФЙЄзїСїжДааЦїЃЛЦфНтОіСЫjobвРРЕЫГађЕФЮЪЬтЃЌВЂЬсЙЉСЫвЛИіМђЕЅвзгУЕФгУЛЇНчУцМьВтЮвУЧЕФЙЄзїСїЁЃ
AzkabanЬиадШчЯТЃК
МцШнЫљгаHadoopАцБО
МђЕЅвзгУЕФwebВйзїНчУцКЭwebЙЄзїСїзЪдДЬсНЛЛњжЦ
дкAzkabanжаУПИіЯюФПЯрЛЅЖРСЂЛЅВЛгАЯьЁЃ
СМКУЕФЙЄзїСїжДааЗтзАЃЈжДааШЮЮёСїЮоашЬЋИДдгЕФВйзї вЛИіАДХЅИуЖЈЃЉЁЃ
ФЃПщЛЏКЭВхМўЛЏЃКжДааЕФОпЬхШЮЮёВЛЛсгыAzkabanЯрЛЅёюКЯЃЌДњТыЧжШыадЕЭЁЃ
ШЯжЄгыЪкШЈЃКСМКУЕФШЈЯоЙмРэЛњжЦ
ИњзйгУЛЇЕФааЮЊЃКЗНБуГіЯжЮЪЬтКѓжЊЕРЪЧФФИігУЛЇЕФДэЮѓЕМжТЕФЁЃ
ШЮЮёГЩЙІ/ЪЇАмКѓЕФ гЪМўЭЈжЊЛњжЦ
ШЮЮёДэЮѓЕФжиЪдЛњжЦ
Azkaban3.x вдКѓВЛЬсЙЉжБНгЕФАВзААќЯТдиЃЌЦфАВзААќашЭЈЙ§GradleНХБОРДБрвыЃЌ ВЂЧввЊЧѓзюЕЭЕФJavaАцБОЪЧ8.
ШчЯТЪЧAzkabanЕФбЇЯАЭјеОЃК
AzkabanЕФЙйЭјЃКhttps://azkaban.github.io
AzkabanЕФПђМмдДТыЃКhttps://github.com/azkaban/azkaban
AzkabanЮФЕЕЃКhttps://github.com/azkaban/azkaban.github.io
#2. AzkabanМмЙЙМђЮі
AzkabanгЩШ§ИіЙиМќзщМўЙЙГЩЃЈШчЯТЭМЃЉЃК
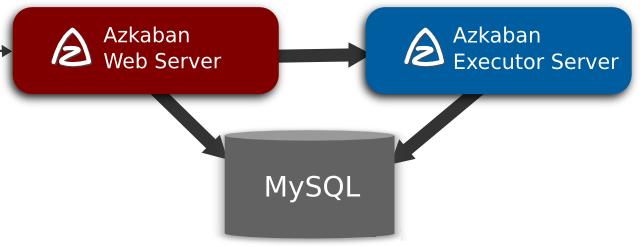
MySQLЙиЯЕаЭЪ§ОнПтЃКAzkabanЪЙгУЪ§ОнПтДцДЂДѓВПЗжзДЬЌЃЌAzkabanWebServerКЭAzkabanExecutorServerЖМашвЊЗУЮЪЪ§ОнПтЁЃ
AzkabanWebServerЃКAzkabanWebServerЪЧећИіAzkabanЙЄзїСїЯЕЭГЕФжївЊЙмРэепЃЌЫќИКд№projectЙмРэЁЂгУЛЇЕЧТМШЯжЄЁЂЖЈЪБжДааЙЄзїСїЁЂИњзйЙЄзїСїжДааНјЖШЕШвЛЯЕСаШЮЮёЁЃ
AzkabanExecutorServerЃКдчЦкАцБОЕФAzkabanдкЕЅИіЗўЮёжаОпгаAzkabanWebServerКЭAzkabanExecutorServerЙІФмЃЌФПЧАAzkabanвбНЋAzkabanExecutorServerЗжРыГЩЖРСЂЕФЗўЮёЦїЁЃЦфКУДІЪЧФГИіШЮЮёСїЪЇАмКѓЃЌПЩвдИќЗНБуЕФНЋЦфжиаТжДааЃЌБугкAzkabanЩ§МЖЁЃ
AzkabanЕФСНжждЫааФЃЪН
дкАцБО3.0жаЃЌAzkabanЬсЙЉСЫвдЯТСНжжФЃЪНЃК
solo server modeЃКзюМђЕЅЕФФЃЪНЃЌЪ§ОнПтФкжУЕФH2Ъ§ОнПтЃЌAzkabanWebServerКЭAzkabanExecutorServerЖМдквЛИіНјГЬжадЫааЃЌШЮЮёСПВЛДѓЯюФППЩвдВЩгУДЫФЃЪНЃЈЬиБ№ЪЪКЯГѕбЇепбЇЯАЪЙгУЃЌЙІФмЦыШЋЃЉЁЃ
multiple executor modeЃК ЪЪгУгкИќЖрЕФЩњВњЛЗОГЃЌЦфЪЙгУMySQL РДНјаадЊЪ§ОнЙмРэВЂЧвжЇГжжїДгНсЙЙЁЃдкетжжФЃЪНЯТweb
serverКЭexecutor server ЖРСЂдЫаадкВЛЭЌЕФжїЛњжаЁЃетжжФЃЪНДјРДЕФКУДІЪЧПЩвдШУAzkabanИќМгНЁзГКЭПЩРЉеЙЁЃ
дкбЇЯАЕФЙ§ГЬжаЃЌЮвУЧПЩвдЪЙгУРДsolo server етжжФЃЪНРДдЫааAzkabanЪЕР§ЁЃ
3. AzkabanЕФЯТдиКЭБрвы
ЯТдижЎЧА ЧыШЗБЃБОЛњЕФ Java АцБОЮЊ 1.8 ЁЃ
ЯТдиAzkabanдДТыЃК
НтбЙazkabanбЙЫѕАќВЂНјШыИУФПТМЃК

azkaban-common: ЛљБОЕФвРРЕАќ
azkaban-db: ПђМмКЫаФзщМў-Ъ§ОнПтЙЄОп
azkaban-exec-server & azkaban-web-server : ПђМмКЫаФзщМў
azkaban-solo-server: МЏГЩдЫааФЃЪНЙЄОпАќ
azkaban-spi : azkabanДцДЂНгПквдМАexceptionРр
azkaban-hadoop-security-plugin: hadoop гаЙиkerberosВхМў
дкБрвыдДТыжЎЧАЃЌЯШвЊЯТдиgradleЕФвРРЕАќЃЌжСгквЊЪВУДАцБОЃЌВщПДШчЯТЃК

ШчЯТЕижЗЪЧGradleЕФЙйЗНЯТдиЕижЗЃКhttps://services.gradle.org/distributions
ЯТдиКУЖдгІЕФАцБОКѓЃЌНЋбЙЫѕАќДцЗХЕНШчЯТЮЛжУЃК

аоИФХфжУЮФМўЃК
ЗЕЛиАВзААќжїФПТМжДааБрвыГЬађЃЈзЂвтЙйЗНИјГіЕФБрвыАцБОВЛДјВтЪдУќСю-x test,ЪОР§ШчЯТЃЉ
# Build without
running tests
>$ ./gradlew build installDist -x test |
жДааЩЯУцЕФУќСюЃЌГіЯжСЫgitгаЙиЕФвьГЃЃЌетРяжївЊЪЧЯЕЭГУЛгаАВзАgitУќСюЃЌЪЙгУyum install
-y git,КѓжиаТжДааВНжш4ЃЌНгЯТРДЕШД§ТўГЄЕФЯТдиЃЈвђЮЊФЌШЯЪЙгУЕФЪЧЙњЭтЕФgradleОЕЯёНјаазЪдДЯТдиЃЉЁЃ

ЮЊСЫМѕЩйБрвыЪБЯТдиеМгУЪБМфЃЌвЛАуЛсЮЊgradleдЖГЬзЪдДЬсЙЉОЕЯёЕижЗЗНБуЯТди
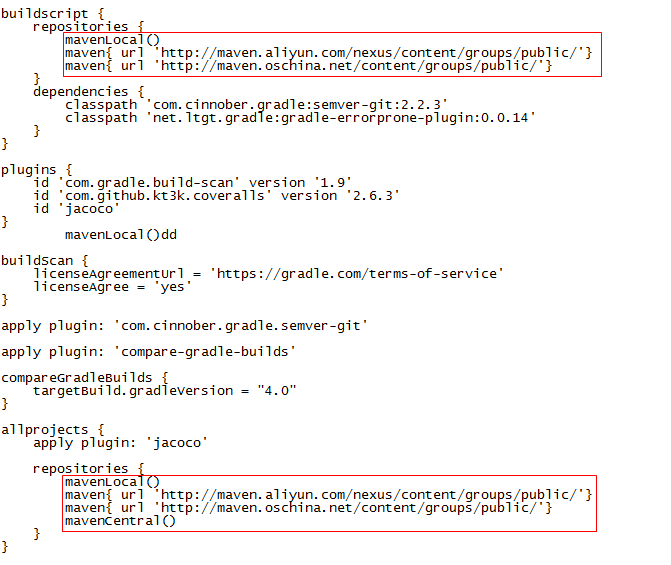
#дк ${AZKABAN_HOME}/build.gradleЮФМўжаХфжУ,ШЛКѓжиаТжДааВНжш4ЃК
mavenLocal()
maven{ url 'http://maven.aliyun.com/nexus/content/groups/public/'}
maven{ url 'http://maven.oschina.net/content/groups/public/'} |
4БрвыГЩЙІКѓЃЌПЩвдевЕНећИіМмЙЙЕФУПИіВПЗжЖМЛсЖрГівЛИіbuildЮФМўМаЃЌетВХЪЧЮвУЧвЊАВзАЕФЮФМўЃК
[root@azkabanvm
azkaban]# ls azkaban-solo-server/build
classes distributions install libs resources tmp
[root@azkabanvm azkaban]# ls azkaban-exec-server/build
classes distributions install libs resources tmp
[root@azkabanvm azkaban]# ls azkaban-web-server/build
classes distributions dust install jsToPackage
less libs nodejs resources tmp
[root@azkabanvm azkaban]# ls azkaban-db/build
classes distributions install libs sql tmp |
4. Azkaban-solo-serverАВзА
дкЩЯвЛНкЕФНВНтжаЃЌЮвУЧвбОЭъГЩAzkabanИїИіФЃПщЕФБрвыЁЃШчЯТЃК
$AZKABAN_SOURCE_HOME/azkaban-solo-server/build/distributions/*.tar.gz(zip)
$AZKABAN_SOURCE_HOME/azkaban-web-server/build/distributions/*.tar.gz(zip)
$AZKABAN_SOURCE_HOME/azkaban-executor-server/build/distributions/*.tar.gz(zip) |
НЋЦфЖдгІАќЯТЕФ.tar.gzЮФМўПНБДЕНЖРСЂЕФЮФМўМаЯТЃЈИУЮФМўМагУРДАВзА
AzkabanЃЉВЂНтбЙЃЌВЂЧвВЛвЊЭќМЧПНБДazkaban-db/build/distributions/xxx.sqlЮФМўЃЈетЪЧвЛИіЪ§ОнПтГѕЪМЛЏЕФНХБОЮФМўЃЉ
:
[root@azkabanvm
packages]# ll
total 58276
drwxr-xr-x. 6 root root 4096 Sep 29 01:24 azkaban-exec-server-0.1.0-SNAPSHOT
-rw-r--r--. 1 root root 15767192 Sep 29 01:24
azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz
drwxr-xr-x. 8 root root 4096 Sep 29 01:25 azkaban-solo-server-0.1.0-SNAPSHOT
-rw-r--r--. 1 root root 23876418 Sep 29 01:25
azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz
drwxr-xr-x. 6 root root 4096 Sep 29 01:25 azkaban-web-server-0.1.0-SNAPSHOT
-rw-r--r--. 1 root root 20009922 Sep 29 01:25
azkaban-web-server-0.1.0-SNAPSHOT.tar.gz |
ГѕЪМЛЏMySQL,етРяжБНгЬљГізюМђЕЅЕФАВзАЗНЪНЃК
yum install -y
mysql-server
yum install -y mysql
service mysqld start
mysql> mysql -u root -p
mysql> ##ЕквЛДЮАВзАУЛгаУмТы жБНгАДEnterМќ ШЛКѓаоИФЕБЧАУмТы
mysql> set password for 'root'@'localhost'
= password('root') ;
mysql> grant all privileges on *.* to root@192.168.60.13
identified by 'root';
mysql> FLUSH PRIVILEGES;
mysql> create database azkaban; |
НЋsqlЮФМўЕМШыЕНazkabanЪ§ОнПтжа
mysql> use
azkaban;
mysql> source /usr/local/azkaban/packages/create-all-sql-0.1.0-SNAPSHOT.sql;
mysql> show tables; |
ЩњГЩУидПЮФМўЃК
ДђПЊazkaban-solo-server-0.1.0-SNAPSHOT/conf/azkaban.propertiesЮФМўЃЈетРяжївЊХфжУЕФЪЧЪ§ОнПтЧ§ЖЏКЭжЄЪщШЯжЄЃЉЃК
default.timezone.id=Asia/Shanghai
database.type=mysql
mysql.port=3306
## етРязюКУХфжУIPЕижЗ
mysql.host=192.168.66.170
mysql.database=azkaban
mysql.user=root
mysql.password=sql_9879
mysql.numconnections=100
jetty.use.ssl=true
jetty.maxThreads=25
jetty.ssl.port=8666
jetty.port=8081
#зЂвтетРявЊЭГвЛХфжУКУkeystoreЮФМўДцДЂЕФТЗОЖ
jetty.keystore=.../keystore
jetty.password=000000
jetty.keypassword=000000
#зЂвтетРявЊЭГвЛХфжУКУkeystoreЮФМўДцДЂЕФТЗОЖ
jetty.truststore=.../keystore
jetty.trustpassword=000000 |
Дгazkaban.propertiesЮФМўФкШнПЩвдПДГіЛЙгавЛИіЮФМўЪЧгУРДЙмРэЕЧТМЕФгУЛЇЕФЃЌФЧОЭЪЧazkaban-users.xmlЃЌЮвУЧПЩвддкетИіЮФМўжаХфжУУмТыЃК

дкБОЛњЕФ /etc/hosts ЮФМўжаЬэМгБОЛњIPЕижЗЕФгГЩфЃК
ЗЕЛиazkaban-solo-server-0.1.0-SNAPSHOTФПТМЃЌдкетИіФПТМЯТЦєЖЏsoloЃК
[root@azkabanvm
azkaban-solo-server-0.1.0-SNAPSHOT]# bin/start-solo.sh
[root@azkabanvm azkaban-solo-server-0.1.0-SNAPSHOT]#
jps
3252 Jps
3227 AzkabanSingleServer
#ШчЙћНјГЬУЛгаЦєЖЏ ПЩвддкЕБЧАФПТМЯТЛсздЖЏДДНЈЦєЖЏНХБОЕФШежОЃК
[root@azkabanvm azkaban-solo-server-0.1.0-SNAPSHOT]#
cat soloServerLog__2018-09-29+18\:30\:29.out |
зЂвтЃКЩЯУцЕФsolo-serverЛсДДНЈвЛИіНаAzkabanSingleServerЕФНјГЬЃЌВЂдкЦєЖЏвЛЛсжЎКѓжїЖЏЭЫГіЃЌетИіВйзїПЩвдгУРДМьВщЮвУЧЕФХфжУЮФМўЪЧЗёе§ШЗЁЃЖјЮвУЧеце§вЊЦєЖЏЕФЪЧвЛИіExecutor
НјГЬКЭ WebНјГЬЁЃ
5. web/executor-server АВзА
НЋsolo-serverЯТЕФazkaban.propertiesЮФМўКЭazkaban-users.xmlЮФМўПНБДЕНweb/conf
ЮФМўМаЯТЁЃ
ЦєЖЏwebЗўЮёЃК
[root@azkabanvm
azkaban-web-server-0.1.0-SNAPSHOT]# bin/start-web.sh
[root@azkabanvm azkaban-web-server-0.1.0-SNAPSHOT]#
jps
3744 Jps
3336 AzkabanWebServer
|
ДгЦєЖЏЕФШежОЮФМўжаЮвУЧвВПЩвдПДЕНЦєЖЏЕФЖЫПкЃЌзЂвтетРявЛЖЈвЊБЃжЄЗРЛ№ЧНЪЧЙиБеЕФЃК
| [root@azkabanvm
azkaban-web-server-0.1.0-SNAPSHOT]# service iptables
stop |
дкЭјвГЖЫЗУЮЪsslвГУцЃК
НЋsolo-serverЯТЕФazkaban.propertiesЮФМўКЭazkaban-users.xmlЮФМўПНБДЕНexecutor/conf
ЮФМўМаЯТЁЃ
НјШыexecutorЮФМўМаЃЌЦєЖЏexecutorНјГЬЃК
[root@azkabanvm
azkaban-exec-server-0.1.0-SNAPSHOT]# bin/start-exec.sh
[root@azkabanvm azkaban-exec-server-0.1.0-SNAPSHOT]#
jps
3634 Jps
3607 AzkabanExecutorServer
3336 AzkabanWebServer |
6. ЦеЭЈshellУќСюJob
ЕЧТМвГУцКѓЃЌДДНЈвЛИіJobЯюФПЁЃ
ДДНЈcommand.jobЮФМўЃЌФкШнШчЯТЃЌПНБДЭъГЩКѓНЋЦфДђАќГЩzipЮФМў
ЩЯДЋJobЯюФПжаЃК
#command.job
type=command
command=echo 'hello' |
ЕквЛДЮжДааЯюФПЪБГіЯжПЈзЁЕФЯжЯѓЃЌжївЊЪЧazkabanвЊЧѓжДааJobБиаыдЫаадкзюЕЭга3GЕФФкДцПеМфРяЃЌШчЙћФуВЛашвЊетбљЕФЯожЦПЩвдаоИФexecutor/plugins/jobtypes/commonprivate.propertiesЮФМўЃЌНЋmemCheck.enabled=falseЁЃШЛКѓжиЦєећИіЗўЮёЃЈАќРЈwebКЭexecutorЃЉЁЃжиаТжДааШЮЮёВХЛсГЩЙІЁЃ
7. HDFSВйзїЕФJob
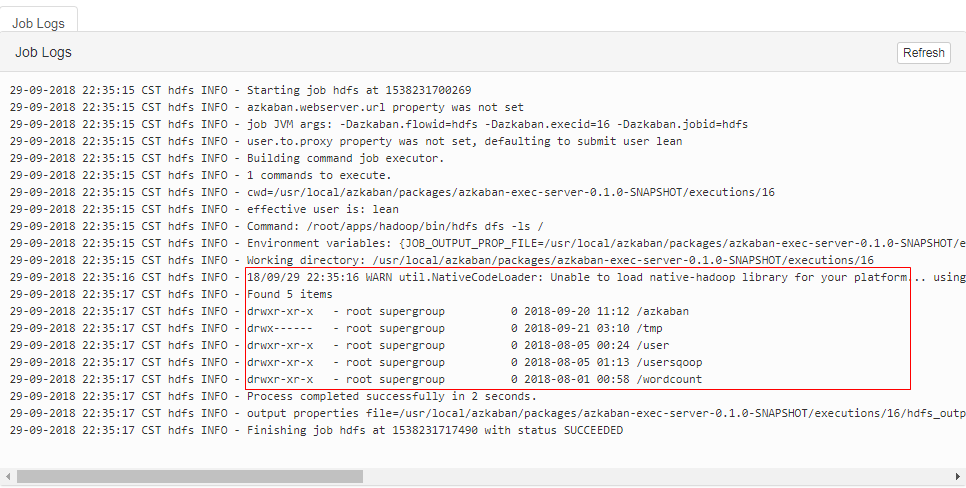
Г§СЫПЩвддкAzkabanЩЯжДааЦеЭЈЕФshellУќСюЃЌЛЙПЩвджДааHDFSЕФУќСюЃЌНгЯТРДгУвЛИіаЁАИР§РДЪЕЯжЃК

ЪзЯШвЊШЗБЃУќСюУЛгаДэЃЌНгЯТРДздМКаДвЛИіjobЃЌФкШнШчЯТЃК
#hdfs.job
type=command
command=/root/apps/hadoop/bin/hdfs dfs -ls / |
дкПижЦЬЈВщПДНсЙћШчЯТЃК
8. MapReduceВйзїЕФJob
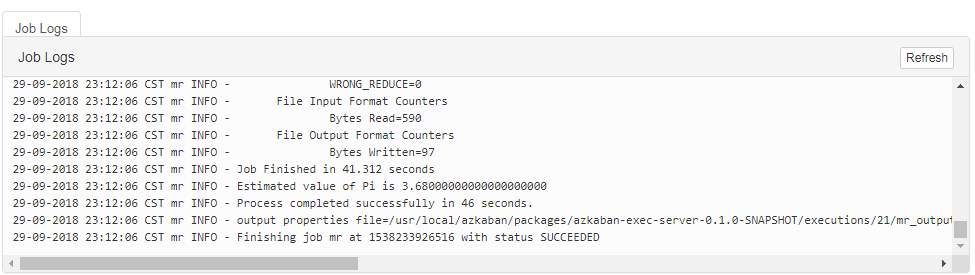
МШШЛПЩвдВйзїHDFSЃЌФЧУДЪЧЗёПЩвджДааMapReduce , ЮЊСЫбщжЄетИіНсЙћЃЌЪзЯШвЊгаИіMapReduceГЬађЃЌШчЯТЃК

ЖдгкжДааMapReduceЃЌВйзїЪБКђПЩвдНЋjarАќКЭjobЮФМўвЛЦ№ДђАќЃЌвВПЩвддкjobФкВПжИЖЈjarАќЕФТЗОЖЃК
#mapreduce.job
type=command
command=/root/apps/hadoop/bin/hadoop jar /root/apps/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar
pi 5 5 |
жДааНсЙћШчЯТЃК
9. HiveВйзїЕФJob
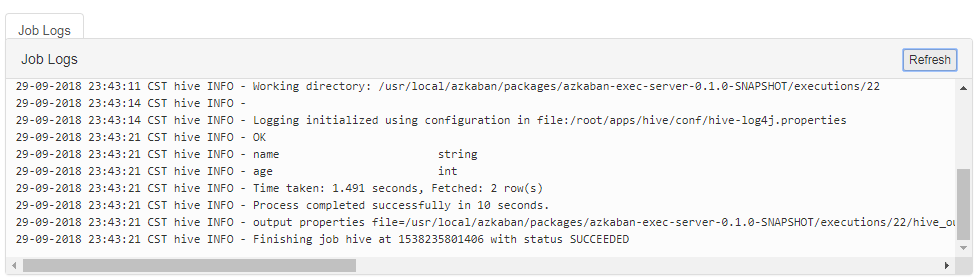
ЪзЯШ вЊБЃжЄЛЗОГжагаhiveЙЄОпПЩвдЪЙгУЃЌВЂгаЖдгІЕФЪ§ОнПтПЩвдВйзїЃЌhive.jobФкШнШчЯТЃК
##hive.job
type=command
command=/root/apps/hive/bin/hive -f curd.sql |
curd.sql ФкШнШчЯТЃК
НЋетСНВПЗжФкШнДђАќЕНazkabanЦНЬЈЃЌжДааШчЯТЃК
10. ШЮЮёЕФвРРЕЙиЯЕ
дкAzkabanжаЪЕМЪЩњВњжаЃЌИќЖрЪЙгУЕФЪЧЖрИіВЛЭЌШЮЮёЕФJobаЮГЩаТЕФЕФJobЃЌЦфФкВПЕФУПИіjobЖМашвЊЖЈвхКУжДааЕФЫГађЃЌетРяПЩвдЪЙгУdependenciesЪєадРДХфжУЁЃ
##foo.job
type=command
command=echo "foo"
##bar.job
type=command
dependencies=foo
command=echo "bar" |
11. AzkabanжЊЪЖЕуВЙГф
AzkabanжЇГжЕФжИСюРраЭгаКмЖржжЃЌБШШчshellжИСюЃЌhadoop shellжИСюЃЌJavaДњТыЃЌhadoop
javaДњТыЃЌPig жИСюЃЌHiveжИСюЕШЕШЃЌЕЋЪЧзюГЃМћЕФЛЙЪЧshell ЕФcommandжИСюЃЌЙйЗНТЗОЖЪЧЃК
https://azkaban.readthedocs.io/en/latest/jobTypes.html
ЁЃ
дквЛИіjobжаПЩвдвЛДЮаджДааЖрИіВЛЭЌЕФcommandжИСюЃЌЯё command.1
, command.2 ЕШЕШЁ
##multiple commands
job
type=command
command.1=ls /root
command.2=mkdir /root/wolfcode
command.3=... |
ЕБЧАЮвУЧзюГЃгУЕФЪЧЗНЪНЪЧЭЈЙ§Azkaban ЬсЙЉЕФЭјвГЖЫРДВйзїШЮЮёСїЃЌЭЌЪБAzkaban
вВЬсЙЉСЫajax apiЕФЗНЪНРДВйзїШЮЮёСїЃЌЯъЧщПЩвдВщПДЙйЗНЮФЕЕЃК https://azkaban.readthedocs.io/en/latest /ajaxApi.htmlhighlight=ajaxЁЃ
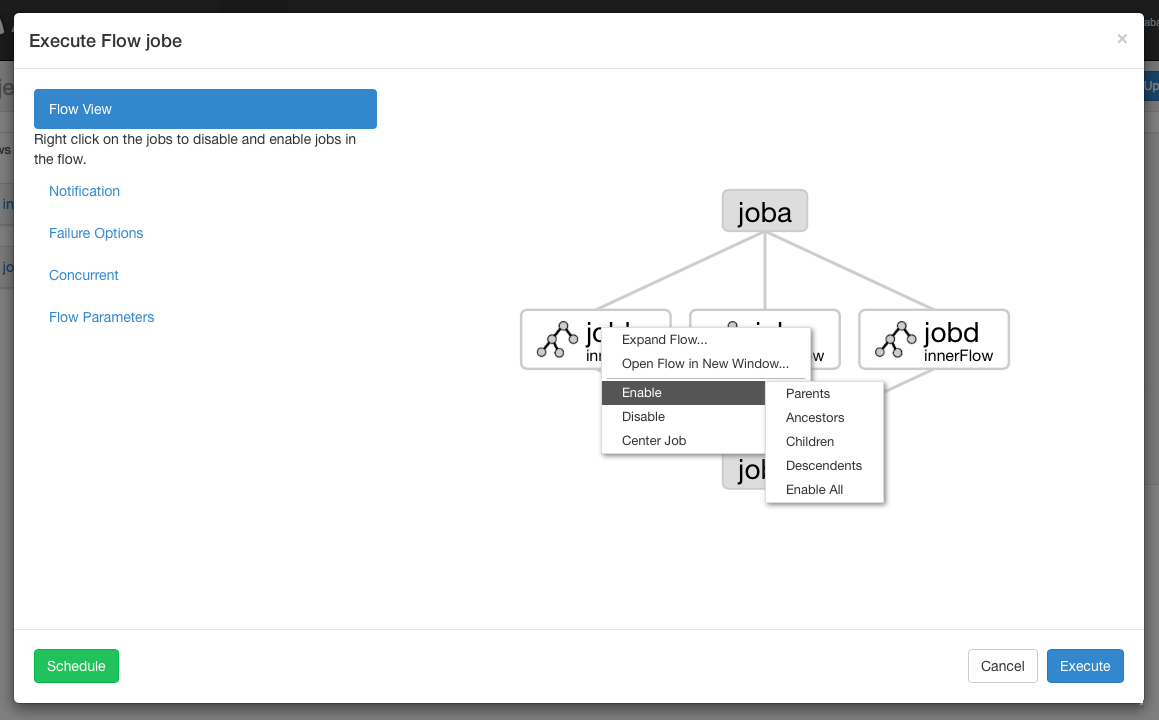
1.жДааЙЄзїСїНчУцЃКFrom the Flow View panel, you can right
click on the graph and disable or enable jobs. Disabled
jobs will be skipped during execution as if their
dependencies have been met. Disabled jobs will appear
translucent.
2.дкЙЄзїСїЕФзѓБпЛЙгавЛИіЭЈжЊУцАхЃЌдкЕБжДааЭъГЩ/ГЩЙІ/ЪЇАмЕФЪБКђЃЌПЩвдЭЈЙ§ХфжУemailРДНјааЯрЙид№ШЮШЫЕФЭЈжЊЃЈетИіФЃПщвђЮЊМАЪБадБШНЯЕЭ
вЛАугУВЛЕНЃЉ
3.дкЙЄзїСїзѓЯТНЧЛЙгавЛИіЖЈЪБЦїЕФАДХЅЃЌЦфЪБМфЕФЙцЗЖгыcrontab ЕФЪБМфЙцЗЖвЛжТЃЌЦфгУРДжИЖЈШЮЮёзіЖЈЪБжДааЁЃ
|









