| БрМЭЦМі: |
| БОЮФРДздгкCSDNЃЌБОЮФвдЪЕеНЮЊв§НщЩмСЫCommondРраЭЖрjobжДааЃЌHDFSВйзїШЮЮёвдМАHiveНХБОШЮЮёЕШЯрЙиФкШнЁЃ |
|
1ЁЂCommondРраЭЖрjobжДаа
1ЃЉЁЂБрМjobФкШн
ЕквЛИіjobЃЈbar.jabЃЉФкШнШчЯТЃЌвРРЕfoo.job
# bar.job
type=command
dependencies=foo
command=echo bar |
ЕкЖўИіjobЃЈfoo.jobЃЉФкШнШчЯТ
# foo.job
type=command
command=echo foo |
2ЃЉЁЂСНИіjobДђЕНвЛИіzipАќжаЃЈfoobar.zipЃЉ
3ЃЉЁЂдкazkabanЕФwebЙмРэНчУцДДНЈЙЄГЬВЂЩЯДЋzipАќ
етРябнЪОвЛБщКѓУцОЭВЛбнЪОСЫ
ДДНЈproject
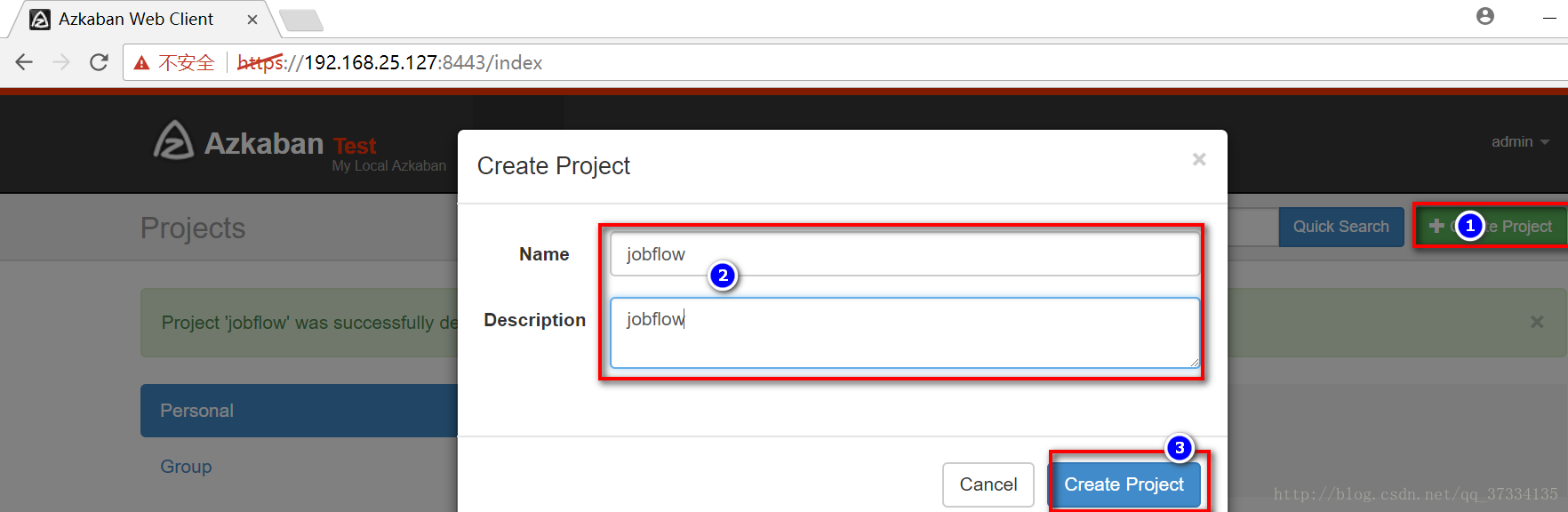
бЁдёИеДђКУЕФfoolbar.zipЩЯДЋ
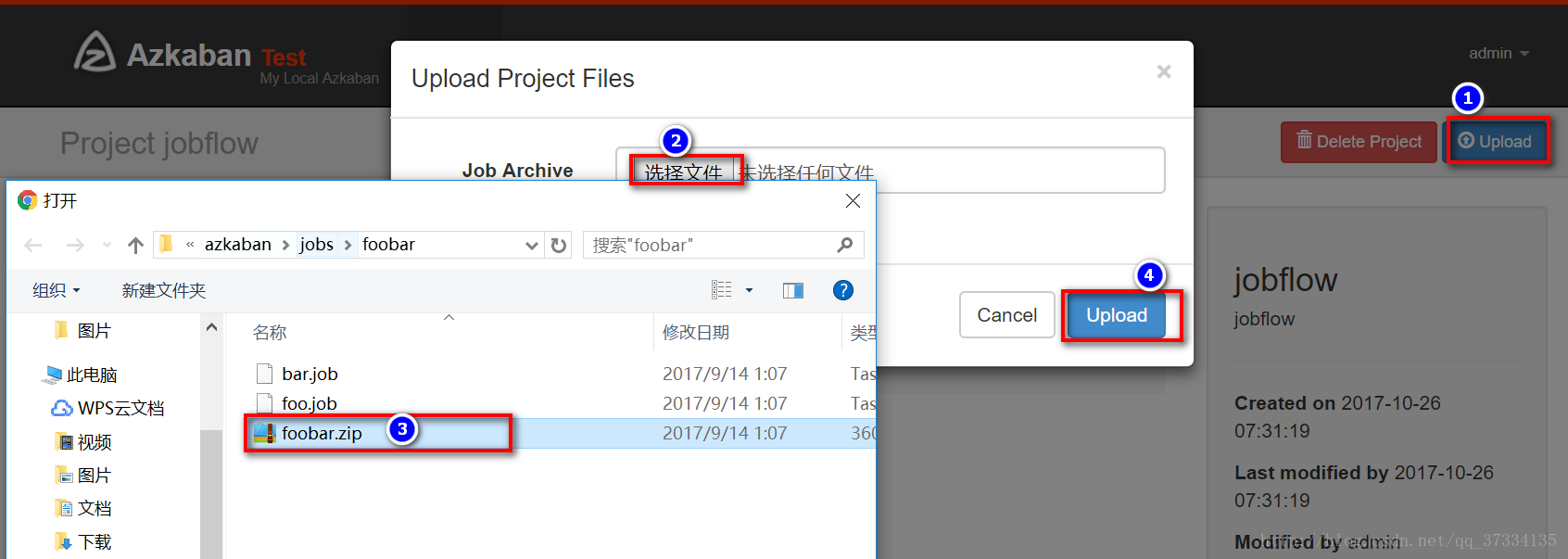
ЩЯДЋКѓбЁдёжДаа

вЛИіЪЧЕїЖШЃЌвЛИіЪЧСЂМДжДааЃЌетРяСЂМДжДаа
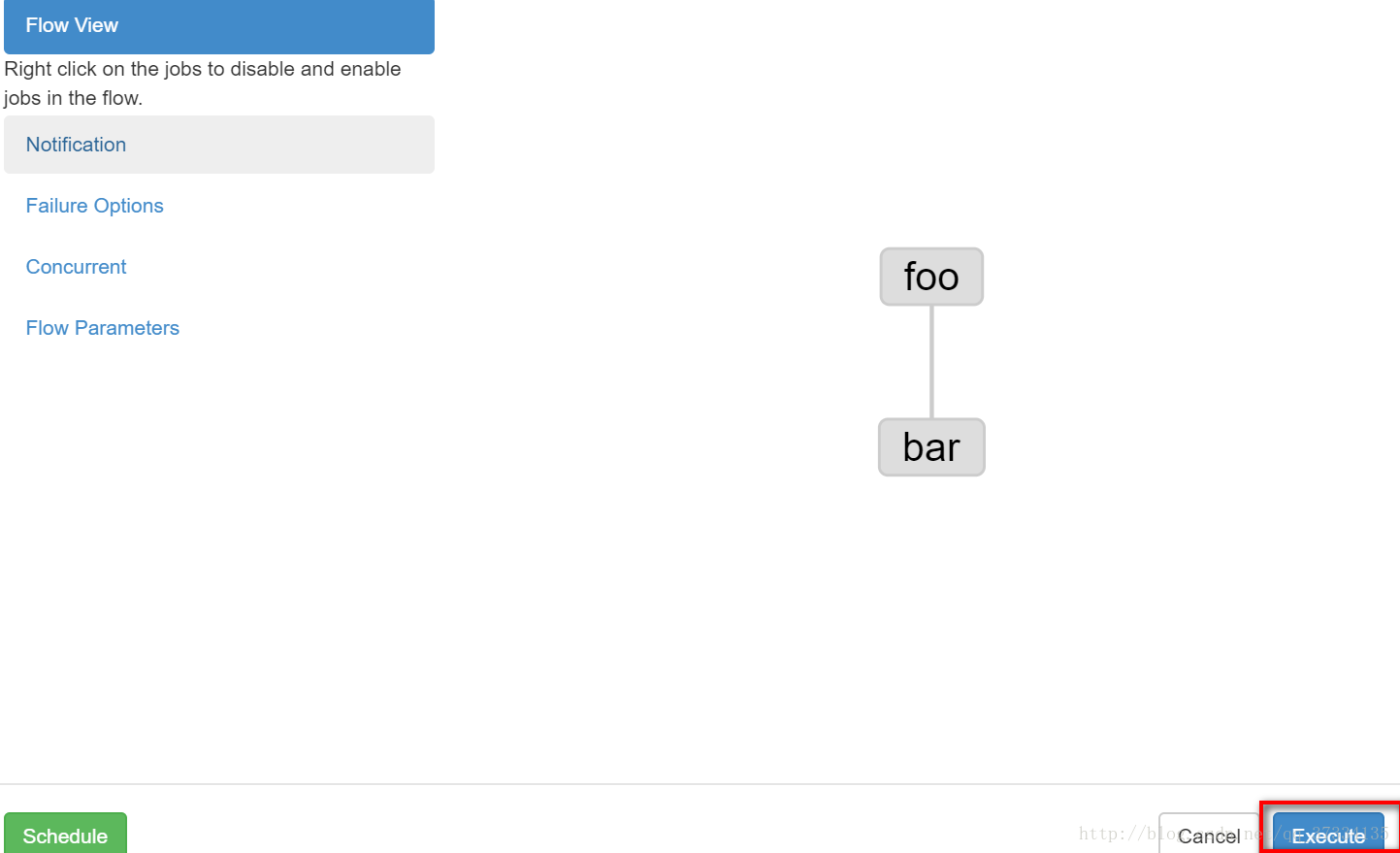
вбОЬсЪОГЩЙІСЫ
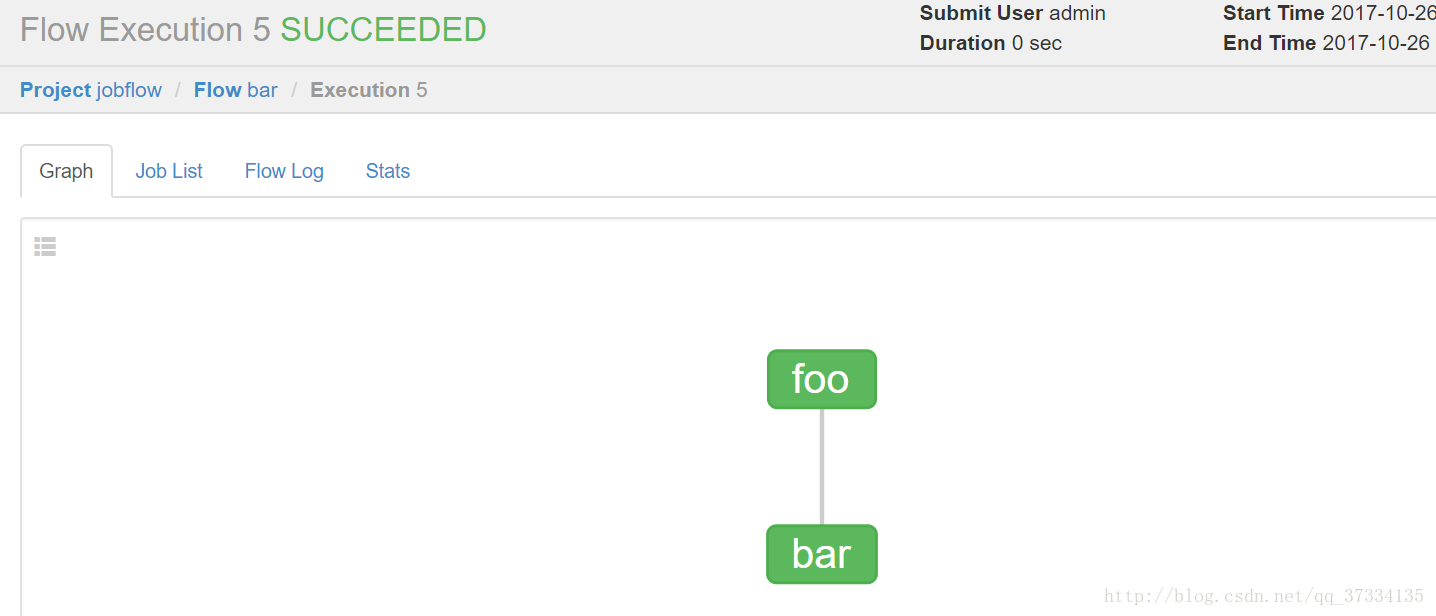
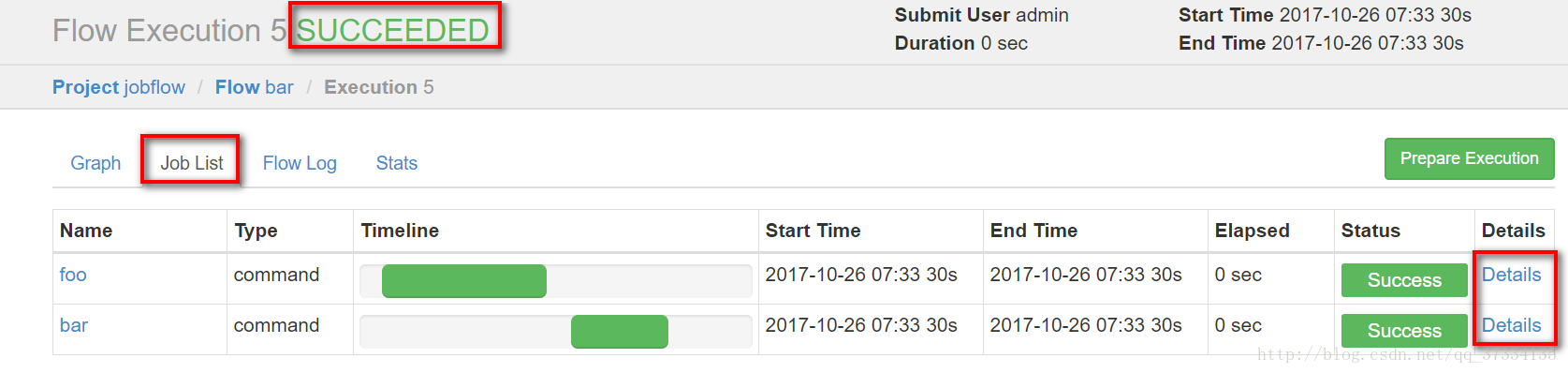
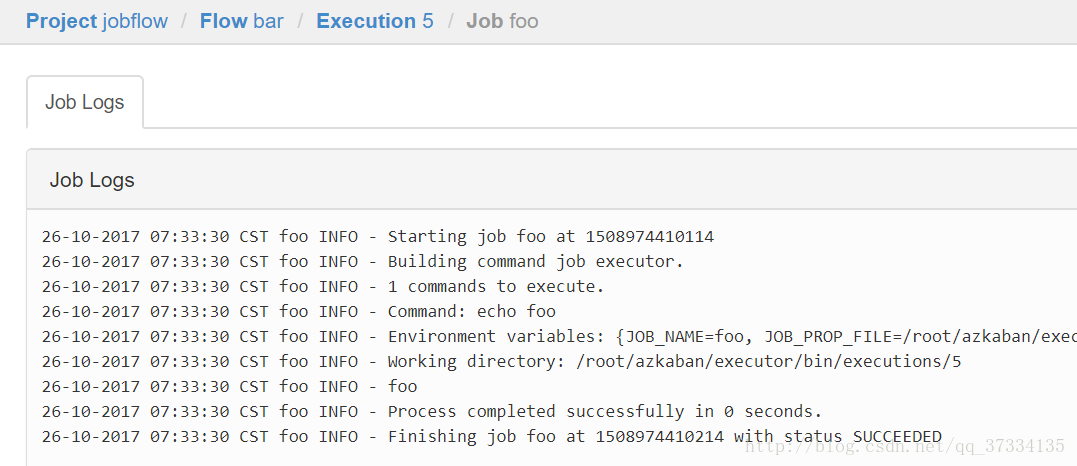
ЕуЛїdetailsФмПДЕНжДааЯъЧщ
2ЁЂHDFSВйзїШЮЮё
1ЃЉЁЂДДНЈjobЃЈfs.jobЃЉФкШнШчЯТ
# fs.job
type=command
command=/root/apps/hadoop-2.6.4/bin/hadoop fs
-mkdir /azaz |
зЂЃКжДааЕФЪЧhadoopУќСюЃЌашвЊаДЧхГўЮЛжУдкФФЃЌПЩвдЪЙгУwhichРДВщПД
[root@mini1
~]# which hadoop
/root/apps/hadoop-2.6.4/bin/hadoop |
2ЃЉЁЂДђГЩfs.zip
3ЃЉЁЂдкazkabanЕФwebЙмРэНчУцДДНЈЙЄГЬВЂЩЯДЋzipАќ
4ЃЉЁЂжДааИУjob
зЂЃКhadoopМЏШКашвЊЦ№РДВХФмХмЃЌФмДДНЈИУЮФМўМаЕФЛА
жДаажЎКѓГѕЪМЪЧrunningзДЬЌНгзХЛсЯдЪОsucceedЃЌГіДэСЫвВЛсЬсЪОДэЮѓаХЯЂЁЃХмЭъжЎКѓвГУцВщПДЪЧЗёдкhdfsЩЯДДНЈСЫazazФПТМ
ЪЙгУhadooУќСюДДНЈЮФМўМаГЩЙІСЫЃЌФЧУДЦфЫќВйзїЛљБОвВВЛЛсгаЮЪЬтОЭВЛбнЪОСЫЁЃ
3ЁЂХмMapreduceГЬађ
MrШЮЮёвРШЛПЩвдЪЙгУcommandЕФjobРраЭРДжДаа
1ЃЉЁЂДДНЈmrwc.jobФкШнШчЯТЃЈwordcountГЬађЃЉ
# mrwc.job
type=command
command=/root/apps/hadoop-2.6.4/bin/hadoop jar
hadoop-mapreduce-examples-2.6.1.jar wordcount
/wordcount2/input /wordcount2/azout |
2ЃЉЁЂДђwc.zipАќ
зЂЃКвЊНЋФмНјааЕЅДЪЭГМЦГЬађЫљдкЕФjarАќвВвЛЦ№ДђНјШЅ
ЕЋЪЧЛЙашвЊзМБИЙЄзїЃЌДДНЈКУФПТМЃЌДЋНјШыашвЊЭГМЦЕФЕЅДЪЫљдкЕФЮФМўЁЃ
[root@mini1 ~]#
vi c.txt
hello tom
hello jack
jack lucy
[root@mini1 ~]# hadoop fs -mkdir -p /wordcount2/input
[root@mini1 ~]# hadoop fs -put c.txt /wordcount2/input |
3ЃЉЁЂдкazkabanЕФwebЙмРэНчУцДДНЈЙЄГЬВЂЩЯДЋzipАќ
ЕШЭъГЩКѓШЅвГУцВщПД
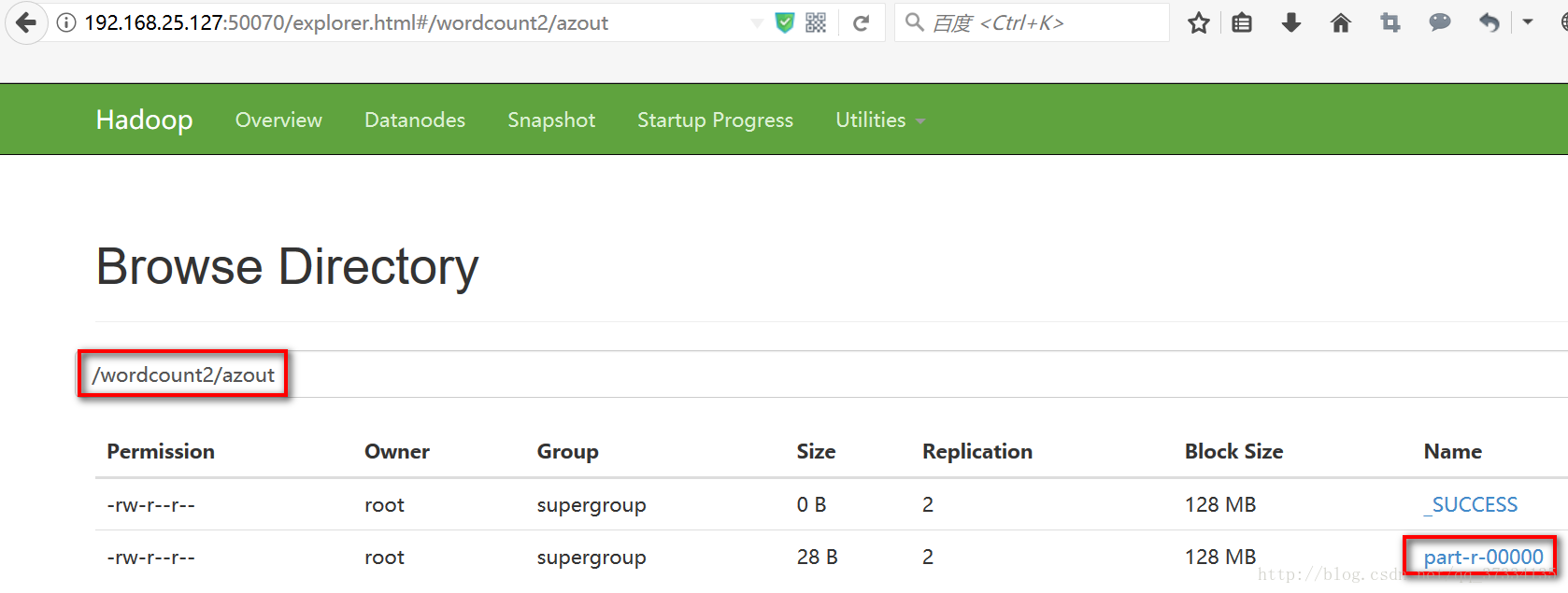
ВщПДЭГМЦНсЙћ
[root@mini1 ~]#
hadoop fs -ls /wordcount2/azout
Found 2 items
-rw-r--r-- 2 root supergroup 0 2017-10-26 08:08
/wordcount2/azout/_SUCCESS
-rw-r--r-- 2 root supergroup 28 2017-10-26 08:08
/wordcount2/azout/part-r-00000
[root@mini1 ~]# hadoop fs -cat /wordcount2/azout/part-r-00000
hello 2
jack 2
lucy 1 |
HiveНХБОШЮЮё
hiveНХБОЃЌtest.sqlФкШнШчЯТ
use default;
drop table aztest;
create table aztest(id int,name string) row format
delimited fields terminated by ',';
load data local inpath '/root/b.txt' into table
aztest;
create table azres as select * from aztest;
insert overwrite local directory '/root/hiveoutput'
select count(1) from aztest; |
jobУшЪіЮФМўЃЈhive.jabЃЉШчЯТ
# hivef.job
type=command
command=/root/apps/hive/bin/hive -f 'test.sql'
#-fБэЪОжДаааДдкЮФМўРяУцЕФsqlгяОф |
ЭЌбљЪЧЩЯДЋжДааЃЌЭъГЩКѓВщПДЪЧЗёДДНЈСЫСНеХБэКЭБОЕиЮФМў/root/hiveoutput/xxxx
hive> select
* from aztest;
OK
2 bb
3 cc
7 yy
9 pp
Time taken: 0.067 seconds, Fetched: 4 row(s)
hive> select * from azres;
OK
2 bb
3 cc
7 yy
9 pp
Time taken: 0.179 seconds, Fetched: 4 row(s)
hive> |
[root@mini1 ~]#
cd hiveoutput/
[root@mini1 hiveoutput]# ll
змгУСП 4
-rw-r--r--. 1 root root 2 10дТ 26 08:44 000000_0
[root@mini1 hiveoutput]# cat 000000_0
4
[root@mini1 hiveoutput]# |
|









