| 编辑推荐: |
本文来自于51cto,Apache
Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的
Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度.
|
|
YARN产生背景
YARN是Hadoop2.x才有的,所以在介绍YARN之前,我们先看一下MapReduce1.x时所存在的问题:
单点故障
节点压力大
不易扩展
MapReduce1.x时的架构如下:
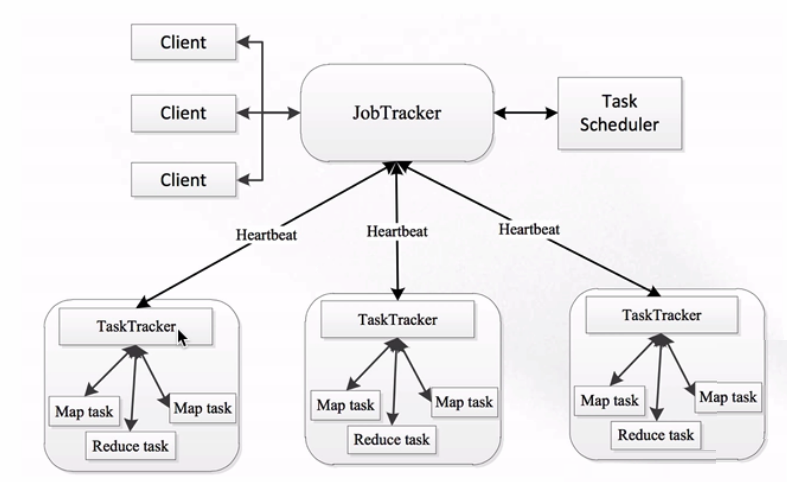
分布式资源调度——YARN框架
可以看到,1.x时也是Master/Slave这种主从结构,在集群上的表现就是一个JobTracker带多个TaskTracker。
JobTracker:负责资源管理和作业调度
TaskTracker:定期向JobTracker汇报本节点的健康状况、资源使用情况以及作业执行情况。还可以接收来自JobTracker的命令,例如启动任务或结束任务等。
那么这种架构存在哪些问题呢:
1.整个集群中只有一个JobTracker,就代表着会存在单点故障的情况
2.JobTracker节点的压力很大,不仅要接收来自客户端的请求,还要接收大量TaskTracker节点的请求
3.由于JobTracker是单节点,所以容易成为集群中的瓶颈,而且也不易域扩展
4.JobTracker承载的职责过多,基本整个集群中的事情都是JobTracker来管理
1.x版本的整个集群只支持MapReduce作业,其他例如Spark的作业就不支持了
由于1.x版本不支持其他框架的作业,所以导致我们需要根据不同的框架去搭建多个集群。这样就会导致资源利用率比较低以及运维成本过高,因为多个集群会导致服务环境比较复杂。如下图:
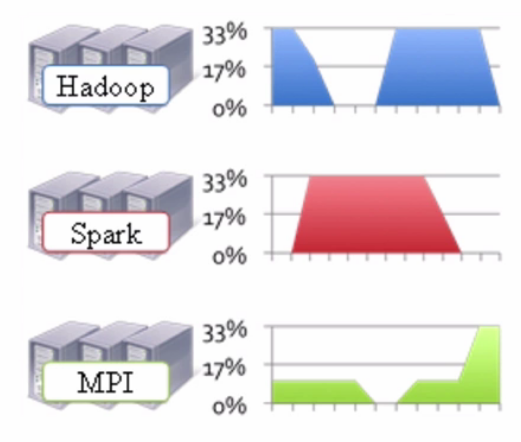
在上图中我们可以看到,不同的框架我不仅需要搭建不同的集群。而且这些集群很多时候并不是总是在工作,如上图可以看到,Hadoop集群在忙的时候Spark就比较闲,Spark集群比较忙的时候Hadoop集群就比较闲,而MPI集群则是整体并不是很忙。这样就无法高效的利用资源,因为这些不同的集群无法互相使用资源。除此之外,我们还得运维这些个不同的集群,而且文件系统是无法共享的。如果当需要将Hadoop集群上的HDFS里存储的数据传输到Spark集群上进行计算时,还会耗费相当大的网络IO流量。
所以我们就想着要把这些集群都合并在一起,让这些不同的框架能够运行在同一个集群上,这样就能解决这各种各样的问题了。如下图:
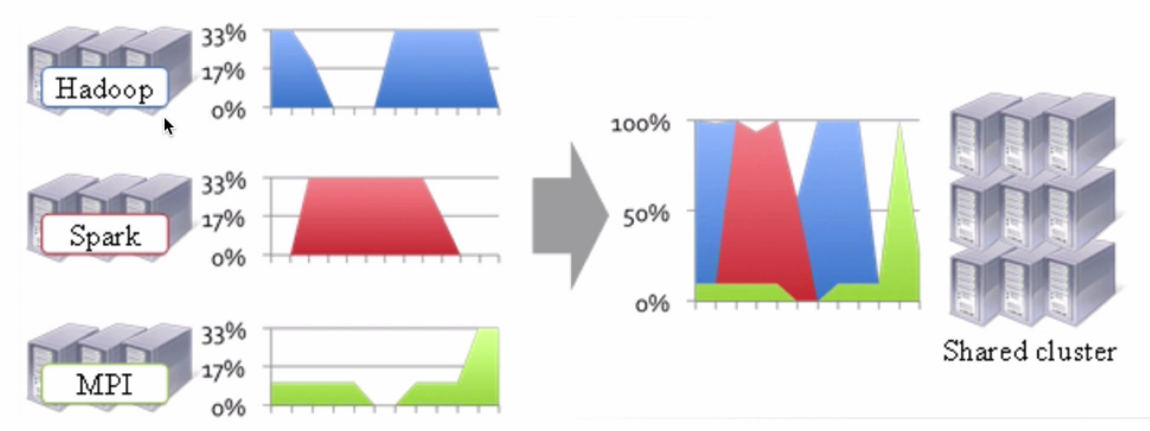
正是因为在1.x中,有各种各样的问题,才使得YARN得以诞生,而YARN就可以令这些不同的框架运行在同一个集群上,并为它们调度资源。我们来看看Hadoop2.x的架构图:
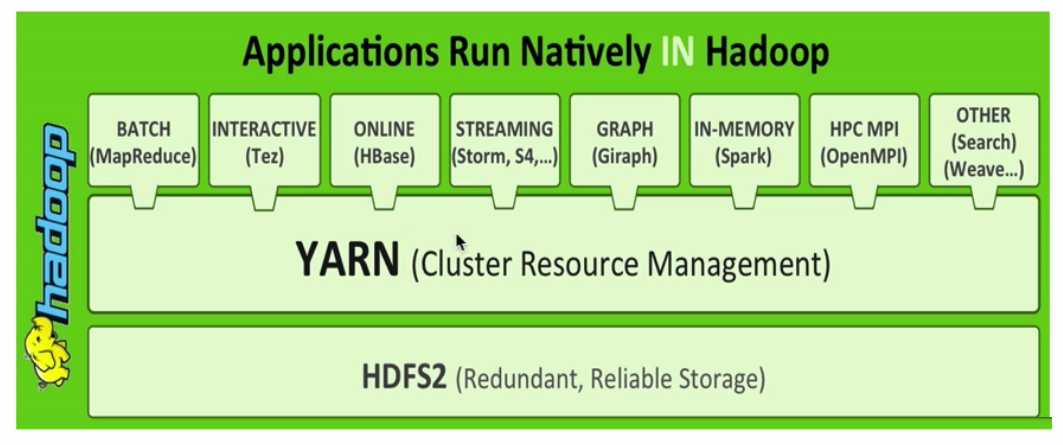
在上图中,我们可以看到,集群最底层的是HDFS,在其之上的就是YARN层,而在YARN层上则是各种不同的计算框架。所以不同计算框架可以共享同一个HDFS集群上的数据,享受整体的资源调度,进而提高集群资源的利用率,这也就是所谓的
xxx on YARN。
YARN架构
YARN概述:
YARN是资源调度框架
通用的资源管理系统
为上层应用提供统一的资源管理和调度
YARN架构图,也是Master/Slave结构的:
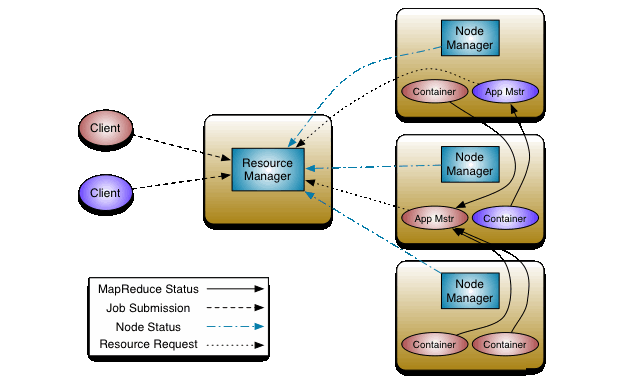
从上图中,我们可以看到YARN主要由以下几个核心组件构成:
1. ResourceManager, 简称RM,整个集群同一时间提供服务的RM只有一个,它负责集群资源的统一管理和调度。以及还需要处理客户端的请求,例如:提交作业或结束作业等。并且监控集群中的NM,一旦某个NM挂了,那么就需要将该NM上运行的任务告诉AM来如何进行处理。
2. NodeManager, 简称NM,整个集群中会有多个NM,它主要负责自己本身节点的资源管理和使用,以及定时向RM汇报本节点的资源使用情况。接收并处理来自RM的各种命令,例如:启动Container。NM还需要处理来自AM的命令,例如:AM会告诉NM需要启动多少个Container来跑task。
3. ApplicationMaster, 简称AM,每个应用程序都对应着一个AM。例如:MapReduce会对应一个、Spark会对应一个。它主要负责应用程序的管理,为应用程序向RM申请资源(Core、Memory),将资源分配给内部的task。AM需要与NM通信,以此来启动或停止task。task是运行在Container里面的,所以AM也是运行在Container里面。
4. Container, 封装了CPU、Memory等资源的一个容器,相当于是一个任务运行环境的抽象。
5. Client, 客户端,它可以提交作业、查询作业的运行进度以及结束作业。
YARN官方文档地址
YARN执行流程
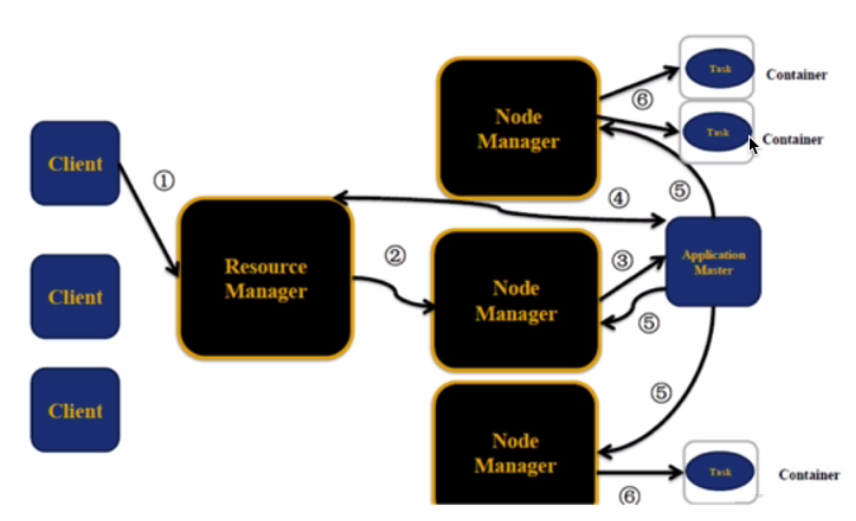
假设客户端向ResourceManager提交一个作业,ResourceManager则会为这个作业分配一个Container。所以ResourceManager会与NodeManager进行通信,要求这个NodeManager启动一个Container。而这个Container是用来启动ApplicationMaster的,ApplicationMaster启动完之后会与ResourceManager进行一个注册。这时候客户端就可以通过ResourceManager查询作业的运行情况了。然后ApplicationMaster还会到ResourceManager上申请作业所需要的资源,申请到以后就会到对应的NodeManager之上运行客户端所提交的作业,然后NodeManager就会把task运行在启动的Container里。
如下图:
YARN环境搭建
介绍完基本的理论部分之后,我们来搭建一个伪分布式的单节点YARN环境,使用的hadoop版本如下:
hadoop-2.6.0-cdh5.7.0
官方的安装文档地址
1.下载并解压好hadoop-2.6.0-cdh5.7.0,这一步可以参考我之前写的一篇关于HDFS伪分布式环境搭建的文章,我这里就不再赘述了。
确保HDFS是正常启动状态:
[root@localhost
~]# jps
3827 Jps
3383 NameNode
3500 DataNode
3709 SecondaryNameNode
[root@localhost ~]# |
2.编辑mapred-site.xml配置文件,在文件中增加如下内容:
[root@localhost
~] # cd /usr/local/hadoop-2.6.0 -cdh5.7.0/etc/hadoop
[root@localhost /usr/local/hadoop -2.6.0-cdh5.7.0/etc/hadoop] #
cp mapred-site.xml.template mapred-site.xml #
拷贝模板文件
[root@localhost /usr/local/hadoop -2.6.0-cdh5.7.0/etc/hadoop]
# vim mapred-site.xml # 增加如下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> |
3.编辑yarn-site.xml配置文件,在文件中增加如下内容:
[root@localhost
/usr/local/hadoop-2.6.0 -cdh5.7.0/etc/hadoop]
# vim yarn-site.xml # 增加如下内容
<property>
<name>yarn.nodemanager.aux-services </name>
<value>mapreduce_shuffle</value>
</property> |
4.启动ResourceManager进程以及NodeManager进程:
[root@localhost
/usr/local/hadoop-2.6.0 -cdh5.7.0/etc/hadoop]#
cd ../../sbin/
[root@localhost /usr/local/hadoop-2.6.0 -cdh5.7.0/sbin]#
./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.6.0-cdh5.7.0/logs/ yarn-root-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /usr/local/hadoop-2.6.0-cdh5.7.0/logs/yarn -root-nodemanager-localhost.out
[root@localhost /usr/local/hadoop -2.6.0-cdh5.7.0/sbin]#
jps
3984 NodeManager # 启动成功后可以看到多出了NodeManager
4947 DataNode
5252 Jps
5126 SecondaryNameNode
3884 ResourceManager # 和ResourceManager进程,这样才是正常的。
4813 NameNode
[root@localhost /usr/local/hadoop-2.6.0 -cdh5.7.0/sbin]#
netstat -lntp |grep java
tcp 0 0 0.0.0.0:50090 0.0.0.0:* LISTEN 5126/java
tcp 0 0 127.0.0.1:42602
0.0.0.0:*
LISTEN 4947/java
tcp 0 0 192.168.77.130:8020 0.0.0.0:* LISTEN 4813/java
tcp 0 0 0.0.0.0:50070 0.0.0.0:* LISTEN 4813/java
tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN 4947/java
tcp 0 0 0.0.0.0:50075 0.0.0.0:* LISTEN 4947/java
tcp 0 0 0.0.0.0:50020 0.0.0.0:* LISTEN 4947/java
tcp6 0 0 :::8040
:::*
LISTEN 5566/java
tcp6 0 0 :::8042
:::*
LISTEN
5566/java
tcp6 0 0 :::8088 :::*
LISTEN
5457/java
tcp6 0 0 :::13562
:::*
LISTEN 5566/java
tcp6 0 0 :::8030 :::*
LISTEN
5457/java
tcp6 0 0 :::8031
;:::*
LISTEN 5457/java
tcp6 0 0 :::8032 :::*
LISTEN
5457/java
tcp6 0 0 :::48929 :::*
LISTEN 5566/java
tcp6 0 0 :::8033 :::*
LISTEN
5457/java
[root@localhost /usr/local/hadoop-2.6.0-cdh5.7.0/sbin]#
|
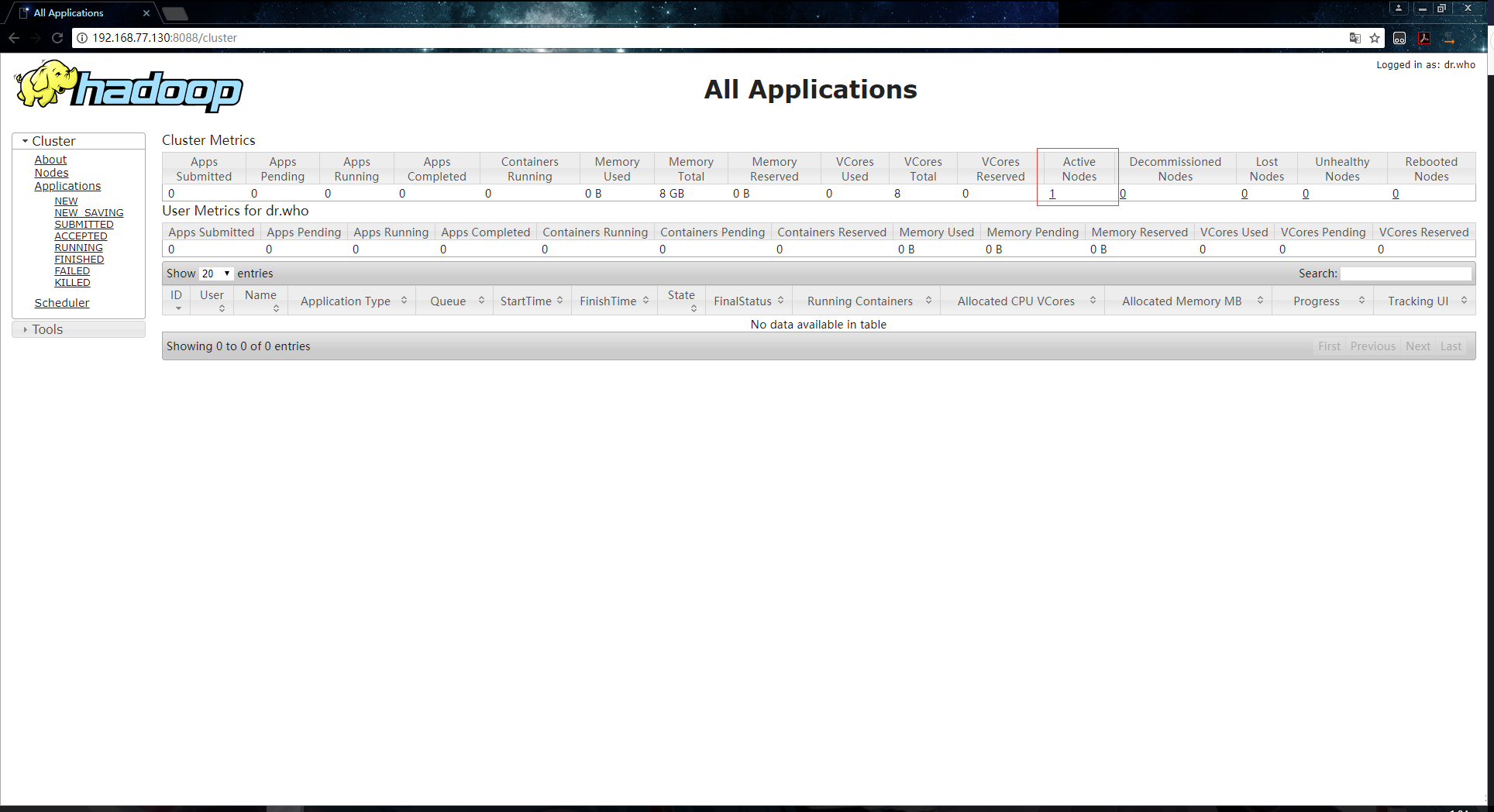
5.通过浏览器来访问ResourceManager,默认端口是8088,例如192.168.77.130:8088,就会访问到这样的一个页面上:

错误解决:
从上图中,可以看到有一个不健康的节点,也就是说我们的单节点环境有问题,点击红色框框中标记的数字可以进入到详细的信息页面,在该页面中看到了如下信息:
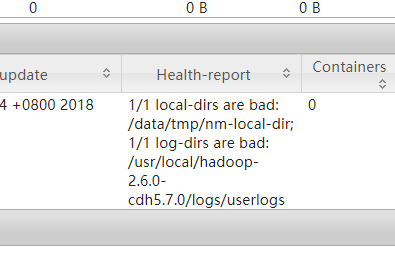
于是查看yarn的日志文件:yarn-root-nodemanager-localhost.log,发现如下警告与异常:
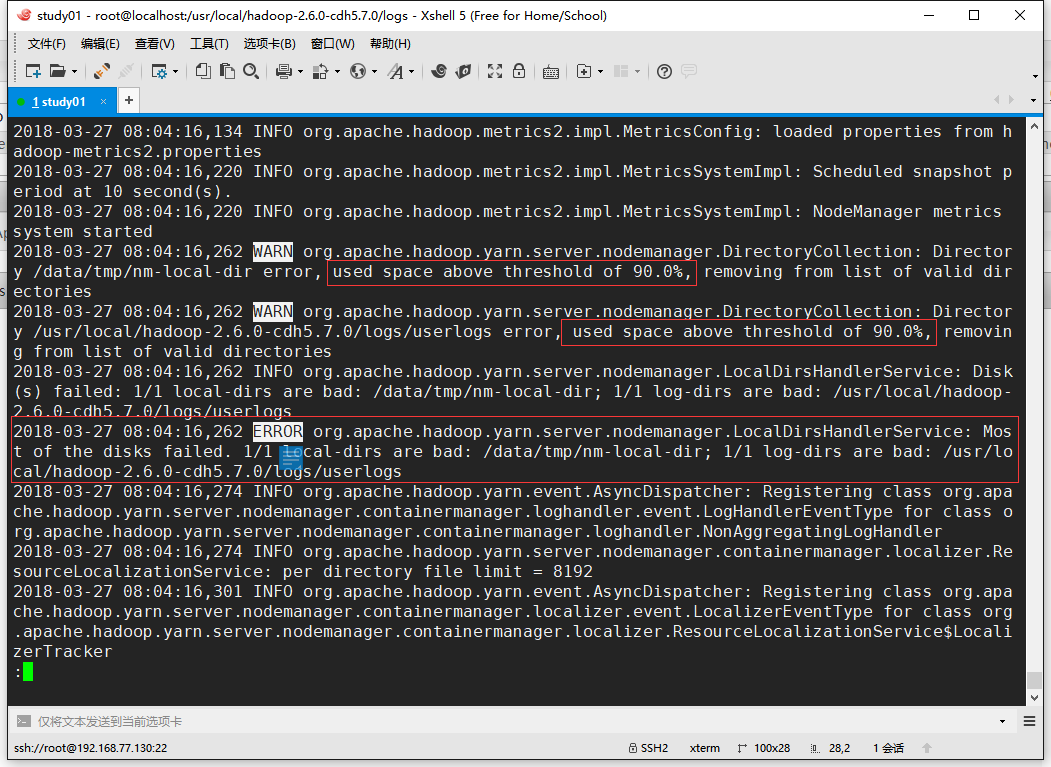
很明显是因为磁盘的使用空间达到了90%,所以我们需要删除一些没有的数据,或者扩容磁盘空间才行。于是删除了一堆安装包,让磁盘空间降低到90%以下了:
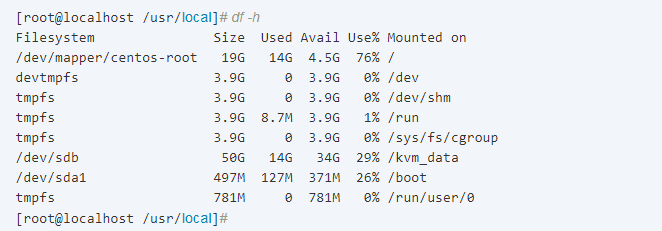
这时再次刷新页面,可以发现这个节点就正常了:
到此为止,我们的yarn环境就搭建完成了。
如果需要关闭进程则使用以下命令:
| [root@localhost
/usr/local/hadoop -2.6.0-cdh5.7.0/sbin] # stop-yarn.sh |
初识提交PI的MapReduce作业到YARN上执行
虽然我们没有搭建MapReduce的环境,但是我们可以使用Hadoop自带的一些测试例子来演示一下如何提交作业到YARN上执行。Hadoop把example的包放在了如下路径,可以看到有好几个jar包:
[root@localhost
~]# cd /usr/local/hadoop-2.6.0 -cdh5.7.0/share/hadoop/mapreduce/
[root@localhost /usr/local/hadoop -2.6.0-cdh5.7.0/share/hadoop/mapreduce]#
ls
hadoop-mapreduce -client-app-2.6.0-cdh5.7.0.jar
hadoop-mapreduce -client-common-2.6.0-cdh5.7.0.jar
hadoop-mapreduce -client-core-2.6.0-cdh5.7.0.jar
hadoop-mapreduce -client-hs-2.6.0-cdh5.7.0.jar
hadoop-mapreduce -client-hs-plugins-2.6.0-cdh5.7.0.jar
hadoop-mapreduce -client-jobclient-2.6.0-cdh5.7.0.jar
hadoop-mapreduce -client-jobclient-2.6.0-cdh5.7.0-tests.jar
hadoop-mapreduce -client-nativetask-2.6.0-cdh5.7.0.jar
hadoop-mapreduce -client-shuffle-2.6.0-cdh5.7.0.jar
hadoop-mapreduce -examples-2.6.0-cdh5.7.0.jar
lib
lib-examples
sources
[root@localhost /usr/local/hadoop -2.6.0-cdh5.7.0/share/hadoop/mapreduce]#
|
在这里我们使用hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar这个jar包来进行演示:
| [root@localhost
/usr/local/hadoop-2.6.0 -cdh5.7.0/share/hadoop/mapreduce]#
hadoop jar hadoop -mapreduce -examples-2.6.0-cdh5.7.0.jar
pi 2 3 |
命令说明:
hadoop jar 执行一个jar包作业的命令
hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar 需要被执行的jar包路径
pi 表示计算圆周率,可以写其他的
末尾的两个数据分别表示指定运行2次map, 以及指定每个map任务取样3次,两数相乘即为总的取样数。
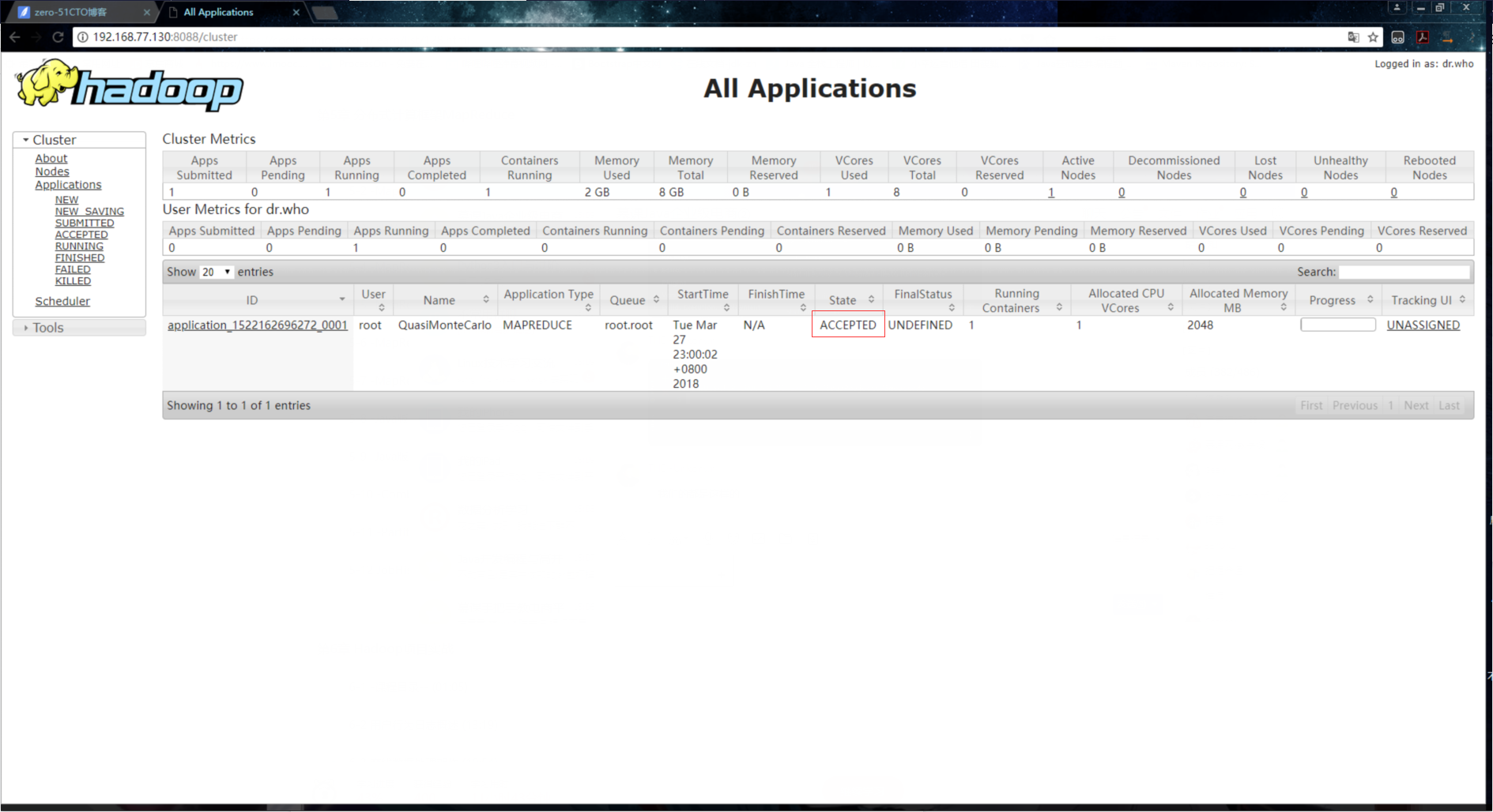
运行以上命令后,到浏览器页面上进行查看,会有以下三个阶段:
1.接收资源,这个阶段就是ApplicationMaster到ResourceManager上申请作业所需要的资源:
2.运行作业,这时候NodeManager就会把task运行在启动的Container里:
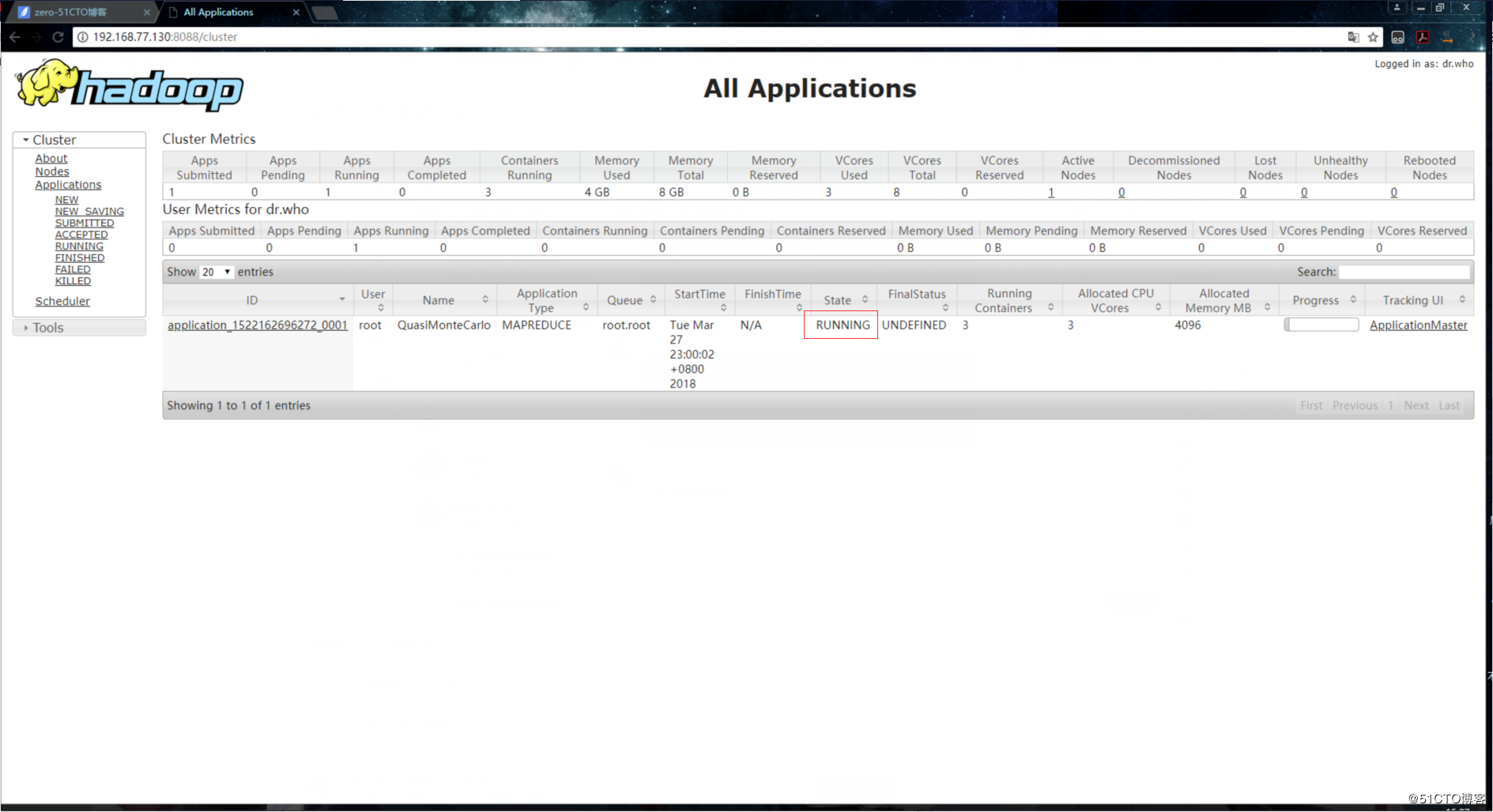
3.作业完成:
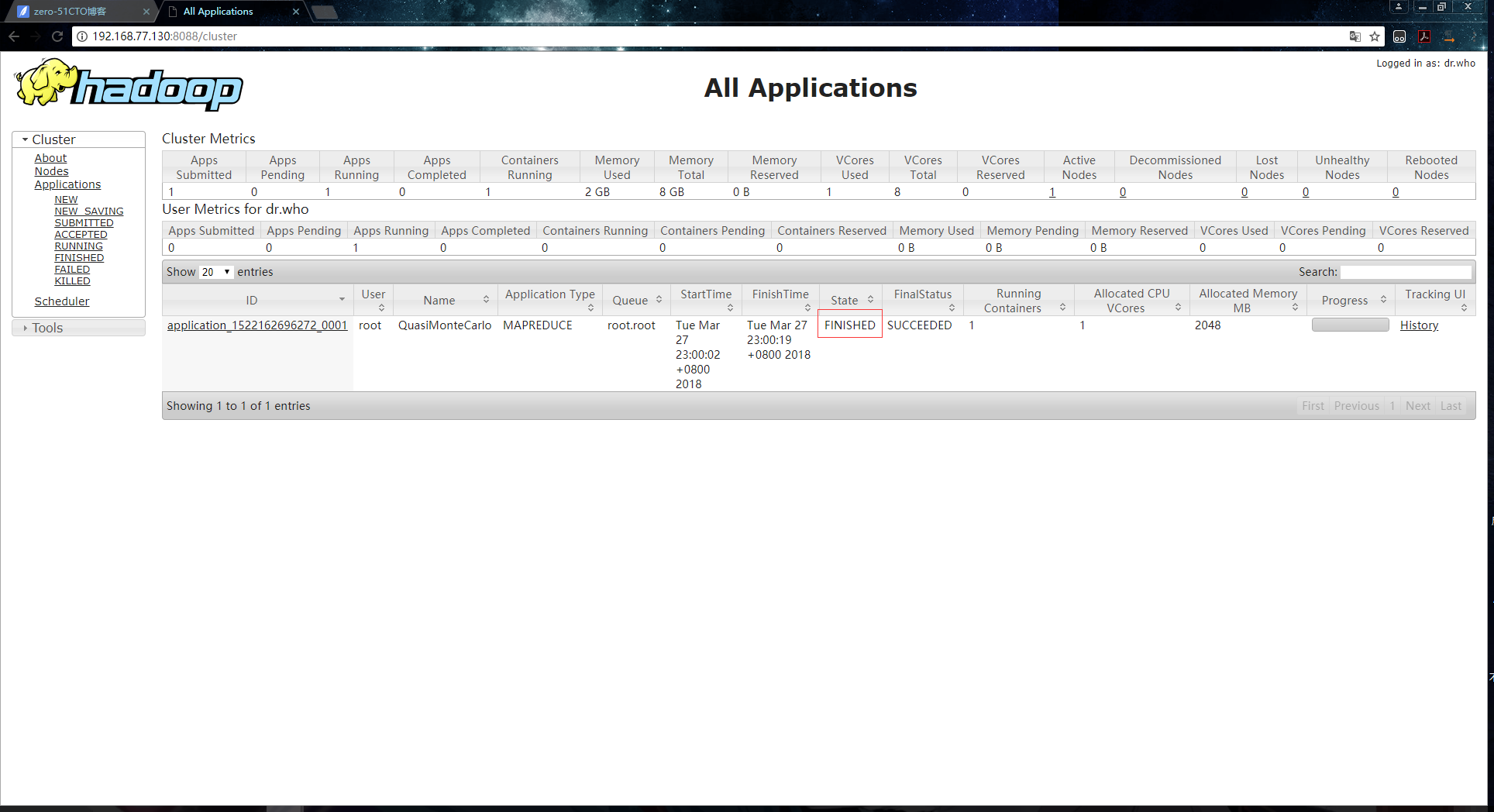
终端输出信息如下:
[root@localhost
/usr/local/hadoop-2.6.0 -cdh5.7.0/share/hadoop/mapreduce] #
hadoop jar hadoop-mapreduce -examples-2.6.0-cdh5.7.0.jar
pi 2 3
Number of Maps = 2
Samples per Map = 3
Wrote input for Map #0
Wrote input for Map #1
Starting Job
18/03/27 23:00:01 INFO client.RMProxy: Connecting
to ResourceManager at /0.0.0.0:8032
18/03/27 23:00:01 INFO input.FileInputFormat:
Total input paths to process : 2
18/03/27 23:00:01 INFO mapreduce.JobSubmitter:
number of splits:2
18/03/27 23:00:02 INFO mapreduce.JobSubmitter:
Submitting tokens for job: job_1522162696272_0001
18/03/27 23:00:02 INFO impl.YarnClientImpl: Submitted
application application_1522162696272_0001
18/03/27 23:00:02 INFO mapreduce.Job: The url
to track the job: http://localhost:8088/proxy/application _1522162696272_0001/
18/03/27 23:00:02 INFO mapreduce.Job: Running
job: job_1522162696272_0001
18/03/27 23:00:10 INFO mapreduce.Job: Job job_1522162696272_0001
running in uber mode : false
18/03/27 23:00:10 INFO mapreduce.Job: map 0% reduce
0%
18/03/27 23:00:15 INFO mapreduce.Job: map 50%
reduce 0%
18/03/27 23:00:16 INFO mapreduce.Job: map 100%
reduce 0%
18/03/27 23:00:19 INFO mapreduce.Job: map 100%
reduce 100%
18/03/27 23:00:20 INFO mapreduce.Job: Job job_1522162696272_0001
completed successfully
18/03/27 23:00:20 INFO mapreduce.Job: Counters:
49
File System Counters
FILE: Number of bytes read=50
FILE: Number of bytes written=335298
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=536
HDFS: Number of bytes written=215
HDFS: Number of read operations=11
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots
(ms)=7108
Total time spent by all reduces in occupied slots
(ms)=2066
Total time spent by all map tasks (ms)=7108
Total time spent by all reduce tasks (ms)=2066
Total vcore-seconds taken by all map tasks=7108
Total vcore-seconds taken by all reduce tasks=2066
Total megabyte-seconds taken by all map tasks=7278592
Total megabyte-seconds taken by all reduce tasks=2115584
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=36
Map output materialized bytes=56
Input split bytes=300
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=56
Reduce input records=4
Reduce output records=0
Spilled Records=8
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=172
CPU time spent (ms)=2990
Physical memory (bytes) snapshot=803618816
Virtual memory (bytes) snapshot=8354324480
Total committed heap usage (bytes)=760217600
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=236
File Output Format Counters
Bytes Written=97
Job Finished in 19.96 seconds
Estimated value of Pi is 4.00000000000000000000
[root@localhost /usr/local/hadoop -2.6.0-cdh5.7.0/share/hadoop/mapreduce]# |
以上这个例子计算了一个PI值,下面我们再来演示一个hadoop中比较经典的例子:wordcount
,这是一个经典的词频统计的例子。首先创建好用于测试的文件:
[root@localhost
~]# mkdir /tmp/input
[root@localhost ~]# cd /tmp/input/
[root@localhost /tmp/input] # echo "hello
word" > file1.txt
[root@localhost /tmp/input] # echo "hello
hadoop" > file2.txt
[root@localhost /tmp/input] # echo "hello
mapreduce" >> file2.txt
[root@localhost /tmp/input] # hdfs dfs -mkdir /wc_input
[root@localhost /tmp/input] # hdfs dfs -put ./file*
/wc_input
[root@localhost /tmp/input] # hdfs dfs -ls /wc_input
Found 2 items
-rw-r--r-- 1 root supergroup
11 2018-03-27 23:11 /wc_input/file1.txt
-rw-r--r-- 1 root supergroup 29
2018-03-27 23:11 /wc_input/file2.txt
[root@localhost /tmp/input]# |
然后执行以下命令:
[root@localhost
/tmp/input] # cd /usr/local/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce
[root@localhost /usr/local/hadoop -2.6.0-cdh5.7.0/share/hadoop/mapreduce]#
hadoop jar ./hadoop-mapreduce -examples-2.6.0-cdh5.7.0.jar
wordcount /wc_input /wc_output |
在yarn页面上显示的阶段信息:
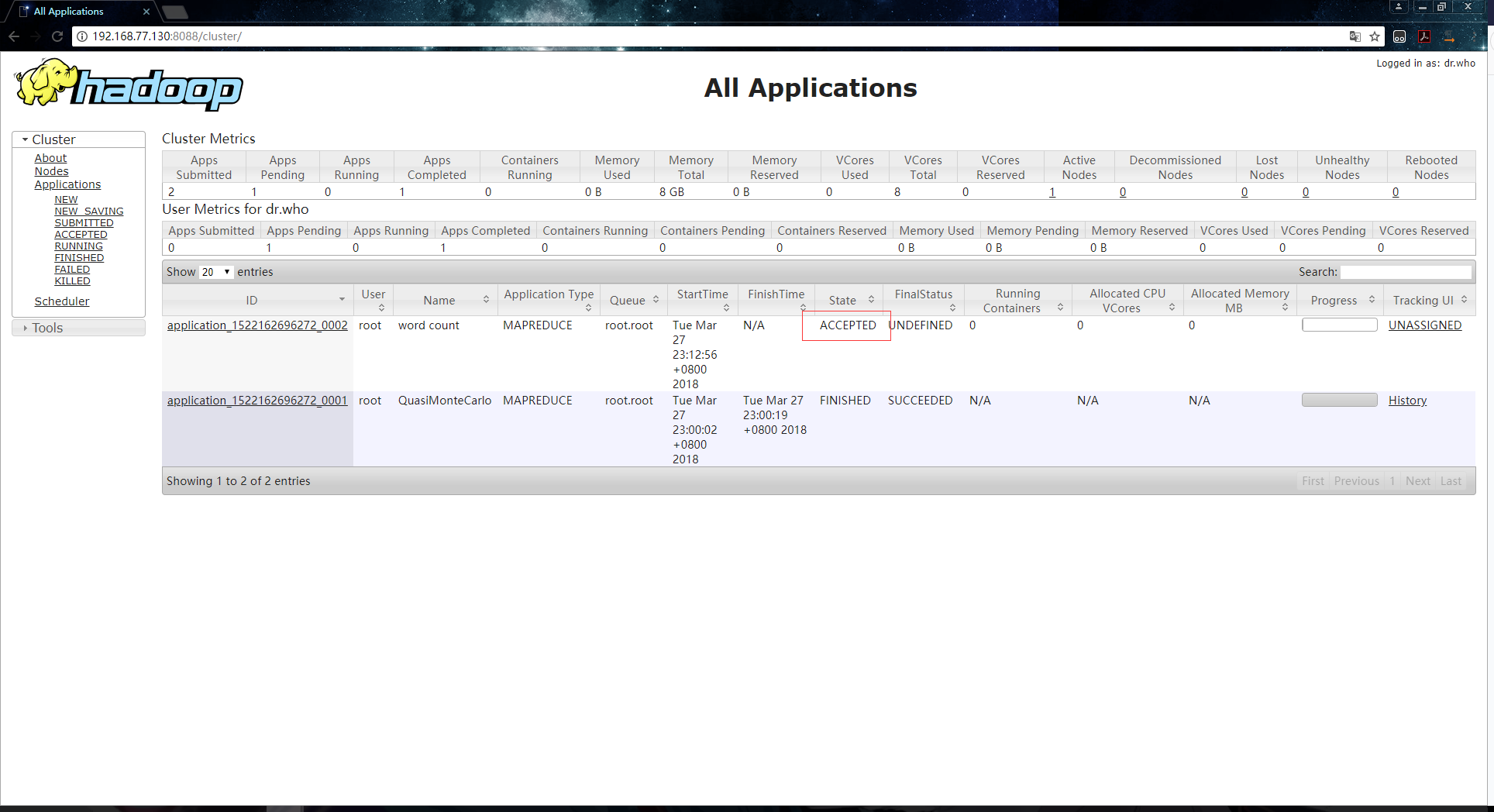
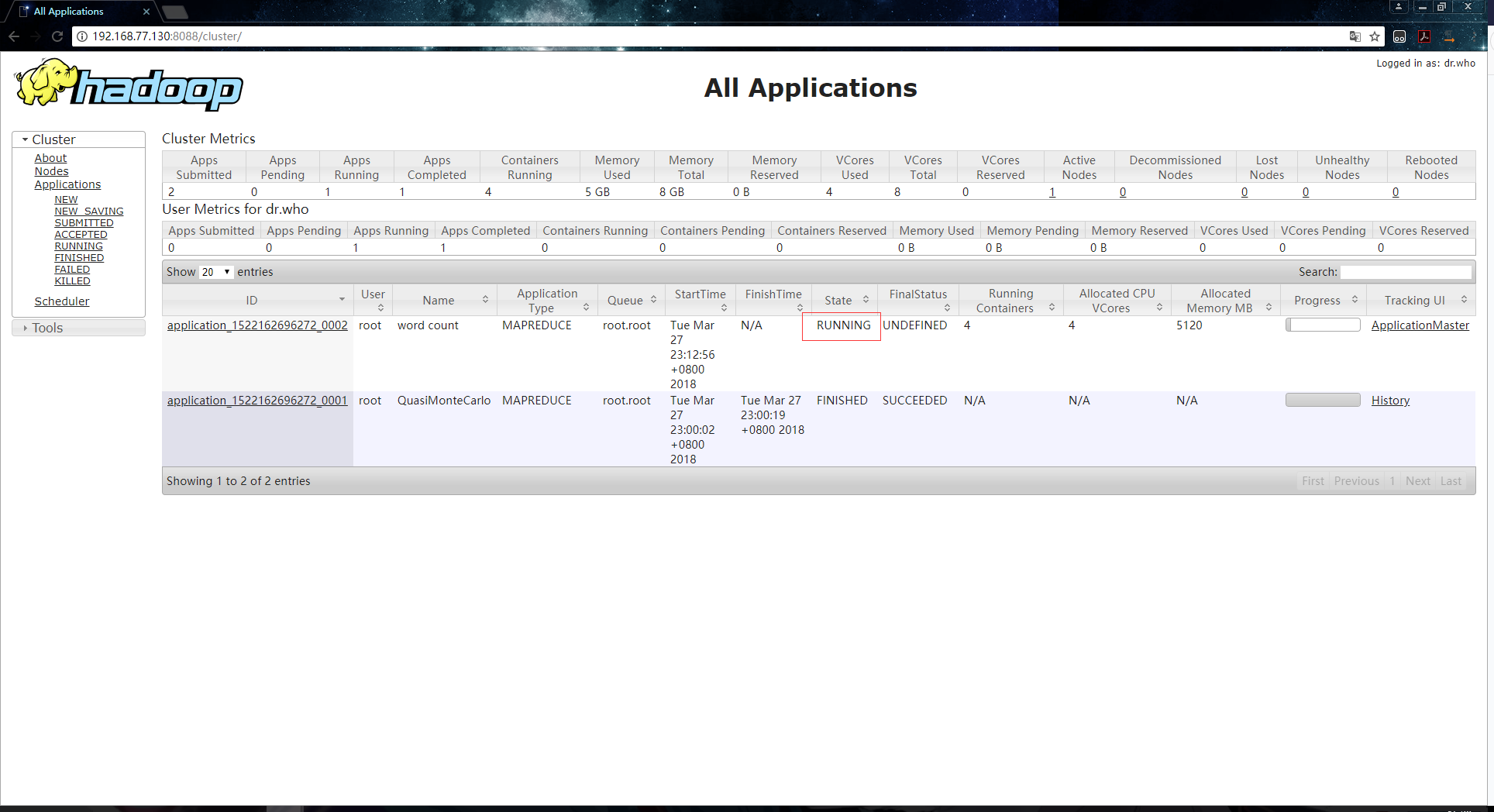
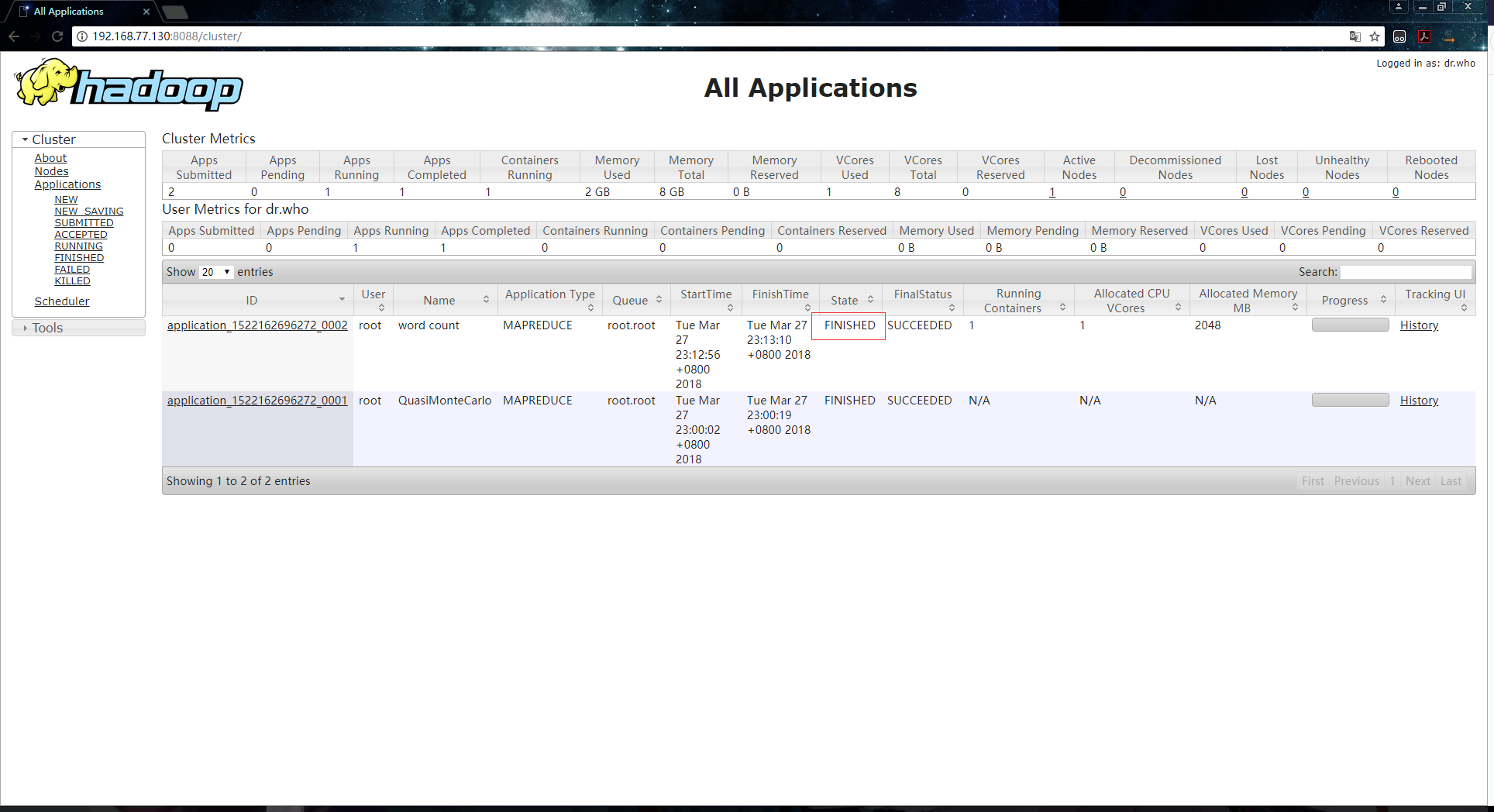
终端输出信息如下:
[root@localhost
/usr/local/hadoop-2.6.0 -cdh5.7.0/share/hadoop/mapreduce] #
hadoop jar ./hadoop-mapreduce -examples-2.6.0-cdh5.7.0.jar
wordcount /wc_input /wc_output
18/03/27 23:12:54 INFO client.RMProxy: Connecting
to ResourceManager at /0.0.0.0:8032
18/03/27 23:12:55 INFO input.FileInputFormat:
Total input paths to process : 2
18/03/27 23:12:55 INFO mapreduce.JobSubmitter:
number of splits:2
18/03/27 23:12:55 INFO mapreduce.JobSubmitter:
Submitting tokens for job: job_1522162696272_0002
18/03/27 23:12:56 INFO impl.YarnClientImpl: Submitted
application application_1522162696272_0002
18/03/27 23:12:56 INFO mapreduce.Job: The url
to track the job: http://localhost:8088/proxy/application_1522162696272_0002/
18/03/27 23:12:56 INFO mapreduce.Job: Running
job: job_1522162696272_0002
18/03/27 23:13:02 INFO mapreduce.Job: Job job_1522162696272_0002
running in uber mode : false
18/03/27 23:13:02 INFO mapreduce.Job: map 0% reduce
0%
18/03/27 23:13:06 INFO mapreduce.Job: map 50%
reduce 0%
18/03/27 23:13:07 INFO mapreduce.Job: map 100%
reduce 0%
18/03/27 23:13:11 INFO mapreduce.Job: map 100%
reduce 100%
18/03/27 23:13:12 INFO mapreduce.Job: Job job_1522162696272_0002
completed successfully
18/03/27 23:13:12 INFO mapreduce.Job: Counters:
49
File System Counters
FILE: Number of bytes read=70
FILE: Number of bytes written=334375
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=260
HDFS: Number of bytes written=36
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots
(ms)=5822
Total time spent by all reduces in occupied slots
(ms)=1992
Total time spent by all map tasks (ms)=5822
Total time spent by all reduce tasks (ms)=1992
Total vcore-seconds taken by all map tasks=5822
Total vcore-seconds taken by all reduce tasks=1992
Total megabyte-seconds taken by all map tasks=5961728
Total megabyte-seconds taken by all reduce tasks=2039808
Map-Reduce Framework
Map input records=3
Map output records=6
Map output bytes=64
Map output materialized bytes=76
Input split bytes=220
Combine input records=6
Combine output records=5
Reduce input groups=4
Reduce shuffle bytes=76
Reduce input records=5
Reduce output records=4
Spilled Records=10
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=157
CPU time spent (ms)=2290
Physical memory (bytes) snapshot=800239616
Virtual memory (bytes) snapshot=8352272384
Total committed heap usage (bytes)=762314752
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=40
File Output Format Counters
Bytes Written=36
[root@localhost /usr/local/hadoop -2.6.0-cdh5.7.0/share/hadoop/mapreduce] #
|
查看输出的结果文件:
[root@localhost
/usr/local/hadoop -2.6.0- cdh5.7.0/share/hadoop/mapreduce]#
hdfs dfs -ls /wc_output
Found 2 items
-rw-r--r-- 1 root supergroup 0 2018-03-27 23:13
/wc_output/_SUCCESS
-rw-r--r-- 1 root supergroup
36 2018-03-27 23:13
/wc_output/part-r-00000
[root@localhost /usr/local/hadoop-2.6.0 -cdh5.7.0/share/hadoop/mapreduce]#
hdfs dfs -cat /wc_output/part -r-00000 # 实际输出结果在part-r-00000中
hadoop 1
hello 3
mapreduce 1
word 1
[root@localhost /usr/local/hadoop -2.6.0-cdh5.7.0/share/hadoop/mapreduce]# |
为了更好的查看代码请查看电脑版 |









