| БрМЭЦМі: |
| БОЮФРДздгкmamicodeЃЌБОЮФНщЩмСЫFlinkЕФИХФюЃЌFlinkЫљжЇГжЕФЬиадЃЌFlinkЕФШ§жжВПЪ№ФЃвдМАFlinkПЊЗЂБъзМСїГЬЕШЯрЙиФкШнЁЃ |
|
1. FlinkЕФв§Шы
етМИФъДѓЪ§ОнЕФЗЩЫйЗЂеЙЃЌГіЯжСЫКмЖрШШУХЕФПЊдДЩчЧјЃЌЦфжажјУћЕФга HadoopЁЂStormЃЌвдМАКѓРДЕФ
SparkЃЌЫћУЧЖМгазХИїздзЈзЂЕФгІгУГЁОАЁЃSpark ЯЦПЊСЫФкДцМЦЫуЕФЯШКгЃЌвВвдФкДцЮЊЖФзЂЃЌгЎЕУСЫФкДцМЦЫуЕФЗЩЫйЗЂеЙЁЃSpark
ЕФЛ№ШШЛђЖрЛђЩйЕФбкИЧСЫЦфЫћЗжВМЪНМЦЫуЕФЯЕЭГЩэгАЁЃОЭЯё FlinkЃЌвВОЭдкетИіЪБКђФЌФЌЕФЗЂеЙзХЁЃ
дкЙњЭтвЛаЉЩчЧјЃЌгаКмЖрШЫНЋДѓЪ§ОнЕФМЦЫув§ЧцЗжГЩСЫ 4 ДњЃЌЕБШЛЃЌвВгаКмЖрШЫВЛЛсШЯЭЌЁЃЮвУЧЯШЙУЧветУДШЯЮЊКЭЬжТлЁЃ
ЪзЯШЕквЛДњЕФМЦЫув§ЧцЃЌЮовЩОЭЪЧ Hadoop ГадиЕФ MapReduceЁЃетРяДѓМвгІИУЖМВЛЛсЖд MapReduce
ФАЩњЃЌЫќНЋМЦЫуЗжЮЊСНИіНзЖЮЃЌЗжБ№ЮЊ Map КЭ ReduceЁЃЖдгкЩЯВугІгУРДЫЕЃЌОЭВЛЕУВЛЯыЗНЩшЗЈШЅВ№ЗжЫуЗЈЃЌЩѕжСгкВЛЕУВЛдкЩЯВугІгУЪЕЯжЖрИі
Job ЕФДЎСЊЃЌвдЭъГЩвЛИіЭъећЕФЫуЗЈЃЌР§ШчЕќДњМЦЫуЁЃ
гЩгкетбљЕФБзЖЫЃЌДпЩњСЫжЇГж DAG ПђМмЕФВњЩњЁЃвђДЫЃЌжЇГж DAG ЕФПђМмБЛЛЎЗжЮЊЕкЖўДњМЦЫув§ЧцЁЃШч
Tez вдМАИќЩЯВуЕФ OozieЁЃетРяЮвУЧВЛШЅЯИОПИїжж DAG ЪЕЯжжЎМфЕФЧјБ№ЃЌВЛЙ§ЖдгкЕБЪБЕФ Tez
КЭ Oozie РДЫЕЃЌДѓЖрЛЙЪЧХњДІРэЕФШЮЮёЁЃ
НгЯТРДОЭЪЧвд Spark ЮЊДњБэЕФЕкШ§ДњЕФМЦЫув§ЧцЁЃЕкШ§ДњМЦЫув§ЧцЕФЬиЕужївЊЪЧ Job ФкВПЕФ DAG
жЇГжЃЈВЛПчдН JobЃЉЃЌвдМАЧПЕїЕФЪЕЪБМЦЫуЁЃдкетРяЃЌКмЖрШЫвВЛсШЯЮЊЕкШ§ДњМЦЫув§ЧцвВФмЙЛКмКУЕФдЫааХњДІРэЕФ
JobЁЃ
ЫцзХЕкШ§ДњМЦЫув§ЧцЕФГіЯжЃЌДйНјСЫЩЯВугІгУПьЫйЗЂеЙЃЌР§ШчИїжжЕќДњМЦЫуЕФадФмвдМАЖдСїМЦЫуКЭ SQL ЕШЕФжЇГжЁЃFlink
ЕФЕЎЩњОЭБЛЙщдкСЫЕкЫФДњЁЃетгІИУжївЊБэЯждк Flink ЖдСїМЦЫуЕФжЇГжЃЌвдМАИќвЛВНЕФЪЕЪБадЩЯУцЁЃЕБШЛ
Flink вВПЩвджЇГж Batch ЕФШЮЮёЃЌвдМА DAG ЕФдЫЫуЁЃ
ЪзЯШЃЌЮвУЧПЩвдЭЈЙ§ЯТУцЕФадФмВтЪдГѕВНСЫНтСНИіПђМмЕФадФмЧјБ№ЃЌЫќУЧЖМПЩвдЛљгкФкДцМЦЫуПђМмНјааЪЕЪБМЦЫуЃЌЫљвдЖМгЕгаЗЧГЃКУЕФМЦЫуадФмЁЃОЙ§ВтЪдЃЌFlinkМЦЫуадФмЩЯТдКУЁЃ
ВтЪдЛЗОГЃК
1.CPUЃК7000ИіЃЛ
2.ФкДцЃКЕЅЛњ128GBЃЛ
3.АцБОЃКHadoop 2.3.0ЃЌSpark 1.4ЃЌFlink 0.9
4.Ъ§ОнЃК800MBЃЌ8GBЃЌ8TBЃЛ
5.ЫуЗЈЃКK-meansЃКвдПеМфжаKИіЕуЮЊжааФНјааОлРрЃЌЖдзюППНќЫќУЧЕФЖдЯѓЙщРрЁЃЭЈЙ§ЕќДњЕФЗНЗЈЃЌж№ДЮИќаТИїОлРржааФЕФжЕЃЌжБжСЕУЕНзюКУЕФОлРрНсЙћЁЃ
6.ЕќДњЃКK=10ЃЌ3зщЪ§Он
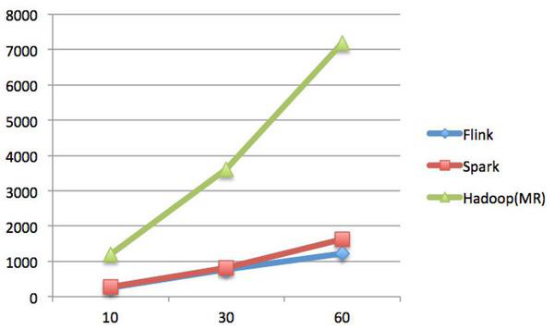
ЕќДњДЮЪ§ЃЈзнзјБъЪЧУыЃЌКсзјБъЪЧДЮЪ§ЃЉ
SparkКЭFlinkШЋВПЖМдЫаадкHadoop YARNЩЯЃЌадФмЮЊFlink > Spark
> Hadoop(MR)ЃЌЕќДњДЮЪ§дНЖрдНУїЯдЃЌадФмЩЯЃЌFlinkгХгкSparkКЭHadoopзюжївЊЕФдвђЪЧFlinkжЇГждіСПЕќДњЃЌОпгаЖдЕќДњздЖЏгХЛЏЕФЙІФмЁЃ
2. FlinkМђНщ
КмЖрШЫПЩФмЖМЪЧдк 2015 ФъВХЬ§ЕН Flink етИіДЪЃЌЦфЪЕдчдк 2008 ФъЃЌFlink ЕФЧАЩэвбОЪЧАиСжРэЙЄДѓбЇвЛИібаОПадЯюФПЃЌ
дк 2014 БЛ Apache ЗѕЛЏЦїЫљНгЪмЃЌШЛКѓбИЫйЕиГЩЮЊСЫ ASFЃЈApache Software
FoundationЃЉЕФЖЅМЖЯюФПжЎвЛЁЃFlink ЕФзюаТАцБОФПЧАвбОИќаТЕНСЫ 0.10.0 СЫЃЌдкКмЖрШЫИаПЎ
Spark ЕФПьЫйЗЂеЙЕФЭЌЪБЃЌЛђаэЮвУЧвВИУЮЊ Flink ЕФЗЂеЙЫйЖШЕуИідоЁЃ
Flink ЪЧвЛИіеыЖдСїЪ§ОнКЭХњЪ§ОнЕФЗжВМЪНДІРэв§ЧцЁЃЫќжївЊЪЧгЩ Java ДњТыЪЕЯжЁЃФПЧАжївЊЛЙЪЧвРПППЊдДЩчЧјЕФЙБЯзЖјЗЂеЙЁЃЖд
Flink ЖјбдЃЌЦфЫљвЊДІРэЕФжївЊГЁОАОЭЪЧСїЪ§ОнЃЌХњЪ§ОнжЛЪЧСїЪ§ОнЕФвЛИіМЋЯоЬиР§ЖјвбЁЃдйЛЛОфЛАЫЕЃЌFlink
ЛсАбЫљгаШЮЮёЕБГЩСїРДДІРэЃЌетвВЪЧЦфзюДѓЕФЬиЕуЁЃ
Flink ПЩвджЇГжБОЕиЕФПьЫйЕќДњЃЌвдМАвЛаЉЛЗаЮЕФЕќДњШЮЮёЁЃВЂЧв Flink ПЩвдЖЈжЦЛЏФкДцЙмРэЁЃдкетЕуЃЌШчЙћвЊЖдБШ
Flink КЭ Spark ЕФЛАЃЌFlink ВЂУЛгаНЋФкДцЭъШЋНЛИјгІгУВуЁЃетвВЪЧЮЊЪВУД Spark
ЯрЖдгк FlinkЃЌИќШнвзГіЯж OOM ЕФдвђЃЈout of memoryЃЉЁЃОЭПђМмБОЩэгыгІгУГЁОАРДЫЕЃЌFlink
ИќЯрЫЦгы StormЁЃШчЙћжЎЧАСЫНтЙ§ Storm Лђеп Flume ЕФЖСепЃЌПЩФмЛсИќШнвзРэНт Flink
ЕФМмЙЙКЭКмЖрИХФюЁЃЯТУцШУЮвУЧЯШРДПДЯТ Flink ЕФМмЙЙЭМЁЃ
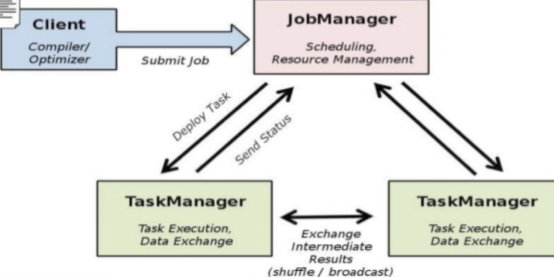
ЮвУЧПЩвдСЫНтЕН Flink МИИізюЛљДЁЕФИХФюЃЌClientЁЂJobManager КЭ TaskManagerЁЃClient
гУРДЬсНЛШЮЮёИј JobManagerЃЌJobManager ЗжЗЂШЮЮёИј TaskManager ШЅжДааЃЌШЛКѓ
TaskManager ЛсаФЬјЕФЛуБЈШЮЮёзДЬЌЁЃПДЕНетРяЃЌгаЕФШЫгІИУвбОгажжЛиЕН Hadoop вЛДњЕФДэОѕЁЃШЗЪЕЃЌДгМмЙЙЭМШЅПДЃЌJobManager
КмЯёЕБФъЕФ JobTrackerЃЌTaskManager вВКмЯёЕБФъЕФ TaskTrackerЁЃШЛЖјгавЛИізюживЊЕФЧјБ№ОЭЪЧ
TaskManager жЎМфЪЧЪЧСїЃЈStreamЃЉЁЃЦфДЮЃЌHadoop вЛДњжаЃЌжЛга Map КЭ Reduce
жЎМфЕФ ShuffleЃЌЖјЖд Flink ЖјбдЃЌПЩФмЪЧКмЖрМЖЃЌВЂЧвдк TaskManager ФкВПКЭ
TaskManager жЎМфЖМЛсгаЪ§ОнДЋЕнЃЌЖјВЛЯё HadoopЃЌЪЧЙЬЖЈЕФ Map ЕН ReduceЁЃ
3. ММЪѕЕФЬиЕуЃЈПЩбЁЃЉ
ЙигкFlinkЫљжЇГжЕФЬиадЃЌЮветРяжЛЪЧЭЈЙ§ЗжРрЕФЗНЪНМђЕЅзівЛЯТЪсРэЃЌЩцМАЕНОпЬхЕФвЛаЉИХФюМАЦфдРэЛсдкКѓУцЕФВПЗжзіЯъЯИЫЕУїЁЃ
3.1. СїДІРэЬиад
жЇГжИпЭЬЭТЁЂЕЭбгГйЁЂИпадФмЕФСїДІРэ
жЇГжДјгаЪТМўЪБМфЕФДАПкЃЈWindowЃЉВйзї
жЇГжгазДЬЌМЦЫуЕФExactly-onceгявх
жЇГжИпЖШСщЛюЕФДАПкЃЈWindowЃЉВйзїЃЌжЇГжЛљгкtimeЁЂcountЁЂsessionЃЌвдМАdata-drivenЕФДАПкВйзї
жЇГжОпгаBackpressureЙІФмЕФГжајСїФЃаЭ
жЇГжЛљгкЧсСПМЖЗжВМЪНПьееЃЈSnapshotЃЉЪЕЯжЕФШнДэ
вЛИідЫааЪБЭЌЪБжЇГжBatch on StreamingДІРэКЭStreamingДІРэ
FlinkдкJVMФкВПЪЕЯжСЫздМКЕФФкДцЙмРэ
жЇГжЕќДњМЦЫу
жЇГжГЬађздЖЏгХЛЏЃКБмУтЬиЖЈЧщПіЯТShuffleЁЂХХађЕШАКЙѓВйзїЃЌжаМфНсЙћгаБивЊНјааЛКДц
3.2. APIжЇГж
ЖдStreamingЪ§ОнРргІгУЃЌЬсЙЉDataStream API
ЖдХњДІРэРргІгУЃЌЬсЙЉDataSet APIЃЈжЇГжJava/ScalaЃЉ
3.3. LibrariesжЇГж
жЇГжЛњЦїбЇЯАЃЈFlinkMLЃЉ
жЇГжЭМЗжЮіЃЈGellyЃЉ
жЇГжЙиЯЕЪ§ОнДІРэЃЈTableЃЉ
жЇГжИДдгЪТМўДІРэЃЈCEPЃЉ
3.4. ећКЯжЇГж
жЇГжFlink on YARN
жЇГжHDFS
жЇГжРДздKafkaЕФЪфШыЪ§Он
жЇГжApache HBase
жЇГжHadoopГЬађ
жЇГжTachyon
жЇГжElasticSearch
жЇГжRabbitMQ
жЇГжApache Storm
жЇГжS3
жЇГжXtreemFS
3.5. FlinkЩњЬЌШІ
вЛИіМЦЫуПђМмвЊгаГЄдЖЕФЗЂеЙЃЌБиаыДђдьвЛИіЭъећЕФ StackЁЃВЛШЛОЭИњжНЩЯЬИБјвЛбљЃЌУЛгаШЮКЮвтвхЁЃжЛгаЩЯВугаСЫОпЬхЕФгІгУЃЌВЂФмКмКУЕФЗЂЛгМЦЫуПђМмБОЩэЕФгХЪЦЃЌФЧУДетИіМЦЫуПђМмВХФмЮќв§ИќЖрЕФзЪдДЃЌВХЛсИќПьЕФНјВНЁЃЫљвд
Flink вВдкХЌСІЙЙНЈздМКЕФ StackЁЃ
Flink ЪзЯШжЇГжСЫ Scala КЭ Java ЕФ APIЃЌPython вВе§дкВтЪджаЁЃFlink
ЭЈЙ§ Gelly жЇГжСЫЭМВйзїЃЌЛЙгаЛњЦїбЇЯАЕФ FlinkMLЁЃTable ЪЧвЛжжНгПкЛЏЕФ SQL
жЇГжЃЌвВОЭЪЧ API жЇГжЃЌЖјВЛЪЧЮФБОЛЏЕФ SQL НтЮіКЭжДааЁЃЖдгкЭъећЕФ Stack ЮвУЧПЩвдВЮПМЯТЭМЁЃ
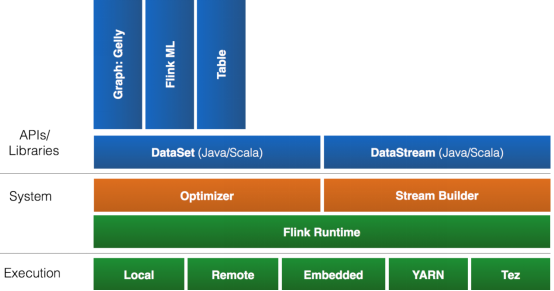
Flink ЮЊСЫИќЙуЗКЕФжЇГжДѓЪ§ОнЕФЩњЬЌШІЃЌЦфЯТвВЪЕЯжСЫКмЖр Connector ЕФзгЯюФПЁЃзюЪьЯЄЕФЃЌЕБШЛОЭЪЧгы
Hadoop HDFS МЏГЩЁЃЦфДЮЃЌFlink вВаћВМжЇГжСЫ TachyonЁЂS3 вдМА MapRFSЁЃВЛЙ§Ждгк
Tachyon вдМА S3 ЕФжЇГжЃЌЖМЪЧЭЈЙ§ Hadoop HDFS етВуАќзАЪЕЯжЕФЃЌвВОЭЪЧЫЕвЊЪЙгУ
Tachyon КЭ S3ЃЌОЭБиаыга HadoopЃЌЖјЧввЊИќИФ Hadoop ЕФХфжУЃЈcore-site.xmlЃЉЁЃШчЙћфЏРР
Flink ЕФДњТыФПТМЃЌЮвУЧОЭЛсПДЕНИќЖр Connector ЯюФПЃЌР§Шч Flume КЭ KafkaЁЃ
4. АВзА
Flink гаШ§жжВПЪ№ФЃЪНЃЌЗжБ№ЪЧ LocalЁЂStandalone Cluster КЭ Yarn
ClusterЁЃ
4.1. LocalФЃЪН
Ждгк Local ФЃЪНРДЫЕЃЌJobManager КЭ TaskManager ЛсЙЋгУвЛИі JVM РДЭъГЩ
WorkloadЁЃШчЙћвЊбщжЄвЛИіМђЕЅЕФгІгУЃЌLocal ФЃЪНЪЧзюЗНБуЕФЁЃЪЕМЪгІгУжаДѓЖрЪЙгУ Standalone
Лђеп Yarn ClusterЃЌЖјlocalФЃЪНжЛЪЧНЋАВзААќНтбЙЦєЖЏЃЈ./bin/start-local.shЃЉМДПЩЃЌдкетРяВЛдкбнЪОЁЃ
4.2. Standalone ФЃЪН
4.2.1. ЯТди
АВзААќЯТдиЕижЗЃКhttp://flink.apache.org/downloads.html
ПьЫйШыУХНЬГЬЕижЗЃК
https://ci.apache.org/projects/flink/flink-docs-release-1.3/quickstart/setup_quickstart.html
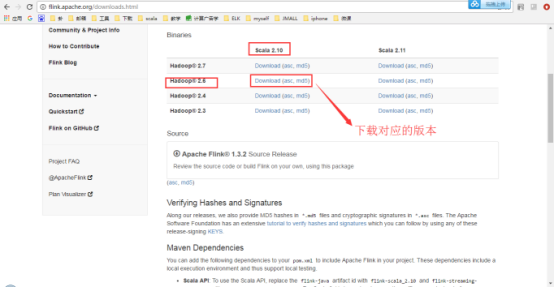
4.2.2. ЩЯДЋАВзААќЕНlinuxЯЕЭГ
ЪЙгУrzУќСю
4.2.3. НтбЙ
tar ЈCzxvf flink-1.3.2-bin-hadoop26-scala_2.10.tgz
4.2.4. жиУќУћ
mv flink-1.3.2 flink
4.2.5. аоИФЛЗОГБфСП
ЧаЛЛЕНrootгУЛЇХфжУ
export FLINK_HOME=/home/hadoop/flink
export PATH=$PATH:$FLINK_HOME/bin
ХфжУНсЪјКѓЧаЛЛЛсЦеЭЈгУЛЇ
source /etc/profile |
4.2.6. аоИФХфжУЮФМў
аоИФflink/conf/masters
master1:8081
аоИФflink/conf/slaves
master1ha
master2
master2ha
аоИФflink/conf/flink-conf.yaml
taskmanager.numberOfTaskSlots: 2
jobmanager.rpc.address: master1 |
4.2.7. ЦєЖЏflink
/home/Hadoop/flink/bin/start-cluster.sh
4.2.8. Flink ЕФ Rest API
Flink КЭЦфЫћДѓЖрПЊдДЕФПђМмвЛбљЃЌЬсЙЉСЫКмЖргагУЕФ Rest APIЁЃВЛЙ§ Flink ЕФ RestAPIЃЌФПЧАЛЙВЛЪЧКмЧПДѓЃЌжЛФмжЇГжвЛаЉ
Monitor ЕФЙІФмЁЃFlink Dashboard БОЩэвВЪЧЭЈЙ§Цф Rest РДВщбЏИїЯюЕФНсЙћЪ§ОнЁЃдк
Flink RestAPI ЛљДЁЩЯЃЌПЩвдБШНЯШнвзЕФНЋ Flink ЕФ Monitor ЙІФмКЭЦфЫћЕкШ§ЗНЙЄОпЯрМЏГЩЃЌетвВЪЧЦфЩшМЦЕФГѕждЁЃ
дк Flink ЕФНјГЬжаЃЌЪЧгЩ JobManager РДЬсЙЉ Rest API ЕФЗўЮёЁЃвђДЫдкЕїгУ
Rest жЎЧАЃЌвЊШЗЖЈ JobManager ЪЧЗёДІгке§ГЃЕФзДЬЌЁЃе§ГЃЧщПіЯТЃЌдкЗЂЫЭвЛИі Rest
ЧыЧѓИј JobManager жЎКѓЃЌClient ОЭЛсЪеЕНвЛИі JSON ИёЪНЕФЗЕЛиНсЙћЁЃгЩгкФПЧА
Rest ЬсЙЉЕФЙІФмЛЙВЛЖрЃЌашвЊдіЧПетПщЙІФмЕФЖСепПЩвддкзгЯюФП flink-runtime-web
жаевЕНЖдгІЕФДњТыЁЃЦфжазюЙиМќвЛИіРр WebRuntimeMonitorЃЌОЭЪЧгУРДЖдЫљгаЕФ Rest
ЧыЧѓзіЗжСїЕФЃЌШчЙћашвЊЬэМгвЛИіаТРраЭЕФЧыЧѓЃЌОЭашвЊдкетРядіМгЖдгІЕФДІРэДњТыЁЃЯТУцЮвР§ОйМИИіГЃгУ Rest
APIЁЃ
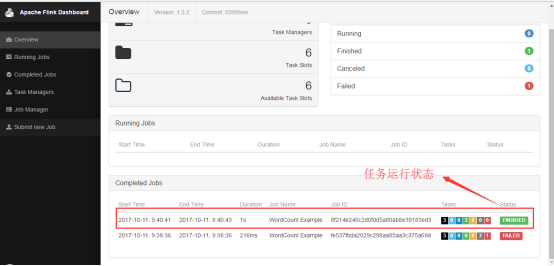
1.ВщбЏ Flink МЏШКЕФЛљБОаХЯЂ: /overviewЁЃЪОР§УќСюааИёЪНвдМАЗЕЛиНсЙћШчЯТЃК
$ curl http://localhost:8081/overview
{"taskmanagers":1,"slots-total":16,
"slots-available":16,"jobs-running":0,"jobs-finished":0,"jobs-cancelled":0,"jobs-failed":0} |
2.ВщбЏЕБЧА Flink МЏШКжаЕФ Job аХЯЂЃК/jobsЁЃЪОР§УќСюааИёЪНвдМАЗЕЛиНсЙћШчЯТЃК
$ curl http://localhost:8081/jobs
{"jobs-running":[],"jobs-finished":
["f91d4dd4fdf99313d849c9c4d29f8977"],"jobs-cancelled":[],"jobs-failed":[]} |
3.ВщбЏвЛИіжИЖЈЕФ Job аХЯЂ: /jobs/jobidЁЃетИіВщбЏЕФНсЙћЛсЗЕЛиЬиБ№ЖрЕФЯъЯИЕФФкШнЃЌетЪЧЮвдкфЏРРЦїжаНјааЕФВтЪдЃЌШчЯТЭМЃК
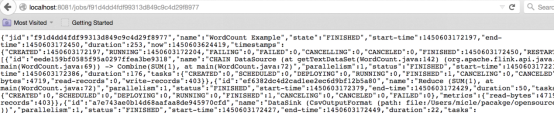
ЯывЊСЫНтИќЖр Rest ЧыЧѓФкШнЕФЖСепЃЌПЩвдШЅ Apache Flink ЕФвГУцжаВщевЁЃ
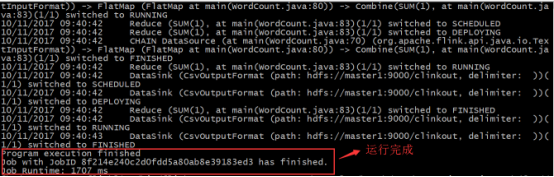
4.2.9. дЫааВтЪдШЮЮё
| ./bin/flink
run -m master1:8082 ./examples/batch/WordCount.jar
--input hdfs://master1:9000/words.txt --output
hdfs://master1:9000/clinkout |
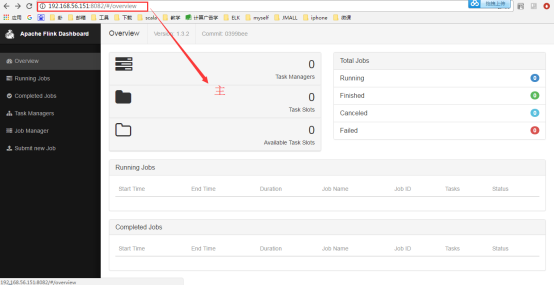
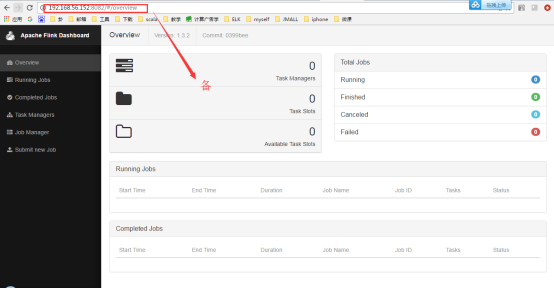
4.3. Flink ЕФ HA
ЪзЯШЃЌЮвУЧашвЊжЊЕР Flink гаСНжжВПЪ№ЕФФЃЪНЃЌЗжБ№ЪЧ Standalone вдМА Yarn Cluster
ФЃЪНЁЃЖдгк Standalone РДЫЕЃЌFlink БиаывРРЕгк Zookeeper РДЪЕЯж JobManager
ЕФ HAЃЈZookeeper вбОГЩЮЊСЫДѓВПЗжПЊдДПђМм HA БиВЛПЩЩйЕФФЃПщЃЉЁЃдк Zookeeper
ЕФАяжњЯТЃЌвЛИі Standalone ЕФ Flink МЏШКЛсЭЌЪБгаЖрИіЛюзХЕФ JobManagerЃЌЦфжажЛгавЛИіДІгкЙЄзїзДЬЌЃЌЦфЫћДІгк
Standby зДЬЌЁЃЕБЙЄзїжаЕФ JobManager ЪЇШЅСЌНгКѓЃЈШчхДЛњЛђ CrashЃЉЃЌZookeeper
ЛсДг Standby жабЁОйаТЕФ JobManager РДНгЙм Flink МЏШКЁЃ
Ждгк Yarn Cluaster ФЃЪНРДЫЕЃЌFlink ОЭвЊвРПП Yarn БОЩэРДЖд JobManager
зі HA СЫЁЃЦфЪЕетРяЭъШЋЪЧ Yarn ЕФЛњжЦЁЃЖдгк Yarn Cluster ФЃЪНРДЫЕЃЌJobManager
КЭ TaskManager ЖМЪЧБЛ Yarn ЦєЖЏдк Yarn ЕФ Container жаЁЃДЫЪБЕФ
JobManagerЃЌЦфЪЕгІИУГЦжЎЮЊ Flink Application MasterЁЃвВОЭЫЕЫќЕФЙЪеЯЛжИДЃЌОЭЭъШЋвРППзХ
Yarn жаЕФ ResourceManagerЃЈКЭ MapReduce ЕФ AppMaster вЛбљЃЉЁЃгЩгкЭъШЋвРРЕСЫ
YarnЃЌвђДЫВЛЭЌАцБОЕФ Yarn ПЩФмЛсгаЯИЮЂЕФВювьЁЃетРяВЛдйзіЩюОПЁЃ
4.3.1. аоИФХфжУЮФМў
аоИФflink-conf.yaml
state.backend:
filesystem
state.backend.fs.checkpointdir: hdfs://master1:9000/flink-checkpoints
high-availability: zookeeper
high-availability.storageDir: hdfs://master1:9000/flink/ha/
high-availability.zookeeper.quorum: master1ha:2181,master2:2181,master2ha:2181
high-availability.zookeeper.client.acl: openЁЁ |
аоИФconf
server.1=master1ha:2888:3888
server.2=master2:2888:3888
server.3=master2ha:2888:3888 |
аоИФmasters
master1:8082
master1ha:8082 |
аоИФslaves
master1ha
master2
master2ha |
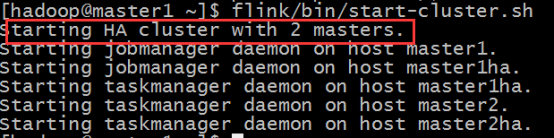
4.3.2. ЦєЖЏ
/home/Hadoop/flink/bin/start-cluster.sh
4.4. Yarn Cluster ФЃЪН
4.4.1. в§Шы
дквЛИіЦѓвЕжаЃЌЮЊСЫзюДѓЛЏЕФРћгУМЏШКзЪдДЃЌвЛАуЖМЛсдквЛИіМЏШКжаЭЌЪБдЫааЖржжРраЭЕФ WorkloadЁЃвђДЫ
Flink вВжЇГждк Yarn ЩЯУцдЫааЁЃЪзЯШЃЌШУЮвУЧЭЈЙ§ЯТЭМСЫНтЯТ Yarn КЭ Flink ЕФЙиЯЕЁЃ

дкЭМжаПЩвдПДГіЃЌFlink гы Yarn ЕФЙиЯЕгы MapReduce КЭ Yarn ЕФЙиЯЕЪЧвЛбљЕФЁЃFlink
ЭЈЙ§ Yarn ЕФНгПкЪЕЯжСЫздМКЕФ App MasterЁЃЕБдк Yarn жаВПЪ№СЫ FlinkЃЌYarn
ОЭЛсгУздМКЕФ Container РДЦєЖЏ Flink ЕФ JobManagerЃЈвВОЭЪЧ App MasterЃЉКЭ
TaskManagerЁЃ
4.4.2. аоИФЛЗОГБфСП
export HADOOP_CONF_DIR= /home/hadoop/hadoop/etc/hadoop
4.4.3. ВПЪ№ЦєЖЏ
yarn-session.sh -d -s 2 -tm 800 -n 2
ЩЯУцЕФУќСюЕФвтЫМЪЧЃЌЭЌЪБЯђYarnЩъЧы3ИіcontainerЃЌЦфжа 2 Иі Container ЦєЖЏ
TaskManagerЃЈ-n 2ЃЉЃЌУПИі TaskManager гЕгаСНИі Task SlotЃЈ-s
2ЃЉЃЌВЂЧвЯђУПИі TaskManager ЕФ Container ЩъЧы 800M ЕФФкДцЃЌвдМАвЛИіApplicationMasterЃЈJob
ManagerЃЉЁЃ
FlinkВПЪ№ЕНYarn ClusterКѓЃЌЛсЯдЪОJob ManagerЕФСЌНгЯИНкаХЯЂЁЃ
Flink on YarnЛсИВИЧЯТУцМИИіВЮЪ§ЃЌШчЙћВЛЯЃЭћИФБфХфжУЮФМўжаЕФВЮЪ§ЃЌПЩвдЖЏЬЌЕФЭЈЙ§-DбЁЯюжИЖЈЃЌШч
-Dfs.overwrite-files=true -Dtaskmanager.network.numberOfBuffers=16368
jobmanager.rpc.addressЃКвђЮЊJobManagerЛсОГЃЗжХфЕНВЛЭЌЕФЛњЦїЩЯ
taskmanager.tmp.dirsЃКЪЙгУYarnЬсЙЉЕФtmpФПТМ
parallelism.defaultЃКШчЙћгажИЖЈslotИіЪ§ЕФЧщПіЯТ
yarn-session.shЛсЙвЦ№НјГЬЃЌЫљвдПЩвдЭЈЙ§дкжеЖЫЪЙгУCTRL+CЛђЪфШыstopЭЃжЙyarn-sessionЁЃ
ШчЙћВЛЯЃЭћFlink Yarn clientГЄЦкдЫааЃЌFlinkЬсЙЉСЫвЛжжdetached YARN
sessionЃЌЦєЖЏЪБКђМгЩЯВЮЪ§-dЛђЁЊdetached
дкЩЯУцЕФУќСюГЩЙІКѓЃЌЮвУЧОЭПЩвддк Yarn Application вГУцПДЕН Flink ЕФМЭТМЁЃШчЯТЭМЁЃ

ШчЙћдкащФтЛњжаВтЪдЃЌПЩФмЛсгіЕНДэЮѓЁЃетРяашвЊзЂвтФкДцЕФДѓаЁЃЌFlink Яђ Yarn ЛсЩъЧыЖрИі
ContainerЃЌЕЋЪЧ Yarn ЕФХфжУПЩФмЯожЦСЫ Container ЫљФмЩъЧыЕФФкДцДѓаЁЃЌЩѕжС
Yarn БОЩэЫљЙмРэЕФФкДцОЭКмаЁЁЃетбљКмПЩФмЮоЗЈе§ГЃЦєЖЏ TaskManagerЃЌгШЦфЕБжИЖЈЖрИі TaskManager
ЕФЪБКђЁЃвђДЫЃЌдкЦєЖЏ Flink жЎКѓЃЌашвЊШЅ Flink ЕФвГУцжаМьВщЯТ Flink ЕФзДЬЌЁЃетРяПЩвдДг
RM ЕФвГУцжаЃЌжБНгЬјзЊЃЈЕуЛї Tracking UIЃЉЁЃетЪБКђ Flink ЕФвГУцШчЭМ
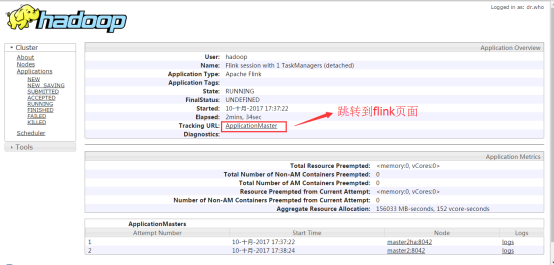
yarn-session.shЦєЖЏУќСюВЮЪ§ШчЯТЃК
Usage:
Required
-n,--container <arg> Number of YARN container
to allocate (=Number of Task Managers)
Optional
-D <arg> Dynamic properties
-d,--detached Start detached
-jm,--jobManagerMemory <arg> Memory for
JobManager Container [in MB]
-nm,--name Set a custom name for the application
on YARN
-q,--query Display available YARN resources (memory,
cores)
-qu,--queue <arg> Specify YARN queue.
-s,--slots <arg> Number of slots per TaskManager
-st,--streaming Start Flink in streaming mode
-tm,--taskManagerMemory <arg> Memory per
TaskManager Container [in MB] |
4.4.4. ЬсНЛШЮЮё
жЎКѓЃЌЮвУЧПЩвдЭЈЙ§етжжЗНЪНЬсНЛЮвУЧЕФШЮЮё
./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar
вдЩЯУќСюдкВЮЪ§ЧАМгЩЯyЧАзКЃЌ-ynБэЪОTaskManagerИіЪ§ЁЃ
дкетИіФЃЪНЯТЃЌЭЌбљПЩвдЪЙгУ-m yarn-clusterЬсНЛвЛИі"дЫааКѓМДЗй"ЕФdetached
yarnЃЈ-ydЃЉзївЕЕНyarn clusterЁЃ
4.4.5. ЭЃжЙyarn cluster
yarn application -kill application_1507603745315_0001
5. ММЪѕЕФЪЙгУ
5.1. FlinkПЊЗЂБъзМСїГЬ
ЛёШЁexecution environment,
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Мгди/ДДНЈГѕЪМЛЏЪ§Он
DataStream<String> text = env.readTextFile("file:///path/to/file");
жИЖЈ transformations зїгУдкЪ§ОнЩЯ
val mapped = input.map { x => x.toInt }
ДцДЂНсЙћМЏ
writeAsText(String path)
print()
ДЅЗЂГЬађжДаа
дкlocalФЃЪНЯТжДааГЬађ
execute()
НЋГЬађДяГЩjarдЫаадкЯпЩЯ
./bin/flink run \
-m master1:8082 \
./examples/batch/WordCount.jar \
--input hdfs://master1:9000/words.txt \
--output hdfs://master1:9000/clinkout \
5.2. Wordcount
5.2.1. ScalaДњТы
object SocketWindowWordCount
{
def main(args: Array[String]) : Unit = {
// the port to connect to
val port: Int = try {
ParameterTool.fromArgs(args).getInt("port")
} catch {
case e: Exception => {
System.err.println("No port specified. Please
run ЁЎSocketWindowWordCount --port <port>ЁЎ")
return
}
}
// get the execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// get input data by connecting to the socket
val text = env.socketTextStream("localhost",
port, ЁЎ\nЁЎ)
// parse the data, group it, window it, and aggregate
the counts
val windowCounts = text
.flatMap { w => w.split("\\s") }
.map { w => WordWithCount(w, 1) }
.keyBy("word")
.timeWindow(Time.seconds(5), Time.seconds(1))
.sum("count")
// print the results with a single thread, rather
than in parallel
windowCounts.print().setParallelism(1)
env.execute("Socket Window WordCount")
}
// Data type for words with count
case class WordWithCount(word: String, count:
Long)
} |
5.2.2. JavaДњТы
public class
SocketWindowWordCount {
public static void main(String[] args) throws
Exception {
// the port to connect to
final int port;
try {
final ParameterTool params = ParameterTool.fromArgs(args);
port = params.getInt("port");
} catch (Exception e) {
System.err.println("No port specified. Please
run ЁЎSocketWindowWordCount --port <port>ЁЎ");
return;
}
// get the execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// get input data by connecting to the socket
DataStream<String> text = env.socketTextStream("localhost",
port, "\n");
// parse the data, group it, window it, and aggregate
the counts
DataStream<WordWithCount> windowCounts =
text
.flatMap(new FlatMapFunction<String, WordWithCount>()
{
@Override
public void flatMap(String value, Collector<WordWithCount>
out) {
for (String word : value.split("\\s"))
{
out.collect(new WordWithCount(word, 1L));
}
}
})
.keyBy("word")
.timeWindow(Time.seconds(5), Time.seconds(1))
.reduce(new ReduceFunction<WordWithCount>()
{
@Override
public WordWithCount reduce(WordWithCount a, WordWithCount
b) {
return new WordWithCount(a.word, a.count + b.count);
}
});
// print the results with a single thread, rather
than in parallel
windowCounts.print().setParallelism(1);
env.execute("Socket Window WordCount");
}
// Data type for words with count
public static class WordWithCount {
public String word;
public long count;
public WordWithCount() {}
public WordWithCount(String word, long count)
{
this.word = word;
this.count = count;
}
@Override
public String toString() {
return word + " : " + count;
}
}
}ЁЁ |
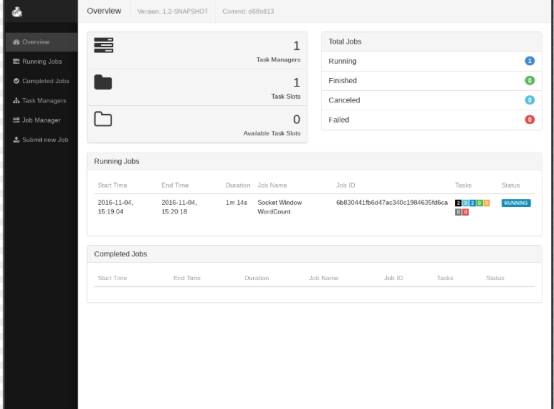
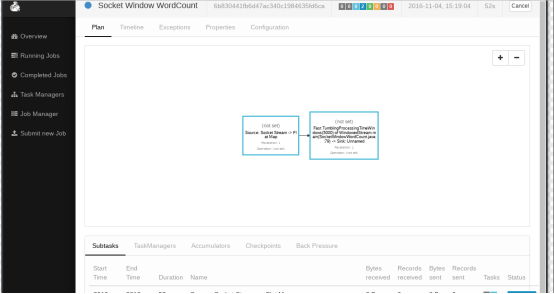
5.2.3. дЫаа
l ЦєЖЏncЗЂЫЭЯћЯЂ
$ nc -l 9000
l ЦєЖЏflinkГЬађ
$ ./bin/flink run examples/streaming/SocketWindowWordCount.jar
--port 9000
5.2.4. ВтЪд
l ЪфШы
$ nc -l 9000
lorem ipsum
ipsum ipsum ipsum
bye |
l ЪфГі
$ tail -f log/flink-*-jobmanager-*.out
lorem : 1
bye : 1
ipsum : 4 |
5.3. ЪЙгУIDEAПЊЗЂРыЯпГЬађ
DatasetЪЧflinkЕФГЃгУГЬађЃЌЪ§ОнМЏЭЈЙ§sourceНјааГѕЪМЛЏЃЌР§ШчЖСШЁЮФМўЛђепађСаЛЏМЏКЯЃЌШЛКѓЭЈЙ§transformationЃЈfilteringЁЂmappingЁЂjoiningЁЂgroupingЃЉНЋЪ§ОнМЏзЊГЩЃЌШЛКѓЭЈЙ§sinkНјааДцДЂЃЌМШПЩвдаДШыhdfsетжжЗжВМЪНЮФМўЯЕЭГЃЌвВПЩвдДђгЁПижЦЬЈЃЌflinkПЩвдгаКмЖржждЫааЗНЪНЃЌШчlocalЁЂflinkМЏШКЁЂyarnЕШ
5.3.1. Pom
n Java
<properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.10.2</scala.version>
<scala.compat.version>2.10</scala.compat.version>
<hadoop.version>2.6.2</hadoop.version>
<flink.version>1.3.2</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.10</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_2.10</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java_2.10</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.10</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.22</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-make:transitive</arg>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.
resource.ManifestResourceTransformer">
<mainClass>org.apache.spark.WordCount</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>ЁЁ |
n Scala
<properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.10.2</scala.version>
<scala.compat.version>2.10</scala.compat.version>
<hadoop.version>2.6.2</hadoop.version>
<flink.version>1.3.2</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.10</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.10</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.10</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.22</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-make:transitive</arg>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation=
"org.apache.maven.plugins.shade.resource.
ManifestResourceTransformer">
<mainClass>org.apache.spark.WordCount</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build> |
5.3.2. ГЬађ
n Java
public class
WordCountExample {
public static void main(String[] args) throws
Exception {
//ЙЙНЈЛЗОГ
final ExecutionEnvironment env =
ExecutionEnvironment.getExecutionEnvironment();
//ЭЈЙ§зжЗћДЎЙЙНЈЪ§ОнМЏ
DataSet<String> text = env.fromElements(
"WhoЁЎs there?",
"I think I
hear them. Stand, ho! WhoЁЎs there?");
//ЗжИюзжЗћДЎЁЂАДееkeyНјааЗжзщЁЂЭГМЦЯрЭЌЕФkeyИіЪ§
DataSet<Tuple2<String, Integer>> wordCounts
= text
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
//ДђгЁ
wordCounts.print();
}
//ЗжИюзжЗћДЎЕФЗНЗЈ
public static class LineSplitter implements FlatMapFunction<String,
Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String,
Integer>> out) {
for (String word : line.split(" "))
{
out.collect(new Tuple2<String, Integer>(word,
1));
}
}
}
} |
n Scala
import org.apache.flink.api.scala._
object WordCount {
def main(args: Array[String]) {
//ГѕЪМЛЏЛЗОГ
val env = ExecutionEnvironment.getExecutionEnvironment
//ДгзжЗћДЎжаМгдиЪ§Он
val text = env.fromElements(
"WhoЁЎs there?",
"I think I hear them. Stand, ho! WhoЁЎs
there?")
//ЗжИюзжЗћДЎЁЂЛузмtupleЁЂАДееkeyНјааЗжзщЁЂЭГМЦЗжзщКѓwordИіЪ§
val counts = text.flatMap { _.toLowerCase.split("\\W+")
filter { _.nonEmpty } }
.map { (_, 1) }
.groupBy(0)
.sum(1)
//ДђгЁ
counts.print()
}
} |
5.3.3. дЫаа
n БОЕи
жБНгrunasМДПЩ
n ЯпЩЯ
1ЁЂ ДђАќ
2ЁЂ ЩЯДЋ
3ЁЂ жДааУќСюЃКflink run -m master1:8082 -c org.apache.flink.WordCount
original-Flink-1.0-SNAPSHOT.jar |









