| БрМЭЦМі: |
БОЮФРДздгкМђЪщЃЌБОЮФжївЊНщЩмЮЊЪВУДашвЊЗжВМЪНЮФМўЯЕЭГвдМАHDFSЖдЮФМўЕФДцДЂЖСШЁКЭШчКЮЪЙгУHDFSЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
|
|
HDFSзїЮЊHadoopЕФКЫаФВПЗжЃЌЪЧHadoopжаMapReduceПђМмЕФДцДЂВуЁЃ
1ЁЂЮЊЪВУДашвЊЗжВМЪНЮФМўЯЕЭГ
ЕБЮФМўЕФДѓаЁГЌЙ§СЫЕЅЬЈМЦЫуЛњЕФДцДЂФмСІЪБЃЌОЭашвЊНЋЦфЗжЧјДцДЂдкВЛЭЌЕЅЖРЕФМЦЫуЛњЩЯЁЃ
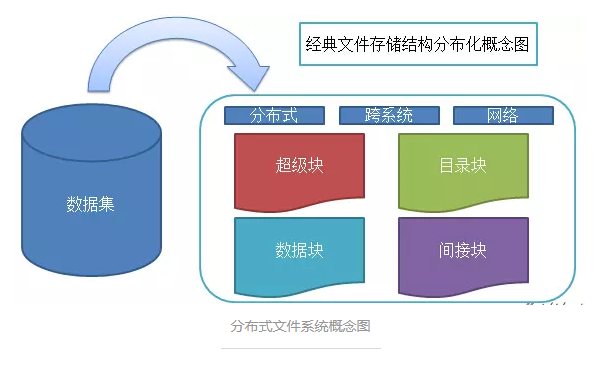
ЗжВМЪНЮФМўЯЕЭГИХФюЭМЮФМўЯЕЭГЕФШ§ИіжївЊзщГЩВПЗжЃКБЛЙмРэЕФЮФМўЁЂЮФМўЙмРэЯрЙиШэМўЁЂЪЕЪЉЮФМўЙмРэЫљашвЊЕФЪ§ОнНсЙЙ
НЋЮФМўЗжВМЪНДцДЂКѓДјРДЕФЮЪЬтЃКЮФМўВЛЭъећЃЌЯЕЭГИДдгЖШМгДѓЃЌв§ШыЭјТчБрГЬ
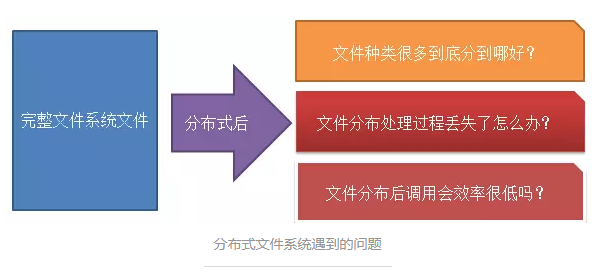
2ЁЂHDFSЖдЮФМўЕФЖСШЁЗНЪНЃКСїДІРэЗУЮЪФЃЪН

HDFSвдСїДІРэЗУЮЪФЃЪНРДДцДЂЮФМўЪВУДЪЧСїДІРэЗУЮЪФЃЪНФиЃПЮЊЪВУДЗжВМЪНЮФМўЯЕЭГГЁОАЯТетжжЮФМўЗУЮЪФЃЪНИќКЯЪЪЃП
ВйзїЯЕЭГжаЮФМўЗУЮЪЗНЪНгаКУМИжжЃЌГЃМћЕФЪЧЫцЛњЪ§ОнЗУЮЪЗНЪНЃЌетжжЗНЪНвЊЧѓЮФМўЖЈЮЛЁЂВщбЏЛђепаоИФЪ§ОнЕФбгГйБШНЯаЁЃЌБШНЯЪЪКЯГЃМћЪ§ОнКѓЖрДЮВщбЏЁЂЖСаДЕФГЁОАЃЌДЋЭГЙиЯЕаЭЪ§ОнПтЗЧГЃЗћКЯетвЛЕуЁЃ
ДѓЪ§ОнГЁОАгыЙиЯЕЯЕЪ§ОнПтЕФГЁОАгаЗЧГЃДѓЕФВЛЭЌЁЃДѓЪ§ОнЕФЪ§ОндДЭЈГЃгЩдДЩњГЩЛђДгЪ§ОндДжБНгИДжЦЖјРДЃЌНгзХГЄЪБМфдкДЫЪ§ОнМЏЩЯНјааИїРрЗжЮіЃЌВЛашвЊАсРДАсШЅЃЛетжжЪ§ОнЗУЮЪГЁОАЪЧЕфаЭЕФвЛДЮаДШыЃЌЖрДЮЖСШЁЕФГЁОАЃЈаДШыЪ§ОнжЛашвЊЩњГЩЪ§ОнЕФФЧвЛДЮЃЌЛљБОУЛгааоИФЪ§ОнЕФвЊЧѓЃЌКѓУцОЭЪЧЖрДЮЖСШЁвдЗжЮіЃЉЃЌЫљвдетжжГЁОАЯТЕФЪ§ОнЗУЮЪЗНЪНИќЪЪКЯВЩгУСїДІРэЗНЪНЁЃ
СїДІРэЪ§ОнЗУЮЪЗНЪНЪдДХХЬбАжЗПЊЯњзюаЁЛЏЃКжЛашвЊвЛДЮбАжЗЃЈЦ№ЪМЕижЗЃЉЃЌШЛКѓОЭЪЧСЌајЕФСїЪНЖСШЁЁЃгВХЬЕФЮяРэЙЙдьЕМжТбАжЗПЊЯњЕФгХЛЏИњВЛЩЯЖСШЁПЊЯњЃЌЫљвдСїЪНЖСШЁИќМгЪЪКЯгВХЬЕФБОЩэЬиадЃЌЕБШЛДѓЮФМўЕФЬиЕувВИќЪЪКЯСїЪНЖСШЁЁЃ
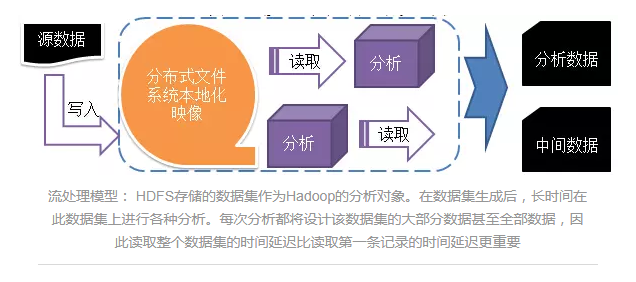
СїДІРэФЃаЭЃК HDFSДцДЂЕФЪ§ОнМЏзїЮЊHadoopЕФЗжЮіЖдЯѓЁЃдкЪ§ОнМЏЩњГЩКѓЃЌГЄЪБМфдкДЫЪ§ОнМЏЩЯНјааИїжжЗжЮіЁЃУПДЮЗжЮіЖМНЋЩшМЦИУЪ§ОнМЏЕФДѓВПЗжЪ§ОнЩѕжСШЋВПЪ§ОнЃЌвђДЫЖСШЁећИіЪ§ОнМЏЕФЪБМфбгГйБШЖСШЁЕквЛЬѕМЧТМЕФЪБМфбгГйИќживЊ
HDFSЪЧгУСїДІРэЗНЪНДІРэЮФМўЃЌУПИіЮФМўдкЯЕЭГРяЖМФмевЕНЫќЕФБОЕиЛЏгГЯёЃЌЫљвдЖдгкгУЛЇРДЫЕЃЌВЛгУЙиаФЮФМўЪЧЪВУДИёЪНЕФЃЌвВВЛгУдквтБЛЗжЕНФФРяЃЌжЛЙмДгHDFSРяШЁГіОЭПЩвдСЫЁЃ
3ЁЂHDFSЖдЮФМўЕФДцДЂЗНЪНЃКЗжЦЌШпгрДцДЂ
бЙЫѕДцДЂ
ЯШЫЕвЛЫЕбЙЫѕДцДЂЁЃ
дкДцДЂзЪдДЮоЗЈТњзуЪ§ОнСПдіГЄЪБЃЌашвЊЖдЪ§ОнбЙЫѕКѓдйДцДЂЃЌжиИДЪ§ОнЩОГ§ММЪѕЪЧЮоЫ№бЙЫѕЕФММЪѕжЎвЛЃЌЫќЕФЛљБОдРэЪЧЖдФПБъЮФМўЗжПщЃЌШЛКѓвдПщЮЊЕЅЮЛНјаажиИДФкШнЕФБШЖдЃЌШєЗЂЯжФкШнЯрЭЌЕФЪ§ОнПщЃЌжЛдкДцДЂНщжЪЩЯДцЗХвЛЗнЃЌВЂМЧТМЯрЙиТпМЙиЯЕЃЌДгЖјМѕЩйЪЕМЪДцДЂПЊЯњЁЃ
етжжЪ§ОнбЙЫѕЗНЪНгАЯьЪ§ОнЕФАВШЋадКЭПЩгУадЃЌШчЯТЭМЃК
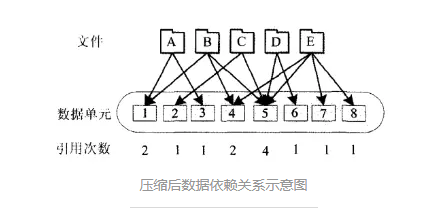
Ъ§ОнЕЅдЊ2жЛЪєгкЮФМўCЃЌвђДЫЪ§ОнЕЅдЊ2ЙЪеЯжЛЛсгАЯьЮФМўCЃЛЖјЪ§ОнЕЅдЊ5ЭЌЪБЪєгк4ИіЮФМўЃЌЫќЙЪеЯСЫЛсЭЌЪБгАЯь4ИіЮФМўВЛФме§ГЃЪЙгУЁЃ
ШпгрДцДЂ
ЮЊСЫБЃжЄЗжВМЪНДцДЂКѓЕФЮФМўОпгаИпПЩгУадЃЌВЩгУШпгрДцДЂетжжШнДэВпТдЁЃГЃгУЕФЗНЗЈЪЧЪ§ОнИДжЦММЪѕЁЂОРЩОТыММЪѕЁЃ
/ Ъ§ОнИДжЦММЪѕ /
Ъ§ОнИДжЦММЪѕЪЧИББОШпгрВпТдЃЌЖдДцДЂЯЕЭГжаЕФЪ§ОнПщНјааЖрДІИББОБЃДцЃЈДцДЂПЊЯњЯрЖдНЯДѓЃЉЁЃ
ОЭЪ§ОнЖјбдЃЌHDFSВЩгУУПЗнЪ§Он3ИББОЕФЗНЪНЃЌБЃжЄФГаЉЪ§ОнЫ№ЪЇжЎКѓШдФмМЬајЪЙгУЁЃ
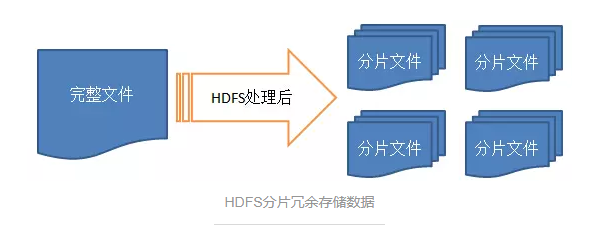
/ ОРЩОТыММЪѕ /
Ъ§ОнЕФШнДэГ§СЫИББОЛЙгаСэвЛжжзіЗЈЃЌОЭЪЧАбЖЊЪЇЕФЪ§ОнМЦЫуГіРДЁЃетОЭЪЧОРЩОТыЕФЫМЯыСЫЁЃгыИББОЯрБШЃЌОРЩОТыЕФгХЕудкгкНкЪЁДцДЂПеМфЃЌШБЕудкгкгаМЦЫуПЊЯњЖјЧваоИДашвЊвЛЖЈЪБМфЃЌЖјИББОЫ№ЪЇжЛвЊИДжЦГіРДЫ№ЪЇЕФЪ§ОнЃЌЮДЫ№ЪЇЕФЪ§ОнПЩвдМЬајЬсЙЉЗўЮёЁЃ
МђЕЅдРэЃКОРЩОТыЃЈerasure codingЃЌECЃЉММЪѕЪЧНЋЪ§ОнПщЗжЮЊmИіЪ§ОнПщЃЌШЛКѓЭЈЙ§БрТыШпгрРЉеЙжСnИіЪ§ОнПщЃЈn>mЃЉЃЌетnИіЪ§ОнПщжага
k=n-m ИіЪЧаЃбщПщЃЌШчЙћmИіЪ§ОнПщжаШЮвтвЛИіЖЊЪЇСЫЃЌПЩвдЭЈЙ§kИіаЃбщПщМЦЫуЛжИДГіРДЃЌетвВЪЧвЛжжШпгрДцДЂВпТдЃЌВЛЙ§ЯрБШИББОММЪѕЖјбдИќМбНкЪЁДцДЂПеМф
[4]ЁЃ
ОРЩОТыПЩвдгУгкгаДѓСПЪ§ОнКЭШЮКЮашвЊШнДэЕФгІгУГЬађЛђЯЕЭГжаЃЌБШШчДХХЬеѓСаЯЕЭГЁЂЪ§ОнЭјИёЁЂЗжВМЪНДцДЂгІгУГЬађЁЂЖдЯѓДцДЂЛђЙщЕЕДцДЂЁЃФПЧАЃЌОРЩОТыЕФвЛИіГЃМћЕФЪЙгУАИР§ЪЧЛљгкЖдЯѓЕФдЦДцДЂЁЃ
4ЁЂHDFSЖдЮФМўЕФаЃбщЗНЪНЃКЗжЦЌШпгрЃЌБОЕиаЃбщ
ЗжВМЪНЮФМўЯЕЭГИКд№Ъ§ОнЗжВМДцДЂКЭЪ§ОнЙмРэЃЌВЂЬсЙЉЖдЪ§ОнИпЭЬЭТСПЗУЮЪЕФадФмЁЃжївЊЙІФмГ§СЫЖСаДВйзїжЎЭтЃЌЛЙгавЛИіОЭЪЧЪ§ОнаЃбщЙІФмЃЌДЫЙІФмдкЪ§ОнЖСаДЙ§ГЬжаЖМЛсдЫгУЕНЁЃЫќЪЧЪ§ОнЭъећадЕФСМКУБЃеЯЁЃЗжВМЪНЮФМўЯЕЭГдкЖСаДЪ§ОнЪБЖСШЁвЛИіЮФМўПщПЩФмгЩгкДцДЂЩшБИЁЂЭјТчЛђепШэМўЕФШБЯнЕШдвђЖјГіЯжЫ№ЛЕЕФЧщПіЁЃЖдгкДѓЪ§ОнДІРэЃЌдБОИДдгЗБжиЕФМЦЫуШЮЮёдйМгЩЯЪ§ОнаЃбщЙ§ГЬЛсИјЗжВМЪНЮФМўЯЕЭГДјРДЖюЭтИКЕЃЃЌЖСаДЫйТЪвВЛсЫцжЎгаЫљЯТНЕЃЌетОЭашвЊНЈСЂвЛИіЭъећЕФЬхЯЕЃЌдкБЃжЄЪ§ОнЭъећЕФЧщПіЯТОЁСПМѕаЁвђЮЊЪ§ОнаЃбщЖјИјЯЕЭГДјРДЕФгАЯьЁЃ
HDFSЕФНтОіЗНАИЪЧЗжЦЌШпгрЃЌБОЕиаЃбщЃЛЪ§ОнШпгрЪНДцДЂЃЌжБНгНЋЖрЗнЕФЗжЦЌЮФМўНЛИјЗжЦЌКѓЕФДцДЂЗўЮёЦїШЅаЃбщЃЛШпгрКѓЕФЗжЦЌЮФМўЛЙгаИіЖюЭтЙІФмЃЌжЛвЊШпгрЕФЗжЦЌЮФМўжагавЛЗнЪЧЭъећЕФЃЌОЙ§ЖрДЮаЭЌЕїећКѓЃЌЦфЫћЗжЦЌЮФМўвВНЋЭъећЁЃ
DFSЭЈЙ§CheckSumКЭDataBlockScannerСНжжЗНЪНЭЌЪБРДБЃжЄБЃДцдкЪ§ОнНкЕуЩЯЕФЪ§ОнЪБЭъећЕФЁЃHDFSжаЕФDataNodeдкБОЕиЮФМўЯЕЭГДцДЂЪ§ОнПщЕФдЊЪ§ОнгУгкCRCаЃбщЁЃЖдгкУПвЛИіПщЃЌЯђDataNodeЧыЧѓchecksumаХЯЂЃЌЗЕЛиЕФаХЯЂжаАќРЈПщЕФЫљгаchecksumЕФMD5еЊвЊЃЌШчЙћЯђвЛИіDataNodeЧыЧѓЪЇАмЃЌЛсЯђСэвЛDataNodeЧыЧѓЃЌзюКѓНЋЫљгаПщЕФMD5КЯВЂЃЌВЂМЦЫуетаЉФкШнЕФMD5еЊвЊЁЃ[5]
5ЁЂHDFSЕФИХФю
HDFSПЩвдгУЯТУцетИіГщЯѓЭМЕФОпЬхЪЕЯжЃК
КЮЮЊдЊЪ§Он
дЊЪ§ОнЪЧгУгкУшЪівЊЫиЁЂЪ§ОнМЏЛђЪ§ОнМЏЯЕСаЕФФкШнЁЂИВИЧЗЖЮЇЁЂжЪСПЁЂЙмРэЗНЪНЁЂЪ§ОнЕФЫљгаепЁЂЪ§ОнЕФЬсЙЉЗНЪНЕШгаЙиЕФаХЯЂЁЃИќМђЕЅЕФЫЕЃЌЪЧЙигкЪ§ОнЕФЪ§ОнЁЃ
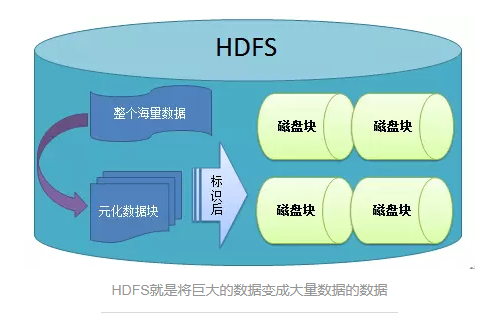
ПщгыПщДѓаЁЕФЩшжУ
ПщЪЧЮФМўДцДЂДІРэЕФТпМЕЅдЊЁЃ
ДХХЬДцДЂЮФМўЪБЃЌЪЧАДееЪ§ОнПщРДДцДЂЕФЃЌвВОЭЪЧЫЕЃЌЪ§ОнПщЪЧДХХЬЕФЖС/аДзюаЁЕЅЮЛЁЃЪ§ОнПщвВГЦДХХЬПщЁЃЙЙНЈгкЕЅИіДХХЬЩЯЕФЮФМўЯЕЭГЪЧЭЈЙ§ДХХЬПщРДЙмРэЮФМўЯЕЭГЃЌвЛАуРДЫЕЃЌЮФМўЯЕЭГПщЕФДѓаЁЪЧДХХЬПщЕФећЪ§БЖЁЃЬиБ№ЕФЃЌЕЅИіДХХЬЮФМўЯЕЭГЃЌаЁгкДХХЬПщЕФЮФМўЛсеМгУећИіДХХЬПщЁЃДХХЬПщЕФДѓаЁвЛАуЪЧ512зжНкЁЃ
дкHDFSжаЃЌвВгаПщЃЈblockЃЉетИіИХФюЃЌФЌШЯЮЊ64MBЃЌУПИіПщзїЮЊЖРСЂЕФДцДЂЕЅдЊЁЃ
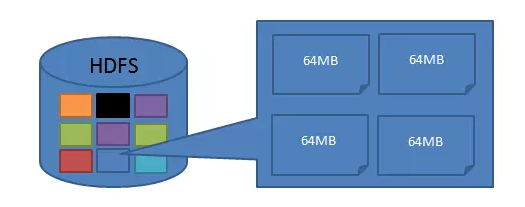
гыЦфЫћЮФМўЯЕЭГВЛвЛбљЃЌHDFSжаУПИіаЁгкПщДѓаЁЕФЮФМўВЛЛсеМОнећИіПщЕФПеМфЁЃ
HDFSЮЊЪВУДЪЙгУДѓПщ
ЃЈ1ЃЉМѕЩйNameNodeЕФбЙСІ
NameNodeгУРДДцДЂhdfsЩЯЮФМўЕФдЊЪ§ОнаХЯЂЃЌШчЙћЪЧаЁЮФМўЃЌЛсЕМжТВњЩњДѓСПЕФдЊЪ§ОнаХЯЂЁЃHDFSжаУПИіЮФМўЁЂФПТМКЭЪ§ОнПщЕФДцДЂаХЯЂДѓдМдк150зжНкЃЌШчЙћДѓСПаЁЮФМўЛсЕМжТNameNodeФкДцВЛЙЛгУЁЃ
ЃЈ2ЃЉзюаЁЛЏбАжЗЪБМф
ШчЙћПщЩшжУЕФзуЙЛДѓЃЌДгДХХЬДЋЪфЪ§ОнЕФЪБМфЛсУїЯдДѓгкЖЈЮЛетИіПщПЊЪМЮЛжУЫљашвЊЕФЪБМфЃЌвђЖјЃЌДЋЪфвЛИігЩЖрПщзщГЩЕФЮФМўЪБМфШЁОігкДЋЪфЫйТЪЃЈбАжЗЪБМфПЩКіТдВЛМЦЃЉЁЃ
T(ДцДЂЪБМф)=T(ЖЈЮЛЪБМф)+T(ДЋЪфЪБМф)
ШчЙћУПИівЊДЋЪфЕФПщЩшжУЕУзуЙЛДѓЃЌФЧУДДгДХХЬДЋЪфЪ§ОнЕФЪБМфПЩвдУїЯдДѓгкЖЈЮЛетИіПщПЊЪМЮЛжУЕФЪБМф
T(ДцДЂЪБМф)=T(ЖЈЮЛЪБМф) )[-Ёо]+T(ДЋЪфЪБМф)[Ёо]
НќЫЦЕШгкЃКT(ДцДЂЪБМф)=T(ДЋЪфЪБМф)
ШчЙћЮвУЧЩшжУЕФПщЙ§аЁЃЌФЧУДвЛИіЮФМўОЭЪЧВњЩњКмЖрЕФПщЃЌЕБЮвУЧвЊЖдПщНјааВйзїЕФЪБКђЃЌОЭЛсВњЩњКУЖрДЮЕФбАжЗЃЌетбљОЭЕМжТСЫбАжЗЕФЪБМфЛсКмГЄЁЃ
ЕБбАжЗЪБМфБШioЛЙГЄЕФЪБКђЃЌбАжЗЪБМфОЭГЩЮЊСЫЦПОБЁЃЫљвдЃЌКЯРэЩшжУДѓаЁФмЬсИпЭЬЭТСПЁЃ
ЃЈ3ЃЉПщЕФДѓаЁвВВЛКЯЪЪЬЋДѓ
HDFSЬсЙЉИјMapReduceЪ§ОнЗўЮёЃЌЖјвЛАуРДЫЕMapReduceЕФMapШЮЮёЭЈГЃвЛДЮДІРэвЛИіПщжаЕФЪ§ОнЃЌШчЙћШЮЮёЪ§ЬЋЩйЃЈЩйгкМЏШКжаНкЕуЕФЪ§СПЃЉЃЌОЭУЛгаЗЂЛгЖрНкЕуЕФгХЪЦЃЌЩѕжСзївЕЕФдЫааЫйЖШОЭЛсКЭЕЅНкЕувЛбљЃЌШчЙћПщЩшжУЕФЬЋДѓЃЌОЭЮоЗЈГфЗжРћгУВЂааЕФЬиадЁЃ
ЗжВМЪНЕФЮФМўГщЯѓФмЙЛДјРДЕФгХЪЦ
вЛИіЮФМўПЩвдДѓгкУПИіДХХЬ
ЮФМўВЛгУШЋдквЛИіДХХЬЩЯ
МђЛЏСЫДцДЂзгЯЕЭГЕФЩшМЦ
ЛљгкдЊЪ§ОнПщЕФДцДЂЗНЪНЗЧГЃЪЪКЯгУгкБИЗнЃЌРћгУБИЗнПЩЬсЙЉЪ§ОнШнДэФмСІКЭПЩгУад
HDFSжаЕФСНРрНкЕуЃЈnodeЃЉ
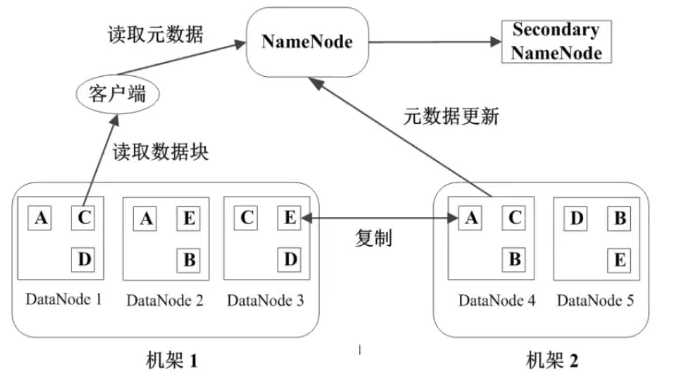
NameNode
ЪЧЙмРэНкЕуЃЌДцЗХЮФМўдЊЪ§ОнЃК
ЃЈ1ЃЉЮФМўгыЪ§ОнПщЕФгГЩфБэ
ЃЈ2ЃЉЪ§ОнПщгыЪ§ОнНсЕуЕФгГЩфБэ
ПЭЛЇЖЫЖСШЁЪ§ОнжЎЧАЃЌЯШДгNameNodeжаЖСШЁдЊЪ§ОнЃЌДгЖјЕУжЊЮФМўДцЗХдкФЧаЉDataNodeЩЯЕФЃЌдйДгЪ§ОнНкЕужаФУЕНЪ§ОнПщЃЌЦДзАГЩЯывЊЕФЮФМўЁЃ
DataNode
ЪЧЙЄзїНкЕуЃЌДцЗХЪ§ОнПщ
аФЬјМьВт
NameNodeКЭDataNodeжЎМфгааФЬјавщЃЌDataNodeЖЈЦкЯђNameNodeЛуБЈздЩэзДПіЃЌЪЧЗёДІгкactiveзДЬЌЁЂЭјТчЪЧЗёе§ГЃЁЂЛњЦїЪЧЗёе§ГЃдЫаа
Secondary NameNodeЃЈЖўМЖNameNodeЃЉ
ЖўМЖNameNodeВЂВЛЪЧNameNodeЕФБИЗнЃЌЖЈЦкЭЌВНдЊЪ§ОнгГЯёЮФМўЃЈfsimageЃЉКЭаоИФШежОЃЈedit
logsЃЉЕФЃЌЯъМћЃКSecondary NameNode:ЫќОПОЙгаЪВУДзїгУЃП
Secondary NameNodeЕФећИіФПЕФЪЧдкHDFSжаЬсЙЉвЛИіМьВщЕуЁЃЫќжЛЪЧNameNodeЕФвЛИіжњЪжНкЕуЁЃетвВЪЧЫќдкЩчЧјФкБЛШЯЮЊЪЧМьВщЕуНкЕуЕФдвђЁЃ
HDFSжаЮФМўЖСаДЕФСїГЬ
ЖСЮФМўСїГЬ
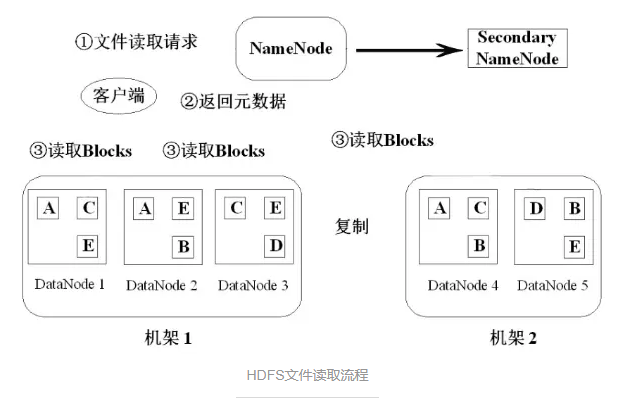
HDFSЮФМўЖСШЁСїГЬ
ЃЈ1ЃЉПЭЛЇЖЫЃЈjava/shell/...ЃЉЗЂЦ№ЮФМўЖСШЁЧыЧѓЃЌНЋЮФМўУћЁЂТЗОЖИцжЊNameNodeЃЛ
ЃЈ2ЃЉNameNodeВщбЏВЂЗЕЛидЊЪ§ОнИјПЭЛЇЖЫЃЌАќРЈИУЮФМўдкФФаЉПщжаЁЂетаЉПьвЊдкФФаЉЛњЦїжаЕФФФаЉDataNodeжаШЅевЃЛ
ЃЈ3ЃЉПЭЛЇЖЫИљОнаХЯЂШЅЖСblockЃЌНЋblockЯТдиЯТРДКѓНјаазщзАЃЌЖСШЁЭъГЩЁЃ
аДЮФМўСїГЬ
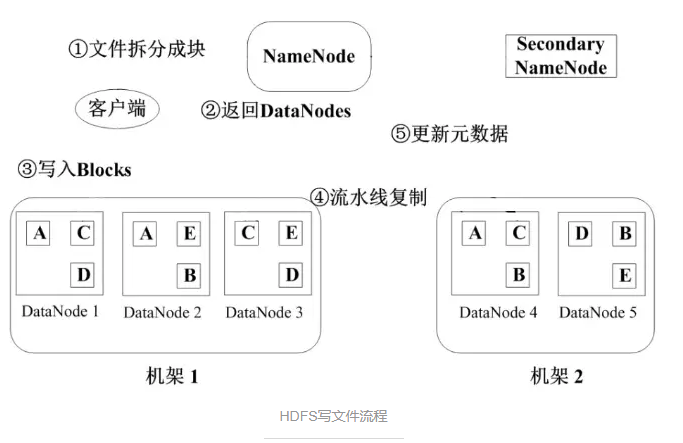
HDFSаДЮФМўСїГЬ
ЃЈ1ЃЉНЋЮФМўВ№ЗжГЩПщЃЈЙЬЖЈДѓаЁ64MЃЉЃЌЭЈжЊNameNodeЃЛ
ЃЈ2ЃЉNameNodeНЋЕБЧАПЩгУВЂЧвДѓаЁЗћКЯЕФDataNodeаХЯЂЗЕЛиЃЛ
ЃЈ3ЃЉПЭЛЇЖЫНЋblocksаДШыЯргІЕФDataNodeЃЛ
ЃЈ4ЃЉblockаДШыКѓНјааСїЫЎЯпИДжЦЃЛ
ЃЈ5ЃЉИќаТдЊЪ§ОнЃЛ
ЃЈ6ЃЉУПДЮаДвЛИіblock
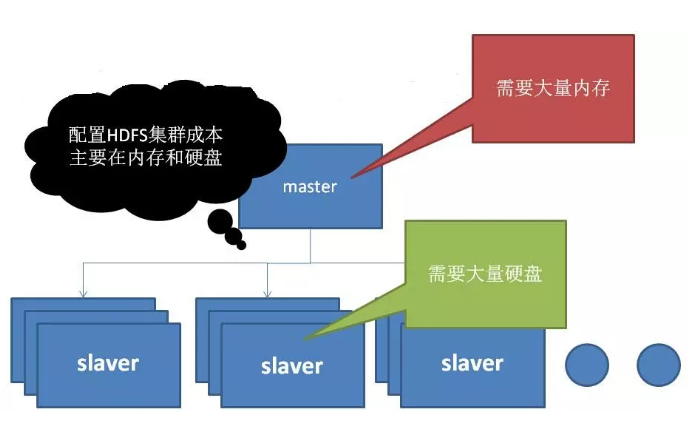
6ЁЂHDFSЕФЙиМќдЫзїЛњжЦ
HDFSЪЧЛљгкжїДгНсЙЙЃЈmaster/slaverЃЉЙЙМўЁЃ
7ЁЂШчКЮЪЙгУHDFS
HDFSЪЧдкАВзАhadoop-0.20.2.tar.gzВЂГЩЙІХфжУКѓМДПЩЪЙгУЁЃЮоТлЪЧЪЙгУshellНХБОЃЌЛђепЪЙгУWEB
UIНјааВйзїЃЌЪЙгУЧАБиаыЕУУїАзHDFSЕФХфжУЃЌБугкДцДЂВйзїЛђепВйзїгХЛЏЁЃ
# lists the commands
supported by Hadoop shell
$bin/hdfs dfs -help
# displays more detailed help for a command
$bin/hdfs dfs -help command-name
bin/hadoop fs <==> bin/hdfs dfs
|
hadoop fs
This command is documented in the File System Shell
Guide. It is a synonym for hdfs dfs
when HDFS is in useЃЈЕБHDFSдкЪЙгУЪБЃЌhadoop fsКЭhdfs dfs ЪЧЁАЭЌвхДЪЁБЃЉ.
$hadoop fs -ls
/
$hadoop fs -put <file> <dest>
$hadoop fs -mkdir <file>
$... |
|









