| БрМЭЦМі: |
| РДдДгкзїепАЌМбЃЌБОЮФвдеЦЛлзнгЏЮЊАИР§ЃЌВћЪіСЫЮяСЊЭјЦѓвЕЕФвЕЮёМмЙЙКЭЪ§ОнМмЙЙЃЌвдМАММЪѕбЁаЭЕФЫМПМЙ§ГЬЁЃ |
|
ШчКЮДюНЈДѓЪ§ОнЦНЬЈММЪѕМмЙЙЃПгаУЛгаКУЕФДѓЪ§ОнЦНЬЈМмЙЙАИР§ЃП ЧыПДЯТЮФ
НшжњЁАЛЅСЊЭј+ДѓЪ§Он+ЛњГЁЁБШ§ТжЧ§ЖЏЃЌеЦЛлзнгЏУПФъЮЊ6.4вкШЫДЮГіааЬсЙЉЮоЯпЭјТчСЌНгЗўЮёЁЃ ЫцзХвЕЮёЕФЭиеЙЃЌЫцжЎКѓРДЕФЬєеНЪЧЪ§ОнСПЕФБЉдіЁЃ
2016ФъЃЌеЦЛлзнгЏЭЈЙ§АЂРядЦВњЦЗЃЌТЪЯШЙЙНЈСЫвЕНчСьЯШЕФДѓЪ§ОнЦНЬЈЁЃ
вдЯТРДздеЦЛлзнгЏЕФДѓЪ§ОнЦНЬЈМмЙЙЪІЕФЗжЯэЃК
вЕЮёМмЙЙ
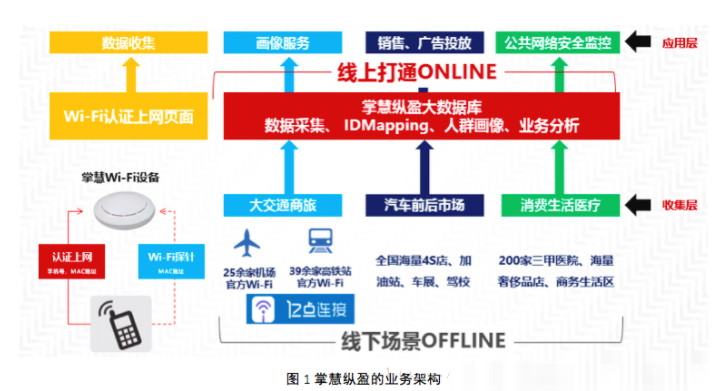
еЦЛлзнгЏЕФвЕЮёМмЙЙШчЭМЫљЪОЁЃЮвУЧЕФвЕЮёФЃЪНжївЊОЭЪЧЭЈЙ§здгаЩшБИЖдЪ§ОнНјааЪеМЏЃЌЖдЪ§ОнЕФМлжЕНјааЭкОђЃЌзюКѓЖдетаЉЪ§ОнгІгУЁЃ
Ъ§ОнЪеМЏВуЃЌЮвУЧДДСЂСЫЙњФкЛњГЁЙйЗНWi-FiЕквЛЦЗХЦЁАAirport-Free-WiFiЁБЃЌЭјТчБщВМШЋЙњ25ИіЪрХІЛњГЁКЭ39ИіЪрХІИпЬњеОЃЌУПФъЮЊ6.4вкШЫДЮГіааЬсЙЉЮоЯпЭјТчСЌНгЗўЮёЃЛЮвУЧгЕгаШЋЙњзюДѓЕФМнаЃWi-FiЭјТчЃЌЕН17ФъЕзНЋИВИЧ1500+ЫљМнаЃЃЛЮвУЧвВЪЧжаЙњЫФДѓГЕеЙЃЈББОЉЁЂЩЯКЃЁЂЙужнЁЂГЩЖМЃЉWi-FiЗўЮёЩЬЃЌЮЊГЌЙ§120ЭђШЫДЮЬсЙЉСЫЭјТчЗўЮёЃЛДЫЭтЃЌЮвУЧЛЙдЫгЊСЫШЋЙњ2000+ИіМггЭеОКЭ600+ИіЦћГЕ4SОЯњЕъЕФWi-FiЭјТчЁЃ
Ъ§ОнгІгУВуЃЌЮвУЧДђЭЈСЫЯпЩЯКЭЯпЯТааЮЊЪ§ОнЃЌгУгкгУЛЇЛЯёЃЌЮЊАќРЈSSPЃЌDSPЃЌDMPЃЌRTBдкФкЕФЙуИцвЕЮёЬсЙЉИќИпаЇЕФОЋзМДЅДяЃЛВЂКЭЙЋАВВПКЯзїЃЌХХВщЙЋЙВЭјТчАВШЋЭўаВЁЃ
еЦЛлзнгЏЕФДѓЪ§ОнЦНЬЈКЭЙуИцЭЖЗХЦНЬЈЛЙЮЊЦѓвЕЪфГіММЪѕФмСІЃЌАяжњЦѓвЕНЈСЂздМКЕФДѓЪ§ОнЦНЬЈЃЌгУЗсИЛЕФСПЛЏЪ§ОнЬсЩ§ЦѓвЕЕФдЫгЊЙмРэаЇТЪЁЃ
Ъ§ОнМмЙЙ
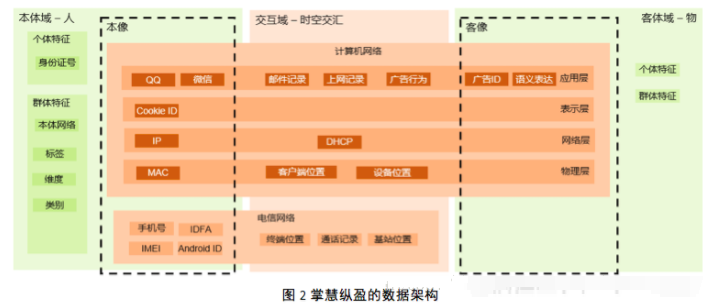
ЛљгкЮвУЧЕФвЕЮёМмЙЙЃЌЮвУЧГщЯѓГ§СЫЮвУЧЕФЪ§ОнМмЙЙЃЌЦфжаАќКЌСЫаэЖржїЬтЃЌЦфжїЬтЪгЭМШчЭМЫљЪОЁЃЭМжаБОЬхПЩвдМђЕЅЕФРэНтЮЊШЫЃЌПЭЬхПЩвдМђЕЅЕФРэНтЮЊЮяЃЛБОЬхгыПЭЬхвдИїжжаЮЪННјааСЌНгЃЌетжжСЌНгЪЧвЛжжЪБМфЮЌЖШКЭПеМфЮЌЖШЩЯЕФНЛЛуЃЌетжжСЌНгЭЈЙ§МЦЫуЛњЭјТчКЭЕчаХЭјТчЭъГЩЁЃБОЬхдкСЌНгЭјТчжагаздМКЕФЯёЃЌПЩвдМђЕЅЕФРэНтЮЊащФтЩэЗнЃЈAvatarsЃЉЃЛПЭЬхдкСЌНгЭјТчжавВгаздМКЕФЯёЃЌР§ШчЮЌЛљАйПЦЖдФГвЛЪТЮяЕФУшЪіЃЌдйБШШчФГвЛЪТЮяЩЬвЕЛЏКѓаЮГЩВњЦЗЛђЗўЮёЃЌдйОЙ§ЙуИцАќзАГЩЦфЙуИцаЮЯѓЃЌетаЉЖМЪЧЦфПЭЯёЁЃБОЬхгыПЭЬхЕФНЛЛЅЪЕМЪЩЯОЭЪЧБОЯёКЭПЭЯёЕФНЛЛЅЃЌетжжНЛЛЅдкЪБМфКЭПеМфЕФЮЌЖШЩЯЖМЛсСєЯТЙьМЃЁЃ
БОЬхЕФИіЬхЬиеїКЭШКЬхЬиеїЃЌПЭЬхЕФИіЬхЬиеїКЭШКЬхЬиеїЃЌБОПЭНЛЛЅЕФЫљгаЙьМЃЃЌЫљгаетаЉжїЬтаЮГЩЕФДѓЪ§ОнЃЌОЙ§ЩюЖШЭкОђКЭбЇЯАЃЌПЩвдЕУГіЧПДѓЕФЖДВьСІЃЌетжжЖДВьСІОпгаВЛПЩЙРСПЕФЩЬвЕМлжЕЁЃ
еЦЛлзнгЏФПЧАдкБОЬхгђКЭНЛЛЅгђЕФЪ§ОнЬхСПЃК

ММЪѕбЁаЭ
НгЯТРДЫЕвЛЯТЮвУЧММЪѕбЁаЭЕФЫМТЗЁЃЮвШЯЮЊЃЌУЛгазюКУЕФММЪѕМмЙЙЃЌжЛгазюКЯЪЪЕФМмЙЙЁЃГЩЙІЕФITЙцЛЎОЭЪЧДгвЕЮёМмЙЙГіЗЂЃЌеыЖдЦфУПвЛИівЕЮёГЁОАЃЌИјГізюКЯЪЪЕФММЪѕМмЙЙЁЃ
ЙІФмашЧѓ
ЪзЯШРДПДЮвУЧЕФЙІФмашЧѓЁЃвдЮвУЧЕФЙуИцвЕЮёЮЊР§ЃЌФПБъЪЧШеЯћЯЂДІРэСПДяЕН100вкЬѕЁЃЦфЖдДѓЪ§ОнФмСІЕФвЊЧѓШчЯТЃК
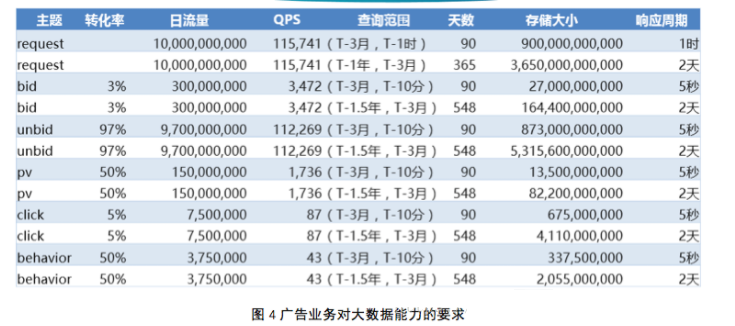
МйЩшМЧТМДѓаЁЪЧ2KBЃЌШнФЩетаЉЪ§ОнЮвУЧашвЊ70PBЕФЮяРэШнСПЁЃЖдВщбЏЗЖЮЇЕФвЊЧѓЃЌЭЦЕМГіЃЌРыЯпМЦЫуЕФДІРэЪБГЄ24аЁЪБЃЌдкЯпМЦЫу10ЗжжгЁЃ
ЗЧЙІФмашЧѓ
ЯЃЭћЭЈЙ§дЦЦНЬЈНЋЛљДЁЩшЪЉАВзАдЫЮЌЭтАќЁЃ
ДѓЪ§ОнММЪѕШеаТдТвьЃЌЯЃзщМўАцБОФмЙЛМАЪБИќаТЁЃ
ЭтВПЩЬвЕЛЗОГбИЫйБфЛЏЃЌЯЃЭћМЦЫузЪдДПЩвдЖЏЬЌдіМѕЃЌвдНкдМГЩБОЁЃ
ЯЃЭћвдНЯЕЭЕФГЩБОЛёШЁЯрЖдзЈвЕЕФАВШЋЗўЮёЁЃ
ОЁСПЪЙгУПЊдДзщМўЃЌЗНБуећЬхЪфГіЁЃ
ВњЦЗбЁдё
злКЯПМВьЙњФкЕФдЦЗўЮёЬсЙЉЩЬЃЌЮвУЧбЁдёСЫАЂРядЦЃЌгШЦфЪЧЦфE-MapReduceВњЦЗЃЌЙКТђжЎКѓЃЌМЏШКТэЩЯОЭДДНЈКУСЫЃЌHive,
Spark, HBaseЕШПЊдДДѓЪ§ОнзщМўМДПЬПЩгУЁЃ
ЪзЯШЮвУЧбЁдёЪ§ОнДцДЂв§ЧцЁЃ
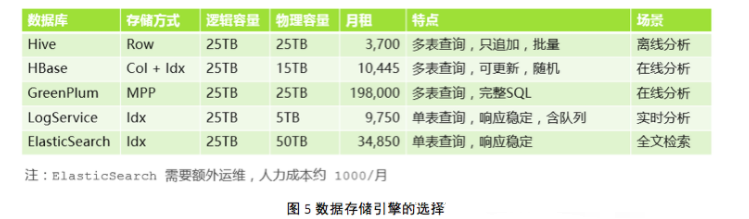
ЮвУЧвдДцДЂ25TBЕФЪ§ОнЮЊЛљзМЃЌПМВьИїИібЁЯюЕФадФмКЭМлИёЁЃДгЭМжаПЩвдПДГіЃЌеыЖдРыЯпЗжЮіРДЫЕЃЌШчЙћЯыгУПЊдДзщМўЃЌПЩвдПМТЧHive
on OSSЕФФЃЪНЃЌРДДцДЂНќвЛФъЕФЪ§ОнЁЃеыЖддкЯпЗжЮіЕФГЁОАЃЌЪЙгУHBaseДцДЂНќШ§ИідТЕФЪ§ОнЃЌПЩвдЛёЕУКмИпЕФадМлБШЃЌетИіЗНАИПЩвдЖрБэСЊВщЃЌЕЋЪЧSQLЕФЯьгІЖдГЁОАУєИаЃЌВЛЭЌИДдгЖШЕФSQLЯьгІЪБМфЪЧВЛвЛбљЕФЁЃШчЙћЯЃЭћЯьгІЪБМфКуЖЈЃЌПЩвдПМТЧЛљгкЫїв§ЕФЗНАИЃЌМДШежОЗўЮёЃЌШБЕуОЭЪЧВЛФмЖрБэСЊВщЃЛШчЙћЯыЪЙгУПЊдДзщМўЃЌПЩвдздаадкECSЩЯДюНЈELKЁЃ
НгЯТРДЮвУЧбЁдёВщбЏв§ЧцЁЃЮвУЧЪЙгУвЛИіЛљзМSQLЃЌЗНБуЖдЦфЯьгІЪБМфНјааКсЯђЖдБШЃЌЛљзМSQLШчЯТЭМЫљЪОЃК
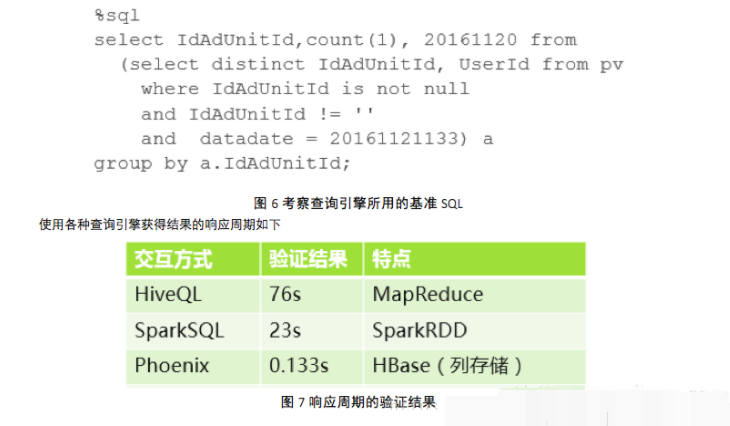
НсТлЪЧЃЌЪЙгУPhoenixЛљгкHBaseНјааНЛЛЅЪНВщбЏЃЌПЩвдЛёЕУКмТњвтЕФЯьгІжмЦкЁЃ
бЁаЭВПЗжИцвЛЖЮЃЌНгЯТРДИјГіДѓЪ§ОнЦНЬЈЕФММЪѕМмЙЙЁЃ
ММЪѕМмЙЙ
ДѓЪ§ОнЦНЬЈЕФММЪѕМмЙЙИХРРШчЭМЫљЪОЃЌЭМжаМИКѕЫљгаЕФЗўЮёКЭЙІФмЖМЪЧЭЈЙ§АЂРядЦВњЦЗРДЪЕЯжЕФЃЌЦфжаПЊЗЂВтЪдЛЗОГвВЪЧЛљгкАЂРядЦЕФECSДюНЈЕФЁЃДгЭМжаПЩвдПДГіЃЌЮвУЧВЂВЛашвЊЙиаФЛњЗПЕФЕчдДЁЂЭјТчЁЂащФтЛЏЁЂгВХЬИќЛЛЕШвЛЯЕСаЛљДЁЩшЪЉЮЪЬтЃЌжБНгЛљгкдЦЦНЬЈЃЌзЈзЂгкЮвУЧздМКЕФвЕЮёЁЃ
ВњЦЗЪЙгУжагавЛаЉаФЕУЃЌзмНсШчЯТЃК
E-MapReduce
АЂРядЦЕФE-MapReduceЪЧЮвУЧДѓЪ§ОнЦНЬЈЕФКЫаФВњЦЗЃЌЦфКИЧСЫHive, Spark, HBase,
StormЕШДѓЪ§ОнСьгђКЫаФЕФПЊдДзщМўЃЌЛЙгаPhoenix, PrestoЕШвЕНчЧАбиЕФВщбЏв§ЧцЃЌЦфZeppelin,
HueЕШНЛЛЅзщМўвВЪЧПЊЯфМДгУЁЃ
E-MapReduceВЛЖЯгааТЕФАцБОЗЂВМЃЌЦфжаЕФзщМўАцБОвВЪЧВЛЖЯИќаТЃЌЕЋЪЧвбОЙКТђЕФE-MapReduceЪЧЮоЗЈЗНБуЕФЩ§МЖЕФЃЌЮЊСЫМАЪБЩ§МЖзщМўАцБОЃЌЮвУЧВЩШЁАќдТЖјВЛЪЧАќФъФЃЪНЁЃАќдТЕНЦкЃЌЯывЊЩ§МЖЃЌжБНгТђаТЕФЃЌОЩЕФВЛајЗбЃЌздааЯњЛйЁЃАЂРяЕФE-MapReduceжЛФмдіМгНкЕуВЛФмМѕЩйНкЕуЃЌЭЈЙ§ЩЯЪіЕФЙіЖЏФЃЪНЃЌЛЙПЩвдЫцЪБЕїећМЏШКЙцФЃКЭИїжжХфжУЁЃ
ЩЯЪіЕФетжжЙіЖЏФЃЪНЃЌЖдгкМЦЫуМЏШКРДЫЕУЛЮЪЬтЃЌЪ§ОнДцДЂдѕУДАьФиЃПE-MapReduceЫљгУЕФЛњЦїХфжУЖМКмИпЃЌгУРДДцДЂЪ§ОнОЭПЩЯЇСЫЃЌЪ§ОнПЩвдДцДЂдкOSSЩЯЃЌЪЙгУHiveМгдиМДПЩЁЃВЛЙ§вЊЪЙгУHBaseЛЙЪЧвЊАбЪ§ОнДцЕНE-MapReduceЩЯЃЌвЛЕЋЗХЕНE-MapReduceЩЯЃЌетИіМЏШКОЭВЛФмЫцвтЯњЛйСЫЁЃЫљвдЃЌЮвУЧЪЕМљЕБжаНЋЪ§ОнМЏШККЭМЦЫуМЏШКЗжПЊЃЌМЦЫуМЏШКПЩвдЫцЪБЯњЛйКЭЩ§МЖЃЌЪ§ОнМЏШКашвЊГЄЦкЮШЖЈЬсЙЉЗўЮёЁЃетСНжжЕФМЏШКХфжУвВЪЧВЛвЛбљЕФЃЌМЦЫуМЏШКгУSSDЃЌжїЙЅЁАПьЁБЃЌЪ§ОнМЏШКЃЈHBaseЃЉгУИпаЇдЦХЬЃЌжїЙЅЁАДѓЁБЁЃ
ФЧАДСПИЖЗбФиЃЌЪВУДГЁОАЯТЪЙгУЃПЮвУЧМЦЫуЙ§ЃЌШчЙћМЦЫуЪБГЄГЌЙ§7ЬьЃЌФЧУДЛЙЪЧжБНгЙКТђАќдТЕФМЏШКБШНЯЛЎЫуЁЃАДСПИЖЗбЕФМЏШКПЩвдгУгкСйЪБЭЛЗЂЕФМЦЫуШЮЮёЁЃ
ЙЄЕЅЙмРэ
ЪЙгУАЂРяЕФдЦЗўЮёЃЌзюЮќв§ШЫЕФОЭЪЧЙЄЕЅЗўЮёЁЃгЩгкЮвУЧЕФдЫЮЌЭХЖгЛсОГЃгіЕНИДдгЧвашвЊНєЦШНтОіЕФЮЪЬтЃЌЭХЖгГЩдБПЩвджБНгЭЈЙ§ЙЄЕЅЧыЧѓАЂРяЕФЙЄГЬЪІажњНтОіЁЃЙЕЭЈЮЪЬтЕФЙ§ГЬвВЪЧЮвУЧбЇЯАЕФЙ§ГЬЃЌЮвУЧЯђАЂРядЦЗўЮёЕФЙЄГЬЪІУЧбЇЕНСЫВЛЩйЕФЖЋЮїЁЃ
ШэМўЪгЭМ
ЛљгкММЪѕИХРРЃЌЮвУЧММЪѕМмЙЙжаЕФШэМўЪгЭМШчЯТЫљЪОЃК
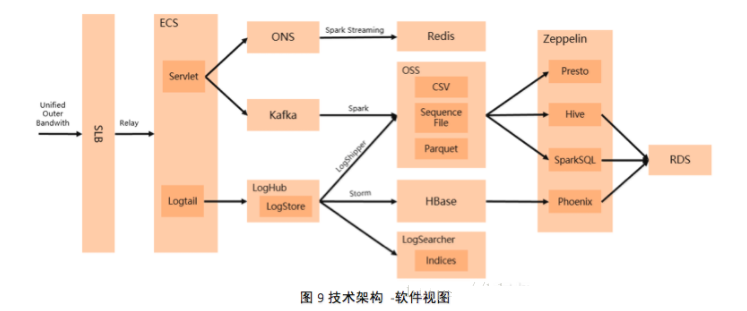
вЛаЉЪЙгУаФЕУзмНсШчЯТЃК
ИКдиОљКтSLB
дРДЃЌЮЊСЫЙмРэЗНБуЃЌЮвУЧКУЖрдЦЗўЮёЦїECSЖМПЊЭЈСЫЭтЭјЃЌЕЋЪЧЪЕМЪЪЙгУТЪВЛИпЃЌЭтЭјДјПэЕФГЩБОеМгУдЦЗўЮёЦїГЩБОКмДѓЕФвЛВПЗжЃЌЯждкЮвУЧЫљгадЦЗўЮёЦїЖМШЅЕєСЫЭтЭјДјПэЃЌЭГвЛзпИКдиОљКтSLBЃЌЙВЯэИКдиОљКтSLBЕФЭтЭјДјПэЃЌАќРЈSSHЕШЫљгагІгУЕФЖЫПкЖМЪЧгУИКдиОљКтSLBзЊЗЂЁЃИКдиОљКтSLBДјПэВЛЪмЯожЦЃЌЫйЖШЩЯРДСЫЃЌГЩБОЯТРДСЫЃЌЫуЪЧЮвУЧЖдИКдиОљКтSLBЕФвЛИіЛюгУЁЃ
дЦЗўЮёЦїECS
гЩгкЮвУЧЕФвЕЮёЛЗОГБфЛЏКмПьЃЌгааЉЛњЦїПЩФмНёЬьЛЙгагУЃЌУїЬьОЭУЛгУСЫЃЌЫљвдЮвУЧВЩгУАќдТМгздЖЏајЗбЕФФЃЪНЃЌЫцЪБдіМѕЛњЦїЃЌЫцЪБдіХфМѕХфЁЃ
ONS
вВМДАЂРяЕФШежОЗўЮёЃЌАЂРяФкВПНаMQЃЌЦфЯьгІЪБМфКмПьЃЌЭЬЭТСПКмДѓЃЌПЩвдгІгУгкЪЕЪБадЗЧГЃИпЕФГЁОАЃЌР§ШчЪЕЪБОКМлЁЃ
ШежОЗўЮёLog Service
ЦфАќКЌLogtailЃЌLogStore, LogHubЃЌLogShipperКЭLogSearchЗўЮёЃЌЦфжаШежОЭЖЕнЃЈLogShipperЃЉЙІФмКмгагУЃЌПЩвдздЖЏНЋВЩМЏЕФШежОЭЖЕнЕНЖдЯѓДцДЂOSSЃЌетбљОЭПЩвджБНгЪЙгУHiveМгдиСЫЃЌВЛЙ§ФПЧАжЛжЇГжjsonИёЪНЁЃдкЮвУЧЕФНЈвщЯТЃЌШежОЗўЮёЭХЖгНЋЛсжЇГжCSVЃЌSequenceFileКЭParquetИёЪНЃЌдЄМЦгк2017Фъ1дТЩЯЯпЁЃ
Spark
ЦфЙйЗНИјГіЕФР§згКЭАЂРяАяжњЮФЕЕРяЕФР§згЖМЪЧЛљгкScalaЕФЃЌВЛЙ§ЮвУЧЛЙЪЧбЁдёСЫгУJavaНјааSparkгІгУЕФПЊЗЂЃЌетбљЮвУЧПЊЗЂЭХЖгЕФзщНЈЛсИќМгБуРћЁЃШчЙћФмЪЙгУJava
8ЃЌФЧУДДгКЏЪ§ЪНБрГЬЗНЪНгШЦфЪЧlambdaБэДяЪНЕФНЧЖШОЭЪЎЗжНгНќScalaЕФБэЯжФмСІСЫЁЃдкЮвУЧЕФНЈвщЯТЃЌФПЧААЂРядЦаТАцБОЕФE-MapReduceвбОжЇГжСЫJava
8ЁЃ
ашвЊЬсвЛОфЃЌЪ§ОндкДѓЪ§ОнМЦЫуЗўЮёODPSЃЈЯжУћГЦMaxComputeЃЉЃЌФЧвВУЛЙиЯЕЁЃE-MapReduce
ЬсЙЉ SparkSQLЗўЮёЃЌПЩвдЮоЗьЗУЮЪДѓЪ§ОнМЦЫуЗўЮёODPSЪ§ОнЁЃЪЙгУДѓЪ§ОнМЦЫуЗўЮёODPSЕФгУЛЇвВПЩвдМгШыЕНSparkЩњЬЌЬхЯЕжаЁЃ
Storm
ФПЧАE-MapReduceвбОЬсЙЉСЫStormзщМўЃЌЯывЊЪЙгУДЫзщМўЃЌгаСНИібЁдёЃКДгШежОЗўЮёЯћЗбЃЛЛђепЭЈЙ§в§ЕМВйзїдкE-MapReduceЩЯАВзАKafkaЃЌжЇГждіМгНкЕуЁЃ
ЖдЯѓДцДЂOSS
ЖдЯѓДцДЂOSSжївЊгУгкДцДЂЃЌгыE-MapReduceНсКЯЃЌЪЕЯжСЫМЦЫугыДцДЂЕФЗжРыЁЃ
Zeppelin
етецЕФЪЧвЛИіКУЖЋЮїЃЌвЕЮёШЫдБЭЈЙ§ЫќЃЌПЩвдЭЈЙ§WebЕФаЮЪНЪЙгУHiveQL, SparkSQL, Phoenix,
PrestoЕШЖдЪ§ОнНјааЬНЫїЪНКЭНЛЛЅЪНЕФВщбЏЃЌЖјЮоашБрГЬКЭЕЧТМSSHЃЌВЂЧвПЩвдБЃДцЙ§ЭљЕФВщбЏЃЌЛЙПЩвдаЮГЩМђЕЅЕФжљзДЭМБ§ЭМЁЃЮвУЧЕФDMPЙЄГЬЪІдйвВВЛгУЮЊСЫФГвЛИіЭГМЦЪ§зжЭЈЯќаДДњТыСЫЃЌвЕЮёШЫдБздМКОЭПЩвдИуЖЈЁЃ
Phoenix
HBaseБОЩэЪЧNoSQLЪ§ОнПтЃЌНсЙЙЛЏВщбЏЪЧЦфШѕЯюЃЌЮвУЧОЭЪЧгаКмЖрOLAPЕФашЧѓЃЌЯЃЭћНЛЛЅЪНГіНсЙћЃЌдРДЕФзіЗЈЪЧздМКДДНЈHBaseЕФЖўМЖЫїв§ЃЌЖдЗЧжїМќзжЖЮНјааЬјзЊВщбЏЁЃКѓРДЗЂЯжЃЌE-MapReduceЩЯЃЌPhoenixвбОЮЊЮвУЧДюНЈКУСЫАЁЃЌЦфЫїв§ЛњжЦЩњГЩЕФHBaseЫїв§БэЃЌВЛОЭЪЧЮвУЧдРДЪжЙЄДДНЈЕФЫїв§БэТ№ЁЃгкЪЧШЋВПзЊЯђЪЙгУPhoenixНјааНЛЛЅЪНВщбЏЁЃE-MapReduceРЯАцБОЕФPhoenixЕФФЌШЯВщбЏГЌЪБЪЧ1ЗжжгЃЌЖдЮвУЧРДЫЕЬЋЖЬСЫЃЌИФВЮЪ§гжвЊжиЦєЁЃдкЮвУЧЕФНЈвщЯТЃЌФПЧАE-MapReduceаТАцБОЕФPhoenixЕФФЌШЯГЌЪБЪБГЄвбОЩшжУЮЊАыИіаЁЪБСЫЁЃ
ГЁОАОйР§
ХњСПМЦЫуЃЌLogTail + LogHub + LogShipper + OSS + Hive +
SparkSQL
ХњСПМЦЫужидкВЩМЏЃЌЪЙгУLogTailХфжУКУВЩМЏЙцдђЃЌЭЈЙ§LogShipperздЖЏЭЖЕнЕНOSSЃЌЪЙгУHiveжБНгМгдиаЮГЩЪ§ОнВжПтЃЌдкZeppelinНчУцЩЯЭЈЙ§SparkSQLжБНгВщбЏHiveжаЕФЪ§ОнЃЌећИіETLЕФЙ§ГЬЪЎЗжСїГЉЃЌМИКѕВЛгУаДШЮКЮДњТыЁЃ
НЛЛЅЪНМЦЫуЃЌLogTail + LogHub + Storm + HBase + Phoenix
ЖдгкЯьгІЪБМфвЊЧѓИќбЯИёЕФOLAPвЕЮёЃЌПЩвдвдHBaseЮЊжааФЙЙНЈOLAPЪ§ОнПтЃЌЮЊСЫЫѕЖЬЪ§ОнПЩгУЕФжмЦкЃЌПЩвдЕЅЖРвЛЬѕЭЈЕРЁЃЪЙгУLogTailВЩМЏЃЌВЂНЋLogHubжаЕФЪ§ОнЖдНгЕНStormЩЯЃЌЪЙгУStormНјаазЊЛЛВЂаДШыHBaseЃЌШЛКѓдкZeppelinЕФНчУцЩЯЪЙгУPhoenixНјааВщбЏЁЃ
ЪЕЪБМЦЫуЃЌServlet + ONS + Spark Streaming + Redis
ЖдгкЪЕЪБОКМлЕШЪЕЪБМЦЫувЕЮёЃЌПЩвдГфЗжРћгУONSЕФГЌПьЯьгІЃЈ1msвдФкЃЉЃЌГЌДѓВЂЗЂЕФЬиадЃЌЭЈЙ§Spark
StreamingНјааМЦЫуЃЌзюКѓДцДЂЕНRedisжаЁЃ
еЙЭћЮДРД
Spark 2.0 ЗЂВМСЫReleaseЃЌHadoop 3.0ЗЂВМСЫAlphaЃЌHBase 2.0
ЗЂВМСЫSNAPSHOTЃЌетаЉзщМўжаЕФКУЖраТЬиадЖМЪЧЮвУЧЪЎЗжЦкД§ЕФЃЌЮвУЧЛсУмЧаЙизЂАЂРядЦE-MapReduceаТВњЦЗЕФЗЂВМЃЌЯЃЭћдчШегУЩЯаТАцБОЕФПЊдДзщМўЁЃ
|









