| БрМЭЦМі: |
| БОЮФРДздгкjdonЃЌБОЮФжївЊНщЩмСЫStormЁЂStormКЭHadoopЕФЧјБ№ЁЂStormЕФШнДэадКЭПЩППадЕШЯрЙиФкШнЁЃ |
|
ЪВУДЪЧStormЃП
StormЪЧЃК
ПьЫйЧвПЩРЉеЙЩьЫѕ
ШнДэ
ШЗБЃЯћЯЂФмЙЛБЛДІРэ
взгкЩшжУКЭВйзї
ПЊдДЕФЗжВМЪНЪЕЪБМЦЫуЯЕЭГ
- зюГѕгЩNathan MarzПЊЗЂ
- ЪЙгУJava КЭ Clojure БраД
StormКЭHadoopжївЊЧјБ№ЪЧЪЕЪБКЭХњДІРэЕФЧјБ№ЃК

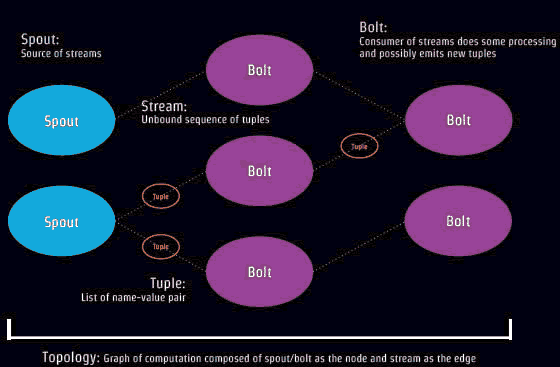
StormИХФю зщГЩЃКSpout КЭBoltзщГЩTopologyЁЃ
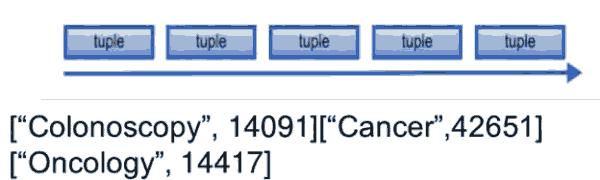
TupleЪЧStormЕФЪ§ОнФЃаЭЃЌШч['jdon',12346]
ЖрИіTupleзщГЩЪТМўСїЃК
SpoutЪЧЖСШЁашвЊЗжЮіДІРэЕФЪ§ОндДЃЌШЛКѓзЊЮЊTuplesЃЌетаЉЪ§ОндДПЩвдЪЧWebШежОЁЂ
APIЕїгУЁЂЪ§ОнПтЕШЕШЁЃSpoutЯрЕБгкЪТМўСїЕФЩњВњепЁЃ
Bolt ДІРэTuplesШЛКѓдйДДНЈаТЕФTuplesСїЃЌBoltЯрЕБгкЪТМўСїЕФЯћЗбепЁЃ
Bolt зїЮЊеце§вЕЮёДІРэепЃЌжївЊЪЕЯжДѓЪ§ОнДІРэЕФКЫаФЙІФмЃЌБШШчзЊЛЛЪ§ОнЃЌгІгУЯргІЙ§ТЫЦїЃЌМЦЫуКЭОлКЯЪ§Он(БШШчЭГМЦзмКЭЕШЕШ)
ЁЃ
вдTwitterЕФФГИіTweetЮЊАИР§ЃЌПДПДStormШчКЮДІРэЃК
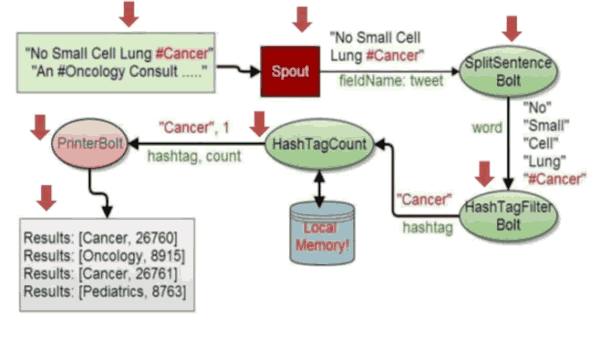
етаЉtweettЬљФкШнЪЧЃКЁАNo Small Cell Lung #Cancer(УЛгааЁЯИАћЗЮАЉЃЃАЉжЂ)ЁБ
"An #OnCology Consult...."
етаЉЬљБЛSpoutЖСШЁвдКѓЃЌВњЩњTupleЃЌзжЖЮУћЪЧtweetЃЌФкШнЪЧ"No
Small Cell Lung #Cancer"ЃЌИёЪНРрЫЦЃК['No Small Cell
Lung #Cancer',133221]ЁЃ
ШЛКѓНјШыБЛСї ЯћЗбепBoltНјааДІРэЃЌЕквЛИіBoltЪЧSplitSentenceЃЌНЋtupleФкШнНјааЗжРыЃЌНсЙћГЩЮЊЃКвЛИіИіЕЅДЪЃК"No"
"Small" "Cell" "Lung"
"#Cancer" ЃЛШЛКѓОЙ§ЕкЖўИіBoltНјааЙ§ТЫHashTagFilterДІРэЃЌHashБъЧЉЪЧЕЅДЪжагУ#БъзЂЕФЃЌвВОЭЪЧCancerЃЛдйОЙ§HasTagCountМЦЪ§ЃЌПЩвдБОЕиФкДцЛКДцетИіМЦЪ§НсЙћЃЌзюКѓЭЈЙ§PrinterBoltДђгЁГіБъЧЉЕЅДЪЭГМЦНсЙћ
ЁЃ
ЮвУЧЪЙгУStomЫљвЊзіЕФОЭЪЧБржЦSpoutКЭBoltДњТыЃК
public class
RandomSentenceSpout extends BaseRichSpout {
ЁЁЁЁSpoutOutputCollector collector;
ЁЁЁЁRandom random;
//ЖСШыЭтВПЪ§Он
ЁЁЁЁpublic void open(Map conf, TopologyContext
context, SpoutOutputCollector collector) {
ЁЁЁЁЁЁЁЁthis.collector = collector;
ЁЁЁЁЁЁЁЁrandom = new Random();
ЁЁЁЁ}
ЁЁЁЁ//ВњЩњTuple
ЁЁЁЁ public void nextTuple() {
ЁЁЁЁЁЁЁЁString[] sentences = new String[] {
ЁЁЁЁЁЁЁЁЁЁЁЁ"No Small Cell Lung #Cancer",
ЁЁЁЁЁЁЁЁЁЁЁЁ"An #OnCology Consultant apple a
day keeps the doctor away",
ЁЁЁЁЁЁЁЁЁЁЁЁ"four score and seven years ago",
ЁЁЁЁЁЁЁЁЁЁЁЁ"snow white and the seven dwarfs",
ЁЁЁЁЁЁЁЁЁЁЁЁ"i am at two with nature"
ЁЁЁЁЁЁЁЁ};
ЁЁЁЁЁЁЁЁString tweet = sentences[random.nextInt(sentences.length)];
ЁЁЁЁЁЁЁЁ//ЖЈвхзжЖЮУћ"tweet" ЕФжЕ
ЁЁЁЁЁЁЁЁcollector.emit(new Values(tweet));
ЁЁ}
ЁЁЁЁ// ЖЈвхзжЖЮУћ"tweet"
ЁЁpublic void declareOutputFields(OutputFieldsDeclarer
declarer) {
ЁЁЁЁЁЁЁЁdeclarer.declare(new Fields("tweet"));
ЁЁЁЁ}
ЁЁЁЁ@Override
ЁЁЁЁpublic void ack(Object msgId) {}
ЁЁЁЁ@Override
ЁЁЁЁpublic void fail(Object msgId) {}
} |
ЯТУцЪЧBoltЕФДњТыБраДЃК
public class
SplitSentenceBolt extends BaseRichBolt {
ЁЁЁЁOutputCollector collector;
ЁЁЁЁ@Override
ЁЁЁЁpublic void prepare(Map stormConf, TopologyContext
context, OutputCollector collector) {
ЁЁЁЁЁЁЁЁthis.collector = collector;
ЁЁЁЁ}
ЁЁЁЁ@Override ЯћЗбепМЄЛюжївЊЗНЗЈЃКЗжРыГЩЕЅИіЕЅДЪ
ЁЁЁЁpublic void execute(Tuple input) {
ЁЁЁЁЁЁЁЁfor (String s : input.getString(0).split("\\s"))
{
ЁЁЁЁЁЁЁЁЁЁЁЁcollector.emit(new Values(s));
ЁЁЁЁЁЁЁЁ}
ЁЁЁЁ}
ЁЁЁЁ@Override ЖЈвхаТЕФзжЖЮУћ
ЁЁЁЁpublic void declareOutputFields(OutputFieldsDeclarer
declarer) {
ЁЁЁЁЁЁЁЁdeclarer.declare(new Fields("word"));
ЁЁЁЁ} |
зюКѓЪЧзАХфдЫааSpoutКЭBoltЕФПЭЛЇЖЫЕїгУДњТыЃК
public class
WordCountTopology {
ЁЁЁЁpublic static void main(String[] args) throws
Exception {
ЁЁЁЁЁЁЁЁTopologyBuilder builder = new TopologyBuilder();
ЁЁЁЁЁЁЁЁbuilder.setSpout("tweet", new RandomSentenceSpout(),
2);
ЁЁЁЁЁЁЁЁbuilder.setBolt("split", new SplitSentenceBolt(),
4)
ЁЁЁЁЁЁЁЁЁЁЁЁ.shuffleGrouping("tweet")
ЁЁЁЁЁЁЁЁЁЁЁЁ.setNumTasks(8);
ЁЁЁЁЁЁЁЁbuilder.setBolt("count", new WordCountBolt(),
6)
ЁЁЁЁЁЁЁЁЁЁЁЁ.fieldsGrouping("split", new Fields("word"));
ЁЁЁЁЁЁЁЁ..ЩшжУЖрИіBolt
ЁЁЁЁЁЁЁЁConfig config = new Config();
ЁЁЁЁЁЁЁЁconfig.setNumWorkers(4);
ЁЁЁЁЁЁЁЁ
ЁЁЁЁЁЁЁЁStormSubmitter.submitTopology("wordcount",
config, builder.createTopology());
// Local testing
//LocalCluster cluster = new LocalCluster();
// cluster.submitTopology("wordcount",
config, builder.createTopology());
//Thread.sleep(10000);
//cluster.shutdown();
}
} |
дкетИіДњТыжаЖЈвхСЫвЛаЉВЮЪ§БШШчWorksЕФЪ§ФПЪЧ4ЃЌЦфКЌвхдкКѓУцЯъЯИЗжЮіЁЃ
ЯТУцЮвУЧвЊНЋЩЯУцетЖЮДњТыЗЂВМВПЪ№ЕНStormжаЃЌЪзЯШСЫНтStormЮяРэМмЙЙЭМЃК
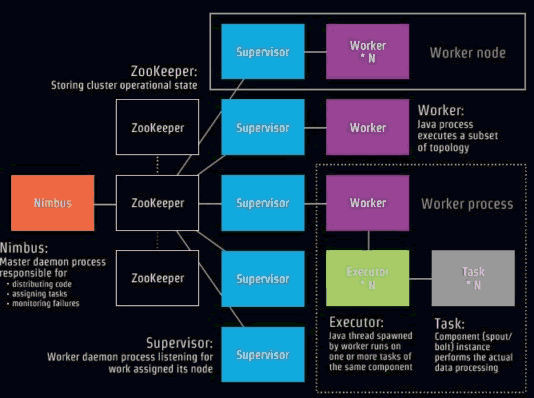
NimbusЪЧвЛИіжїКѓЬЈДІРэЦїЃЌжївЊИКд№ЃК
1.ЗЂВМЗжЗЂДњТы
2.ЗжХфШЮЮё
3.МрПиЪЇАмЁЃ
SupervisorЪЧИКд№ЕБЧАетИіНкЕуЕФКѓЬЈЙЄзїДІРэЦїЕФМрЬ§ЁЃ
WorkРрЫЦJavaЕФЯпГЬЃЌВЩШЁJDKЕФExecutor ЁЃ
ЯТУцПЊЪМНЋЮвУЧЕФДњТыВПЪ№ЕНетИіЭјТчЭиЦЫжаЃК
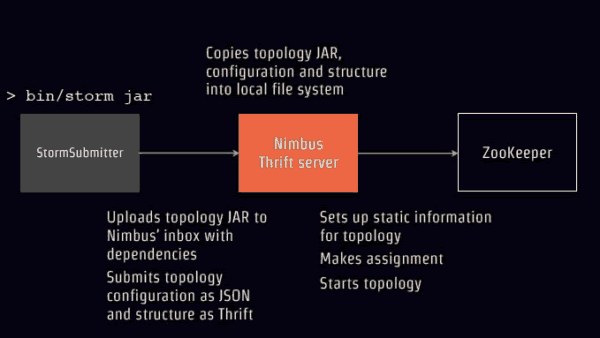
НЋДњТыJarАќЩЯДЋЕНNimbusЕФinboxЃЌАќРЈЫљгаЕФвРРЕАќЃЌШЛКѓЬсНЛЁЃ
NimbusНЋБЃДцдкБОЕиЮФМўЯЕЭГЃЌШЛКѓПЊЪМХфжУЭјТчЭиЦЫЃЌЗжХфПЊЪМЭиЦЫЁЃ
МћЯТЭМЃК
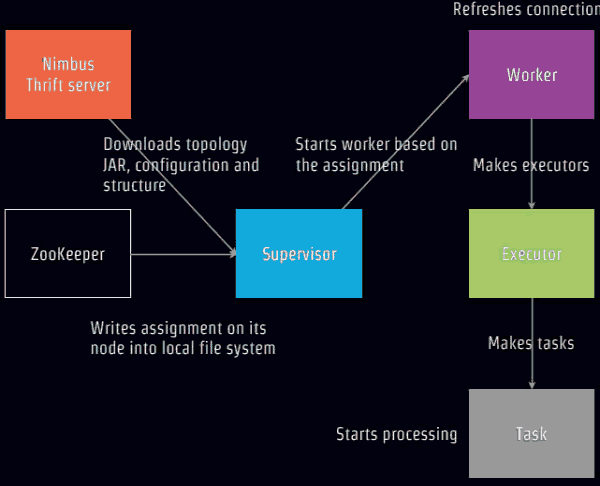
NimbusЗўЮёЦїНЋЭиЦЫJar ХфжУКЭНсЙЙЯТдиЕН SupervisorЃЌИКдиЦНКтZooKeeperЗжХфФГИіЬиЖЈЕФSupervisorЗўЮёЦїЃЌЖјSupervisorПЊЪМЛљгкХфжУЗжХфWorkЃЌWorkЕїгУJDKЕФExecutorЦєЖЏЯпГЬЃЌПЊЪМШЮЮёДІРэЁЃ
ЯТУцЪЧЮвУЧДњТыЖдЭиЦЫЗжХфЕФВЮЪ§ЪОвтЭМЃК

ExecutorЦєЖЏЕФЯпГЬЪ§ФПЪЧ12ИіЃЌзщМўЕФЪЕР§ЪЧ16ИіЃЌФЧУДШчКЮдкЪЕМЪЗўЮёЦїжаЗжХфФиЃПШчЯТЭМЃК
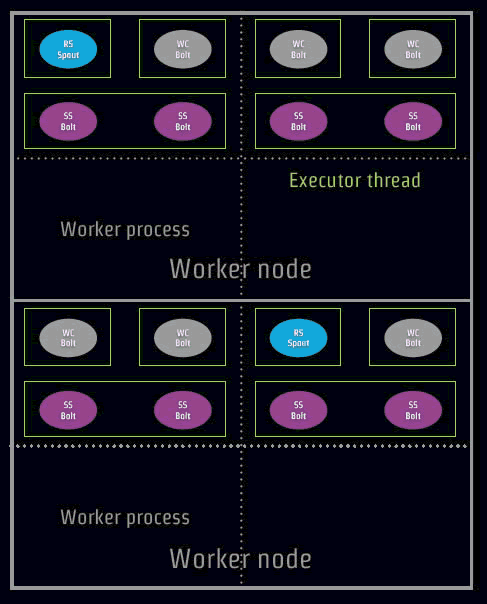
ЭМжаRsSpoutДњБэЮвУЧЕФДњТыжаRandomSentenceSpoutЃЛSplitSentenceBoltМђаДЮЊSSboltЃЛ
ЯждкПЊЪМЗжЮіStormФкВПМмЙЙЃЌЪзЯШПДПДWorkжЎМфЕФЯћЯЂДЋЕнЃЌШчЯТЭМЃЌ
WorkжЎМфЕФЭЈбЖЪЧЭЈЙ§ZeroMQЃЌЕЋЪЧYahooКѓРДЗЂЯжЪЙгУвьВНЕФNettyФмЙЛЬсЩ§StormвЛБЖадФмЃЌЪ§ОнЪЙгУKryoНјааађСаЛЏЃЌБОЕиЭЈбЖЪЙгУLmaxЕФDisruptor
ЃЌФкВПЮоашађСаЛЏЁЃ
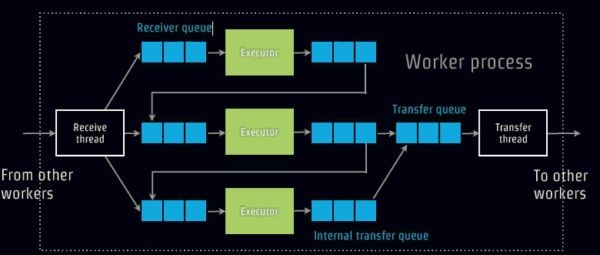
ШнДэад
ШчЯТЭМЃЌexecutorЗЂЫЭаФЬјЕНZookeeperЃЌSupervisorДгБОЕиЮФМўЖСШЁЫљдкЗўЮёЦїЕФworkerаФЬјзДЬЌЃЌШЛКѓЭЌВНЗжХфЗЂЫЭЕНzooKeeperЁЃNimbusМрПиМЏШКзДЬЌЁЃетбљФмШЗБЃworkerвЛжБЛюзХЁЃ

ШчЙћФГИіНкЕувВОЭЪЧЗўЮёЦїУЛгааФЬјЃЌNimbusНЋжиаТЗжХфаТЕФЗўЮёЦїЩЯЯпЙЄзїЁЃ
ШчЙћФГИіНкЕуЗўЮёЦїжаworkУЛгааФЬјЃЌФЧУДSupervisorНЋИКд№жиЦєЯпГЬЁЃ
ШчЙћФГИіSupervisorЭъЕАЃЌећИіДІРэе§ГЃЃЌЕЋЪЧЗжХфЕФЭЌВНЙЄзїОЭЮоЗЈНјааСЫЁЃ
ШчЙћNimbusБРРЃЃЌећИіЯЕЭГПЩвддЫааЃЌЕЋЪЧЭиЦЫЗжХфЙЄзїЮоЗЈНјааСЫЁЃ
ПЩППадЃКШЗБЃЯћЯЂБЛДІРэ
public class
RandomSentenceSpout extends BaseRichSpout {
ЁЁЁЁpublic void nextTuple() {
ЁЁЁЁЁЁЁЁ UUID msgId = getMsgId();//гУЯћЯЂIDЗЂЫЭЯћЯЂ
ЁЁЁЁЁЁЁЁcollector.emit(new Values(tweet), msgId);
ЁЁЁЁ}
ЁЁЁЁpublic void ack(Object msgId) {
ЁЁЁЁЁЁЁЁ// Do something with acked message id. ШЗШЯЯћЯЂID
ЁЁЁЁ}
ЁЁЁЁpublic void fail(Object msgId) {
ЁЁЁЁЁЁЁЁ // Do something with failed message id. ЯћЯЂIDЪЇАмСЫ
ЁЁЁЁ}
}
public class SplitSentenceBolt extends BaseRichBolt
{
ЁЁЁЁpublic void execute(Tuple input) {
ЁЁЁЁЁЁЁЁfor (String s : input.getString(0).split("\\s"))
{
ЁЁЁЁЁЁЁЁЁЁЁЁcollector.emit(input, new Values(s));
ЁЁЁЁЁЁЁЁ}
ЁЁЁЁЁЁЁЁ//ЕБећИіДЪгяЖМБЛЧаЗжКѓЃЌШЗШЯЪфШыЕФЪТМўвбОБЛНгЪмДІРэЁЃ
ЁЁЁЁЁЁЁЁcollector.ack(input);
ЁЁЁЁ}
} |
ЯТУцЪЧвЛИіAckШЗШЯСїГЬЃЌзЂвтЕНAcker Implicit boltЁЃ
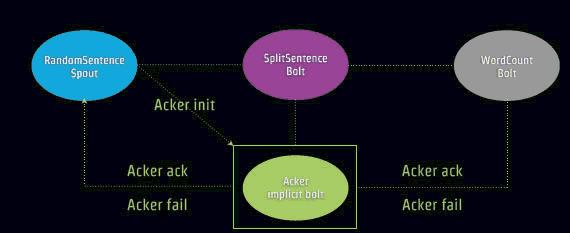
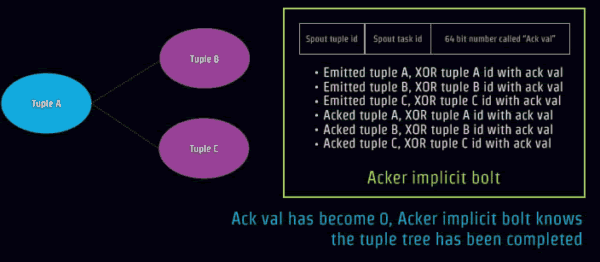
ЖдгквЛИіЪїаЮНсЙЙTupleСїЃЌвВОЭЪЧTupleРяУцЧЖЬзTupleЁЃ
ШчЙћЪТМўБЛЯТвЛИіНкЕуГЩЙІНгЪмКЭДІРэЃЌетИіНкЕуНЋИќаТЯргІГѕЪМЪТМўЕФЧЉУћЃЌЭЈЙ§вьЛђВйзїЃЌНЋЪфШыЪТМўЕФIDКЭЫљгаЛљгкИУЪфШыЪТМўВњЩњЕФЫљгаЪТМўЕФIDНјаавьЛђВйзїЃЌШчЯТЭМЃЌЪТМў
01111 ВњЩњзгЪТМў 01100, 10010, КЭ 00010, етбљЪТМў 01111ЕФЧЉУћЪЧ11100
(= 01111 (initial value) xor 01111 xor 01100 xor 10010
xor 00010).
ЕБAckжЕБфГЩ0ЃЌAcker implicit boltОЭжЊЕРtupleЪїаЮЪ§ОнМЏКЯШЋВПБЛДІРэЭъГЩЃЌвЛИіЪТЮёШЗБЃПЩППНсЪјЁЃР§ШчгяОфЗжГЩвЛИіИіЕЅДЪШЋВПЭъГЩЁЃ
StormЕФМЏШКЩшжУ
ЩшжУZooKeeper cluster
(1)АВзАStormвРРЕЕФПтАќЕНЗўЮёЦїЩЯ:
- ZeroMQ 2.1.7 and JZMQ
- Java 6 and Python 2.6.6
- unzip
(2)ЯТдиНтбЙStormЁЃ
ЬюаДЧПжЦадХфжУЕНstorm.yaml
гУstormНХБОЦєЖЏЪиЛЄСїГЬЕФМрЖН
ЭЈЙ§WebНчУцФмЙЛЙлВьЙмРэЭиЦЫЭјТчЧщПіКЭзщМўЧщПіЁЃ |









