| БрМЭЦМі: |
БОЮФРДздгкВЉПЭдАЃЌБОЮФНсКЯвЛИіаЁбљР§ЃЌНјааФЃаЭБрГЬЃЌДДНЈЪ§ОнПђСїКЭЪ§ОнМЏСївдМАЙмРэСїЪНВщбЏЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
|
|
ИХРР
Structured Streaming ЪЧвЛИіПЩЭиеЙЃЌШнДэЕФЃЌЛљгкSpark SQLжДаав§ЧцЕФСїДІРэв§ЧцЁЃЪЙгУаЁСПЕФОВЬЌЪ§ОнФЃФтСїДІРэЁЃАщЫцСїЪ§ОнЕФЕНРДЃЌSpark
SQLв§ЧцЛсж№НЅСЌајДІРэЪ§ОнВЂЧвИќаТНсЙћЕНзюжеЕФTableжаЁЃФуПЩвддкSpark SQLЩЯв§ЧцЩЯЪЙгУDataSet/DataFrame
APIДІРэСїЪ§ОнЕФОлМЏЃЌЪТМўДАПкЃЌКЭСїгыХњДЮЕФСЌНгВйзїЕШЁЃзюКѓStructured Streaming
ЯЕЭГПьЫйЃЌЮШЖЈЃЌЖЫЕНЖЫЕФЧЁКУвЛДЮБЃжЄЃЌжЇГжШнДэЕФДІРэЁЃ
аЁбљР§
| import
org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder
.appName("StructuredNetworkWordCount")
.getOrCreate()
import spark.implicits._
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
// Split the lines into words
val words = lines.as[String].flatMap(_.split("
"))
// Generate running word count
val wordCounts = words.groupBy("value").count()
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination() |
БрГЬФЃаЭ
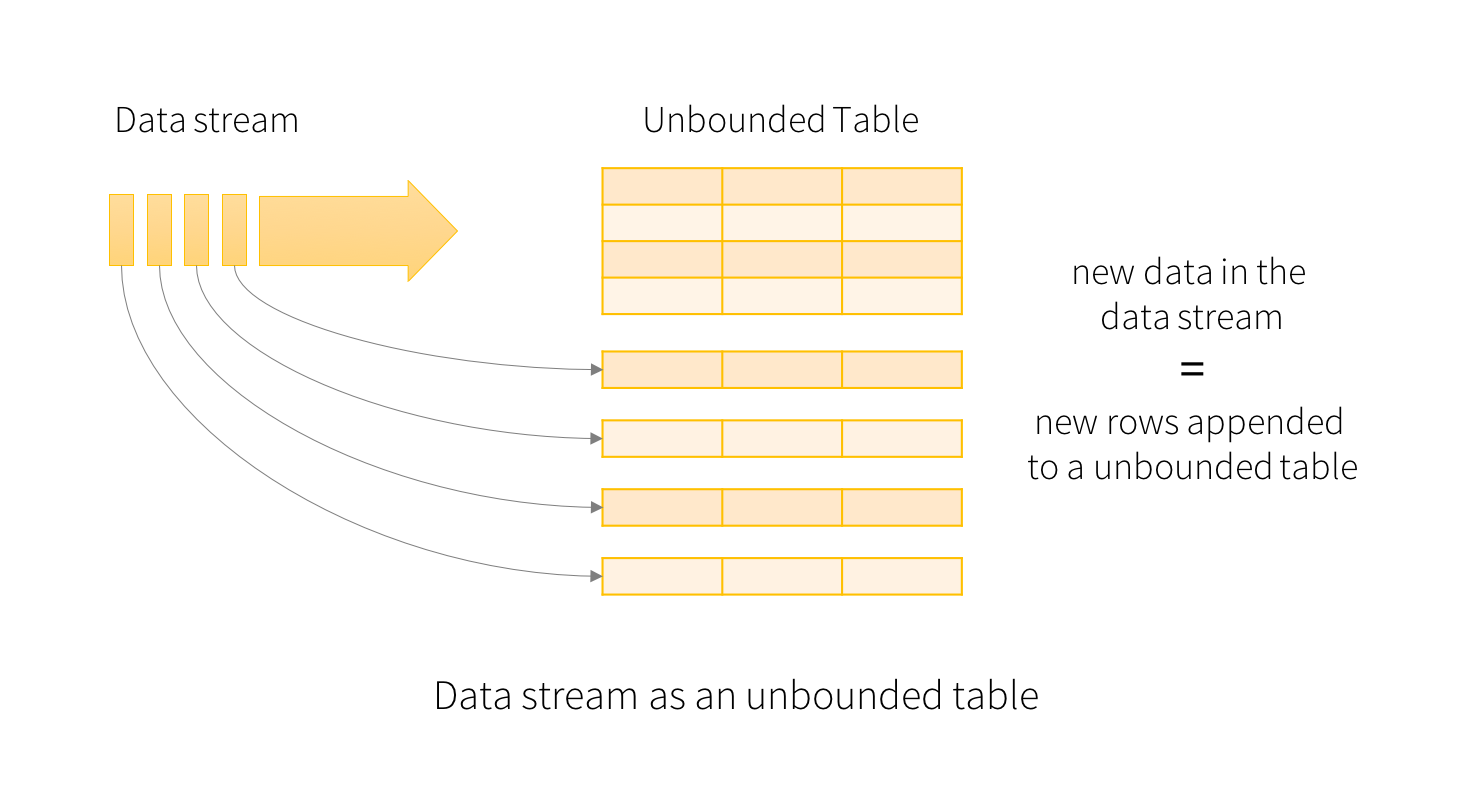
НсЙЙЛЏСїЕФЙиМќЫМЯыЪЧНЋЪЕЪБЪ§ОнСїЪгЮЊвЛИіСЌајИНМгЕФБэ
ЛљБОИХФю
НЋЪфШыЕФЪ§ОнЕБГЩвЛИіЪфШыЕФБэИёЃЌУПвЛИіЪ§ОнЕБГЩЪфШыБэЕФвЛИіаТааЁЃ
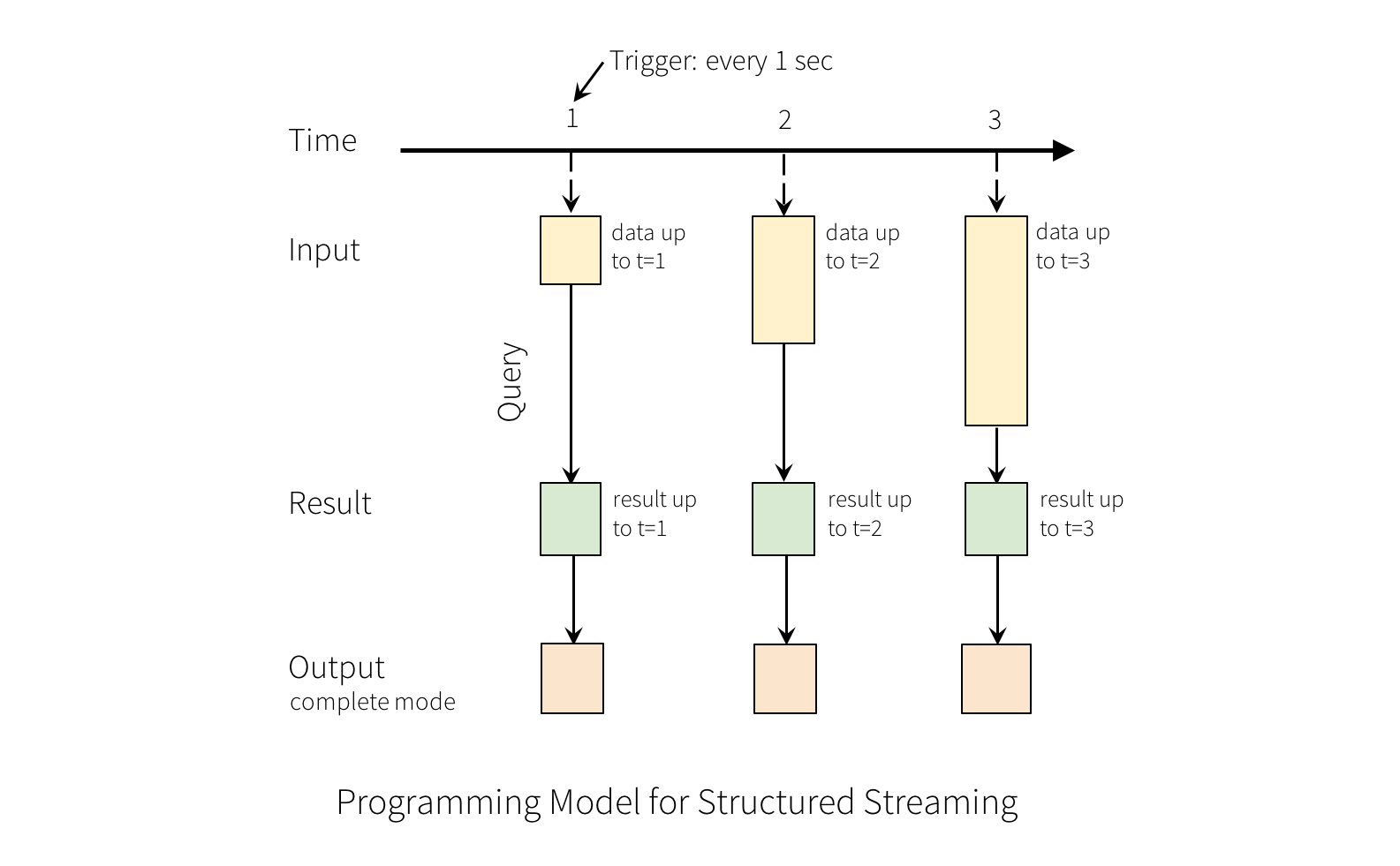
"Output"ЪЧаДШыЕНЭтВПДцДЂЕФаДЗНЪНЃЌаДШыЗНЪНгаВЛЭЌЕФФЃЪНЃК
1.CompleteФЃЪНЃК НЋећИіИќаТБэаДШыЕНЭтВПДцДЂЃЌаДШыећИіБэЕФЗНЪНгЩДцДЂСЌНгЦїОіЖЈЁЃ
2.AppendФЃЪНЃКжЛгаздЩЯДЮДЅЗЂКѓдкНсЙћБэжаИНМгЕФаТааНЋБЛаДШыЭтВПДцДЂЦїЁЃетНіЪЪгУгкНсЙћБэжаЕФЯжгаааВЛЛсИќИФЕФВщбЏЁЃ
3.UpdateФЃЪНЃКжЛгаздЩЯДЮДЅЗЂКѓдкНсЙћБэжаИќаТЕФааНЋБЛаДШыЭтВПДцДЂЦїЃЈдкSpark
2.0жаЩаВЛПЩгУЃЉЁЃзЂвтЃЌетгыЭъШЋФЃЪНВЛЭЌЃЌвђЮЊДЫФЃЪНВЛЪфГіЮДИќИФЕФааЁЃ
ДІРэЪТМўЪБМфКЭбгГйЪ§Он
ЪТМўЪБМфЪЧЧЖШыдкЪ§ОнБОЩэжаЕФЪБМфЁЃЖдгкаэЖргІгУГЬађЃЌФњПЩФмЯЃЭћдкДЫЪТМўЪБМфВйзїЁЃР§ШчЃЌШчЙћвЊЛёШЁIoTЩшБИУПЗжжгЩњГЩЕФЪТМўЪ§ЃЌдђПЩФмашвЊЪЙгУЩњГЩЪ§ОнЕФЪБМфЃЈМДЪ§ОнжаЕФЪТМўЪБМфЃЉЃЌЖјВЛЪЧSparkНгЪеЕФЪБМфЫћУЧЁЃДЫЪТМўЪБМфдкДЫФЃаЭжаЗЧГЃздШЛЕиБэЪО
- РДздЩшБИЕФУПИіЪТМўЖМЪЧБэжаЕФвЛааЃЌЪТМўЪБМфЪЧИУаажаЕФвЛИіСажЕЁЃетдЪаэЛљгкДАПкЕФОлКЯЃЈР§ШчУПЗжжгЕФЪТМўЪ§ЃЉНіНіЪЧХМЪ§ЪБМфСаЩЯЕФЬиЪтРраЭЕФЗжзщКЭОлКЯ
- УПИіЪБМфДАПкЪЧвЛИізщЃЌВЂЧвУПвЛааПЩвдЪєгкЖрИіДАПк/зщЁЃвђДЫЃЌПЩвддкОВЬЌЪ§ОнМЏЃЈР§ШчЃЌРДздЪеМЏЕФЩшБИЪТМўШежОЃЉвдМАЪ§ОнСїЩЯвЛжТЕиЖЈвхетжжЛљгкЪТМўЪБМфДАЕФОлКЯВщбЏЃЌЪЙЕУгУЛЇЕФЩњЛюИќШнвзЁЃ
ДЫЭтЃЌИУФЃаЭздШЛЕиДІРэЛљгкЦфЪТМўЪБМфБШдЄЦкЕНДяЕФЪ§ОнЁЃгЩгкSparkе§дкИќаТНсЙћБэЃЌвђДЫЕБДцдкбгГйЪ§ОнЪБЃЌЫќПЩвдЭъШЋПижЦИќаТОЩОлКЯЃЌвдМАЧхГ§ОЩОлКЯвдЯожЦжаМфзДЬЌЪ§ОнЕФДѓаЁЁЃгЩгкSpark
2.1ЃЌЮвУЧжЇГжЫЎгЁЃЌдЪаэгУЛЇжИЖЈКѓЦкЪ§ОнЕФуажЕЃЌВЂдЪаэв§ЧцЯргІЕиЧхГ§ОЩЕФзДЬЌЁЃЩдКѓНЋдкЁАДАПкВйзїЁБВПЗжжаЖдДЫНјааЯъЯИЫЕУїЁЃ
ШнДэгявх
ЬсЙЉЖЫЕНЖЫЕФвЛДЮадгявхЪЧНсЙЙЛЏСїЕФЩшМЦБГКѓЕФЙиМќФПБъжЎвЛЁЃЮЊСЫЪЕЯжетвЛЕуЃЌЮвУЧЩшМЦСЫНсЙЙЛЏСїдДЃЌНгЪеЦїКЭжДаав§ЧцЃЌвдПЩППЕиИњзйДІРэЕФШЗЧаНјеЙЃЌвдБуЫќПЩвдЭЈЙ§жиаТЦєЖЏКЭ/ЛђжиаТДІРэРДДІРэШЮКЮРраЭЕФЙЪеЯЁЃМйЖЈУПИіСїдДОпгаЦЋвЦСПЃЈРрЫЦгкKafkaЦЋвЦСПЛђKinesisађСаКХЃЉвдИњзйСїжаЕФЖСШЁЮЛжУЁЃв§ЧцЪЙгУМьВщЕуКЭдЄаДШежОРДМЧТМУПИіДЅЗЂЦїжае§дкДІРэЕФЪ§ОнЕФЦЋвЦЗЖЮЇЁЃСїНгЪеЦїБЛЩшМЦЮЊгУгкДІРэдйДІРэЕФУнЕШЁЃНсКЯЪЙгУПЩжиЗХдДКЭУнЕШЫоЃЌНсЙЙЛЏСїПЩвдШЗБЃдкШЮКЮЙЪеЯЯТЕФЖЫЕНЖЫЕФвЛДЮадгявхЁЃ
ЪЙгУDataFrameКЭDataSet API
ДгSpark 2.0ПЊЪМЃЌDataFramesКЭDatasetsПЩвдБэЪООВЬЌЃЌгаНчЪ§ОнЃЌвдМАСїЪНЃЌЮоНчЪ§ОнЁЃгыОВЬЌDataSets/
DataFramesРрЫЦЃЌФњПЩвдЪЙгУЙЋЙВШыПкЕу SparkSessionЃЈScala / Java
/ Python ЮФЕЕЃЉДгСїдДДДНЈСї DataFrames /DataSetsЃЌВЂЖдЫќУЧгІгУгыОВЬЌ
DataFrames / DatasetsЯрЭЌЕФВйзїЁЃШчЙћФњВЛЪьЯЄ Datasets / DataFramesЃЌЧПСвНЈвщФњЪЙгУ
DataFrame / DatasetБрГЬжИФЯЪьЯЄЫќУЧЁЃ
ДДНЈЪ§ОнПђСїКЭЪ§ОнМЏСї
Streaming DataFrames ПЩвдЭЈЙ§ SparkSession.readStreamЃЈЃЉЗЕЛиЕФ
DataStreamReader НгПкЃЈScala / Java / Python docsЃЉДДНЈЁЃРрЫЦгкгУгкДДНЈОВЬЌDataFrameЕФЖСШЁНгПкЃЌФњПЩвджИЖЈдД
- Ъ§ОнИёЪНЃЌФЃЪНЃЌбЁЯюЕШЕФЯъЯИаХЯЂЁЃ
Ъ§ОндД
дкSpark 2.0ЃЌгаМИИіФкжУЕФЪ§ОндДЃК
1.ЮФМўдДЃКНЋаДШыФПТМжаЕФЮФМўЖСШЁЮЊЪ§ОнСїЁЃжЇГжЕФЮФМўИёЪНгаtextЃЌcsvЃЌjsonЃЌparquetЁЃЧыВЮдФDataStreamReaderНчУцЕФЮФЕЕвдЛёШЁИќаТЕФСаБэЃЌвдМАУПжжЮФМўИёЪНжЇГжЕФбЁЯюЁЃзЂвтЃЌЮФМўБиаыдзгЕиЗХжУдкИјЖЈФПТМжаЃЌдкДѓЖрЪ§ЮФМўЯЕЭГжаЃЌПЩвдЭЈЙ§ЮФМўвЦЖЏВйзїРДЪЕЯжЁЃ
2.KafkaдДЃКДгkafkaРШЁЪ§ОнЃЌжЇГж kafka broker
versions 0.10.0 or higher. Дг kafka МЏГЩжИФЯЛёШЁИќЖраХЯЂЁЃ
3.SocketдДЃЈВтЪдгУЃЉЃКДгЬзНгзжСЌНгЖСШЁUTF8ЮФБОЪ§ОнЁЃМрЬ§ЗўЮёЦїЬзНгзждкЧ§ЖЏГЬађЁЃзЂвтЃЌетгІИУНігУгкВтЪдЃЌвђЮЊетВЛЬсЙЉЖЫЕНЖЫШнДэБЃжЄ
етаЉЪОР§ЩњГЩЮоРраЭЕФСїЪНDataFramesЃЌетвтЮЖзХдкБрвыЪБВЛМьВщDataFrameЕФФЃЪНЃЌНідкЬсНЛВщбЏЪБдкдЫааЪБМьВщЁЃвЛаЉВйзїЃЌШчmapЃЌflatMapЕШЃЌашвЊдкБрвыЪБжЊЕРРраЭЁЃвЊзіЕНетаЉЃЌФуПЩвдЪЙгУгыОВЬЌDataFrameЯрЭЌЕФЗНЗЈНЋетаЉЮоРраЭЕФСїDataFramesзЊЛЛЮЊРраЭЛЏСїЪ§ОнМЏЁЃгаЙиИќЖрЯъЯИаХЯЂЃЌЧыВЮдФSQLБрГЬжИФЯЁЃДЫЭтЃЌгаЙижЇГжЕФСїУНЬхдДЕФИќЖрЯъЯИаХЯЂНЋдкЮФЕЕжаЩдКѓЬжТлЁЃ
Ъ§ОнПђ/Ъ§ОнМЏСїЕФФЃЪНЭЦРэКЭЗжЧј
ФЌШЯЧщПіЯТЃЌЛљгкЮФМўЕФдДЕФНсЙЙЛЏСївЊЧѓФњжИЖЈФЃЪНЃЌЖјВЛЪЧвРППSparkздЖЏЭЦЖЯЁЃДЫЯожЦШЗБЃМДЪЙдкЗЂЩњЙЪеЯЕФЧщПіЯТЃЌвЛжТЕФФЃЪНвВНЋгУгкСїЪНВщбЏЁЃЖдгкСйЪБгУР§ЃЌПЩвдЭЈЙ§НЋ
spark . sql . streaming . schemaInference ЩшжУЮЊtrueРДжиаТЦєгУФЃЪНЭЦЖЯЁЃ
ЕБУћЮЊ/ key = value /ЕФзгФПТМДцдкЪБЃЌЗЂЩњЗжЧјЗЂЯжЃЌВЂЧвСаБэНЋздЖЏЕнЙщЕНетаЉФПТМжаЁЃШчЙћетаЉСаГіЯждкгУЛЇЬсЙЉЕФФЃЪНжаЃЌЫќУЧНЋгЩSparkИљОне§дкЖСШЁЕФЮФМўЕФТЗОЖЬюГфЁЃЕБВщбЏПЊЪМЪБЃЌзщГЩЗжЧјЗНАИЕФФПТМБиаыДцдкЃЌВЂЧвБиаыБЃГжОВЬЌЁЃР§ШчЃЌПЩвдЬэМг/
data / year = 2016 / when / data / year = 2015 /ДцдкЃЌЕЋЪЧИќИФЗжЧјСаЪЧЮоаЇЕФЃЈМДЭЈЙ§ДДНЈФПТМ/
data / date = 2016-04-17 /ЃЉЁЃ
СїЪНDataFrames/DatasetsЩЯЕФВйзї
ФњПЩвдЖдСїЪНDataFrames /Ъ§ОнМЏгІгУИїжжВйзї - ДгЮоРраЭЃЌРрЫЦSQLЕФВйзїЃЈР§ШчselectЃЌwhereЃЌgroupByЃЉЕНРраЭЛЏЕФRDDРрВйзїЃЈР§ШчmapЃЌfilterЃЌflatMapЃЉЁЃгаЙиИќЖрЯъЯИаХЯЂЃЌЧыВЮдФSQLБрГЬжИФЯЁЃШУЮвУЧРДПДПДвЛаЉФуПЩвдЪЙгУЕФЪОР§ВйзїЁЃ
ЛљБОВйзї - бЁдёЃЌЭЖгАЃЌОлКЯ
| case
class DeviceData(device: String, type: String,
signal: Double, time: DateTime)
val df: DataFrame = ... // streaming DataFrame
with IOT device data with schema { device: string,
type: string, signal: double, time: string }
val ds: Dataset[DeviceData] = df.as[DeviceData]
// streaming Dataset with IOT device data
// Select the devices which have signal more
than 10
df.select("device").where("signal
> 10") // using untyped APIs
ds.filter(_.signal > 10).map(_.device) //
using typed APIs
// Running count of the number of updates for
each device type
df.groupBy("type").count() // using
untyped API
// Running average signal for each device type
import org.apache.spark.sql.expressions.scalalang.typed._
ds.groupByKey(_.type).agg(typed.avg(_.signal))
// using typed API |
ЪТМўЪБМфЩЯЕФДАПкВйзї
ЛЌЖЏЪТМўЪБМфДАПкЩЯЕФОлКЯЭЈЙ§НсЙЙЛЏСїжБНгНјааЁЃРэНтЛљгкДАПкЕФОлКЯЕФЙиМќЫМЯыгыЗжзщОлКЯЗЧГЃЯрЫЦЁЃдкЗжзщОлКЯжаЃЌЮЊгУЛЇжИЖЈЕФЗжзщСажаЕФУПИіЮЈвЛжЕЮЌЛЄОлКЯжЕЃЈР§ШчМЦЪ§ЃЉЁЃдкЛљгкДАПкЕФОлКЯЕФЧщПіЯТЃЌЖдгкааЕФЪТМўЪБМфТфШыЕФУПИіДАПкЮЌГжОлКЯжЕЁЃШУЮвУЧгУВхЭМРДРэНтетвЛЕуЁЃ
ЯыЯѓвЛЯТЃЌЮвУЧЕФПьЫйЪОР§БЛаоИФЃЌСїЯждкАќКЌаавдМАЩњГЩааЕФЪБМфЁЃЮвУЧВЛЯыдЫаазжЪ§ЃЌЖјЪЧМЦЫу10ЗжжгФкЕФзжЪ§ЃЌУП5ЗжжгИќаТвЛДЮЁЃвВОЭЪЧЫЕЃЌдк10ЗжжгДАПк12ЃК00-12ЃК10,12ЃК05-12ЃК15,12ЃК10-12ЃК20ЕШжЎМфНгЪеЕФДЪжаЕФзжЪ§ЁЃзЂвтЃЌ12:00
-12ЃК10втЮЖзХЪ§Ондк12:00жЎКѓЕЋдк12:10жЎЧАЕНДяЁЃЯждкЃЌПМТЧдк12:07ЪеЕНЕФвЛИізжЁЃетИіЕЅДЪгІИУдіМгЖдгІгкСНИіДАПк12:00
- 12:10КЭ12:05 - 12:15ЕФМЦЪ§ЁЃвђДЫЃЌМЦЪ§НЋЭЈЙ§ЗжзщМќЃЈМДзжЃЉКЭДАПкЃЈПЩвдДгЪТМўЪБМфМЦЫуЃЉРДЫїв§ЁЃ
НсЙћБэНЋШчЯТЫљЪОЃК
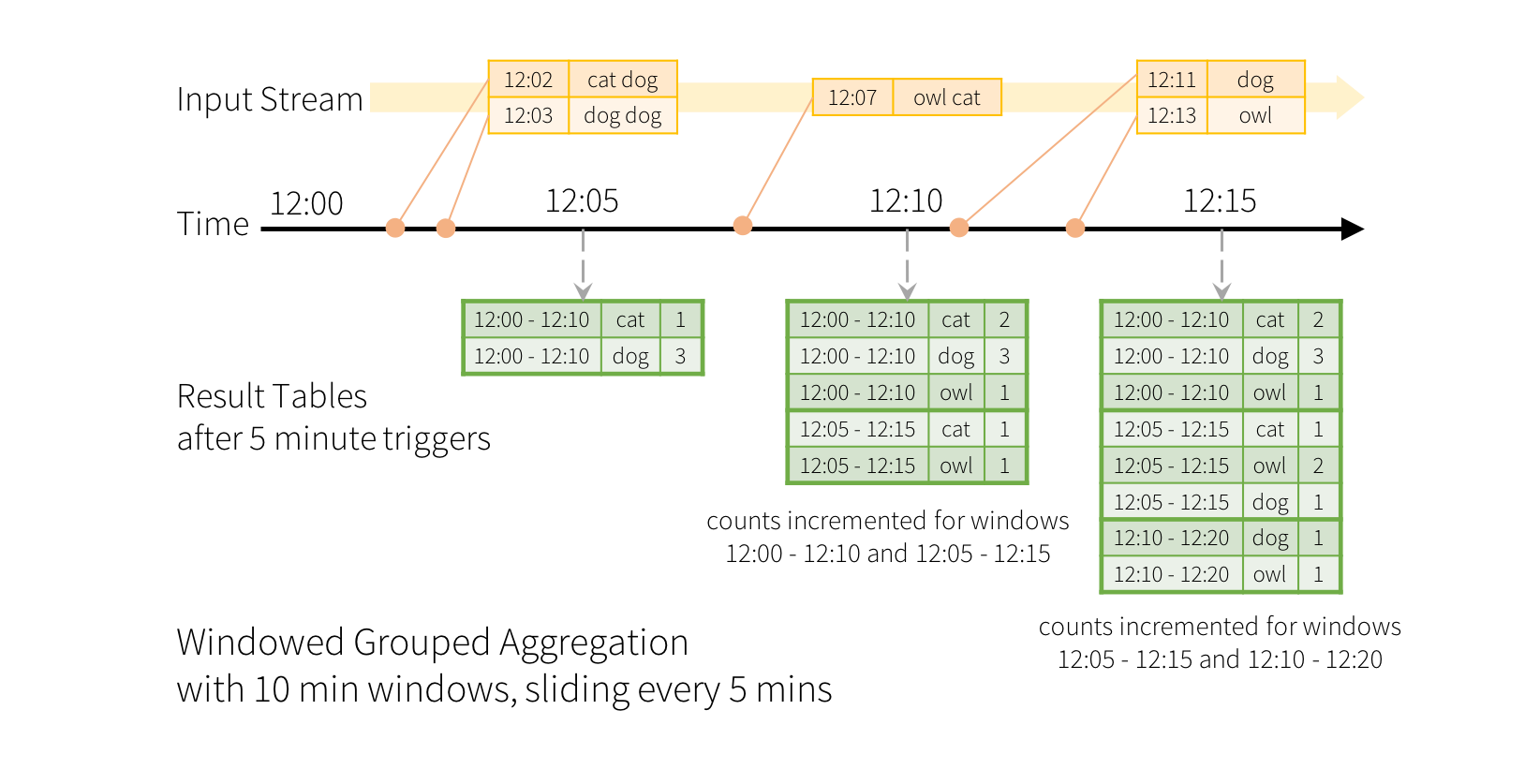
гЩгкДЫДАПкРрЫЦгкЗжзщЃЌвђДЫдкДњТыжаЃЌПЩвдЪЙгУgroupByЃЈЃЉКЭwindowЃЈЃЉВйзїРДБэЪОДАПкЛЏОлКЯЁЃФњПЩвддкScala
/ Java / PythonжаВщПДвдЯТЪОР§ЕФЭъећДњТыЁЃ
ДІРэбгГйЪ§ОнКЭЫЎЮЛЯп
ЯждкПМТЧШчЙћЪТМўжаЕФвЛИіЕНДягІгУГЬађЕФГйЕНЛсЗЂЩњЪВУДЁЃР§ШчЃЌР§ШчЃЌдк12:04ЃЈМДЪТМўЪБМфЃЉЩњГЩЕФДЪПЩвдгЩгІгУдк12:11НгЪеЕНЁЃгІгУГЬађгІЪЙгУЪБМф12:04ЖјВЛЪЧ12:11РДИќаТДАПк12:00
- 12:10ЕФОЩМЦЪ§ЁЃетдкЮвУЧЕФЛљгкДАПкЕФЗжзщжаздШЛЕиЗЂЩњ - НсЙЙЛЏСїПЩвдГЄЪБМфЕиБЃГжВПЗжОлКЯЕФжаМфзДЬЌЃЌЪЙЕУЭэЦкЪ§ОнПЩвде§ШЗЕиИќаТОЩДАПкЕФОлМЏЃЌШчЯТЫљЪОЁЃ
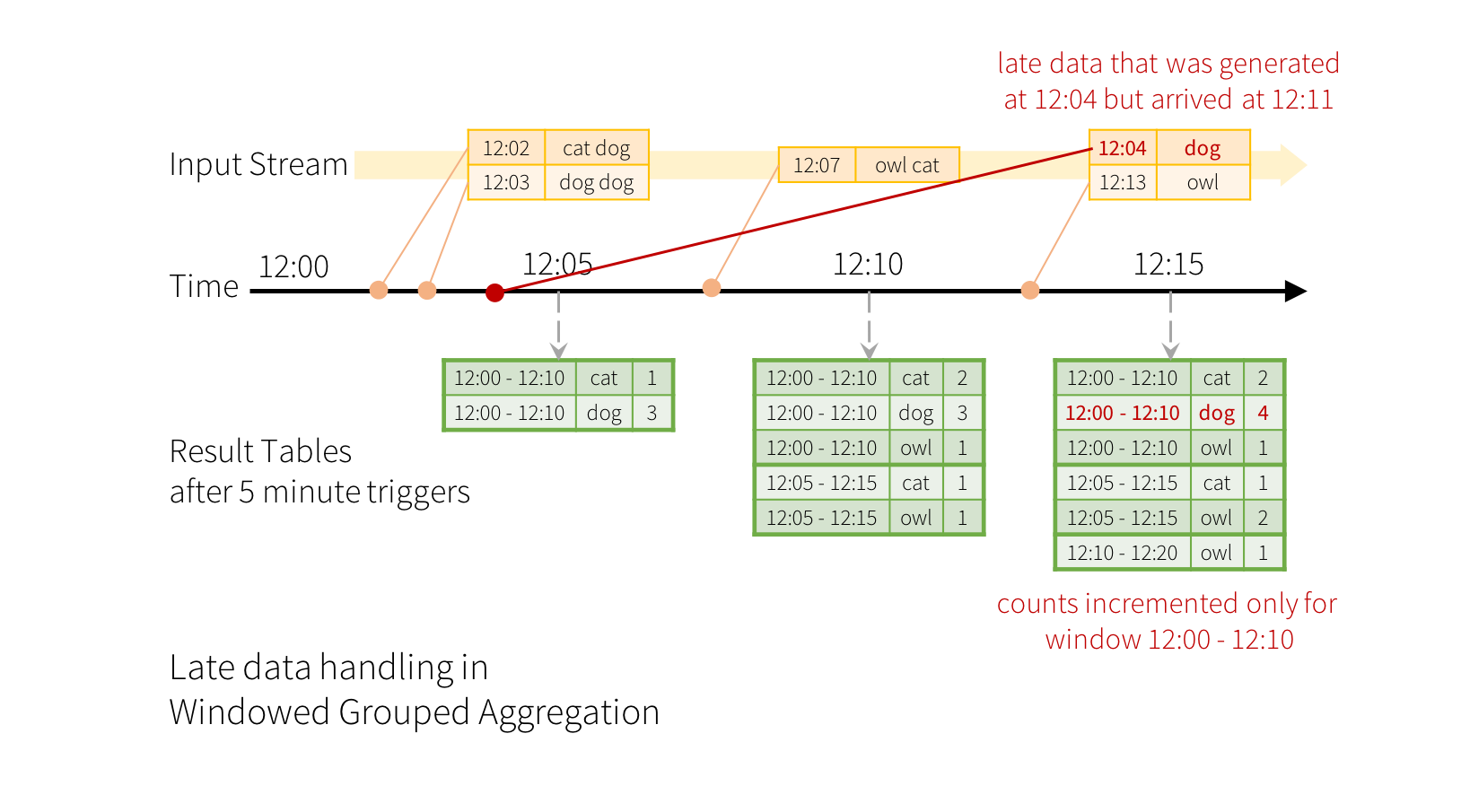
ЕЋЪЧЃЌвЊдЫааДЫВщбЏЕФЬьЪ§ЃЌЯЕЭГБиаыАѓЖЈЦфРлЛ§ЕФжаМфФкДцжазДЬЌЕФЪ§СПЁЃетвтЮЖзХЯЕЭГашвЊжЊЕРКЮЪБПЩвдДгФкДцжазДЬЌЩОГ§ОЩОлКЯЃЌвђЮЊгІгУГЬађНЋВЛдйНгЪеИУОлКЯЕФбгГйЪ§ОнЁЃЮЊСЫЪЕЯжетвЛЕуЃЌдкSpark
2.1жаЃЌЮвУЧв§ШыСЫЫЎгЁЃЌШУЮвУЧЕФв§ЧцздЖЏИњзйЪ§ОнжаЕФЕБЧАЪТМўЪБМфЃЌВЂГЂЪдЯргІЕиЧхРэОЩЕФзДЬЌЁЃФњПЩвдЭЈЙ§жИЖЈЪТМўЪБМфСаКЭИљОнЪТМўЪБМфдЄМЦЪ§ОнбгГйЕФуажЕРДЖЈвхВщбЏЕФЫЎгЁЁЃЖдгкдкЪБМфTПЊЪМЕФЬиЖЈДАПкЃЌв§ЧцНЋБЃГжзДЬЌВЂдЪаэКѓЦкЪ§ОнИќаТзДЬЌЃЌжБЕНЃЈгЩв§ЧцПДЕНЕФзюДѓЪТМўЪБМф
- КѓЦкуажЕ> TЃЉЁЃЛЛОфЛАЫЕЃЌуажЕФкЕФЭэЪ§ОнНЋБЛОлКЯЃЌЕЋЭэгкуажЕЕФЪ§ОнНЋБЛЖЊЦњЁЃШУЮвУЧгУвЛИіР§згРДРэНтетИіЁЃЮвУЧПЩвдЪЙгУwithWatermarkЃЈЃЉдкЩЯУцЕФР§згжаЧсЫЩЖЈвхЫЎгЁЃЌШчЯТЫљЪОЁЃ
| import
spark.implicits._
val words = ... // streaming DataFrame of schema
{ timestamp: Timestamp, word: String }
// Group the data by window and word and compute
the count of each group
val windowedCounts = words
.withWatermark("timestamp", "10
minutes")
.groupBy(
window($"timestamp", "10 minutes",
"5 minutes"),
$"word")
.count() |
дкетИіР§згжаЃЌЮвУЧЖЈвхВщбЏЕФЫЎгЁЖдСаЁАtimestampЁБЕФжЕЃЌВЂЧвЛЙЖЈвхЁА10ЗжжгЁБзїЮЊдЪаэЪ§ОнГЌЪБЕФуажЕЁЃШчЙћДЫВщбЏдкAppendЪфГіФЃЪНЃЈЩдКѓдкЁАЪфГіФЃЪНЁБВПЗжжаЬжТлЃЉжадЫааЃЌдђв§ЧцНЋДгСаЁАtimestampЁБИњзйЕБЧАЪТМўЪБМфЃЌВЂдкзюжеШЗЖЈДАПкМЦЪ§КЭЬэМгжЎЧАЕШД§ЪТМўЪБМфЕФЖюЭтЁА10ЗжжгЁБЫћУЧЕННсЙћБэЁЃетЪЧвЛИіР§жЄЁЃ
ШчЭМЫљЪОЃЌгЩв§ЧцИњзйЕФзюДѓЪТМўЪБМфЪЧРЖЩЋащЯпЃЌВЂЧвдкУПИіДЅЗЂЕФПЊЪМДІЩшжУЮЊЃЈзюДѓЪТМўЪБМф - '10Зжжг'ЃЉЕФЫЎгЁЪЧКьЩЋЯпЁЃР§ШчЃЌЕБв§ЧцЙлВьЪ§ОнЃЈ12:14ЃЌЙЗЃЉЃЌЫќНЋЯТвЛИіДЅЗЂЦїЕФЫЎгЁЩшжУЮЊ12:04ЁЃЖдгкДАПк12:00
- 12:10ЃЌВПЗжМЦЪ§БЃГжЮЊФкВПзДЬЌЃЌЖјЯЕЭГе§дкЕШД§бгГйЪ§ОнЁЃдкЯЕЭГЗЂЯжЪ§ОнЃЈМДЃЈ12:21ЃЌowlЃЉЃЉЪЙЕУЫЎгЁГЌЙ§12:10жЎКѓЃЌВПЗжМЦЪ§БЛзюжеШЗЖЈВЂИНМгЕНБэЁЃДЫМЦЪ§НЋВЛЛсНјвЛВНИќИФЃЌвђЮЊЫљгаГЌЙ§12:10ЕФЁАЬЋЭэЁБЪ§ОнНЋБЛКіТдЁЃ
ЧызЂвтЃЌдкзЗМгЪфГіФЃЪНЯТЃЌЯЕЭГБиаыЕШД§ЁАбгГйуажЕЁБЪБМфВХФмЪфГіДАПкЕФОлКЯЁЃШчЙћЪ§ОнПЩФмКмЭэЃЌЃЈР§Шч1ЬьЃЉЃЌВЂЧвФњЯЃЭћВПЗжМЦЪ§ЖјВЛЕШД§вЛЬьЃЌетПЩФмВЛЪЧРэЯыЕФЁЃНЋРДЃЌЮвУЧНЋЬэМгИќаТЪфГіФЃЪНЃЌетНЋдЪаэУПДЮИќаТОлКЯаДШыЕНУПИіДЅЗЂЦїЁЃ
гУгкЧхГ§ОлКЯзДЬЌЕФЫЎгЁЕФЬѕМўживЊЕФЪЧвЊзЂвтЃЌЫЎгЁгІЕБТњзувдЯТЬѕМўвдЧхГ§ОлКЯВщбЏжаЕФзДЬЌЃЈДгSpark
2.1ПЊЪМЃЌНЋРДЛсИФБфЃЉЁЃ
1.ЪфГіФЃЪНБиаыЮЊзЗМгЁЃЭъГЩФЃЪНвЊЧѓБЃСєЫљгаОлКЯЪ§ОнЃЌвђДЫВЛФмЪЙгУЫЎгЁРДЩОГ§жаМфзДЬЌЁЃгаЙиУПжжЪфГіФЃЪНЕФгявхЕФЯъЯИЫЕУїЃЌЧыВЮМћЁАЪфГіФЃЪНЁБВПЗжЁЃ
2.ОлКЯБиаыОпгаЪТМўЪБСаЃЌЛђЪТМўЪБСаЩЯЕФДАПкЁЃ
3.withWatermarkБиаыдкгыОлКЯжаЪЙгУЕФЪБМфДССаЯрЭЌЕФСаЩЯЕїгУЁЃР§ШчЃЌ
df.withWatermark ЃЈЁАtimeЁБЃЌЁА1 minЁБЃЉЁЃgroupByЃЈЁАtime2ЁБЃЉЁЃcountЃЈЃЉдкAppendЪфГіФЃЪНЯТЮоаЇЃЌвђЮЊЫЎгЁЪЧдкгыОлКЯСаВЛЭЌЕФСаЩЯЖЈвхЕФЁЃ
4.ЦфжадквЊЪЙгУЫЎгЁЯИНкЕФОлКЯжЎЧАБиаыЕїгУwithWatermarkЁЃР§ШчЃЌ
df . groupBy ЃЈЁАtimeЁБЃЉ. count ЃЈЃЉ . withWatermark ЃЈ
ЁА time ЁБ ЃЌЁА 1 min ЁБЃЉ дкAppendЪфГіФЃЪНжа ЮоаЇЁЃ
JoinВйзї
СїDataFramesПЩвдгыОВЬЌDataFramesСЌНгвдДДНЈаТЕФСїDataFramesЁЃетРягаМИИіР§згЁЃ
| val
staticDf = spark.read. ...
val streamingDf = spark.readStream. ...
streamingDf.join(staticDf, "type")
// inner equi-join with a static DF
streamingDf.join(staticDf, "type",
"right_join") // right outer join
with a static DF |
ВЛжЇГжЕФВйзї
ЕЋЪЧЃЌЧызЂвтЃЌЫљгаЪЪгУгкОВЬЌDataFrames /Ъ§ОнМЏЕФВйзїдкСїЪНDataFrames /Ъ§ОнМЏжаВЛЪмжЇГжЁЃЫфШЛетаЉВЛжЇГжЕФВйзїжаЕФвЛаЉНЋдкЮДРДЕФSparkАцБОжаЕУЕНжЇГжЃЌЕЋЛЙгавЛаЉЛљБОЩЯФбвдгааЇЕидкСїЪ§ОнЩЯЪЕЯжЁЃР§ШчЃЌЪфШыСїЪ§ОнМЏВЛжЇГжХХађЃЌвђЮЊЫќашвЊИњзйСїжаНгЪеЕФЫљгаЪ§ОнЁЃвђДЫЃЌетдкИљБОЩЯФбвдгааЇЕижДааЁЃДгSpark
2.0ПЊЪМЃЌвЛаЉВЛЪмжЇГжЕФВйзїШчЯТЃК
1.дкСїЪ§ОнМЏЩЯЛЙВЛжЇГжЖрИіСїОлМЏЃЈМДЃЌСїDFЩЯЕФОлКЯСДЃЉЁЃ
2.дкСїЪ§ОнМЏЩЯВЛжЇГжЯожЦКЭЛёШЁЧАNааЁЃ
3.ВЛжЇГжЖдСїЪ§ОнМЏНјааВЛЭЌВйзїЁЃ
4.ХХађВйзїНідкОлКЯКѓдкЭъећЪфГіФЃЪНЯТжЇГжСїЪ§ОнМЏЁЃ
5.ЬѕМўжЇГжСїЪНДЋЪфКЭОВЬЌЪ§ОнМЏжЎМфЕФЭтСЌНгЁЃ
6.ВЛжЇГжДјгаСїЪ§ОнМЏЕФЭъШЋЭтСЌНг
7.ВЛжЇГжзѓЭтВПСЌНггыгвВрЕФСїЪ§ОнМЏ
8.ВЛжЇГжзѓВрЕФСїЪ§ОнМЏЕФгвЭтВПСЊНг
9.ЩаВЛжЇГжСНИіСїЪ§ОнМЏжЎМфЕФШЮКЮРраЭЕФСЌНгЁЃ
ДЫЭтЃЌЛЙгавЛаЉDatasetЗНЗЈВЛФмгУгкСїЪ§ОнМЏЁЃЫќУЧЪЧНЋСЂМДдЫааВщбЏВЂЗЕЛиНсЙћЕФВйзїЃЌетЖдСїЪ§ОнМЏУЛгавтвхЁЃЯрЗДЃЌетаЉЙІФмПЩвдЭЈЙ§ЯдЪНЕиЦєЖЏСїВщбЏРДЭъГЩЃЈВЮМћЯТвЛВПЗжЃЉЁЃ
countЃЈЃЉ - ЮоЗЈДгСїЪ§ОнМЏЗЕЛиЕЅИіМЦЪ§ЁЃ
ЯрЗДЃЌЪЙгУds.groupBy.countЃЈЃЉЗЕЛиАќКЌдЫааМЦЪ§ЕФСїЪ§ОнМЏЁЃ
foreachЃЈЃЉ - ЖјЪЧЪЙгУds.writeStream.foreachЃЈ...ЃЉЃЈВЮМћЯТвЛНкЃЉЁЃ
showЃЈЃЉ - ЖјЪЧЪЙгУПижЦЬЈНгЪеЦїЃЈЧыВЮдФЯТвЛНкЃЉЁЃ
ШчЙћФњГЂЪдШЮКЮетаЉВйзїЃЌФњНЋПДЕНвЛИіAnalysisExceptionШчЁАВйзїXYZВЛжЇГжгыСїDataFrames
/Ъ§ОнМЏЁБЁЃ
ЦєЖЏСїЪНВщбЏ
вЛЕЉЖЈвхСЫзюжеНсЙћDataFrame / DatasetЃЌЪЃЯТЕФОЭЪЧЦєЖЏСїМЦЫуЁЃЮЊДЫЃЌФњБиаыЪЙгУЭЈЙ§Dataset.writeStreamЃЈЃЉЗЕЛиЕФDataStreamWriterЃЈScala
/ Java / PythonЮФЕЕЃЉЁЃФњБиаыдкДЫНчУцжажИЖЈвдЯТвЛИіЛђЖрИіЁЃ
ЪфГіНгЪеЦїЕФЯъЯИаХЯЂЃКЪ§ОнИёЪНЃЌЮЛжУЕШ
ЪфГіФЃЪНЃКжИЖЈаДШыЪфГіНгЪеЦїЕФФкШнЁЃ
ВщбЏУћГЦЃКЃЈПЩбЁЃЉжИЖЈВщбЏЕФЮЈвЛУћГЦвдНјааБъЪЖЁЃ
ДЅЗЂМфИєЃКПЩбЁдёжИЖЈДЅЗЂМфИєЁЃШчЙћЮДжИЖЈЃЌЯЕЭГНЋдкЩЯвЛИіДІРэЭъГЩКѓСЂМДМьВщаТЪ§ОнЕФПЩгУадЁЃШчЙћгЩгкЯШЧАДІРэЩаЮДЭъГЩЖјДэЙ§ДЅЗЂЪБМфЃЌдђЯЕЭГНЋГЂЪддкЯТвЛДЅЗЂЕуДІДЅЗЂЃЌЖјВЛЪЧдкДІРэЭъГЩжЎКѓСЂМДДЅЗЂЁЃ
МьВщЕуЮЛжУЃКЖдгкПЩвдБЃжЄЖЫЕНЖЫШнДэЕФФГаЉЪфГіНгЪеЦїЃЌЧыжИЖЈЯЕЭГНЋаДШыЫљгаМьВщЕуаХЯЂЕФЮЛжУЁЃетгІИУЪЧHDFSМцШнЕФШнДэЮФМўЯЕЭГжаЕФФПТМЁЃМьВщЕуЕФгявхНЋдкЯТвЛНкжаИќЯъЯИЕиЬжТлЁЃ
ЪфГіФЃЪН
гаМИжжРраЭЕФЪфГіФЃЪНЃК
1.ИНМгФЃЪНЃЈФЌШЯЃЉ - етЪЧФЌШЯФЃЪНЃЌЦфжажЛгаздЩЯДЮДЅЗЂКѓЬэМгЕННсЙћБэжаЕФаТааНЋЪфГіЕННгЪеЦїЁЃетНіжЇГжФЧаЉЬэМгЕННсЙћБэжаЕФааДгВЛЛсИќИФЕФВщбЏЁЃвђДЫЃЌИУФЃЪНБЃжЄУПаажЛЪфГівЛДЮЃЈМйЩшШнДэЫоЃЉЁЃР§ШчЃЌжЛгаselectЃЌwhereЃЌmapЃЌflatMapЃЌfilterЃЌjoinЕШЕФВщбЏНЋжЇГжAppendФЃЪНЁЃ
2.ЭъГЩФЃЪН - УПДЮДЅЗЂКѓЃЌећИіНсЙћБэНЋЪфГіЕННгЪеЦїЁЃОлКЯВщбЏжЇГжДЫбЁЯюЁЃ
3.ИќаТФЃЪН - ЃЈдкSpark 2.1жаВЛПЩгУЃЉжЛгаНсЙћБэжаздЩЯДЮДЅЗЂКѓИќаТЕФааВХЛсЪфГіЕННгЪеЦїЁЃИќЖраХЯЂНЋдкЮДРДАцБОжаЬэМгЁЃ
ВЛЭЌРраЭЕФСїВщбЏжЇГжВЛЭЌЕФЪфГіФЃЪНЁЃетРяЪЧМцШнадОиеѓЃК
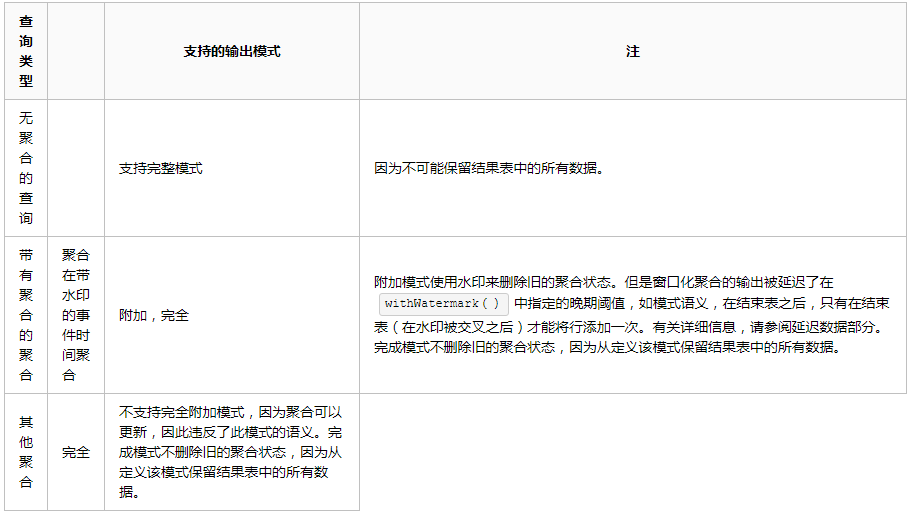
ЪфГіНгЪеЦї
гаМИжжРраЭЕФФкжУЪфГіНгЪеЦїЃК
1.ЮФМўНгЪеЦї - НЋЪфГіДцДЂЕНФПТМЁЃ
2.Foreach sink - ЖдЪфГіжаЕФМЧТМдЫааШЮвтМЦЫуЁЃгаЙиЯъЯИаХЯЂЃЌЧыВЮдФКѓУцЕФВПЗжЁЃ
3.ПижЦЬЈНгЪеЦїЃЈгУгкЕїЪдЃЉ - УПДЮгаДЅЗЂЦїЪБНЋЪфГіДђгЁЕНПижЦЬЈ/
stdoutЁЃетгІИУгУгкЕЭЪ§ОнСПЩЯЕФЕїЪдФПЕФЃЌвђЮЊУПДЮДЅЗЂКѓЃЌећИіЪфГіБЛЪеМЏВЂДцДЂдкЧ§ЖЏГЬађЕФФкДцжаЁЃ
4.ФкДцНгЪеЦїЃЈгУгкЕїЪдЃЉ - ЪфГізїЮЊФкДцБэДцДЂдкФкДцжаЁЃжЇГжИНМгКЭЭъГЩЪфГіФЃЪНЁЃетгІИУгУгкЕЭЪ§ОнСПЩЯЕФЕїЪдФПЕФЃЌвђЮЊУПДЮДЅЗЂКѓЃЌећИіЪфГіБЛЪеМЏВЂДцДЂдкЧ§ЖЏГЬађЕФФкДцжаЁЃ
ЯТУцЪЧЫљгаНгЪеЦїЕФБэИёКЭЯргІЕФЩшжУЃК

зюКѓЃЌФуБиаыЕїгУstartЃЈЃЉВХФмеце§ПЊЪМжДааВщбЏЁЃетЗЕЛивЛИіStreamingQueryЖдЯѓЃЌЫќЪЧСЌајдЫааЕФжДааЕФОфБњЁЃФњПЩвдЪЙгУДЫЖдЯѓРДЙмРэВщбЏЃЌЮвУЧНЋдкЯТвЛаЁНкжаЬжТлЁЃЯждкЃЌШУЮвУЧЭЈЙ§МИИіР§згРДРэНтетвЛЧаЁЃ
| //
========== DF with no aggregations ==========
Dataset<Row> noAggDF = deviceDataDf.select("device").where("signal
> 10");
// Print new data to console
noAggDF
.writeStream()
.format("console")
.start();
// Write new data to Parquet files
noAggDF
.writeStream()
.parquet("path/to/destination/directory")
.start();
// ========== DF with aggregation ==========
Dataset<Row> aggDF = df.groupBy("device").count();
// Print updated aggregations to console
aggDF
.writeStream()
.outputMode("complete")
.format("console")
.start();
// Have all the aggregates in an in-memory
table
aggDF
.writeStream()
.queryName("aggregates") // this query
name will be the table name
.outputMode("complete")
.format("memory")
.start();
spark.sql("select * from aggregates").show();
// interactively query in-memory table |
ЪЙгУforeach
foreachВйзїдЪаэЖдЪфГіЪ§ОнМЦЫуШЮвтВйзїЁЃДгSpark 2.1ПЊЪМЃЌетжЛЪЪгУгкScalaКЭJavaЁЃвЊЪЙгУетИіЃЌФуБиаыЪЕЯжНгПкForeachWriterЃЈScala
/ Java docsЃЉЃЌЫќгавЛИіЗНЗЈЃЌЕБДЅЗЂКѓВњЩњвЛЯЕСааазїЮЊЪфГіЪББЛЕїгУЁЃЧызЂвтвдЯТвЊЕуЁЃ
БраДЦїБиаыЪЧПЩађСаЛЏЕФЃЌвђ- ЮЊЫќНЋБЛађСаЛЏВЂЗЂЫЭЕНжДааЦївдЙЉжДааЁЃ
ЫљгаШ§ИіЗНЗЈЃЌДђПЊЃЌДІРэКЭЙиБеНЋБЛЕїгУЕФжДааепЁЃ
жЛгаЕБЕїгУopenЗНЗЈЪБЃЌаДГЬађБиаыжДааЫљгаЕФГѕЪМЛЏЃЈР§ШчДђПЊСЌНгЃЌЦєЖЏЪТЮёЕШЃЉЁЃЧызЂвтЃЌШчЙћдкДДНЈЖдЯѓЪБдкРржагаШЮКЮГѕЪМЛЏЃЌФЧУДИУГѕЪМЛЏНЋдкЧ§ЖЏГЬађжаНјааЃЈвђЮЊетЪЧДДНЈЪЕР§ЕФЕиЗНЃЉЃЌетПЩФмВЛЪЧФњЯывЊЕФЁЃ
АцБОКЭЗжЧјЪЧopenжаЕФСНИіВЮЪ§ЃЌЫќУЧЮЈвЛЕиБэЪОашвЊБЛЭЦГіЕФвЛзщааЁЃАцБОЪЧвЛИіЕЅЕїдіМгЕФidЃЌЫцзХУПИіДЅЗЂЦїдіМгЁЃpartitionЪЧБэЪОЪфГіЕФЗжЧјЕФidЃЌвђЮЊЪфГіЪЧЗжВМЪНЕФЃЌВЂЧвНЋдкЖрИіжДааЦїЩЯДІРэЁЃ
openПЩвдЪЙгУАцБОКЭЗжЧјРДбЁдёЪЧЗёашвЊаДааађСаЁЃвђДЫЃЌЫќПЩвдЗЕЛиtrueЃЈМЬајаДШыЃЉЛђfalseЃЈВЛашвЊаДШыЃЉЁЃШчЙћЗЕЛиfalseЃЌФЧУДНЋВЛЛсдкШЮКЮааЩЯЕїгУНјГЬЁЃР§ШчЃЌдкВПЗжЙЪеЯжЎКѓЃЌЪЇАмДЅЗЂЦїЕФвЛаЉЪфГіЗжЧјПЩФмвбОБЛЬсНЛЕНЪ§ОнПтЁЃЛљгкДцДЂдкЪ§ОнПтжаЕФдЊЪ§ОнЃЌаДепПЩвдЪЖБ№вбОЬсНЛЕФЗжЧјЃЌвђДЫЗЕЛиfalseвдЬјЙ§дйДЮЬсНЛЫќУЧЁЃ
УПЕБЕїгУopenЪБЃЌвВНЋЕїгУcloseЃЈГ§ЗЧJVMгЩгкФГаЉДэЮѓЖјЭЫГіЃЉЁЃМДЪЙopenЗЕЛиfalseЃЌвВЪЧШчДЫЁЃШчЙћдкДІРэКЭаДШыЪ§ОнЪБГіЯжШЮКЮДэЮѓЃЌНЋЪЙгУДэЮѓЕїгУcloseЁЃФњгад№ШЮЧхГ§дкПЊЗХжаДДНЈЕФзДЬЌЃЈР§ШчСЌНгЃЌЪТЮёЕШЃЉЃЌвдБуУЛгазЪдДаЙТЉЁЃ
ЙмРэСїЪНВщбЏ
ЦєЖЏВщбЏЪБДДНЈЕФStreamingQueryЖдЯѓПЩгУгкМрЪгКЭЙмРэВщбЏЁЃ
| StreamingQuery
query = df.writeStream().format("console").start();
// get the query object
query.id(); // get the unique identifier of
the running query
query.name(); // get the name of the auto-generated
or user-specified name
query.explain(); // print detailed explanations
of the query
query.stop(); // stop the query
query.awaitTermination(); // block until query
is terminated, with stop() or with error
query.exception(); // the exception if the
query has been terminated with error
query.sourceStatus(); // progress information
about data has been read from the input sources
query.sinkStatus(); // progress information
about data written to the output sink |
ФњПЩвддкЕЅИіSparkSessionжаЦєЖЏШЮвтЪ§СПЕФВщбЏЁЃЫћУЧНЋЭЌЪБдЫааЙВЯэМЏШКзЪдДЁЃФњПЩвдЪЙгУsparkSession.streamsЃЈЃЉЛёШЁПЩгУгкЙмРэЕБЧАЛюЖЏВщбЏЕФStreamingQueryManagerЃЈScala
/ Java / PythonЮФЕЕЃЉЁЃ
| SparkSession
spark = ...
spark.streams().active(); // get the list of
currently active streaming queries
spark.streams().get(id); // get a query object
by its unique id
spark.streams().awaitAnyTermination(); // block
until any one of them terminates |
МрЪгСїВщбЏ
гаСНИіAPIгУгквдНЛЛЅЪНКЭвьВНЗНЪНМрЪгКЭЕїЪдЛюЖЏЕФВщбЏЁЃ
НЛЛЅЪНAPI
ФњПЩвдЪЙгУ streamingQuery.lastProgressЃЈЃЉКЭ
streamingQuery.statusЃЈЃЉжБНгЛёШЁЛюЖЏВщбЏЕФЕБЧАзДЬЌКЭжИБъЁЃ lastProgressЃЈЃЉдк
Scala КЭJavaжаЗЕЛивЛИі StreamingQueryProgress ЖдЯѓЃЌдкPythonжаЗЕЛивЛИіОпгаЯрЭЌзжЖЮЕФзжЕфЁЃЫќОпгаЙигкдкСїЕФзюКѓДЅЗЂжаЫљНјааЕФНјеЙЕФЫљгааХЯЂ
- ЪВУДЪ§ОнБЛДІРэЃЌЪВУДЪЧДІРэЫйТЪЃЌЕШД§ЪБМфЕШЁЃЛЙга streamingQuery.recentProgress
ЃЌЫќЗЕЛизюКѓМИИіНјЖШЕФЪ§зщЁЃ
ДЫЭтЃЌstreamingQuery.statusЃЈЃЉдкScalaКЭJavaжаЗЕЛиStreamingQueryStatusЖдЯѓЃЌдкPythonжаЗЕЛиОпгаЯрЭЌзжЖЮЕФзжЕфЁЃЫќЬсЙЉгаЙиВщбЏСЂМДжДааЕФВйзїЕФаХЯЂ
- ЪЧДЅЗЂЦїЛюЖЏЃЌе§дкДІРэЪ§ОнЕШЁЃетРягаМИИіР§згЁЃ
| StreamingQuery
query = ...
System.out.println(query.lastProgress());
/* Will print something like the following.
{
"id" : "ce011fdc-8762-4dcb-84eb-a77333e28109",
"runId" : "88e2ff94-ede0-45a8-b687-6316fbef529a",
"name" : "MyQuery",
"timestamp" : "2016-12-14T18:45:24.873Z",
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0,
"durationMs" : {
"triggerExecution" : 3,
"getOffset" : 2
},
"eventTime" : {
"watermark" : "2016-12-14T18:45:24.873Z"
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "KafkaSource[Subscribe[topic-0]]",
"startOffset" : {
"topic-0" : {
"2" : 0,
"4" : 1,
"1" : 1,
"3" : 1,
"0" : 1
}
},
"endOffset" : {
"topic-0" : {
"2" : 0,
"4" : 115,
"1" : 134,
"3" : 21,
"0" : 534
}
},
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0
} ],
"sink" : {
"description" : "MemorySink"
}
}
*/
System.out.println(query.status());
/* Will print something like the following.
{
"message" : "Waiting for data
to arrive",
"isDataAvailable" : false,
"isTriggerActive" : false
}
*/
|
вьВНAPI
ФњЛЙПЩвдЭЈЙ§ИНМг StreamingQueryListenerЃЈ
Scala / Java docs ЃЉвьВНМрЪггы SparkSession ЯрЙиСЊЕФЫљгаВщбЏЁЃЪЙгУ
sparkSession . streams . attachListenerЃЈЃЉИНМгздЖЈвхStreamingQueryListenerЖдЯѓКѓЃЌЕБВщбЏЦєЖЏКЭЭЃжЙвдМАЛюЖЏВщбЏжагаНјЖШЪБЃЌФњНЋЛёЕУЛиЕїЁЃетРяЪЧвЛИіР§зг
| SparkSession
spark = ...
spark.streams.addListener(new StreamingQueryListener()
{
@Overrides void onQueryStarted(QueryStartedEvent
queryStarted) {
System.out.println("Query started: "
+ queryStarted.id());
}
@Overrides void onQueryTerminated(QueryTerminatedEvent
queryTerminated) {
System.out.println("Query terminated: "
+ queryTerminated.id());
}
@Overrides void onQueryProgress(QueryProgressEvent
queryProgress) {
System.out.println("Query made progress:
" + queryProgress.progress());
}
}); |
ЪЙгУМьВщЕуДгЙЪеЯжаЛжИД
дкЙЪеЯЛђЙЪвтЙиБеЕФЧщПіЯТЃЌФњПЩвдЛжИДЯШЧАВщбЏЕФЯШЧАНјЖШКЭзДЬЌЃЌВЂМЬајдкЦфЭЃжЙЕФЕиЗНЁЃетЪЧЭЈЙ§ЪЙгУМьВщЕуКЭдЄаДШежОРДЭъГЩЕФЁЃФњПЩвдХфжУОпгаМьВщЕуЮЛжУЕФВщбЏЃЌВЂЧвВщбЏНЋБЃДцЫљгаНјЖШаХЯЂЃЈМДУПИіДЅЗЂЦїжаДІРэЕФЦЋвЦЗЖЮЇЃЉКЭе§дкдЫааЕФОлКЯЃЈР§ШчПьЫйЪОР§жаЕФзжМЦЪ§ЃЉЕНМьВщЕуЮЛжУЁЃДЫМьВщЕуЮЛжУБиаыЪЧHDFSМцШнЮФМўЯЕЭГжаЕФТЗОЖЃЌВЂЧвПЩвддкЦєЖЏВщбЏЪБдкDataStreamWriterжаЩшжУЮЊбЁЯюЁЃ
| aggDF
.writeStream()
.outputMode("complete")
.option("checkpointLocation", "path/to/HDFS/dir")
.format("memory")
.start();
|
|









