| БрМЭЦМі: |
| РДдДЭјТчЃЌБОЮФжївЊНВНтСЫгадоЪ§ОнЦНЬЈЕФећЬхМмЙЙЃЌSparkSQL
дкгадоЕФММЪѕбнНјЃЌДг Hive ЕН SparkSQL ЕФЧЈвЦжЎТЗЕШЗНУцжЊЪЖЁЃ |
|
ЧАбд
гадоЪ§ОнЦНЬЈДг 2017 ФъЩЯАыФъПЊЪМЃЌж№ВНЪЙгУ SparkSQL ЬцДњ Hive жДааРыЯпШЮЮёЃЌФПЧА
SparkSQL УПЬьЕФдЫаазївЕЪ§СП 5000 ИіЃЌеМРыЯпзївЕЪ§ФПЕФ 55%ЃЌЯћКФЕФ cpu зЪдДеММЏШКзмзЪдДЕФ
50% зѓгвЁЃБОЮФНщЩмгЩ SparkSQL ЬцЛЛ Hive Й§ГЬжаХіЕНЕФЮЪЬтвдМАДІРэОбщКЭгХЛЏНЈвщЃЌАќРЈвдЯТЗНУцЕФФкШнЃК
гадоЪ§ОнЦНЬЈЕФећЬхМмЙЙЁЃ
SparkSQL дкгадоЕФММЪѕбнНјЁЃ
Дг Hive ЕН SparkSQL ЕФЧЈвЦжЎТЗЁЃ
вЛ. гадоЪ§ОнЦНЬЈНщЩм
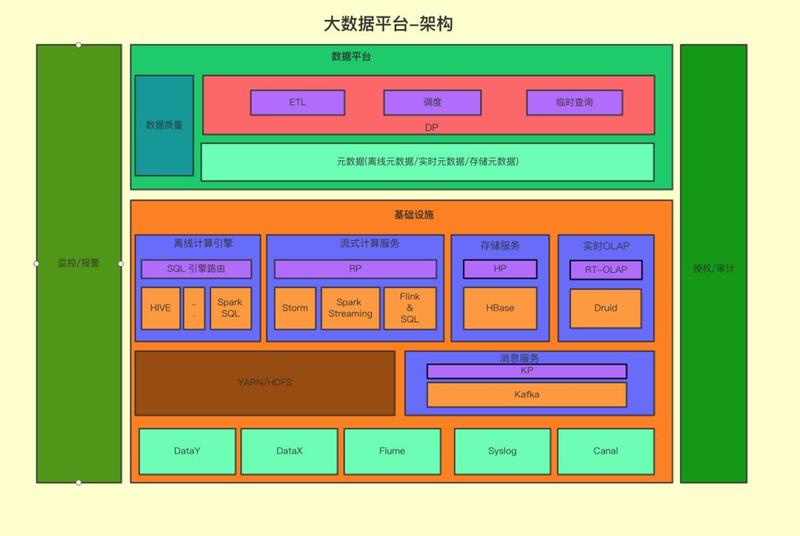
ЪзЯШНщЩмвЛЯТгадоДѓЪ§ОнЦНЬЈзмЬхМмЙЙЃК
ШчЯТЭМЫљЪОЃЌЕзВуЪЧЪ§ОнЕМШыВПЗжЃЌЦфжа DataY ЧјБ№гкПЊдДНьЕФШЋСПЕМШыЕМГіЙЄОп alibaba/DataXЃЌЪЧгадоФкВПбаЗЂЕФРыЯп
Mysql діСПЕМШы Hive ЕФЙЄОпЃЌАб Hive жаРњЪЗЪ§ОнКЭЕБЬьдіСПВПЗжзіКЯВЂЁЃDataX /
DataY ИКд№НЋ Mysql жаЕФЪ§ОнЭЌВНЕНЪ§ВжЕБжаЃЌFlume зїЮЊШежОЪ§ОнЕФжївЊЭЈЕРЃЌЭЌЪБвВЪЧ
Mysql binlog ЭЌВНЕН HDFS ЕФЙмЕРЃЌЙЉ DataY зідіСПКЯВЂЪЙгУЁЃ
ЕкЖўВуЪЧДѓЪ§ОнЕФМЦЫуПђМмЃЌжївЊЗжГЩСНВПЗжЃКЗжВМЪНДцДЂМЦЫуКЭЪЕЪБМЦЫуЃЌЪЕЪБПђМмФПЧАжївЊжЇГж JStormЃЌSpark
Streaming КЭ FlinkЃЌЦфжа Flink ЪЧНёФъПЊЪМжЇГжЕФЃЛЖјЗжВМЪНДцДЂКЭМЦЫуПђМметБпЃЌЕзВуЪЧ
Hadoop КЭ HbaseЃЌETL жївЊЪЙгУ Hive КЭ SparkЃЌНЛЛЅВщбЏдђЛсЪЙгУ SparkЃЌPrestoЃЌЪЕЪБ
OLAP ЯЕЭГНёФъв§ШыСЫ DruidЃЌЬсЙЉШежОЕФОлКЯВщбЏФмСІЁЃ
ЕкШ§ВуЪЧЪ§ОнЦНЬЈВПЗжЃЌЪ§ОнЦНЬЈЪЧжБНгУцЖдЪ§ОнПЊЗЂепЕФЃЌАќРЈМИВПЗжЕФЙІФмЃЌЪ§ОнПЊЗЂЦНЬЈЃЌАќРЈШеГЃЪЙгУЕФЕїЖШЃЌЪ§ОнДЋЪфЃЌЪ§ОнжЪСПЯЕЭГЃЛЪ§ОнВщбЏЦНЬЈЃЌАќРЈ
ad-hoc ВщбЏвдМАдЊЪ§ОнВщбЏЁЃгаЙигадоЪ§ОнЦНЬЈЕФЯъЯИНщЩмПЩвдВЮПМЭљЦкгадоЪ§ОнЦНЬЈЕФВЉПЭФкШнЁЃ
ЁЁЁЁ
Жў. SparkSQL ММЪѕбнНј
Дг 2017 ФъЖўМОЖШЃЌгадоЪ§ОнзщЕФЭЌбЇУЧПЊЪМСЫ SparkSQL ЗНУцЕФГЂЪдЃЌжївЊЕФГіЗЂЕуЪЧЕБЪБМЏШКзЪдДЪЧЦПОБЃЌHive
ХмШЮЮёвбОж№НЅПЊЪМЗІСІЃЌгааЉИДдгЕФ SQLЃЌЭЈЙ§ SQL ЕФТпМгХЛЏДяЕНМЋЯоЃЌШдШЛашвЊМИИіаЁЪБЕФЪБМфЁЃвЕЮёЪ§ОнСПе§дкВЛЖЯдіДѓЃЌетаЉШЮЮёЛсгАЯьвЕЮёЖдЭтЗўЮёЕФГаХЕЁЃЭЌЪБЃЌЫцзХ
Spark вдМАЦфЩчЧјЕФВЛЖЯЗЂеЙЃЌSpark МА Spark SQL БОЩэММЪѕЕФВЛЖЯГЩЪьЃЌSpark
дкММЪѕМмЙЙКЭадФмЩЯЖМеЙЪОГі Hive ЮоЗЈБШФтЕФгХЪЦЁЃ
ДгПЊЪМЩЯЯпЬсЙЉРыЯпШЮЮёЗўЮёЃЌдйЕН Hive ШЮЮёж№НЅЭљ SparkSQL ЧЈвЦЃЌВШЙ§ВЛЩйПгЃЌвВЬюСЫВЛЩйПгЃЌетРяжївЊЗжСНИіЗНУцНщЩмЃЌвЛЗНУцЪЧЮвУЧЖд
SparkSQL ПЩгУадЗНУцЕФИФдьвдМАгХЛЏЃЌСэвЛЗНУцЪЧ Hive ЧЈвЦЪБгіЕНЕФжжжжЮЪЬтвдМАЖдВпЁЃ
2.1 ПЩгУадИФдь
ПЩгУадЮЪЬтАќРЈСНЗНУцЃЌвЛИіЪЧЯЕЭГЕФЮШЖЈадЃЌМрПи / ЩѓМЦ / ШЈЯоЕШЃЌСэвЛИіЪЧгУЛЇЪЙгУЕФЬхбщЃЌгУЛЇвдЧАЯАЙпгУ
HiveЃЌШчЙћ SparkSQL ЕФШежОЛђеп Spark thrift server ЕФ UI ВЛФмЙЛАяжњгУЛЇЖЈЮЛЮЪЬтЃЌНтОіЮЪЬтЃЌФЧвВЛсгАЯьгУЛЇЕФЪЙгУЛђепЧЈвЦвтдИЁЃЫљвдЮвЪзЯШЬИвЛЯТгУЛЇНЛЛЅЕФЮЪЬтЁЃ
гУЛЇЬхбщ
ЮвУЧХіЕНЕФЕквЛИіЮЪЬтЪЧгУЛЇЯђЮвУЧБЇдЙЭЈЙ§ JDBC ЕФЗНЪНКЭ Spark thrift server(STS)
НЛЛЅЃЌжДаавЛИі SQL ЪБЃЌУЛгажДааЕФНјЖШаХЯЂЃЌашвЊвЛжБЕШД§жДааГЩЙІЃЌЛђепШЮЮёГіДэЪБНгЪеШЮЮёБЈДэгЪМўЕУжЊжДааЭъЁЃгкЪЧжДааНјЖШШУгУЛЇПЩИажЊЪЧвЛИіБивЊЕФЙІФмЁЃЮвУЧзіСЫ
Spark ЕФИФдьЃЌдіМгдЫааЪБЕФ operation ШежОЃЌВЂЧвЯђЩчЧјЬсНЛСЫ patch(spark-22496)ЃЌ
ЖјдкЮвУЧФкВПЃЌИќдіМгСЫжДааНјЖШШежОЃЌУПИє 2 УыДђгЁГіЕБЧАжДааЕФ job/stage ЕФНјЖШЃЌШчЯТЭМЫљЪОЁЃ
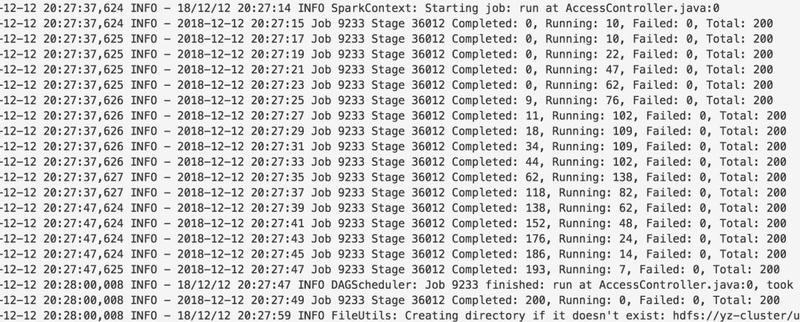
МрПи
SparkSQL ашвЊЪеМЏ STS ЩЯжДааЕФ SQL ЕФЩѓМЦаХЯЂЃЌАќРЈЬсНЛепжДааЕФОпЬх SQLЃЌПЊЪМНсЪјЪБМфЃЌжДааЭъГЩзДЬЌЁЃдЩњ
STS ЛсАбетаЉаХЯЂЭЈЙ§ЪТМўЕФЗНЪН post ЕНЪТМўзмЯпЃЌМрЬ§епНЧЩЋ (HiveThriftServer2Listener)
дкЪТМўзмЯпЩЯзЂВсЃЌЖЉдФЯћЗбЪТМўЃЌЕЋЪЧетИіМрЬ§епжЛИКд№ Spark UI ЕФ JDBC Tab ЩЯЕФеЙЪОЃЌЮвУЧИФдьСЫ
SparkListener РрЃЌНЋ session вдМАжДааЕФ sql statement МЖБ№ЕФЯћЯЂвВЗХЕНСЫзмЯпЩЯЃЌМрЬ§епПЩвддкзмЯпЩЯзЂВсЃЌвдБуЯћЗбетаЉЩѓМЦаХЯЂЃЌВЂЧвдіМгСЫвЛаЉЮвУЧИааЫШЄЕФЮЌЖШЃЌШчЪЙгУЕФ
cpu зЪдДЃЌЙщЪєЕФЙЄзїСї (airflowId)ЁЃЭЌЪБЃЌЮвУЧдіМгСЫвЛжжаТЕФЭъГЩзДЬЌ cancelledЃЌвдЗНБуЧјЗжЪЧгУЛЇжїЖЏШЁЯћЕФШЮЮёЁЃ
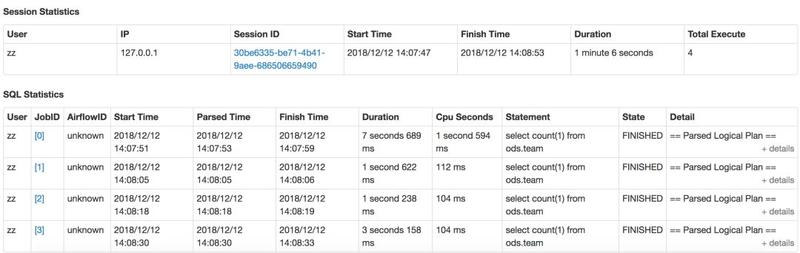
Thrift Server HA
ЯрБШгк HiveServerЃЌSTS ЪЧБШНЯДрШѕЕФЃЌвЛЪЧгЩгк Spark ЕФ driver ЪЧБШНЯжиЕФЃЌЫљгаЕФзївЕЖМЛсЭЈЙ§
driver Брвы sqlЃЌЕїЖШ job/task жДааЃЌЗжЗЂ broadcast БфСПЃЌЖўЪЧЖдгкУПИі
SQLЃЌЯрБШгк HiveServer ЛсаТЦ№вЛИіНјГЬШЅДІРэетИі SQL ЕФжДааЃЌSTS жЛгавЛИіНјГЬШЅДІРэЃЌШчЙћФГИі
SQL гавьГЃЃЌВщбЏСЫЙ§ЖрЕФЪ§ОнСПЃЌ STS га OOM ЭЫГіЕФЗчЯеЃЌФЧУДЩњВњЛЗОГЮЌГж STS ЕФЮШЖЈадОЭЯдЕУЮоБШживЊЁЃ
Г§СЫБивЊЕФДцЛюБЈОЏЃЌЪзЯШЮвУЧЧјЗжСЫ ad-hoc ВщбЏКЭРыЯпЕїЖШЕФ STS ЗўЮёЃЌвђЮЊРыЯпЕїЖШЕФШЮЮёЭљЭљМЦЫуНсЪјЪБЪЧАбНсЙћаДШы
table ЕФЃЌЖј ad-hoc ДѓВПЗжЪЧжБНгАбНсЙћЛузмдк driverЃЌЖд driver ЕФбЙСІБШНЯДѓЃЛДЫЭтЃЌЮвУЧдіМгСЫЛљгк
ZK ЕФИпПЩгУЁЃЖдгквЛжжРраЭЕФ STSЃЈЪТЪЕЩЯЃЌгадоЕФ STS ЗжЮЊЖрзщЃЌШч ad-hocЃЌДѓФкДцХфжУзщЃЉдк
ZK ЩЯзЂВсвЛИіНкЕуЃЌJDBC ЕФСЌНгжБНгЗУЮЪ ZK ЛёШЁЫцЛњПЩгУЕФ STS ЕижЗЁЃетбљЃЌХМШЛЕФ OOM
ЃЌЛђеп bug БЛДЅЗЂЕМжТ STS ВЛПЩгУЃЌвВВЛЛсбЯжиЕНгАЯьЕїЖШШЮЮёЭъШЋВЛПЩгУЃЌИјПЊЗЂдЫЮЌШЫдББШНЯГфзуЕФЪБМфЖЈЮЛЮЪЬтЁЃ
ШЈЯоПижЦ
жЎКѓгаСэвЛИіЮФеТЯъЯИНщЩмЮвУЧЖдгкАВШЋКЭШЈЯоЕФНЈЩшжЎТЗЃЌетРяМђЕЅНщЩмвЛЯТЃЌHive ЕФШЈЯоПижЦжївЊАќРЈвдЯТМИжж:
SQL Standards Based Hive Authorization
Storage Based Authorization in the Metastore
ServerAuthorization using Apache Ranger & Sentry
ЕїбаЖдБШИїжжЪЕЯжЗНАИжЎКѓЃЌгЩгкЮвУЧЪЧДгЮоЕНгаЕФдіМгСЫШЈЯоПижЦЃЌУЛгаРњЪЗИКЕЃЁЃЮвУЧжБНгбЁдёСЫ ranger
+ зщМў plugin ЕФШЈЯоЙмРэЗНАИЁЃ
Г§СЫвдЩЯЬсЕНЕФМИИіЕуЃЌЮвУЧЛЙДгЩчЧј backport СЫЪ§ЪЎИі patch вдНтОігАЯьПЩгУадЕФЮЪЬтЃЌШчВЛЪЖБ№
hiveconf/hivevar (SPARK-13983)ЃЌзюКѓвЛааБЛНиЖЯ (HIVE-10541)
ЕШЕШЁЃ
2.2 адФмгХЛЏ
жЎЧАЬИЕНЃЌSTS жЛгавЛИіНјГЬШЅДІРэЫљгаЬсНЛ SQL ЕФБрвыЃЌЫљгаЕФ SQL Job ЙВЯэвЛИі Hive
ЪЕР§ЃЌИќдуИтЕФЪЧетИі Hive ЪЕР§ЛЙгаДІРэ loadTable/loadPartition етбљЕФ
IO ВйзїЃЌЛсзшШћЦфЫћШЮЮёЕФБрвыЃЌДцдкЕЅЕуЮЪЬтЁЃЮвУЧжЎЧАВтЪдвЛИіЩЯЭђ partition ЕФ Hive
БэдкжДаа loadTable ВйзїЪБЃЌЛсзшШћЦфЫћШЮЮёЬсНЛЃЌЪБМфГЄДяаЁЪБМЖБ№ЁЃЖдгк loadTable
етбљЕФ IO ВйзїЃЌвЊУДВЛМгЫјЃЌвЊУДМѕЩйМгЫјЕФЪБМфЁЃЮвУЧбЁдёЕФЪЧКѓепЃЌЪзЯШВЩгУЕФЪЧЩчЧј SPARK-20187
ЕФзіЗЈЃЌНЋ loadTable ЪЕЯжгЩ copyFile ЕФЗНЪНИФЮЊ moveFileЃЌМћЯТЭМЃК
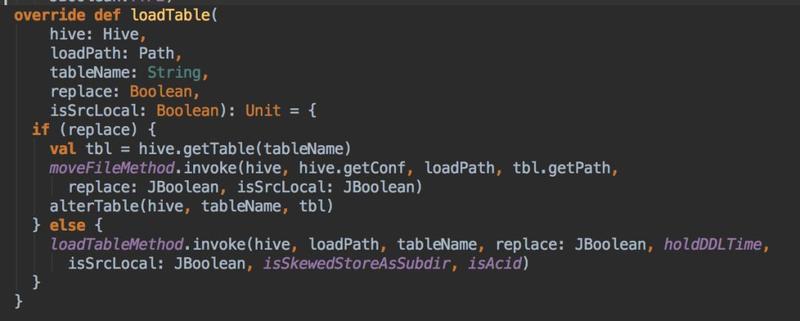
жЎКѓБфИќСЫХфжУ spark.sql.hive.metastore.jars=mavenЃЌдЫааЪБЭЈЙ§
Maven ЕФЗНЪНМгди jar АќЃЌНтОіАќвРРЕЙиЯЕЃЌЪЙЕУМгдиЕФ Hive РрЪЧ 2.1.1 ЕФАцБОЃЌКЭЮвУЧ
Hive АцБОвЛжТЃЌетбљЕУКУДІЪЧКмЖрааЮЊЖМЛсКЭ Hive ЕФЯрвЛжТЃЌЗНБуХХВщЮЪЬтЃЛБШШчЩОГ§ЮФМўЕН TrashЃЌжЎЧА
SparkSQL ЩОГ§БэЛђепЗжЧјКѓЪЧВЛЛсТфЕН Trash ЕФЁЃ
2.3 аЁЮФМўЮЪЬт
ЮвУЧдкЪЙгУ SparkSQL Й§ГЬжаЃЌЗЂЯжаЁЮФМўЕФЮЪЬтБШНЯбЯжиЃЌSparkSQL дкаДЪ§ОнЪБЛсВњЩњКмЖраЁЮФМўЃЌЛсЖд
namenode ВњЩњКмДѓЕФбЙСІЃЌНјЖјДјРДећИіЯЕЭГЮШЖЈадЕФвўЛМЃЌзюНќШ§ИідТЮФМўИіЪ§МИКѕЗСЫИіБЖЁЃЖдгкаЁЮФМўЮЪЬтЃЌЮвУЧВЩгУСЫЩчЧј
SPARK-24940 ЕФЗНЪНДІРэЃЌНшжњ SQL hint ЕФЗНЪНКЯВЂаЁЮФМўЁЃЭЌЪБЃЌЮвУЧгавЛИізЈУХзі
merge ЕФШЮЮёЃЌЖЈЪБвьВНЕФЖдЬьМЖБ№ЕФЗжЧјЩЈУшВЂзіаЁЮФМўКЯВЂЁЃ
ЛЙгавЛЕуЪЧ spark.hadoop.mapreduce .fileoutputcommitter.algorithm.version=2,
MapReduce-4815 ЯъЯИНщЩмСЫ fileoutputcommitter ЕФдРэЃЌЪЕМљжаЩшжУСЫ
version=2 ЕФБШФЌШЯ version=1 ЕФМѕЩйСЫ 70% вдЩЯЕФ commit ЪБМфЁЃ
Ш§. SparkSQL ЧЈвЦжЎТЗ
НтОіСЫДѓВПЗжЕФПЩгУадЮЪЬтвдКѓЃЌЮвУЧж№ВНПЊЪМСЫ SparkSQL ЕФЭЦЙуЃЌв§ЕМгУЛЇбЁдё SparkSQL
в§ЧцЃЌОјДѓВПЗжЕФШЮЮёЕФадФмФмЕУЕННЯДѓЕФЬсЩ§ЁЃгкЪЧЮвУЧНјвЛВНПЊЪМНЋдРД Hive жДааЕФШЮЮёЯђ SparkSQL
зЊвЦЁЃ
дк SparkSQL ЧЈвЦжЎГѕЃЌЮвУЧбЁдёЕФТЗЯпЪЧзёбЖўАЫЗЈдђЃЌДггХЛЏКФЗбзЪдДзюЖрЕФЭЗВПШЮЮёПЊЪМЃЌАб
Top100 ЕФШЮЮёДг Hive Эљ SparkSQL ЧЈвЦЃЌж№ВНЛ§РлЕфаЭДэЮѓЃЌАќРЈ SparkSQL
КЭ Hive ЕФВЛвЛжТааЮЊЃЌБШНЯЕфаЭЕФЮЪЬтгЩ ORC ИёЪНЮФМўЮЊПеЃЌSpark ЛсХзПежИеывьГЃЖјЪЇАмЃЌORC
ИёЪНКЭ metastore РраЭВЛвЛжТЃЌSparkSQL вВЛсБЈДэЪЇАмЁЃОЙ§вЛВЈШЫЙЄЭЦЙужЎКѓЃЌЭЗВПШЮЮёНкЪЁЕФзЪдДЯрЕБПЭЙлЃЌдк
2017 ФъЕзЃЌЧаЛЛЕН SparkSQL ЕФШЮЮёЪ§еМБШ 5%ЃЌеМЕФзЪдД 20%ЃЌзЪдДЪЙгУНіеМ Hive
дЫааЕФ 10%-30%ЁЃ
дк case by case ДІРэСЫвЛЖЮЪБМфвдКѓЃЌЮвУЧЗЂЯжетжжЗНЪНВЛЬЋФмЙЛРЉеЙСЫЁЃЪзЯШКЭзївЕЕФ owner
аЩЬаоИФашвЊЙЕЭЈГЩБОЃЌЖјЧваЁзївЕЕФИФЖЏЪевцВЛЪЧФЧУДДѓЃЌзївЕЕФ owner зіетбљЕФИФЖЏЖдЫћРДЫЕЪевцБШНЯаЁЃЌЗДЖјгавЛЖЈИХТЪЕФЗчЯеЁЃЫљвдЕНетИіНзЖЮ
SparkSQL ЕФЧЈвЦжЎТЗНјеЙБШНЯЛКТ§ЁЃ
гкЪЧЮвУЧПЊЪМЙЙЫМздЖЏЛЏЧЈвЦЗНЪНЃЌЙЙЫМСЫвЛжжжДаав§ЧцжЎЩЯЕФжЧФмжДаав§ЧцбЁдёЗўЮё SQL Engine
Proposer(proposer)ЃЌПЩвдИљОнВщбЏЕФЬиеївдМАЕБЧАМЏШКжаЕФЖгСазДЬЌЮЊ SQL ВщбЏбЁдёКЯЪЪЕФжДаав§ЧцЁЃЪ§ОнЦНЬЈЯђФГИіжДаав§ЧцЬсНЛВщбЏжЎЧАЃЌЛсЯШЗУЮЪжЧФмжДаав§ЧцбЁдёЗўЮёЁЃдкбЁЖЈКЯЪЪЕФжДаав§ЧцжЎКѓЃЌЪ§ОнЦНЬЈНЋШЮЮёЬсНЛЕНЖдгІЕФв§ЧцЃЌАќРЈ
HiveЃЌSparkSQLЃЌвдМАНЯДѓФкДцХфжУЕФ SparkSQLЁЃ
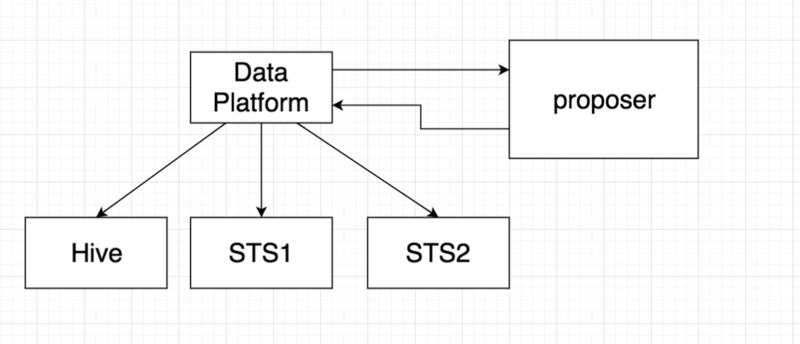
ВЂЧвдк SQL Engine ProposerЃЌЮвУЧЬэМгСЫвЛЯЕСаВпТдЃК
ЙцдђВпТдЃЌетаЉЙцдђПЩвдЪЧФГвЛжж SQL patternЃЌproposer ЪЙгУ Antlr4 РДДІРэжДаав§ЧцЕФгяЗЈЃЌЖдгкФГаЉЧЈвЦгаЮЪЬтЕФЮЪЬтЃЌНЋетжж
pattern ЪЖБ№ГіРДЃЌЬэМгЕНЙцдђМЏКЯжаЃЌЕфаЭЕФЙцдђгаУЛгаЗЂЩњ shuffle ЕФШЮЮёЃЌЛђепжЛЗЂЩњ
broadcast join ЕФШЮЮёЃЌетаЉШЮЮёгаПЩФмЛсВњЩњКмЖраЁЮФМўЃЌВЂЧвТпМвЛАуБШНЯМђЕЅЃЌЪЙгУ Hive
дЫаазЪдДЯћКФВЛЛсЬЋЖрЁЃ
АзУћЕЅВпТдЃЌгааЉШЮЮёЯЃЭћОЭЪЧгУ Hive жДааЃЌОЭЭЈЙ§АзУћЕЅЙ§ТЫЁЃЕБ Hive КЭ SparkSQL
ааЮЊВЛвЛжТЕФЪБКђЃЌвВПЩвдЯШМгШыетИіМЏКЯжаЃЌБЃГжжДааКЭЮЪЬтЖЈЮЛФмЙЛЭЌЪБНјааЁЃ
гХЯШМЖВпТдЃЌдкЛвЖШЧЈвЦЕФЪБКђЃЌЪЧДгЕЭгХЯШМЖШЮЮёПЊЪМЕФЃЌдк proposer жаЮвУЧХфжУСЫЛвЖШЕФВпТдЃЌДгЕЭгХЯШМЖШЮЮёЧавЛЖЈЕФСїСППЊЪМЧЈвЦЃЌж№ВНЗХПЊЃЌдкгХЯШМЖФкДяЕНШЋСПЃЌФПЧАЗХПЊСЫГ§
P1P2 вдЭтЕФ 3 МЖШЮЮёЁЃ
Й§ЭљжДааМЧТМЃЌproposer бЁдёЪБЛсИљОнРњЪЗжДааГЩЙІЧщПівдМАжДааЪБМфЃЌШчЙћ SparkSQL аЇТЪБШ
Hive гаЯджјЬсЩ§ЃЌВЂЧвдкЙ§ШЅвЛжБжДааГЩЙІЃЌФЧУД proposer ЛсИќЧуЯђгкбЁдё SparkSQLЁЃ
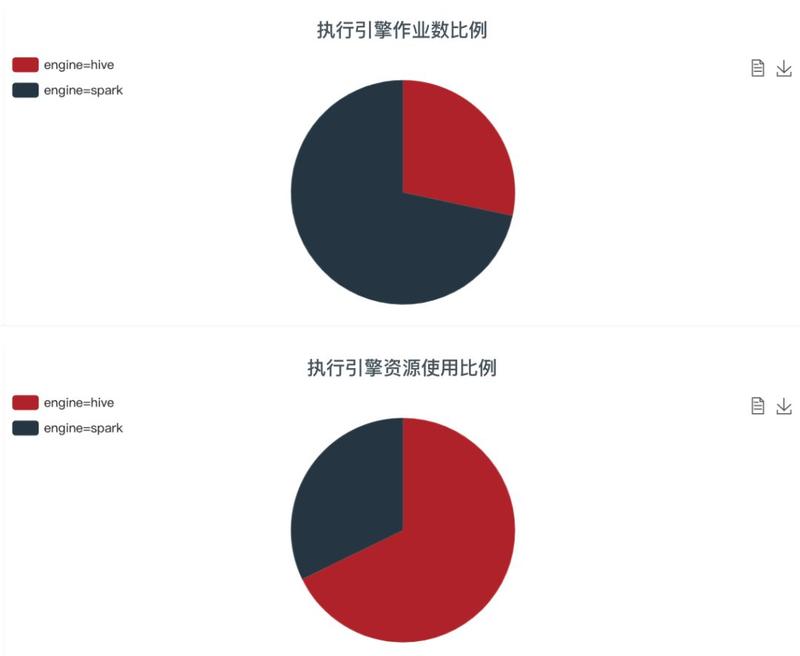
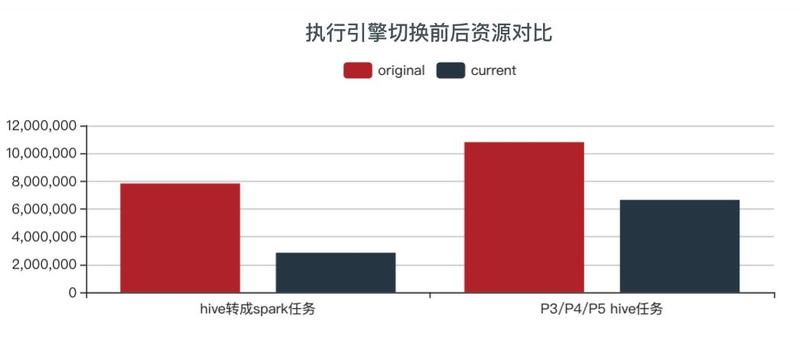
НижЙФПЧАЃЌжДаав§ЧцбЁдёЕФзївЕЪ§жа SparkSQL еМБШДяЕНСЫ 73%ЃЌЪЙгУзЪдДНіеМ 32%ЃЌЧЈвЦЕН
SparkSQL дЫааЕФзївЕДјРДСЫ 67% зЪдДЕФНкЪЁЁЃ
ЮДРДеЙЭћ
ЮвУЧМЦЛЎ Hadoop МЏШКзЪдДНјвЛВНЯђ SparkSQL ЗНЯђзЊвЦЃЌДяЕН 80%ЃЌзївЕЪ§Дя 70%ЃЌАбзюИпгХЯШМЖвВПЊЗХЕНбЁдёв§ЧцЃЌв§Шы
Intel ПЊдДЕФ Adaptive Execution ЙІФмЃЌгХЛЏжДааЙ§ГЬжаЕФ shuffle Ъ§ФПЃЌжДааЙ§ГЬжаЛљгкДњМлЕФ
broadcast join гХЛЏЃЌЬцЛЛ sort merge joinЃЌЭЌЪБИќГЙЕзНтОіаЁЮФМўЮЪЬтЁЃ |









