| БрМЭЦМі: |
| БОЮФРДздгкcnblogsЃЌБОЮФжївЊНщЩмСЫELKШежОЗжЮіЦНЬЈЪЙгУБГОАЁЂДюНЈЛЗОГвдМАДюНЈЙ§ГЬЕШЯрЙиФкШнЁЃ |
|
вЛЁЂЪЙгУБГОА
ЕБЩњВњЛЗОГгаКмЖрЗўЮёЦїЁЂКмЖрвЕЮёФЃПщЕФШежОашвЊУПЪБУППЬВщПДЪБ
ЖўЁЂЛЗОГ
ЯЕЭГЃКcentos 6.5
JDKЃК1.8
Elasticsearch-5.0.0
Logstash-5.0.0
kibana-5.0.0
Ш§ЁЂАВзА
1ЁЂАВзАJDK
ЯТдиJDKЃКhttp://www.oracle.com/technetwork/java
/javase/downloads/jdk8-downloads-2133151.html
БОЛЗОГЯТдиЕФЪЧ64ЮЛtar.gzАќЃЌНЋАВзААќПНБДжСАВзАЗўЮёЦї/usr/localФПТМ
[root@localhost ~]# cd /usr/local/
[root@localhost local]# tar -xzvf jdk-8u111-linux-x64.tar.gz
ХфжУЛЗОГБфСП
[root@localhost local]# vim /etc/profile
НЋЯТУцЕФФкШнЬэМгжСЮФМўФЉЮВЃЈМйШчЗўЮёЦїашвЊЖрИіJDKАцБОЃЌЮЊСЫELKВЛгАЯьЦфЫќЯЕЭГЃЌвВПЩвдНЋЛЗОГБфСПЕФФкШнЩдКѓЬэМгЕНELKЕФЦєЖЏНХБОжаЃЉ
JAVA_HOME=/usr/local/jdk1.8.0_111
JRE_HOME=/usr/local/jdk1.8.0_111/jre
CLASSPATH=.:$JAVA_HOME/lib:/dt.jar:$JAVA_HOME
/lib/tools.jar
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME
export JRE_HOME
ulimit -u 4096
[root@localhost local]# source /etc/profile
ХфжУlimitЯрЙиВЮЪ§
[root@localhost local]# vim /etc/security/limits.conf
ЬэМгвдЯТФкШн
* soft nproc 65536
* hard nproc 65536
* soft nofile 65536
* hard nofile 65536
ДДНЈдЫааELKЕФгУЛЇ
[root@localhost local]# groupadd elk
[root@localhost local]# useradd -g elk elk
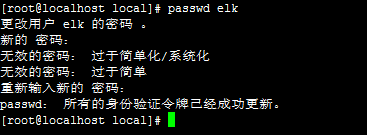
ДДНЈELKдЫааФПТМ
[root@localhost local]# mkdir /elk
[root@localhost local]# chown -R elk:elk /elk
ЙиБеЗРЛ№ЧНЃК
[root@localhost ~]# iptables -F
вдЩЯШЋВПЪЧrootгУЛЇЭъГЩ
2ЁЂАВзАELK
вдЯТгЩelkгУЛЇВйзї
вдelkгУЛЇЕЧТМЗўЮёЦї
ЯТдиELKАВзААќЃКhttps://www.elastic.co/downloadsЃЌВЂЩЯДЋЕНЗўЮёЦїЧвНтбЙЃЌНтбЙУќСюЃКtar
-xzvf АќУћ

ХфжУElasticsearch

аоИФШчЯТФкШнЃК

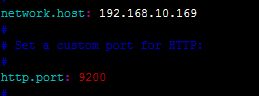
БЃДцЭЫГі
ЦєЖЏElasticsearch

ВщПДЪЧЗёЦєЖЏГЩЙІ
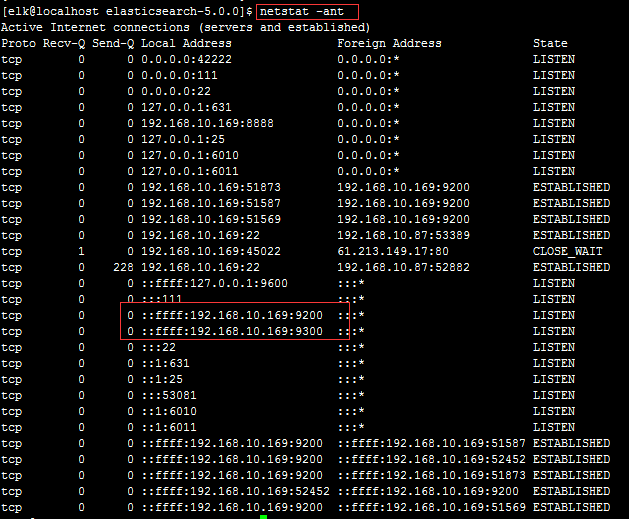
гУфЏРРЦїЗУЮЪЃКhttp://192.168.10.169:9200
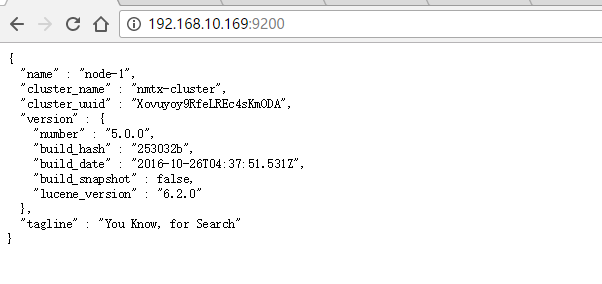
ElasticsearchАВзАЭъБЯ
АВзАlogstash
logstashЪЧELKжаИКд№ЪеМЏКЭЙ§ТЫШежОЕФ

БраДХфжУЮФМўШчЯТЃК
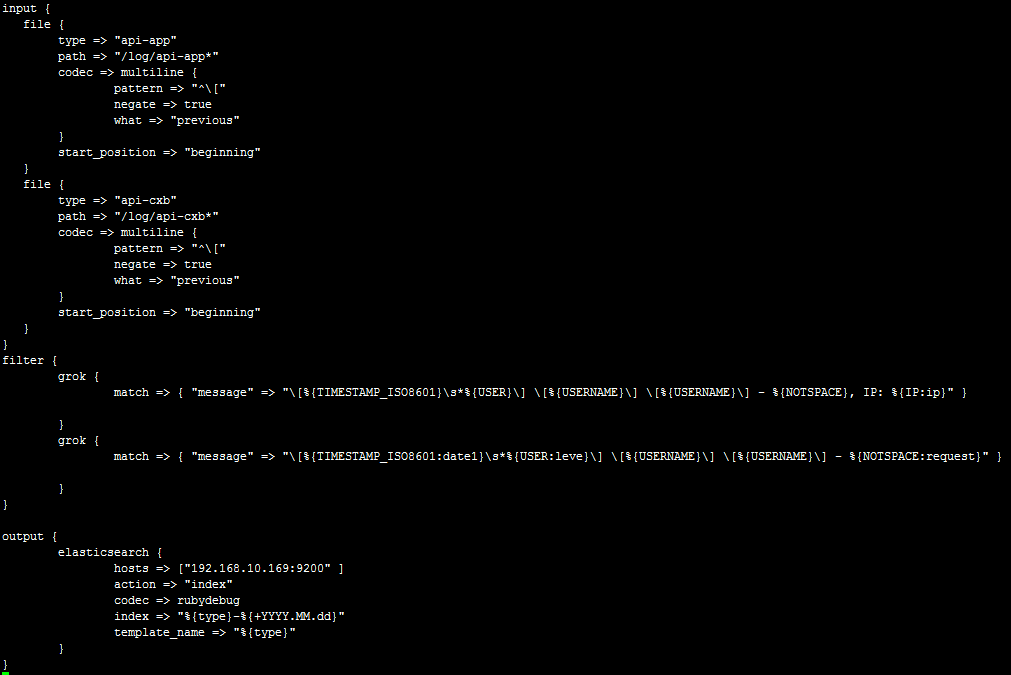
НтЪЭЃК
logstashЕФХфжУЮФМўаыАќКЌШ§ИіФкШнЃК
input{}ЃКДЫФЃПщЪЧИКд№ЪеМЏШежОЃЌПЩвдДгЮФМўЖСШЁЁЂДгredisЖСШЁЛђепПЊЦєЖЫПкШУВњЩњШежОЕФвЕЮёЯЕЭГжБНгаДШыЕНlogstash
filter{}ЃКДЫФЃПщЪЧИКд№Й§ТЫЪеМЏЕНЕФШежОЃЌВЂИљОнЙ§ТЫКѓЖдШежОЖЈвхЯдЪОзжЖЮ
output{}ЃКДЫФЃПщЪЧИКд№НЋЙ§ТЫКѓЕФШежОЪфГіЕНelasticsearchЛђепЮФМўЁЂredisЕШ
БОЛЗОГВЩгУДгЮФМўЖСШЁШежОЃЌвЕЮёЯЕЭГВњЩњШежОЕФИёЪНШчЯТЃК
[2016-11-05 00:00:03,731 INFO] [http-nio-8094-exec-10]
[filter.LogRequestFilter] - /merchant/get-supply-detail.shtml,
IP: 121.35.185.117, [device-dpi = 414*736, version
= 3.6, device-os = iOS8.4.1, timestamp = 1478275204,
bundle = APYQ9WATKK98V2EC, device-network = WiFi,
token = 393E38694471483CB3686EC77BABB496, device-model
= iPhone, device-cpu = , sequence = 1478275204980,
device-uuid = C52FF568-A447-4AFE-8AE8-4C9A54CED10C,
sign = 0966a15c090fa6725d8e3a14e9ef98dc, request =
{
"supply-id" : 192
}]
[2016-11-05 00:00:03,731 DEBUG] [http-nio-8094-exec-10]
[filter.ValidateRequestFilter] - Unsigned: bundle=APYQ9WATKK98V2EC&device-cpu=&device-dpi=414*736&device-model=iPhone&device-network=WiFi&device-os=iOS8.4.1&device-uuid=C52FF568-A447-4AFE-8AE8-4C9A54CED10C&request={
"supply-id" : 192
outputжБНгЪфГіЕНElasticsearch
БОЛЗОГашДІРэСНЬзвЕЮёЯЕЭГЕФШежО
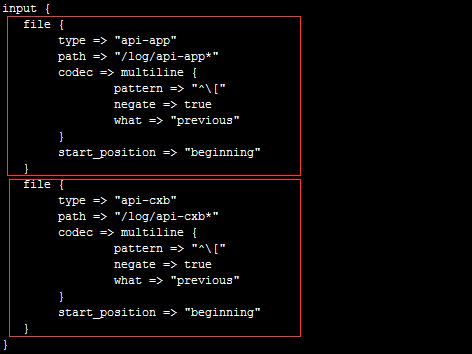
typeЃКДњБэРраЭЃЌЦфЪЕОЭЪЧНЋетИіРраЭЭЦЫЭЕНElasticsearchЃЌЗНБуКѓУцЕФkibanaНјааЗжРрЫбЫїЃЌвЛАужБНгУќУћвЕЮёЯЕЭГЕФЯюФПУћ
pathЃКЖСШЁЮФМўЕФТЗОЖ
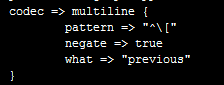
етИіЪЧДњБэШежОБЈДэЪБЃЌНЋБЈДэЕФЛЛааЙщЪєгкЩЯвЛЬѕmessageФкШн
start_position => "beginning"ЪЧДњБэДгЮФМўЭЗВППЊЪМЖСШЁ

filter{}жаЕФgrokЪЧВЩгУе§дђБэДяЪНРДЙ§ТЫШежОЃЌЦфжа%{TIMESTAMP_ISO8601}ДњБэвЛИіФкжУЛёШЁ2016-11-05
00:00:03,731ЪБМфЕФе§дђБэДяЪНЕФКЏЪ§ЃЌ%{TIMESTAMP_ISO8601:date1}ДњБэНЋЛёШЁЕФжЕИГИјdate1ЃЌдкkibanaжаПЩвдЬхЯжГіРД
БОЛЗОГгаСНЬѕgrokЪЧДњБэЃЌЕквЛЬѕВЛЗћКЯНЋжДааЕкЖўЬѕ
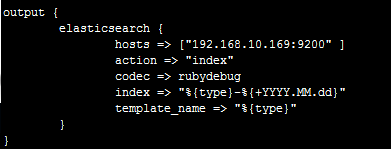
ЦфжаindexЪЧЖЈвхНЋЙ§ТЫКѓЕФШежОЭЦЫЭЕНElasticsearchКѓДцДЂЕФУћзж
%{type}ЪЧЕїгУinputжаЕФtypeБфСП(КЏЪ§)
ЦєЖЏlogstash

ДњБэЦєЖЏГЩЙІ
АВзАkibana

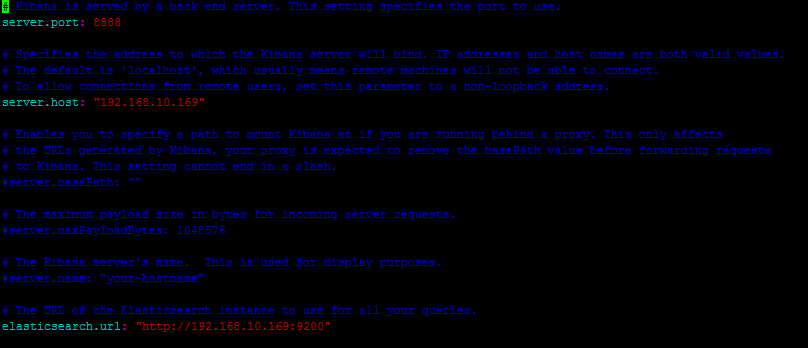
БЃДцЭЫГі
ЦєЖЏkibana

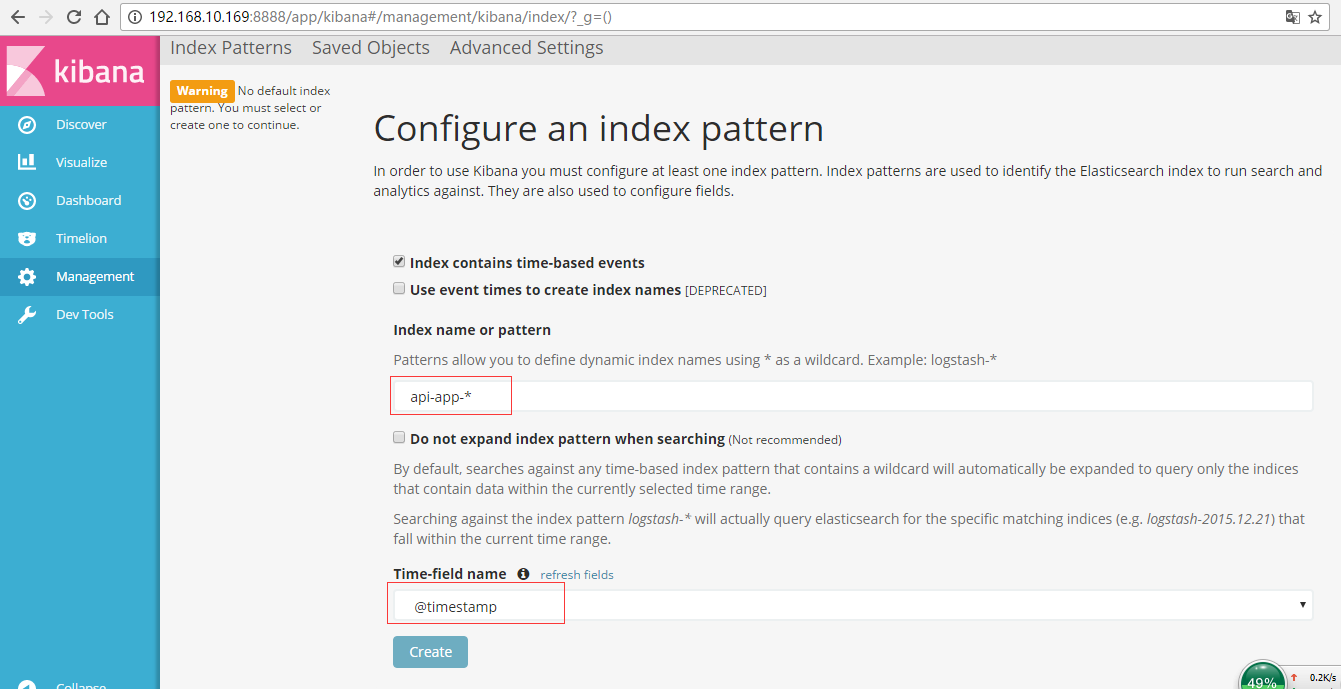
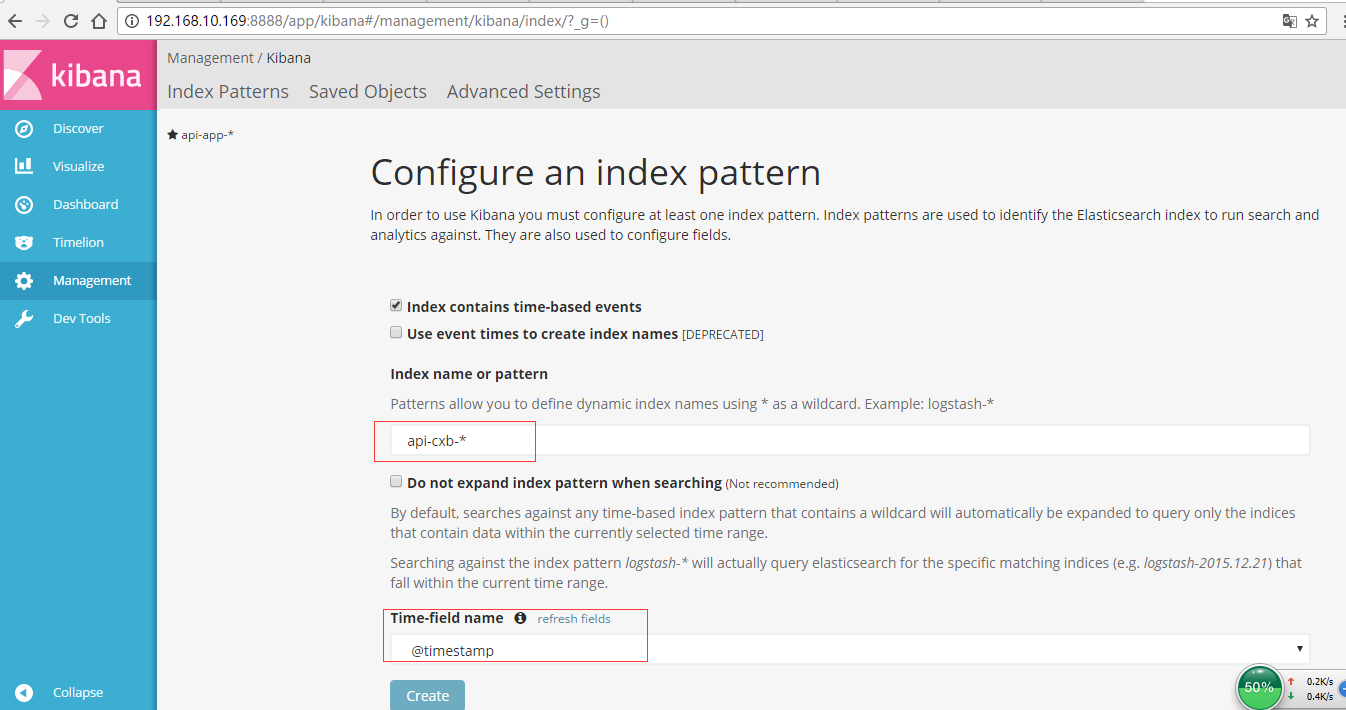
Цфжаapi-app-*КЭapi-cxb-*ДгРДЕФЃЌ*ДњБэЫљга
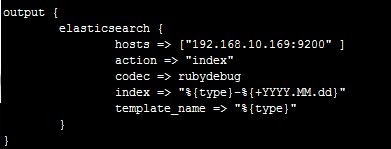
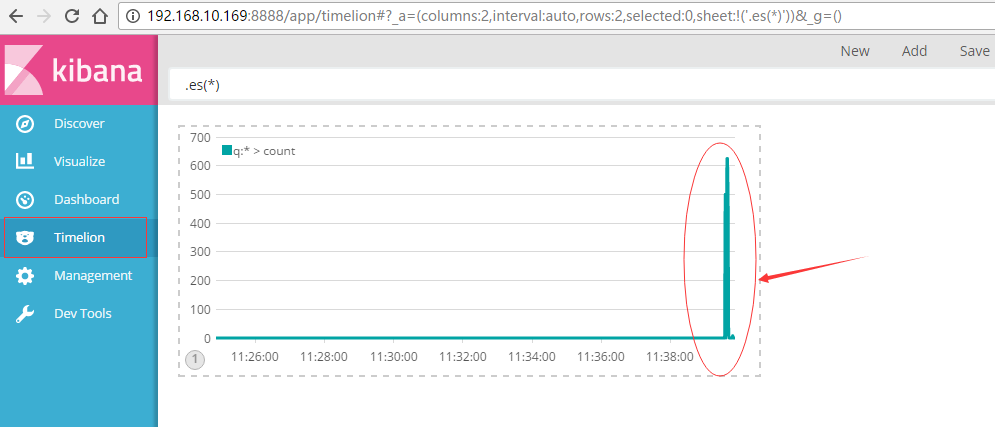
ДњБэЪЕЪБЪеМЏЕФШежОЬѕЪ§
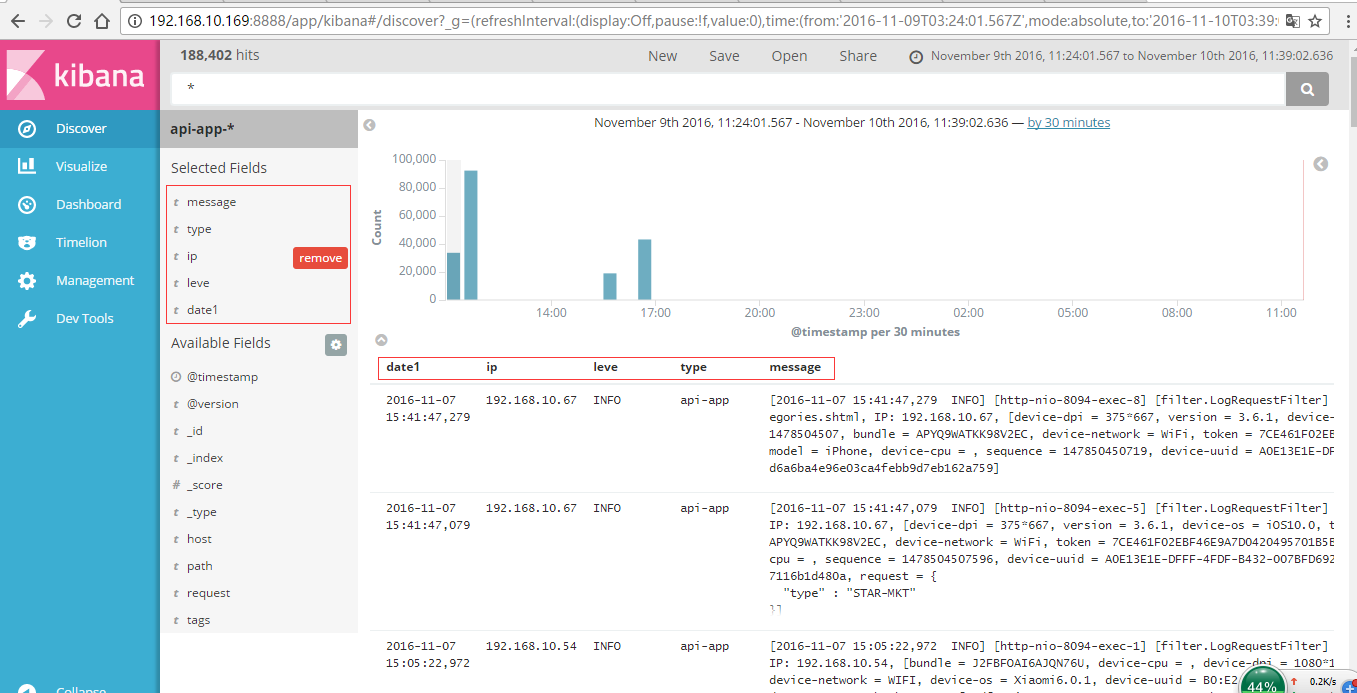
КьЩЋПђФкЕФОЭЪЧдкИеВХfilterЙ§ТЫЙцдђжаЖЈвхЕФ |









