| БрМЭЦМі: |
| БОЮФРДздгкaliyunЃЌБОЮФжївЊНщЩмСЫHBaseдк360ЕФЪЙгУЧщПіЁЂЛљгкHBaseЪЕЯжЕФЙІФмКЭИФНјЕШЁЃ |
|
вЛЁЂHBaseдк360ЕФЪЙгУЧщПі
ДгЪ§ОнРДПДЃЌ360ФПЧАЙВга27ИіHBaseМЏШКЃЌЦфжадкЯпМЏШК9ИіЃЌзлКЯМЏШК3ИіЁЃећИі360ЙВга12500ИіHBaseНкЕуЃЌЕЅМЏШКзюЖрга2184ИіRegionServerЁЃ360
ЕФHBaseМЏШКЙВга1885ИіTableвдМА719703ИіRegionЃЌЖјЕЅБэзюДѓЕФRegionЪ§ЮЊ74788ЁЃДЫЭтЃЌДгвЕЮёВуУцРДПДЃЌ360ЕФHBaseМЏШКУПУыжгДѓдМашвЊЯьгІ3АйЭђДЮЧыЧѓЁЃЭЈЙ§етаЉЪ§ОнвВФмЙЛЫЕУїЃЌФПЧАЖдгк360ЖјбдЃЌЮоТлЪЧHBaseМЏШКЛЙЪЧНкЕуЃЌЪ§СПЖМЗЧГЃХгДѓЃЌЧыЧѓСПвВЗЧГЃДѓЁЃЖјШчНёЃЌећИі360БГКѓЕФМИДѓживЊвЕЮёЖМгаHBaseЕФЩэгАЃЌБШШч360ЫбЫїЁЂАВШЋвЕЮёвдМА360Н№ШкКЭIoTЕШБГКѓЖМЪЙгУСЫHBaseДцДЂЪ§ОнРДжЇГХвЕЮёЕФПьЫйЗЂеЙЁЃ
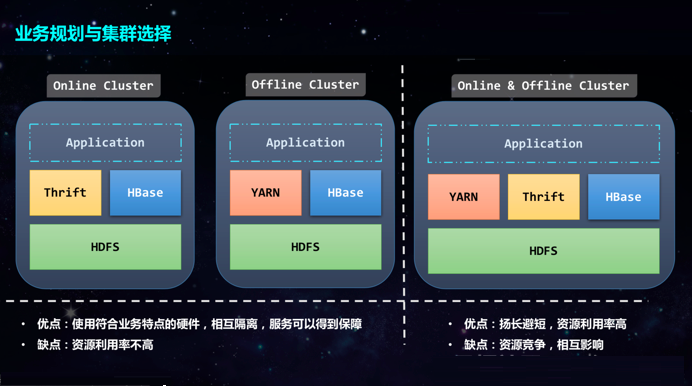
еыЖдШчДЫжкЖрЕФвЕЮёГЁОАЃЌ360ИљОнвЕЮёЬиЕуНЋЦфЗжЮЊСЫШ§РрЃК
ЕквЛРрвЕЮёЖдЯьгІЪБМфБШНЯУєИаЃЌетРрвЛАуЪЧдкЯпвЕЮёЃЌЫљЪЙгУЕФЗНЪНОЭЪЧЪЕЪБДцШЁЪ§ОнЁЃЖдгкДЫРрвЕЮёЃЌвЛАуЖјбдЛсНЋЦфЗХЕНЯпМЏШКжЎЩЯЃЌдкЯпМЏШКЕФЗўЮёЦїХфжУЃЈCPUЁЂФкДцЁЂДјПэЕШЃЉЖМЛсЯрЖдИќИпвЛаЉЁЃгыДЫЭЌЪБЃЌЮЊСЫБЃжЄЗўЮёжЪСПЃЌВЛЛсдкетаЉМЏШКжаХмMRЛђSparkЕШМЦЫузївЕЁЃ
ЕкЖўРрвЕЮёЖдДХХЬШнСПвЊЧѓНЯИпЃЌЦфгІгУГЁОАвЛАуЪЧЖЈЦкХњСПаДШыДѓСПЪ§ОнЃЌВЂжмЦкадЕиНјааРыЯпЗжЮіЛђБИЗнЁЃетРрвЕЮёЛсБЛЗХЕНРыЯпМЏШКЩЯЃЌЖјРыЯпМЏШКвЛАуЛсХфжУДѓгВХЬЃЌЖјCPUЁЂФкДцХфжУвВЛсЯргІЕЭвЛЕуЁЃЖдгкДЫРрвЕЮёЃЌ360ЕФHBaseЭХЖгвВПЊЗЂСЫвЛаЉMRзївЕЃЌвдАяжњвЕЮёПЩвдЗНБуЕФДѓХњСПЖСаДЁЂЗжЮіHBaseжаЕФЪ§ОнЁЃ
ЕкШ§РрвЕЮёЪєгкЕквЛРрКЭЕкЖўРржаМфЕиДјЕФЧщПіЃЌетРрвЕЮёЖдДХХЬШнСПКЭЯьгІЪБМфгаВПЗжвЊЧѓЃЌЕЋВЂВЛЪЎЗжУєИаЃЌБШШчМрПиЁЂЛКДцЫндДЁЂБЈБэЕШАыдкЯпвЕЮёЁЃетРрвЕЮёвЛАуЛсЗХЕНзлКЯМЏШКжаЃЌзлКЯМЏШКЕФХфжУКЭдкЯпМЏШКЯрЕБЃЌетИіМЏШКМШПЩвдзідкЯпЖСаДHBaseЃЌвВПЩвдХмРыЯпЗжЮізївЕЃЌвђДЫПЩвдГфЗжЕФРћгУгВМўзЪдДЁЃЕЋетбљЕФШБЕувВКмУїЯдЃЌФЧОЭЪЧЛсГіЯжзЪдДОКељКЭЯрЛЅгАЯьЕФЧщПіЁЃ
ЖўЁЂЛљгкHBaseЪЕЯжЕФЙІФмКЭИФНј
ЖўМЖЫїв§
ЮЊСЫИќКУЕижЇГХвЕЮёЃЌ360дкHBase0.89-FacebookАцБОЩЯЪЕЯжКЭИФНјСЫвЛаЉЙІФмЁЃЖдгкHBaseЖјбдЃЌЦфВщбЏЗНЪНжївЊгаСНжжЃЌМДgetКЭscanЁЃgetВщбЏЫйЖШПьЃЌЕЋжЛПЩвдЛљгкRowKeyНјааВщбЏЃЌЫфШЛПЩвдЩшМЦзщКЯзжЖЮЕФRowKeyЃЌЕЋВЛСщЛюЃЌЪЙгУИДдгЃЌЖјЧвШнвздьГЩЪ§ОнЧуаБЁЃscanВщбЏдђЛсЯћКФДѓСПзЪдДЃЌЖјЧвЮоЗЈБЃжЄЪБаЇадЁЃЮЊСЫИќКУЕиЪЕЯжHBaseЕФВщбЏЃЌ360дкЖўМЖЫїв§ЩЯзіСЫКмЖрЙЄзїЁЃ
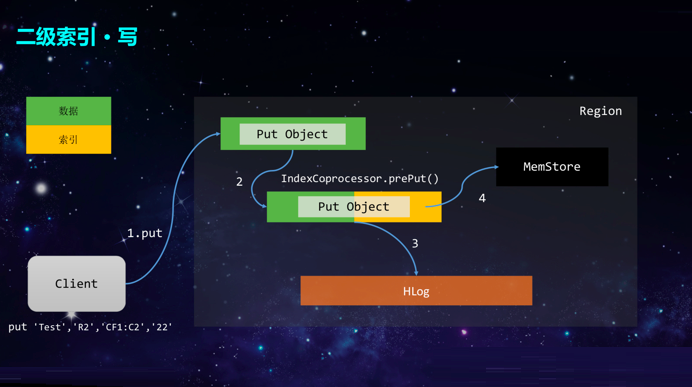
ФПЧАЃЌвЕНчЖдгкЖўМЖЫїв§ЕФЪЕЯжЗНАИДѓЬхЗжЮЊСНРрЃКШЋОжЖўМЖЫїв§ЗНАИКЭОжВПЖўМЖЫїв§ЗНАИЃЌСНжжЗНАИИїгагХСгЃЌЖј360бЁдёСЫОжВПЖўМЖЫїв§ЗНАИЁЃвдЯТЭМЕФTestБэЮЊР§ЃЌЮЊCF1:C2СаНЈСЂСЫЖўМЖЫїв§ЃЌДЫЪБЃЌдкБэЕФЭЌИіRegionжаЃЌГ§СЫдРДЕФЪ§ОнЃЌЛЙЛсВхШыЫїв§Ъ§ОнЃЌжЛВЛЙ§Ыїв§Ъ§ОнДцДЂдквЛИіЬиЪтЕФINDEX
Column FamilyжаЁЃЖдгкЫїв§Ъ§ОнЕФRowKeyЖјбдЃЌвдRegionЕФStartKeyПЊЭЗвдБЃжЄКЭдЪМЪ§ОндкЭЌвЛИіRegionжаЃЌвдецЪЕЪ§ОнЕФRowKeyНсЮВЃЌвдБЃжЄЫїв§Ъ§ОнRowKeyЕФЮЈвЛадЁЃЫїв§Ъ§ОнЕФValueЃЌжЛЪЧМЧТМСЫЫїв§RowKeyВЛЭЌВПЗжЕФГЄЖШЃЌвдЗНБуЗДађСаЛЏRowKeyЕФИїИіВПЗжЁЃдкНјаааДЪ§ОнЕФЪБКђЃЌПЩФмашвЊЦДГіРДЫїв§Ъ§ОнШЛКѓВхШыЕНБэжаЁЃдкЖСЪ§ОнЕФЪБКђЃЌОЭПЩвдЭЈЙ§StartKeyЁЂINDEX
nameКЭValueЦДГіРДЕФscanВщбЏгяОфНЋЫїв§Ъ§ОнШЁГіРДЃЌЛёЕУЫљашвЊВщбЏЪ§ОнЕФRowKeyСаБэЃЌдйШЅСаБэжаШЁГіецЪЕЪ§ОнЁЃ

ЖдгкаДЗНАИЕФОпЬхЪЕЯжЃЌМђЕЅЖјбдОЭЪЧЪЙгУСЫHBaseздДјЕФаДІРэЦїЃЌвђДЫПЩвдЪЕЯжСуЧжШыЕФЖўМЖЫїв§ЗНАИЁЃЕБПЭЛЇЖЫашвЊPutЪ§ОнЕФЪБКђЃЌаДІРэЦїПЩвддкPutжЎЧАНЋЖўМЖЫїв§ЕФЪ§ОнвВМгШыашвЊДЋЪфЕФЖдЯѓжаЃЌвдБЃжЄдзгадЁЃ
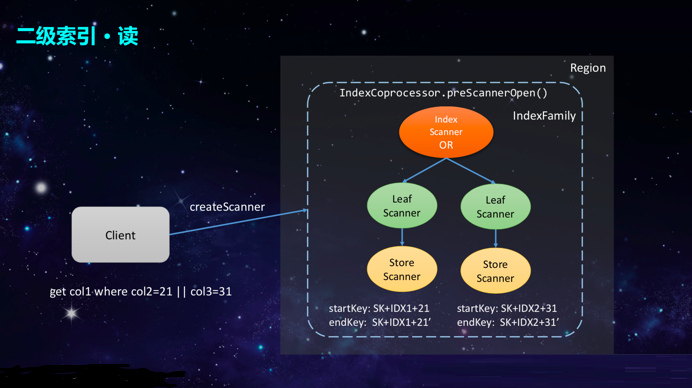
ЖдгкЖСЗНАИЕФОпЬхЪЕЯжЖјбдЃЌОЭЪЧашвЊЯШДДНЈвЛИіScannerЃЌдйЕїгУNext()ЗНЗЈРДЖСШЁЪ§ОнЁЃ360ЕФЗНАИжЇГжРрSQLаДЗЈЃЌЫљвдЕБПЭЛЇЖЫЪеЕНРрSQLЧыЧѓЪБЃЌЛсЯШНјаагяЗЈНтЮіЃЌШчЙћгяЗЈУЛЮЪЬтЃЌдђЛсЙЙдьвЛИіscanЖдЯѓЃЌВЂЧыЧѓRegion
ServerРДCreateScannerЁЃдкRegion ServerЖЫЃЌдђЭЈЙ§аДІРэЦїРДРЙНиЃЌВЂИљОнЧыЧѓЙЙдьГівЛИіScannerгяЗЈЪїЁЃ
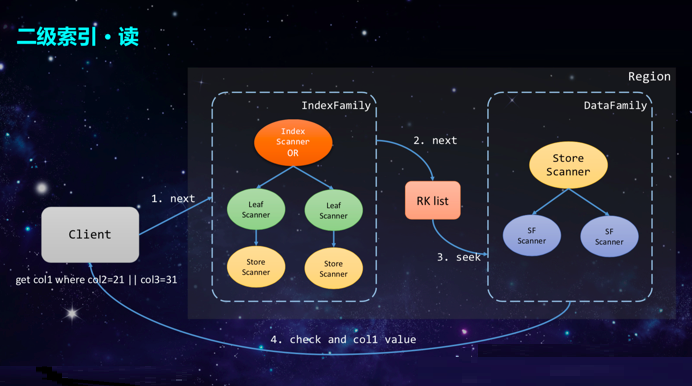
дкДДНЈЭъScannerжЎКѓЃЌЯТвЛВНОЭЪЧЭЈЙ§next()ЗНЗЈЖСШЁЪ§ОнЁЃетВПЗжвВЗжЮЊСНВНЃЌЯШВщбЏЫїв§Ъ§ОнЃЌШЛКѓЗДађСаЛЏГіецЪЕЪ§ОнЕФRowKeyСаБэЃЌжЎКѓЪЙгУетИіRowKeyСаБэШЅВщбЏецЪЕЪ§ОнЕФColumn
FamilyЁЃВщбЏГіЪ§ОнжЎКѓЃЌашвЊМьВщЪ§ОнЪЧЗёгааЇЃЌШЛКѓНЋЪ§ОнЗЕЛиИјПЭЛЇЖЫЁЃЖдгкЖўМЖЫїв§ЕФЖССїГЬЖјбдЃЌашвЊЯШВщбЏЫїв§Ъ§ОнЃЌдйВщбЏецЪЕЪ§ОнЃЌвђДЫашвЊВщбЏСНДЮЁЃЦфЪЕЃЌЖдгкДЫСїГЬЖјбдЃЌвВПЩвдМЬајНјаагХЛЏЃЌБШШчАбецЪЕЪ§ОнвВађСаЛЏЕН
INDEX familyЕФValueжаЃЌетбљвЛРДжЛашвЊВщбЏвЛДЮЫїв§Ъ§ОнМДПЩЗЕЛиИјПЭЛЇЖЫЁЃ
ПчМЏШКБИЗн
ЮЊСЫЪЕЯжHBaseИќИпЕФПЩгУадКЭЗНБувЕЮёОЭНќЗУЮЪЪ§ОнЃЌ360ЕФHBaseЭХЖгПЊЗЂСЫПчМЏШКБИЗнЙІФмЁЃTransferTableЪЧвЛеХЦеЭЈЕФHbaseБэЃЌдкетРяПЩвдАбЫќЕБзівЛИіЛКДцЖгСаЃЌЭМжаЦфзѓВрЕФLogEntryVisitorЯрЕБгквЛИіЩњВњепЃЌИКд№ЯђTransferTableБэжааДЪ§ОнЃЌЫќгвБпЕФTransferDaemonЯрЕБгквЛИіЯћЗбепЃЌИКд№ДгTransferTableжаЖСЪ§ОнВЂЗЂЫЭЕНБИЗнМЏШКЁЃетбљЕФЩњВњеп-ЯћЗбепФЃаЭОЭЪЧПчМЏШКБИЗнЕФКЫаФТпМЁЃ
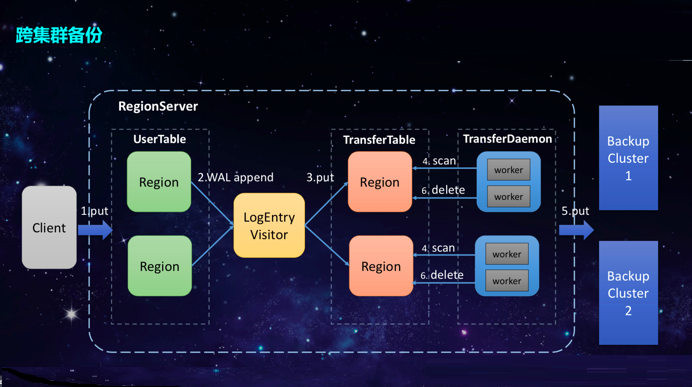
змНсЖјбдЃЌЕБПЭЛЇЖЫЯђUserTableжааДЪ§ОнЪБЃЌLogEntryVisitorЛсРЙНиWAL AppendВйзїЃЌВЂАбетЬѕМЧТМаДЕНTransferTableжаЃЌетЪЧЭЌВНЕФЙ§ГЬЁЃЮЊСЫБЃжЄаДTransferTableЕФаЇТЪЃЌ360
HBaseЭХЖгПЊЗЂСЫРрЫЦгкBalancerЙІФмЃЌБЃжЄУПИіUserTable RegionЫљдкЕФRegionServerжСЩйгавЛИіTransferRegionЃЌаДTransferTableЕФЪБКђжБНгЕїгУPutЗНЗЈМДПЩЃЌБмУтСЫВЛБивЊЕФађСаЛЏКЭЗДађСаЛЏВйзїЁЃШЛКѓЃЌTransferDaemonЯпГЬВЛЖЯДгTransferTableжаЩЈУшЪ§ОнЃЌВЂЪЙгУЖрИіЯпГЬВЂааЗЂЫЭЕНдЖЖЫЕФБИЗнМЏШКжаЁЃ
Ш§ЁЂHBase2.0 гІгУЪЕМљ
ШчНёЕФHBaseКЭЧАМИФъЫљЬИЕФHBaseвбОВювьКмДѓСЫЃЌжЎЧАЕФHBaseПЩФмНіНіжИЕФЪЧвЛИіKey-ValueаЭЕФNoSQLЪ§ОнПтЃЌЖјЯждкHBaseШДДњБэзХвЛИіЩњЬЌЃЌВЛНіЪЧKVЃЌЛЙгаЪБПеЁЂЪБађЁЂЭМЕШзщМўЁЃЫљвдЖдгкПЊЗЂзщжЏЖјбдЃЌгІИУОЁдчШкШыЩњЬЌжЎжаЃЌБмУтКѓајЕФМцШнадЮЪЬтКЭДѓСПЕФЧЈвЦЙЄзїЁЃФПЧАЃЌ360ЕФHBase2.0ЪЕМљжажївЊгаСНжжгІгУГЁОАЃЌМДЖдЯѓДцДЂЗўЮёКЭЪБађЗўЮёЁЃ
ЫФЁЂЮЪЬтгыНтОі
дкЪЙгУHBase2.0ЪБЃЌ360ЫљгіЕНЕФжївЊЮЪЬтОЭЪЧMOBЬиадЫљДјРДЕФЮЪЬтЃЌетИіаТЬиадДјРДСЫЕЅЕуCompactionЁЂMOBЮФМўЙ§гкМЏжаЃЌвдМАЮФМўЙ§ДѓВЛБуЪЭЗХПеМфЕШЮЪЬтЁЃОпЬхЕФНтОіЗНАИдђШчЯТЭМЫљЪОЃК

ШчНёЃЌHBaseжИЕФВЛдйНіНіЪЧжЎЧАЫљЬИМАЕФKey-ValueРраЭЕФNoSQLЪ§ОнПтЃЌЖјЪЧДњБэзХвЛећИіHBaseЩњЬЌЁЃзїЮЊММЪѕШЫдБЃЌЮвУЧгІИУОпБИММЪѕЧАеАадЃЌгТИвЕигЕБЇЩњЬЌЃЌВЂЮЊЩчЧјКЭЩњЬЌзіГіЙБЯзЁЃЫфШЛЃЌЩњЬЌПЩФмВЂВЛЙЛГЩЪьЃЌЕЋЪЧЬєеНБиНЋгыЛњгіВЂДцЁЃ |









