| БрМЭЦМі: |
| БОЮФРДздгкinfoqЃЌБОЮФМђЕЅЕФНщЩмСЫЕЮЕЮЕЅМЏШКМмЙЙЦПОБвдМАЕЅМЏШКЦПОБЕФЬєеНМАЖрМЏШКМмЙЙЪЕМљОбщЃЌЯЃЭћЖдФњЕФбЇЯАгаАяжњЁЃ |
|
Elasticsearch ЪЧЛљгк Lucene ЪЕЯжЕФЗжВМЪНЫбЫїв§ЧцЃЌЬсЙЉСЫКЃСПЪ§ОнЪЕЪБМьЫїКЭЗжЮіФмСІЁЃElastic
ЙЋЫОПЊдДЕФвЛЯЕСаВњЦЗзщГЩЕФ Elastic StackЃЌПЩвдЮЊШежОЗўЮёЁЂЫбЫїв§ЧцЁЂЯЕЭГМрПиЕШЬсЙЉМђЕЅЁЂвзгУЕФНтОіЗНАИЁЃ
ЕЮЕЮ Elasticsearch МђНщ
ЕЮЕЮ 2016 ФъГѕПЊЪМЙЙНЈ Elasticsearch ЦНЬЈЃЌШчНёвбОЗЂеЙЕНГЌЙ§ 3500+ Elasticsearch
ЪЕР§ЃЌГЌЙ§ 5PB ЕФЪ§ОнДцДЂЃЌЗхжЕаДШы tps ГЌЙ§СЫ 2000w/s ЕФГЌДѓЙцФЃЁЃ
Elasticsearch дкЕЮЕЮгазХЗЧГЃЗсИЛЕФЪЙгУГЁОАЃЌР§ШчЯпЩЯКЫаФЕФДђГЕЕиЭМЫбЫїЃЌПЭЗўЁЂдЫгЊЕФЖрЮЌЖШВщбЏЃЌЕЮЕЮШежОЗўЮёЕШНќЧЇИіЦНЬЈгУЛЇЁЃ
ГЌДѓЕФЙцФЃКЭЗсИЛЕФГЁОАИјЕЮЕЮ Elasticsearch ЦНЬЈДјРДСЫМЋДѓЕФЬєеНЃЌЮвУЧдкетЦкМфЛ§РлСЫЗсИЛОбщЃЌвВШЁЕУСЫвЛаЉГЩЙћЁЃБОЮФИјДѓМвЗжЯэЯТЕЮЕЮдк
Elasticsearch ЖрМЏШКМмЙЙЕФЪЕМљЁЃ
ЕЅМЏШКМмЙЙЦПОБ
НщЩмЕЅМЏШКМмЙЙЦПОБЧАЃЌЯШРДПДЯТЕЮЕЮ
Elasticsearch ЕЅМЏШКЕФМмЙЙЁЃ
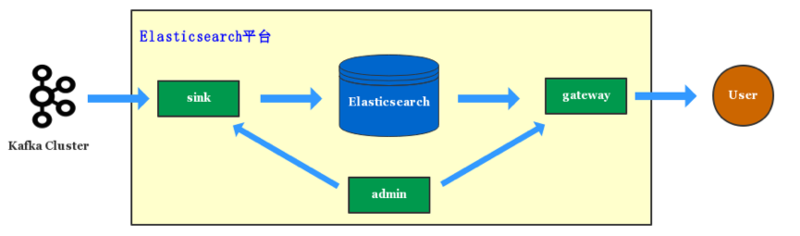
ЕЮЕЮдкЕЅМЏШКМмЙЙЕФЪБКђЃЌаДШыКЭВщбЏОЭвбОЭЈЙ§ Sink ЗўЮёКЭ Gateway ЗўЮёЙмПиЦ№РДЁЃ
Sink ЗўЮё
ЕЮЕЮМИКѕЫљгааДШы Elasticsearch ЕФЪ§ОнЖМЪЧОгЩ kafka ЯћЗбШыЕН ElasticsearchЁЃkafka
ЕФЪ§ОнАќРЈвЕЮё log Ъ§ОнЁЂmysql binlog Ъ§ОнКЭвЕЮёзджїЩЯБЈЕФЪ§ОнЃЌSink ЗўЮёНЋетаЉЪ§ОнЪЕЪБЯћЗбШыЕН
ElasticsearchЁЃ
зюГѕЩшМЦ Sink ЗўЮёЪЧЯыЖдаДШы Elasticsearch МЏШКНјааЙмПиЃЌБЃЛЄ Elasticsearch
МЏШКЃЌЗРжЙКЃСПЕФЪ§ОнаДШыЭЯПх ElasticsearchЃЌжЎКѓЮвУЧвВвЛжБбигУСЫ Sink ЗўЮёЃЌВЂНЋИУЗўЮёДг
Elasticsearch ЦНЬЈЗжРыГіШЅЃЌГЩСЂЕЮЕЮ Sink Ъ§ОнЭЖЕнЦНЬЈЃЌПЩвдДг kafka Лђеп
MQ ЪЕЪБЭЌВНЪ§ОнЕН ElasticsearchЁЂHDFSЁЂCeph ЕШЖрИіДцДЂЗўЮёЁЃ
гаСЫЖрМЏШКМмЙЙКѓЃЌElasticsearch ЦНЬЈПЩвдЯћЗбвЛЗн MQ Ъ§ОнаДШыЖрИі Elasticsearch
МЏШКЃЌзіЕНМЏШКМЖБ№ЕФШнджЃЌЛЙФмЭЈЙ§ MQ ЛиЫнЪ§ОнНјааЙЪеЯЛжИДЁЃ
Gateway ЗўЮё
ЫљгавЕЮёЕФВщбЏЖМЪЧОЙ§ Gateway ЗўЮёЃЌGateway ЗўЮёЪЕЯжСЫ Elasticsearch
ЕФ http restful КЭ tcp авщЃЌвЕЮёЗНПЩвдЭЈЙ§ Elasticsearch ИїгябдАцБОЕФ
sdk жБНгЗУЮЪ Gateway ЗўЮёЃЌGateway ЗўЮёЛЙЪЕЯжСЫ SQL НгПкЃЌвЕЮёЗНПЩвджБНгЪЙгУ
SQL ЗУЮЪ Elasticsearch ЦНЬЈЁЃ
Gateway ЗўЮёзюГѕЬсЙЉСЫгІгУШЈЯоЕФЙмПиЃЌЗУЮЪМЧТМЃЌЯоСїЁЂНЕМЖЕШЛљБОФмСІЃЌКѓУцЫцзХЦНЬЈбнНјЃЌGateway
ЗўЮёЛЙЬсЙЉСЫЫїв§ДцДЂЗжРыЁЂDSL МЖБ№ЕФЯоСїЁЂЖрМЏШКджБИЕШФмСІЁЃ
Admin ЗўЮё
ећИі Elasticsearch ЦНЬЈгЩ Admin ЗўЮёЭГвЛЙмПиЦ№РДЁЃAdmin ЗўЮёЬсЙЉСЫЫїв§ЕФЩњУќжмЦкЙмРэЃЌЫїв§ШнСПздЖЏЙцЛЎЃЌЫїв§НЁПЕЗжЃЌМЏШКМрПиЕШЗсИЛЕФЦНЬЈФмСІЃЌвдМАЮЊ
SinkЁЂGateway ЗўЮёЬсЙЉЫїв§ЁЂШЈЯоЕШдЊЪ§ОнаХЯЂЁЃ
Elasticsearch ЕЅМЏШКЦПОБ
ЫцзХЕЮЕЮ Elasticsearch ЦНЬЈЙцФЃЕФПьЫйЗЂеЙЃЌElasticsearch МЏШКдНРДдНДѓЃЌзюДѓЕФЪБКђЃЌЪЧгЩМИАйЬЈЮяРэЛњзщГЩМЏШКЃЌЕБЪБМЏШКЙВ
3000+ ЕФЫїв§ЃЌГЌЙ§СЫ 50000 Иі shardЃЌМЏШКзмШнСПДяЕНСЫ PB МЖБ№ЁЃГЌДѓЕФ Elasticsearch
МЏШКУцСйСЫКмДѓЕФЮШЖЈадЗчЯеЃЌетаЉЗчЯежївЊРДздгквдЯТШ§ИіЗНУцЃК
1.Elasticsearch МмЙЙЦПОБ
2.Ыїв§зЪдДЙВЯэЗчЯе
3.вЕЮёГЁОАВювьДѓ
Elasticsearch МмЙЙЦПОБ
Elasticsearch МмЙЙдкМЏШКБфДѓЕНвЛЖЈЕФЙцФЃЛсгіЕНЦПОБЃЌЦПОБжївЊИњ Elasticsearch
ШЮЮёДІРэФЃаЭгаЙиЁЃ
Elasticsearch ПДЦ№РДЪЧ p2p МмЙЙЃЌЕЋЪЕМЪЩЯЃЌШдШЛЪЧжааФЛЏЕФЗжВМЪНМмЙЙЁЃећИіМЏШКжЛгавЛИі
active masterЁЃmaster ИКд№ећИіМЏШКЕФдЊЪ§ОнЙмРэЁЃМЏШКЕФЫљгадЊЪ§ОнБЃДцдк ClusterState
ЖдЯѓжаЃЌжївЊАќРЈШЋОжЕФХфжУаХЯЂЁЂЫїв§аХЯЂКЭНкЕуаХЯЂЁЃжЛвЊдЊЪ§ОнЗЂЩњаоИФЃЌЖМЕУгЩ master ЭъГЩЁЃ
Elasticsearch master ЕФШЮЮёДІРэЪЧЕЅЯпГЬЭъГЩЕФЃЌУПДЮДІРэШЮЮёЃЌЩцМАЕН ClusterState
ЕФИФЖЏЃЌЖМЛсНЋзюаТЕФ ClusterState ЖдЯѓ publish ИјМЏШКЕФШЋВПНкЕуЃЌВЂзшШћЕШД§ШЋВПНкЕуНгЪмЕНБфИќЯћЯЂЃЌДІРэЭъБфИќШЮЮёКѓЃЌВХЭъГЩБОДЮШЮЮёЁЃ
етбљЕФМмЙЙФЃаЭЕМжТдкМЏШКЙцФЃБфДѓЕФЪБКђГіЯжКмбЯжиЕФЮШЖЈадЗчЯеЁЃ
ШчЙћгаНкЕуМйЫРЃЌБШШч jvm ФкДцБЛДђТњЃЌНјГЬЛЙДцЛюзХЃЌЯьгІ master ШЮЮёЪБМфЛсКмГЄЃЌгАЯьЕЅИіШЮЮёЕФЭъГЩЪБМфЁЃ
гаДѓСПЛжИДШЮЮёЕФЪБКђЃЌгЩгк master ЪЧЕЅЯпГЬДІРэЕФЃЌЫљгаШЮЮёашвЊХХЖгДІРэЃЌВњЩњДѓСПЕФ pending_tasksЁЃЛжИДЪБМфБфЕУКмГЄЁЃ
Elasticsearch ЕФШЮЮёЗжСЫгХЯШМЖЃЌР§Шч put-mapping ШЮЮёгХЯШМЖЕЭгкДДНЈЁЂЛжИДЫїв§ЃЌШчЙћвЛаЉвЕЮёЩЯЕЭгХЯШМЖЫїв§дкЛжИДЃЌе§ГЃЫїв§гааТзжЖЮаДШыЪБЛсБЛзшШћЁЃ
master ШЮЮёДІРэФЃаЭЃЌдкШЮЮёжДааЭъГЩКѓЃЌЛсЛиЕїДѓСП listener ДІРэдЊЪ§ОнБфИќЁЃЦфжагааЉЛиЕїТпМдкЫїв§ЁЂshard
ХђеЭКѓЃЌЛсГіЯжДІРэЛКТ§ЕФЮЪЬтЃЌЕБ shard ХђеЭЕН 5-6w ЪБЃЌвЛаЉШЮЮёДІРэашвЊ 8-9s ЕФЪБМфЃЌбЯжигАЯьСЫМЏШКЕФЛжИДФмСІЁЃ
еыЖдетаЉЮЪЬтЃЌElasticsearch вВдкВЛЖЯгХЛЏЃЌеыЖдЯрЭЌРраЭЕФШЮЮёЃЌБШШч put-mapping
ШЮЮёЃЌmaster ЛсвЛДЮадДІРэЫљгаЖбЛ§дкЖгСаРяЕФЯрЭЌШЮЮёЁЃClusterState ЖдЯѓжЛДЋЕн diff
ФкШнЃЌгХЛЏЛиЕї listener ФЃПщЕФДІРэКФЪБЛЗНкЕШЕШЁЃ
ЕЋЪЧгЩгкећИіМЏШКЕФШЮЮёЖММЏжадквЛИі master ЕФвЛИіЯпГЬжаДІРэЃЌдкЯпГЬжаашвЊЭЌВНдЊЪ§ОнБфИќИјМЏШКЕФУПИіНкЕуЃЌВЂзшШћЕШД§ШЋВПНкЕуЭЌВНЭъГЩЁЃетИіФЃаЭдкМЏШКЙцФЃВЛЖЯХђеЭЪБЃЌЮШЖЈадЛсВЛЖЯЯТНЕЁЃ
Ыїв§зЪдДЙВЯэЗчЯе
Elasticsearch Ыїв§ЪЧгЩЖрИі shard зщГЩЃЌmaster ЛсЖЏЬЌИјетаЉ shard
ЗжХфНкЕузЪдДЁЃ ВЛЭЌЕФЫїв§ЛсДцдкзЪдДЛьВПЕФЧщПіЁЃ
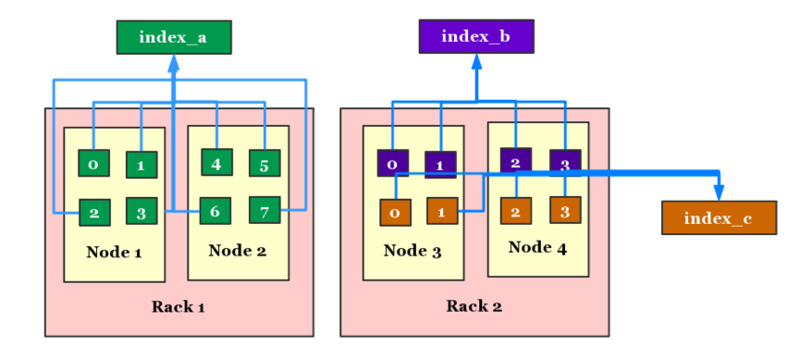
Elasticsearch ЭЈЙ§ Shard Allocation Awareness ЕФЩшМЦЃЌПЩвдНЋМЏШКЕФНкЕуАДМЏКЯЛЎЗжГЩВЛЭЌЕФ
rackЁЃдкЗжХфЫїв§ЪБПЩвджИЖЈ rack СаБэЃЌетбљЫїв§ОЭжЛЛсЗжХфдкжИЖЈ rack ЖдгІЕФНкЕуСаБэжаЃЌДгЖјзіЕНЮяРэзЪдДЕФИєРыЁЃ
ЕЋЪЧЪЕМЪЪЙгУжаЃЌКмЖрШнСПаЁЕФЫїв§гЩгкеМгУзЪдДгаЯоЃЌЛсЛьВПдквЛаЉНкЕужаЁЃетжжЧщПіЯТЃЌЛсвђЮЊИіБ№Ыїв§ЕФВщбЏЁЂаДШыСПьЩ§ЃЌЖјгАЯьЕНЦфЫћЫїв§ЕФЮШЖЈадЁЃШчЙћГіЯжСЫНкЕуЙЪеЯЃЌОЭЛсгАЯьЕНећИіМЏШКЕФЮШЖЈадЁЃ
ећИіМЏШК masterЁЂclientnode зЪдДЪЧЙВЯэЕФЃЌmaster ЗчЯеЧАУцвбОЕЅЖРЬсМАЃЌclientnode
ЙВЯэДјРДЕФ gcЁЂЖЖЖЏЁЂвьГЃЮЪЬтЖМЛсгАЯьЕНМЏШКФкЕФШЋВПЫїв§ЁЃ
вЕЮёГЁОАВювьДѓ
Elasticsearch ЪЪгУЕФвЕЮёГЁОАВювьЬиБ№ДѓЁЃ
еыЖдЯпЩЯКЫаФЕФШыПкЫбЫїЃЌвЛАуАДГЧЪаЛЎЗжЫїв§КѓЃЌЫїв§ШнСПВЛДѓЃЌЪ§ОнУЛгаЪЕЪБаДШыЛђепЪЕЪБаДШы tps
КмаЁЃЌБШШчЕиЭМ poi Ъ§ОнВЩгУРыЯпИќаТЕФЗНЪНЃЌЭтТєЩЬМвЁЂВЫЦЗаДШыСПвВКмаЁЁЃЕЋЪЧВщбЏЕФ qps КмИпЃЌВщбЏЖд
rt ЕФЦНОљЪБМфКЭЖЖЖЏЧщПівЊЧѓКмИпЁЃ
еыЖдШежОМьЫїЕФЕФГЁОАЃЌЪЕЪБаДШыСПЬиБ№ДѓЃЌгааЉЫїв§ЩѕжСГЌЙ§СЫ 100w/s ЕФ tpsЃЌИУГЁОАЖдЭЬЭТСПвЊЧѓКмИпЃЌЕЋЖдВщбЏ
qps КЭВщбЏ rt вЊЧѓВЛИпЁЃ
еыЖд binlog Ъ§ОнЕФМьЫїЃЌаДШыСПЯрБШШежОЛсаЁКмЖрЃЌЕЋЪЧЖдВщбЏЕФИДдгЖШЁЂqps КЭ rt гавЛЖЈЕФвЊЧѓЁЃ
еыЖдМрПиЁЂЗжЮіРрЕФГЁОАЃЌОлКЯВщбЏашЧѓЛсБШНЯЖрЃЌЖд Elasticsearch ФкДцбЙСІНЯДѓЃЌШнвзв§Ц№НкЕуЕФЖЖЖЏКЭ
gcЁЃ
етаЉГЁОАИївьЃЌЮШЖЈадЁЂадФмвЊЧѓИїВЛЯрЭЌЕФГЁОАЃЌвЛИі Elasticsearch МЏШКМДЪЙЪЙгУИїжжгХЛЏЪжЖЮЃЌКмФбШЋВПТњзуашЧѓЃЌзюКУЕФЗНЪНЛЙЪЧАДвЕЮёГЁОАЛЎЗж
Elasticsearch МЏШКЁЃ
ЖрМЏШКЬєеН
е§ЪЧЕЅМЏШКУцСйСЫЗЧГЃДѓЕФЮШЖЈадЗчЯеЃЌЮвУЧПЊЪМЙцЛЎЖрМЏШКЕФМмЙЙЁЃЮвУЧдкЩшМЦЖрМЏШКЗНАИЕФЪБКђЃЌЦкЭћЖдвЕЮёЗНЪЧСуИажЊЕФЁЃ
аДШыЛЙЪЧОЙ§ kafkaЃЌSink ЗўЮёПЩвдНЋВЛЭЌ topic ЕФЪ§ОнШыЕНВЛЭЌЕФ Elasticsearch
МЏШКЁЃ
ВщбЏМЬајЭЈЙ§ Gateway ЗўЮёЃЌЖјЧввЕЮёЗНШдШЛЯёжЎЧАвЛбљДЋЕнЫїв§УћГЦЃЌЖјЮоашИажЊЕНЦНЬЈФкВПЕФЫїв§ЗжВМЁЃЫљгаЕФЫїв§дкВЛЭЌМЏШКЕФЗжВМЯИНкЃЌОљгЩ
Gateway ЗўЮёЦСБЮЁЃ
ећИіИФдьзюДѓЕФЬєеНдкгкВщбЏЗНЪНЕФМцШнЁЃElasticsearch ВщбЏЫїв§ЕФЗНЪНЗЧГЃСщЛюЃЌПЩвджЇГж
* КХзїЮЊЭЈХфЗћЦЅХфЁЃетбљвЛИіЫїв§ query ПЩФмВщбЏЕФЪЧЖрИіЫїв§ЃЌБШШчгаШчЯТ 3 ИіЫїв§ЃК
1.index_a
2.index_b
3.index_c
ЪЙгУ index* ВщбЏЕФЪБКђЃЌПЩвдЭЌЪБВщбЏЕН index_aЁЂindex_bЁЂindex_c Ш§ИіЫїв§ЁЃ
Elasticsearch етжжЪЕЯжЗНЪНЗЧГЃМђЕЅЃЌгЩгквЛДЮ query зюжеВщбЏЕФЪЧЖрИі shard
ЕФЪ§ОнЃЌЫљвдЮоТлЖдгкОпЬхЕФЫїв§ЃЌЛЙЪЧФЃК§ЕФЫїв§ЃЌЖМЪЧЯШИљОнЫїв§УћГЦЕУЕН shard СаБэЃЌдйНЋЖрИі
shard ЕФ query НсЙћ merge ЕНвЛЦ№ЗЕЛиЁЃ
етбљЕФЪЙгУЗНЪНЃЌЖдгкЖрМЏШКЗНАИОЭЛсгіЕНЮЪЬтЃЌБШШч index_a дк A МЏШКЃЌindex_b дк
B МЏШКЁЂindex_c дк C МЏШКЃЌЖдгк index* ЕФ queryЃЌОЭЮоЗЈдквЛИіМЏШКЩЯЭъГЩЁЃ
tribenode НщЩм
ОЙ§ЕїбаЃЌЮвУЧЗЂЯж Elasticsearch tribenode ЬиадПЩвдКмКУЕФТњзуЖрМЏШКВщбЏЕФЬиадЁЃ
tribenode ЕФЪЕЯжЗЧГЃЧЩУюЁЃ
org.elasticsearch.tribe АќЯТжЛгаШ§ИіЮФМўЃЌКЫаФРрЪЧ TribeServiceЁЃtribenode
ЕФКЫаФдРэОЭЪЧ merge УПИіМЏШКЕФ ClusterState ЖдЯѓГЩвЛИіЙЋЙВЕФ ClusterState
ЖдЯѓЃЌClusterState АќКЌСЫЫїв§ЁЂshard КЭНкЕуЪ§ОнЗжВМБэЁЃЖј Elasticsearch
ЕФЙЄзїТпМЖМЪЧЛљгк ClusterState дЊЪ§ОнЧ§ЖЏЕФЃЌЫљвдЖдЭтПДЦ№РДОЭЪЧвЛИіАќКЌШЋВПЫїв§ЕФЕФ
clientnodeЁЃ
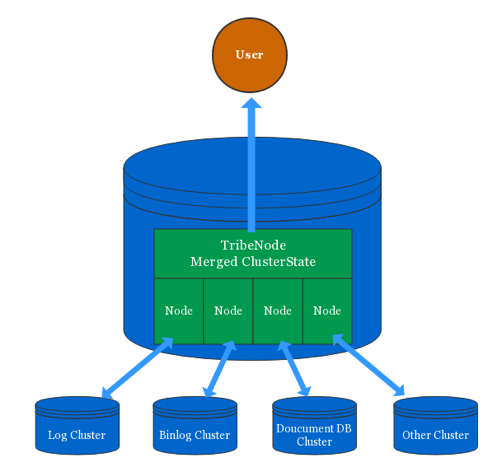
tribenode ЭЈЙ§ХфжУЖрИі Elasticsearch МЏШКЕижЗЃЌШЛКѓвд clientnode
НЧЩЋЗжБ№СЌНгУПИіМЏШКЃЌУПИіМЏШКПДЦ№РДЛсЖрСЫвЛИі clientnodeЁЃ
tribenode ЭЈЙ§ИУ clientnode НЧЩЋЛёШЁЕНМЏШКЕФ ClusterState аХЯЂЃЌВЂАѓЖЈ
listener МрЬ§ ClusterState БфЛЏЁЃtribenode НЋЛёШЁЕФЫљгаМЏШКЕФ ClusterState
аХЯЂ merge ЕНвЛЦ№ЃЌаЮГЩвЛИіЖдЭтВПЗУЮЪЪЙгУЕФ ClusterState ЖдЯѓЃЌЖдЭтЬсЙЉЗўЮёЁЃtribenode
Г§СЫзЂВс listener КЭ merge ClusterStateЃЌЦфЫћЕФЫљгаТпМЖМЪЧИДгУСЫ clientnode
ЕФДњТыЁЃ
ПЩвдПДЕН tribenode ЕФгХЕуЃК
1.ФмЙЛТњзуЖрМЏШКЗУЮЪЕФашЧѓЃЌЖдЭтЪЙгУЪЧЭИУїЕФЁЃ
2.ЪЕЯжЕФМђЕЅЁЂгХбХЃЌПЩППадгаБЃжЄЁЃ
ЭЌЪБ tribenode гааЉВЛзуЕФЕиЗНЃК
tribenode Биаывд clientnode МгШыЕНУПИі Elasticsearch МЏШКЃЌmaster
ЕФБфИќШЮЮёБиаыЕШД§ tribenode ЕФЛигІВХФмМЬајЃЌПЩФмгАЯьЕНдМЏШКЕФЮШЖЈадЁЃ
tribenode ВЛЛсГжОУЛЏ ClusterState ЖдЯѓЃЌжиЦєЪБашвЊДгУПИі Elasticsearch
МЏШКЛёШЁдЊЪ§ОнЁЃЖјдкЛёШЁдЊЪ§ОнЦкМфЃЌtribenode ОЭвбОФмЙЛЬсЙЉЗУЮЪЃЌЛсЕМжТВщбЏЕНЛЙдкГѕЪМЛЏжаЕФМЏШКЫїв§ЗУЮЪЪЇАмЁЃtribenode
СЌНгЕФМЏШКЖрСЫЃЌГѕЪМЛЏЛсБфЕУКмТ§ЁЃеыЖдИУШБЯнЃЌЮвУЧЦНЬЈдкжиЦєФГИі tribenode МЏШКЪБЃЌНЋ Gateway
ЗУЮЪИУМЏШКЕФШЋВПСїСПЧаЕНБИЗн tribenode МЏШКНтОіЁЃ
ШчЙћЖрИіМЏШКгаЯрЭЌЕФЫїв§УћГЦЃЌtribenode жЛФмЩшжУвЛжж perfer ЙцдђЃКЫцЛњЁЂЖЊЦњЁЂprefer
жИЖЈМЏШКЁЃетПЩФмДјРДВщЕНВЛЗћКЯдЄЦкЕФвьГЃЁЃЕЮЕЮ Elasticsearch ЦНЬЈЭЈЙ§ЭГвЛЙмПиЫїв§ЃЌБмУтСЫЭЌвЛИіЫїв§УћГЦГіЯждк
tribenode СЌНгЕФЖрИіМЏШКжаЁЃ
е§ЪЧ tribenode гаСЫетаЉшІДУЃЌElasticsearch дкИпАцБОв§ШыСЫ Cross Cluster
Search ЕФЩшМЦЃЌCross Cluster ВЛЛсвдНкЕуЕФаЮЪНСЌНгЕНЦфЫћМЏШКЃЌжЛЪЧНЋЧыЧѓДњРэЁЃФПЧАЮвУЧЛЙдкЦРЙР
Cross Cluster ЕФЗНАИЃЌетРяВЛеЙПЊНщЩмЁЃ
ЖрМЏШКМмЙЙЭиЦЫ
зюжеИФдьКѓЃЌЮвУЧЕФМЏШКМмЙЙЭиЦЫШчЯТЃК
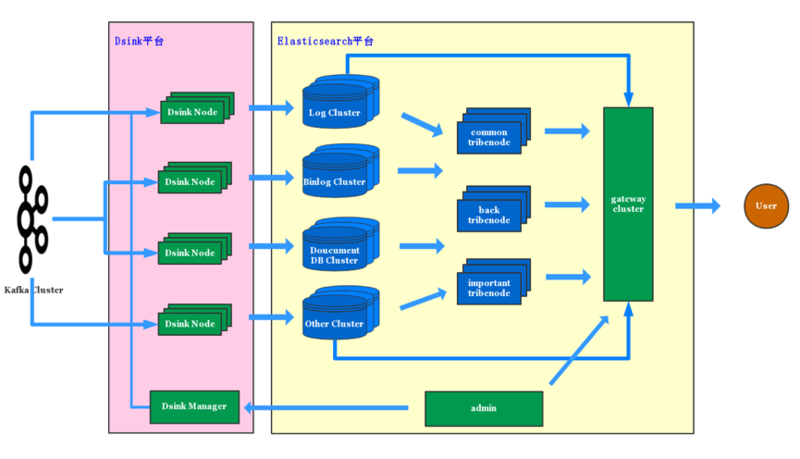
АДееВЛЭЌЕФгІгУГЁОАЃЌЦНЬЈНЋ Elasticsearch МЏШКЛЎЗжГЩЫФжжРраЭЃЌLog МЏШКЁЂBinlog
МЏШКЁЂЮФЕЕЪ§ОнМЏШКЁЂЖРСЂМЏШКЁЃЙЋЙВМЏШКвЛАузюЖр 100 ЬЈ datanode ЮЊЛљзМзщГЩвЛИіМЏШКЁЃЮвУЧРћгУЕЮЕЮдЦ
ЪЕЯжСЫМЏШКЕФздЖЏЛЏВПЪ№КЭЕЏадРЉЫѕШнЃЌПЩвдКмЗНБуЕФЫЎЦНРЉеЙМЏШКЁЃ
Elasticsearch МЏШКЧАУцЪЧЖрзщ tribenode МЏШКЃЌжївЊЪЧЮЊСЫНтОі tribenode
ЕФЮШЖЈадЮЪЬтЁЃ
Gateway ЛсЭЌЪБСЌНг tribenode МЏШККЭ Elasticsearch МЏШКЃЌИљОнгІгУЗУЮЪЕФЫїв§СаБэЃЌХфжУгІгУЗУЮЪЕФМЏШКУћГЦЃЌGateway
ИљОнМЏШКУћГЦЃЌНЋЧыЧѓДњРэЕНжИЖЈМЏШКЗУЮЪЃЌШчЙћЗУЮЪЕФЪЧ tribenode МЏШКЃЌдђИУгІгУПЩвдЗУЮЪЕНЖрИіМЏШКЕФЫїв§ЁЃ
Admin ЗўЮёдђЙмПиСЫЫљгаЕФ Elasticsearch МЏШКЃЌвдМАЫїв§КЭМЏШКЕФЖдгІЙиЯЕЁЃвЛЯЕСаЙІФмЖМеыЖдЖрМЏШКзіСЫИФдьЁЃ
Sink ЗўЮёвбОДг Elasticsearch ЦНЬЈЗжРыГіШЅЃЌГЩСЂ DSink Ъ§ОнЭЖЕнЦНЬЈЃЌDSink
Manager ИКд№ЙмРэ DSink НкЕуЃЌDSink Manager Дг Elasticsearch
Admin ЗўЮёЛёШЁЫїв§ЕФдЊЪ§ОнаХЯЂЃЌЯТЗЂИјЖдгІЕФ DSink НкЕуЁЃ
ЖрМЏШКМмЙЙЪЕМљзмНс
ЖрМЏШКМмЙЙЪевц
Elasticsearch ЖрМЏШКМмЙЙИФдьИј Elasticsearch ЦНЬЈДјРДСЫШчЯТЪевцЃК
Elasticsearch ЦНЬЈЕФИєРыадПЩвдДгЮяРэНкЕуМЖБ№ЩЯЩ§ЕН Elasticsearch МЏШКМЖБ№ЁЃЖдгкКЫаФЕФЯпЩЯгІгУЃЌПЩвдЪЙгУЖРСЂЕФ
Elasticsearch МЏШКжЇГжЁЃ
ВЛЭЌРраЭЕФЪ§ОнАДМЏШКЛЎЗжЃЌБмУтЯрЛЅгАЯьЃЌМѕаЁСЫЙЪеЯЕФгАЯьУцЃЌЖдЦНЬЈЮШЖЈадДјРДМЋДѓЕФЬсЩ§ЁЃ
Elasticsearch ЦНЬЈЕФРЉеЙФмСІНјвЛВНЬсЩ§ЃЌЭЈЙ§аТдіМЏШКПЩвдКмКУЕФзіЕНЫЎЦНРЉеЙЁЃ
ЖрМЏШКМмЙЙзюжезіЕНСЫЖдвЕЮёЗНЮоИажЊЃЌвЕЮёПДЦ№РДЃЌElasticsearch ЦНЬЈОЭЯёвЛИіЮоЯоДѓЕФ
Elasticsearch МЏШКЃЌЖјЮоашИажЊЫїв§ецЪЕЕФМЏШКЗжВМЁЃ
ЖрМЏШКМмЙЙЪЕМљОбщ
ЕЮЕЮ Elasticsearch ЦНЬЈЖрМЏШКЕФМмЙЙвбОбнНјСЫвЛФъАыЪБМфЃЌетЦкМфвВгіЕНвЛаЉЖрМЏШКМмЙЙДјРДЕФЬєеНЁЃ
tribenode ЮШЖЈадЬєеНЃК
ЫцзХМЏШКЪ§СПдНРДдНЖрЃЌЧАУцЬсЕНЕФ tribenode ВЛзудНРДдНУїЯдЃЌБШШчГѕЪМЛЏЕФЪБМфдНРДдНГЄЕШЕШЁЃЮвУЧВЩШЁЕФгІЖдВпТдЪЧВПЪ№Жрзщ
tribenode МЏШКЃЌгаМИзщСЌНгШЋСПЕФМЏШКЃЌЛЅЮЊджБИЃЌгаМИзщжЛСЌНгКЫаФЕФвЛаЉМЏШКЃЌгУзїИќЮЊживЊЕФПчМЏШКЗУЮЪГЁОАЁЃ
tribenode ЕФ ClusterState дЊЪ§ОнАќКЌСЫЬЋЖрЕФЫїв§КЭ shardЃЌElasticsearch
ЕФ search ТпМдкгааЉ case ДІРэЯТШнвзГіЯжКФЪБЙ§ГЄЕФЧщПіЁЃElasticsearch дк
client НгЪеЕН search ЧыЧѓЪБЃЌЪЧдк netty ЕФ io ЯпГЬжаЭъГЩЧыЧѓзЊЗЂИјУПИі shard
ЕФЃЌЕЭАцБОЕФ Elasticsearch ЛЙУЛгаЯожЦвЛДЮ query ЕФ shard Ъ§СПЃЌдквЛаЉИДдгЕФФЃК§Ыїв§ЦЅХф
shard ЕФТпМжаЃЌвдМАИјУПИі shard ЗЂЫЭ query ЧыЧѓЪБЃЌЛсГіЯжНЯИпЕФКФЪБЃЌПЩФмгаГЌЙ§
1-2s ЕФ caseЃЌетЛсгАЯьЕНИУ netty worker ЩЯЕФЦфЫћЕФЧыЧѓЃЌдьГЩВПЗжЯьгІьИпЕФЧщПіЁЃЮвУЧгХЛЏСЫ
tribenode search СїГЬжавЛаЉЫїв§ЁЂshard ХђеЭжЎКѓЕФКФЪБТпМЃЌНтОіСЫИУЮЪЬтЁЃ
ЖрМЏШКХфжУЁЂАцБОЭГвЛЕФЬєеНЃК
дкжЛгавЛИіМЏШКЕФЪБКђЃЌЦНЬЈжЛгУЮЌЛЄвЛЗнМЏШКЕФХфжУКЭАцБОЁЃЕБМЏШКЪ§СПдіЖрКѓЃЌВЛЭЌМЏШКМфЕФ _cluster
settings аХЯЂЛсГіЯжВПЗжВювьЃЌетаЉВювьЃЌПЩФмЛсЕМжТМЏШКМфЕФИКдиВЛОљЃЌЛжИДЫйЖШЙ§ПьЛђепЙ§Т§ЕШЮЪЬтЃЌУПИіМЏШКЛЙгавЛЗнЛљДЁЕФЫїв§ФЃАхХфжУЃЌетРяУцвВГіЯжСЫВПЗжВювьЁЃетИіЮЪЬтФПЧАЮвУЧЛЙдкНтОіжаЃЌЮвУЧМЦЛЎНЋ
Admin ЗўЮёЗжРыГЩЫїв§ЙмРэЗўЮёКЭМЏШКЙмРэЗўЮёЃЌМЏШКЙмРэЛсзЈзЂгкМЏШКАцБОЁЂХфжУЁЂВПЪ№ЁЂРЉШнЁЂМрПиЕШЗНУцЖд
Elasticsearch МЏШКНјааИќШЋУцЕФЙмПиЁЃ
ЮвУЧзіЕФвЛаЉ Elasticsearch дДТыгХЛЏЃЌЛсЯШКѓдкВПЗжМЏШКЩЯЯпЃЌетбљЕМжТСЫМЏШКМфЕФАцБОЛьТвЕФЮЪЬтЁЃЮвУЧЕФНтОіЗНАИЪЧдк
Elasticsearch КЭ Lucene ФкдіМгФкВПЕФАцБОКХЃЌЭЈЙ§ЙЋЫОФкВПЕФЗЂВМЯЕЭГЃЌЗЂВМ Elasticsearch
ЕФИќаТЃЌКѓајМЏШКЙмРэЗўЮёЛсНЋМЏШКЕФАцБОЙмРэЦ№РДЁЃ
ЖрМЏШКМфШнСПОљКтЕФЬєеНЃК
ЮвУЧжївЊДгПчМЏШКЫїв§ЧЈвЦКЭШнСПЙцЛЎНтОіМЏШКМфШнСПОљКтЕФЬєеНЃЌдкЕЅ Elasticsearch МЏШКЕФЪБКђЃЌЪ§ОнЧЈвЦПЩвдвРРЕ
Elasticsearch ЕФ rebalance ФмСІЭъГЩЁЃдкЪЙгУЖрМЏШКМмЙЙКѓЃЌЦНЬЈФкВПЕФ Elasticsearch
МЏШКЛсГіЯжзЪдДЗжХфВЛОљЕФЮЪЬтЃЌР§ШчгааЉЫїв§ШнСПдіГЄЕФКмПьЃЌЕМжТЫљдкМЏШКЕФзЪдДНєеХЃЌгааЉЫїв§Ъ§ОнМѕЩйЃЌВЛашвЊеМгУЬЋЖрзЪдДЃЌЕМжТМЏШКзЪдДПеЯаЁЃгкЪЧВњЩњСЫЫїв§ПчМЏШКЧЈвЦЕФашЧѓЁЃеыЖдетИіашЧѓЃЌЮвУЧЭЈЙ§ИјЫїв§ЬэМгАцБОКХЃЌНтОіСЫЫїв§ПчМЏШКЧЈвЦЮЪЬтЁЃжЎКѓЮвУЧгаЮФеТЛсЯъЯИЕФНщЩмИУЗНАИЁЃ
ЕЮЕЮ Elasticsearch ЦНЬЈЪЕЯжСЫЫїв§ШнСПЕФздЖЏЙцЛЎЃЌНтОіСЫМЏШКМфЕФШнСПОљКтЁЃElasticsearch
ЦНЬЈПЩвдЖЏЬЌЕФЙцЛЎЫїв§ЕФШнСПЁЃЕБвЛИіМЏШКШнСПЙцЛЎВЛзуЪБЃЌЦНЬЈПЩвдЖЏЬЌЕФЧЈвЦвЛВПЗжЫїв§ЕНПеЯаЕФМЏШКжаЁЃаТЕФЫїв§НгШыашЧѓЛсгХЯШНгШыдкПеЯаЕФМЏШКзЪдДжаЁЃЕЮЕЮ
Elasticsearch ЦНЬЈЪЧШчКЮЪЕЯжЫїв§ШнСПЕФздЖЏЙцЛЎЃЌвВЧыЦкД§КѓајЕФЗжЯэЁЃ
змНс
ЕЮЕЮЕФЖрМЏШКМмЙЙЃЌзюГѕЪЧЮЊСЫНтОі Elasticsearch ЕЅМЏШКМмЙЙЕФЦПОБЁЃЮЊСЫжЇГжЖрМЏШКМмЙЙЃЌКѓУцЕФКмЖрзщМўЖМашвЊПМТЧСЌНгЖрИіМЏШКЕФГЁОАЃЌИјЦНЬЈМмЙЙДјРДСЫвЛЖЈЕФИДдгадЁЃЕЋЪЧЖр
Elasticsearch МЏШКДјРДЕФЮШЖЈадКЭИєРыадЕФЬсЩ§ЃЌЫќЫљДјРДЕФЪевцдЖдЖДѓгкМмЙЙЕФИДдгадЁЃИФдьГЩЖрМЏШКМмЙЙКѓЃЌЮвУЧПИзЁСЫ
Elasticsearch ЦНЬЈЙцФЃБЌеЈЪНдіГЄЃЌElasticsearch ЦНЬЈЕФЙцФЃЗСЫ 5 БЖЖрЃЌЖрМЏШКМмЙЙКмКУЕФжЇГХСЫвЕЮёЕФПьЫйЗЂеЙЁЃ
|









