| БрМЭЦМі: |
| БОЮФРДздгкinfoqЃЌБОЮФжївЊНщЩмСЫЫеФўЗжВМЪНЮЂЗўЮёМмЙЙдкДѓаЭЦѓвЕгІгУНЈЩшЃЌЯЃЭћЖдФњЕФбЇЯАгаАяжњЁЃ |
|
ЯюФПБГОА
ЖдеЫЦНЬЈМђНщ
ЪБжСНёШеЃЌЗжВМЪНЮЂЗўЮёМмЙЙдкДѓаЭЦѓвЕгІгУНЈЩшжавбОЕУЕНЦеБщЪЙгУЁЃЦѓвЕФкВПЃЌЫцзХИїЗўЮёзгЯЕЭГЕФВ№ЗжЃЌвЕЮёЪ§ОнЕФДІРэСДТЗвВдНРДдНГЄЃЌвЛЬѕЪ§ОнДгзюЩЯгЮвЕЮёЯЕЭГВњЩњЕНзюЯТгЮЯћЗбЯЕЭГЪЙгУЭљЭљашвЊОРњЪ§ИіЩѕжСЪЎМИИіДѓаЁВЛвЛЁЂзїгУВЛЭЌЕФЗўЮёзгЯЕЭГЃЛЦѓвЕЖдЭтЃЌКЭЭтВПЯЕЭГР§ШчвјааЁЂЕкШ§ЗННгПкЕФЪ§ОнЭЬЭТвВдНРДдНЖрЃЌЕфаЭЕФР§ШчзЊеЫжЇИЖНЛвзМЧТМКЫЖдЁЃвђДЫЃЌЖдгкЖрЗНСїзЊЙВгУЕФЪ§ОнНјааБШНЯКЫЖдЁЂМАЪБЗЂЯжВюДэвХТЉЛђжиИДетжжашЧѓОЭШевцдіЖрЁЃзёбБмУтжиИДПЊЗЂЁЂГщЯѓЙВЭЈЙцдђЁЂНЈЩшзЈжАЯЕЭГЕФЫМТЗЃЌЫеФўФкВПКмдчОЭПЊЗЂЪЕЪЉСЫвЛЬзЪ§ОнЖдеЫПЊЗХЦНЬЈЃЈвдЯТМђГЦЮЊЁАЖдеЫЦНЬЈЁБЃЉВЂЕУЕНСМКУгІгУЃЌжїЬхМмЙЙМАЪ§ОнДІРэЙ§ГЬШчЯТМђЭМЁЃ
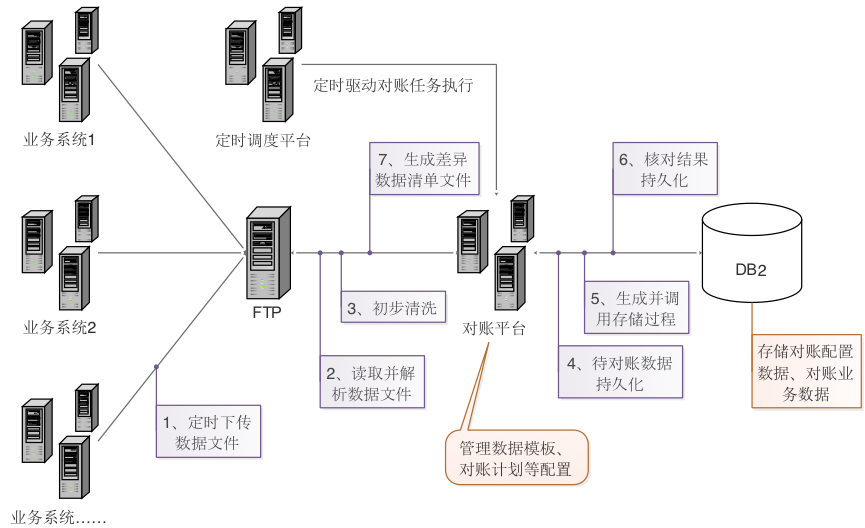
ЮЪЬтЬсГігыНтОіЫМТЗ
ЫцзХМЏЭХДѓПЊЗЂеНТдПьЫйЭЦНјЃЌвЕЮёЪ§ОнСПГЪЯжБЌЗЂЪНдіГЄЬЌЪЦЃЌдЖдеЫЦНЬЈвбж№НЅВЛФмТњзуЪЙгУЃЌжївЊБэЯжЮЊЧхЯДгыКЫЖдМЦЫуЫйЖШНЯТ§ЁЂећЬхМмЙЙФбвдРЉеЙЃЌЯожЦСЫНгШывЕЮёЯЕЭГЕФЪ§СПКЭЪ§ОнЙцФЃЁЃвђДЫЃЌЖдеЫЦНЬЈЩ§МЖИФдьЯюФПгІдЫЖјЩњЁЃ
еыЖддЖдеЫЦНЬЈЕФЮЪЬтНјааЗжЮіЃЌВЛФбЗЂЯжЃЌВЛОпБИСМКУЫЎЦНРЉеЙадЪЧЦфзюЙиМќЕФЭДЕуЃЌжївЊЬхЯжжЎвЛБуЪЧКЫЖдМЦЫуЕФЪ§ОнПтДцДЂЙ§ГЬадФмВЛФмЭЈЙ§РЉДѓЪ§ОнПтМЏШКЕШЗНЗЈРДЪЕЯжНќЯпадРЉеЙЁЃЦфДЮЃЌЭДЕужЎЖўЪЧМЦЫуДІРэЙ§ГЬжаДХХЬ
IO ВйзївРРЕНЯжиЃЌКЫЖдМЦЫуДцДЂЙ§ГЬжДааЙ§ГЬжаашвЊЦЕЗБЩЈУшДХХЬЪ§ОнЃЌЕМжТадФмНЯВюЁЃЮЊНтОіетаЉЮЪЬтЃЌЮвУЧЪзЯШШЗЖЈЩ§МЖИФНјЕФДѓЗНЯђЃЌМДЪЙгУЗжВМЪНМЦЫуМмЙЙДњЬцЪ§ОнПтДцДЂЙ§ГЬМЏжаМЦЫуМмЙЙЃЌВЂОЙ§ЖрДЮЕиЕїбаЖдБШЃЌзюжеВЩгУ
Apache Ignite ЦНЬЈзїЮЊБОДЮЩ§МЖИФНјЕФжївЊММЪѕбЁаЭЁЃ
Лљгк Ignite ЕФЩ§МЖЗНАИвЊЕу
дЊЪ§ОнНсЙЙЃКЖўНјжЦБрзщЦї
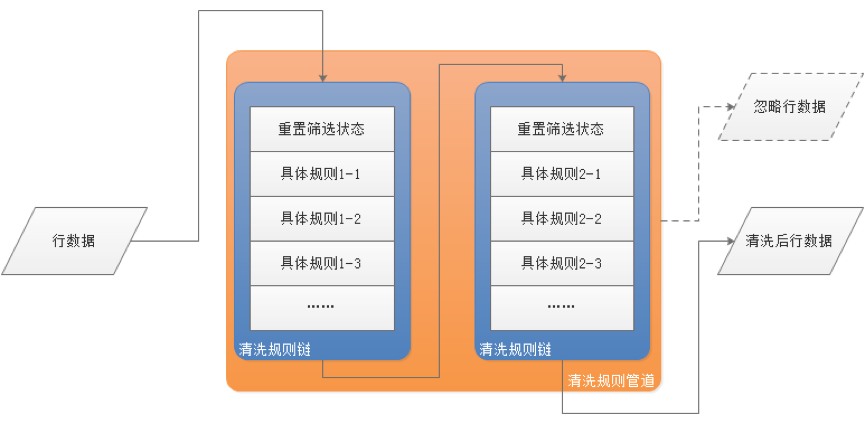
гЩгквЕЮёЯЕЭГЖЏЬЌНгШыЃЌЖдеЫЦНЬЈдкЩшМЦПЊЗЂНзЖЮЮоЗЈдЄжЊНгШыЗНЕФЪ§ОнИёЪНЃЌМДЪ§ОнНсЙЙгЕгаФФаЉзжЖЮЁЂЗжБ№ЮЊЪВУДРраЭЁЃетаЉдЊЪ§ОнНсЙЙЖМЪЧдкЯЕЭГЩЯЯпдЫааЙ§ГЬжагЩЖдеЫЙмРэдБДДНЈЖдеЫМЦЛЎЪБХфжУЃЌвђДЫЖдеЫЦНЬЈБиаыжЇГждЊЪ§ОнЙмРэЃЌВЂЧвдкЪ§ОнДІРэЙ§ГЬжаЪЙгУдЊЪ§ОнзїЮЊЪ§ОнФЃЪНЃЈSchemaЃЉЁЃ
ЖдеЫЦНЬЈдЯШЕФНтОіЗНАИЮЊЃКНЋгУЛЇХфжУЕФЪ§ОнФЃЪНзжЖЮаХЯЂДцДЂЮЊЪ§ОнПтжаЕФНсЙЙЛЏЪ§ОнЃЌРрЫЦгкЙиЯЕаЭЪ§ОнПтжаЕФЯЕЭГБэШч
MySQL жаЕФ information_schema.COLUMNSЃЌЖдеЫЦНЬЈЪЙгУИГгш DDL ШЈЯоЕФеЫКХСЌНгЪ§ОнПтЃЌИљОнХфжУзжЖЮаХЯЂЩњГЩНЈБэгяОфЃЌИљОнХфжУЕФЪ§ОнЧхЯДЁЂКЫЖдЙцдђЩњГЩМЦЫуДцДЂЙ§ГЬНХБОЃЌдйжДааетаЉгяОфНХБОвдЪЕЯждЫааЪБдЊЪ§ОнХфжУЕФжЇГжЁЃетжжЗНАИгХЕуЪЧЪЕЯжЯрЖдМђЕЅШнвзЃЌЕЋЪЧШБЕувВКмУїЯдЃК
ЕквЛгІгУГЬађЪЙгУЕФЪ§ОнПтеЫЛЇШЈЯоНЯИпЃЛ
ЕкЖўЙиЯЕаЭЪ§ОнПтЕФааДцЗНЪНЕМжТжЛШЁгУЩйЪ§СаЪБадФмВЛЙЛРэЯыЃЛ
ЕкШ§ЪЙгУДцДЂЙ§ГЬЭъГЩЪ§ОнДІРэМЦЫуВЛРћгкКсЯђРЉеЙЁЃ
ЖдДЫЃЌаТЗНАИВЩгУ Ignite жаЕФЖўНјжЦБрзщЦїЃЈBinary MarshallerЃЉРДТњзуЪ§ОнДІРэЙ§ГЬжаЕФдЊЪ§ОнжЇГжашЧѓЁЃIgnite
ЕФЖўНјжЦБрзщЦїЪЧвЛжжаТЕФађСаЛЏ / ЗДађСаЛЏИёЪНЃЌЫќПЩвдЪЕЯжЪ§ОнЖдЯѓжЕЁЂдЊЪ§ОнЕФЖЏЬЌДІРэЃЌЫќЬсЙЉСЫвдЯТМИИіЬиадЃК
дЪаэжЛЗУЮЪЪ§ОнЖдЯѓЕФВПЗжЪєадЖјВЛгУЗДађСаЛЏећИіЖдЯѓЁЃ
дЪаэдЫааЪБЖЏЬЌЬэМгЛђепЩОГ§ЖдЯѓзжЖЮЖјВЛашвЊЙЬЖЈЕФЪ§ОнФЃаЭРрЃЈModelЃЉЁЃ
дЪаэЛљгкРраЭУћГЦДДНЈаТЖдЯѓЖјВЛашвЊЪ§ОнФЃаЭРрЖЈвхЁЃ
етбљвЛРДЃЌЭЈЙ§вдЩЯМИЕуЃЌдкВЛжБНгВйзїЪЙгУ CGlibЁЂjavassist жЎРрЖЏЬЌзжНкТыЩњГЩММЪѕЕФЧщПіЯТЃЌаТЗНАИПЩвдТњзуЖЏЬЌдЊЪ§ОнХфжУМАЪЙгУЕФашЧѓЁЃВЂЧвЃЌгЩгквЕЮёЯЕЭГдЪМЪ§ОнПЩФмзжЖЮЖрДяЩЯАйИіЖјеце§ашвЊЖдеЫДІРэЪЙгУЕФПЩФмНіЪЎЖрИіЃЌЛљгкЩЯЪіЕквЛЬѕЬиадЃЌдкКѓУцЕФЪ§ОнДІРэМЦЫуЙ§ГЬжаЃЌБОЗНАИНЯдЗНАИЯрБШаЇТЪЩЯгаКмДѓЬсЩ§ЁЃ
Ъ§ОнНгШыЃКПчНкЕу ExecutorService гыЗжВМЪНФкДцЛКДц
вЕЮёЯЕЭГдЪМЪ§ОнНгШыЪЧећИіДІРэЙ§ГЬжаЕФЕквЛВНЁЃгЩгкИївЕЮёЯЕЭГНЈЩшЪБЦкЁЂММЪѕМмЙЙДѓЖрДцдкВювьЃЌвђДЫзюГѕгыИївЕЮёЯЕЭГаЩЬДяГЩвЛжТЃЌВЩгУвЕЮёЯЕЭГЩњГЩЮФБОИёЪНЪ§ОнЮФМўДЋЪфЕНЙЋЙВ
FTP ЗўЮёЦїЕФЗНЪНРДЪЕЯжЪ§ОнНгШыЃЌЖдеЫЦНЬЈАДееЩшЖЈКУЕФЖЈЪБЕїЖШШЮЮёЧ§ЖЏЃЌВщбЏЪ§ОнПтЛёШЁДІгкЁАНтЮіЪ§ОнЮФМўЁБЛЗНкЁАД§ДІРэЁБзДЬЌЕФЖдеЫШЮЮёЃЌИљОнЛёШЁЕНЕФНсЙћЪ§ОнЗУЮЪ
FTP МьВщВЂЛёШЁЫљашЕФЪ§ОнЮФМўЃЌдйИљОнгУЛЇЪТЯШХфжУКУЕФЪ§ОнФЃАхРДНтЮіЪ§ОнЮФМўВЂГжОУЛЏШыПтЕШД§КѓајДІРэЁЃ
гЩгкВЩгУСЫЫеФўФкВПЕФМЏжаЖЈЪБЕїЖШМмЙЙЃЌЖдеЫЦНЬЈМЏШКзїЮЊЖЈЪБЕїЖШШЮЮёЦНЬЈЕФПЭЛЇЖЫЃЌУПДЮДЅЗЂЦїжЛЛсНЋЕїЖШдЫаажИСюЯТЗЂЕНЖдеЫЦНЬЈМЏШКЩЯЕФФГвЛИіНкЕуРДЦєЖЏНтЮіЪ§ОнЮФМўШыПтЕФШЮЮёЁЃ
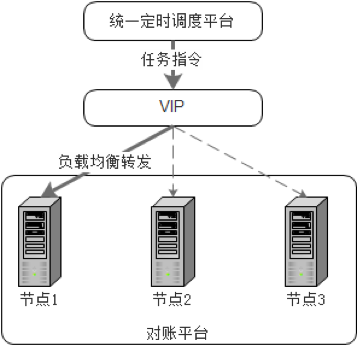
дЗНАИЕїЖШНтЮіШЮЮё
дквЕЮёЯЕЭГЪ§ОнСПвЛАуЕФЧщПіЯТЃЌЕЅНкЕуНтЮіДІРэЩаФмТњзуашЧѓЃЌЕЋЫцзХИќЖрВЦЮёЯрЙивЕЮёЯЕЭГНгШыЃЌВЦЮёвЕЮёЯЕЭГУПИіЖдеЫжмЦкФкЕФЪ§ОнСПНЯДѓЁЂЖдНтЮіДІРэЪБЯовЊЧѓНЯИпЃЌЕЅНкЕуНтЮіДІРэвбВЛФмжЇГХЦфашЧѓЁЃВЂЧвЕЅНкЕужДааШЮЮёетжжФЃЪНЯдШЛУЛгаГфЗжРћгУећИіМЏШКЕФМЦЫузЪдДЃЌШнвздьГЩФГНкЕуИККЩЙ§жиЖјЦфЫќНкЕуШДБШНЯПеЯаЕФЧщПіЁЃМјгкДЫЃЌЩшЗЈИФНјШЮЮёжДааЗНЪНЃЌЕїгУЖрНкЕуВЂаажДааЭЌвЛИіШЮЮёЃЌМШФмИФЩЦЕЅИіШЮЮёЕФжДаааЇТЪЃЌгжФмЗжЬЏШЮЮёжДаабЙСІЁЃ
Ignite МЦЫуЭјИёжаЕФЗжВМЪН ExecutorService ФмСІе§ЪЧЗЧГЃЪЪКЯЕФНтОіЗНАИЁЃЫќЪЕЯжСЫ
JDK БъзМЕФ ExecutorService НгПкЃЌвђДЫдРДЕЅНкЕуДДНЈЬсНЛШЮЮёТпМДњТыМИКѕВЛгУИФЖЏМДПЩдкаТЕФЗНАИжаМЬајЪЙгУЃЌжЛЪЧЯпГЬГигЩдРДЕФЕЅНкЕу
JVM НјГЬФкБфГЩСЫећИіМЏШКЛЏПчНкЕуЃЌБОжЪЩЯЪЧгЩ Ignite НЋФГНкЕуЬсНЛЕФМЦЫуГЬађБеАќађСаЛЏКѓЗЂЫЭЕНЗжХфЕФНкЕуЩЯЗДађСаЛЏжДааЃЈШчЭМЃЉЁЃетбљЃЌНтЮіЪ§ОнЮФМўШыПтЕФШЮЮёПЩвдЪЕЯжЗжВМЬсНЛЁЂЗжВМжДааЃЌПьЫйЪЕЯжСЫМЏШКВЂааЛЏЃЌВЂздЖЏЛёЕУСЫШЮЮёИКдиОљКтЁЂЙЪеЯздЖЏзЊвЦЕФЬиадЁЃ
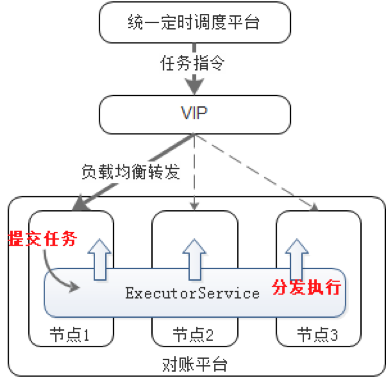
аТЗНАИЕїЖШНтЮіШЮЮё
дкЕїгУМЏШКЖрНкЕуВЂааМгдиЪ§ОнЪБЃЌНЋЪ§ОнМгдиЕНКЮДІвВЪЧашвЊПМТЧЕФЮЪЬтЁЃдНтОіЗНАИНЋНтЮіКѓЕФдЪМЪ§Онвд
JDBC batch ВйзїЗНЪНжБНгДцШыЙиЯЕаЭЪ§ОнПтЃЌКѓајЕФКЫЖдЙ§ГЬвВдкЪ§ОнПтжаЭъГЩЁЃаТЗНАИдђВЩгУ Ignite
КЫаФвВЪЧзюЧПОЂЕФЬиадЁАЗжВМЪНЪ§ОнЭјИёЁБзїЮЊЪ§ОнжїЙЄзїДцДЂЁЃжївЊвРОнЦфгавдЯТживЊЬиЕуЃК
ЗжВМЪНЁЃIgnite Ъ§ОнЭјИёвЛЖЈГЬЖШЩЯКЭ HDFS БШНЯЯрЫЦЃЌСНепОљжЇГжЪ§ОнЗжЦЌДцДЂЁЂЖрИББОБИЗнвдЪЕЯжЪ§Он
АВШЋЁЃЕЋВЛЭЌЕФЪЧЃЌIgnite жЇГжЪ§ОнЕФИќаТгыЩОГ§ЃЌВЂЧвжЇГжЪТЮёЁЃРэТлЩЯЃЌВЩгУЗжЧјФЃЪНЕФ Ignite
Ъ§ОнЭјИёПЩвдЧсЫЩЕиЭЈЙ§діМгМЏШКНкЕуЗНЪННјааЫЎЦНРЉеЙЃЌДгЖјжЇГж TB МЖЕФФкДцЪ§ОнДцДЂЁЃ
SQL жЇГжЁЃIgnite Ъ§ОнЭјИёздДј SQL в§ЧцЃЌВЂжЇГж JDBC Ч§ЖЏЃЌПЩвдЭЈЙ§БъзМЕФ JDBC
ЗНЪННјаа DDLЁЂDML ВйзїЃЌМЋДѓЕиНЕЕЭСЫБрГЬПЊЗЂФбЖШКЭЪЙгУУХМїЁЃ
Ыїв§жЇГжЁЃIgniteSQL ЭјИёжЇГжЫїв§ЁЃЖдгк SQL жаЩљУїДДНЈЕФУПвЛИіЫїв§ЃЌIgnite ЖМЛсВЩгУвЛПХзЈгУ
B+ ЪїЕФЪ§ОнНсЙЙРДЙмРэЛКДцЪ§ОнЁЃЭЈЙ§Ыїв§ЬиЕуЃЌIgnite ФмЙЛНјвЛВНЬсИпЪ§ОнВщбЏМьЫїаЇТЪвдТњзуИќИпЯьгІЪБМфвЊЧѓЁЃ
жЇГжЭЈЖСЭЈаДЁЃФкДцБЯОЙВЛЪЧГжОУЛЏЃЌЪ§ОнзюжеЛЙЪЧашвЊТфЕНжюШчЙиЯЕаЭЪ§ОнПтЕФГжОУЛЏДцДЂжаШЅЁЃЭЈЙ§ХфжУЭЈЖСЁЂКѓаДЛКДцЃЌаТЗНАИЭЌбљЪЕЯжЪ§ОнЕНГжОУЛЏДцДЂжаЕФХњСПВйзїЁЃ
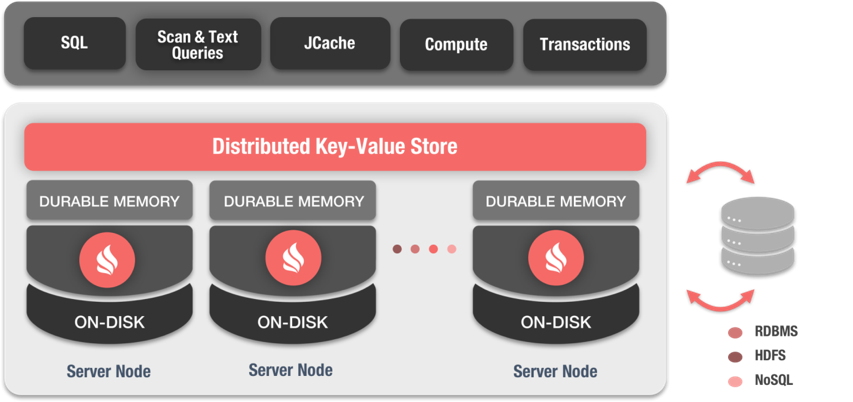
Ignite ЗжВМЪНЪ§ОнЭјИёЃЈЙйЗНЭМЃЉ
дЄДІРэЧхЯДЃКЙцдђСДЗтзАгы StreamReceiver
ДІРэЭъдЪМЪ§ОнЕФНгШыЃЌНгЯТРДЙиМќЪЧИїжжЪ§ОнДІРэЙцдђРДЖдЪ§ОнНјааМгЙЄМЦЫуЃЌПЩвдЫЕетЪЧЖдеЫЦНЬЈзюживЊзюИДдгЕФЛЗНкжЎвЛЁЃгЩгкНгШыЕФвЕЮёЯЕЭГжЎМфВювьКмДѓЃЌЪ§ОнжЪСПВЮВюВЛЦыЃЌВЂЧвЪ§ОнБШЖдТпМвВЧЇВюЭђБ№ЃЌвђДЫЖдеЫЦНЬЈЮоЗЈАДееПЊЗЂзЈгУГЬађЕФЗНЪНРДеыЖдУПвЛИіНгШывЕЮёЯЕЭГНјааЖЈжЦЃЌЖјБиаыжЇГжгУЛЇСщЛюХфжУИїжжЙцдђЁЃИљОнвЕЮёЪсРэЃЌжївЊЕФЧхЯДЙцдђЗжЮЊСНРрЃК
ЕЅааФкЧхЯДЃЌАќРЈЃК
ЬѕМўЩИбЁЃКХаЖЯЪЧЗёЗћКЯЩшЖЈЬѕМўвдОіЖЈЪЧЗёМЬајНјааКѓајЧхЯДЁЃР§ШчЃЌЖдгкЁАНЛвзРраЭЁБЕШгк A ЕФЪ§ОнМЬајБОзщЙцдђКѓајДІРэЃЛ
ЮФБОНиШЁЃКжИЖЈЮФБОзжЖЮЮоЬѕМўЛђТњзуЩшЖЈЬѕМўЪБе§ / ЗДЯђНиШЁЬиЖЈЦ№жЙЮЛжУзгДЎЁЃР§ШчЃЌЕБЁАЖЉЕЅРраЭЁБзжЖЮЕк
1~2 ЮЛЕШгкЁАXSЁБЪБе§ЯђНиШЁЁАБИзЂЁБзжЖЮЕк 8~10 ЮЛЩшжУЕНзжЖЮЁАдЄСє 1ЁБжаЃЛ
ЕЅааЖрИіЮФБОзжЖЮЦДНгЃКНЋжИЖЈЕФЖрИіЮФБОзжЖЮФкШнСЌНгГЩаТзжЗћДЎЁЃР§ШчЃЌНЋЁАНЛвзШеЦкЁБЁЂЁАСїЫЎКХЁБЁЂЁАжЇИЖЗНЪНЁБЦДНгЩшжУЕНзжЖЮЁАдЄСє
2ЁБжаЃЛ
Ъ§зжзжЖЮдЫЫуЃКЕЅИіЛђЖрИіЪ§зжРраЭзжЖЮжЕНјааБэДяЪНЫФдђдЫЫуЁЃР§ШчЃЌНЋБэДяЪНЁАЕЅМл *(ЯњЪлЪ§СП -
ЭЫЕЅЪ§СП)/10000.0ЁБЕФМЦЫуНсЙћДцШызжЖЮЁАдЄСє 3ЁБжаЃЛ
зжЖЮЩшжЕЃКИљОнФГзжЖЮЬѕМўНЋСэвЛзжЖЮЩшжУЮЊжИЖЈжЕЁЃР§ШчЃЌЕБЁАУХЕъДњТыЁБАќКЌЁАNJЁБЪБНЋЁАЕиЧјЁБЩшжУЮЊЁАФЯОЉЁБЃЛ
ЩИбЁЙ§ТЫЃКХзЦњЗћКЯЩшЖЈЬѕМўЕФЪ§ОнааЁЃР§ШчЃЌЕБЁАБИзЂЁБзжЖЮАќКЌЁАжиИДЯТЕЅЁБЪБИУЬѕЪ§ОнВЛВЮгыКѓајДІРэМАКЫЖдЃЛ
ЕШЕШЃЛ
ЖрааМфЧхЯДЃЌАќРЈЃК
ЗжзщЛузмЃКИљОнжИЖЈЕФЗжзщзжЖЮРлМгЩшЖЈЕФЛузмзжЖЮЁЃР§ШчЃЌНЋЁАНЛвзЕЅКХЁБЁЂЁАЩЬМвДњТыЁБЯрЭЌЕФЪ§ОнааЛузмЦфЁАЖЉЕЅН№ЖюЁБЁЂЁАЩЬЦЗЪ§СПЁБЃЛ
ЗжзщХХжиЃКИљОнжИЖЈЕФЗжзщзжЖЮХХжижЛБЃСєвЛааЁЃР§ШчЃЌИљОнЁАЦОжЄКХЁБЁЂЁАСїЫЎКХЁБЗжзщЃЌжЛБЃСєвЛЬѕЪ§ОнНјааКѓајДІРэЁЃ
гЩЩЯПЩМћЃЌЪ§ОнЧхЯДЙцдђзщКЯЖрБфЃЌУПИіЧхЯДЙцдђзщжаПЩвдАќКЌЖрИіОпЬхЧхЯДЙцдђЃЌЖрИіЧхЯДЙцдђзщжЎМфЛЙДцдкЫГСЊЙиЯЕЃЌПЩвдПДзівЛИі
ETL Й§ГЬЃЌећЬхЛЙЪЧБШНЯИДдгЕФЁЃ
ЖдДЫЃЌЖдеЫЦНЬЈдЗНАИЩшЖЈСЫВЛПЩИќИФЕФЙцдђгХЯШМЖЃЌЧПжЦЕЅааЬѕМўЩИбЁЙцдђзюЯШДІРэЁЂЖрааЧхЯДЙцдђзюКѓДІРэЁЂЦфЫќЙцдђАДХфжУЕФЯШКѓЫГађДІРэЃЌОпЬхЪЕЯжВЩгУЪ§ОнЮФМўНтЮібЛЗжаЭъГЩЕЅааЧхЯДЙцдђДІРэЁЂЖЏЬЌЩњГЩДцДЂЙ§ГЬЭъГЩЖрааМфЧхЯДЙцдђДІРэЕФАьЗЈЁЃДЫЗНАИЖдгкДѓЖрЪ§вЛАуашЧѓвбПЩвдТњзуЃЌЕЋвВПЩвдПДГіЃЌЧПжЦгХЯШМЖВЛФмТњзуИДдгашЧѓЃЌР§ШчЯШЬѕМўЩИбЁКѓЮФБОНиШЁЁЂИљОнНиШЁНсЙћдйЬѕМўЩИбЁЕФГЁОАЃЛНЋЁАЪ§ОнЧхЯДЁБЙ§ГЬИюСбЮЊЕЅааЁЂЖрааСНВПЗжЗжЩЂЪЕЯжЃЌвВВЛРћгкРЉеЙМАЮЌЛЄЁЃ
аТЗНАИдђЪзЯШЖдЧхЯДЙцдђНјааГщЯѓЃЌНЋИїОпЬхЙцдђЕиЮЛЦНЕШЛЏЃЌЪгзїЖдУПааЪ§ОнЕФВЛЭЌМЦЫуДІРэЃЌЖрИіОпЬхЧхЯДЙцдђАДееХфжУЕФЯШКѓЫГађзщГЩвЛЬѕДІРэСДЃЌЖрЬѕДІРэСДаЮГЩвЛИіЪ§ОнДІРэЙмЕРЃЈШчЭМЃЉЁЃ
дЄДІРэМгЙЄМЦЫуГщЯѓЪОвт
ЯдЖјвзМћЃЌИУФЃаЭЗћКЯСїДІРэЬиЕуЃЌНсКЯЧАЪіЕФЪ§ОнЮФМўНтЮіВНжшЃЌЗЧГЃЪЪКЯЪЙгУ Ignite ЕФЪ§ОнзЂШыКЭСїДІРэЬиадЁЃЭЈЙ§
IgniteDataStreamerAPIЃЌЖдеЫЦНЬЈПЩвдГжајИпаЇЕизЂШыЪ§ОнЃЌВЂЧвЭЈЙ§ StreamReceiver
НЋЧхЯДЙцдђЙмЕРАќКЌдкЦфжаЖдЪ§ОнНјааДІРэЁЃЛљгкИїНкЕуВЂааЕФЪ§ОнНтЮізЂШыШЮЮёЃЌStreamReceiver
КмШнвзЪЕЯжДѓЙцФЃЕФИпаЇЕЅааЪ§ОнМЦЫуДІРэЃЌРрЫЦ Spark жа RDD ЕФ Map ЫузгВйзїЃЌЕЋгы Spark
Map ЫузгВйзїВЛЭЌЕФЪЧЃЌIgnite StreamReceiver Ъ§ОнДІРэ process ЗНЗЈЕФШыВЮЪЧПЩБфЕФЪ§ОнЪЕЬхЃЌПЊЗЂШЫдБПЩвддкМЦЫуЙ§ГЬжажБНгИФБфЪ§ОнЪЕЬхЕФжЕЃЈР§ШчЖдФГзжЖЮЕФжЕНјааНиШЁВЂИќаТЃЉЃЌгЩ
Ignite БОЩэЖдЪ§ОнЪЕЬхНјааВЂЗЂЫјАВШЋПижЦЃЛЖј Spark Map ЫузгЗНЗЈШыВЮЪЧВЛПЩБфЕФЪ§ОнЖдЯѓЃЌдЪ§ОнЖдЯѓЕФжЕВЛПЩИФБфЃЌУПДЮМЦЫуЪЕМЪЩЯЩњГЩаТЕФ
RDDЁЃЕЅааЧхЯДЙцдђНтОіСЫЃЌФЧУДЖрааМфЧхЯДЙцдђдѕУДАьФиЃПДЫДІЃЌЮвУЧРћгУСЫ Ignite БОЩэКЫаФЕФЗжВМЪНМќжЕЛКДцФмСІЁЃСНжжЖрааМфЧхЯДЙцдђЦфИљБОЖМПЩвдПДзіЪЧЗжзщЃЈGroupЃЉЃЌФЧУДЕБгіЕНЖрааМфЧхЯДЙцдђЪБЃЌЮвУЧЯШЩшжУвЛИі
IgniteCacheЃЌдкДІРэааЪ§ОнЪБЃЌШЁЙцдђЕФЗжзщзжЖЮЦДКЯзїЮЊМќЃЌЕНИУМќжЕЛКДцжаВщевЪЧЗёДцдкЖдгІЕФжЕЃЌШчЙћВЛДцдкЃЌФЧУДОЭНЋБОааЪ§ОнЗХШыЦфжаЃЌШчЙћвбДцдкЃЌФЧУДОЭЪгОпЬхЙцдђЮЊЗжзщЛузмЛЙЪЧЗжзщХХжиЃЌНЋИУааЪ§ОнЕФЛузмзжЖЮжЕРлМгЕНЛКДцжЕЖдЯѓжаЛђепХзЦњЁЃЭЈЙ§етжжЗНЪНЃЌЕЅааЧхЯДЙцдђгыЖрааЧхЯДЙцдђЖМПЩвдгІгУЕНбЛЗааДІРэЕФЧхЯДЙцдђСДЙмЕРФЃаЭжаШЅЃЌДгЖјЗћКЯЭГвЛГщЯѓЩшМЦЁЃ
ЫЋЗНЪ§ОнКЫЖдЃКФкДцЪ§ОнПтгы SQL ЭјИё
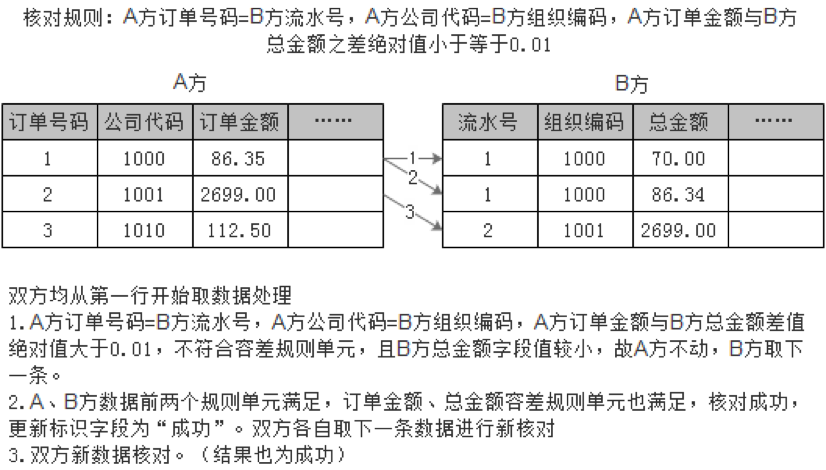
жЎЧАЕФЪ§ОнМгдиМАдЄДІРэМгЙЄЖМЪЧ AЁЂB ЕЅЗНИїздДІРэЃЌЫЋЗНжЎМфЪ§ОнЛЅВЛгАЯьЃЌЖјжївЕЮёЙ§ГЬЕФзюКѓвЛИіЛЗНкМДЁАКЫЖдЁБЛЗНкЃЌОЭашвЊгУЫЋЗНЕФЪ§ОнНјааБШЖдСЫЁЃЮЊСЫЬсИпЦНЬЈЭЈгУадТњзуИДдгЖрБфЕФЖдеЫвЕЮёашЧѓЃЌКЫЖдЛЗНкЭЌбљжЇГжЖржжКЫЖдЙцдђЕЅдЊЕФСщЛюзщКЯХфжУЃЌЛљБОКЫЖдЙцдђЕЅдЊжївЊАќРЈЃК
ОЋШЗЦЅХфЃЌжИ A ЗНЪ§ОнМЧТМЕФФГзжЖЮжЕЕШгк B ЗНЪ§ОнМЧТМЕФФГзжЖЮжЕЁЃР§ШчЃЌA ЗНЪ§ОнЕФЁАЖЉЕЅКХТыЁБЕШгк
B ЗНЪ§ОнЕФЁАНЛвзСїЫЎКХЁБЁЃ
ЯрЙиЦЅХфЃЌжИ A ЗНЪ§ОнМЧТМЕФФГзжЖЮЕШгкжИЖЈжЕЃЌЭЌЪБ B ЗНЪ§ОнМЧТМЕФФГзжЖЮЕШгкСэвЛжИЖЈжЕЁЃР§ШчЃЌA
ЗНЪ§ОнЕФЁАНЛвзРраЭЁБЕШгкЁАЯТЕЅЁБЃЌB ЗНЪ§ОнЕФЁАЪежЇРраЭЁБЕШгкЁАЪеШыЁБЁЃ
ШнВюЦЅХфЃЌгжЗжЮЊе§ЁЂЗДЯђСНжжЃЌжИ A ЗНЪ§ОнМЧТМЕФФГЪ§жЕзжЖЮжЕгы B ЗНЪ§ОнМЧТМЕФФГЪ§жЕзжЖЮжЕЕФВюЃЈе§ЯђЃЉЛђепКЭЃЈЗДЯђЃЉЕФОјЖджЕаЁгкЕШгкжИЖЈжЕЁЃР§ШчЃЌA
ЗНЁАЖЉЕЅН№ЖюЁБгы B ЗНЁАжЇИЖН№ЖюЁБВюжЕОјЖджЕаЁгкЕШгк 0.01ЃЈдЊЃЉЁЃ
МгМѕЦЅХфЃЌжИ A ЗНЕФвЛИіЛђЖрИіЪ§жЕзжЖЮНјааМгМѕдЫЫуКѓЕФжЕгы B ЗНЪ§ОнМЧТМЕФвЛИіЛђепЖрИіЪ§жЕзжЖЮМгМѕдЫЫужЕЯрЕШЁЃР§ШчЃЌA
ЗНЕФ (ЁАЖЉЕЅН№ЖюЁБ-ЁАгХЛнН№ЖюЁБ) ЕШгк B ЗНЕФ (ЁАзЪН№ЪеШыЁБ+ЁАащФтЕжПлЁБ)ЁЃ
вЛИіЛђЖрИіЛљБОЙцдђЕЅдЊзщГЩвЛЬѕКЫЖдЙцдђЃЌЖрЬѕКЫЖдЙцдђдйНјвЛВНЙЙГЩЭъећЕФЖрВуДЮКЫЖдЙцдђзщЃЌЫЋЗНЪ§ОнашвРДЮГЂЪдвРОнКЫЖдЙцдђзщжаЕФКЫЖдЙцдђЃЌжБЕНЗћКЯФГЬѕКЫЖдЙцдђЖјКЫЖдГЩЙІЛђепВЛЗћКЯШЮвЛКЫЖдЙцдђЖјМЧЮЊЪЇАмВювьЁЃдкЙцдђзщжаЛЙвўКЌСЫвЛЬѕЁАЧБЙцдђЁБддђЃКAЁЂB
ЗНУПЬѕЪ§ОнзюЖржЛдЪаэБЛГЩЙІЦЅХфЪЙгУвЛДЮЁЃМйЩш A ЗНФГЬѕЪ§Он A1 ФмЧвНіФмгы B ЗНФГСНЬѕЪ§Он B1ЁЂB2
ЗћКЯКЫЖдЙцдђ R1ЃЌФЧУД A1 гы B1 КЫЖдГЩЙІКѓ A1ЁЂB1 МДБЛЪЙгУЯћКФЃЌA1 ВЛФмдйгУзїгы
B2 КЫЖдЃЌЙЪ B2 ЮЊВювьЁЃ
ЯдШЛЃЌдкКЫЖдЙ§ГЬжаЃЌЫЋЗНЪ§ОнМЧТМвЛЕЉвРОнФГЙцдђКЫЖдГЩЙІОЭашвЊВЩгУФГжжЗНЪННјааБъМЧЩИГ§ЃЌвдУтБЛжиИДЪЙгУЁЃдЗНАИЛљгкЙиЯЕаЭЪ§ОнПтДцДЂЙ§ГЬЪЕЯжЫЋЗНЪ§ОнКЫЖдЃЌИХРЈОЭЪЧЃКгЩгІгУИљОнКЫЖдЙцдђзщЩњГЩДцДЂЙ§ГЬГЬађНХБОЃЌЖЏЬЌЫЂШыЪ§ОнПтдйЕїгУЃЛдкЫЋЗНЪ§ОнБэжаЩшвЛзжЖЮгУРДБъЪЖИУМЧТМЪЧЗёБЛКЫЖдГЩЙІЪЙгУЃЌГѕЪМжЕОљЮЊЗёЃЛДцДЂЙ§ГЬжавдвЛЗНЪ§ОнВщбЏНсЙћМЏЮЊгЮБъЃЌБщРњУПааЪ§ОнЃЌвдЛљБОКЫЖдЙцдђЕЅдЊзїЮЊВщбЏЬѕМўЃЌЕНСэвЛЗНЪ§ОнБэжаВщевЩаЮДКЫЖдГЩЙІВЂЦЅХфЕФМЧТМЃЌШєгаЃЌдђШЁЕквЛаазїЮЊКЫЖдГЩЙІЃЌИќаТЫЋЗНЕФГЩЙІЪЙгУБъЪЖЁЃ
ПЩвдПДГідНтОіЗНАИЛљгкДХХЬЪ§ОнГжОУЛЏЕФЖСаДадФмвВВЛФмжЇГжИќИпЕФаЇТЪвЊЧѓЃЌВЂЧвНсЙћМЏгЮБъБщРњВщбЏКЫЖдЫуЗЈЕФЪБМфИДдгЖШНЯИпЃЈO(n2)ЃЉЃЌЙЪаТЗНАИжиЕуНтОіетСНЗНУцЕФЮЪЬтЁЃЖдгкЕквЛЕуЃЌЪЕМЪЩЯдкЧАЪіЪ§ОнНгШыЛЗНкаТЗНАИЩшМЦвбОНЋЫЋЗНЪ§ОнЗжБ№ЗХШы
Ignite ЗжВМЪНФкДцМЏКЯжаЃЌвђДЫЪ§Он IO ДѓЖрЖМЛљгкФкДцЃЌЫйЖШздШЛБШДХХЬ IO вЊИпГіаэЖрЁЃЙигкЕкЖўЕуЃЌаТЗНАИВЩгУ
Ignite ЕФФкДцЪ§ОнПтЬиадЃЌНЋ AЁЂB ЫЋЗНЪ§ОнЕФЗжВМЪНФкДцЛКДцМЏКЯРћгУ SQL гяОфФмСІНјааДІРэЃЌгУЯШХХађКѓБШЖдЕФЫуЗЈНЋЪБМфИДдгЖШНЕЕЭЕН
O(n)ЃЌОпЬхзіЗЈЮЊЃКИљОнКЫЖдЙцдђЫљЪЙгУЕНЕФзжЖЮЃЈАќРЈОЋШЗЦЅХфЁЂШнВюЦЅХфЁЂМгМѕЦЅХфКѓЕФжЕЕШЃЉзїЮЊХХађзжЖЮЃЌзщГЩХХађ
SQL гяОфЃЌЖд AЁЂB ЗНЪ§ОнЛКДцКЯМЏЗжБ№НјааХХађВЂдіМгааКХЃЛдйДгЫЋЗНХХађКѓЪ§ОнМЏжаДгЕквЛЬѕПЊЪМЃЌвРОнХХађзжЖЮЫГађНјааж№зжЖЮЙцдђЕЅдЊКЫЖдБШНЯЃЌШєШЋВПЗћКЯдђЮЊКЫЖдГЩЙІЃЌНЋЫЋЗНЪ§ОнааЕФБъМЧзжЖЮИќаТЃЌЧвЫЋЗНОљШЁЯТвЛЬѕМЧТМПЊЪМаТКЫЖдЃЌШєВЛЗћКЯЃЌдђШЁКЫЖдЪЇАмзжЖЮжЕНЯаЁвЛЗНЕФЯТвЛЬѕЪ§ОндйРДДгИУКЫЖдЙцдђЕФЪзИіЕЅдЊзжЖЮПЊЪМГЂЪдКЫЖдЃЛжиИДДЫЙ§ГЬжБЕНФГЗНЪ§ОнКФОЁЁЃЃЈШчЯТЭМЃЉ
ЛљгкХХађЪ§ОнМЏЕФКЫЖдЫуЗЈЪОвт
гЩгкЫЋЗНЪ§ОндкЗжВМЪНФкДцЛКДцжаЃЌЧвЗжВМЪНВЂааХХађаЇТЪКмИпЃЌМгЩЯКЫЖдЫуЗЈЭЈЙ§ЛљгкХХађКѓЕФЪ§ОнНјааБШЖдБмУтСЫЖдвЛЗНШЋСПЮоађЪ§ОнЕФжиИДВщбЏМьЫїЃЌвђДЫзмЬхадФмЩЯгаКмДѓЬсЩ§ЁЃНјвЛВНЕиЃЌЛЙПЩвдЖдвЛЗНЕФФГвЛОЋШЗЦЅХфЙцдђЕЅдЊзжЖЮжЕНјааВЩбљЗжЖЮЃЌзїЮЊЩЯЯТНчВЮЪ§ЙЙдьГівЛИіВПЗжКЫЖдЕФзгШЮЮёЃЌЦфжЛИКд№ДгЛКДцЪ§ОнМЏжаШЁЩЯЯТНчФкЕФЪ§ОнВЂНсКЯСэвЛЗННјааКЫЖдЃЌДгЖјЪЕЯжЖрЯпГЬВЂааДІРэвдДяЕНИќИпаЇКЫЖдЕФФПБъЁЃ
ЪЕМљаЇЙћ
вдФГецЪЕЪ§ОнЖдеЫашЧѓЮЊР§ЃЌИУашЧѓ AЁЂB ЫЋЗНдЪМЪ§ОнИїдМ 1600 ЭђЃЌA ЗНЪ§ОнФЃАхЙВ 19 ИізжЖЮЃЌB
ЗНЪ§ОнФЃАхЙВ 127 ИізжЖЮЃЌA ЗНЪ§ОнЧхЯДЙцдђ 4 зщЙВ 653 ЬѕЃЌB ЗНЪ§ОнЧхЯДЙцдђ 19 зщЙВ
61 ЬѕЃЌЫЋЗНКЫЖдЙцдђ 4 зщЙВ 24 ЬѕЁЃдкЯрЭЌЕФгВМўЬѕМўЯТЃЌИїЛЗНкгУЪБЕШжИБъЖдБШШчЯТЁЃ
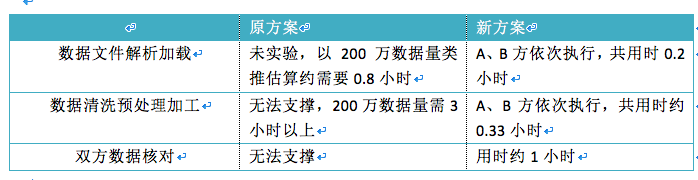
Г§ПЩвдЪЕЯжИќДѓЪ§ОнСПДІРэЭтЃЌИќживЊЕФЪЧаТЗНАИПЩвдЧсЫЩЪЕЯжЫЎЦНРЉеЙвдЬсИпЯЕЭГЕФДІРэФмСІЃЌжЛашвЊЯђМЏШКжадіМг
Ignite НкЕуМДПЩЁЃвђДЫЃЌФПЧАЯпЩЯЪЕМЪдкгУЕФЖдеЫЦНЬЈШеОљРлМЦДІРэЪ§ОнСПвбДяЕНЪЎвкзѓгвЃЌгаСІЕижЇГХСЫЧАЖЫИївЕЮёдДЯЕЭГЕФдЫааЪ§ОнКѓЦкДІРэашЧѓЁЃ
|









