| БрМЭЦМі: |
| БОЮФРДздгкCSDNЃЌБОЮФжївЊНщЩмСЫДѓЪ§ОнЕФАВзАХфжУЛЗОГЁЂHDFSвдМАYARN
- Hadoop зЪдДЙмРэЦїЕШЁЃ |
|
вЛЁЂЪВУДЪЧApache HadoopЃП
1.1 ЖЈвхКЭЬиад
ПЩППЕФЁЂПЩРЉеЙЕФЁЂЗжВМЪНМЦЫуПЊдДШэМўЁЃ
Apache HadoopШэМўПтЪЧвЛИіПђМмЃЌдЪаэЪЙгУМђЕЅЕФБрГЬФЃаЭЃЌдкМЦЫуЛњМЏШКЗжВМЪНЕиДІРэДѓаЭЪ§ОнМЏЁЃ
ЫќПЩвдДгЕЅИіЗўЮёЦїРЉеЙЕНЪ§ЧЇЬЈЛњЦїЃЌУПИіЛњЦїЖМЬсЙЉБОЕиМЦЫуКЭДцДЂЁЃ
УПвЛЬЈМЦЫуЛњЖМШнвзГіЯжЙЪеЯЃЌПтБОЩэЕФФПЕФЪЧМьВтКЭДІРэгІгУВуЕФЙЪеЯЃЌвђДЫдквЛзщМЦЫуЛњЩЯЬсЙЉИпПЩгУадЗўЮёЃЌЖјВЛЪЧвРППгВМўРДЬсЙЉИпПЩгУадЁЃ
1.2 жївЊФЃПщЃК
Hadoop Distributed File System(HDFS): вЛИіЗжВМЪНЮФМўЯЕЭГЃЌЫќЬсЙЉЖдгІгУГЬађЪ§ОнЕФИпЭЬЭТСПЗУЮЪЁЃ
Hadoop YARN: зївЕЕїЖШКЭМЏШКзЪдДЙмРэЕФПђМмЁЃ
Hadoop MapReduce: ЛљгкYARNЕФДѓаЭЪ§ОнМЏВЂааДІРэЯЕЭГЁЃ
ЖўЁЂHadoopАВзАЃЈвдhadoop-1.2.1ЮЊР§ЃЉ
2.1 зМБИЬѕМў
LinuxВйзїЯЕЭГ
АВзАJDKвдМАХфжУЯрЙиЛЗОГБфСП
ЯТдиHadoopАВзААќЃЌШчЃКhadoop-1.2.1.tar.gzЃЈЙйЭјЯТдиЕижЗЃКhttp://hadoop.apache.org/releases.htmlЃЉ
2.2 АВзА
НЋhadoop-1.2.1.tar.gzНтбЙЕНжИЖЈФПТМЃЌШчЃК/opt/hadoop-1.2.1/
2.3 ХфжУhadoopЛЗОГБфСП
дк/etc/profileжаХфжУШчЯТаХЯЂЃК
export JAVA_HOME=/opt/jdk1.8.0_131
export JRE_HOME=/opt/jdk1.8.0_131/jre
export HADOOP_HOME=/opt/hadoop-1.2.1
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/Lib
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$PATH |
2.4 аоИФЫФИіХфжУЮФМў
етЫФИіХфжУЮФМўОљдк/opt/hadoop-1.2.1/conf/ФПТМЯТЁЃ
(a)аоИФhadoop-env.sh,ЩшжУJAVA_HOME:
# The java implementation
to use. Required.
export JAVA_HOME=/opt/jdk1.8.0_131 |
(b)аоИФcore-site.xml,ЩшжУhadoop.tmp.dir,dfs.name.dir,fs.default.name:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<!-- hadoopСйЪБЙЄзїФПТМ -->
<value>/home/jochen/hadoop</value>
</property>
<property>
<name>dfs.name.dir</name>
<!-- hadoopдДЪ§ОнФПТМ -->
<value>/home/jochen/hadoop/name</value>
</property>
<property>
<name>fs.default.name</name>
<!-- ЮФМўЯЕЭГnamenode => ЕижЗЃКЖЫПкКХ -->
<value>hdfs://localhost:9000</value>
</property>
</configuration> |
(c)аоИФmapred-site.xml,ЩшжУmapred.job.tracker
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration> |
(d)аоИФhdfs-site.xml,ЩшжУdfs.data.dir:
<configuration>
<property>
<name>dfs.data.dir</name>
<!-- dfsЮФМўПщДцЗХФПТМ -->
<value>/home/jochen/hadoop/data</value>
</property>
</configuration> |
2.5 ИёЪНЛЏ
жДааУќСюЃК
| $ hadoop namenode
-format |
е§ШЗжДааЕФНсЙћШчЯТЫљЪОЃК
Warning: $HADOOP_HOME
is deprecated.
17/05/19 23:46:05 INFO namenode.NameNode: STARTUP_MSG:
/***************************************************
*********
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = ubuntu/127.0.0.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.2.1
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common
/branches/branch-1.2
-r 1503152; compiled by
'mattf' on Mon Jul 22
15:23:09 PDT 2013
STARTUP_MSG: java = 1.8.0_131
*************************************************
***********/
17/05/19 23:46:05 INFO util.GSet: Computing
capacity
for map BlocksMap
17/05/19 23:46:05 INFO util.GSet: VM type = 64-bit
17/05/19 23:46:05 INFO util.GSet: 2.0% max memory
= 932184064
17/05/19 23:46:05 INFO util.GSet: capacity = 2^21
= 2097152 entries
17/05/19 23:46:05 INFO util.GSet: recommended=2097152,
actual=2097152
17/05/19 23:46:05 INFO namenode.FSNamesystem:
fsOwner=jochen
17/05/19 23:46:05 INFO namenode.FSNamesystem:
supergroup=supergroup
17/05/19 23:46:05 INFO namenode.FSNamesystem:
isPermissionEnabled=true
17/05/19 23:46:05 INFO namenode.FSNamesystem:
dfs.block.invalidate.limit=100
17/05/19 23:46:05 INFO namenode.FSNamesystem:
isAccessTokenEnabled=false accessKeyUpdateInterval
=0
min(s), accessTokenLifetime=0 min(s)
17/05/19 23:46:05 INFO namenode.FSEditLog: dfs.namenode.edits.toleration.length
= 0
17/05/19 23:46:05 INFO namenode.NameNode:
Caching
file names occuring more than 10 times
17/05/19 23:46:05 INFO common.Storage: Image file
/home/jochen/hadoop/dfs/name/current/fsimage
of
size 112 bytes saved in 0 seconds.
17/05/19 23:46:06 INFO namenode.FSEditLog:
closing
edit log: position=4, editlog=/home/jochen/hadoop/dfs/name/current/edits
17/05/19 23:46:06 INFO namenode.FSEditLog:
close
success: truncate to 4, editlog=/home/jochen/hadoop/dfs/name/current/edits
17/05/19 23:46:06 INFO common.Storage: Storage
directory /home/jochen/hadoop/dfs/name has been
successfully formatted.
17/05/19 23:46:06 INFO namenode.NameNode:
SHUTDOWN_MSG:
/*******************************************
*****************
SHUTDOWN_MSG: Shutting down NameNode at
ubuntu/127.0.0.1
********************************************
****************/ |
2.6 ЦєЖЏ
$ cd /opt/hadoop-1.2.1/bin
$ ./start-all.sh |
2.7 ВщПДЕБЧАдЫааЕФjavaНјГЬ
дкTerminalЪфШыУќСюЃЌГіЯжШчЯТНсЙћБэЪОhadoopАВзАГЩЙІЃК
$ jps
12785 JobTracker
1161 Jps
23626 TaskTracker
23275 DataNode
21659 NameNode
23436 SecondaryNameNodeЁЖЦЊЁЗ |
Ш§ЁЂHDFSМђНщ
3.1 HDFSЛљБОИХФю
HDFSЩшМЦМмЙЙ
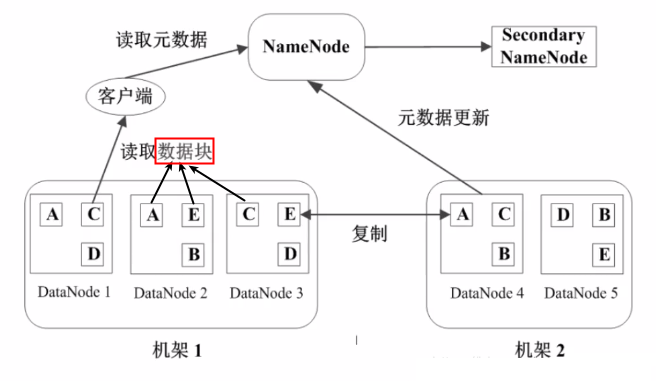
ПщЃЈBlockЃЉЃК
HDFSЕФЮФМўБЛЗжГЩПщНјааДцДЂ
HDFSПщЕФФЌШЯДѓаЁЮЊ64MB
ПщЪЧЮФМўДцДЂДІРэЕФТпМЕЅдЊ
ЙмРэНкЕуЃЈNameNodeЃЉЃЌДцЗХЮФМўдЊЪ§ОнЃК
ЮФМўгыЪ§ОнПщЕФгГЩфБэ
Ъ§ОнПщгыЪ§ОнНкЕуЕФгГЩфБэ
DataNodeЃК
DataNodeЪЧHDFSЕФЙЄзїНкЕу
ДцЗХЪ§ОнПщ
3.2 Ъ§ОнЙмРэВпТдгыШнДэ
Ъ§ОнПщИББОЃКУПИіЪ§ОнПщжСЩй3ИіИББОЃЌЗжВМдкСНИіЛњМмФкЕФЖрИіНкЕу
аФЬјМьВтЃКDataNodeЖЈЦкЯђNameNodeЗЂЫЭаФЬјЯћЯЂ 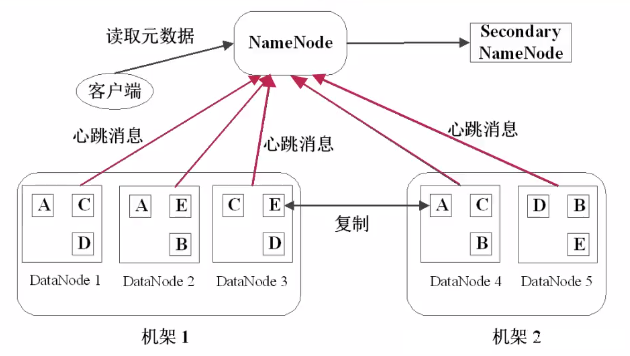
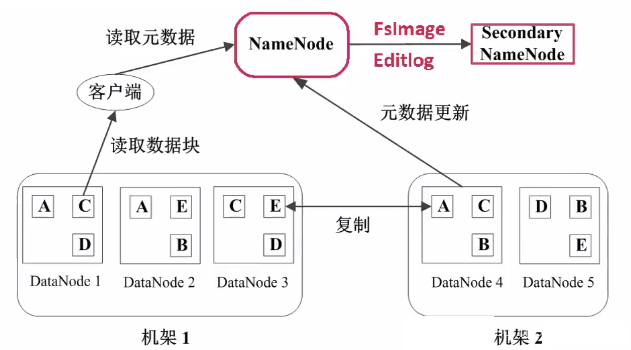
ЖўМЖNameNodeЃКЖўМЖNameNodeЖЈЦкЭЌВНдЊЪ§ОнгГЯёЮФМўКЭаоИФШежОЃЌNameNodeЗЂЩњЙЪеЯЪБЃЌЖўМЖNameNodeЬцЛЛЮЊжїNameNode
3.3 HDFSжаЮФМўЕФЖСаДВйзї
HDFSЖСШЁЮФМўЕФСїГЬ
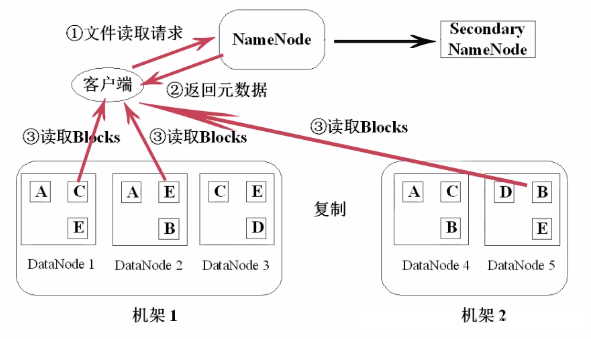
HDFSаДШыЮФМўЕФСїГЬ
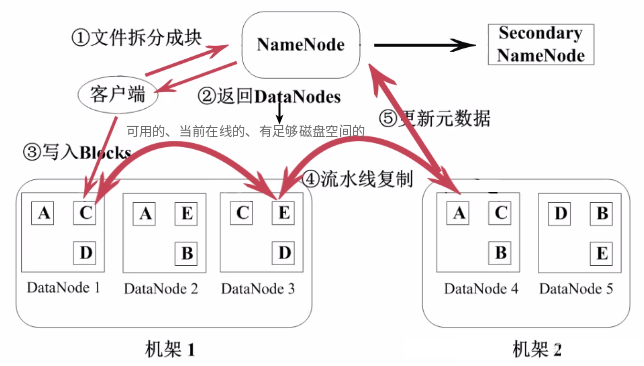
3.4 HDFSЕФЬиЕу
Ъ§ОнШпгрЃЌгВМўШнДэ
СїЪНЕФЪ§ОнЗУЮЪЃЈвЛДЮаДШыЁЂЖрДЮЖСШЁЃЉ
ЪЪКЯДцДЂДѓЮФМў
ЪЪгУадКЭОжЯоад
ЪЪКЯЪ§ОнХњСПЖСаДЃЌЭЬЭТСПИп
ВЛЪЪКЯНЛЛЅЪНгІгУЃЌЕЭбгГйКмФбТњзу
ЪЪКЯвЛДЮаДШыЖрДЮЖСШЁЃЌЫГађЖСаД
ВЛжЇГжЖргУЛЇВЂЗЂаДЯрЭЌЮФМў
3.5 HDFSЪЙгУ
HDFSУќСюааВйзїЃК
hadoop fs -ls
dirpath // СаГіФГФПТМЯТЕФЮФМўКЭФПТМ
hadoop fs -mkdir dirname // дкHDFSжааТНЈФПТМ
hadoop fs -put filepath dirpath // НЋБОЕиЮФМўЩЯДЋЕНHDFS
hadoop fs -get filepath dirpath // ДгHDFSЯТдиЮФМўЕНБОЕи
hadoop fs -cat filepath // ВщПДЮФМўФкШн
hadoop dfsadmin -report // ВщПДHDFSаХЯЂ |
ЫФЁЂMapReduceМђНщ
4.1 MapReduceЕФдРэ
ЗжЖјжЮжЎЃЌвЛИіДѓШЮЮёЗжГЩЖрИіаЁЕФзгШЮЮёЃЈmapЃЉЃЌВЂаажДааКѓЃЌКЯВЂНсЙћЃЈreduceЃЉ
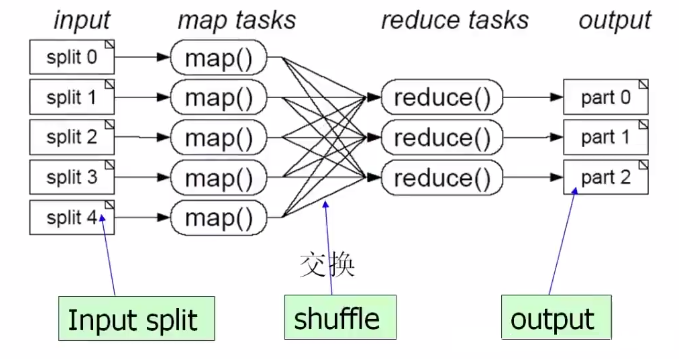
4.2 MapReduceЕФдЫааСїГЬ
ЛљБОИХФю
Job(зївЕ) & Task(ШЮЮё)
вЛИіJobПЩвдЗжГЩЖрИіTaskЃЈMapTask & ReduceTaskЃЉ
JobTrackerЃЈзївЕЙмРэНкЕуЃЉ
ПЭЛЇЖЫЬсНЛJobЃЌJobTrackerНЋЦфЗХШыКђбЁЖгСажаЃЌдкЪЪЕБЕФЪБКђНјааЕїЖШЃЌНЋJobВ№ЗжГЩЖрИіMapTaskКЭReduceTaskЃЌЗжЗЂИјTaskTrackerжДааЁЃJobTrackerЕФНЧЩЋЃК
зївЕЕїЖШ
ЗжХфШЮЮёЁЂМрПиШЮЮёжДааНјЖШ
МрПиTaskTrackerЕФзДЬЌ
TaskTrackerЃЈШЮЮёЙмРэНкЕуЃЉ
ЭЈГЃTaskTrackerКЭHDFSЕФDataNodeЪєгкЭЌвЛзщЮяРэНкЕуЃЌЪЕЯжСЫвЦЖЏМЦЫуДњЬцвЦЖЏЪ§ОнЃЌБЃжЄЖСШЁЪ§ОнПЊЯњзюаЁЁЃTaskTrackerЕФНЧЩЋЃК
жДааШЮЮё
ЛуБЈШЮЮёзДЬЌ
MapReduceЕФЬхЯЕНсЙЙ
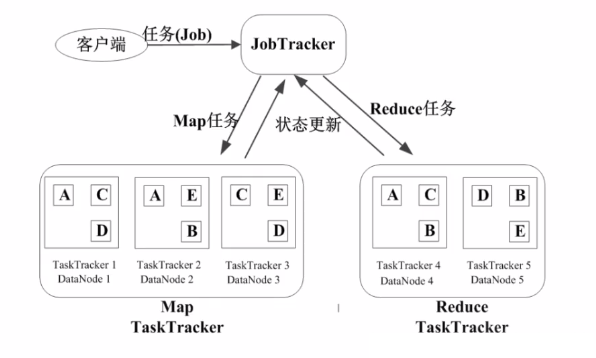
MapReduceзївЕжДааЙ§ГЬ

MapReduceЕФШнДэЛњжЦ
жиИДжДаа
ФЌШЯЮЊзюЖр4ДЮКѓЗХЦњ
ЭЦВтжДаа
двђЃКЫљгаMapЖЫдЫЫуЭъГЩЃЌВХПЊЪМжДааReduceЖЫЁЃ
зїгУЃКБЃжЄећИіШЮЮёЕФМЦЫуЃЌВЛЛсвђЮЊФГвЛСНИіTaskTrackerЕФЙЪеЯЃЌЕМжТећИіШЮЮёжДаааЇТЪКмЕЭЁЃ
ЮхЁЂYARN - Hadoop зЪдДЙмРэЦї
YARNЕФЛљБОЫМЯыЪЧНЋзЪдДЙмРэКЭзївЕЕїЖШ/МрПиЕФЙІФмВ№ЗжЕНВЛЭЌЕФЪиЛЄНјГЬЁЃетжжЫМЯыашвЊгавЛИіШЋОжЕФзЪдДЙмРэЦїЃЈRMЃЉКЭЃЈУПИігІгУГЬађЖМвЊгаЕФЃЉгІгУГЬађЙмРэЦїЃЈAMЃЉЁЃ
зЪдДЙмРэЦїЃЈRMЃЉКЭНкЕуЙмРэЦїЃЈNodeManagerЃЉаЮГЩСЫЪ§ОнМЦЫуПђМмЁЃзЪдДЙмРэЦїЃЈRMЃЉЪЧдкЯЕЭГжаЫљгагІгУГЬађМфжйВУзЪдДЕФзюжеШЈЭўЁЃНкЕуЙмРэЦїЃЈNodeManagerЃЉЪЧУПЬЈЛњЦїЕФПђМмДњРэЃЌИКд№ШнЦїЕФЙмРэЃЌМрПиЫћУЧЕФзЪдДЪЙгУЧщПі(cpuЁЂФкДцЁЂДХХЬЁЂЭјТч)ЃЌВЂЯђзЪдДЙмРэЦїЃЈRMЃЉ/ЕїЖШЦїБЈИцИУЧщПіЁЃ
УПИігІгУГЬађЕФгІгУГЬађЙмРэЦїЃЈAMЃЉЪЕМЪЩЯЪЧвЛИіЬиЖЈЕФПђМмЕФПтЃЌЫќЕФШЮЮёЪЧгызЪдДЙмРэЦїЃЈRMЃЉаЩЬзЪдДЃЌВЂгыНкЕуЙмРэЦїЃЈNodeManagerЃЉвЛЦ№ЙЄзїРДжДааКЭМрЪгШЮЮёЁЃ
зЪдДЙмРэЦїЃЈRMЃЉгаСНИіжївЊзщМў:ЕїЖШГЬађКЭгІгУГЬађЙмРэЦїЃЈAMЃЉЁЃ
ЕїЖШГЬађИКд№НЋзЪдДЗжХфИјИїжждЫааЕФгІгУГЬађЁЃЕїЖШГЬађЪЧДПДтЕФЕїЖШЦїЃЌвђЮЊЫќВЛжДаагІгУГЬађЕФзДЬЌМрЪгЛђИњзйЁЃСэЭтЃЌЫќвВВЛФмБЃжЄжиаТЦєЖЏЪЇАмЕФШЮЮёЃЌЮоТлЪЧгЩгкгІгУГЬађЪЇАмЛЙЪЧгВМўЙЪеЯЁЃ
гІгУГЬађЙмРэЦїЃЈAMЃЉИКд№НгЪеЬсНЛЕФЙЄзїЃЌаЩЬжДаагІгУГЬађЕФЕквЛИіШнЦїЃЌВЂВЂЬсЙЉдкЪЇАмЪБжиаТЦєЖЏгІгУГЬађЙмРэЦї(AM)ШнЦїЕФЗўЮёЁЃУПИігІгУГЬађЙмРэЦї(AM)ИКд№ДгЕїЖШГЬађжааЩЬЪЪЕБЕФзЪдДШнЦїЃЌИњзйЫќУЧЕФзДЬЌВЂМрЪгНјГЬЁЃ
YARN ЛЙжЇГжзЪдДдЄЖЈЕФИХФюЃЌБЃСєзЪдДвдШЗБЃживЊЙЄзїЕФПЩдЄМћаджДааЁЃдЄЖЉЯЕЭГЛсЖдзЪдДНјааИњзйЃЌЖддЄЖЉНјааПижЦЃЌВЂЖЏЬЌЕижИЕМЕзВуЕФЕїЖШГЬађЃЌвдШЗБЃдЄЖЉЪЧТњЕФЁЃ
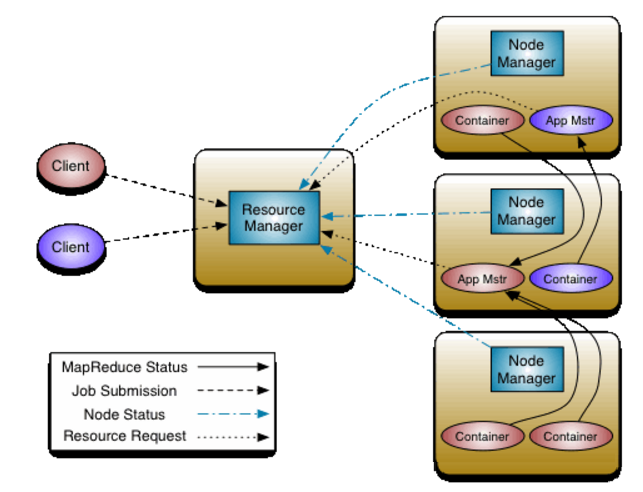
|









