| БрМЭЦМі: |
| БОЮФРДздгк51ctoЃЌБОЮФећРэСЫГЃМћЪЕЪБЪ§ОнзщМўЕФадФмЬиЕуКЭЪЪгУГЁОАЃЌНщЩмСЫУРЭХШчКЮЭЈЙ§
Flink в§ЧцЙЙНЈЪЕЪБЪ§ОнВжПтЁЃ |
|
в§бд
НќаЉФъЃЌЦѓвЕЖдЪ§ОнЗўЮёЪЕЪБЛЏЗўЮёЕФашЧѓШевцдіЖрЁЃБОЮФећРэСЫГЃМћЪЕЪБЪ§ОнзщМўЕФадФмЬиЕуКЭЪЪгУГЁОАЃЌНщЩмСЫУРЭХШчКЮЭЈЙ§
Flink в§ЧцЙЙНЈЪЕЪБЪ§ОнВжПтЃЌДгЖјЬсЙЉИпаЇЁЂЮШНЁЕФЪЕЪБЪ§ОнЗўЮёЁЃБОЮФжївЊВћЪіЪЙгУ Flink дкЪЕМЪЪ§ОнЩњВњЩЯЕФОбщЁЃ
ЪЕЪБЦНЬЈГѕЦкМмЙЙ
дкЪЕЪБЪ§ОнЯЕЭГНЈЩшГѕЦкЃЌгЩгкЖдЪЕЪБЪ§ОнЕФашЧѓНЯЩйЃЌаЮГЩВЛСЫЭъећЕФЪ§ОнЬхЯЕЁЃЮвУЧВЩгУЕФЪЧЁАвЛТЗЕНЕзЁБЕФПЊЗЂФЃЪНЃКЭЈЙ§дкЪЕЪБМЦЫуЦНЬЈЩЯВПЪ№
Storm зївЕДІРэЪЕЪБЪ§ОнЖгСаРДЬсШЁЪ§ОнжИБъЃЌжБНгЭЦЫЭЕНЪЕЪБгІгУЗўЮёжаЁЃ
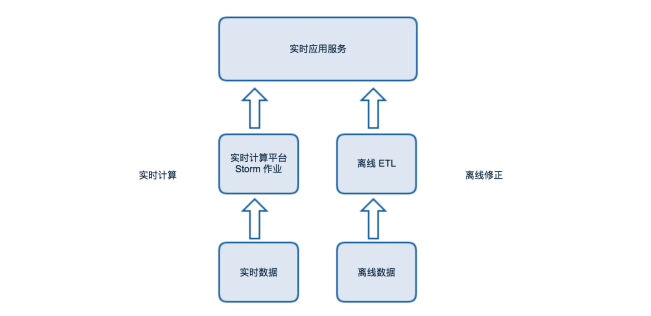
ЭМ1 ГѕЦкЪЕЪБЪ§ОнМмЙЙ
ЕЋЪЧЃЌЫцзХВњЦЗКЭвЕЮёШЫдБЖдЪЕЪБЪ§ОнашЧѓЕФВЛЖЯдіЖрЃЌаТЕФЬєеНвВЫцжЎЗЂЩњЁЃ
Ъ§ОнжИБъдНРДдНЖрЃЌЁАбЬДбЪНЁБЕФПЊЗЂЕМжТДњТыёюКЯЮЪЬтбЯжиЁЃ
ашЧѓдНРДдНЖрЃЌгаЕФашвЊУїЯИЪ§ОнЃЌгаЕФашвЊ OLAP ЗжЮіЁЃЕЅвЛЕФПЊЗЂФЃЪНФбвдгІИЖЖржжашЧѓЁЃ
ШБЩйЭъЩЦЕФМрПиЯЕЭГЃЌЮоЗЈдкЖдвЕЮёВњЩњгАЯьжЎЧАЗЂЯжВЂаоИДЮЪЬтЁЃ
ЪЕЪБЪ§ОнВжПтЕФЙЙНЈ
ЮЊНтОівдЩЯЮЪЬтЃЌЮвУЧИљОнЩњВњРыЯпЪ§ОнЕФОбщЃЌбЁдёЪЙгУЗжВуЩшМЦЗНАИРДНЈЩшЪЕЪБЪ§ОнВжПтЃЌЦфЗжВуМмЙЙШчЯТЭМЫљЪОЃК
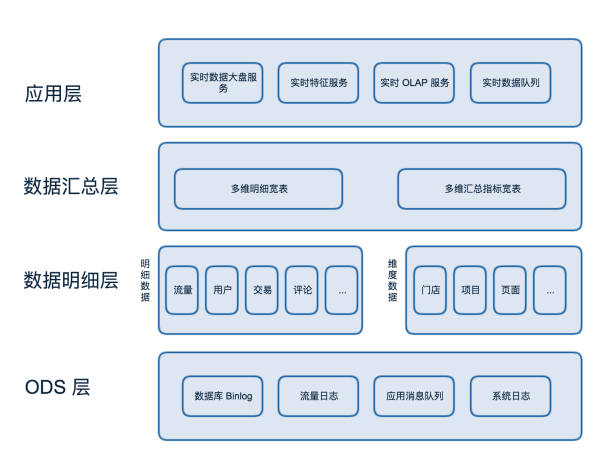
ЭМ2 ЪЕЪБЪ§ВжЪ§ОнЗжВуМмЙЙ
ИУЗНАИгЩвдЯТЫФВуЙЙГЩЃК
ODS ВуЃКBinlog КЭСїСПШежОвдМАИївЕЮёЪЕЪБЖгСаЁЃ
Ъ§ОнУїЯИВуЃКвЕЮёСьгђећКЯЬсШЁЪТЪЕЪ§ОнЃЌРыЯпШЋСПКЭЪЕЪББфЛЏЪ§ОнЙЙНЈЪЕЪБЮЌЖШЪ§ОнЁЃ
Ъ§ОнЛузмВуЃКЪЙгУПэБэФЃаЭЖдУїЯИЪ§ОнВЙГфЮЌЖШЪ§ОнЃЌЖдЙВаджИБъНјааЛузмЁЃ
App ВуЃКЮЊСЫОпЬхашЧѓЖјЙЙНЈЕФгІгУВуЃЌЭЈЙ§ RPC ПђМмЖдЭтЬсЙЉЗўЮёЁЃ
ЭЈЙ§ЖрВуЩшМЦЮвУЧПЩвдНЋДІРэЪ§ОнЕФСїГЬГСЕэдкИїВуЭъГЩЁЃБШШчдкЪ§ОнУїЯИВуЭГвЛЭъГЩЪ§ОнЕФЙ§ТЫЁЂЧхЯДЁЂЙцЗЖЁЂЭбУєСїГЬ;дкЪ§ОнЛузмВуМгЙЄЙВадЕФЖрЮЌжИБъЛузмЪ§ОнЁЃЬсИпСЫДњТыЕФИДгУТЪКЭећЬхЩњВњаЇТЪЁЃЭЌЪБИїВуМЖДІРэЕФШЮЮёРраЭЯрЫЦЃЌПЩвдВЩгУЭГвЛЕФММЪѕЗНАИгХЛЏадФмЃЌЪЙЪ§ВжММЪѕМмЙЙИќМђНрЁЃ
ММЪѕбЁаЭ
1.ДцДЂв§ЧцЕФЕїба
ЪЕЪБЪ§ВждкЩшМЦжаВЛЭЌгкРыЯпЪ§ВждкИїВуМЖЪЙгУЭЌжжДЂДцЗНАИЃЌБШШчЖМДцДЂдк Hive ЁЂDB жаЕФВпТдЁЃЪзЯШЖджаМфЙ§ГЬЕФБэЃЌВЩгУНЋНсЙЙЛЏЕФЪ§ОнЭЈЙ§ЯћЯЂЖгСаДцДЂКЭИпЫй
KV ДцДЂЛьКЯЕФЗНАИЁЃЪЕЪБМЦЫув§ЧцПЩвдЭЈЙ§МрЬ§ЯћЯЂЯћЗбЯћЯЂЖгСаФкЕФЪ§ОнЃЌНјааЪЕЪБМЦЫуЁЃЖјдкИпЫй KV
ДцДЂЩЯЕФЪ§ОндђПЩвдгУгкПьЫйЙиСЊМЦЫуЃЌБШШчЮЌЖШЪ§ОнЁЃ ЦфДЮдкгІгУВуЩЯЃЌеыЖдЪ§ОнЪЙгУЬиЕуХфжУДцДЂЗНАИжБНгаДШыЁЃБмУтСЫРыЯпЪ§ВжгІгУВуЭЌВНЪ§ОнСїГЬДјРДЕФДІРэбгГйЁЃ
ЮЊСЫНтОіВЛЭЌРраЭЕФЪЕЪБЪ§ОнашЧѓЃЌКЯРэЕФЩшМЦИїВуМЖДцДЂЗНАИЃЌЮвУЧЕїбаСЫУРЭХФкВПЪЙгУБШНЯЙуЗКЕФМИжжДцДЂЗНАИЁЃ
Бэ1 ДцДЂЗНАИСаБэ

УРЭХЕуЦРЛљгк Flink ЕФЪЕЪБЪ§ВжНЈЩшЪЕМљ
ИљОнВЛЭЌвЕЮёГЁОАЃЌЪЕЪБЪ§ВжИїИіФЃаЭВуДЮЪЙгУЕФДцДЂЗНАИДѓжТШчЯТЃК
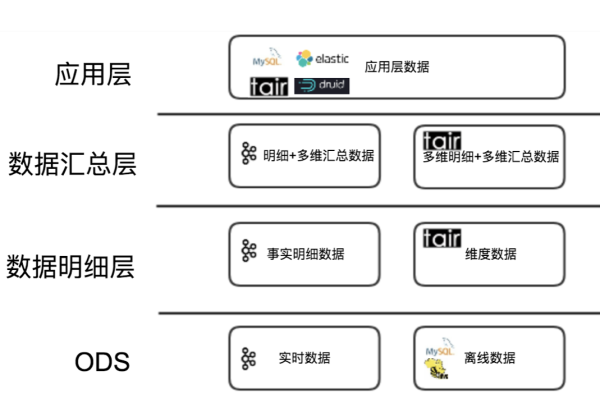
ЭМ3 ЪЕЪБЪ§ВжДцДЂЗжВуМмЙЙ
Ъ§ОнУїЯИВу ЖдгкЮЌЖШЪ§ОнВПЗжГЁОАЯТЙиСЊЕФЦЕТЪПЩДя 10w+ TPSЃЌЮвУЧбЁдё Cellar(УРЭХФкВПДцДЂЯЕЭГ)
зїЮЊДцДЂЃЌЗтзАЮЌЖШЗўЮёЮЊЪЕЪБЪ§ВжЬсЙЉЮЌЖШЪ§ОнЁЃ
Ъ§ОнЛузмВу ЖдгкЭЈгУЕФЛузмжИБъЃЌашвЊНјааРњЪЗЪ§ОнЙиСЊЕФЪ§ОнЃЌВЩгУКЭЮЌЖШЪ§ОнвЛбљЕФЗНАИЭЈЙ§ Cellar
зїЮЊДцДЂЃЌгУЗўЮёЕФЗНЪННјааЙиСЊВйзїЁЃ
Ъ§ОнгІгУВу гІгУВуЩшМЦЯрЖдИДдгЃЌдйЖдБШСЫМИжжВЛЭЌДцДЂЗНАИКѓЁЃЮвУЧжЦЖЈСЫвдЪ§ОнЖСаДЦЕТЪ 1000 QPS
ЮЊЗжНчЕФХаЖЯвРОнЁЃЖдгкЖСаДЦНОљЦЕТЪИпгк 1000 QPS ЕЋВщбЏВЛЬЋИДдгЕФЪЕЪБгІгУЃЌБШШчЩЬЛЇЪЕЪБЕФОгЊЪ§ОнЁЃВЩгУ
Cellar ЮЊДцДЂЃЌЬсЙЉЪЕЪБЪ§ОнЗўЮёЁЃЖдгквЛаЉВщбЏИДдгЕФКЭашвЊУїЯИСаБэЕФгІгУЃЌЪЙгУ Elasticsearch
зїЮЊДцДЂдђИќЮЊКЯЪЪЁЃЖјвЛаЉВщбЏЦЕТЪЕЭЃЌБШШчвЛаЉФкВПдЫгЊЕФЪ§ОнЁЃ Druid ЭЈЙ§ЪЕЪБДІРэЯћЯЂЙЙНЈЫїв§ЃЌВЂЭЈЙ§дЄОлКЯПЩвдПьЫйЕФЬсЙЉЪЕЪБЪ§Он
OLAP ЗжЮіЙІФмЁЃЖдгквЛаЉРњЪЗАцБОЕФЪ§ОнВњЦЗНјааЪЕЪБЛЏИФдьЪБЃЌвВПЩвдЪЙгУ MySQL ДцДЂБугкВњЦЗЕќДњЁЃ
2.МЦЫув§ЧцЕФЕїба
дкЪЕЪБЦНЬЈНЈЩшГѕЦкЮвУЧЪЙгУ Storm в§ЧцРДНјааЪЕЪБЪ§ОнДІРэЁЃStorm в§ЧцЫфШЛдкСщЛюадКЭадФмЩЯЖМБэЯжВЛДэЁЃЕЋЪЧгЩгк
API Й§гкЕзВуЃЌдкЪ§ОнПЊЗЂЙ§ГЬжаашвЊЖдвЛаЉГЃгУЕФЪ§ОнВйзїНјааЙІФмЪЕЯжЁЃБШШчБэЙиСЊЁЂОлКЯЕШЃЌВњЩњСЫКмЖрЖюЭтЕФПЊЗЂЙЄзїЃЌВЛНів§ШыСЫКмЖрЭтВПвРРЕБШШчЛКДцЃЌЖјЧвЪЕМЪЪЙгУЪБадФмвВВЛЪЧКмРэЯыЁЃЭЌЪБ
Storm ФкЕФЪ§ОнЖдЯѓ Tuple жЇГжЕФЙІФмвВКмМђЕЅЃЌЭЈГЃашвЊНЋЦфзЊЛЛЮЊ Java ЖдЯѓРДДІРэЁЃЖдгкетжжЛљгкДњТыЖЈвхЕФЪ§ОнФЃаЭЃЌЭЈГЃЮвУЧжЛФмЭЈЙ§ЮФЕЕРДНјааЮЌЛЄЁЃВЛНіашвЊЖюЭтЕФЮЌЛЄЙЄзїЃЌЭЌЪБдкдіИФзжЖЮЪБвВКмТщЗГЁЃзлКЯРДПДЪЙгУ
Storm в§ЧцЙЙНЈЪЕЪБЪ§ВжФбЖШНЯДѓЁЃЮвУЧашвЊвЛИіаТЕФЪЕЪБДІРэЗНАИЃЌвЊФмЙЛЪЕЯжЃК
ЬсЙЉИпМЖ APIЃЌжЇГжГЃМћЕФЪ§ОнВйзїБШШчЙиСЊОлКЯЃЌзюКУЪЧФмжЇГж SQLЁЃ
ОпгазДЬЌЙмРэКЭздЖЏжЇГжОУЛЏЗНАИЃЌМѕЩйЖдДцДЂЕФвРРЕЁЃ
БугкНгШыдЊЪ§ОнЗўЮёЃЌБмУтЭЈЙ§ДњТыЙмРэЪ§ОнНсЙЙЁЃ
ДІРэадФмжСЩйвЊКЭ Storm вЛжТЁЃ
ЮвУЧЖджївЊЕФЪЕЪБМЦЫув§ЧцНјааСЫММЪѕЕїбаЁЃзмНсСЫИїРрв§ЧцЬиадШчЯТБэЫљЪОЃК
Бэ2 ЪЕЪБМЦЫуЗНАИСаБэ
УРЭХЕуЦРЛљгк Flink ЕФЪЕЪБЪ§ВжНЈЩшЪЕМљ
ДгЕїбаНсЙћРДПДЃЌFlink КЭ Spark Streaming ЕФ API ЁЂШнДэЛњжЦгызДЬЌГжОУЛЏЛњжЦЖМПЩвдНтОівЛВПЗжЮвУЧФПЧАЪЙгУ
Storm жагіЕНЕФЮЪЬтЁЃЕЋ Flink дкЪ§ОнбгГйЩЯКЭ Storm ИќНгНќЃЌЖдЯжгагІгУгАЯьзюаЁЁЃЖјЧвдкЙЋЫОФкВПЕФВтЪджа
Flink ЕФЭЬЭТадФмЖдБШ Storm гаЪЎБЖзѓгвЬсЩ§ЁЃзлКЯПМСПЮвУЧбЁЖЈ Flink в§ЧцзїЮЊЪЕЪБЪ§ВжЕФПЊЗЂв§ЧцЁЃ
ИќМгв§Ц№ЮвУЧзЂвтЕФЪЧЃЌFlink ЕФ Table ГщЯѓКЭ SQL жЇГжЁЃЫфШЛЪЙгУ Strom в§ЧцвВПЩвдДІРэНсЙЙЛЏЪ§ОнЁЃЕЋБЯОЙвРОЩЪЧЛљгкЯћЯЂЕФДІРэ
API ЃЌдкДњТыВуВуУцЩЯВЛФмЭъШЋЯэЪмВйзїНсЙЙЛЏЪ§ОнЕФБуРћЁЃЖј Flink ВЛНіжЇГжСЫДѓСПГЃгУЕФ SQL
гяОфЃЌЛљБОИВИЧСЫЮвУЧЕФПЊЗЂГЁОАЁЃЖјЧв Flink ЕФ Table ПЩвдЭЈЙ§ TableSchema
НјааЙмРэЃЌжЇГжЗсИЛЕФЪ§ОнРраЭКЭЪ§ОнНсЙЙвдМАЪ§ОндДЁЃПЩвдКмШнвзЕФКЭЯжгаЕФдЊЪ§ОнЙмРэЯЕЭГЛђХфжУЙмРэЯЕЭГНсКЯЁЃЭЈЙ§ЯТЭМЮвУЧПЩвдЧхЮњЕФПДГі
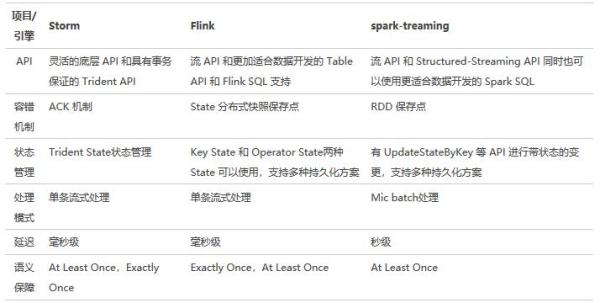
Storm КЭ Flink дкПЊЗЂЭГЙ§ГЬжаЕФЧјБ№ЁЃ
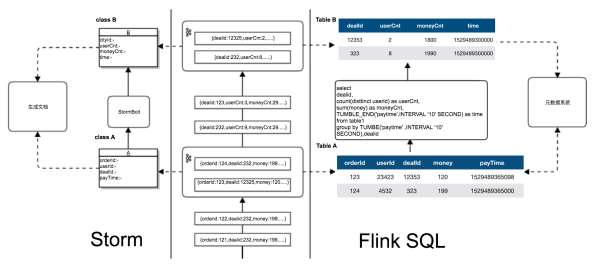
ЭМ4 Flink - Storm ЖдБШЭМ
дкЪЙгУ Storm ПЊЗЂЪБДІРэТпМгыЪЕЯжашвЊЙЬЛЏдк Bolt ЕФДњТыЁЃFlink дђПЩвдЭЈЙ§ SQL
НјааПЊЗЂЃЌДњТыПЩЖСадИќИпЃЌТпМЕФЪЕЯжгЩПЊдДПђМмРДБЃжЄПЩППИпаЇЃЌЖдЬиЖЈГЁОАЕФгХЛЏжЛвЊаоИФ Flink
SQL гХЛЏЦїЙІФмЪЕЯжМДПЩЃЌЖјВЛгАЯьТпМДњТыЁЃЪЙЮвУЧПЩвдАбИќЖрЕФОЋСІЗХЕНЕНЪ§ОнПЊЗЂжаЃЌЖјВЛЪЧТпМЕФЪЕЯжЁЃЕБашвЊРыЯпЪ§ОнКЭЪЕЪБЪ§ОнПкОЖЭГвЛЕФГЁОАЪБЃЌЮвУЧжЛашЖдРыЯпПкОЖЕФ
SQL НХБОЩдМгИФдьМДПЩЃЌМЋДѓЕиЬсИпСЫПЊЗЂаЇТЪЁЃЭЌЪБЖдБШЭМжа Flink КЭ Storm ЪЙгУЕФЪ§ОнФЃаЭЃЌStorm
ашвЊЭЈЙ§вЛИі Java ЕФ Class ШЅЖЈвхЪ§ОнНсЙЙЃЌFlink Table дђПЩвдЭЈЙ§дЊЪ§ОнРДЖЈвхЁЃПЩвдКмКУЕФКЭЪ§ОнПЊЗЂжаЕФдЊЪ§ОнЃЌЪ§ОнжЮРэЕШЯЕЭГНсКЯЃЌЬсИпПЊЗЂаЇТЪЁЃ
FlinkЪЙгУаФЕУ
дкРћгУ Flink-Table ЙЙНЈЪЕЪБЪ§ОнВжПтЙ§ГЬжаЁЃЮвУЧеыЖдвЛаЉЙЙНЈЪ§ОнВжПтЕФГЃгУВйзїЃЌБШШчЪ§ОнжИБъЕФЮЌЖШРЉГфЃЌЪ§ОнАДжїЬтЙиСЊЃЌвдМАЪ§ОнЕФОлКЯдЫЫуЭЈЙ§
Flink РДЪЕЯжзмНсСЫвЛаЉЪЙгУаФЕУЁЃ
1.ЮЌЖШРЉГф
Ъ§ОнжИБъЕФЮЌЖШРЉГфЃЌЮвУЧВЩгУЕФЪЧЭЈЙ§ЮЌЖШЗўЮёЛёШЁЮЌЖШаХЯЂЁЃЫфШЛЛљгк Cellar ЕФЮЌЖШЗўЮёЭЈГЃЕФЯьгІбгГйПЩвддк
1ms вдЯТЁЃЕЋЪЧЮЊСЫНјвЛВНгХЛЏ Flink ЕФЭЬЭТЃЌЮвУЧЖдЮЌЖШЪ§ОнЕФЙиСЊШЋВПВЩгУСЫвьВННгПкЗУЮЪЕФЗНЪНЃЌБмУтСЫЪЙгУ
RPC ЕїгУгАЯьЪ§ОнЭЬЭТЁЃ
ЖдгквЛаЉЪ§ОнСПКмДѓЕФСїЃЌБШШчСїСПШежОЪ§ОнСПдк 10W Ьѕ/УыетИіСПМЖЁЃдкЙиСЊ UDF ЕФЪБКђФкжУСЫЛКДцЛњжЦЃЌПЩвдИљОнУќжаТЪКЭЪБМфЖдЛКДцНјааЬдЬЃЌХфКЯгУЙиСЊЕФ
Key жЕНјааЗжЧјЃЌЯджјМѕЩйСЫЖдЭтВПЗўЮёЕФЧыЧѓДЮЪ§ЃЌгааЇЕФМѕЩйСЫДІРэбгГйКЭЖдЭтВПЯЕЭГЕФбЙСІЁЃ
2.Ъ§ОнЙиСЊ
Ъ§ОнжїЬтКЯВЂЃЌБОжЪЩЯОЭЪЧЖрИіЪ§ОндДЕФЙиСЊЃЌМђЕЅЕФРДЫЕОЭЪЧ Join ВйзїЁЃFlink ЕФ Table
ЪЧНЈСЂдкЮоЯоСїетИіИХФюЩЯЕФЁЃдкНјаа Join ВйзїЪБВЂВЛФмЯёРыЯпЪ§ОнвЛбљЖдСНИіЭъећЕФБэНјааЙиСЊЁЃВЩгУЕФЪЧдкДАПкЪБМфФкЖдЪ§ОнНјааЙиСЊЕФЗНАИЃЌЯрЕБгкДгСНИіЪ§ОнСїжаИїздНиШЁвЛЖЮЪБМфЕФЪ§ОнНјаа
Join ВйзїЁЃгаЕуРрЫЦгкРыЯпЪ§ОнЭЈЙ§ЯожЦЗжЧјРДНјааЙиСЊЁЃЭЌЪБашвЊзЂвт Flink ЙиСЊБэЪББиаыгажСЩйвЛИіЁАЕШгкЁБЙиСЊЬѕМўЃЌвђЮЊЕШКХСНБпЕФжЕЛсгУРДЗжзщЁЃ
гЩгк Flink ЛсЛКДцДАПкФкЕФШЋВПЪ§ОнРДНјааЙиСЊЃЌЛКДцЕФЪ§ОнСПКЭЙиСЊЕФДАПкДѓаЁГЩе§БШЁЃвђДЫ Flink
ЕФЙиСЊВщбЏЃЌИќЪЪКЯДІРэвЛаЉПЩвдЭЈЙ§вЕЮёЙцдђЯожЦЙиСЊЪ§ОнЪБМфЗЖЮЇЕФГЁОАЁЃБШШчЙиСЊЯТЕЅгУЛЇЙКТђжЎЧА 30
ЗжжгФкЕФфЏРРШежОЁЃЙ§ДѓЕФДАПкВЛНіЛсЯћКФИќЖрЕФФкДцЃЌЭЌЪБЛсВњЩњИќДѓЕФ Checkpoint ЃЌЕМжТЭЬЭТЯТНЕЛђ
Checkpoint ГЌЪБЁЃдкЪЕМЪЩњВњжаПЩвдЪЙгУ RocksDB КЭЦєгУдіСПБЃДцЕуФЃЪНЃЌМѕЩй Checkpoint
Й§ГЬЖдЭЬЭТВњЩњгАЯьЁЃЖдгквЛаЉашвЊЙиСЊДАПкЦкКмГЄЕФГЁОАЃЌБШШчЙиСЊЕФЪ§ОнПЩФмЪЧМИЬьвдЧАЕФЪ§ОнЁЃЖдгкетаЉРњЪЗЪ§ОнЃЌЮвУЧПЩвдНЋЦфРэНтЮЊЪЧвЛжжвбОЙЬЖЈВЛБфЕФ"ЮЌЖШ"ЁЃПЩвдНЋашвЊБЛЙиСЊЕФРњЪЗЪ§ОнВЩгУКЭЮЌЖШЪ§ОнвЛжТЕФДІРэЗНЗЈЃК"ЛКДц
+ РыЯп"Ъ§ОнЗНЪНДцДЂЃЌгУНгПкЕФЗНЪННјааЙиСЊЁЃСэЭташвЊзЂвт Flink ЖдЖрБэЙиСЊЪЧжБНгЫГађСДНгЕФЃЌвђДЫашвЊзЂвтЯШНјааНсЙћМЏаЁЕФЙиСЊЁЃ
3.ОлКЯдЫЫу
ЪЙгУОлКЯдЫЫуЪБЃЌFlink ЖдГЃМћЕФОлКЯдЫЫуШчЧѓКЭЁЂМЋжЕЁЂОљжЕЕШЖМгажЇГжЁЃУРжаВЛзуЕФЪЧЖдгк Distinct
ЕФжЇГжЃЌFlink-1.6 жЎЧАЕФВЩгУЕФЗНАИЪЧЭЈЙ§ЯШЖдШЅжизжЖЮНјааЗжзщдйОлКЯЪЕЯжЁЃЖдгкашвЊЖдЖрИізжЖЮШЅжиОлКЯЕФГЁОАЃЌжЛФмЗжБ№МЦЫудйНјааЙиСЊДІРэаЇТЪКмЕЭЁЃЮЊДЫЮвУЧПЊЗЂСЫздЖЈвхЕФ
UDAFЃЌЪЕЯжСЫ MapView ОЋШЗШЅжиЁЂBloomFilter ЗЧОЋШЗШЅжиЁЂ HyperLogLog
ГЌЕЭФкДцШЅжиЗНАИгІЖдИїжжЪЕЪБШЅжиГЁОАЁЃЕЋЪЧдкЪЙгУздЖЈвхЕФ UDAF ЪБЃЌашвЊзЂвт RocksDBStateBackend
ФЃЪНЖдгкНЯДѓЕФ Key НјааИќаТВйзїЪБађСаЛЏКЭЗДађСаЛЏКФЪБКмЖрЁЃПЩвдПМТЧЪЙгУ FsStateBackend
ФЃЪНЬцДњЁЃСэЭтвЊзЂвтЕФвЛЕу Flink ПђМмдкМЦЫуБШШч Rank етбљЕФЗжЮіКЏЪ§ЪБЃЌашвЊЛКДцУПИіЗжзщДАПкЯТЕФШЋВПЪ§ОнВХФмНјааХХађЃЌЛсЯћКФДѓСПФкДцЁЃНЈвщдкетжжГЁОАЯТгХЯШзЊЛЛЮЊ
TopN ЕФТпМЃЌПДЪЧЗёПЩвдНтОіашЧѓЁЃ
ЯТЭМеЙЪОвЛИіЭъећЕФЪЙгУ Flink в§ЧцЩњВњвЛеХЪЕЪБЪ§ОнБэЕФЙ§ГЬЃК
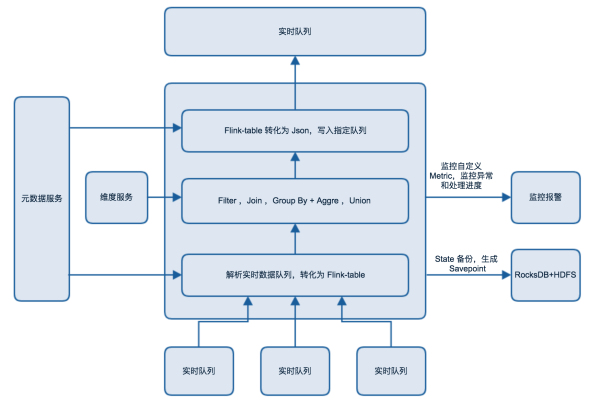
ЭМ5 ЪЕЪБМЦЫуСїГЬЭМ
ЪЕЪБЪ§ВжГЩЙћ
ЭЈЙ§ЪЙгУЪЕЪБЪ§ВжДњЬцдгаСїГЬЃЌЮвУЧНЋЪ§ОнЩњВњжаЕФИїИіСїГЬГщЯѓЕНЪЕЪБЪ§ВжЕФИїВуЕБжаЁЃЪЕЯжСЫШЋВПЪЕЪБЪ§ОнгІгУЕФЪ§ОндДЭГвЛЃЌБЃжЄСЫгІгУЪ§ОнжИБъЁЂЮЌЖШЕФПкОЖЕФвЛжТЁЃдкМИДЮЪ§ОнПкОЖЗЂЩњаоИФЕФГЁОАжаЃЌЮвУЧЭЈЙ§ЖдВжПтУїЯИКЭЛузмНјааИФдьЃЌдкЭъШЋВЛгУаоИФгІгУДњТыЕФЧщПіЯТОЭЭъГЩШЋВПгІгУЕФПкОЖЧаЛЛЁЃдкПЊЗЂЙ§ГЬжаЭЈЙ§бЯИёЕФАбПиЪ§ОнЗжВуЁЂжїЬтгђЛЎЗжЁЂФкШнзщжЏБъзМЙцЗЖКЭУќУћЙцдђЁЃЪЙЪ§ОнПЊЗЂЕФСДТЗИќЮЊЧхЮњЃЌМѕЩйСЫДњТыЕФёюКЯЁЃдйХфКЯЩЯЪЙгУ
Flink SQL НјааПЊЗЂЃЌДњТыМгМђНрЁЃЕЅИізївЕЕФДњТыСПДгЦНОљ 300+ ааЕФ JAVA ДњТы ЃЌЫѕМѕЕНМИЪЎааЕФ
SQL НХБОЁЃЯюФПЕФПЊЗЂЪБГЄвВДѓЗљМѕЖЬЃЌвЛШЫШеПЊЗЂЖрИіЪЕЪБЪ§ОнжИБъЧщПівВВЛЩйМћЁЃ
Г§ДЫвдЭтЮвУЧЭЈЙ§еыЖдЪ§ВжИїВуМЖЙЄзїФкШнЕФВЛЭЌЬиЕуЃЌПЩвдНјааеыЖдадЕФадФмгХЛЏКЭВЮЪ§ХфжУЁЃБШШч ODS
ВужївЊНјааЪ§ОнЕФНтЮіЁЂЙ§ТЫЕШВйзїЃЌВЛашвЊ RPC ЕїгУКЭОлКЯдЫЫуЁЃ ЮвУЧеыЖдЪ§ОнНтЮіЙ§ГЬНјаагХЛЏЃЌМѕЩйВЛБивЊЕФ
JSON зжЖЮНтЮіЃЌВЂЪЙгУИќИпаЇЕФ JSON АќЁЃдкзЪдДЗжХфЩЯЃЌЕЅИі CPU жЛХфжУ 1GB ЕФФкДцМДПЩТњашЧѓЁЃЖјЛузмВужївЊдђжївЊНјааОлКЯгыЙиСЊдЫЫуЃЌПЩвдЭЈЙ§гХЛЏОлКЯЫуЗЈЁЂФкЭтДцЙВЭЌдЫЫуРДЬсИпадФмЁЂМѕЩйГЩБОЁЃзЪдДХфжУЩЯвВЛсЗжХфИќЖрЕФФкДцЃЌБмУтФкДцвчГіЁЃЭЈЙ§етаЉгХЛЏЪжЖЮЃЌЫфШЛЯрБШдгаСїГЬЪЕЪБЪ§ВжЕФЩњВњСДТЗИќГЄЃЌЕЋЪ§ОнбгГйВЂУЛгаУїЯддіМгЁЃЭЌЪБЪЕЪБЪ§ОнгІгУЫљЪЙгУЕФМЦЫузЪдДвВгаУїЯдМѕЩйЁЃ
еЙЭћ
ЮвУЧЕФФПБъЪЧНЋЪЕЪБВжПтНЈЩшГЩПЩвдКЭРыЯпВжПтЪ§ОнзМШЗадЃЌвЛжТадцЧУРЕФЪ§ОнЯЕЭГЁЃЮЊЩЬМвЃЌвЕЮёШЫдБвдМАУРЭХгУЛЇЬсЙЉМАЪБПЩППЕФЪ§ОнЗўЮёЁЃЭЌЪБзїЮЊЕНВЭЪЕЪБЪ§ОнЕФЭГвЛГіПкЃЌЮЊМЏЭХЦфЫћвЕЮёВПУХжњСІЁЃЮДРДЮвУЧНЋИќМгЙизЂдкЪ§ОнПЩППадКЭЪЕЪБЪ§ОнжИБъЙмРэЁЃНЈСЂЭъЩЦЕФЪ§ОнМрПиЃЌЪ§ОнбЊдЕМьВтЃЌНЛВцМьВщЛњжЦЁЃМАЪБЖдвьГЃЪ§ОнЛђЪ§ОнбгГйНјааМрПиКЭдЄОЏЁЃЭЌЪБгХЛЏПЊЗЂСїГЬЃЌНЕЕЭПЊЗЂЪЕЪБЪ§ОнбЇЯАГЩБОЁЃШУИќЖргаЪЕЪБЪ§ОнашЧѓЕФШЫЃЌПЩвдздМКЖЏЪжНтОіЮЪЬтЁЃ |









