| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФжївЊНщЩмПЩЕќДњЕФСїЃЈIterativeStreamЃЉвдМАЗДРЁСїЕШЯрЙиФкШнЁЃ |
|
ЕБЧАFlinkНЋЕќДњЕФжиаФМЏжадкХњДІРэЩЯЃЌжЎЧАЮвУЧЬИМАСЫХњСПЕќДњКЭдіСПЕќДњжївЊЪЧеыЖдХњДІРэЃЈDataSetЃЉAPIЖјбдЕФЃЌВЂЧвFlinkЮЊХњДІРэжаЕФЕќДњЬсЙЉСЫеыЖдадЕФгХЛЏЁЃЕЋЪЧЖдгкСїДІРэЃЈDataStreamЃЉЃЌFlinkЭЌбљЬсЙЉСЫЖдЕќДњЕФжЇГжЃЌетвЛНкЮвУЧжївЊРДЗжЮіСїДІРэжаЕФЕќДњЃЌЮвУЧНЋЛсПДЕНСїДІРэжаЕФЕќДњЯрНЯгкХњДІРэгаЯрЫЦжЎДІЃЌЕЋВювьвВЪЧЪЎЗжжЎУїЯдЁЃ
ПЩЕќДњЕФСїДІРэГЬађдЪаэЖЈвхЁАВНКЏЪ§ЁБЃЈstep functionЃЉВЂНЋЦфФкЧЖЕНвЛИіПЩЕќДњЕФСїЃЈIterativeStreamЃЉжаЁЃвђЮЊвЛИіСїДІРэГЬађПЩФмгРВЛжежЙЃЌвђДЫВЛЭЌгкХњДІРэжаЕФЕќДњЛњжЦЃЌСїДІРэжаЮоЗЈЩшжУЕќДњЕФзюДѓДЮЪ§ЁЃШЁЖјДњжЎЕФЪЧЃЌФуПЩвджИЖЈЕШД§ЗДРЁЪфШыЕФзюДѓЪБМфМфИєЃЈШчЙћГЌЙ§ИУЪБМфМфИєУЛгаЗДРЁдЊЫиЕНРДЃЌФЧУДИУЕќДњНЋЛсжежЙЃЉЁЃЭЈЙ§гІгУsplitЛђfilterзЊЛЛЃЌФуПЩвджИЖЈСїЕФФФвЛВПЗжгУгкЗДРЁИјЕќДњЭЗЃЌФФвЛВПЗжЗжЗЂИјЯТгЮЁЃетРяЮвУЧвдfilterзїЮЊЪОР§РДеЙЪОПЩЕќДњЕФСїДІРэГЬађЕФAPIЪЙгУФЃЪНЁЃ
ЪзЯШЃЌЛљгкЪфШыСїЙЙНЈIterativeStreamЃЌетЪЧвЛИіЕќДњЕФЦ№ЪМЃЌЭЈГЃГЦжЎЮЊЕќДњЭЗЃК
| IterativeStream<Integer>
iteration = inputStream.iterate(); |
НгзХЃЌЮвУЧжИЖЈвЛЯЕСаЕФзЊЛЛВйзїгУгкБэЪідкЕќДњЙ§ГЬжажДааЕФТпМЃЈетРяМђЕЅвдmapзЊЛЛзїЮЊЪОР§ЃЉЃЌmap
APIЫљНгЪмЕФUDFОЭЪЧЮвУЧЩЯЮФЫљЫЕЕФВНКЏЪ§ЃК
| DataStream<Integer>
iteratedStream = iteration.map(/* this is executed
many times */); |
ШЛКѓЃЌзїЮЊЕќДњЮвУЧПЯЖЈашвЊгаЪ§ОнЗДРЁИјЕќДњЭЗНјаажиИДМЦЫуЃЌЫљвдЮвУЧДгЕќДњЙ§ЕФСїжаЙ§ТЫГіЗћКЯЬѕМўЕФдЊЫизщГЩЕФВПЗжСїЃЌЮвУЧГЦжЎЮЊЗДРЁСїЃК
| DataStream<Integer>
feedbackStream = iteratedStream.filter(/* one
part of the stream */); |
НЋЗДРЁСїЗДРЁИјЕќДњЭЗОЭвтЮЖзХвЛИіЕќДњЕФЭъећТпМЕФЭъГЩЃЌФЧУДЫќОЭПЩвдЁАЙиБеЁБетИіБеКЯЕФЁАЛЗЁБСЫЁЃЭЈЙ§ЕїгУIterativeStreamЕФcloseWithетвЛЪЕР§ЗНЗЈПЩвдЙиБевЛИіЕќДњЃЈвВПЩБэЪіЮЊЖЈвхСЫЕќДњЮВЃЉЁЃДЋЕнИјcloseWithЕФЪ§ОнСїНЋЛсЗДРЁИјЕќДњЭЗЃК
| iteration.closeWith(feedbackStream); |
СэЭтЃЌвЛИіЙпгУЕФФЃЪНЪЧЙ§ТЫГіашвЊМЬајЯђЧАЗжЗЂЕФВПЗжСїЃЌетИіЙ§ТЫзЊЛЛЦфЪЕЖЈвхЕФЪЧЁАжежЙЕќДњЁБЕФТпМЬѕМўЃЌЗћКЯЬѕМўЕФдЊЫиНЋБЛЗжЗЂИјЯТгЮЖјВЛгУгкНјааЯТвЛДЮЕќДњЃК
| DataStream<Integer>
output = iteratedStream.filter(/* some other part
of the stream */); |
ИњЗжЮіХњДІРэжаЕФЕќДњвЛбљЃЌЮвУЧШдШЛвдНтОіЪЕМЪЮЪЬтЕФАИР§зїЮЊЧаШыЕуРДПДПДСїДІРэжаЕФЕќДњИњХњДІРэжаЕФЕќДњгаКЮВЛЭЌЁЃ
ЪзЯШУшЪівЛЯТашвЊНтОіЕФЮЪЬтЃКВњЩњвЛИігЩвЛЯЕСаЖўдЊзщЃЈСНИізжЖЮЖМЪЧдквЛИіЧјМфФкВњЩњЕФе§ећЪ§РДзїЮЊьГВЈФЧЦѕЪ§СаЕФСНИіГѕЪМжЕЃЉЙЙГЩЕФЪ§ОнСїЃЌШЛКѓЖдИУЪ§ОнСїжаЕФЖўдЊзщВЛЖЯЕиЕќДњЪЙЦфВњЩњьГВЈФЧЦѕЪ§СаЃЌжБЕНФГДЮВњЩњЕФжЕДѓгкИјЖЈЕФуажЕЃЌдђЭЃжЙЕќДњВЂЪфГіЕќДњДЮЪ§ЁЃ
ИУАИР§ВЮПМздFlinkЫцдДТыЗЂВМЕФЕќДњЪОР§ЃЌДЫАИР§ЮЪЬтЙцФЃНЯаЁВЂЧвФмЙЛЫЕУїЮЪЬтЁЃЕЋЫќЪОР§ДњТыжаЕФвЛЯЕСаБфСПЩдЯдЛьТвЃЌЮЊСЫдіЧПГЬађЕФБэЪіадЃЌБЪепЛсЖдЦфЩдзїЕїећЁЃ
етИіАИР§ШчЙћВ№ЗжЕНЖдЕЅИідЊЫиЃЈЖўдЊзщЃЉЕФНЧЖШРДПДЃЌЦфжДааЙ§ГЬШчЯТЭМЫљЪОЃК
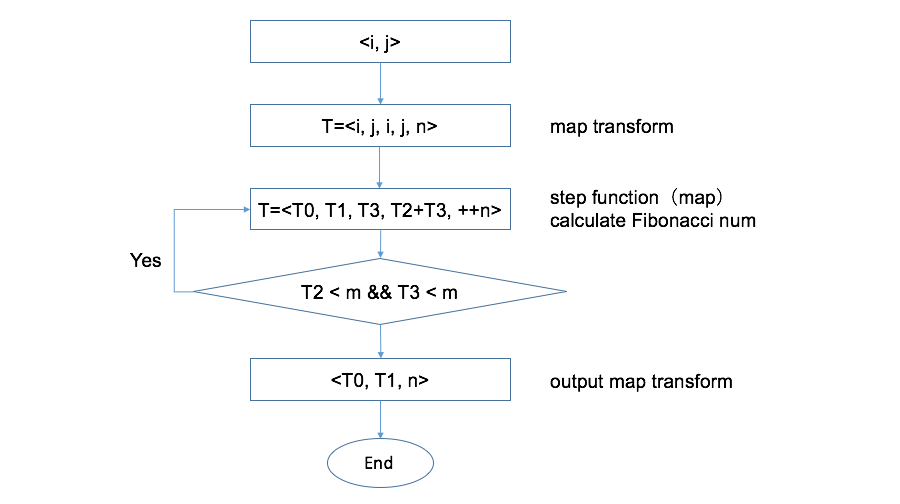
nБэЪОЕќДњДЮЪ§ЃЌдкзюГѕЕФmapзЊЛЛжаГѕЪМЛЏЮЊ0ЃЛmЪЧХаЖЈЕќДњЭЃжЙЕФуажЕЃЛ
СэЭтЃЌTКѓУцИњЕФЪЧзжЖЮЫїв§ЃЌБШШчT2БэЪОШЁдЊзщжаЮЛжУЮЊ3ЕФзжЖЮЁЃЧвзЂвтЫцзХЕќДњTдкВЛЖЯБфЛЏЁЃ
ЩЯУцЮвУЧвбОЖдЮЪЬтЕФКЫаФЙ§ГЬНјааСЫЗжЮіЃЌНгЯТРДЮвУЧЛсЗжВННтОіетИіЮЪЬтЕФЙЙНЈЕќДњЕФСїДІРэГЬађЁЃ
ЪзЯШЃЌЮвУЧЯШЭЈЙ§sourceКЏЪ§ДДНЈГѕЪМЕФСїЖдЯѓinputStreamЃК
| DataStream<Tuple2<Integer,
Integer>> inputStream = env.addSource(new
RandomFibonacciSource()); |
ИУsourceКЏЪ§ЛсЩњГЩЖўдЊзщађСаЃЌЖўдЊзщЕФСНИізжЖЮжЕЪЧЫцЛњЩњГЩЕФзїЮЊьГВЈФЧЦѕЪ§СаЕФГѕЪМжЕЃК
private static
class RandomFibonacciSource
implements SourceFunction<Tuple2<Integer,
Integer>> {
private Random random = new Random();
private volatile boolean isRunning = true;
private int counter = 0;
public void run(SourceContext<Tuple2<Integer,
Integer>> ctx) throws Exception {
while (isRunning && counter < MAX_RANDOM_VALUE)
{
int first = random.nextInt(MAX_RANDOM_VALUE /
2 - 1) + 1;
int second = random.nextInt(MAX_RANDOM_VALUE /
2 -1) + 1;
if (first > second) continue;
ctx.collect(new Tuple2<Integer, Integer>(first,
second));
counter++;
Thread.sleep(50);
}
}
public void cancel() {
isRunning = false;
}
} |
ЮЊСЫЖдаТМЦЫуЕФьГВЈФЧЦѕЪ§СажаЕФжЕвдМАРлМгЕФЕќДњДЮЪ§НјааДцДЂЃЌЮвУЧашвЊНЋЖўдЊзщЪ§ОнСїзЊЛЛЮЊЮхдЊзщЪ§ОнСїЃЌВЂОнДЫДДНЈЕќДњЖдЯѓЃК
IterativeStream<Tuple5<Integer,
Integer, Integer, Integer, Integer>> iterativeStream
=
inputStream.map(new TupleTransformMapFunction()).iterate(5000); |
зЂвтЩЯУцДњТыЖЮжаiterate APIЕФВЮЪ§5000ЃЌВЛЪЧжИЕќДњ5000ДЮЃЌЖјЪЧЕШД§ЗДРЁЪфШыЕФзюДѓЪБМфМфИєЮЊ5УыЁЃСїБЛШЯЮЊЪЧЮоНчЕФЃЌЫљвдЮоЗЈЯёХњДІРэЕќДњФЧбљжИЖЈзюДѓЕќДњДЮЪ§ЁЃЕЋЫќдЪаэжИЖЈвЛИізюДѓЕШД§МфИєЃЌШчЙћдкИјЖЈЕФЪБМфМфИєРяУЛгадЊЫиЕНРДЃЌФЧУДНЋЛсжежЙЕќДњЁЃ
дЊзщзЊЛЛЕФmapКЏЪ§ЪЕЯжЃК
private static
class TupleTransformMapFunction extends RichMapFunction<Tuple2<Integer,
Integer>, Tuple5<Integer, Integer, Integer,
Integer, Integer>> {
public Tuple5<Integer, Integer, Integer, Integer,
Integer> map(
Tuple2<Integer, Integer> inputTuples) throws
Exception {
return new Tuple5<Integer, Integer, Integer,
Integer, Integer>(
inputTuples.f0,
inputTuples.f1,
inputTuples.f0,
inputTuples.f1,
0);
}
} |
ЩЯУцЮхдЊзщжаЃЌЦфжаЫїв§ЮЊ0ЃЌ1етСНИіЮЛжУЕФдЊЫиЃЌЪМжеЖМЪЧзюГѕЩњГЩЕФСНИідЊЫиВЛЛсБфЛЏЃЌЖјКѓШ§ИізжЖЮЖМЛсЫцзХЕќДњЖјБфЛЏЁЃ
дкЕќДњСїiterativeStreamДДНЈЭъГЩжЎКѓЃЌЮвУЧНЋЛљгкЫќжДааьГВЈФЧЦѕЪ§СаЕФВНКЏЪ§ВЂВњЩњьГВЈФЧЦѕЪ§СаСїfibonacciStreamЃК
DataStream<Tuple5<Integer,
Integer, Integer, Integer, Integer>> fibonacciStream
=
iterativeStream.map(new FibonacciCalcStepFunction()); |
етРяЕФfibonacciStreamжЛЪЧвЛИіДњГЦЃЌЦфжаЕФЪ§ОнВЂВЛЪЧеце§ЕФьГВЈФЧЦѕЪ§СаЃЌЦфЪЕОЭЪЧЩЯУцФЧИіЮхдЊзщЁЃ
ЦфжагУгкМЦЫуьГВЈФЧЦѕЪ§СаЕФВНКЏЪ§ЪЕЯжШчЯТЃК
private static
class FibonacciCalcStepFunction extends
RichMapFunction<Tuple5<Integer, Integer,
Integer, Integer, Integer>,
Tuple5<Integer, Integer, Integer, Integer,
Integer>> {
public Tuple5<Integer, Integer, Integer, Integer,
Integer> map(
Tuple5<Integer, Integer, Integer, Integer,
Integer> inputTuple) throws Exception {
return new Tuple5<Integer, Integer, Integer,
Integer, Integer>(
inputTuple.f0,
inputTuple.f1,
inputTuple.f3,
inputTuple.f2 + inputTuple.f3,
++inputTuple.f4);
}
} |
е§ШчЩЯЮФЫљЪіЃЌКѓШ§ИізжЖЮЛсВњЩњБфЛЏЃЌдкМЦЫужЎЧАЃЌЪ§СазюКѓвЛИідЊЫиЛсБЛБЃСєЃЌвВОЭЪЧf3ЖдгІЕФдЊЫиЃЌШЛКѓЭЈЙ§f2дЊЫиМгЩЯf3дЊЫиЛсВњЩњзюаТжЕВЂИќаТf3дЊЫиЃЌЖјf4дђЛсРлМгЁЃ
ЫцзХЕќДњДЮЪ§діМгЃЌВЛЪЧећИіЪ§СаЖМЛсБЛБЃСєЃЌжЛгазюГѕЕФСНИідЊЫиКЭзюаТЕФСНИідЊЫиЛсБЛБЃСєЃЌетРявВУЛБивЊБЃСєећИіЪ§СаЃЌвђЮЊЮвУЧВЛашвЊЭъећЕФЪ§СаЃЌЮвУЧжЛашвЊЖдзюаТЕФСНИідЊЫиНјааХаЖЯМДПЩЁЃ
ЩЯЮФЮвУЧЖдУПИідЊЫиМЦЫуьГВЈФЧЦѕЪ§СаЕФаТжЕВЂВњЩњСЫfibonacciStreamЃЌЕЋЪЧЮвУЧашвЊЖдзюаТЕФСНИіжЕНјааХаЖЯЃЌПДЫќУЧЪЧЗёГЌЙ§СЫжИЖЈЕФуажЕЁЃГЌЙ§СЫуажЕЕФдЊзщНЋЛсБЛЪфГіЃЌЖјУЛгаГЌЙ§ЕФдђЛсдйДЮВЮгыЕќДњЁЃвђДЫетНЋВњЩњСНИіВЛЭЌЕФЗжжЇЃЌЮвУЧвВЮЊДЫЙЙНЈСЫЗжжЇСїЃК
SplitStream<Tuple5<Integer,
Integer, Integer, Integer, Integer>> branchedStream
=
fibonacciStream.split(new FibonacciOverflowSelector()) |
ЖјЖдЪЧЗёГЌЙ§уажЕЕФдЊзщНјааХаЖЯВЂЗжРыЕФЪЕЯжШчЯТЃК
private static
class FibonacciOverflowSelector implements OutputSelector<
Tuple5<Integer, Integer, Integer, Integer,
Integer>> {
public Iterable<String> select(
Tuple5<Integer, Integer, Integer, Integer,
Integer> inputTuple) {
if (inputTuple.f2 < OVERFLOW_THRESHOLD &&
inputTuple.f3 < OVERFLOW_THRESHOLD) {
return Collections.singleton(ITERATE_FLAG);
}
return Collections.singleton(OUTPUT_FLAG);
}
} |
дкЩИбЁЗНЗЈselectжаЃЌЮвУЧЖдВЛЭЌЕФЗжжЇвдВЛЭЌЕФГЃСПБъЪЖЗћНјааБъЪЖЃКITERATE_FLAGЃЈЛЙвЊМЬајЕќДњЃЉКЭOUTPUT_FLAGЃЈжБНгЪфГіЃЉЁЃ
ВњЩњСЫЗжжЇСїжЎКѓЃЌЮвУЧОЭПЩвдДгжаМьГіВЛЭЌЕФСїЗжжЇзіЕќДњЛђепЪфГіДІРэЁЃЖдашвЊдйДЮЕќДњЕФЃЌОЭЭЈЙ§ЕќДњСїЕФcloseWithЗНЗЈЗДРЁИјЕќДњЭЗЃК
iterativeStream.closeWith(branchedStream.select
(ITERATE_FLAG)); |
ЖјЖдгкВЛашвЊЕФЕќДњОЭжБНгШУЦфСїЯђЯТгЮДІРэЃЌетРяЮвУЧжЛЪЧМђЕЅЕУНЋСїЁАжиЙЙЁБСЫвЛЯТШЛКѓжБНгЪфГіЃК
DataStream<Tuple3<Integer,
Integer, Integer>> outputStream = branchedStream
.select(OUTPUT_FLAG).map(new BuildOutputTupleMapFunction());
outputStream.print(); |
ЫљЮНЕФжиЙЙОЭЪЧНЋжЎЧАЕФЮхдЊзщжиаТЫѕМѕЮЊШ§дЊзщЃЌЪЕЯжШчЯТЃК
private static
class BuildOutputTupleMapFunction extends RichMapFunction<
Tuple5<Integer, Integer, Integer, Integer,
Integer>,
Tuple3<Integer, Integer, Integer>> {
public Tuple3<Integer, Integer, Integer>
map(Tuple5<Integer, Integer, Integer, Integer,
Integer> inputTuple) throws Exception {
return new Tuple3<Integer, Integer, Integer>(
inputTuple.f0,
inputTuple.f1,
inputTuple.f4);
}
} |
зюжеЮвУЧНЋЛсЕУЕНРрЫЦШчЯТЕФЪфГіЃК
(7,14,5)
(18,37,3)
(3,46,3)
(23,32,3)
(31,43,2)
(13,45,2)
(37,42,2)
ЁЁ
ЧАСНИіећЪ§ЪЧьГВЈФЧЦѕЪ§СаЕФСНИіГѕЪМжЕЃЌЕкШ§ИіећЪ§БэЪОЦфашвЊОРњЖрЩйДЮЕќДњЦфьГВЈФЧЦѕЪ§СазюаТЕФСНИіжЕВХЛсГЌЙ§уажЕЁЃ
зюжеЭъећЕФжїИЩГЬађДњТыШчЯТЃК
public static
void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment().setBufferTimeout(1);
DataStream<Tuple2<Integer, Integer>>
inputStream = env.addSource(new RandomFibonacciSource());
IterativeStream<Tuple5<Integer, Integer,
Integer, Integer, Integer>> iterativeStream
=
inputStream.map(new TupleTransformMapFunction()).iterate
(5000);
DataStream<Tuple5<Integer, Integer,
Integer,
Integer, Integer>> fibonacciStream =
iterativeStream.map(new FibonacciCalcStepFunction());
SplitStream<Tuple5<Integer, Integer, Integer,
Integer, Integer>> branchedStream =
fibonacciStream.split(new FibonacciOverflowSelector());
iterativeStream.closeWith(branchedStream.select
(ITERATE_FLAG));
DataStream<Tuple3<Integer, Integer, Integer>>
outputStream = branchedStream
.select(OUTPUT_FLAG).map(
new BuildOutputTupleMapFunction());
outputStream.print();
env.execute("Streaming Iteration Example");
} |
|









