| БрМЭЦМі: |
| БОЮФРДздгкИіШЫВЉПЭЃЌБОЮФМђЕЅНщЩмСЫHBaseЩшМЦФЃаЭЃЌЮяРэДцДЂФЃаЭвдМАДцДЂМмЙЙЃЌЯЃЭћЖдФњЕФбЇЯАгаАяжњЁЃ |
|
вЛЁЂЪВУДЪЧHBase
HBaseЪЧвЛИіИпПЩППЁЂИпадФмЁЂУцЯђСаЁЂПЩЩьЫѕЕФЗжВМЪНДцДЂЯЕЭГЃЌРћгУHBaseММЪѕПЩдкСЎМлЕФPC ServerЩЯДюНЈДѓЙцФЃНсЙЙЛЏДцДЂМЏШКЁЃ
HBaseЪЧGoogle BigTableЕФПЊдДЪЕЯжЃЌгыGoogle BigTableРћгУGFSзїЮЊЦфЮФМўДцДЂЯЕЭГРрЫЦЃЌHBaseРћгУHadoop
HDFSзїЮЊЦфЮФМўДцДЂЯЕЭГЃЛ
GoogleдЫааMapReduceРДДІРэBigTableжаЕФКЃСПЪ§ОнЃЌHBaseЭЌбљРћгУHadoop
MapReduceРДДІРэHBaseжаЕФКЃСПЪ§ОнЃЛ
Google BigTableРћгУChubbyзїЮЊаЭЌЗўЮёЃЌHBaseРћгУZookeeperзїЮЊаЭЌЗўЮёЁЃ
ЖўЁЂHBaseЩшМЦФЃаЭ
HBaseжаЕФУПвЛеХБэОЭЪЧЫљЮНЕФBigTableЁЃBigTableЛсДцДЂвЛЯЕСаЕФааМЧТМЃЌааМЧТМгаШ§ИіЛљБОРраЭЕФЖЈвхЃК
1.RowKey
ЪЧаадкBigTableжаЕФЮЈвЛБъЪЖЁЃ
2.TimeStampЃК
ЪЧУПвЛДЮЪ§ОнВйзїЖдгІЙиСЊЕФЪБМфДСЃЌПЩвдПДзїSVNЕФАцБОЁЃ
3.ColumnЃК
ЖЈвхЮЊ<family>:<label>ЃЌЭЈЙ§етСНВПЗжПЩвджИЖЈЮЈвЛЕФЪ§ОнЕФДцДЂСаЃЌfamilyЕФЖЈвхКЭаоИФашвЊЖдHBaseНјааРрЫЦгкDBЕФDDLВйзїЃЌ
ЖјlabelЃЌВЛашвЊЖЈвхжБНгПЩвдЪЙгУЃЌетвВЮЊЖЏЬЌЖЈжЦСаЬсЙЉСЫвЛжжЪжЖЮЁЃfamilyСэвЛИізїгУЬхЯждкЮяРэДцДЂгХЛЏЖСаДВйзїЩЯЃЌЭЌfamily
ЕФЪ§ОнЮяРэЩЯБЃДцЕФЛсБШНЯНгНќЃЌвђДЫдквЕЮёЩшМЦЕФЙ§ГЬжаПЩвдРћгУетИіЬиадЁЃ
1. ТпМДцДЂФЃаЭ
HBaseвдБэЕФаЮЪНДцДЂЪ§ОнЃЌБэгЩааКЭСазщГЩЁЃСаЛЎЗжЮЊШєИЩИіСаДиЃЌШчЯТЭМЫљЪОЃК

ЯТУцЪЧЖдБэжадЊЫиЕФЯъЯИНтЮіЃК
RowKey
гыNoSQLЪ§ОнПтвЛбљЃЌrowkeyЪЧгУРДМьЫїМЧТМЕФжїМќЁЃЗУЮЪHBase
TableжаЕФааЃЌжЛгаШ§жжЗНЪНЃК
1.ЭЈЙ§ЕЅИіrowkeyЗУЮЪ
2.ЭЈЙ§rowkeyЕФrange
3.ШЋБэЩЈУш
rowkeyааМќПЩвдШЮвтзжЗћДЎЃЈзюДѓГЄЖШ64KBЃЌЪЕМЪгІгУжаГЄЖШвЛАуЮЊ10-100bytesЃЉЃЌдкHBaseФкВПRowKeyБЃДцЮЊзжНкЪ§зщЁЃ
ДцДЂЪБЃЌЪ§ОнАДееRowKeyЕФзжЕфађЃЈbyte orderЃЉХХађДцДЂЃЌЩшМЦkeyЪБЃЌвЊГфЗжСЫНтетИіЬиадЃЌНЋОГЃвЛЦ№ЖСШЁЕФааДцЗХдквЛЦ№ЁЃ
ашвЊзЂвтЕФЪЧЃКааЕФвЛДЮЖСаДЪЧдзгВйзїЃЈВЛТлвЛДЮЖСаДЖрЩйСаЃЉ
СаДи
HBaseБэжаЕФУПИіСаЃЌЖМЙщЪєгкФГИіСаДиЃЌСаДиЪЧБэЕФschemaЕФвЛВПЗжЃЈЖјСаВЛЪЧЃЉЃЌБиаыдкЪЙгУБэжЎЧАЖЈвхЁЃСаУћЖМвдСаДизїЮЊЧАзКЁЃР§ШчЃК
courses:history, courses:math ЖМЪєгк courses етИіСаДиЁЃ
ЗУЮЪПижЦЃЌДХХЬКЭФкДцЕФЪЙгУЭГМЦЖМЪЧдкСаДиВуУцНјааЕФЁЃ
ЪЕМЪгІгУжаЃЌСаДиЩЯЕФПижЦШЈЯоФмАяжњЮвУЧЙмРэВЛЭЌРраЭЕФгІгУЃКЮвУЧдЪаэвЛаЉгІгУПЩвдЬэМгаТЕФЛљБОЪ§ОнЁЂ
вЛаЉгІгУПЩвдЖСШЁЛљБОЪ§ОнВЂДДНЈМЬГаЕФСаДиЁЂвЛаЉгІгУдђжЛдЪаэфЏРРЪ§ОнЃЈЩшжУПЩФмвђЮЊвўЫНЕФдвђВЛФмфЏРРЫљгаЪ§ОнЃЉЁЃ
ЪБМфДС
HBaseжаЭЈЙ§rowКЭcolumnsШЗЖЈЕФЮЊвЛИіДцДЂЕЅдЊГЦЮЊcellЁЃУПИіcellЖМБЃДцзХЭЌвЛЗнЪ§ОнЕФЖрИіАцБОЁЃАцБОЭЈЙ§ЪБМфДСРДЫїв§ЁЃ
ЪБМфДСЕФРраЭЪЧ64ЮЛећаЭЁЃЪБМфДСПЩвдгЩHBaseдкаДШыЪБздЖЏИГжЕЃЌДЫЪБЪБМфДСЪЧОЋШЗЕНКСУыЕФЕБЧАЯЕЭГЪБМфЁЃЪБМфДСвВПЩвдгЩПЭЛЇЯдЪОИГжЕЁЃ
ШчЙћгІгУГЬађвЊБмУтЪ§ОнАцБОГхЭЛЃЌОЭБиаыздМКЩњГЩОпгаЮЈвЛадЕФЪБМфДСЁЃУПИіcellжадкВЛЭЌАцБОЕФЪ§ОнАДееЪБМфЕЙађХХађЃЌМДзюаТЕФЪ§ОнХХдкзюЧАУцЁЃ
ЮЊСЫБмУтЪ§ОнДцдкЙ§ЖрЕФАцБОдьГЩЕФЙмРэИКЕЃЃЌHBaseЬсЙЉСЫСНжжЪ§ОнАцБОЛиЪеЗНЪНЁЃвЛЪЧБЃДцЪ§ОнЕФзюКѓnИіАцБОЃЌЖўЪЧБЃДцзюНќвЛЖЮЪБМфФкЕФАцБО
ЃЈБШШчзюНќЦпЬьЃЉЁЃгУЛЇПЩвдеыЖдУПИіСаДиНјааЩшжУЁЃ
Cell
гЩ{row key, column(=+), version} ЮЈвЛШЗЖЈЕФЕЅдЊЁЃcellжаЕФЪ§ОнЪЧУЛгаРраЭЕФЃЌШЋВПЪЧзжНкТыаЮЪНДцДЂЁЃ
2. ЮяРэДцДЂФЃаЭ
TableдкааЕФЗНЯђЩЯЗжИюЮЊЖрИіHRegionЃЌУПИіHRegionЗжЩЂдкВЛЭЌЕФRegionServerжаЁЃ
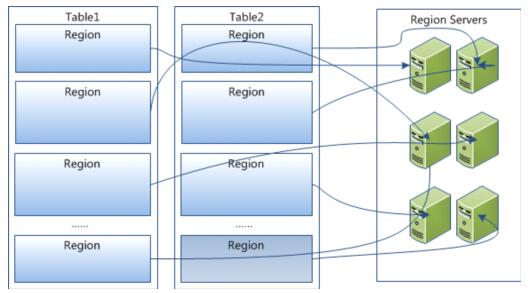
УПИіHRegionгЩЖрИіStoreЙЙГЩЃЌУПИіStoreгЩвЛИіMemStoreКЭ0ЛђЖрИіStoreFileзщГЩЃЌУПИіStoreБЃДцвЛИіColumns
Family 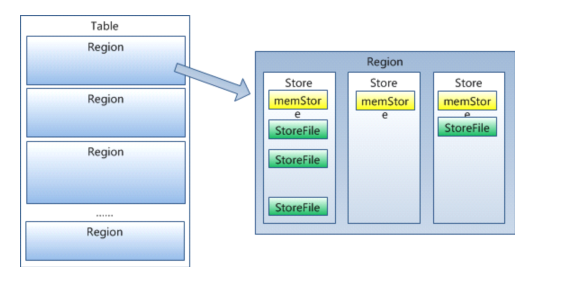
StoreFileвдHFileИёЪНДцДЂдкHDFSжаЁЃ
Ш§ЁЂHBaseДцДЂМмЙЙ
ДгHBaseЕФМмЙЙЭМЩЯПЩвдПДГіЃЌHBaseжаЕФДцДЂАќРЈHMasterЁЂHRegionSeverЁЂHRegionЁЂHLogЁЂStoreЁЂMemStoreЁЂStoreFileЁЂHFileЕШЃЌвдЯТЪЧHBaseДцДЂМмЙЙЭМЃК
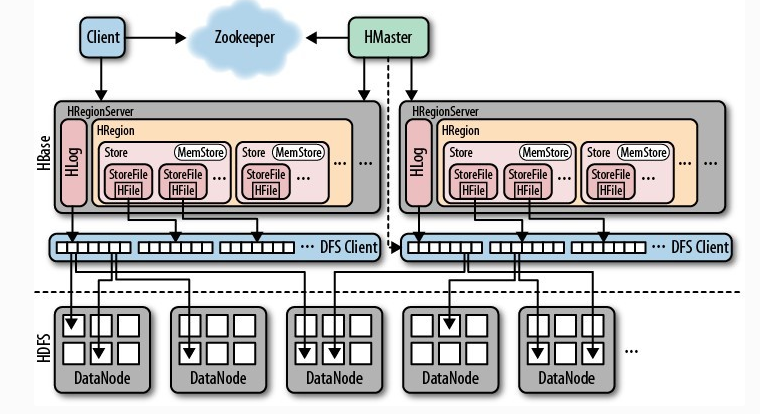
HBaseжаЕФУПеХБэЖМЭЈЙ§МќАДеевЛЖЈЕФЗЖЮЇБЛЗжИюГЩЖрИізгБэЃЈHRegionЃЉЃЌФЌШЯвЛИіHRegionГЌЙ§256MОЭвЊБЛЗжИюГЩСНИіЃЌетИіЙ§ГЬгЩHRegionServerЙмРэЃЌ
ЖјHRegionЕФЗжХфгЩHMasterЙмРэЁЃ
HMasterЕФзїгУЃК
1.ЮЊHRegionServerЗжХфHRegion
2.ИКд№HRegionServerЕФИКдиОљКт
3.ЗЂЯжЪЇаЇЕФHRegionServerВЂжиаТЗжХф
4.HDFSЩЯЕФРЌЛјЮФМўЛиЪе
5.ДІРэSchemaИќаТЧыЧѓ
HRegionServerЕФзїгУЃК
1.ЮЌЛЄHMasterЗжХфИјЫќЕФHRegionЃЌДІРэЖдетаЉHRegionЕФIOЧыЧѓ
2.ИКд№ЧаЗже§дкдЫааЙ§ГЬжаБфЕУЙ§ДѓЕФHRegion
ПЩвдПДЕНЃЌClientЗУЮЪHBaseЩЯЕФЪ§ОнВЂВЛашвЊHMasterВЮгыЃЌбАжЗЗУЮЪZooKeeperКЭHRegionServerЃЌЪ§ОнЖСаДЗУЮЪHRegionServerЃЌ
HMasterНіНіЮЌЛЄTableКЭRegionЕФдЊЪ§ОнаХЯЂЃЌTableЕФдЊЪ§ОнаХЯЂБЃДцдкZooKeeperЩЯЃЌИКдиКмЕЭЁЃHRegionServerДцШЁвЛИізгБэЪБЃЌ
ЛсДДНЈвЛИіHRegionЖдЯѓЃЌШЛКѓЖдБэЕФУПИіСаДиДДНЈвЛИіStoreЖдЯѓЃЌУПИіStoreЖМЛсгавЛИіMemStoreКЭ0ЛђЖрИіStoreFileгыжЎЖдгІЃЌ
УПИіStoreFileЖМЛсЖдгІвЛИіHFileЃЌHFileОЭЪЧЪЕМЪЕФДцДЂЮФМўЁЃвђДЫЃЌвЛИіHRegionгаЖрЩйСаДиОЭгаЖрЩйИіStoreЁЃ
вЛИіHRegionServerЛсгаЖрИіHRegionКЭвЛИіHLogЁЃ
HRegion
TableдкааЕФЗНЯђЩЯЗжИюЮЊЖрИіHRegionЃЌHRegionЪЧHBaseжаЗжВМЪНДцДЂКЭИКдиОљКтЕФзюаЁЕЅдЊЃЌМДВЛЭЌЕФHRegionПЩвдЗжБ№дкВЛЭЌЕФHRegionServerЩЯЃЌ
ЕЋЭЌвЛИіHRegionЪЧВЛЛсВ№ЗжЕНЖрИіHRegionServerЩЯЕФЁЃHRegionАДДѓаЁЗжИюЃЌУПИіБэвЛАужЛгавЛИіHRegionЃЌЫцзХЪ§ОнВЛЖЯВхШыБэЃЌHRegionВЛЖЯдіДѓЃЌ
ЕБHRegionЕФФГИіСаДиДяЕНвЛИіЗЇжЕЃЈФЌШЯ256MЃЉЪБОЭЛсЗжГЩСНИіаТЕФHRegionЁЃ
1ЁЂ<БэУћЃЌStartRowKey, ДДНЈЪБМф>
2ЁЂгЩФПТМБэ(-ROOT-КЭ.META.)МЧТМИУRegionЕФEndRowKey
HRegionЖЈЮЛЃКHRegionБЛЗжХфИјФФИіHRegionServerЪЧЭъШЋЖЏЬЌЕФЃЌЫљвдашвЊЛњжЦРДЖЈЮЛHRegionОпЬхдкФФИіHRegionServerЃЌHBaseЪЙгУШ§ВуНсЙЙРДЖЈЮЛHRegionЃК
1ЁЂЭЈЙ§zkРяЕФЮФМў/hbase/rsЕУЕН-ROOT-БэЕФЮЛжУЁЃ-ROOT-БэжЛгавЛИіregionЁЃ
2ЁЂЭЈЙ§-ROOT-БэВщев.META.БэЕФЕквЛИіБэжаЯргІЕФHRegionЮЛжУЁЃЦфЪЕ-ROOT-БэЪЧ.META.БэЕФЕквЛИіregionЃЛ
.META.БэжаЕФУПвЛИіRegionдк-ROOT-БэжаЖМЪЧвЛааМЧТМЁЃ
3ЁЂЭЈЙ§.META.БэевЕНЫљвЊЕФгУЛЇБэHRegionЕФЮЛжУЁЃгУЛЇБэЕФУПИіHRegionдк.META.БэжаЖМЪЧвЛааМЧТМЁЃ
-ROOT-БэгРдЖВЛЛсБЛЗжИєЮЊЖрИіHRegionЃЌБЃжЄСЫзюЖрашвЊШ§ДЮЬјзЊЃЌОЭФмЖЈЮЛЕНШЮвтЕФregionЁЃClientЛсНЋВщбЏЕФЮЛжУаХЯЂБЃДцЛКДцЦ№РДЃЌЛКДцВЛЛсжїЖЏЪЇаЇЃЌ
вђДЫШчЙћClientЩЯЕФЛКДцШЋВПЪЇаЇЃЌдђашвЊНјаа6ДЮЭјТчРДЛиЃЌВХФмЖЈЮЛЕНе§ШЗЕФHRegionЃЌЦфжаШ§ДЮгУРДЗЂЯжЛКДцЪЇаЇЃЌСэЭтШ§ДЮгУРДЛёШЁЮЛжУаХЯЂЁЃ
Store
УПвЛИіHRegionгЩвЛИіЛђЖрИіStoreзщГЩЃЌжСЩйЪЧвЛИіStoreЃЌHBaseЛсАбвЛЦ№ЗУЮЪЕФЪ§ОнЗХдквЛИіStoreРяУцЃЌМДЮЊУПИіColumnFamilyНЈвЛИіStoreЃЌ
ШчЙћгаМИИіColumnFamilyЃЌвВОЭгаМИИіStoreЁЃвЛИіStoreгЩвЛИіMemStoreКЭ0ЛђепЖрИіStoreFileзщГЩЁЃ
HBaseвдStoreЕФДѓаЁРДХаЖЯЪЧЗёашвЊЧаЗжHRegionЁЃ
MemStore
MemStore ЪЧЗХдкФкДцРяЕФЃЌБЃДцаоИФЕФЪ§ОнМДkeyValuesЁЃЕБMemStoreЕФДѓаЁДяЕНвЛИіЗЇжЕЃЈФЌШЯ64MBЃЉЪБЃЌMemStoreЛсБЛFlushЕНЮФМўЃЌ
МДЩњГЩвЛИіПьееЁЃФПЧАHBaseЛсгавЛИіЯпГЬРДИКд№MemStoreЕФFlushВйзїЁЃ
StoreFile
MemStoreФкДцжаЕФЪ§ОнаДЕНЮФМўКѓОЭЪЧStoreFileЃЌStoreFileЕзВуЪЧвдHFileЕФИёЪНБЃДцЁЃ
HFile
HBaseжаKeyValueЪ§ОнЕФДцДЂИёЪНЃЌЪЧHadoopЕФЖўНјжЦИёЪНЮФМўЁЃ
ЪзЯШHFileЮФМўЪЧВЛЖЈГЄЕФЃЌГЄЖШЙЬЖЈЕФжЛгаЦфжаЕФСНПщЃКTrailerКЭFileInfoЁЃ
TrailerжагажИеыжИЯђЦфЫћЪ§ОнПщЕФЦ№ЪМЕуЃЌFileInfoМЧТМСЫЮФМўЕФвЛаЉmetaаХЯЂЁЃData
BlockЪЧHBase IOЕФЛљБОЕЅдЊЃЌЮЊСЫЬсИпаЇТЪЃЌ
HRegionServerжагаЛљгкLRUЕФBlock CacheЛњжЦЁЃУПИіDataПщЕФДѓаЁПЩвддкДДНЈвЛИіTableЕФЪБКђЭЈЙ§ВЮЪ§жИЖЈЃЈФЌШЯПщДѓаЁ64KBЃЉЃЌ
ДѓКХЕФBlockгаРћгкЫГађScanЃЌаЁКХЕФBlockРћгкЫцЛњВщбЏЁЃУПИіDataПщГ§СЫПЊЭЗЕФMagicвдЭтОЭЪЧвЛИіИіKeyValueЖдЦДНгЖјГЩЃЌ
MagicФкШнОЭЪЧвЛаЉЫцЛњЪ§зжЃЌФПЕФЪЧЗРжЙЪ§ОнЫ№ЛЕЃЌНсЙЙШчЯТЁЃ

HFileНсЙЙЭМШчЯТЃК
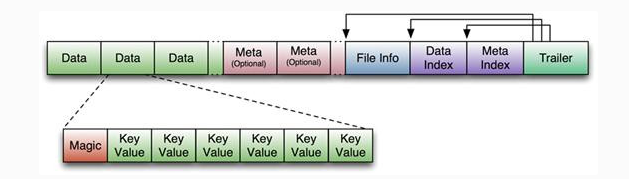
Data BlockЖЮгУРДБЃДцБэжаЕФЪ§ОнЃЌетВПЗжПЩвдБЛбЙЫѕЁЃ Meta BlockЖЮЃЈПЩбЁЕФЃЉгУРДБЃДцгУЛЇздЖЈвхЕФkvЖЮЃЌПЩвдБЛбЙЫѕЁЃ
FileInfoЖЮгУРДБЃДцHFileЕФдЊаХЯЂЃЌВЛФмБЛбЙЫѕЃЌгУЛЇвВПЩвддкетвЛВПЗжЬэМгздМКЕФдЊаХЯЂЁЃ Data
Block IndexЖЮЃЈПЩбЁЕФЃЉгУРДБЃДцMeta BlcokЕФЫїв§ЁЃ TrailerетвЛЖЮЪЧЖЈГЄЕФЁЃБЃДцСЫУПвЛЖЮЕФЦЋвЦСПЃЌЖСШЁвЛИіHFileЪБЃЌЛсЪзЯШЖСШЁTrailerЃЌTrailerБЃДцСЫУПИіЖЮЕФЦ№ЪМЮЛжУ(ЖЮЕФMagic
NumberгУРДзіАВШЋcheck)ЃЌШЛКѓЃЌDataBlock IndexЛсБЛЖСШЁЕНФкДцжаЃЌетбљЃЌЕБМьЫїФГИіkeyЪБЃЌВЛашвЊЩЈУшећИіHFileЃЌЖјжЛашДгФкДцжаевЕНkeyЫљдкЕФblockЃЌЭЈЙ§вЛДЮДХХЬioНЋећИі
blockЖСШЁЕНФкДцжаЃЌдйевЕНашвЊЕФkeyЁЃDataBlock IndexВЩгУLRUЛњжЦЬдЬЁЃ HFileЕФData
BlockЃЌMeta BlockЭЈГЃВЩгУбЙЫѕЗНЪНДцДЂЃЌбЙЫѕжЎКѓПЩвдДѓДѓМѕЩйЭјТчIOКЭДХХЬIOЃЌЫцжЎЖјРДЕФПЊЯњЕБШЛЪЧашвЊЛЈЗбcpuНјаабЙЫѕКЭНтбЙЫѕЁЃЃЈБИзЂЃК
DataBlock IndexЕФШБЯнЁЃ a) еМгУЙ§ЖрФкДцЁЁb) ЦєЖЏМгдиЪБМфЛКТ§ЃЉ
HLog
ЁЁЁЁHLog(WAL log)ЃКWALвтЮЊwrite ahead logЃЌгУРДзіджФбЛжИДЪЙгУЃЌHLogМЧТМЪ§ОнЕФЫљгаБфИќЃЌвЛЕЉregion
server хДЛњЃЌОЭПЩвдДгlogжаНјааЛжИДЁЃ
LogFlusher
ЁЁЁЁЖЈЦкЕФНЋЛКДцжааХЯЂаДШыЕНШежОЮФМўжа
LogRollerЁЁ
ЁЁ ЁЁЖдШежОЮФМўНјааЙмРэЮЌЛЄ
|









