| БрМЭЦМі: |
БОЮФРДздгк36ДѓЪ§ОнЃЌHBaseЪЧвЛжжHadoopЪ§ОнПтЃЌЪЧвЛИіПЩвдЫцЛњЗУЮЪЕФДцДЂКЭМьЫїЪ§ОнЕФЦНЬЈ
|
|
вЛЁЂHBaseНщЩм 1ЁЂЛљБОИХФю HBaseЪЧвЛжжHadoopЪ§ОнПтЃЌОГЃБЛУшЪіЮЊвЛжжЯЁЪшЕФЃЌЗжВМЪНЕФЃЌГжОУЛЏЕФЃЌЖрЮЌгаађгГЩфЃЌЫќЛљгкааМќЁЂСаМќКЭЪБМфДСНЈСЂЫїв§ЃЌЪЧвЛИіПЩвдЫцЛњЗУЮЪЕФДцДЂКЭМьЫїЪ§ОнЕФЦНЬЈЁЃHBaseВЛЯожЦДцДЂЕФЪ§ОнЕФжжРрЃЌдЪаэЖЏЬЌЕФЁЂСщЛюЕФЪ§ОнФЃаЭЃЌВЛгУSQLгябдЃЌвВВЛЧПЕїЪ§ОнжЎМфЕФЙиЯЕЁЃHBaseБЛЩшМЦГЩдквЛИіЗўЮёЦїМЏШКЩЯдЫааЃЌПЩвдЯргІЕиКсЯђРЉеЙЁЃ 2ЁЂHBaseЪЙгУГЁОАКЭГЩЙІАИР§ ЛЅСЊЭјЫбЫїЮЪЬтЃКХРГцЪеМЏЭјвГЃЌДцДЂЕНBigTableРяЃЌMapReduceМЦЫузївЕЩЈУшШЋБэЩњГЩЫбЫїЫїв§ЃЌДгBigTableжаВщбЏЫбЫїНсЙћЃЌеЙЪОИјгУЛЇЁЃ зЅШЁдіСПЪ§ОнЃКР§ШчЃЌзЅШЁМрПижИБъЃЌзЅШЁгУЛЇНЛЛЅЪ§ОнЃЌвЃВтММЪѕЃЌЖЈЯђЭЖЗХЙуИцЕШ ФкШнЗўЮё аХЯЂНЛЛЅ 3ЁЂHBase ShellУќСюааНЛЛЅЃК ЦєЖЏShell $ hbase shell СаГіЫљгаЕФБэ hbase > list
ДДНЈУћЮЊmytableЕФБэЃЌКЌгавЛИіСазхhb hbase >
create ' mytable' , 'hb'
дкЁЎmytableЁЏБэЕФ'first'аажаЕФЁЎhb:dataЁЏСаЖдгІЕФЪ§ОнЕЅдЊжаВхШызжНкЪ§зщЁЎhello
HBaseЁЏ
hbase > put 'mytable' , 'first'
, 'hb:data' , 'hello HBase'
ЖСШЁmytableБэ ЁЎfirstЁЏааЕФФкШн hbase > get 'mytable' ,
'first' ЖСШЁmytableБэЫљгаЕФФкШн hbase > scan ЁЎmytable' ЖўЁЂШыУХ 1ЁЂAPI КЭЪ§ОнВйзїгаЙиЕФHBase APIга5ИіЃЌЗжБ№ЪЧ Get(ЖС)ЃЌPut(аД)ЃЌDelete(ЩО)ЃЌScan(ЩЈУш)КЭIncrement(СажЕЕнді) 2ЁЂВйзїБэ ЪзЯШвЊДДНЈвЛИіconfigurationЖдЯѓ Configuration conf = HBaseConfiguration.create(); ЪЙгУeclipseЪБЕФЛАЛЙБиаыНЋХфжУЮФМўЬэМгНјРДЁЃ conf.addResource (new Path("E:\\share\\hbase-site.xml"));
conf.addResource (new Path("E:\\share\\core-site.xml"));
conf.addResource (new Path("E:\\share\\hdfs-site.xml"));
ЪЙгУСЌНгГиДДНЈвЛеХБэЁЃ HTablePool pool = new HTablePool(conf,1);
HTableInterface usersTable = pool.getTable("users");
3ЁЂаДВйзї гУРДДцДЂЪ§ОнЕФУќСюЪЧputЃЌЭљБэРяДцДЂЪ§ОнЃЌашвЊДДНЈPutЪЕР§ЁЃВЂжЦЖЈвЊМгШыЕФаа
Put put = new Put(byte[] row) ;
PutЕФaddЗНЗЈгУРДЬэМгЪ§ОнЃЌЗжБ№ЩшЖЈСазхЃЌЯоЖЈЗћвдМАЕЅдЊИёЕФжИ put.add (byte[] family , byte[] qualifier , byte[]
value) ; зюКѓЬсНЛУќСюИјБэ usersTable.put(put); usersTable.close(); аоИФЪ§ОнЃЌжЛашжиаТЬсНЛвЛДЮзюаТЕФЪ§ОнМДПЩЁЃ HBaseаДВйзїЕФЙЄзїЛњжЦЃК
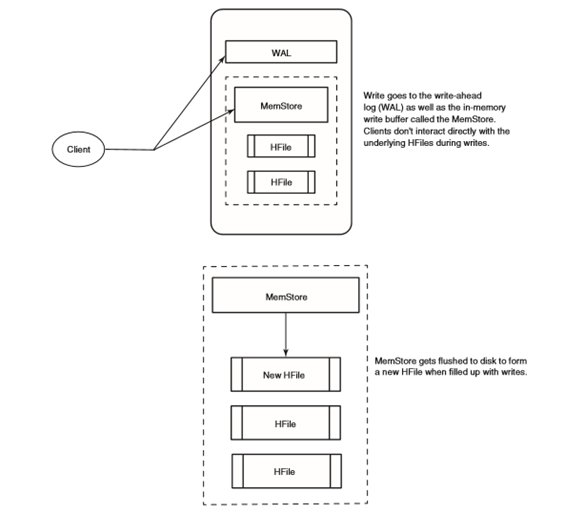
HBaseУПДЮжДаааДВйзїЖМЛсаДШыСНИіЕиЗНЃКдЄаДЪНШежОЃЈwrite-ahead logЃЌвВГЦHLogЃЉКЭMemStoreЃЈаДШыЛКГхЧјЃЉЃЌвдБЃжЄЪ§ОнГжОУЛЏЃЌжЛгаЕБетСНИіЕиЗНЕФБфЛЏаХЯЂЖМаДШыВЂШЗШЯКѓЃЌВХШЯЮЊаДЖЏзїЭъГЩЁЃMemStoreЪЧФкДцРяЕФаДШыЛКГхЧјЃЌHBaseжаЪ§ОндкгРОУаДШыгВХЬжЎЧАдкетРяРлЛ§ЃЌЕБMemStoreЬюТњКѓЃЌЦфжаЕФЪ§ОнЛсЫЂаДЕНгВХЬЃЌЩњГЩвЛИіHFileЁЃ 4ЁЂЖСВйзї ДДНЈвЛИіGetУќСюЪЕР§ЃЌАќКЌвЊВщбЏЕФаа Get get = new Get(byte[] row) ; жДааaddColumn()ЛђaddFamily()ПЩвдЩшжУЯожЦЬѕМўЁЃ НЋgetЪЕР§ЬсНЛЕНБэЛсЗЕЛивЛИіАќКЌЪ§ОнЕФResultЪЕР§ЃЌЪЕР§жаАќКЌаажаЫљгаСазхЕФЫљгаСаЁЃ Result r = usersTable.get(get) ; ПЩвдЖдresultЪЕР§МьЫїЬиЖЈЕФжЕ byte[] b = r.getValue (byte[] family , byte[] qualifier)
; ЙЄзїЛњжЦЃК
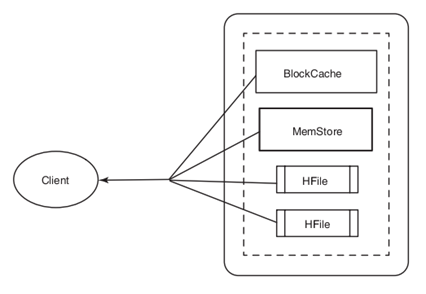
BlockCacheгУРДБЃДцДгHFileжаЖСШыФкДцЕФЦЕЗБЗУЮЪЕФЪ§ОнЃЌБмУтгВХЬЖСЃЌУПИіСазхЖМгаздМКЕФBlockCacheЁЃДгHBaseжаЖСГівЛааЃЌЪзЯШЛсМьВщMemStoreЕШД§аоИФЕФЖгСаЃЌШЛКѓМьВщBlockCacheПДАќКЌИУааЕФBlockЪЧЗёзюНќБЛЗУЮЪЙ§ЃЌзюКѓЗУЮЪгВХЬЩЯЕФЖдгІHFileЁЃ 5ЁЂЩОГ§Вйзї ДДНЈвЛИіDeleteЪЕР§ЃЌжИЖЈвЊЩОГ§ЕФааЁЃ Delete delete = new Delete(byte[] row) ; ПЩвдЭЈЙ§deleteFamily()КЭdeleteColumn()ЗНЗЈжИЖЈЩОГ§ааЕФвЛВПЗжЁЃ 6ЁЂБэЩЈУшВйзї Scan scan = new Scan() ПЩвджИЖЈЦ№ЪМааКЭНсЪјааЁЃ setStartRow() , setStopRow() , setFilter()ЗНЗЈПЩвдгУРДЯожЦЗЕЛиЕФЪ§ОнЁЃ addColumn()КЭaddFamily()ЗНЗЈЛЙПЩвджИЖЈСаКЭСазхЁЃ HBaseФЃЪНЕФЪ§ОнФЃаЭАќРЈЃК БэЃКHBaseгУБэРДзщжЏЪ§ОнЁЃ ааЃКдкБэРяЃЌЪ§ОнАДааДцДЂЃЌаагЩааМќЮЈвЛБъЪЖЁЃааМќУЛгаЪ§ОнРраЭЃЌЮЊзжНкЪ§зщbyte[]ЁЃ СазхЃКааРяЕФЪ§ОнАДееСазхЗжзщЃЌСазхБиаыЪТЯШЖЈвхВЂЧвВЛЧсвзаоИФЁЃБэжаУПаагЕгаЯрЭЌЕФСазхЁЃ СаЯоЖЈЗћЃКСазхРяЕФЪ§ОнЭЈЙ§СаЯоЖЈЗћЛђСаРДЖЈЮЛЃЌСаЯоЖЈЗћВЛБиЪТЯШЖЈвхЁЃ ЕЅдЊЃКДцДЂдкЕЅдЊРяЕФЪ§ОнГЦЮЊЕЅдЊжЕЃЌжЕЪЧзжНкЪ§зщЁЃЕЅдЊгЩааМќЃЌСазхЛђСаЯоЖЈЗћвЛЦ№ШЗЖЈЁЃ ЪБМфАцБОЃКЕЅдЊжЕгаЪБМфАцБОЃЌЪЧвЛИіlongРраЭЁЃ вЛИіHBaseЪ§ОнзјБъЕФР§згЃК
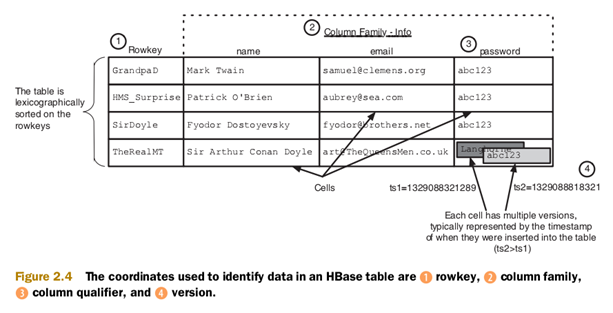
HBaseПЩвдПДзіЪЧвЛИіМќжЕЪ§ОнПтЁЃHBaseЕФЩшМЦЪЧУцЯђАыНсЙЙЛЏЪ§ОнЕФЃЌЪ§ОнМЧТМПЩФмАќКЌВЛвЛжТЕФСаЃЌВЛШЗЖЈДѓаЁЕШЁЃ Ш§ЁЂЗжВМЪНЕФHBaseЁЂHDFSКЭMapReduce 1ЁЂЗжВМЪНФЃЪНЕФHBase HBaseНЋБэЛсЧаЗжГЩаЁЕФЪ§ОнЕЅЮЛНаregionЃЌЗжХфЕНЖрЬЈЗўЮёЦїЁЃЭаЙмregionЕФЗўЮёЦїНазіRegionServerЁЃвЛАуЧщПіЯТЃЌRgionServerКЭHDFS
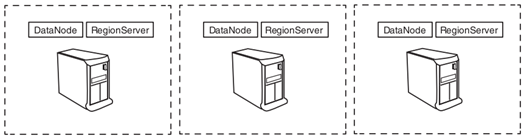
DataNodeВЂСаХфжУдкЭЌвЛЮяРэгВМўЩЯЃЌRegionServerБОжЪЩЯЪЧHDFSПЭЛЇЖЫЃЌдкЩЯУцДцДЂЗУЮЪЪ§ОнЃЌHMasterЗжХфregionИјRegionServer,УПИіRegionServerЭаЙмЖрИіregionЁЃ
HBaseжаЕФСНИіЬиЪтЕФБэЃЌ-ROOT-КЭ.META.ЃЌгУРДВщевИїжжБэЕФregionЮЛжУдкФФЁЃ-ROOT-жИЯђ.META.БэЕФregionЃЌ.META.БэжИЯђЭаЙмД§ВщевЕФregionЕФRegionServerЁЃ вЛДЮПЭЛЇЖЫВщевЙ§ГЬЕФ3ВуЗжВМЪНB+ЪїШчЯТЭМЃК 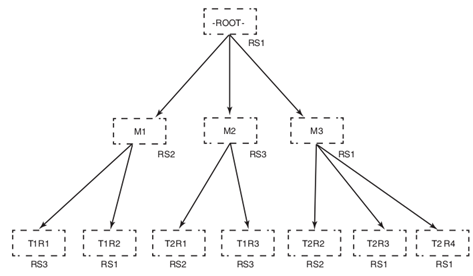
HBaseЖЅВуНсЙЙЭМЃК 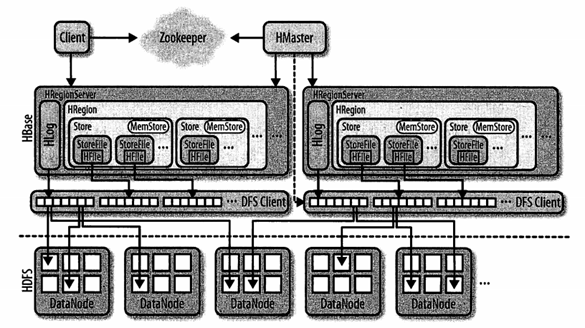
zookeeperИКд№ИњзйregionЗўЮёЦїЃЌБЃДцroot regionЕФЕижЗЁЃ ClientИКд№гыzookeeperзгМЏШКвдМАHRegionServerСЊЯЕЁЃ HMasterИКд№дкЦєЖЏHBaseЪБЃЌАбЫљгаЕФregionЗжХфЕНУПИіHRegion ServerЩЯЃЌвВАќРЈ-ROOT-КЭ.META.БэЁЃ HRegionServerИКд№ДђПЊregionЃЌВЂДДНЈЖдгІЕФHRegionЪЕР§ЁЃHRegionБЛДђПЊКѓЃЌЫќЮЊУПИіБэЕФHColumnFamilyДДНЈвЛИіStoreЪЕР§ЁЃУПИіStoreЪЕР§АќКЌвЛИіЛђЖрИіStoreFileЪЕР§ЃЌЫќУЧЪЧЪЕМЪЪ§ОнДцДЂЮФМўHFileЕФЧсСПМЖЗтзАЁЃУПИіStoreгаЦфЖдгІЕФвЛИіMemStoreЃЌвЛИіHRegionServerЙВЯэвЛИіHLogЪЕР§ЁЃ вЛДЮЛљБОЕФСїГЬЃК aЁЂ ПЭЛЇЖЫЭЈЙ§zookeeperЛёШЁКЌга-ROOT-ЕФregionЗўЮёЦїУћЁЃ bЁЂ ЭЈЙ§КЌга-ROOT-ЕФregionЗўЮёЦїВщбЏКЌга.META.БэжаЖдгІЕФregionЗўЮёЦїУћЁЃ cЁЂ ВщбЏ.META.ЗўЮёЦїЛёШЁПЭЛЇЖЫВщбЏЕФааМќЪ§ОнЫљдкЕФregionЗўЮёЦїУћЁЃ dЁЂ ЭЈЙ§ааМќЪ§ОнЫљдкЕФregionЗўЮёЦїЛёШЁЪ§ОнЁЃ HFileНсЙЙЭМЃК 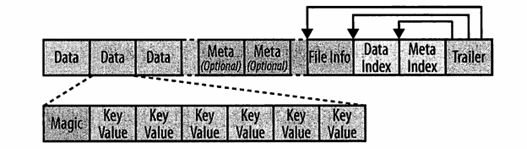
TrailerгажИЯђЦфЫћПщЕФжИеыЃЌIndexПщМЧТМDataКЭMetaПщЕФЦЋвЦСПЃЌDataКЭMetaПщДцДЂЪ§ОнЁЃФЌШЯДѓаЁЪЧ64KBЁЃУПИіПщАќКЌвЛИіMagicЭЗВПКЭвЛЖЈЪ§СПЕФађСаЛЏЕФKeyValueЪЕР§ЁЃ KeyValueИёЪНЃК 
ИУНсЙЙвдСНИіЗжБ№БэЪОМќГЄЖШКЭжЕГЄЖШЕФЖЈГЄЪ§зжПЊЪМЃЌМќАќКЌСЫааМќЃЌСазхУћКЭСаЯоЖЈЗћЃЌЪБМфДСЕШЁЃ дЄаДШежОWALЃК УПДЮИќаТЖМЛсаДШыШежОЃЌжЛгааДШыГЩЙІВХЛсЭЈжЊПЭЛЇЖЫВйзїГЩЙІЃЌШЛКѓЗўЮёЦїПЩвдАДашздгЩЕиХњСПДІРэЛђОлКЯФкДцжаЕФЪ§ОнЁЃ БрМСїдкmemstoreКЭWALжЎМфЗжСїЕФЙ§ГЬЃК
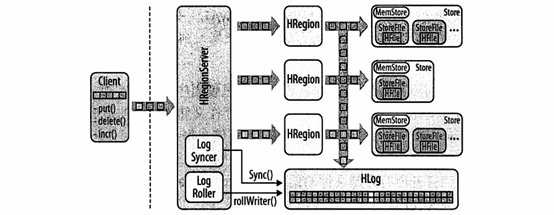
ДІРэЙ§ГЬЃКПЭЛЇЖЫЭЈЙ§RPCЕїгУНЋKeyValueЖдЯѓЪЕР§ЗЂЫЭЕНКЌгаЦЅХфregionЕФHRegionServerЁЃНгзХетаЉЪЕР§БЛЗЂЫЭЕНЙмРэЯргІааЕФHRegionЪЕР§ЃЌЪ§ОнБЛаДШыЕНWALЃЌШЛКѓБЛЗХШыЕНЪЕМЪгЕгаМЧТМЕФДцДЂЮФМўЕФMemStoreжаЁЃЕБmemstoreжаЕФЪ§ОнДяЕНвЛЖЈЕФДѓаЁвдКѓЃЌЪ§ОнЛсвьВНЕиСЌајаДШыЕНЮФМўЯЕЭГжаЃЌWALФмБЃжЄетвЛЙ§ГЬЕФЪ§ОнВЛЛсЖЊЪЇЁЃ 2ЁЂHBaseКЭMapReduce ДгMapReduceгІгУЗУЮЪHBaseга3жжЗНЪНЃК зївЕПЊЪМЪБПЩвдгУHBaseзїЮЊЪ§ОндДЃЌзївЕНсЪјЪБПЩвдгУHBaseНгЪеЪ§ОнЃЌШЮЮёЙ§ГЬжагУHBaseЙВЯэзЪдДЁЃ ЪЙгУHBaseзїЮЊЪ§ОндД НзЖЮmap protected void map(ImmutableBytesWritable rowkey,Result
result,Context context){ }; ДгHBaseБэжаЖСШЁЕФзївЕвд[rowkey:scan result]ИёЪННгЪе[k1,v1]МќжЕЖдЃЌЖдгІЕФРраЭЪЧImmutableBytesWritableКЭResultЁЃ ДДНЈЪЕР§ЩЈУшБэжаЫљгаЕФаа Scan scan = new Scan(); scan.addColumn(Ё); НгЯТРДдкMapReduceжаЪЙгУScanЪЕР§ЁЃ TableMapReduceUtil.initTableMapperJob (tablename,scan,map.class, ЪфГіМќЕФРраЭ.class,ЪфГіжЕЕФРраЭ.class,job); ЪЙгУHBaseНгЪеЪ§Он reduceНзЖЮ protected void reduce(
ImmutableBytesWritable rowkey, Iterable<put>values,
Context context){
}; АбreducerЬюШыЕНзївЕХфжУжаЃЌ TableMapReduceUtil.initTableReducerJob (tablename,reduce.class,job); 3ЁЂHBaseЪЕЯжПЩППадКЭПЩгУад HDFSзїЮЊЕзВуДцДЂЃЌЮЊМЏШКРяЕФЫљгаRegionServerЬсЙЉЕЅвЛУќУћПеМфЃЌвЛИіRegionServerЖСаДЪ§ОнПЩвдЮЊЦфЫќЫљгаRegionServerЖСаДЁЃШчЙћвЛИіRegionServerГіЯжЙЪеЯЃЌШЮКЮЦфЫћRegionServerЖМПЩвдДгЕзВуЮФМўЯЕЭГЖСШЁЪ§ОнЃЌЛљгкБЃДцдкHDFSРяЕФHFileПЊЪМЬсЙЉЗўЮёЁЃНгЙметИіRegionServerzЗўЮёЕФregionЁЃ ЫФЁЂгХЛЏHBase 1ЁЂЫцЛњЖСУмМЏаЭ гХЛЏЗНЯђЃКИпаЇРћгУЛКДцКЭИќКУЕФЫїв§ діМгЛКДцЪЙгУЕФЖбЕФАйЗжБШЃЌЭЈЙ§ВЮЪ§ hfile.block.cache.size ХфжУЁЃ
МѕЩйMemStoreеМгУЕФАйЗжБШЃЌЭЈЙ§hbase.regionserver.global.memstore.lowerLimit
КЭhbase.regionserver.global.memstore.upperLimitРДЕїНкЁЃ
ЪЙгУИќаЁЕФЪ§ОнПщЃЌЪЙЫїв§ЕФСЃЖШИќЯИЁЃ ДђПЊВМТЁЙ§ТЫЦїЃЌвдМѕЩйЮЊВщевжИЖЈааЕФKey ValueЖдЯѓЖјЖСШЁЕФHFileЕФЪ§СПЁЃ ЩшжУМЄНјЛКДцЃЌПЩвдЬсЩ§ЫцЛњЖСадФмЁЃ ЙиБеУЛгаБЛгУЕНЫцЛњЖСЕФСазхЃЌЬсЩ§ЛКДцУќжаТЪЁЃ 2ЁЂЫГађЖСУмМЏаЭ гХЛЏЗНЯђЃКМѕЩйЪЙгУЛКДцЁЃ діДѓЪ§ОнПщЕФДѓаЁЃЌЪЙУПДЮгВХЬбАЕРЪБМфШЁГіЕФЪ§ОнИќЖрЁЃ ЩшжУНЯИпЕФЩЈУшЦїЛКДцжЕЃЌвдБудкжДааДѓЙцФЃЫГађЖСЪБУПДЮRPCЧыЧѓЩЈУшЦїПЩвдШЁЛиИќЖрааЁЃ ВЮЪ§ hbase.client.scanner.caching
ЖЈвхСЫдкЩЈУшЦїЩЯЕїгУnextЗНЗЈЪБШЁЛиЕФааЕФЪ§СПЁЃ ЙиБеЪ§ОнПщЕФЛКДцЃЌБмУтЗЬкЛКДцЕФДЮЪ§ЬЋЖрЁЃЭЈЙ§Scan.setCacheBlocks(false)ЩшжУЁЃ ЙиБеБэЕФЛКДцЃЌвдБудкУПДЮЩЈУшЪБВЛдйЗЬкЛКДцЁЃ 3ЁЂаДУмМЏаЭ гХЛЏЗНЯђЃКВЛвЊЬЋЦЕЗБЫЂаДЃЌКЯВЂЛђепВ№ЗжЁЃ ЕїИпЕзВуДцДЂЮФМўЃЈHStoreFileЃЉЕФзюДѓДѓаЁЃЌregionдНДѓвтЮЖзХдкаДЕФЪБКђВ№ЗждНЩйЁЃЭЈЙ§ВЮЪ§
hbase.hregion.max.filesizeЩшжУЁЃ діДѓMemStoreЕФДѓаЁЃЌЭЈЙ§ВЮЪ§hbase.hregion.memstore.flush.sizeЕїНкЁЃЫЂаДЕНHDFSЕФЪ§ОндНЖрЃЌЩњВњЕФHFileдНДѓЃЌЛсдкаДЕФЪБКђМѕЩйЩњГЩЮФМўЕФЪ§СПЃЌДгЖјМѕЩйКЯВЂЕФДЮЪ§ЁЃ дкУПЬЈRegionServerЩЯдіМгЗжХфИјMemStoreЕФЖбБШР§ЁЃАбupperLimitЩшЮЊФмЙЛШнФЩУПИіregionЕФMemStoreГЫвдУПИіRegionServerЩЯдЄЦкregionЕФЪ§СПЁЃ РЌЛјЛиЪегХЛЏЃЌдкhbase-env.shЮФМўРяЩшжУЃЌПЩвдЩшжУГѕЪМжЕЮЊЃК-Xmx8g -Xms8g -Xmn128m
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 ДђПЊMemStore-Local Allocation BufferетИіЬиадЃЌгажњгкЗРжЙЖбЕФЫщЦЌЛЏЁЃ
ЭЈЙ§ВЮЪ§hbase.hregion.memstore.mslab.enabledЩшжУ 4ЁЂЛьКЯаЭ гХЛЏЗНЯђЃКашвЊЗДИДГЂЪдИїжжзщКЯЃЌШЛКѓдЫааВтЪдЃЌЕУЕНзюМбНсЙћЁЃ гАЯьадФмЕФвђЫиЛЙАќРЈЃК бЙЫѕЃКПЩвдМѕЩйМЏШКЩЯЕФIOбЙСІ КУЕФааМќЩшМЦ дкдЄЦкМЏШКИКдизюаЁЕФЪБКђЪжЙЄДІРэДѓКЯВЂ гХЛЏRegionServerДІРэГЬађМЦЪ§ |









