| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФНщЩмСЫУРЭМдкДюНЈЭъЪ§ОнЦНЬЈВЂПЊЗХИјИїИівЕЮёЯпЪЙгУКѓЃЌЖдЦНЬЈЮШЖЈадзіЕФвЛаЉЪЕМљКЭгХЛЏЁЃ |
|
ШчНёДѓЪ§ОндкИїаавЕЕФгІгУдНРДдНЙуЗКЃКдЫгЊЛљгкЪ§ОнЙизЂдЫгЊаЇЙћЃЌВњЦЗЛљгкЪ§ОнЗжЮіЙизЂзЊЛЏТЪЧщПіЃЌПЊЗЂЛљгкЪ§ОнКтСПЯЕЭГгХЛЏаЇЙћЕШЁЃУРЭМЙЋЫОгаУРХФЁЂУРЭМауауЁЂУРбеЯрЛњЕШЪЎМИИі
appЃЌУПИі app ЖМЛсЛљгкЪ§ОнзіИіадЛЏЭЦМіЁЂЫбЫїЁЂБЈБэЗжЮіЁЂЗДзїБзЁЂЙуИцЕШЃЌећЬхЖдЪ§ОнЕФвЕЮёашЧѓБШНЯЖрЁЂгІгУвВБШНЯЙуЗКЁЃ
вђДЫУРЭМЪ§ОнММЪѕЭХЖгЕФвЕЮёБГОАжївЊЬхЯждкЃКвЕЮёЯпЖрвдМАгІгУБШНЯЙуЗКЁЃетвВЪЧДйЪЙЮвУЧДюНЈЪ§ОнЦНЬЈЕФвЛИізюжївЊЕФдвђЃЌгЩвЕЮёЧ§ЖЏЁЃ
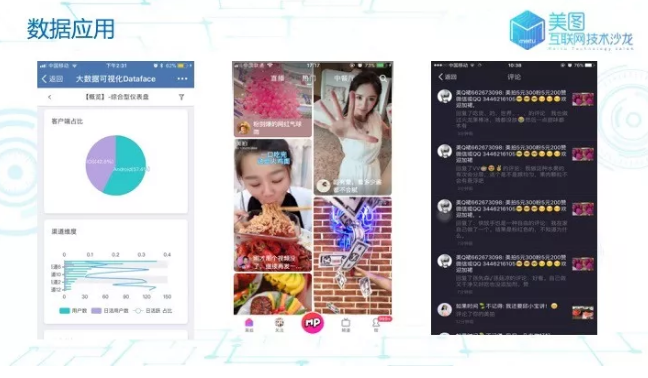
ОйМИИіУРЭМЕФЪ§ОнгІгУАИР§ЁЃШчЭМ 1 ЫљЪОЃЌзѓЦ№ЕквЛеХЪЧУРЭМздбаЕФЪ§ОнПЩЪгЛЏЦНЬЈ
DataFaceЃЌжЇГжвЕЮёЗНздгЩЭЯзЇЩњГЩПЩЪгЛЏБЈБэЃЌБугкИпаЇЕФзіЪ§ОнБЈБэвдМАКѓајЕФЗжЮіЃЛЕкЖўеХЪЧУРХФ
APP ЕФЪзвГЃЌШШУХИіадЛЏЭЦМіЃЌЛљгкгУгкЕФааЮЊЪ§ОнЃЌЮЊгУЛЇЭЦМіПЩФмЯВЛЖЁЂИааЫШЄЕФЪгЦЕСаБэЃЛЕкШ§еХЪЧЛљгкгУЛЇЕФзїБзЕФЪ§ОнЃЌИљОнвЛЖЈЕФФЃаЭгыВпТдНјааЗДзїБзЃЌгааЇХаЖЯЁЂЙ§ТЫгУЛЇЕФзїБзааЮЊЁЃГ§ДЫжЎЭтЃЌАќРЈЫбЫїЁЂa/b
ЪЕбщЁЂЧўЕРИњзйЁЂЙуИцЕШЗНУцЖМгаЙуЗКгІгУЁЃ
ЕБЧАУРЭМУПдТга 5 вкЛюдОгУЛЇЃЌетаЉгУЛЇУПЬьВњЩњНгНќ 200 вкЬѕЕФааЮЊЪ§ОнЃЌећЬхЕФСПМЖЯрЖдРДЫЕЛЙЪЧБШНЯДѓЃЌМЏШКЛњЦїДяЕНЧЇСПМЖЃЌвдМАга
PB МЖЕФРњЪЗзмЪ§ОнСПЁЃ
УРЭМгаБШНЯЖрЕФвЕЮёЯпЃЌВЂЧвИївЕЮёЯпБШНЯЙуЗКЕидЫгУЕНЪ§ОнЃЌвдМАећЬхЕФгУЛЇЙцФЃБШНЯДѓЃЌвдЩЯвђЫиЖМДйЪЙЮвУЧБиаыЙЙНЈЖдгІЕФЪ§ОнЦНЬЈЃЌРДЧ§ЖЏетаЉвЕЮёдіГЄЃЌИќИпаЇЕиЪЙгУЪ§ОнЁЃ
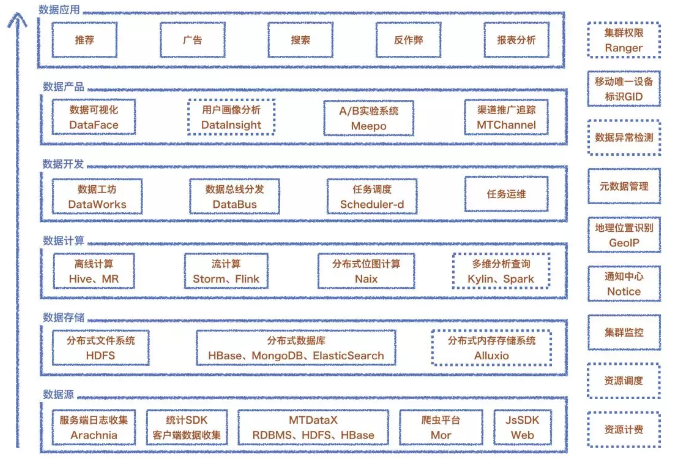
УРЭМЪ§ОнЦНЬЈећЬхМмЙЙ
ШчЭМ 2 ЫљЪОЪЧЮвУЧЪ§ОнЦНЬЈЕФећЬхМмЙЙЁЃдкЪ§ОнЪеМЏетВПЗжЃЌЮвУЧЙЙНЈвЛЬзВЩМЏЗўЮёЖЫШежОЯЕЭГ ArachniaЃЌжЇГжИї
app МЏГЩЕФПЭЛЇЖЫ SDKЃЌИКд№ЪеМЏ app ПЭЛЇЖЫЪ§ОнЃЛЭЌЪБвВгаЛљгк DataX ЪЕЯжЕФЪ§ОнМЏГЩЃЈЕМШыЕМГіЃЉЃЛMor
ХРГцЦНЬЈжЇГжПЩХфжУЕФХРШЁЙЋЭјЪ§ОнЕФШЮЮёПЊЗЂЁЃ
Ъ§ОнДцДЂВужївЊЪЧИљОнвЕЮёЬиЕуРДбЁдёВЛЭЌЕФДцДЂЗНАИЃЌФПЧАжївЊгагУЕН HDFSЁЂMongoDBЁЂHbaseЁЂES
ЕШЁЃдкЪ§ОнМЦЫуВПЗжЃЌЕБЧАРыЯпМЦЫужївЊЛЙЪЧЛљгк Hive&MRЁЂЪЕЪБСїМЦЫуЪЧ Storm ЁЂ
Flink вдМАЛЙгаСэЭтвЛИіздбаЕФ bitmap ЯЕЭГ NaixЁЃ
дкЪ§ОнПЊЗЂетПщЮвУЧЙЙНЈСЫвЛЬзЪ§ОнЙЄЗЛЁЂЪ§ОнзмЯпЗжЗЂЁЂШЮЮёЕїЖШЕШЦНЬЈЁЃЪ§ОнПЩЪгЛЏгыгІгУВПЗжжївЊЪЧЛљгкгУЛЇашЧѓЙЙНЈвЛЯЕСаЪ§ОнгІгУЦНЬЈЃЌАќРЈЃКA/B
ЪЕбщЦНЬЈЁЂЧўЕРЭЦЙуИњзйЦНЬЈЁЂЪ§ОнПЩЪгЛЏЦНЬЈЁЂгУЛЇЛЯёЕШЕШЁЃ
ЭМ 2 гвВреЙЪОЕФЪЧвЛаЉИїзщМўЖМПЩФмвРРЕЕФЛљДЁЗўЮёЃЌАќРЈЕиРэЮЛжУЁЂдЊЪ§ОнЙмРэЁЂЮЈвЛЩшБИБъЪЖЕШЁЃ
ШчЭМ 3 ЫљЪОЪЧЛљБОЕФЪ§ОнМмЙЙСїЭМЃЌЕфаЭЕФ lamda МмЙЙЃЌДгзѓЖЫЪ§ОндДЪеМЏПЊЪМЃЌArachniaЁЂAppSDK
ЗжБ№НЋЗўЮёЖЫЁЂПЭЛЇЖЫЪ§ОнЩЯБЈЕНДњРэЗўЮё collectorЃЌЭЈЙ§НтЮіЪ§ОнавщЃЌАбЪ§ОнаДЕН kafkaЃЌШЛКѓЪЕЪБСїЛсОЙ§вЛВуЪ§ОнЗжЗЂЃЌзюжевЕЮёЯћЗб
kafka Ъ§ОнНјааЪЕЪБМЦЫуЁЃ
РыЯпЛсгЩ ETL ЗўЮёИКд№Дг Kafka dump Ъ§ОнЕН HDFSЃЌШЛКѓвьЙЙЪ§ОндДЃЈБШШч
MySQLЁЂHbase ЕШЃЉжївЊЛљгк DataX вдМА Sqoop НјааЪ§ОнЕФЕМШыЕМГіЃЌзюжеЭЈЙ§ hiveЁЂkylinЁЂspark
ЕШМЦЫуАбЪ§ОнаДШыЕНИїРрЕФДцДЂВуЃЌзюКѓЭЈЙ§ЭГвЛЕФЖдЭт API ЖдНгвЕЮёЯЕЭГвдМАЮвУЧздМКЕФПЩЪгЛЏЦНЬЈЕШЁЃ
Ъ§ОнЦНЬЈЕФНзЖЮадЗЂеЙ
ЦѓвЕМЖЪ§ОнЦНЬЈНЈЩшжївЊЗжШ§ИіНзЖЮЃК
1.ИеПЊЪМЪЧЛљБОЪЙгУУтЗбЕФЕкШ§ЗНЦНЬЈЃЌетИіНзЖЮЕФЬиЕуЪЧФмПьЫйМЏГЩВЂПДЕН
app ЕФвЛаЉЭГМЦжИБъЃЌЕЋЪЧШБЕувВКмУїЯдЃЌУЛгадЪМЪ§ОнГ§СЫФЧаЉЕкШ§ЗНЬсЙЉЕФЛљБОжИБъЦфЫћЗжЮіЁЂЭЦМіЕШЖМЮоЗЈЪЕЯжЁЃЫљвдгаДг
0 ЕН 1 ЕФЙ§ГЬЃЌШУЮвУЧздМКгаЪ§ОнПЩвдгУЃЛ
2.дкгаЪ§ОнПЩгУКѓЃЌвђЮЊвЕЮёЯпЁЂашЧѓСПЕФБЌЗЂЃЌашвЊЬсИпПЊЗЂаЇТЪЃЌШУИќЖрЕФШЫВЮгыЪ§ОнПЊЗЂЁЂЪЙгУЕНЪ§ОнЃЌЖјВЛНіНіОжЯогкЪ§ОнбаЗЂШЫдБЪЙгУЃЌЫљвдОЭЩцМАЕНАбЪ§ОнЁЂМЦЫуДцДЂФмСІПЊЗХИјИїИівЕЮёЯпЃЌЖјВЛЪЧЮедкздМКЪжЩЯЃЛ
3.дкЕБЪ§ОнПЊЗХСЫвдКѓЃЌвЕЮёЗНЛсвЊЧѓЪ§ОнШЮЮёФмЗёХмЕУИќПьЃЌФмЗёУыГіЃЌФмЗёИќЪЕЪБЃЛСэЭтвЛЗНУцЃЌЮЊСЫТњзувЕЮёашЧѓМЏШКЕФЙцФЃдНРДдНДѓЃЌвђДЫЛсПЊЪМПМТЧТњзувЕЮёЕФЭЌЪБЃЌШчКЮЪЕЯжИќНкЪЁзЪдДЁЃ
УРЭМЯждкЪЧДІгкЕкЖўгыЕкШ§НзЖЮЕФЙ§ЖЩЦкЃЌдкВЛЖЯЭъЩЦЪ§ОнПЊЗХЕФЭЌЪБЃЌвВж№ВНЬсЩ§ВщбЏЗжЮіаЇТЪЃЌвдМАПЊЪМПМТЧШчКЮНјаагХЛЏГЩБОЁЃНгЯТРДЛсжиЕуНщЩм
0 ЕН 1 вдМАЪ§ОнПЊЗХетСНИіНзЖЮЮвУЧЦНЬЈЕФЪЕМљвдМАгХЛЏЫМТЗЁЃ
Дг 0 ЕН 1
Дг 0 ЕН 1 НтОіДгЪ§ОнВЩМЏЕНзюжеПЩвдЪЙгУЪ§ОнЁЃШчЭМ 4 ЫљЪОЪЧЪ§ОнЪеМЏЕФбнНјЙ§ГЬЃЌДгИеПЊЪМЪЙгУРрЫЦ
umengЁЂflurry етРрЕФУтЗбЕкШ§ЗНЦНЬЈЃЌЕНКѓУцПьЫйЪЙгУ rsync ЭЌВНШежОЕНвЛЬЈЗўЮёЦїЩЯДцДЂЁЂМЦЫуЃЌдйЕНКѓУцПьЫйПЊЗЂСЫвЛИіМђЕЅЕФpythonНХБОжЇГжвЕЮёЗўЮёЦїЩЯБЈШежОЃЌзюжеЮвУЧПЊЗЂСЫЗўЮёЖЫШежОВЩМЏЯЕЭГ
Arachnia вдМАПЭЛЇЖЫ AppSDKЁЃ
Ъ§ОнВЩМЏЪЧЪ§ОнЕФдДЭЗЃЌдкећИіЪ§ОнСДТЗжаЪЧЯрЖдживЊЕФЛЗНкЃЌашвЊИќЖрЙизЂЃКЪ§ОнЪЧЗёЭъећЁЂЪ§ОнЪЧЗёжЇГжЪЕЪБЩЯБЈЁЂЪ§ОнТёЕуЪЧЗёЙцЗЖзМШЗЁЂвдМАЮЌЛЄЙмРэГЩБОЁЃвђДЫЮвУЧЕФШежОВЩМЏЯЕЭГашвЊТњзувдЯТашЧѓЃК
1.ФмМЏГЩЙмРэЮЌЛЄЃЌАќРЈ Agent ФмздЖЏЛЏВПЪ№АВзАЩ§МЖаЖдиЁЂХфжУШШИќЁЂбгГйЗНУцЕФМрПиЃЛ
2.дкПЩППадЗНУцжСЩйашвЊБЃжЄ at least onceЃЛ
3.УРЭМЯждкгаЖр IDC ЕФЧщПіЃЌашвЊФмжЇГжЖрИі IDC Ъ§ОнВЩМЏЛузмЕНЪ§ОнжааФЃЛ
4.дкзЪдДЯћКФЗНУцОЁСПаЁЃЌОЁСПзіЕНВЛгАЯьвЕЮёЁЃ
ЛљгквдЩЯашЧѓЮвУЧУЛгаЪЙгУ flumeЁЂscribeЁЂfluentdЃЌзюжебЁдёздМКПЊЗЂвЛЬзВЩМЏЯЕЭГ
ArachniaЁЃ
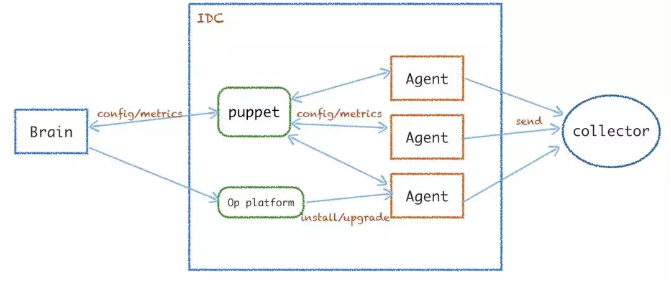
ЭМ 5 ЪЧ Arachnia ЕФМђвзМмЙЙЭМЃЌЫќЭЈЙ§ЯЕЭГДѓФдНјааМЏжаЪНЙмРэЁЃpuppet ФЃПщжївЊзїЮЊЕЅИі
IDC ФкЭГвЛЛузм Agent ЕФ metricsЃЌжазЊзЊЗЂЕФ metrics ЛђепХфжУШШИќУќСюЁЃВЩМЏЦї
Agent жївЊЪЧдЫЮЌЦНЬЈИКд№АВзАЁЂЦєЖЏКѓДг brain РШЁЕНХфжУЃЌВЂПЊЪМВЩМЏЩЯБЈЪ§ОнЕН collectorЁЃ
НгзХПД Arachnia ЕФЪЕМљгХЛЏЃЌЪзЯШЪЧ at least once ЕФПЩППадБЃжЄЁЃВЛЩйЕФЯЕЭГЖМЪЧВЩгУАбЩЯБЈЪЇАмЕФЪ§ОнЭЈЙ§
WAL ЕФЗНЪНМЧТМЯТРДЃЌжиЪддйЩЯБЈЃЌвдУтЩЯБЈЪЇАмЖЊЪЇЁЃЮвУЧЕФЪЕМљЪЧШЅЕє WALЃЌдіМгСЫ coordinator
РДЭГвЛЕФЗжЗЂЙмРэ tx зДЬЌЁЃ
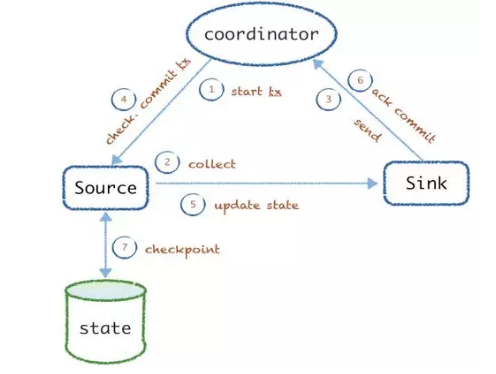
ПЊЪМВЩМЏЧАЛсДг coordinator ЗЂГі txidЃЌsource НгЪеЕНаХКХКѓПЊЪМВЩМЏЃЌВЂНЛгЩ
sink ЗЂЫЭЪ§ОнЃЌЗЂЫЭКѓЛсack txЃЌИцЫп coordinator вбО commitЁЃcoordinator
ЛсНјаааЃбщШЗШЯЃЌШЛКѓдйЗЂЫЭ commit ЕФаХКХИј sourceЁЂsink ИќаТзДЬЌЃЌзюже tx Эъ
source ЛсИќаТВЩМЏНјЖШЕНГжОУВуЃЈФЌШЯЪЧБОЕи fileЃЉЁЃИУЗНЪНШчЙћдкЧАУц 3 ВНгаЮЪЬтЃЌдђЪ§ОнУЛгаЗЂЫЭГЩЙІЃЌВЛЛсжиИДжДааЃЛШчЙћКѓУц
4 ИіВНжшЪЇАмЃЌдђЪ§ОнЛсжиИДЃЌИУ tx ЛсБЛжиЗХЁЃ
ЛљгкЩЯЮФЕФ at least once ПЩППадБЃжЄЃЌгааЉвЕЮёЗНЪЧашвЊЮЈвЛадЕФЃЌЮвУЧетБпжЇГжЮЊУПЬѕШежОЩњГЩЮЈвЛ
ID БъЪЖЁЃСэЭтвЛИіЪ§ОнВЩМЏЯЕЭГЕФжївЊЪЕМљЪЧЃКЮЈвЛЖЈЮЛвЛИіЮФМўвдМАИјУПЬѕШежОзіЮЈвЛЕФ MsgIDЃЌЗНБувЕЮёЗНПЩвдЛљгк
MsgID дкЗЂЩњШежОжиИДЪБФмдкКѓУцзіЧхЯДЁЃ
ЮвУЧвЛПЊЪМЪЧЪЙгУ filenameЃЌКѓУцЗЂЯж filename КмЖрвЕЮёЗНЖМЛсБфИќЃЌЫљвдИФЮЊ
inodeЃЌЕЋЪЧ inode linux ЛсЛиЪежиИДРћгУЃЌзюКѓЪЧвд inode & ЮФМўЭЗВПФкШнзі
hash РДзїЮЊfileIDЁЃЖј MsgID ЪЧЭЈЙ§ agentID & fileID &
offset РДЮЈвЛШЗШЯЁЃ
Ъ§ОнЩЯБЈжЎКѓгЩ collector ИКд№НтЮіавщЭЦЫЭЪ§ОнЕН KafkaЃЌФЧУД Kafka ШчКЮТфЕиЕН
HDFS ФиЃП ЪзЯШПДУРЭМЕФЫпЧѓЃК
1.жЇГжЗжВМЪНДІРэЃЛ
2.ЩцМАЕННЯЖрвЕЮёЯпвђДЫгаЖржжЪ§ОнИёЪНЃЌЫљвдашвЊжЇГжЖржжЪ§ОнИёЪНЕФађСаЛЏЃЌАќРЈ
jsonЁЂavroЁЂЬиЪтЗжИєЗћЕШЃЛ
3.жЇГжвђЮЊЛњЦїЙЪеЯЁЂЗўЮёЮЪЬтЕШЕМжТЕФЪ§ОнТфЕиЪЇАмжиХмЃЌЖјЧвашвЊФмгаБШНЯПьЫйЕФжиХмФмСІЃЌвђЮЊвЛЕЉетПщЙЪеЯЃЌЛсгАЯьЕНКѓајИїИівЕЮёЯпЕФЪ§ОнЪЙгУЃЛ
4.жЇГжПЩХфжУЕФ HDFS ЗжЧјВпТдЃЌФмжЇГжИїИівЕЮёЯпЯрЖдСщЛюЕФЁЂВЛвЛбљЕФЗжЧјХфжУЃЛ
5.жЇГжвЛаЉЬиЪтЕФвЕЮёТпМДІРэЃЌАќРЈЃКЪ§ОнаЃбщЁЂЙ§ЦкЙ§ТЫЁЂВтЪдЪ§ОнЙ§ТЫЁЂзЂШыЕШЃЛ
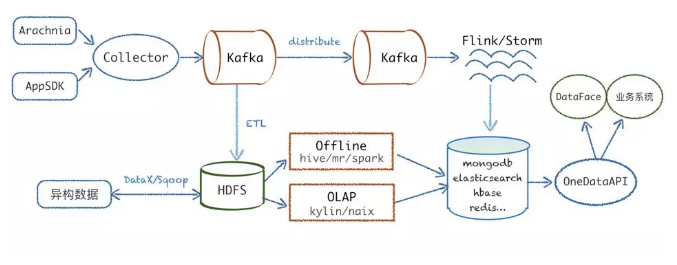
ЛљгкЩЯЪіЫпЧѓЭДЕуЃЌУРЭМДг Kafka ТфЕиЕН HDFS ЕФЪ§ОнЗўЮёЪЕЯжЗНЪНШчЭМ 7 ЫљЪОЁЃ
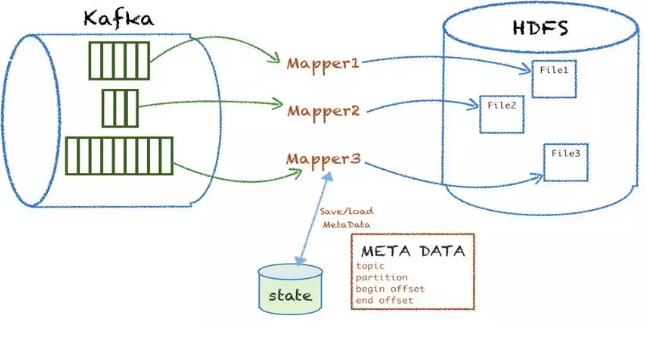
Лљгк Kafka КЭ MR ЕФЬиЕуЃЌеыЖдУПИі kafka topic
ЕФ partitionЃЌзщзА mapper ЕФ inputsplitЃЌШЛКѓЦ№вЛИі mapper НјГЬДІРэЯћЗбетИіХњДЮЕФ
kafka Ъ§ОнЃЌОЙ§Ъ§ОнНтЮіЁЂвЕЮёТпМДІРэЁЂаЃбщЙ§ТЫЁЂзюжеИљОнЗжЧјЙцдђТфЕиаДЕНФПБъ HDFS ЮФМўЁЃТфЕиГЩЙІКѓЛсАбетДЮДІРэЕФ
meta аХЯЂЃЈАќРЈ topicЁЂpartitionЁЂПЊЪМЕФ offsetЁЂНсЪјЕФoffsetЃЉДцДЂЕН
MySQLЁЃЯТДЮдйДІРэЕФЪБКђЃЌЛсДгЩЯДЮДІРэЕФНсЪјЕФ offset ПЊЪМЖСШЁЯћЯЂЃЌПЊЪМаТвЛХњЕФЪ§ОнЯћЗбТфЕиЁЃ
ЪЕЯжСЫЛљБОЙІФмКѓФбУтЛсгіЕНвЛаЉЮЪЬтЃЌБШШчВЛЭЌЕФвЕЮё topic ЕФЪ§ОнСПМЖЪЧВЛвЛбљЕФЃЌетбљЛсЕМжТвЛДЮШЮЮёашвЊЕШД§
partition Ъ§ОнСПзюЖрвдМАДІРэЪБМфзюГЄЕФ mapper НсЪјЃЌВХФмНсЪјећИіШЮЮёЁЃФЧЮвУЧдѕУДНтОіетИіЮЪЬтФиЃПЯЕЭГЩшМЦжагаИіВЛГЩЮФддђЪЧЃКЗжОУБиКЯЁЂКЯОУБиЗжЃЌеыЖдЪ§ОнЧуаБЕФЮЪЬтЮвУЧВЩгУСЫРрЫЦЕФЫМТЗЁЃ
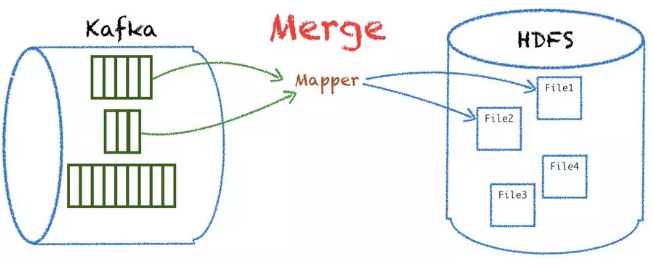
ЪзЯШЖдЪ§ОнСПМЖНЯаЁЕФ partition КЯВЂЕНвЛИі inputsplitЃЌДяЕНвЛИі mapper
ПЩвдДІРэЖрИівЕЮёЕФ partition Ъ§ОнЃЌзюжеТфЕиаДЖрЗнЮФМўЁЃ
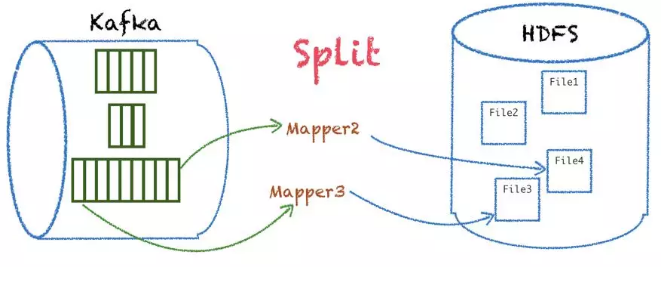
СэЭтЖдЪ§ОнСПМЖНЯДѓЕФ partition жЇГжЗжЖЮВ№ЗжЃЌЦНЗжЕНЖрИі
mapper ДІРэЭЌвЛИі partitionЃЌетбљОЭЪЕЯжСЫИќОљКтЕФ mapper ДІРэЃЌФмИќКУЕигІЖдвЕЮёСПМЖЕФЭЛдіЁЃ
Г§СЫЪ§ОнЧуаБЕФЮЪЬтЃЌЛЙГіЯжИїжждвђЕМжТЪ§Он dump ЕН HDFS ЪЇАмЕФЧщПіЃЌБШШчвђЮЊ kafka
ДХХЬЮЪЬтЁЂhadoop МЏШКНкЕухДЛњЁЂЭјТчЙЪеЯЁЂЭтВПЗУЮЪШЈЯоЕШЕМжТИУ ETL ГЬађГіЯжвьГЃЃЌзюжеПЩФмЕМжТвђЮЊЮД
close HDFS ЮФМўЕМжТЮФМўЫ№ЛЕЕШЃЌашвЊжиХмЪ§ОнЁЃФЧЮвУЧЕФЪ§ОнЪБМфЗжЧјЛљБОЖМЪЧвдЬьЮЊЕЅЮЛЃЌгУдРДЕФЗНЪНПЩФмЛсЕМжТвЛИіЬьСЃЖШЕФЮФМўЫ№ЛЕЃЌНтЮіЮоЗЈЖСШЁЁЃ
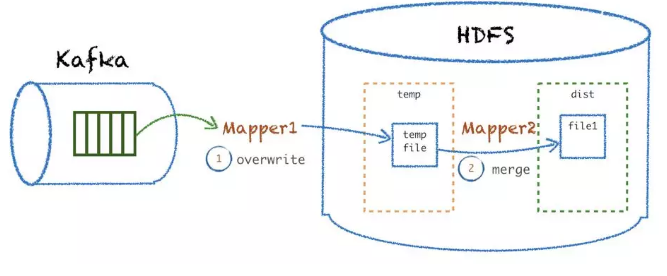
ЮвУЧВЩгУСЫЗжСННзЖЮДІРэЕФЗНЪНЃКmapper 1 ЯШАбЪ§ОнаДЕНвЛИіСйЪБФПТМЃЌmapper
2 Аб Hdfs ЕФСйЪБФПТМЕФЪ§Он append ЕНФПБъЮФМўЁЃетбљЕБ mapper1 ЪЇАмЕФЪБКђПЩвджБНгжиХметИіХњДЮЃЌЖјВЛгУжиХмећЬьЕФЪ§ОнЃЛЕБ
mapper2 ЪЇАмЕФЪБКђФмжБНгДгСйЪБФПТМ merge Ъ§ОнЬцЛЛзюжеЮФМўЃЌМѕЩйСЫжиаТ ETL ЬьСЃЖШЕФЙ§ГЬЁЃ
дкЪ§ОнЕФЪЕЪБЗжЗЂЖЉдФаДШыЕН kafka1 ЕФЪ§ОнЛљБОЪЧУПИівЕЮёЕФШЋСПЪ§ОнЃЌЕЋЪЧеыЖдашЧѓЗНДѓВПЗжвЕЮёЖМжЛЙизЂФГИіЪТМўЁЂФГаЁРрБ№ЕФЪ§ОнЃЌЖјВЛЪЧШЮКЮвЕЮёЖМЯћЗбШЋСПЪ§ОнзіДІРэЃЌЫљвдЮвУЧдіМгСЫвЛИіЪЕЪБЗжЗЂ
Databus РДНтОіетИіЮЪЬтЁЃ
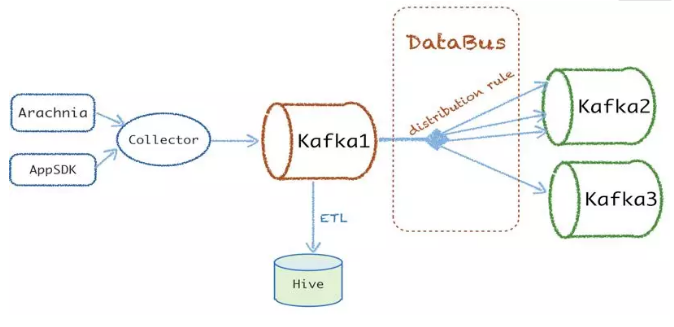
Databus жЇГжвЕЮёЗНздЖЈвхЗжЗЂ rules ЭљЯТгЮЕФ kafka МЏШКаДЪ§ОнЃЌЗНБувЕЮёЗНЖЉдФДІРэздМКЯывЊЕФЪ§ОнЃЌВЂЧвжЇГжИќаЁСЃЖШЕФЪ§ОнжиИДРћгУЁЃ
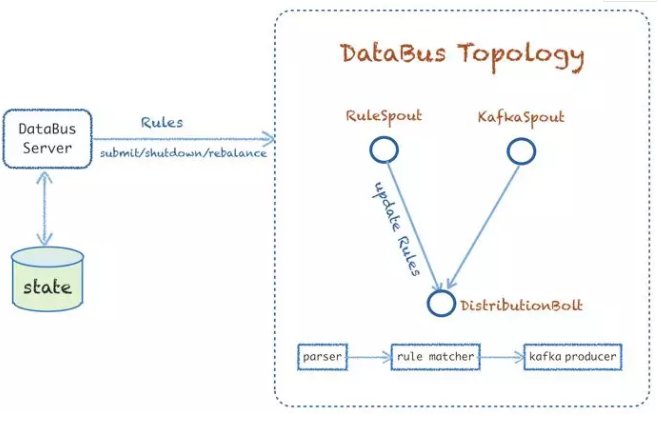
ЭМ 12 ПЩвдПДГі Databus ЕФЪЕЯжЗНЪНЃЌЫќЕФжїЬхЛљгк Storm
ЪЕЯжСЫ databus topologyЁЃDatabus гаСНИі spoutЃЌвЛИіжЇГжРШЁШЋСПвдМАаТдіЕФ
rulesЃЌШЛКѓИќаТЕНЯТгЮЕФЗжЗЂ bolt ИќаТЛКДцЙцдђЃЌСэЭтвЛИіЪЧДг kafka ЯћЗбЕФ spoutЁЃЖј
distributionbolt жївЊЪЧИКд№НтЮіЪ§ОнЁЂЙцдђ matchЃЌвдМААбЪ§ОнЭљЯТгЮЕФ kafka
МЏШКЗЂЫЭЁЃ
Ъ§ОнПЊЗХ
гаСЫдЪМЪ§ОнВЂЧвФмзіРыЯпЁЂЪЕЪБЕФЪ§ОнПЊЗЂвдКѓЃЌЫцжЎЖјРДЕФЪЧЪ§ОнПЊЗЂашЧѓЕФОЎХчЃЌЪ§ОнбаЗЂЭХЖггІНгВЛЯОЁЃЫљвдЮвУЧЭЈЙ§Ъ§ОнЦНЬЈЕФЗНЪНПЊЗХЪ§ОнМЦЫуЁЂДцДЂФмСІЃЌИГгшвЕЮёЗНгаЪ§ОнПЊЗЂЕФФмСІЁЃ
ЖдЪЕЯждЊЪ§ОнЙмРэЁЂШЮЮёЕїЖШЁЂЪ§ОнМЏГЩЁЂDAG ШЮЮёБрХХЁЂПЩЪгЛЏЕШВЛвЛвЛзИЪіЃЌжївЊНщЩмЪ§ОнПЊЗХКѓЃЌУРЭМЖдЮШЖЈадЗНУцЕФЪЕМљаФЕУЁЃ
Ъ§ОнПЊЗХКЭЯЕЭГЮШЖЈадЪЧЯрАЎЯрЩБЕФЙиЯЕЃКвЛЗНУцЃЌПЊЗХСЫжЎКѓВЛдйЪЧгаЪ§ОнЛљДЁЕФбаЗЂШЫдБРДзіЃЌОГЃЛсгіЕНЬсНЛЗЧЗЈЁЂИпзЪдДЯћКФЕШЮЪЬтЕФЪ§ОнШЮЮёЃЌИјЕзВуЕФМЦЫуЁЂДцДЂМЏШКЕФЮШЖЈаддьГЩСЫБШНЯДѓЕФРЇШХЃЛСэЭтвЛЗНУцЃЌЦфЪЕвВЪЧвђЮЊЪ§ОнПЊЗХЃЌВХВЛЖЯЭЦНјЮвУЧБиаыЬсИпЯЕЭГЮШЖЈадЁЃ
еыЖдВЛЩйЕФИпзЪдДЁЂЗЧЗЈЕФШЮЮёЃЌЮвУЧЪзЯШПМТЧФмЗёдк HiveSQL ВуУцФмзівЛаЉаЃбщЁЂЯожЦЁЃШчЭМ 13
ЫљЪОЪЧ HiveSQL ЕФећИіНтЮіБрвыЮЊПЩжДааЕФ MR ЕФЙ§ГЬЃК
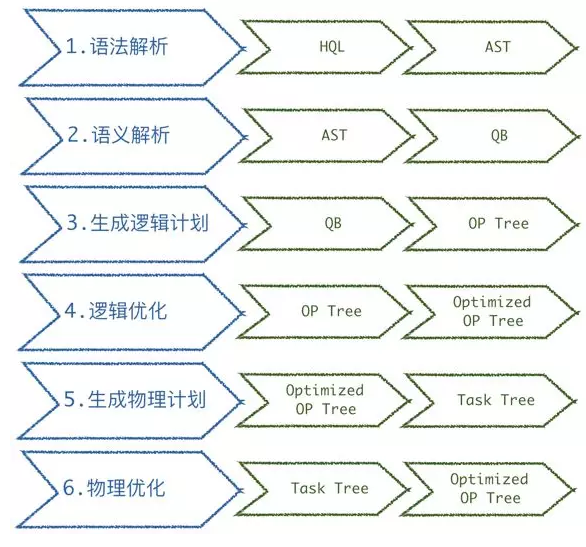
ЪзЯШЛљгк Antlr зігяЗЈЕФНтЮіЃЌЩњГЩ ASTЃЌНгзХзігявхНтЮіЃЌЛљгкAST
ЛсЩњГЩ JAVA ЖдЯѓ QueryBlockЁЃЛљгк QueryBlock ЩњГЩТпММЦЛЎКѓзіТпМгХЛЏЃЌзюКѓЩњГЩЮяРэМЦЛЎЃЌНјааЮяРэгХЛЏКѓЃЌзюжезЊЛЛЮЊвЛИіПЩжДааЕФ
MR ШЮЮёЁЃ
ЮвУЧжївЊдкгявхНтЮіНзЖЮЩњГЩ QueryBlock КѓЃЌФУЕНЫќзіСЫВЛЩйЕФгяОфаЃбщЃЌАќРЈЃКЗЧЗЈВйзїЁЂВщбЏЬѕМўЯожЦЁЂИпзЪдДЯћКФаЃбщХаЖЯЕШЁЃ
ЕкЖўИідкЮШЖЈадЗНУцЕФЪЕМљЃЌжївЊЪЧЖдМЏШКЕФгХЛЏЃЌАќРЈЃК
1.ЮвУЧЭъећЕиЖд HiveЁЂHadoop МЏШКзіСЫвЛДЮЩ§МЖЁЃжївЊЪЧвђЮЊжЎЧАдкЕЭАцБОга
fix вЛаЉЮЪЬтвдМАКЯВЂвЛаЉЩчЧјЕФ patchЃЌдкКѓУцаТАцБОЖМгааоИДЃЛСэЭтвЛИідвђЪЧаТАцБОЕФЬиадвдМАадФмЗНУцЕФгХЛЏЁЃЮвУЧАб
Hive Дг 0.13 АцБОЩ§МЖЕН 2.1 АцБОЃЌHadoop Дг 2.4 Щ§МЖЕН 2.7ЃЛ
2.Жд Hive зіСЫ HA ЕФВПЪ№гХЛЏЁЃЮвУЧАб HiveServer
КЭ MetaStoreServer В№ЗжПЊРДЗжБ№ВПЪ№СЫЖрИіНкЕуЃЌБмУтКЯВЂдквЛИіЗўЮёВПЪ№дЫааЯрЛЅгАЯьЃЛ
3.жЎЧАжДаав§ЧцЛљБОЖМЪЧ On MapReduce ЕФЃЌЮвУЧвВдкзі
Hive On Spark ЕФЧЈвЦЃЌж№ВНАбЯпЩЯШЮЮёДг Hive On MR ЧаЛЛЕН Hive On
SparkЃЛ
4.РвЛИіФкВПЗжжЇЖдЦНЪБгіЕНЕФвЛаЉЮЪЬтзі bugfix ЛђКЯВЂЩчЧј
patch ЕФЬиадЃЛ
дкЦНЬЈЮШЖЈадЗНУцЕФЪЕМљзюКѓвЛВПЗжЪЧЬсИпШЈЯоЁЂАВШЋадЃЌЗРжЙЖдМЏШКЁЂЪ§ОнЕФЗЧЗЈЗУЮЪЁЂЙЅЛїЕШЁЃЬсИпШЈЯожївЊЗжСНПщЃКAPI
ЗУЮЪгыМЏШКЁЃ
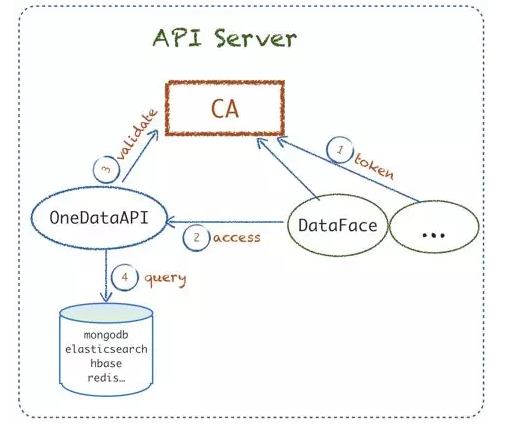
1.API Server ЃКЩЯЮФЬсЕНЮвУЧга OneDataAPIЃЌЬсЙЉИјИїИівЕЮёЯЕЭГЗУЮЪЪ§ОнЕФЭГвЛ
APIЁЃетЗНУцжївЊЪЧЖюЭтЪЕЯжСЫвЛИіЭГвЛШЯжЄ CA ЗўЮёЃЌвЕЮёЯЕЭГБиаыНгШы CA ФУЕН token КѓРДЗУЮЪOneDataAPIЃЌOneDataAPI
дк CA бщжЄЙ§КѓЃЌКЯЗЈЕФВХдЪаэеце§ЗУЮЪЪ§ОнЃЌДгЖјЗРжЙвЕЮёЯЕЭГПЩвдШЮвтЗУЮЪЫљгаЪ§ОнжИБъЁЃ
2.МЏШКЃКФПЧАжївЊЪЧЛљгк Apache Ranger РДЭГвЛИїРрМЏШКЃЌАќРЈ
KafkaЁЂHbaseЁЂHadoop ЕШзіМЏШКЕФЪкШЈЙмРэКЭЮЌЛЄЃЛ
ФЧНгЯТРДЖдЪ§ОнЦНЬЈНЈЩшЙ§ГЬзівЛИіМђЕЅЕФзмНсЁЃ
1.ЪзЯШдкДюНЈЪ§ОнЦНЬЈжЎЧАЃЌвЛЖЈвЊЯШСЫНтвЕЮёЃЌПДвЕЮёЕФећЬхЬхСПЪЧЗёБШНЯДѓЁЂвЕЮёЯпЪЧЗёБШНЯЙуЁЂашЧѓСПЪЧЗёЖрЕНбЯжигАЯьЮвУЧЕФЩњВњСІЁЃШчЙћЖМЪЧПЯЖЈД№АИЃЌФЧПЩвдПМТЧОЁПьДюНЈЪ§ОнЦНЬЈЃЌвдИќИпаЇЁЂПьЫйЬсИпЪ§ОнЕФПЊЗЂгІгУаЇТЪЁЃШчЙћБОЩэЕФвЕЮёСПМЖЁЂашЧѓВЛЖрЃЌВЛвЛЖЈЗЧЕУЬзДѓЪ§ОнЛђепДюНЈЖрУДЭъЩЦЕФЪ§ОнЦНЬЈЃЌвдПьЫйТњзужЇГХвЕЮёгХЯШЁЃ
2.дкЦНЬЈНЈЩшЙ§ГЬжаЃЌашвЊжиЕуЙизЂЪ§ОнжЪСПЁЂЦНЬЈЕФЮШЖЈадЃЌБШШчЙизЂЪ§ОндДВЩМЏЕФЭъећадЁЂЪБаЇадЁЂЩшБИЕФЮЈвЛБъЪЖЃЌЖрдкЦНЬЈЕФЮШЖЈадЗНУцзігХЛЏКЭЪЕМљЃЌЮЊвЕЮёЗНЬсЙЉвЛИіЮШЖЈПЩППЕФЦНЬЈЁЃ
3.дкЬсИпЗжЮіОіВпаЇТЪвдМАЙцФЃж№НЅРЉДѓКѓашвЊЖдГЩБОЁЂзЪдДзівЛаЉгХЛЏКЭЫМПМЁЃ
|









