| БрМЭЦМі: |
| РДдД51ctoЃЌБОЦЊЮФеТЮвУЧгУвЛОфЛАСФСФЪВУДЪЧ
Apache Flink ЕФУќТіЃПЮвЕФД№АИЪЧЃКApache Flink ЪЧвд"ХњЪЧСїЕФЬиР§"ЕФШЯжЊНјааЯЕЭГЩшМЦЕФЁЃ |
|
вЛЁЂApache Flink ЕФУќТі
"УќТі" МДЩњУќгыбЊТіЃЌГЃгїМЋЮЊживЊЕФЪТЮяЁЃЯЕСаЕФЪзЦЊЃЌЪзЦЊЕФЪзЖЮВЛСФApache
FlinkЕФРњЪЗЃЌВЛСФApache FlinkЕФМмЙЙЃЌВЛСФApache FlinkЕФЙІФмЬиадЃЌЮвУЧгУвЛОфЛАСФСФЪВУДЪЧ
Apache Flink ЕФУќТі?ЮвЕФД№АИЪЧЃКApache Flink ЪЧвд"ХњЪЧСїЕФЬиР§"ЕФШЯжЊНјааЯЕЭГЩшМЦЕФЁЃ
ЖўЁЂЮЈПьВЛЦЦ
ЮвУЧОГЃЬ§ЫЕ "ЬьЯТЮфЙІЃЌЮЈПьВЛЦЦ"ЃЌДѓИХвтЫМЪЧЫЕ "ШЮКЮвЛжжЮфЙІЕФеаЪ§ЖМЪЧгаВ№еаЕФЃЌЮЈгаЫйЖШПьЃЌПьЕНЖдЪжИљБОРДВЛМАЗДгІЃЌФуОЭНЋЖдЪжKOСЫЃЌЖдЪжУЛгаЛњЛсВ№еаЃЌЫљвдЮЈПьВЛЦЦ"ЁЃ
ФЧУДетгыApache FlinkгаЪВУДЙиЯЕФи?Apache FlinkЪЧNative Streaming(ДПСїЪН)МЦЫув§ЧцЃЌдкЪЕЪБМЦЫуГЁОАзюЙиаФЕФОЭЪЧ"Пь",вВОЭЪЧ
"ЕЭбгЪБ"ЁЃ
ОЭФПЧАзюШШЕФСНжжСїМЦЫув§ЧцApache SparkКЭApache FlinkЖјбдЃЌЫзюжеЛсГЩЮЊNo1Фи?ЕЅДг
"ЕЭбгЪБ" ЕФНЧЖШПДЃЌSparkЪЧMicro Batching(ЮЂХњЪН)ФЃЪНЃЌзюЕЭбгГйSparkФмДяЕН0.5~2УызѓгвЃЌFlinkЪЧNative
Streaming(ДПСїЪН)ФЃЪНЃЌзюЕЭбгЪБФмДяЕНЮЂУыЁЃКмЯдШЛЪЧЯрЖдНЯЭэГіЕРЕФ Apache Flink
КѓРДепОгЩЯЁЃ ФЧУДЮЊЪВУДApache FlinkФмзіЕНШчДЫжЎ "Пь"Фи?ИљБОдвђЪЧApache
Flink ЩшМЦжЎГѕОЭШЯЮЊ "ХњЪЧСїЕФЬиР§"ЃЌећИіЯЕЭГЪЧNative StreamingЩшМЦЃЌУПРДвЛЬѕЪ§ОнЖМФмЙЛДЅЗЂМЦЫуЁЃЯрЖдгкашвЊППЪБМфРДЛ§дмЪ§ОнMicro
BatchingФЃЪНРДЫЕЃЌдкМмЙЙЩЯОЭвбОеМОнСЫОјЖдгХЪЦЁЃ
ФЧУДЮЊЪВУДЙигкСїМЦЫуЛсгаСНжжМЦЫуФЃЪНФи?ЙщЦфИљБОЪЧвђЮЊЖдСїМЦЫуЕФШЯжЊВЛЭЌЃЌЪЧ"СїЪЧХњЕФЬиР§"
КЭ "ХњЪЧСїЕФЬиР§" СНжжВЛЭЌШЯжЊВњЮяЁЃ
1. Micro Batching ФЃЪН
Micro-Batching МЦЫуФЃЪНШЯЮЊ "СїЪЧХњЕФЬиР§"ЃЌ СїМЦЫуОЭЪЧНЋСЌајВЛЖЯЕФХњНјааГжајМЦЫуЃЌШчЙћХњзуЙЛаЁФЧУДОЭгазуЙЛаЁЕФбгЪБЃЌдквЛЖЈГЬЖШЩЯТњзуСЫ99%ЕФЪЕЪБМЦЫуГЁОАЁЃФЧУДФЧ1%ЮЊЩЖзіВЛЕНФи?етОЭЪЧМмЙЙЕФїШСІЃЌдкMicro-BatchingФЃЪНЕФМмЙЙЪЕЯжЩЯОЭгавЛИіздШЛСїЪ§ОнСїШыЯЕЭГНјаадмХњЕФЙ§ГЬЃЌетдквЛЖЈГЬЖШЩЯОЭдіМгСЫбгЪБЁЃОпЬхШчЯТЪОвтЭМЃК
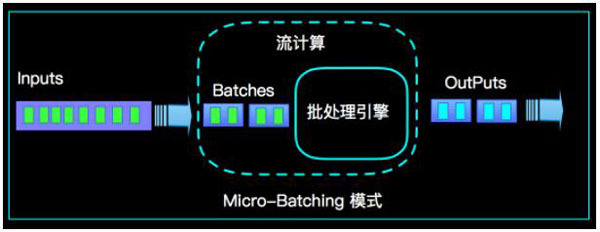
КмЯдШЛMicro-BatchingФЃЪНгаЦфЬьЩњЕФЕЭбгЪБЦПОБЃЌЕЋШЮКЮЪТЮяЕФДцдкЖМгаСНУцадЃЌдкДѓЪ§ОнМЦЫуЕФЗЂеЙРњЪЗЩЯЃЌзюГѕHadoopЩЯЕФMapReduceОЭЪЧгХауЕФХњФЃЪНМЦЫуПђМмЃЌMicro-BatchingдкЩшМЦКЭЪЕЯжЩЯПЩвдНшМјКмЖрГЩЪьЪЕМљЁЃ
2. Native Streaming ФЃЪН
Native Streaming МЦЫуФЃЪНШЯЮЊ ""ХњЪЧСїЕФЬиР§"ЃЌетИіШЯжЊИќЬљЧаСїЕФИХФюЃЌБШШчвЛаЉМрПиРрЕФЯћЯЂСїЃЌЪ§ОнПтВйзїЕФbinlogЃЌЪЕЪБЕФжЇИЖНЛвзаХЯЂЕШЕШздШЛСїЪ§ОнЖМЪЧвЛЬѕЃЌвЛЬѕЕФСїШыЁЃNative
Streaming МЦЫуФЃЪНУПЬѕЪ§ОнЕФЕНРДЖМНјааМЦЫуЃЌетжжМЦЫуФЃЪНЯдЕУИќздШЛЃЌВЂЧвбгЪБадФмДяЕНИќЕЭЁЃОпЬхШчЯТЪОвтЭМЃК
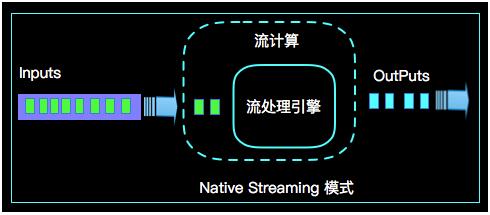
КмУїЯдNative StreamingФЃЪНеМОнСЫСїМЦЫуСьгђ "ЕЭбгЪБ" ЕФКЫаФОКељСІЃЌЕБШЛNative
StreamingФЃЪНЕФЪЕЯжПђМмЪЧвЛИіРњЪЗЯШКгЃЌЕквЛИіЪЕЯжNative StreamingФЃЪНЕФСїМЦЫуПђМмЪЧЕквЛИіГдѓІаЗЕФШЫЃЌашвЊУцСйИќЖрЕФЬєеНЃЌКѓајеТНкЮвУЧЛсТ§Т§НщЩмЁЃЕБШЛNative
StreamingФЃЪНЕФПђМмЪЕЯжЩЯУцКмШнвзЪЕЯжMicro-BatchingКЭBatchingФЃЪНФЃЪНЕФМЦЫуЃЌApache
FlinkОЭЪЧNative StreamingМЦЫуФЃЪНЕФСїХњЭГвЛЕФМЦЫув§ЧцЁЃ
Ш§ЁЂЗсИЛЕФВПЪ№ФЃЪН
Apache Flink АДВЛЭЌЕФашЧѓжЇГжLocalЃЌClusterЃЌCloudШ§жжВПЪ№ФЃЪНЃЌЭЌЪБApache
FlinkдкВПЪ№ЩЯФмЙЛгыЦфЫћГЩЪьЕФЩњЬЌВњЦЗНјааЭъУРМЏГЩЃЌШч ClusterФЃЪНЯТПЩвдРћгУYARN(Yet
Another Resource Negotiator)/MesosМЏГЩНјаазЪдДЙмРэЃЌдкCloudВПЪ№ФЃЪНЯТПЩвдгыGCE(Google
Compute Engine), EC2(Elastic Compute Cloud)НјааМЏГЩЁЃ
1. Local ФЃЪН
ИУФЃЪНЯТApache Flink ећЬхдЫаадкSingle JVMжаЃЌдкПЊЗЂбЇЯАжаЪЙгУЃЌЭЌЪБвВПЩвдАВзАЕНКмЖрЖЫРрЩшБИЩЯЁЃ
2. ClusterФЃЪН
ИУФЃЪНЪЧЕфаЭЕФЭЖВњЕФМЏШКФЃЪНЃЌApache Flink МШПЩвдStandaloneЕФЗНЪННјааВПЪ№ЃЌвВПЩвдгыЦфЫћзЪдДЙмРэЯЕЭГНјааМЏГЩВПЪ№ЃЌБШШчгыYARNНјааМЏГЩЁЃ
етжжВПЪ№ФЃЪНЪЧЕфаЭЕФMaster/SlaveФЃЪНЃЌЮвУЧвдStandalone ClusterФЃЪНЮЊР§ЪОвтШчЯТЃК
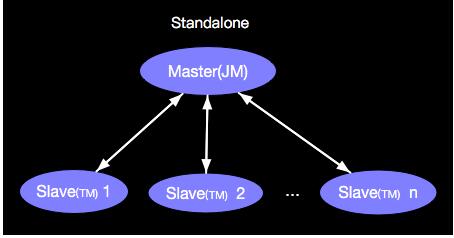
ЦфжаJM(JobManager)ЪЧMasterЃЌTM(TaskManager)ЪЧSlaveЃЌетжжMaster/SlaveФЃЪНгавЛИіЕфаЭЕФЮЪЬтОЭЪЧSPOF(single
point of failure), SPOFШчКЮНтОіФи?Apache Flink гжЬсЙЉСЫHA(High
Availability)ЗНАИЃЌвВОЭЪЧЬсЙЉЖрИіMasterЃЌдкШЮКЮЪБКђзмгавЛИіJMЗўвлЃЌN(N>=1)ИіJMКђбЁ,НјЖјНтОіSPOFЮЪЬтЃЌЪОвтШчЯТЃК
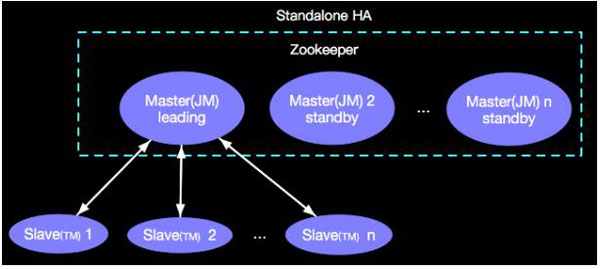
дкЪЕМЪЕФЩњВњЛЗОГЮвУЧЖМЛсХфжУHAЗНАИЃЌФПЧАAlibabaФкВПЪЙгУЕФвВЪЧЛљгкYARN ClusterЕФHAЗНАИЁЃ
3. Cloud ФЃЪН
ИУФЃЪНжївЊЪЧгыГЩЪьЕФдЦВњЦЗНјааМЏГЩЃЌApache FlinkЙйЭјНщЩмСЫGoogleЕФGCE ВЮПМЃЌAmazonЕФEC2
ВЮПМЃЌдкAlibabaЮвУЧвВПЩвдНЋApache FlinkВПЪ№ЕНAlibabaЕФECS(Elastic
Compute Service)ЁЃ
ЫФЁЂЭъЩЦЕФШнДэЛњжЦ
1. ЪВУДЪЧШнДэ
ШнДэ(Fault Tolerance) ЪЧжИШнШЬЙЪеЯЃЌдкЙЪеЯЗЂЩњЪБФмЙЛздЖЏМьВтГіРДВЂЪЙЯЕЭГФмЙЛздЖЏЛиИДе§ГЃдЫааЁЃЕБГіЯжФГаЉжИЖЈЕФЭјТчЙЪеЯЁЂгВМўЙЪеЯЁЂШэМўДэЮѓЪБЃЌЯЕЭГШдФмжДааЙцЖЈЕФвЛзщГЬађЃЌЛђепЫЕГЬађВЛЛсвђЯЕЭГжаЕФЙЪеЯЖјжажЙЃЌВЂЧвжДааНсЙћвВВЛЛсвђЯЕЭГЙЪеЯЖјв§Ц№МЦЫуВюДэЁЃ
2. ШнДэЕФДІРэФЃЪН
дквЛИіЗжВМЪНЯЕЭГжагЩгкЕЅИіНјГЬЛђепНкЕухДЛњЖМгаПЩФмЕМжТећИіJobЪЇАмЃЌФЧУДШнДэЛњжЦГ§СЫвЊБЃжЄдкгіЕНЗЧдЄЦкЧщПіЯЕЭГФмЙЛ"дЫаа"ЭтЃЌЛЙвЊЧѓФм"е§ШЗдЫаа",вВОЭЪЧЪ§ОнФмАДдЄЦкЕФДІРэЗНЪННјааДІРэЃЌБЃжЄМЦЫуНсЙћЕФе§ШЗадЁЃМЦЫуНсЙћЕФе§ШЗадШЁОігкЯЕЭГЖдУПвЛЬѕМЦЫуЪ§ОнДІРэЛњжЦЃЌвЛАугаШчЯТШ§жжДІРэЛњжЦЃК
At Most OnceЃКзюЖрЯћЗбвЛДЮЃЌетжжДІРэЛњжЦЛсДцдкЪ§ОнЖЊЪЇЕФПЩФмЁЃ
At Least OnceЃКзюЩйЯћЗбвЛДЮЃЌетжжДІРэЛњжЦЪ§ОнВЛЛсЖЊЪЇЃЌЕЋЪЧгаПЩФмжиИДЯћЗбЁЃ
Exactly OnceЃКОЋШЗвЛДЮЃЌЮоТлКЮжжЧщПіЯТЃЌЪ§ОнЖМжЛЛсЯћЗбвЛДЮЃЌетжжЛњжЦЪЧЖдЪ§ОнзМШЗадЕФзюИпвЊЧѓЃЌдкН№ШкжЇИЖЃЌвјааеЫЮёЕШСьгђБиаыВЩгУетжжФЃЪНЁЃ
3. Apache FlinkЕФШнДэЛњжЦ
Apache FlinkЕФJobЛсЩцМАЕН3ИіВПЗжЃЌЭтВПЪ§ОндД(External Input), FlinkФкВПЪ§ОнДІРэ(Flink
Data Flow)КЭЭтВПЪфГі(External Output)ЁЃШчЯТЪОвтЭМ:
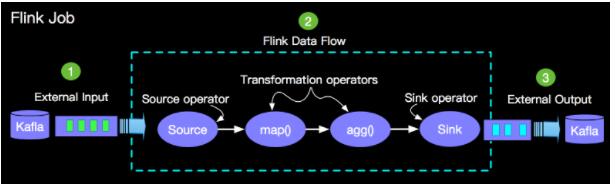
ФПЧАApache Flink жЇГжСНжжЪ§ОнШнДэЛњжЦЃК
At Least Once
Exactly Once
Цфжа Exactly Once ЪЧзюбЯИёЕФШнДэЛњжЦЃЌИУФЃЪНвЊЧѓУПЬѕЪ§ОнБиаыДІРэЧвНіДІРэвЛДЮЁЃФЧУДЖдгкетжжбЯИёШнДэЛњжЦЃЌвЛИіЭъећЕФFlink
JobШнДэвЊзіЕН End-to-End ЕФ ШнДэБиаыНсКЯШ§ИіВПЗжНјааСЊКЯДІРэЃЌИљОнЩЯЭМЮвУЧПМТЧШ§ИіГЁОАЃК
ГЁОАвЛЃКFlinkЕФSource Operator дкЖСШЁЕНKaflaжаpos=2000ЕФЪ§ОнЪБКђЃЌгЩгкФГжждвђхДЛњСЫЃЌетИіЪБКђFlinkПђМмЛсЗжХфвЛИіаТЕФНкЕуМЬајЖСШЁKaflaЪ§ОнЃЌФЧУДаТЕФДІРэНкЕудѕбљДІРэВХФмБЃжЄЪ§ОнДІРэЧвжЛБЛДІРэвЛДЮФи?
ГЁОАЖўЃКFlink Data FlowФкВПФГИіНкЕуЃЌШчЙћЩЯЭМЕФagg()НкЕуЗЂЩњЮЪЬтЃЌдкЛжИДжЎКѓдѕбљДІРэВХФмБЃГжmap()СїГіЕФЪ§ОнДІРэЧвжЛБЛДІРэвЛДЮ?
ГЁОАШ§ЃКFlinkЕФSink Operator дкаДШыKafkaЙ§ГЬжаздЩэНкЕуГіЯжЮЪЬтЃЌдкЛжИДжЎКѓШчКЮДІРэЃЌМЦЫуНсЙћВХФмБЃжЄаДШыЧвжЛБЛаДШывЛДЮ?
4. ЯЕЭГФкВПШнДэ
Apache FlinkРћгУCheckpointingЛњжЦРДДІРэШнДэЃЌCheckpointingЕФРэТлЛљДЁ
Stephan дк Lightweight Asynchronous Snapshots for Distributed
Dataflows НјааСЫЯИНкУшЪіЃЌИУЛњжЦдДгкгаK. MANI CHANDYКЭLESLIE LAMPORT
ЗЂБэЕФ Determining-Global-States-of-a-Distributed-System
PaperЁЃApache Flink ЛљгкCheckpointingЛњжЦЖдFlink Data FlowЪЕЯжСЫAt
Least Once КЭ Exactly Once СНжжШнДэДІРэФЃЪНЁЃ
Apache Flink CheckpointingЕФФкВПЪЕЯжЛсРћгУ BarriersЃЌStateBackendЕШКѓајеТНкЛсЯъЯИНщЩмЕФММЪѕРДНЋЪ§ОнЕФДІРэНјааMarkerЁЃApache
FlinkЛсРћгУBarrierНЋећИіСїНјааБъМЧЧаЗжЃЌШчЯТЪОвтЭМЃК
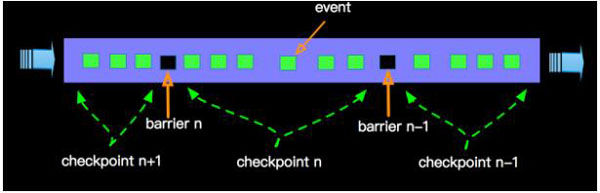
етбљApache FlinkЕФУПИіOperatorЖМЛсМЧТМЕБЧАГЩЙІДІРэЕФCheckpointЃЌШчЙћЗЂЩњДэЮѓЃЌОЭЛсДгЩЯвЛИіГЩЙІЕФCheckpointПЊЪММЬајДІРэКѓајЪ§ОнЁЃБШШч
Soruce OperatorЛсНЋЖСШЁЭтВПЪ§ОндДЕФPositionЪЕЪБЕФМЧТМЕНCheckpointжаЃЌЪЇАмЪБКђЛсДгCheckpointжаЖСШЁГЩЙІЕФpositionМЬајОЋзМЕФЯћЗбЪ§ОнЁЃУПИіЫузгЛсдкCheckpointжаМЧТМздМКЛжИДЪБКђБиаыЕФЪ§ОнЃЌБШШчСїЕФдЪМЪ§ОнКЭжаМфМЦЫуНсЙћЕШаХЯЂЃЌдкЛжИДЕФЪБКђДгCheckpointжаЖСШЁВЂГжајДІРэСїЪ§ОнЁЃ
5. ЭтВПSourceШнДэ
Apache Flink вЊзіЕН End-to-End ЕФ Exactly Once ашвЊЭтВПSourceЕФжЇГжЃЌБШШчЩЯУцЮвУЧЫЕЙ§
Apache FlinkЕФCheckpointingЛњжЦЛсдкSourceНкЕуМЧТМЖСШЁЕФPositionЃЌФЧОЭашвЊЭтВПЪ§ОнЬсЙЉЖСШЁЕФPositionКЭжЇГжИљОнPositionНјааЪ§ОнЖСШЁЁЃ
6. ЭтВПSinkШнДэ
Apache Flink вЊзіЕН End-to-End ЕФ Exactly Once ЯрЖдБШНЯРЇФбЃЌШчЩЯГЁОАШ§ЫљЪіЃЌЕБSink
OperatorНкЕухДЛњЃЌжиаТЛжИДЪБКђИљОнApache Flink ФкВПЯЕЭГШнДэ exactly onceЕФБЃжЄ,ЯЕЭГЛсЛиЙіЕНЩЯДЮГЩЙІЕФCheckpoinМЬајаДШыЃЌЕЋЪЧЩЯДЮГЩЙІCheckpointжЎКѓЕБЧАCheckpointЮДЭъГЩжЎЧАвбОАбвЛВПЗжаТЪ§ОнаДШыЕНkafkaСЫ.
Apache FlinkздЩЯДЮГЩЙІЕФCheckpointМЬајаДШыkafkaЃЌОЭдьГЩСЫkafkaдйДЮНгЪеЕНвЛЗнЭЌбљЕФРДздSink
OperatorЕФЪ§Он,НјЖјЦЦЛЕСЫEnd-to-End ЕФ Exactly Once гявх(жиИДаДШыОЭБфГЩСЫAt
Least OnceСЫ)ЃЌШчЙћвЊНтОіетвЛЮЪЬтЃЌApache Flink РћгУTwo phase commit(СННзЖЮЬсНЛ)ЕФЗНЪНРДНјааДІРэЁЃБОжЪЩЯЪЧSink
Operator ашвЊИажЊећЬхCheckpointЕФЭъГЩЃЌВЂдкећЬхCheckpointЭъГЩЪБКђНЋМЦЫуНсЙћаДШыKafkaЁЃ
ЮхЁЂСїХњЭГвЛЕФМЦЫув§Чц
ХњгыСїЪЧСНжжВЛЭЌЕФЪ§ОнДІРэФЃЪНЃЌШчApache StormжЛжЇГжСїФЃЪНЕФЪ§ОнДІРэЃЌApache SparkжЛжЇГжХњ(Micro
Batching)ФЃЪНЕФЪ§ОнДІРэЁЃФЧУДApache Flink ЪЧШчКЮзіЕНМШжЇГжСїДІРэФЃЪНвВжЇГжХњДІРэФЃЪНФи?
1. ЭГвЛЕФЪ§ОнДЋЪфВу
ПЊЦЊЮвУЧОЭНщЩмApache Flink ЕФ "УќТі"ЪЧвд"ХњЪЧСїЕФЬиР§"ЮЊЕМЯђРДНјаав§ЧцЕФЩшМЦЕФЃЌЯЕЭГЩшМЦГЩЮЊ
"Native Streaming"ЕФФЃЪННјааЪ§ОнДІРэЁЃФЧУДApache FLinkНЋХњФЃЪНжДааЕФШЮЮёПДзіЪЧСїЪНДІРэШЮЮёЕФЬиЪтЧщПіЃЌжЛЪЧдкЪ§ОнЩЯХњЪЧгаНчЕФ(гаЯоЪ§СПЕФдЊЫи)ЁЃ
Apache Flink дкЭјТчДЋЪфВуУцгаСНжжЪ§ОнДЋЪфФЃЪНЃК
PIPELINEDФЃЪН - МДвЛЬѕЪ§ОнБЛДІРэЭъГЩвдКѓЃЌСЂПЬДЋЪфЕНЯТвЛИіНкЕуНјааДІРэЁЃ
BATCH ФЃЪН - МДвЛЬѕЪ§ОнБЛДІРэЭъГЩКѓЃЌВЂВЛЛсСЂПЬДЋЪфЕНЯТвЛИіНкЕуНјааДІРэЃЌЖјЪЧаДШыЕНЛКДцЧјЃЌШчЙћЛКДцаДТњОЭГжОУЛЏЕНБОЕигВХЬЩЯЃЌзюКѓЕБЫљгаЪ§ОнЖМБЛДІРэЭъГЩКѓЃЌВХНЋЪ§ОнДЋЪфЕНЯТвЛИіНкЕуНјааДІРэЁЃ
ЖдгкХњШЮЮёЖјбдЭЌбљПЩвдРћгУPIPELINEDФЃЪНЃЌБШШчЮввЊзіcountЭГМЦЃЌРћгУPIPELINEDФЃЪНФмФУЕНИќКУЕФжДааадФмЁЃжЛгадкЬиЪтЧщПіЃЌБШШчSortMergeJoinЃЌетЪБКђЮвУЧашвЊШЋОжЪ§ОнХХађЃЌВХашвЊBATCHФЃЪНЁЃДѓВПЗжЧщПіСїгыХњПЩгУЭГвЛЕФДЋЪфВпТдЃЌжЛгаЬиЪтЧщПіЃЌВХНЋХњПДзіЪЧСїЕФвЛИіЬиР§МЬајЬиЪтДІРэЁЃ
2. ЭГвЛШЮЮёЕїЖШВу
Apache Flink дкШЮЮёЕїЖШЩЯСїгыХњЙВЯэЭГвЛЕФзЪдДКЭШЮЮёЕїЖШЛњжЦ(КѓајеТНкЛсЯъЯИНщЩм)ЁЃ
3. ЭГвЛЕФгУЛЇAPIВу
Apache Flink дкDataStremAPIКЭDataSetAPIЛљДЁЩЯЃЌЮЊгУЛЇЬсЙЉСЫСїХњЭГвЛЕФЩЯВуTableAPIКЭSQLЃЌдкгяЗЈКЭгявхЩЯСїХњНјааИпЖШЭГвЛЁЃ(ЦфжаDataStremAPIКЭDataSetAPIЖдСїКЭХњНјааСЫЗжБ№ГщЯѓЃЌетвЛЕуВЂВЛгХбХЃЌдкAlibabaФкВПЖдЦфНјааСЫЭГвЛГщЯѓ)ЁЃ
4. ЧѓЭЌДцвь
Apache Flink ЪЧСїХњЭГвЛЕФМЦЫув§ЧцЃЌВЂВЛвтЮЖзХСїгыХњЕФШЮЮёЖМзпЭГвЛЕФcode pathЃЌдкЖдЕзВуЕФОпЬхЫузгЕФЪЕЯжвВЪЧгаИїздЕФДІРэЕФЃЌдкОпЬхЙІФмЩЯУцЛсИљОнВЛЭЌЕФЬиадЧјБ№ДІРэЁЃБШШч
ХњУЛгаCheckpointЛњжЦЃЌСїЩЯВЛФмзіSortMergeJoinЁЃ
СљЁЂApache Flink МмЙЙ
1. зщМўеЛ
ЮвУЧЩЯУцФкШнвбОНщЩмСЫКмЖрApache FlinkЕФИїжжзщМўЃЌЯТУцЮвУЧећЬхИХРРвЛЯТШЋУВЃЌШчЯТЃК
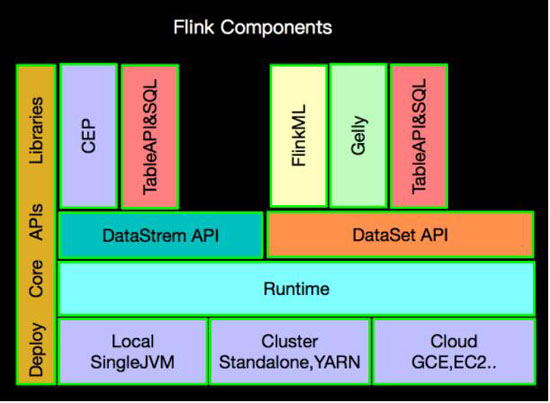
TableAPIКЭSQLЖМНЈСЂдкDataSetAPIКЭDataStreamAPIЕФЛљДЁжЎЩЯЃЌФЧУДTableAPIКЭSQLЪЧШчКЮзЊЛЛЮЊDataStreamКЭDataSetЕФФи?
2. TableAPI&SQLЕНDataStrem&DataSetЕФМмЙЙ
TableAPI&SQLзюжеЛсОЙ§CalciteгХЛЏжЎКѓзЊЛЛЮЊDataStreamКЭDataSetЃЌОпЬхзЊЛЛЪОвтШчЯТЃК
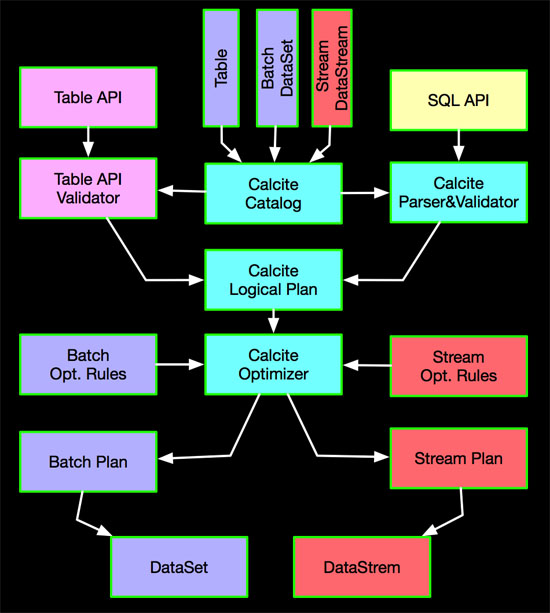
ЖдгкСїШЮЮёзюжеЛсзЊЛЛГЩDataStreamЃЌЖдгкХњШЮЮёзюжеЛсзЊЛЛГЩDataSetЁЃ
3. ANSI-SQLЕФжЇГж
Apache Flink жЎЫљвдРћгУANSI-SQLзїЮЊгУЛЇЭГвЛЕФПЊЗЂгябдЃЌЪЧвђЮЊSQLгазХЗЧГЃУїЯдЕФгХЕуЃЌШчЯТЃК

Declarative - гУЛЇжЛашвЊБэДяЮвЯывЊЪВУДЃЌВЛгУЙиаФШчКЮМЦЫуЁЃ
Optimized - ВщбЏгХЛЏЦїПЩвдЮЊгУЛЇЕФ SQL ЩњГЩзюгХЕФжДааМЦЛЎЃЌЛёШЁзюКУЕФВщбЏадФмЁЃ
Understandable - SQLгябдБЛВЛЭЌСьгђЕФШЫЫљЪьжЊЃЌгУSQL зїЮЊПчЭХЖгЕФПЊЗЂгябдПЩвдКмДѓЕиЬсИпаЇТЪЁЃ
Stable - SQL ЪЧвЛИігЕгаМИЪЎФъРњЪЗЕФгябдЃЌЪЧвЛИіЗЧГЃЮШЖЈЕФгябдЃЌКмЩйгаБфЖЏЁЃ
Unify - Apache Flinkдкв§ЧцЩЯЖдСїгыХњНјааЭГвЛЃЌЭЌЪБгжРћгУANSI-SQLдкгяЗЈКЭгявхВуУцНјааЭГвЛЁЃ
4. ЮоЯоРЉеЙЕФгХЛЏЛњжЦ
Apache Flink РћгУApache CalciteЖдSQLНјааНтЮіКЭгХЛЏЃЌApache CalciteВЩгУCalciteЪЧПЊдДЕФвЛЬзВщбЏв§ЧцЃЌЪЕЯжСЫСНЬзPlannerЃК
HepPlanner - ЪЧRBO(Rule Base Optimize)ФЃЪНЃЌЛљгкЙцдђЕФгХЛЏЁЃ
VolcanoPlanner - ЪЧCBO(Cost Base Optimize)ФЃЪНЃЌЛљгкГЩБОЕФгХЛЏЁЃ
Flink SQLЛсРћгУCalciteНтЮігХЛЏжЎКѓЃЌзюжезЊЛЛЮЊЕзВуЕФDataStremКЭDatasetЁЃЩЯЭМжа
Batch rulesКЭStream rulesПЩвдИљОнгХЛЏашвЊЮоЯоЬэМггХЛЏЙцдђЁЃ
ЦпЁЂЗсИЛЕФРрПтКЭЫузг
Apache Flink гХауЕФМмЙЙОЭЯёвЛзљФІЬьДѓЯУЕФЕиЛљвЛбљЮЊApache Flink ГжОУЕФЩњУќСІДђЯТСЫСМКУЕФЛљДЁЃЌЮЊДђдьApache
FlinkЗсИЛЕФЙІФмЩњЬЌСєЯТЮоЯоЕФПеМфЁЃ
1. РрПт
CEP - ИДдгЪТМўДІРэРрПтЃЌКЫаФЪЧвЛИізДЬЌЛњЃЌЙуЗКгІгУгкЪТМўЧ§ЖЏЕФМрПидЄОЏРрвЕЮёГЁОАЁЃ
ML - ЛњЦїбЇЯАРрПтЃЌЛњЦїбЇЯАжївЊЪЧЪЖБ№Ъ§ОнжаЕФЙиЯЕЁЂЧїЪЦКЭФЃЪНЃЌвЛАугІгУдкдЄВтРрвЕЮёГЁОАЁЃ
GELLY - ЭММЦЫуРрПтЃЌЭММЦЫуИќЖрЕФЪЧПМТЧБпКЭЕуЕФИХФюЃЌвЛАуБЛгУРДНтОіЭјзДЙиЯЕЕФвЕЮёГЁОАЁЃ
2. Ыузг
Apache Flink ЬсЙЉСЫЗсИЛЕФЙІФмЫузгЃЌЖдгкЪ§ОнСїЕФДІРэРДНВЃЌПЩвдЗжЮЊЕЅСїДІРэ(вЛИіЪ§ОндД)КЭЖрСїДІРэ(ЖрИіЪ§ОндД)ЁЃ
3. ЖрСїВйзї
UNION - НЋЖрИізжЖЮРраЭвЛжТЪ§ОнСїКЯВЂЮЊвЛИіЪ§ОнСїЃЌШчЯТЪОвтЃК

JOIN - НЋЖрИіЪ§ОнСї(Ъ§ОнРраЭПЩвдВЛвЛжТ)СЊНгЮЊвЛИіЪ§ОнСїЃЌШчЯТЪОвтЃК

ШчЩЯЭЈЙ§UIONКЭJOINЮвУЧПЩвдНЋЖрСїзюжеБфГЩЕЅСїЃЌApache Flink дкЕЅСїЩЯЬсЙЉСЫИќЖрЕФВйзїЫузгЁЃ
4. ЕЅСїВйзї
НЋЖрСїБфГЩЕЅСїжЎКѓЃЌЮвУЧАДЪ§ОнЪфШыЪфГіЕФВЛЭЌЙщРрШчЯТЃК
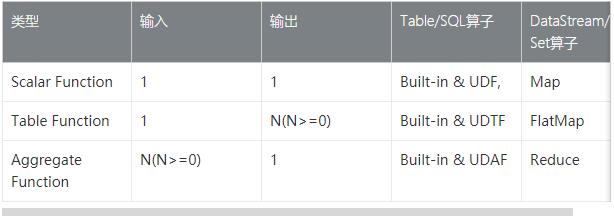
ШчЩЯБэИёЖдЕЅСїЩЯУцВйзїзіМђЕЅЙщРрЃЌГ§ДЫжЎЭтЛЙПЩвдзі Й§ТЫЃЌХХађЃЌДАПкЕШВйзїЃЌЮвУЧКѓајеТНкЛсж№вЛНщЩмЁЃ
4. ДцдкЕФЮЪЬт
Apache Flink ФПЧАЕФМмЙЙЛЙДцдкКмДѓЕФгХЛЏПеМфЃЌБШШчЧАУцЬсЕНЕФDataStreamAPIКЭDataSetAPIЦфЪЕЪЧСїгыХњдкAPIВуУцВЛЭГвЛЕФЬхЯжЃЌЭЌЪБПДОпЬхЪЕЯжЛсЗЂЯжDataStreamAPIЛсЩњГЩTransformation
treeШЛКѓЩњГЩStreamGraphЃЌзюКѓЩњГЩJobGraphЃЌЕзВуЖдгІStreamTaskЃЌЕЋDataSetAPIЛсаЮГЩOperator
treeЃЌflink-optimizeФЃПщЛсЖдBatch PlanНјаагХЛЏЃЌаЮГЩOptimized
Plan КѓаЮГЩJobGraph,зюКѓаЮГЩBatchTaskЁЃОпЬхЪОвтШчЯТЃК
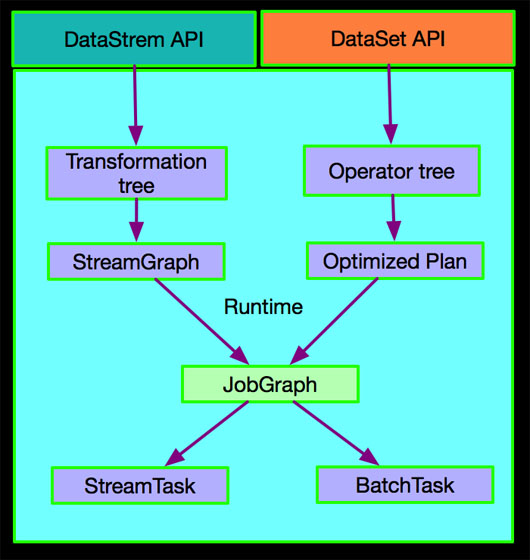
етжжЧщПіЦфЪЕ DataStreamAPIЕНRuntime КЭ DataSetAPIЕНRuntimeЕФЪЕЯжЩЯВЂУЛгаЕУЕНзюДѓГЬЖШЕФЭГвЛКЭИДгУЁЃдкетвЛЕуЩЯУцAalibab
ЦѓвЕАцЕФFlinkдкМмЙЙКЭЪЕЯжЩЯЖМНјааСЫНјвЛВНгХЛЏЁЃ
АЫЁЂAlibabaЦѓвЕАцFlinkМмЙЙ
1. зщМўеЛ
Alibaba ЖдApache FlinkНјааСЫДѓСПЕФМмЙЙгХЛЏЃЌШчЯТМмЙЙЪЧвЛжБХЌСІЕФЗНЯђЃЌДѓВПЗжЙІФмЛЙдкГжајПЊЗЂжаЃЌОпЬхШчЯТЃК
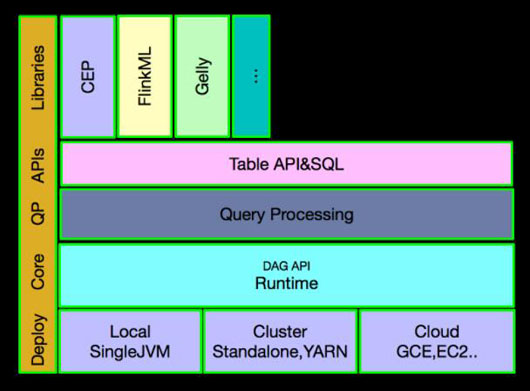
ШчЩЯМмЙЙЮвУЧЗЂЯжНЯДѓЕФБфЛЏЪЧЃК
Query Processing - ЮвУЧдіМгСЫQuery ProcessingВуЃЌдкетвЛВуНјааЭГвЛЕФСїКЭХњЕФВщбЏгХЛЏКЭЕзВуЫузгЕФзЊЛЛЁЃ
DAG API - ЮвУЧдкRuntimeВуУцЭГвЛГщЯѓAPIНгПкЃЌдкAPIВуЖдСїгыХњНјааЭГвЛЁЃ
2. TableAPI&SQLЕНRuntimeЕФМмЙЙ
Apache FlinkжДааВуЪЧСїХњЭГвЛЕФЩшМЦЃЌдкAPIКЭЫузгЩшМЦЩЯУцЮвУЧОЁСПДяЕНСїХњЕФЙВЯэЃЌдкTableAPIКЭSQLВуЮоТлЪЧСїШЮЮёЛЙЪЧХњШЮЮёзюжеЖМзЊЛЛЮЊЭГвЛЕФЕзВуЪЕЯжЁЃЪОвтЭМШчЯТЃК
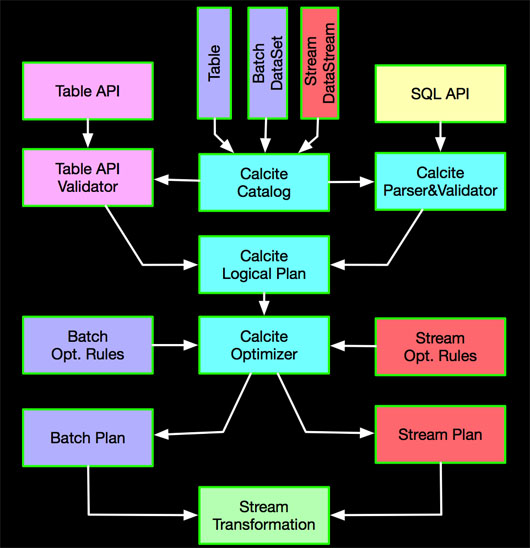
етИіВуУцзюКЫаФЕФБфЛЏЪЧХњзюжевВЛсЩњГЩStreamGraphЃЌжДааВудЫааStream TaskЁЃ
ОХЁЂЬиБ№ЫЕУї
КѓајеТНкЛсвдAlibaba ЦѓвЕАц FlinkЮЊжїНщЩмЙІФмЫузгЃЌЦЊеТжаЗжЯэЕФЙІФмПЩФмПЊдДднЪБУЛгаЃЌЕЋетаЉЕФФкШнКѓајAlibabaЛсЙВЯэИјЩчЧјЃЌашвЊДѓМвФЭаФЕШД§ЁЃ
ЪЎЁЂаЁНс
БОЦЊИХвЊЕФНщЩмСЫ"ХњЪЧСїЕФЬиР§"етвЛЩшМЦЙлЕуЪЧApache FlinkЕФ"УќТі"ЃЌЫќОіЖЈСЫApache
FlinkЕФдЫааФЃЪНЪЧДПСїЪНЕФЃЌетдкЪЕЪБМЦЫуГЁОАЕФ"ЕЭбгГй"ашЧѓЩЯЃЌЯрЖдгкMicro
BatchingФЃЪНеМОнСЫМмЙЙЕФОјЖдгХЪЦЃЌЭЌЪБИХвЊЕФЯђДѓМвНщЩмСЫApache FlinkЕФВПЪ№ФЃЪНЃЌШнДэДІРэЃЌв§ЧцЕФЭГвЛадКЭApache
FlinkЕФМмЙЙЃЌзюКѓКЭДѓМвЗжЯэСЫAlibabaЦѓвЕАцЕФFlinkЕФМмЙЙЃЌвдМАЖдПЊдДApache FlinkЫљзїГіЕФгХЛЏЁЃ
БОЦЊУЛгаЖдОпЬхММЪѕНјааЯъЯИеЙПЊЃЌДѓМвжЛвЊЖдApache FlinkгаГѕВНИажЊЃЌЭЗФджажЊЕРAlibabaЖдApache
FlinkНјааСЫМмЙЙгХЛЏЃЌдіМгСЫжкЖрЙІФмОЭПЩвдСЫЃЌжСгкApache FlinkЕФОпЬхММЪѕЯИНкКЭЪЕЯждРэЃЌвдМАAlibabaЖдApache
FlinkзіСЫФФаЉМмЙЙгХЛЏКЭдіМгСЫФФаЉЙІФмКѓајеТНкЛсеЙПЊНщЩм! |









