| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФНщЩмСЫїШзхздМКЕФгІгУГЁОАЁЂЦНЬЈЛЏЫМТЗКЭвЛаЉВПЪ№дЫЮЌЩЯЕФОбщЁЃ |
|
Apache KylinЪЧЪзИіЭъШЋгЩжаЙњЭХЖгЩшМЦПЊЗЂЃЌВЂЙБЯзЕНApacheШэМўЛљН№Лс(ASF)ЕФЖЅМЖЯюФПЃЌПЊдДвЛФъзѓгвЕФЪБМфЃЌвбОдкЙњФкЙњМЪЖрИіЙЋЫОБЛВЩгУзїЮЊДѓЪ§ОнЗжЮіЦНЬЈЕФЙиМќзщГЩВПЗжЃЌгЕгаДѓСПгУЛЇАИР§ЁЃ
їШзхДѓЪ§ОнЦНЬЈМмЙЙЪІедЬьЫИдк?8дТ13ШеЕФЁОДДПЭ168ЁПЕк7ЦкЃКДѓЪ§ОнЦНЬЈМмЙЙМАгІгУЪЕМљ
КЭ 9дТ22ШеЕФЕкШ§НьЛЅСЊЭјгІгУММЪѕЗхЛсЩЯ НјааСЫЁАДѓЪ§ОнЖрЮЌЗжЮів§ЧцдкїШзхЕФЪЕМљЁБЕФЗжЯэЁЃ
Apache Kylin НќШеЛёЕУЪкШЈЗжЯэетдђАИР§ЃЌЯЃЭћЖдФњгаЫљАяжњЁЃдкДЫИааЛедЬьЫИЯШЩњЕФОЋВЪЗжЯэЁЃ
KylinетЦЅЩёЪодкДѓЪ§ОнШІЖљФквбОж№НЅГЩЮЊвЛИіЮоЗЈКіЪгЕФДцдкЃЌЫќШУФуФмЙЛЭЈЙ§БъзМSQLЃЈANSI
SQLзгМЏЃЉдквЛИі100вк+МЧТМЕФБэжаНјааЖрЮЌЗжЮіВщбЏЃЌВЂЧвНсЙћФмЙЛдкУыМЖЗЕЛиЃЌетвЛЬиадШУЫќГЩЮЊКмЖрПЊЗХЪНЃЌИпВЂЗЂСПЪ§ОнЗжЮіЗўЮёЕФЩЯМббЁдёЃЌНёЬьОЭШУЮвУЧРДвЛЬНОПОЙЃЌПДПДKylinЪЧШчКЮзіЕНвдЩЯетаЉЬиадЕФЃЌЛЙгаїШзхздМКЕФгІгУГЁОАЁЂЦНЬЈЛЏЫМТЗКЭвЛаЉВПЪ№дЫЮЌЩЯЕФОбщЁЃ
дкВЛУІЕФЪБМфЮвЛсИјНтД№Йигк Apache KylinExtreme
OLAP Engine for Big DataApache Kylin ЪЧвЛИіПЊдДЕФЗжВМЪНЗжЮів§ЧцЃЌЮЊHadoopЕШДѓаЭЗжВМЪНЪ§ОнЦНЬЈжЎЩЯЕФГЌДѓЙцФЃЪ§ОнМЏЬсЙЉЭЈЙ§БъзМSQLВщбЏМАЖрЮЌЗжЮіЃЈOLAPЃЉЕФЙІФмЃЌЬсЙЉбЧУыМЖЕФНЛЛЅЪНЗжЮіФмСІЁЃ
Apache Kylin МмЙЙ
ПеМфЛЛЪБМф
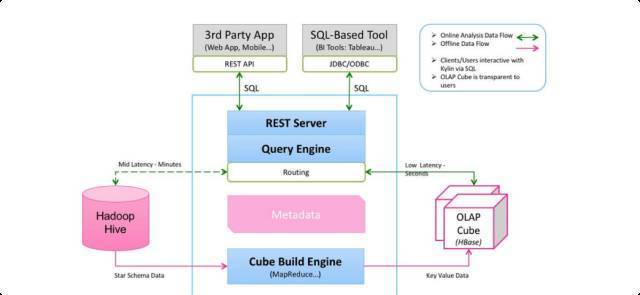
Apache Kylin ЛљБОдРэ
Layer Cubing
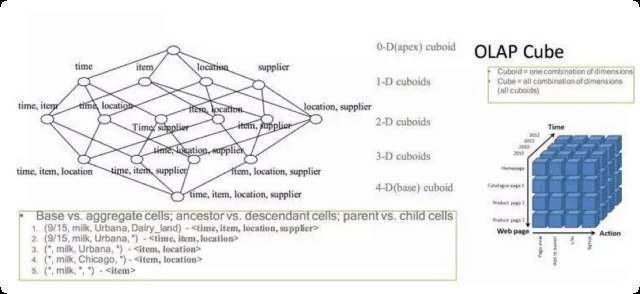
Fast Cubing
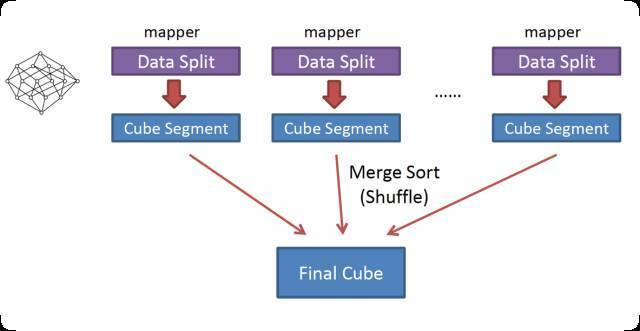
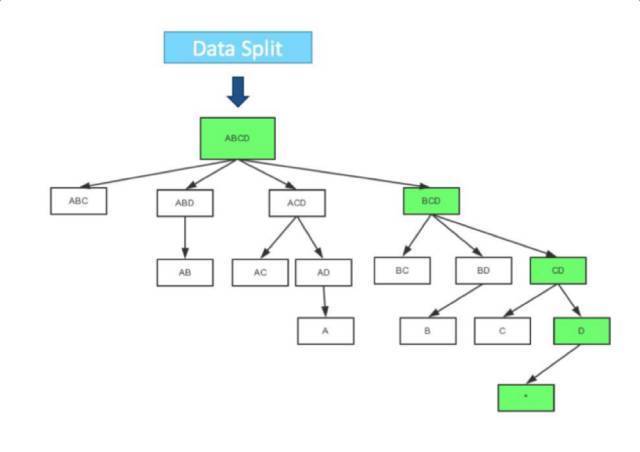
How to Store Cube Data
Query Engine
Kylin Explain Plan

Web UI
REST API

зюаТЬиад
ПЩРЉеЙВхМўЪНМмЙЙ
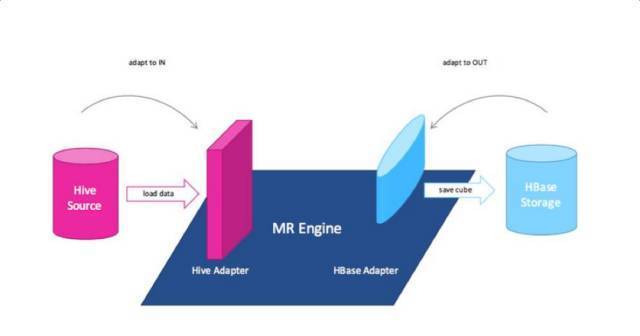
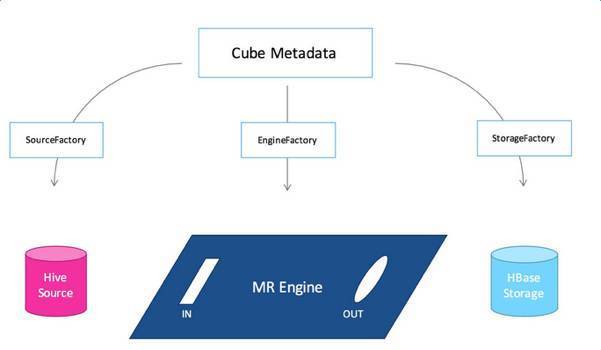
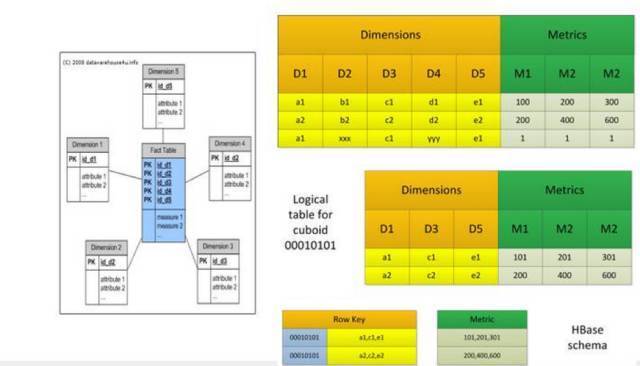
ПЩРЉеЙМмЙЙНЋKylinЕФШ§ДѓвРРЕЃЈЪ§ОндДЁЂCubeв§ЧцЁЂДцДЂв§ЧцЃЉГЙЕзНтёюЁЃKylinНЋВЛдйжБНгвРРЕгкHadoop/HBase/HiveЃЌЖјЪЧАбKylinзїЮЊвЛИіПЩРЉеЙЕФЦНЬЈБЉТЖГщЯѓНгПкЃЌОпЬхЕФЪЕЯжвдВхМўЕФЗНЪНжИЖЈЫљгУЕФЪ§ОндДЁЂв§ЧцКЭДцДЂЁЃ
Parallel Scan
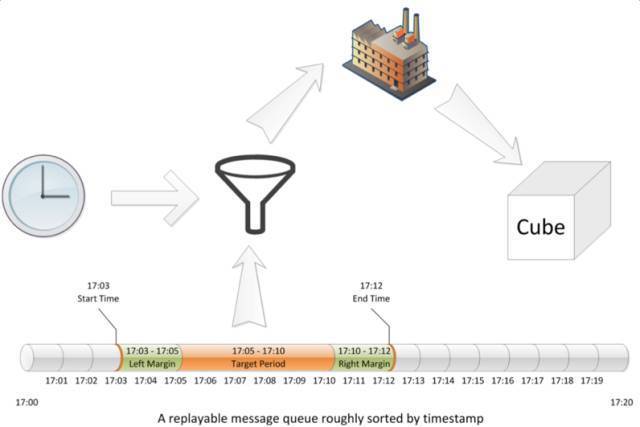
Streaming Cubing
ЦфЫћживЊаТЬиад
- жЇГжОЋШЗЕФDistinctМЦЪ§ЃЈЫљгаЪ§ОнРраЭЃЉЃЛ
- жЇГжеыЖдВЛЭЌЕФProjectЩшжУВЛЭЌЕФMR jobдЫааЖгСаЃЛ
- Top NжИБъжЇГжЖрСаGroup ByЃЛ
- жїЖЏМрВтOOMЃЌНЋЖбеЛжаЕФCuboidЛКДцЕНБОЕиДХХЬЃЛ
- ВщбЏУїЯИЪ§ОнЃЈRAW MEASUREЃЉЃЛ
- жЇГжHiveЪгЭМзїЮЊLookup БэЁЃ
вЕНчАИР§
ОЉЖЋ@дЦКЃ JCloud

Why Kylin
- ЦНЬЈЬхЯЕЭъЩЦЃЌГЩЪьЖШИпЃЌВПЪ№МђЕЅЃЌвзгУЃЛ
- дкИпВЂЗЂЗУЮЪЯТБЃГжВЛДэЕФадФмЃЌЫцзХЪ§ОнСПКЭЮЌЖШзщКЯЕФдіГЄЃЌадФмЫЅМѕвВВЛЛсЬиБ№УїЯдЃЛ
- CubeФЃаЭЕФКЯРэЩшМЦЃЌПЩвдМѕЩйШЫЙЄХфжУ ETLjobЕФЪ§СПЃЛ
- ПЩвддкЪ§ОнзМШЗЖШЁЂДцДЂПеМфЁЂадФмжЎМфСщЛюЕїећЃЌевЕНзюЪЪКЯашЧѓГЁОАЕФЦНКтЕуЃЛ
- БъзМSQLгяЗЈ+JDBC/ODBCЧ§ЖЏПЩвдКмЗНБуЕФКЭЯжгаЯЕЭГзіМЏГЩЃЛ
- ЩчЧјЛюдОЃЌгаKyligenceетбљЕФЩЬвЕЙЋЫОдкБГКѓЭЦЖЏЁЃ
Key FeatureКЭЁАПгЁБ
- жЇГжOffsetЃЛ
- жЇГжвбЖЈвхЗЖЮЇФкЃЌGroup ByЮЌЖШздгЩзщКЯЃЛ
- ЮЌЖШПЩвдзїЮЊWhereЬѕМўЙ§ТЫЃЛ
- Order By ПЩвдЪЧЮЌЖШЛђжИБъЃЛ
- жЇГжJoinЃЈНіЯогкЪТЪЕБэКЭLookup TableЃЌLookup
TableПЩвдЖрИіЃЉЃЛ
- Top NжЛжЇГжSumРраЭЕФжИБъЃЛ
- ШеЦкдіСПЪ§ОнWhereЬѕМўзюКУАќКЌШеЦкЗЖЮЇЃЌВЛШЛHBase ScanЛсГЌЪБЁЃ
гІгУГЁОАЬиеї
- Ъ§ОнСПДѓЃЌЭЌЪБЖдВщбЏадФмгаашЧѓЃЛ
- Ъ§ОнЪЕЪБадвЊЧѓВЛИпЃЈФПЧАзюИпЕНаЁЪБМЖИќаТЃЉЃЛ
- ЮЌЖШзщКЯКЭВщбЏЬѕМўзщКЯдкПЩдЄМћЕФЗЖЮЇФкЃЛ
- Ъ§ОнзмСПДѓЃЌЕЋЬѕМўЩЈУшЗЖЮЇВЛЛсЬЋДѓЕФЃЛ
- ВЛЪЪКЯашвЊДѓЗЖЮЇФЃК§ЫбЫїХХађЕФГЁОАЃЈРрЫЦSearchЃЉЁЃ
їШзхЕФВПЪ№ФЃЪН
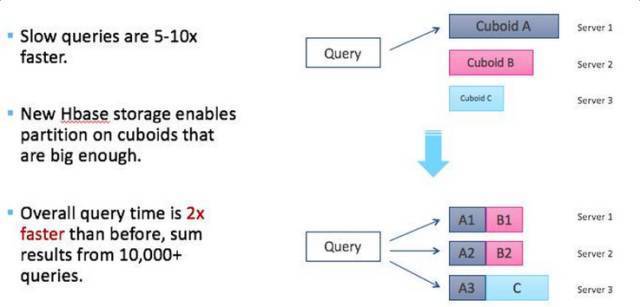
їШзхгІгУАИР§
- ЕЅИіCubeзюДѓЮЌЖШ9ИіЃЌЪ§ОнСП6вкЃЌДцДЂПеМф600GЃЛ
- вЛИіЛљЪ§ЧЇЭђМЖЮЌЖШЃЛ- 1ИіЛљЪ§АйЭђМЖЮЌЖШЃЛ
- ЦфЫћЮЌЖШЛљЪ§дк10wвдФкЁЃ
ВщбЏГЁОАЃК
select max(xxx),min(xxx),cout(distinct
xxx),count(1),
dimension1,dimension2, from T wherepartition_date>=xxxxx
and partition_date<=xxxxx and(ЦфЫћЮЌЖШЕФЫцЛњВЮЪ§зщКЯ)order
by count(1) desc limit 20 offset 100
адФмЃК
- ЦНОљЯьгІЪБМф50%дк1sвдФкЃЌ30%дк2sвдФкЃЌ10%дк5УывдФкЃЛ
- ЩйСПДѓЗЖЮЇЩЈУшЕФSQLЪБМфдк10УызѓгвЃЛ
- вдЩЯадФмЪЧВЛУќжаCacheЕФЪзДЮВщбЏЃЌKylinздДјФкДцEhcacheЁЃ
їШзхCubeгХЛЏЪЕМљ
гХЛЏЧА
- CubeдЪММЧТМ 6вкЃЈвЛИідТЪ§Он ЃЉЃЛ
- BuildКѓЕФCube Size 1.9T ЃЛ
- ЕЅДЮВщбЏЩЈУшвЛжмЪ§ОнЃЌHBaseЦЕЗБГЌЪБЃЌRegion ServerОГЃБЛЭЯЫРЃЌЦНОљЯьгІЪБМфНќ30sЁЃ
ЛюгУAggregation Groups
http : // kylin . apache . org / blog
/ 2016 / 02 / 18 / new - aggregation - group /?
- НЋЪЙгУГЁОАНјааЗжзщЃЌЖдгІВЛЭЌЕФGroupЃЛ
- ДѓЛљЪ§ЮЌЖШДДНЈЕЅЖРЕФGroupЃЌОЁСПШЗШЯашЧѓЃЌЪеЫѕЬѕМўзщКЯЗЖЮЇЃЌIncludeжажЛАќКЌЯрЙиЕФЮЌЖШЃЛ
- ЕЭЛљЪ§ЕФЮЌЖШПЩвдЕЅЖРНЈСЂвЛИіGroupЃЌМгЩЯБибЁЬѕМўЮЌЖШЃЌАбЕЭЛљЪ§ЕФЮЌЖШЖМЩшжУГЩMandatoryЃЌетбљЮЌЖШзщКЯГіЯжЪБkylinЛсСщЛюНјааФкДцФкЖўДЮОлКЯЃЌЕЋвђЮЊетаЉЮЌЖШЛљЪ§ЖМВЛДѓЃЌЖдадФмВЛЛсгАЯьЬЋЖрЃЛ
- ЖўбЁвЛЛђЖрбЁвЛЕФЬѕМўЮЌЖШВЛвЊАќКЌдкЭГвЛИіGroupЃЈБШШчБРРЃЪБМфКЭЩЯДЋЪБМфЃЉЃЛ-
ЭЌЪБгаКУМИИіДѓЛљЪ§GroupЕФЛАПЩвдПМТЧУПИіGroupЕЅЖРНЈвЛИіCubeЃЈБмУтCubeХђеЭЃЌRow
KeyНсЙЙвВИќКЯРэЃЉЁЃ
kylin.query.mem.budget
Rowkey
- гаШеЦкЗжЧјзжЖЮЕФЃЌПЩвдНЋШеЦкзЊГЩжЛАќКЌБфЛЏЗЖЮЇЕФЪ§зжЃК
БШШчдЪМИёЪНЪЧзжЗћДЎЕФ2016-07-15 12:31:25ЃЌжЛБЃСєвЛИідТЕФЪ§ОнЃЌЭЌЪБВщбЏЪЧАДЬьЮЌЖШGroup
By ВЛЙиаФаЁЪБЗжжгПЩвдАбШеЦкзЊГЩyyMMdd ЃЌ160715ЃЌетбљПЩвдМЋДѓЕФНЕЕЭЮЌЖШЛљЪ§ЃЛ
- ЛљЪ§аЁЕФЮЌЖШдкЧАУцЃЛ
- ЕЭЛљЪ§ЕФЮЌЖШОЁСПгУDictБрТыЃЈ100wвдФкЃЉЁЃ
ВуМЖЮЌЖШ/ХЩЩњЮЌЖШ
http : // kylin . apache . org / docs15
/ howto / howto_optimize_cubes . html
гХЛЏаЇЙћ
- Cube BuildКѓДѓаЁНЕЕЭЕН500GЩЯЯТЃЛ
- 50%ЕФВщбЏадФмдк2sвдФкЃЛ
- Cube BuildЪБМфЫѕЖЬ30%ЁЃ
ЦНЬЈМЏГЩ
ЖдНгМЏГЩПЊЗЂЦНЬЈ

етРяЛЙЪЧвЊЭЦМіЯТаЁБрЕФДѓЪ§ОнбЇЯАQQШЙ:532218147ЃЌВЛЙмФуЪЧаЁАзЛЙЪЧДѓХЃЃЌаЁБрЮвЖМЛЖгЃЌВЛЖЈЦкЗжЯэИЩЛѕЃЌАќРЈаЁБрздМКећРэЕФвЛЗн2018зюаТЕФДѓЪ§ОнзЪСЯКЭ0ЛљДЁШыУХНЬГЬЃЌЛЖгГѕбЇКЭНјНзжаЕФаЁЛяАщЁЃ
дкВЛУІЕФЪБМфЮвЛсИјНтД№ГЃМћЮЪЬт?
Q1 - ЖдmdxжЇГжЧщПіШчКЮЃП
ЯждкВЛжЇГжMDXВщбЏЃЌВщбЏШыПкЪЧSQLЃЌЯёSaikuетжжЛљгкMDXЕФВйзїЃЌЩчЧјвбОгаШЫЙБЯзСЫMondrian
JarАќЃЌПЩвдНЋSaiku ЧАЬЈЬсЙЉЕФMDXзЊЛЛЮЊSQLЃЌдйЭЈЙ§JDBC JarЗЂЫЭЕНKylin ServerЃЌВЛЙ§ЙІФмЩЯгаЫљЯожЦЃЌLeft
Join, Top N, Count DistinctжЇГжЪмЯоЁЃ
Q2 - їшїыеыЖдГіРДTМЖБ№ЕФЪ§ОнЃЌУПШежЦзїcubeДѓдМЛАЗбЖрОУЪБМфЃП
ОпЬхCubeЙЙНЈЪБМфЪгВЛЭЌЧщПіЖјЖЈЃЌОпЬхШЁОігкDimensionЪ§СПМАВЛЭЌзщКЯЧщПіЁЂCardinalityДѓаЁЁЂдДЪ§ОнДѓаЁЁЂCubeгХЛЏГЬЖШЁЂМЏШКМЦЫуФмСІЕШвђЫиЁЃдквЛаЉАИР§жаЃЌдквЛИіShared
ClusterЙЙНЈЪ§ЪЎGBЕФЪ§ОнжЛашвЊМИЪЎЗжжгЁЃНЈвщДѓМвдкЪЕМЪЛЗОГЯШНјааВтЪдЃЌбАевПЩвдЖдCubeНјаагХЛЏЕФЕуЁЃДЫЭтЃЌвЛАуРДЫЕЃЌCubeЕФдіСПЙЙНЈПЩвддкETLЭъГЩКѓгЩЯЕЭГздЖЏДЅЗЂЃЌЭљЭљетИіЪБМфКЭЗжЮіЪІзіЪ§ОнЗжЮіЪЧДэЗхЕФЁЃ
Q3 - ШчКЮЯђKylinЬсНЛДњТы?
НЋаоИФЕФДњТыгУGit Format-PatchзіГЩPatchЮФМўЃЌШЛКѓAttacheдкЖдгІЕФJiraЩЯЃЌKylin
CommitterЛсРДReviewЃЌУЛгаЮЪЬтЕФЛАЛсMergeЕНПЊЗЂЗжжЇЁЃ
Q4 - ШчЙћЪ§ОнЪЧдкElastic SearchЃЌKylinЕФжЇГжШчКЮ?
ФПЧАЛЙВЛжЇГжжБНгДгESГщШЁЪ§ОнЃЌашвЊЯШЕМГіЕНHiveдйзіCube BuildЃЛгааЫШЄЕФЭЌбЇПЩвдЛљгкKylin
1.5ЕФPluginМмЙЙЪЕЯжвЛИіESЕФData SourceЁЃ
Q5 - ЙЄзїЕФБШНЯКУЕФЧАЖЫЭЯзЇПиМўгаЪВУДЃП
ФПЧАгІИУЪЧTableauжЇГжНЯКУЃЌSaikuжЇГжВЛЪЧКмКУЃЌгааЉГЁОАШчLeft
Join, Count Distinct, Top NжЇГжВЛЪЧКмКУЃЌгУЛЇЪЧПЩвдЛљгкAPIПЊЗЂздМКЕФЭЯзЇвГУцЕФЁЃ
Q6 - ЖдЖрВЂЗЂжЇГжБэЯжШчКЮЃП
KylinКЭЦфЫћMPPМмЙЙММЪѕЯыБивЛДѓгХЪЦОЭдкИпВЂЗЂЁЃвЛЬЈKylinЕФQuery
ServerОЭжЇГжМИЪЎЕНЩЯАйЕФQPS (ШЁОігкВщбЏЕФИДдгЖШЃЌЛњЦїЕФХфжУЕШвђЫи)ЃЌЖјЧв KylinжЇГжСМадЕФЫЎЦНРЉеЙЃЌМДдіЖрKylin
ServerКЭHBaseНкЕуОЭПЩбИЫйдіДѓВЂЗЂЁЃ
Q7 - KylinПЩвдећКЯSpark Machine LearningКЭSpark
SQLТ№ЃП
ЛљгкЧАУцНВЕНЕФПЩВхАЮМмЙЙЃЌЪЧПЩвдећКЯЕФЁЃ
Q8 - ИњЦфЫќЙЄОпЖдБШЃЌгаУЛгаПМТЧCubeЕФЙЙНЈЪБМфЃП
вђЮЊШЫМвЪЧЪЕЪБМЦЫуЕФЃЌФуЪЧдЄМЦЫуЕФЃЌетДгЛњРэЩЯЪЧВЛвЛбљЕФЁЃKylinИњЦфЫќMPPМмЙЙЕФММЪѕдкВщбЏадФмЕФЖдБШЃЌЪБМфРяЪЧВЛКЌCubeЙЙНЈЕФЪБМфЕФЃЌЫљвдДгФГжжвтвхЩЯРДНВетбљЕФЖдБШЪЧгааЉВЛЙЋЦНЁЃЕЋЪЧЃЌДггУЛЇНЧЖШРДПДЃЌЗжЮіЪІКЭзюжегУЛЇжЛЙиаФВщбЏадФмЃЌЖјKylinгУдЄМЦЫуФмДѓДѓЬсИпВщбЏЫйЖШЃЌете§ЪЧгУЛЇЫљашвЊЕФЃЁ
Q9 - Kylin ODBC Ч§ЖЏГЬађгаЪОР§ДњТыЃП
ФПЧАДњТыдкMasterЗжжЇЃЌЛЖгДѓМвМгШыЩчЧјвЛЦ№ЙБЯзЁЃ
Q10 - 4вкЪ§ОнгаЕуЩйЃЌїшїыгаУЛгазіЙ§ЯрЙиЕФBenchmark
ЃЌдкАйвкМЖБ№Ъ§ОнЃЌЪЎИіЮГЖШЕФЧщПіЯТЃЌБэЯжШчКЮЃП
РДздЩчЧјЕФВтЪдЪ§ОнЃЌдквЛИіНќ280вкЬѕдЪМЪ§ОнЕФCubeЃЈ26TBЃЉЩЯЃЌ90%ЕФВщбЏдк5УыФкЭъГЩЁЃ
Q11 - Ъ§ОнСПЗБЖЕФЛА,ПеМфЪЙгУЛсзіжИЪ§МЖдіГЄУД?
ЭЈГЃCubeЕФдіГЄгыдЪ§ОнЕФдіГЄЛљБОвЛжТЃЌМДдЪ§ОнЗБЖЃЌCubeвВЗБЖЃЌЛђепИќаЁвЛаЉ,
ЖјЗЧжИЪ§діГЄЁЃ
|









