| БрМЭЦМі: |
| БОЮФРДздгкЬкбЖдЦЃЌБОЮФЪзЯШНщЩмСЫHadoopжаЕФResourceManagerжаЕФestimator
serviceЕФПђМмгыдЫааСїГЬЃЌШЛКѓЖдЦфжагУЕНЕФзЪдДЙРЫуЫуЗЈНјааСЫдРэЦЪЮіЁЃ |
|
вЛ. Resource Estimator ServiceЕФГіЗЂЕугыФПБъ
ЙРМЦзївЕдЫааЪЙгУзЪдДЪЧДѓЪ§ОнДІРэМЏШКЕФвЛИіживЊЧвОпгаЬєеНадЕФЮЪЬтЁЃЫцзХгУЛЇЪЙгУЕФМЏШКзЪдДдНРДдНЖрЃЌетвЛашЧѓБЛж№НЅЗХДѓЁЃЕБЧАЯжгаЕФНтОіЗНАИвЛАуЪЧвРРЕгкгУЛЇЕФОбщРДЖдзївЕзЪдДашЧѓНјааЙРМЦЃЌетбљМДЗБЫігжЕЭаЇЁЃИљОнЖдМЏШКЙЄзїИКдиЕФЗжЮіЃЌПЩвдЗЂЯжДѓВПЗжЙЄзї(ГЌЙ§60%)ЪЧжиИДЙЄзїЃЌетбљЮвУЧБугаЛњЛсИљОнзївЕРњЪЗзЪдДЪЙгУЧщПіРДЙРМЦзївЕЯТвЛДЮЕФзЪдДашЧѓСПЁЃЭЌЪБЃЌдкЮДРДЃЌЯЃЭћФмЬсГівЛжжгыПђМмЮоЙиЕФКкКаНтОіЗНАИЁЃетбљЃЌМДЪЙзївЕРДздВЛЭЌЕФМЦЫуПђМмЃЌЮвУЧвВФмЖджиИДадзївЕНјаазЪдДашЧѓЙРЫуЁЃ
Жў. Resource Estimator ServiceЕФПђМмНсЙЙ
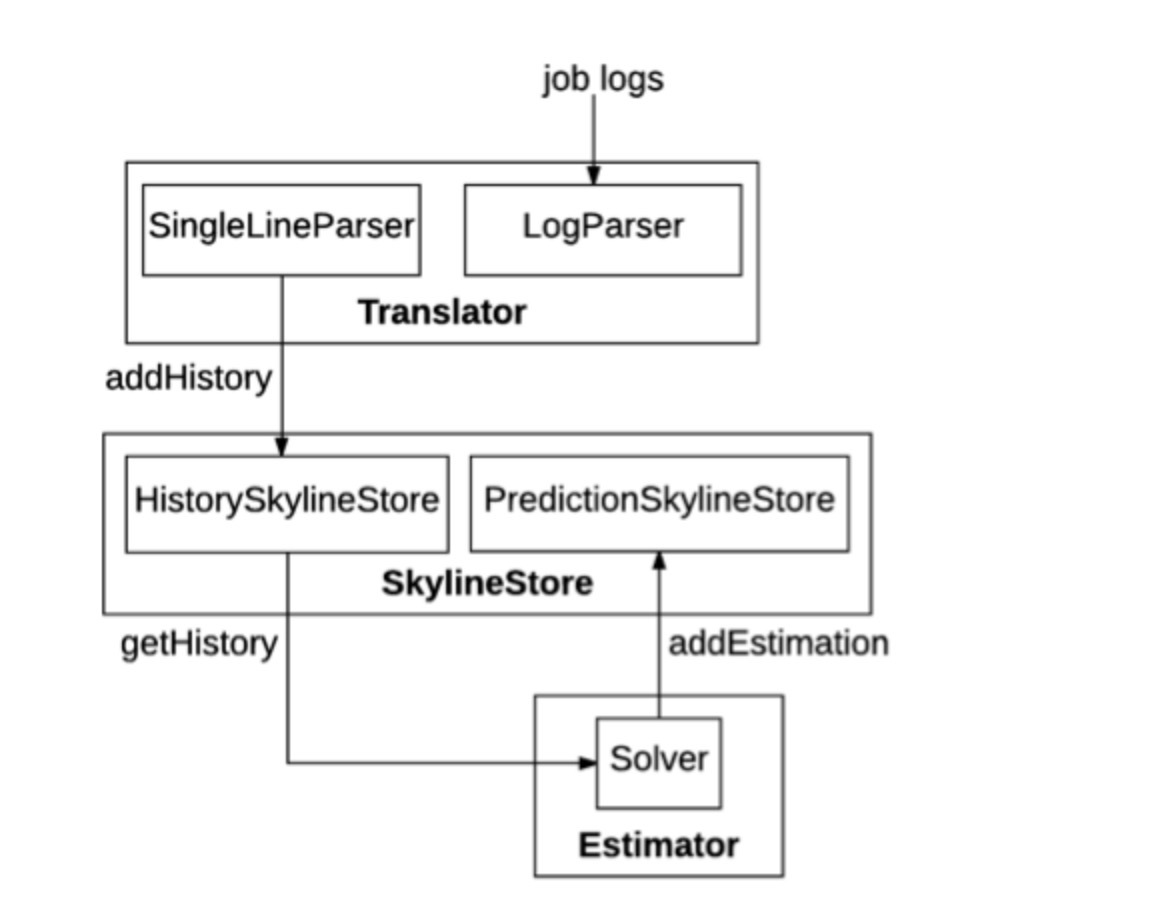
Hadoop-resource estimatorжївЊгЩШ§ИіФЃПщзщГЩЃКTranslatorЃЌSkylineStoreКЭEstimatorЁЃЯТУцЗжБ№НщЩметШ§ВПЗжЁЃ
1.ResourceSkylineгУРДБэеїзївЕдкЦфЩњУќжмЦкжаЕФзЪдДРћгУТЪЁЃЫќЪЙгУRLESparseResourceAllocationМЧТМШнЦїЗжХфЕФаХЯЂЁЃRecurrenceIdгУгкБъЪЖжиИДpipelineЕФЬиЖЈдЫааЁЃpipelineПЩвдАќКЌЖрИізївЕЃЌУПИізївЕЖМгавЛИіResourceSkylineРДБэеїЦфзЪдДРћгУТЪЁЃ
2.TranslatorгУРДНтЮізївЕШежОЃЌЬсШЁЫћУЧЕФResourceSkylinesВЂНЋЫќУЧДцДЂЕНSkylineStoreЁЃSingleLineParserНтЮіШежОСїжаЕФвЛааВЂЬсШЁResourceSkylineЁЃ
3.SkylineStoreГфЕБHadoop-resource estimatorЕФДцДЂВуЃЌгЩ2ВПЗжзщГЩЁЃHistorySkylineStoreДцДЂгЩзЊЛЛГЬађЬсШЁЕФResourceSkylinesЁЃЫќжЇГжЫФжжВйзїЃКaddHistoryЃЌdeleteHistoryЃЌupdateHistoryКЭgetHistoryЁЃaddHistoryНЋаТЕФResourceSkylinesИНМгЕНЖЈЦкpipelineЃЌЖјupdateHistoryЩОГ§ЬиЖЈЖЈЦкpipelineЕФЫљгаResourceSkylineЃЌВЂжиаТВхШыаТЕФResourceSkylinesЁЃPredictionSkylineStoreДцДЂгЩEstimatorЩњГЩЕФдЄВтRLESparseResourceAllocationЁЃЫќжЇГжСНИіВйзїЃКaddEstimationКЭgetEstimationЁЃ
4.EstimatorИљОнРњЪЗМЧТМдЫаадЄВтжиИДГіЯжЕФpipelineзЪдДашЧѓЃЌНЋдЄВтДцДЂЕНSkylineStoreВЂдкYARNЩЯНјаазЪдДдЄСєЁЃSolverЖСШЁЬиЖЈЖЈЦкpipelineЕФЫљгаРњЪЗResourceSkylinesЃЌВЂдЄВтЦфАќКЌдкRLESparseResourceAllocationжаЕФаТзЪдДашЧѓЁЃФПЧАЃЌHadoop-resource
estimatorЬсЙЉСЫвЛИіLPSOLVERРДНјаадЄВтЃЈЦфжагУЕНЕФЫуЗЈФЃаЭЛсдкКѓУцНјааНВНтЃЉЁЃ
Ш§.вдЪОР§demoбнЪОЦфдЫааСїГЬ
Resource Estimator ServiceЕФURIЪЧhttp://0.0.0.0ЃЌФЌШЯЗўЮёЖЫПкЪЧ9998
(дк$ ResourceEstimatorServiceHome/conf/resourceestimator-config.xmlЁБ
жаХфжУ)ЁЃ дк$ ResourceEstimatorServiceHome/dataжаЃЌгавЛИіЪОР§ШежОЮФМўresourceEstimatorService.txtЃЌЦфжаАќКЌ2ДЮдЫааЕФtpch_q12ВщбЏзївЕЕФШежОЁЃНјаазЪдДдЄВтжївЊгавдЯТМИИіВНжшЃК
1.НтЮізївЕШежОЃК
| POST
http://URI:port/resourceestimator/translator
/LOG_FILE_DIRECTORY |
ЗЂЫЭ
| POST
http://0.0.0.0:9998/resourceestimator/translator
/data/resourceEstimatorService.txt |
underlying estimatorНЋДгШежОЮФМўжаЬсШЁResourceSkylinesВЂНЋЫќУЧДцДЂдкjobHistory
SkylineStoreжаЁЃ
2.ВщбЏзївЕЕФРњЪЗResourceSkylinesЃК
| GET
http://URI:port/resourceestimator/skylinestore/
history/{pipelineId}/{runId} |
ЗЂЫЭ
| GET
http://0.0.0.0:9998/resourceestimator/
skylinestore/history/*/* |
underlying estimatorНЋЗЕЛиРњЪЗSkylineStoreжаЕФЫљгаМЧТМЁЃдкЪОР§ЮФМўжаФмЙЛПДЕНСНДЮдЫааtpch_q12ЕФResourceSkylinesЃКtpch_q12_0КЭtpch_q12_1ЁЃ
3.дЄВтзївЕЕФзЪдДЪЙгУЧщПіЃК
| GET
http://URI:port/resourceestimator/estimator/{pipelineId} |
ЗЂЫЭ
| http://0.0.0.0:9998/resourceestimator/estimator/tpch_q12 |
estimatorНЋИљОнЦфРњЪЗResourceSkylinesдЄВтаТдЫааЕФзївЕзЪдДашЧѓЃЌВЂНЋдЄВтЕФзЪдДашЧѓДцДЂЕНjobEstimation
SkylineStoreЁЃ
4.ВщбЏзївЕЕФдЄВтзЪдДЧщПіЃК
| GET
http://URI:port/resourceestimator/skylinestore
/estimate/{pipelineId} |
ЗЂЫЭ
| http://0.0.0.0:9998/resourceestimator/skylinestore
/estimation/tpch_q12 |
ЙРЫуЦїНЋЗЕЛиtpch_q12зївЕзЪдДдЄВтЧщПіЁЃ
5.ЩОГ§зївЕЕФРњЪЗзЪдДЧщПіЪ§ОнЃК
| DELETE
http://URI:port/resourceestimator/skylinestore
/history/{pipelineId}/{runId} |
ЗЂЫЭ
| http://0.0.0.0:9998/resourceestimator/skylinestore
/history/tpch_q12/tpch_q12_0 |
underlying estimatorНЋЩОГ§tpch_q12_0ЕФResourceSkylineМЧТМЁЃжиаТЗЂЫЭ
| GET
http://0.0.0.0:9998/resourceestimator/
skylinestore/history/*/* |
ЫФ.зЪдДдЄВтЫуЗЈжагУЕНЕФЪ§ОнНщЩм
Hadoop-resource estimatorЕФTranslatorзщМўЛсНтЮіШежОВЂНЋЦфАДеевЛЖЈЙцЗЖЕФИёЪННјааЦДНгЃЌЯТУцИјГіСЫЪОР§жаЕФзЪдДРњЪЗЪЙгУЪ§ОнКЭдЄВтзЪдДЪ§ОнЃЌПЩвдПДЕНзївЕЕФРњЪЗзЪдДЪЙгУЪ§ОнЪЧЭЌвЛИіjobЕФСНДЮrunЃЌЗжБ№ЮЊtpch_q12_0КЭtpch_q12_1,ЦфжївЊИјГіСЫЫцЪБМфБфЛЏЕФmemoryКЭcpuЕФЪЙгУЧщПіЁЃЦфжаЕк0ЪБМфЕЅЮЛБэЪОЕФЪЧcontainerЙцИёЃЌЮЊmemory:1024,vcores:1ЃЌЕк25ЪБМфЕЅЮЛЮЊзївЕНсЪјЪБПЬЃЌmemoryКЭcpuНдЮЊ0ЁЃПЩвдПДЕНдЄВтЪ§ОнИљОнРњЪЗЪ§ОнИјГіСЫ10~25ЪБМфЕЅЮЛЕФзЪдДдЄВтЪ§ОнЁЃ
РњЪЗзЪдДЪЙгУЪ§Он:
| [[{"pipelineId":"tpch\_q12","runId":"tpch\_q12\_0"},
[{"jobId":"tpch\_q12\_0","jobInputDataSize":0.0,
"jobSubmi
ssionTime":0,"jobFinishTime":25,"containerSpec":
{"memory":1024,"vcores":1},
"skylineList":
{"resourceAllocation":{
"0":{"memory":1024,"vcores":1},
"10":{"memory":1099776,"vcores":1074},
"15":{"memory":2598912,"vcores":2538},
"20":{"memory":2527232,"vcores":2468},
"25":{"memory":0,"vcores":0}}}}]],
[{"pipelineId":"tpch\_q12","runId":"tpch\_q12\_1"},
[{"jobId":"tpch\_q12\_1","jobInputDataSize":0.0,
"jobSubmi
ssionTime":0,"jobFinishTime":25,"containerSpec":
{"memory":1024,"vcores":1},
"skylineList":
{"resourceAllocation":{
"0":{"memory":1024,"vcores":1},
"10":{"memory":813056,"vcores":794},
"15":{"memory":2577408,"vcores":2517},
"20":{"memory":2543616,"vcores":2484},
"25":{"memory":0,"vcores":0}}}}]]] |
дЄВтЪ§Он:
| {"resourceAllocation":
"10":{"memory":1083392,"vcores":1058},
"15":{"memory":2598912,"vcores":2538},
"20":{"memory":2543616,"vcores":2484},
"25":{"memory":0,"vcores":0}}} |
Юх.Resource Estimator ServiceЫуЗЈПђМмгыдРэ
дкБОВПЗжНЋжиЕуНщЩмвЛЯТestimatorжагУЕНЕФзЪдДдЄВтЫуЗЈдРэЁЃДЫЫуЗЈгЩЮЂШэЬсГіЃЌЦфСДНгдкЮФФЉВЮПМзЪСЯжаИјГіЁЃЯТЭМЪЧestimatorЕФдЫааПђМмЃЌПЩвдПДЕНЦфжївЊгЩШ§ВПЗжзщГЩЃЌЯТУцЗжБ№НщЩметШ§ВПЗжЁЃ
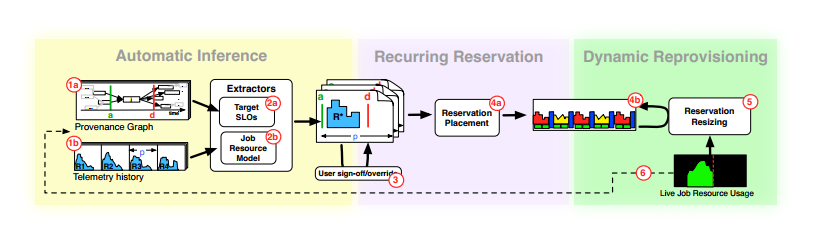
Automatic interence,ЬсШЁГізївЕЕФдЫааЪБМфКЭРњЪЗзЪдДЪЙгУЧщПіЁЃ
(a) Extractor of target,ФмЬсШЁГізївЕЕФдЫааПЊЪМгыНсЪјЪБМфЁЃ
(b) Job resource model,ФмЬсШЁГізївЕЕФзЪдДЪЙгУЧщПі,Р§ШчзївЕзЪдДЫцЪБМфдЫааЕФБфЛЏЧщПіКЭзЪдДЪЙгУзмСПЁЃ
Recurring Reservation,ДЫВПЗжАќРЈгаJob Resource ModelЃЌПЩвдИљОнзївЕРњЪЗдЫааЪБМфгызївЕРњЪЗзЪдДЪЙгУЧщПіИјГіЯТвЛШЮЮёЕФзЪдДЪЙгУЧщПіЁЃ
(a) ЭЈЙ§ИФБфВЮЪ§ІСЃЌПЩвдПижЦestimatorдкЗжХфзЪдДЕФЪБКђЪЧВржиЙ§ЗжХфЛЙЪЧВржиЧЗЗжХфЁЃ
(b) ИљОнзївЕзЪдДдЄВтФЃаЭИјГіЕФдЄВтжЕЮЊзївЕдкдРДЗжХфЕФзЪдДЕФЛљДЁЩЯЬэМгзЪдДЬэМгagendaЁЃДЫjobЯТвЛИіrunОЭдЫаадкДЫзЪдДЗжХфЕФЛљДЁЩЯЁЃ
Dynamic ReprovisioningЃЌДЫВПЗжИљОнЧАУцИјГіЕФзЪдДagenda,ЖЏЬЌЕїећзївЕЕФУПИідЫааНзЖЮЕФзЪдДЗжХфЁЃ
Сљ.ЫуЗЈдРэЦЪЮі
ЮЂШэЬсГіЕФДЫзЪдДЗжХфЫуЗЈБОжЪЩЯЪЧвЛжжзюгХЛЏЫуЗЈЃЌЦфгХЛЏЕФФПБъКЏЪ§ЪЧгЩСНВПЗжзщГЩЕФЯпадзщКЯЃЌЯТЮФжаstageЕФИХФюЪЧжИУПИіjobЕФдЫааЦкМфАДеевЛЖЈЙцдђЛЎЗжГЩЖрИіЪБМфЦЌЃЌУПИіЪБМфЦЌГЦжЎЮЊвЛИіstageЃЌЯТУцЗжВНжшВћЪіЦфЫуЗЈдРэЁЃ
1.ЪзЯШЖЈвхвЛИіФПБъКЏЪ§ЃЌвВПЩвдГЦжЎЮЊЫ№ЪЇКЏЪ§ЃЌМДЮвУЧгХЛЏЕФФПБъЁЃдкДЫЫуЗЈжагЩЙ§ЗжХфКЭЧЗЗжХфзщГЩЕФЯпадзщКЯзщГЩЫ№ЪЇКЏЪ§costfunctionЁЃФПБъОЭЪЧ,ЯТЭМБШНЯжБЙлЕФЯдЪОСЫestimatorдкдЄВтзЪдДЪБЕФвЛжжЙ§ЗжХфгыЧЗЗжХфЕФЧщПіЁЃ

2.еыЖдУПИіstage,ДЫЫуЗЈЕФВпТдОЭЪЧбЁдёПЩвдЪЙЕУcostfunctionзюаЁЕФзЪдДЗжХфЗНЪНЃЌМДбЁдёвЛИіжЕЪЙЕУcostfunctionзюаЁЃЌМДЕУЕН,МДУПвЛИіstageЩЯЕФзЪдДЗжХфжЕЁЃ
вђЮЊЗжХфжЕЪЧЙЬЖЈЙцИёЕФБЖЪ§ЃЌЫљвддкЪЕЯжЪБПЩвдЭЈЙ§МђЕЅЕФforбЛЗЛђепвЛаЉзюгХЛЏЫуЗЈБШШчХРЩНЗЈЛђепвЯШКЫуЗЈОЭПЩвдПьЫйЕУЕНзюаЁжЕЁЃ
3.змНсЃКЫуЗЈжаЕФзіЗЈЪЧеыЖдвЛИіjobЃЌИљОнЦфРњЪЗдЫааЪБМфФУЕНЦфзївЕПЊЪМКЭНсЪјЪБМфЃЌдкетЪБМфЖЮФкАДеевЛЖЈЙцдђЛЎЗжЪБМфЦЌЃЌУПвЛИіЪБМфЦЌЮЊвЛИіstageЃЌИљОнЭЌвЛjobЖрДЮrunЕФРњЪЗзЪдДЪЙгУЧщПіРДдЄВтЯТвЛrunЕФзЪдДЪЙгУЧщПіЁЃЦфУПДЮХфжУЕФВпТдЪЧЪЙЕУcostfunctionзюаЁЁЃcostfunctionЪЧЙ§ЗжХфгыЧЗЗжХфЕФвЛИіЯпадзщКЯЁЃ
Цп.ЫуЗЈЕФВтЪдаЇЙћ
дкБОДЮВтЪджадЫааtpch_q12зївЕ9ДЮЃЌВЂдкУПДЮдЫаажаЪеМЏзївЕЕФзЪдДskylinesЁЃШЛКѓЃЌдкResource
Estimator ServiceжадЫааШежОНтЮіЦїЃЌДгШежОжаЬсШЁResourceSkylinesВЂНЋЫќУЧДцДЂдкSkylineStoreжаЁЃЯТУцЛцжЦСЫзївЕЕФResourceSkylinesвдНјаабнЪОЁЃ

дкResource Estimator ServiceжадЫааЙРЫуЦїРДдЄВтаТдЫааЕФзЪдДашЧѓ,ЯТУцЛцжЦСЫдЄВтЕФзЪдДашЧѓЪ§ОнЁЃПЩвдПДЕНдЄВтЪ§ОнИљОнРњЪЗзЪдДЪЙгУЧщПіНЯКУЕиБэеїСЫЯТвЛДЮдЫааЕФзЪдДЪЙгУЪ§ОнЃЌгавЛЖЈЕФВЮПМвтвхЁЃСэЭтдкЪЕМЪГЁОАвЕЮёЩЯЕФВтЪдаЇЙћЛЙгаД§ПМжЄЁЃ

|









