| БрМЭЦМі: |
| БОЮФРДздгкinfoqЃЌБОЮФЪЙгУСЫ
Apache KylinЃЌЪ§ОнЗжЮіЪІПЩвджБНгВщбЏДѓЪ§ОнЁЂЮоашХХЖгЁЂбЧУыМЖЯьгІЃЌећЬхПЊЗЂаЇТЪЬсИпСЫ
10 БЖвдЩЯЁЃ |
|
ЮЊЪВУД Apache Kylin ЪЧЗжЮіЪІЕФБъХфММФм
ЫЕЕН Apache KylinЃЈвдЯТМђГЦ KylinЃЉЃЌЖдгкзіДѓЪ§ОнПЊЗЂЃЌгШЦфЪЧЪ§ОнВжПтПЊЗЂЕФЭЌбЇЃЌМДЪЙУЛгУЙ§ЃЌжСЩйвЛЖЈЛђЖрЛђЩйЬ§Й§ЃЌЕЋЖдгкЪ§ОнЗжЮіЪІЖјбдЃЌПЩФмВЛвЛЖЈЪЎЗжЪьЯЄЃЌдкТэЗфЮбЃЌРћгУ
KylinЃЌздМКЖЏЪжДюНЈЫљИКд№вЕЮёЕФЪ§ОнВжПтЃЌвбОГЩЮЊЪ§ОнЗжЮіЪІШеГЃЙЄзїЕФвЛВПЗжЃЌЪЧЗжЮіЪІЕФБъХфММФмЁЃ

ДЋЭГЕФИљОнЪ§ОнСїНјааЗжВуЕФЪ§ОнЭХЖгзщжЏМмЙЙжаЃЌЪ§ОнЗжЮіЭХЖгДѓЖрЪЧзїЮЊЪ§ОнЦНЬЈЕФЪЙгУепЃЌЭЈЙ§ИїжжЪ§ОнКѓЬЈЃЌЬсШЁЪ§ОнНјааЗжЮіЙЄзїЃЌетИќЖрЪЧбигУСЫДѓЪ§ОнММЪѕаЫЦ№ЧАЕФзщжЏМмЙЙЁЃ
ДгвЕЮёНЧЖШПДЃКЫцзХвЕЮёИДдгадМАвЕЮёЗЂеЙЫйЖШдНРДдНПьЃЌгШЦфЪЧТэЗфЮбЕФвЕЮёДгзюГѕЕФЩчЧјЁЂЕНЙЅТдЁЂдйЕННќСНФъж№НЅЗЂСІЕФОЦЕъКЭЕчЩЬЦНЬЈЕШЩЬвЕЛЏвЕЮёЯпЃЌЩцМАгУЛЇТУааЕФааЧАЁЂаажаЁЂааКѓЕФЫљгаЛЗНкЃЌзіећИіТУгЮаавЕЕФБеЛЗЁЃТэЗфЮбФкВПИќЯёЪЧвЛИіМЏЭХЙЋЫОЃЌИїИіЭХЖгМфЕФвЕЮёЧщПіЁЂЪ§ОнашЧѓМАЗЂеЙНзЖЮгаКмДѓВЛЭЌЃЌНсКЯздЩэвЕЮёЕФИДдгадЃЌДЋЭГЕФАДВПОЭАрЃЌВуВуЖбЕўЕФзщжЏНсЙЙКЭзіЪТЗНЪНЃЌвбОВЛзувдЪЪгІЕБЯТЕФвЕЮёЗЂеЙвЊЧѓЁЃ
ДгЪ§ОнЗжЮіНЧЖШРДПДЃЌгЩгкзщжЏНсЙЙЕФЗжВуЃЌвВЭљЭљШнвзГіЯжЬпЦЄЧђЃЌЪ§ОнЯюФПжмЦкРГЄЃЌЩѕжСвђВуВуДЋЕнЕМжТЕФРэНтЦЋВюЃЌЫљДјРДЕФЧБдкЮЪЬтЕШЁЃ
ДгММЪѕНЧЖШПДЃКЫцзХ Kylin ЕШЯрЙиДѓЪ§ОнММЪѕЕФШеЧїГЩЪьЃЌИїЙЋЫОЪ§ОнМмЙЙДѓЭЌаЁвьЃЌжиаФвбДгДгЛљБОМмЙЙКЭЙІФмЪЕЯжЃЌж№НЅБфЮЊШчКЮГфЗжЮќЪеИїжжДѓЪ§ОнЯрЙиММЪѕЃЌШчКЮГфЗжЗЂЛгММЪѕгыЪ§ОнЕФМлжЕЁЃ
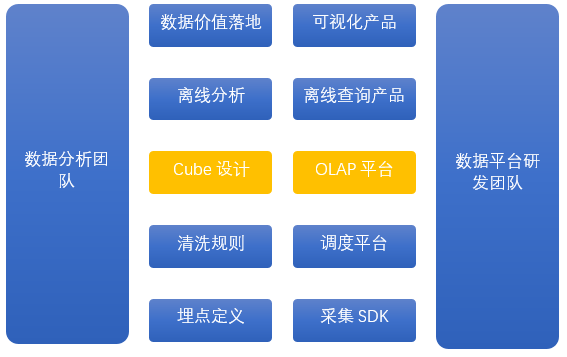
ЭЈЙ§Ъ§ОнЦНЬЈВњЦЗЛЏЃЌИГФмИјЪ§ОнЗжЮіЪІЮЊДњБэЕФЗЧЪ§ОнПЊЗЂаЁЛяАщЃЌЙВЭЌНјааЪ§ОнЦНЬЈНЈЩшЁЃ
зїЮЊбаЗЂЮЊжїЕФЪ§ОнЦНЬЈЭХЖгЃЌгЩЗтБеЕФЪ§ОнСїЕФПЊЗЂепЃЌзЊЮЊПЊЗХЕФЪ§ОнЦНЬЈВњЦЗЕФЩшМЦгыЪЕЯжепЃЌГфЗжНЋЪ§ОнСїИїЛЗНкВњЦЗЛЏЃЌНЋЛЗНкжаЕФЕФЪ§ОнгыММЪѕФмСІЭЈЙ§Ъ§ОнВњЦЗПЊЗХГіРДЃЌдЪаэЗжЮіЪІЕШЪ§ОнЪЙгУепМгШыНјРДЃЌПЊЗХЙВНЈЦНЬЈЁЃ
зїЮЊЖдНгЪ§ОнгывЕЮёЕФжїСІОќЃЌЪ§ОнЗжЮіЪІДгвЛИізюЩЯВуЕФЪ§ОнЪЙгУепЃЌзЊБфЮЊЪ§ОнШЋЩњУќжмЦкЕФЙмРэепКЭНЈЩшепЃЌФмЙЛЖдЪ§ОнзіЕНЖЫЕНЖЫЕФАбПиЃЌвЛЭЗПижЦЪ§ОндДЭЗЃЌвЛЭЗПижЦЪ§ОнашЧѓЃЌжаМфЭЈЙ§Ъ§ОнЦНЬЈИїИіВњЦЗзджњЭъГЩЪ§ОнСїЃЌжАд№ИВИЧЪ§ОнТёЕуЖЈвхЁЂЧхЯДЙцдђЩшСЂЃЌЪ§ОнВжПтЩшМЦгыЪЕЯжЃЌРыЯпЗжЮіЁЂПДАхХфжУЃЌAPI
ЪфГіЁЂЭЦЖЏЪ§ОнЯюФПТфЕиЕШЁЃ
Kylin зїЮЊвЛИіГЩЪьЕФ OLAP в§ЧцЃЌБЛв§ШыЕНЪ§ОнЦНЬЈЕФВњЦЗНЈЩшжаЃЌЭЈЙ§МђЕЅЕФЖўДЮПЊЗЂгыМЏГЩЃЌЪЙЕУЪ§ОнВжПтЕФНЈЩшФмСІЕУвдПЊЗХГіРДЃЌДѓДѓНЕЕЭСЫЪ§ОнВжПтЕФНЈЩшУХМїЃЌЪЙЕУЪ§ОнЗжЮіЪІФмЙЛКмКУЕФдкЦфЩЯНјааЪ§ОнВжПтЕФЖЈвхгыЙЙНЈЃЌДјРДСЫУыМЖЕФВщбЏЯьгІЫйЖШЃЌДѓДѓЬсЩ§СЫЗжЮіЪІШеГЃЪ§ОнВщбЏаЇТЪЃЌМАЯрЙиЪ§ОндквЕЮёГЁОАжаЕФТфЕиЁЃ
Kylin дкТэЗфЮбЗжЮіЪІЭХЖгЕФШеГЃ
вдТэЗфЮбПЭЗўЗўЮёжЪСПЭГМЦашЧѓЮЊР§ЃЌвЕЮёВПУХЯЃЭћФмЙЛДгУПЬьМДаЫХм SQL етжжСйЪБВщбЏЕФЗНЪНЃЌЩ§МЖЮЊШеГЃПЩЪЙгУЕФКѓЬЈЁЃКѓЬЈжажївЊЭГМЦжИБъЮЊЃКДгЕъЦЬЮЌЖШЃЌЙмМвЮЌЖШЃЌЩЬЦЗЮЌЖШКЭФПЕФЕиЮЌЖШЗжБ№ЭГМЦЯњЪлвЕМЈКЭЗўЮёжЪСПЁЃЯњЪлвЕМЈКЭЗўЮёжЪСПОпЬхашЧѓШчЯТЭМЃК

дк Kylin УЛгаГЩЮЊЪ§ОнЗжЮіЪІБъХфжЎЧАЃЌетбљЕФвЛИіКѓЬЈашвЊЧАКѓЖЫПЊЗЂ / Ъ§ОнЗжЮіЪІ / Ъ§ОнПтЙЄГЬЪІКЭЪ§ОнПЊЗЂЙЄГЬЪІазїЃЌДѓдМашКФЪБ
1 ИідТЃЌЛЙШнвзвђЮЊПЊЗЂЖдвЕЮёВЛРэНтШнвзЕМжТжИБъЭГМЦГіЮЪЬтЁЃ
ЯждкдкТэЗфЮбЃЌжЛашвЊЗжЮіЪІКЭашЧѓЗНРэЧхашЧѓЃЌШЗЖЈКУЭГМЦжїЬтЃЌИїжїЬтЯТЗжБ№ЭГМЦФФаЉЮЌЖШЃЌИїИіЮЌЖШЯТгжгаФФаЉЖШСПЃЌвдМАЖШСПЕФЭГМЦСЃЖШКЭЭГМЦПкОЖЃЌОЭПЩвдвРЭаЪ§ОнВњЦЗЃЌЖРСЂЭъГЩЭГМЦКѓЬЈДюНЈЃЌКФЪБдМвЛжмЃЌећЬхПЊЗЂаЇТЪЬсЩ§
10 БЖвдЩЯЃЌОпЬхЙЄзїСїГЬШчЯТЭМЁЃ

Ъ§ОнЗжЮіЪІдкРэЧхашЧѓКѓЃЌДгШ§ИіЗНУцЖдЛљДЁЪ§ОнНјаагааЇадбщжЄЃК
вЛЪЧвРОнШежОЩшМЦЮФЕЕж№вЛаЃЖдШежОЪЧЗёАДеежИЖЈЕФвЊЧѓгыТпМЩЯБЈЃЛ
ЖўЪЧГщбљЖдЛљДЁЪ§ОнзіУшЪіадЭГМЦЃЌАќРЈИїИізжЖЮЕФОљжЕ / жаЮЛЪ§ / ЫФЗжЮЛЪ§ / МЋжЕ / ШБЪЁжЕИіЪ§НјааЭГМЦЃЌзіЕНдкЭГМЦВуУцЩЯЖдЪ§ОнаФжагаЪ§ЃЛ
Ш§ЪЧЖдЙиМќНкЕуЪ§ОнКЭПЊЗЂВтЪдвЛЦ№ЃЌНјааТпМаЃЖдЃЌжЦзїЪ§ОнжЪСППДАхЃЌВЂеыЖдЙиМќЪ§ОнЃЌгЩВтЪдЭХЖгБраДздЖЏЛЏВтЪдгУР§НјааЪ§ОнаЃбщЃЌЫЋжиБЃжЄЪ§ОнжЪСПЃЌОЁПЩФмзіЕНЪ§ОндкВњЩњЕФЪБКђВЛГіЮЪЬтЃЌГіСЫЮЪЬтЃЌвВФмдкЕквЛЪБМфИажЊВЂаоИДЁЃ
ЗжЮіЪІЖдЪ§ОнЕФгааЇадбщжЄЭъКѓЃЌВЩгУ HIVE ЪгЭМЕФЗНЪНЃЌвРОнЭГМЦТпМЖдЪ§ОнНјааЧхЯДКЭећРэЁЃдкБОР§жаЃЌашвЊНЋ
IM ЛсЛАаХЯЂЃЌВњЦЗЛљДЁаХЯЂЃЌПЭЗўЗўЮёЪБМфаХЯЂЃЌВњЦЗЖЉЕЅаХЯЂЗжБ№АДееЖдгІЕФжїЬтЃЌДДНЈЪТЪЕБэКЭЮЌЖШБэЁЃгаСЫЪТЪЕБэКЭЮЌЖШБэКѓЃЌПЩвдОнДЫПьЫйгУ
Kylin ДюНЈ CUBEЁЃ
дкЪЙгУ Kylin ЕФЪБКђгаШ§ИіШнвзГіЯжЕФЮЪЬтЃК
вЛЪЧЗжЮіЪІЖдЪ§ОнВжПтЕФаЧаЭФЃаЭЃЌбЉЛЈФЃаЭЃЌЛђепаЧЯЕФЃаЭЕШРэНтВЛЙЛЃЌКмШнвзГщРыВЛГіРДЮЌЖШБэЃЌзіГіРДЕФЪЧвЛеХвЕЮёДѓПэБэЃЌОнДЫДДНЈЕФ
CUBE ХђеЭТЪНЯИпЃЌжЛЪЧРћгУСЫ Kylin ЕФдЄМЦЫуФмСІЃЌПьЫйГіЭГМЦНсЙћЃЛ
ЖўЪЧЗжЮіЪІКмФбЦНКтМЦЫуЪБМфКЭДцДЂПеМфЕФЙиЯЕЃЌЭљЭљЛсИљОнвЕЮёЗНЕФашЧѓЃЌЙ§ЗжЧПЕїЯьгІЫйЖШЃЌАбвЛаЉВЛЬЋШнвзгУЕНЕФЮЌЖШвВЗХдк
CUBE РяЃЌЕМжТ CUBE Ъ§СПЖрЃЌХђеЭТЪИпЃЌеМгУДѓСПМЦЫуКЭДцДЂзЪдДЃЛ
Ш§ЪЧЗжЮіЪІЖд Kylin ЕзВуЫуЗЈВЛРэНтЃЌгХЛЏ CUBE ФмСІгаЯоЁЃФПЧАВЩгУЕФЗНАИЪЧЃЌЗжЮіЪІДДНЈ CUBE
КѓгЩзЈШЫИКд№ЩѓКЫКЭгХЛЏЁЃ
ЗжЮіЪІДДНЈЭъ CUBE КѓЃЌдк MDWЃЈзЂЃКТэЗфЮбЭГМЦжИБъПтЃЉжагУ SQL ДДНЈжИБъВЂЖЈвхЮЌЖШЁЃMDW
ВЛДцДЂгЩ CUBE зїЮЊЪ§ОндДЕФЪ§ОнЃЌжЛЪЧБЃСєСЫМЦЫужИБъЕФ SQLЃЈМЦЫуТпМЃЉЃЌВЂдкашвЊЕФЪБКђШЅ Kylin
жаЪЕЪБЛёШЁЪ§ОнЁЃ
MDW гаБъзМЕФ API НгПкЃЌПЩвдЮоЗьНгШыТэЗфЮбЕФЪ§ОнПДАхЯЕЭГЁЃЗжЮіЪІРћгУЪ§ОнПДАхЯЕЭГЃЌНЋ MDW
жИБъАДеежїЬт / ЮЌЖШЕШзщКЯГЩЬиЖЈЕФПДАхзщЃЌВЂХфжУКУПДАхКЭПДАхЯрЛЅжЎМфЕФЬјзЊЙиЯЕЃЌПДАхФкВПвРЭа MDW
ФкЖдЭЌвЛжИБъВЛЭЌЮЌЖШЕФЙмРэЪЕЯжЯТзъКЭЩЯОэЁЃДЫЪБЃЌТэЗфЮбПЭЗўЗўЮёжЪСПЭГМЦКѓЬЈОЭЛљБОДюНЈЭъГЩЃЈШчЯТЭМЃЉЁЃ
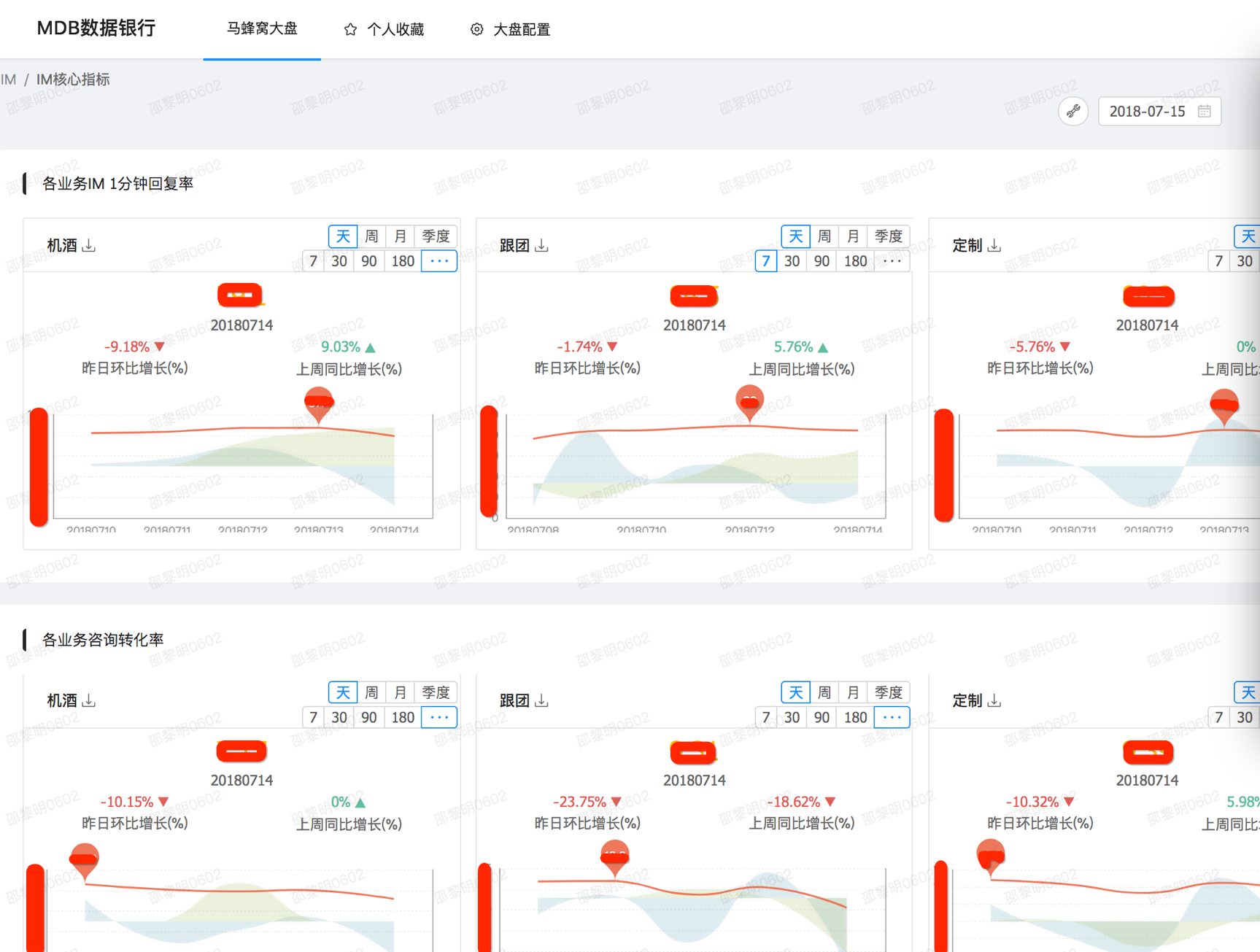
Kylin МЏГЩЕНЪ§ОнЦНЬЈЕФОбщ
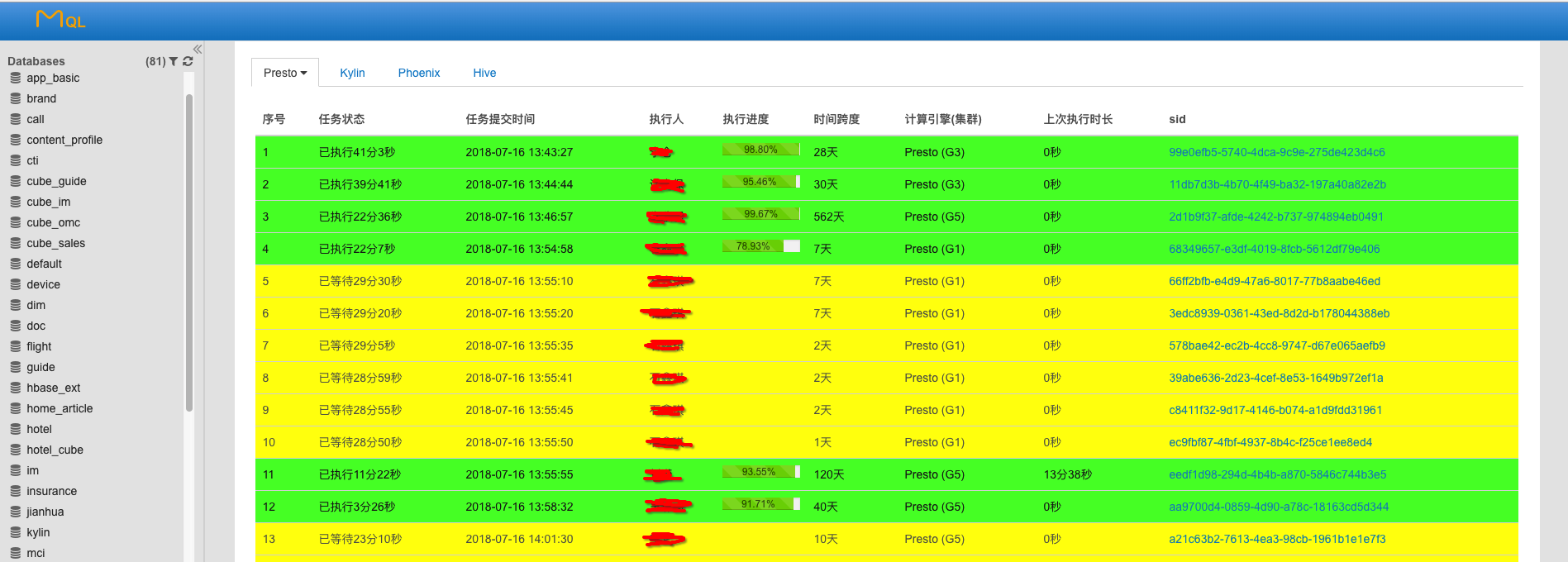
ШчЩЯЭМЫљЪО, Ъ§ОнЗжЮіЪІШеГЃЙЄзїжаДѓВПЗжЕФМДаЫВщбЏЪЧЛљгк MQL(ЮвУЧЕФ OLAP ЦНЬЈ) РДЬНЫїЪ§ОнЃЌMQL
ФкжУжЇГж Presto,Hive,Kylin,Phoenix ЕШВЛЭЌ SQL в§ЧцЁЃ
ЫцзХвЕЮёЗЂеЙЃЌЪ§ОнЗжЮіЪІЬсНЛЕФ Presto SQL ШЮЮёЃЌЭљЭљЪмЯогк Presto МЏШКЕФВЂЗЂадМАвЛаЉДѓзЪдДПЊЯњЕФ
SQL гАЯьЃЌЮвУЧЭЈЙ§в§ШыЗжМЏШКЖгСаЕФХХЖгЕїЖШЃЌОЁПЩФмБЃжЄЗжЮіЪІЕФ SQL жДааГЩЙІТЪЃЌЕЋШДдіМгСЫЕШД§ЕФЪБМфЁЃ
ЮвУЧУПЬьга 160+ ИігУЛЇдкЪЙгУ MQL, УПЬьдМ 2k+ ДЮ SQL ВщбЏЁЃдкЩЯЭМЕФШЮЮёзДЬЌжаЃЌЮвУЧПЩвдПДЕНЫцзХ
Presto SQL ЕФЬсНЛЃЌЗжЮіЪІУЧЕФЪ§ОнЬНЫїЪБМфГіЯжЯпадЪНЕФдіГЄЃЌЫћУЧашвЊЕШД§АыаЁЪБЃЌЩѕжСвЛаЁЪБЕФЪБМфВХФмжДааЫћУЧЕФ
SQL ШЮЮёЁЃ
ТэЗфЮбДѓЪ§ОнЦНЬЈзд 2017 ФъЯТАыФъв§Шы Kylin вдРДЃЌЦфбЧУыМЖЕФЯьгІЫйЖШЃЌМЋДѓЕФЬсЩ§СЫЪ§ОнЗжЮіЪІЖдгкЪ§ОнЕФЬНЫїЕФаЇТЪЁЃЯждкЪ§ОнЗжЮіЪІдк
MQL НјааЬсНЛ Kylin SQL КѓЃЌЮоашХХЖгЃЌбЧУыМЖЯьгІЃЌЯрБШгкжЎЧАЕФ Presto SQL
ШЮЮёЃЌKylin ИјЗжЮіЪІУЧМѕЩйСЫМИЪЎБЖЃЌЩѕжСМИАйБЖЕФЕШД§ЪБМфЃЌИјЪ§ОнЗжЮіЪІЕФЙЄзїДјРДСЫКмДѓЕФаЇТЪЁЃ
ЕБЧАдкТэЗфЮб Kylin ЦНЬЈЃЌЮвУЧга 80+ Иі cube дк Kylin ЩЯдЫзЊЃЌ90% ЕФ
cube дк 5s ФкЯьгІЃЌУПЬьдМ 5w+ ДЮ Kylin ЕїгУЁЃЮвУЧЕФ cube вбОИВИЧСЫТэЗфЮбЫљгаЕФвЕЮёЯпЃЌШчЕчЩЬЃЌОЦЕъЃЌЫбЫїЃЌЭЦЫЭЃЌгУЛЇдіГЄЕШЕШвЕЮёЯпЁЃ
ЯТУцНЋЗжГЩ 3 ИіВПЗжРДНВЯТ Kylin дкТэЗфЮбЕФЪЕеНЁЃ
1. Kylin дкТэЗфЮбЪ§ОнЦНЬЈЕФгІгУ
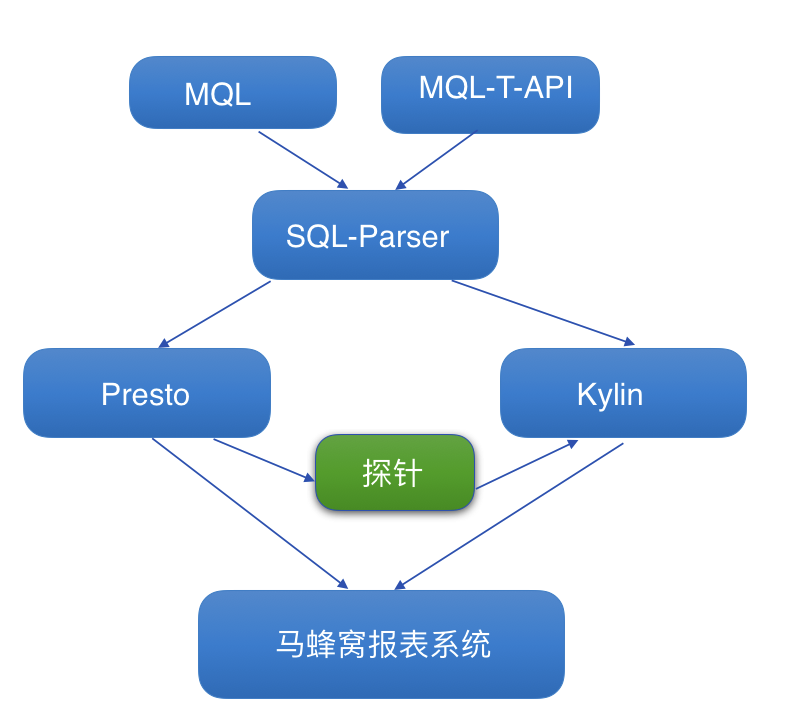
ШчЩЯЭМЫљЪОЃЌЮвУЧЙцЗЖСЫЪ§ОнЗжЮіЪІЪ§ОнЬНЫїЕФЭГвЛШыПкЁЃMQL зїЮЊТэЗфЮбЕФ OLAP ЦНЬЈЃЌЫљгаЪ§ОнЗжЮіЪІЭЈЙ§
MQL ЬсНЛ SQL жЎКѓЃЌЯЕЭГИљОнЗжЮіЪІЫљбЁЕФв§ЧцРДНЋ SQL ЗжЗЂЕНВЛЭЌЕФ Presto ЦНЬЈКЭ
Kylin ЦНЬЈЁЃ
Г§ДЫжЎЭт, ЯЕЭГИљОн SQL НтЮіЦїШЅЛёШЁЗжЮіЪІ SQL РяЕФзжЖЮСаКЭЬѕМўСа, вдБуКѓајЮвУЧФмгаеыЖдадЕФЖд
Kylin cube НјаагХЛЏЁЃMQL-T-API ЪЧЖдЭтЪфГіЕФЪ§ОнЛёШЁ APIЃЌЗжЮіЪІЭЈЙ§ MQL
Template НјааФЃАхДДНЈКѓЃЌНЋФЃАхСДНгЗжЯэИјЦфЫћЙЄГЬЪІЃЌЙЄГЬЪІЭЈЙ§ГЬађЕїгУФмдкМЋЖЬЕФЪБМфФкЃЌЮоЗьЕФНгШыЕНИїИіЪ§ОнБЈБэКѓЬЈМАвЕЮёЯЕЭГЃЈР§ШчЖЈЯђЭЦЫЭЃЉЕБжаЁЃ
дкЭМжаЫљЪОЃЌЮвУЧгаИіЬНеыФЃПщЃЌРћгУЬНеыРДШЅИњзйВЂЦРЙРЗжЮіЪІЫљЬсНЛЕФ SQLЃЌАДееЙцЗЖЃЌЮвУЧЛсЩњГЩЬНеыФЃПщБЈБэЃЌЪфЫЭИјЗжЮіЪІЃЌРДШУЫћУЧАб
Presto SQL НЅНЅЕФзЊЛЏГЩ Kylin CubeЁЃетбљвЛРДЃЌЭЈЙ§ЬНеыФЃПщЃЌЮвУЧвВФмВЛЖЯШЅЗЂЯжВЂЭкОђ
Kylin Cube ЕФдіГЄЕу, ЭЌЪБЬсЩ§ЗжЮіЪІЕФЙЄзїаЇТЪЁЃ
2. Kylin дкТэЗфЮбЪ§ОнЦНЬЈЕїЖШСїГЬ

ШчЩЯЭМЫљЪОЃЌдкЪ§ОнВжПтжаЃЌЮвУЧАДВЛЭЌжїЬтНЈСЂЗжВуЃЌУПвЛВуЖМЛсгаВЛЭЌЕФЪ§ОнБэЃЌВЛЭЌЪ§ОнБэжаЛсгавРРЕЙиЯЕЁЃдкТэЗфЮбЪ§ОнЦНЬЈЃЌв§Шы
AirFlow ЭъГЩЛљгк DAG ЕФЪ§ОнбЊдЕвРРЕЕФЕїЖШЯЕЭГЁЃ
дк Kylin ЦНЬЈЃЌШЗБЃ cube ЕФОЭаїЪБМфЃЌе§ШЗЕФ build Ъ§ОнВЂДЅЗЂЯТгЮжИБъЦНЬЈЕФМЦЫуЃЌЪЧЗЧГЃЙиМќЕФвЛВНЁЃ
гЩгк Kylin Ъ§ОндДЖМРДзд Hive ВжПтЃЌЖјБэМШгаЮяРэБэКЭЪгЭМЃЌЮвУЧЛсАДее Kylin Project
ЗжЯюФПЯТШЅМгдиИїздЕФЪ§ОнБэЃЌЭЈЙ§НтЮіЦїШЅЛёШЁБэЪгЭМЫљвРРЕЕФЮяРэБэЃЌШЛКѓдк AirFlow ЕїЖШЦНЬЈШЅМьВтЫљгаЮяРэБэЛђЪгЭМЕФзДЬЌЃЌЖМзМБИОЭаїКѓЃЌВХЛсДЅЗЂ
Kylin Cube ЕФЙЙНЈЁЃ
дкећИіЪ§ОнбЊдЕЦНЬЈжаЃЌЮвУЧвВашвЊШЅМрПиИїИіБэЕФе§ГЃзДЬЌЃЌЭЈЙ§ЯЕЭГДгЖјФмздЖЏЕФЖўДЮЙЙНЈ Kylin
CubeЃЌвдШЗБЃЪ§Оне§ШЗЭГМЦгыЪЙгУЁЃ
3. Kylin дкТэЗфЮбЪ§ОнЦНЬЈЩЯЯпЕФБъзМСїГЬ
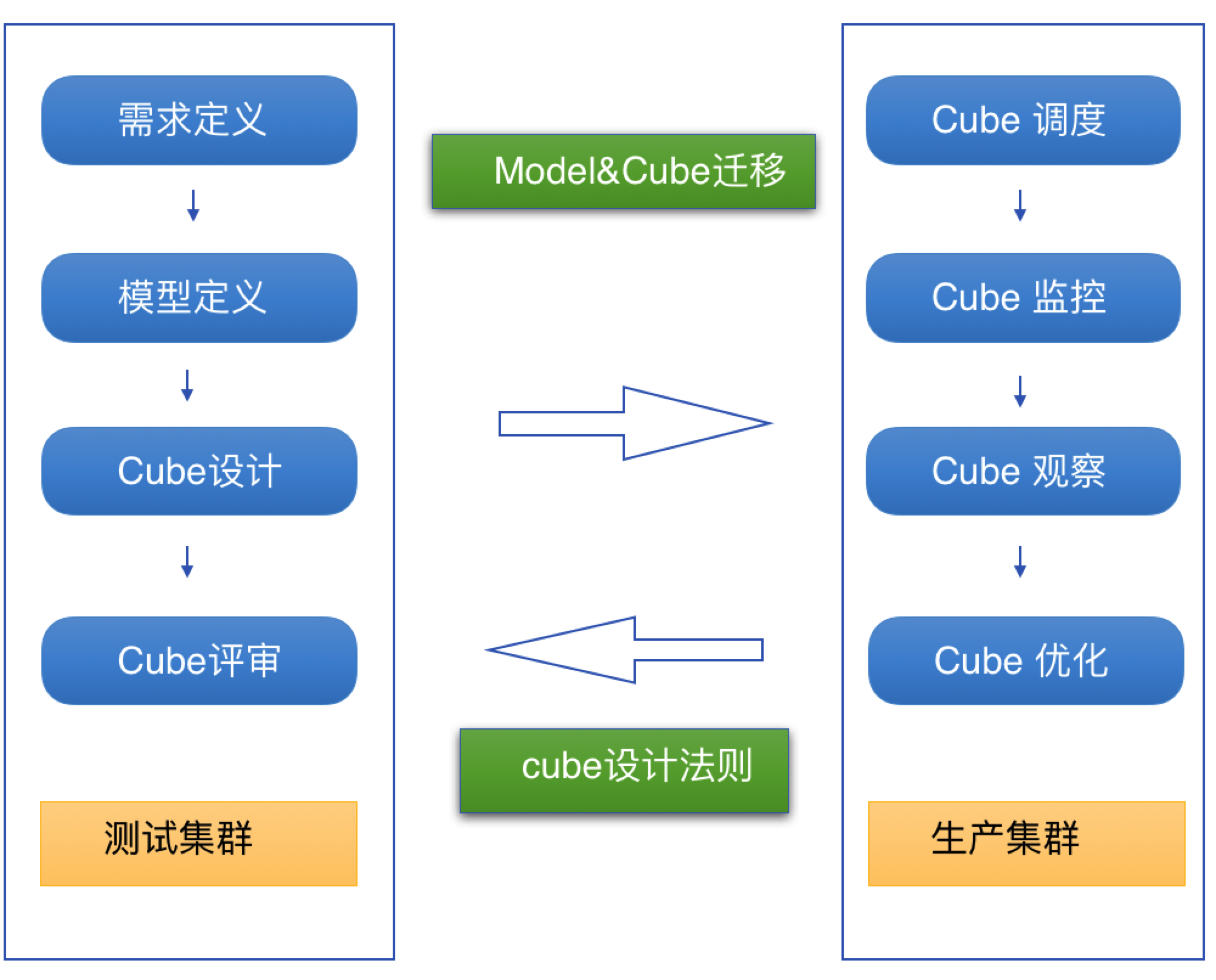
ШчЩЯЭМЫљЪОЃЌетЪЧаТ cube дкЩЯЯпжЎЧАЕФвЛИіБъзМСїГЬЁЃЫцзХТэЗфЮбвЕЮёЕФВЛЖЯЗЂеЙЃЌЮвУЧЪ§ОнЗжЮіЪІЭХЖгЕФеѓШндНРДдНДѓЁЃашвЊжЦЖЈвЛЬзБъзМСїГЬЃЌРДШЗБЃЯпЩЯЕФ
cube зуЙЛгХауКЭНЁзГЁЃЕБЧАЮвУЧВ№ЗжСЫСНЬзМЏШКЃЌвЛИіВтЪдМЏШККЭЩњВњМЏШКЁЃ
Ъ§ОнЗжЮіЪІдкВтЪдМЏШКЩЯАДееашЧѓНјаа cube ЩшМЦжЎКѓЃЌЮвУЧЛсЖдаТЕФ cube АДееБъзМ cube
ЩшМЦЗЈдђНјааЦРЩѓЃЌдкХаЖЯ cube зуЙЛКУжЎКѓЃЌЮвУЧжЛЛсЧЈвЦ mode КЭ cube дЊЪ§ОнЕНЩњВњМЏШКЃЌВЂМгШыЕїЖШЯЕЭГУПЬье§ГЃ
buildЁЃдкЩњВњМЏШКЃЌЮвУЧвВЛсЖдУПвЛИі cube ВщбЏНјааЖўДЮЙлВьЃЌАДееЦфВщбЏЬѕМўЙцдђРДЖд cube
НјааЖўДЮгХЛЏЁЃ
СэЭт, ЮвУЧвВВЛЖЯЕФМГШЁаавЕОбщЃЌВЂАДеездМКЪЕеНЕФОбщЃЌРДЙцЗЖВЂжЦЖЈвЛЬз cube ЩшМЦЕФЛљБОЗЈдђЃЌВЂАбЗЈдђЪфЫЭИјУПвЛИіЪ§ОнЗжЮіЪІЃЌЪЙЦфГЩЮЊвЛИіБъзМЕФ
cube ЙмРэепЁЃ
Нсгя
Kylin дкТэЗфЮбЕФе§ЪНЪЙгУВЛЕНвЛФъЕФЪБМфЃЌЖјзїЮЊЪ§ОнЗжЮіЪІЕФБъХфММФмЃЌвВЪЧдкЪЙгУЙ§ГЬжаж№ВНЛ§РлзмНсОбщаЮГЩЕФЃЌЦкМфашвЊЪ§ОнЗжЮіЭХЖгКЭЦНЬЈбаЗЂЭХЖгДѓСПЕФЙЕЭЈазїЃЌгХЛЏЦНЬЈВњЦЗгыЙЄзїСїГЬЃЌШУИќЖрЕФЪ§ОнЗжЮіЪІФмЙЛМндІ
Kylin етИіЧПДѓЕФЙЄОпЃЌЗўЮёКУИќЖрЕФвЕЮёГЁОАЃЌЬсЩ§ТэЗфЮбИїИіИкЮЛЕФаЁЛяАщЪ§ОнЪЙгУЕФаЇТЪЁЃ
ЮвУЧЛсМЬајЙизЂ Kylin ЩчЧјЕФЗЂеЙЃЌвВЯЃЭћИќЖрЕФШЫФмСЫНтВЂВЮгыНјРДЃЌдчЕуМндІКЭИаЪметжЛЧПДѓЩёЪоЕФСІСПЁЃ |









